SpringAI 使用 RAG
由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题:
- 知识数据比较落后,往往是几个月之前的
- 不包含太过专业领域 或者企业私有的数据
为了解决这些问题,我们就需要用到RAG了。
一、RAG原理
要解决大模型的知识限制问题,其实并不复杂。
解决的思路就是给大模型外挂一个知识库,可以是专业领域知识,也可以是企业私有的数据。
不过,知识库不能简单的直接拼接在提示词中。
因为通常知识库数据量都是非常大的,而大模型的上下文是有大小限制的,因此知识库不能直接写在提示词中。
怎么办?
思路很简单,庞大的知识库中与用户问题相关的其实并不多。
所以,我们需要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了。
那么该如何从知识库中找到与用户问题相关的内容呢?
而要从内容相似度来判断,就得用到向量模型了。
1.1 向量模型 -向量相似度
先说说向量,向量是空间中有方向和长度的量,空间可以是二维,也可以是多维。
向量既然是在空间中,两个向量之间就一定能计算距离。
我们以二维向量为例,向量之间的距离有两种计算方法:
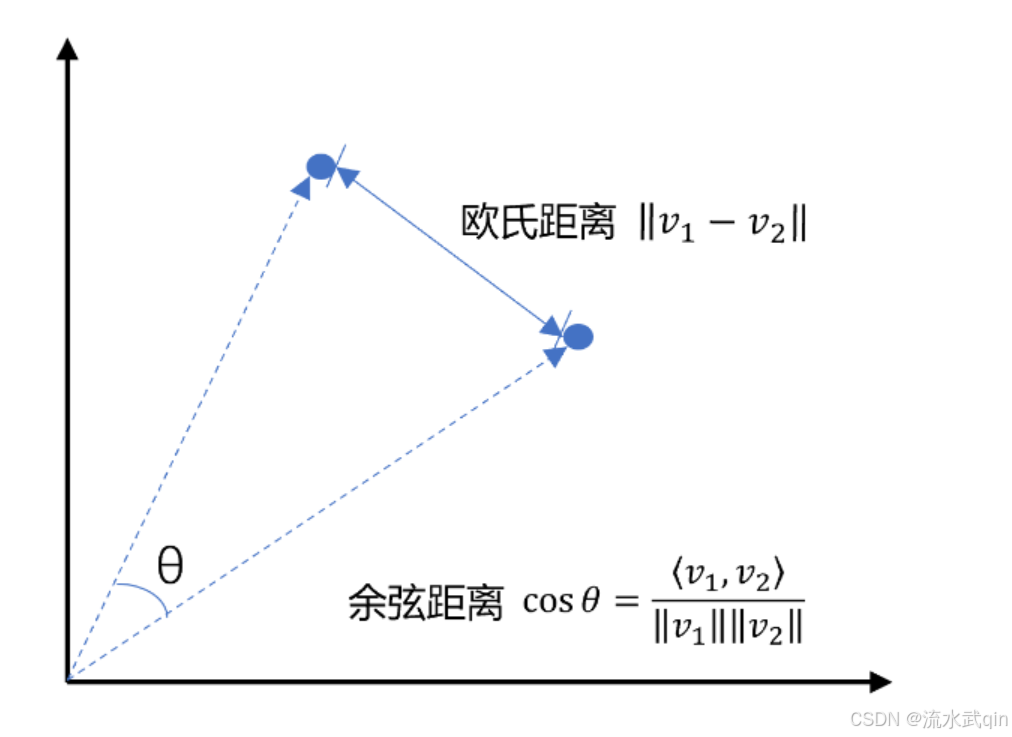
通常,两个向量之间欧式距离越近 ,我们认为两个向量的相似度越高。
而余弦距离相反,余弦距离越大,则余弦的夹角越小,那么两个向量的相似度就越高。
但是由于余弦距离没有涉及向量的长短,所以准确性会比欧式距离要差一些。
所以,如果我们能把文本转为向量 ,就可以通过向量距离来判断文本的相似度了。
现在,有不少的专门的向量模型 ,就可以实现将文本向量化。一个好的向量模型,就是要尽可能让文本含义相似的向量,在空间中距离更近:
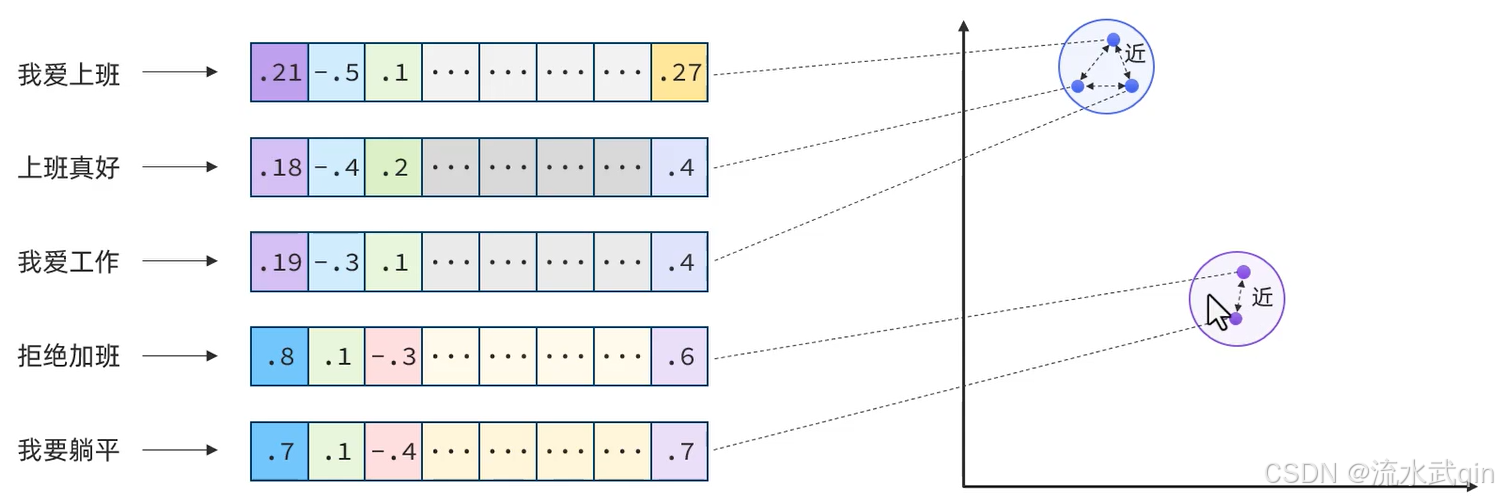
比如我爱上班、上班真好、我爱工作在文本含义上就相似,那么它们在向量空间上应该更接近。
而拒绝加班、我要躺平在文本含义上就相似,那么它们在向量空间上应该更接近。
现在我准备一个向量模型,用于将文本向量化。
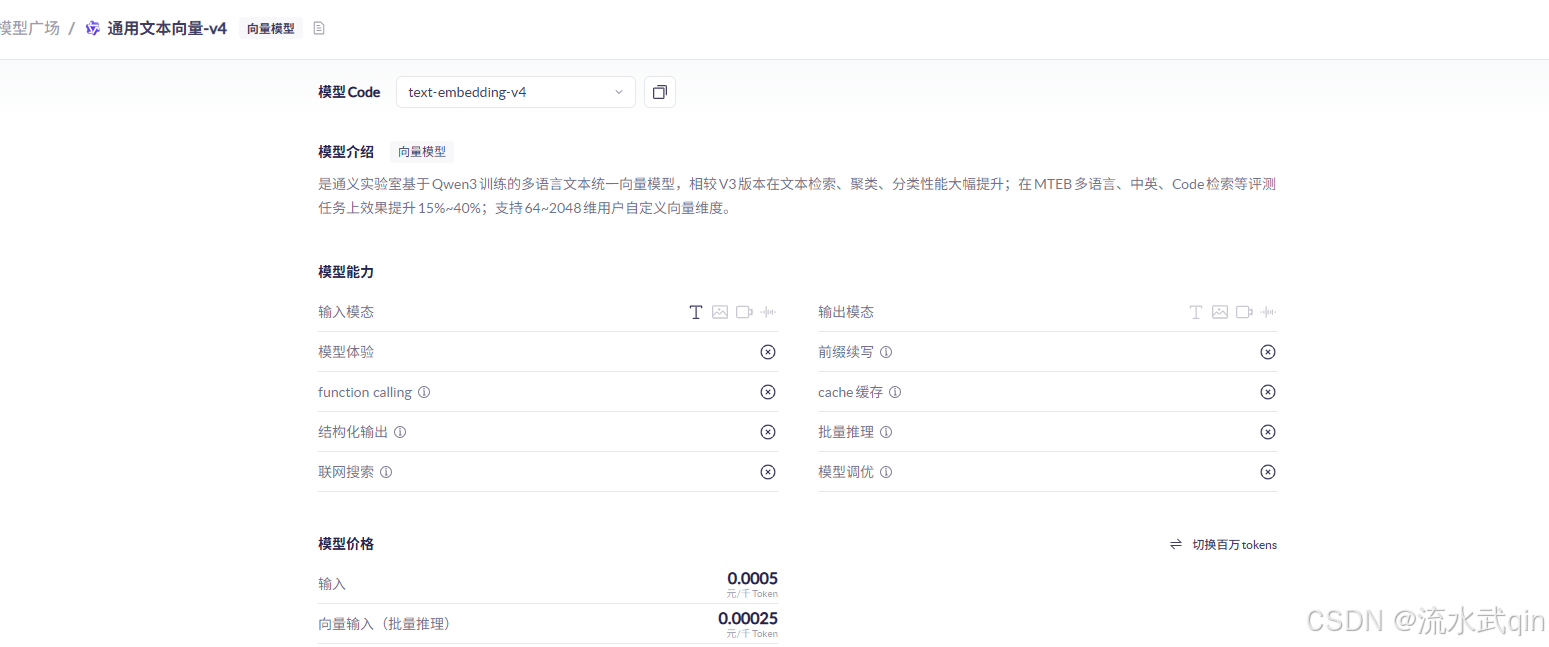
阿里云百炼平台就提供了一些这样的模型:
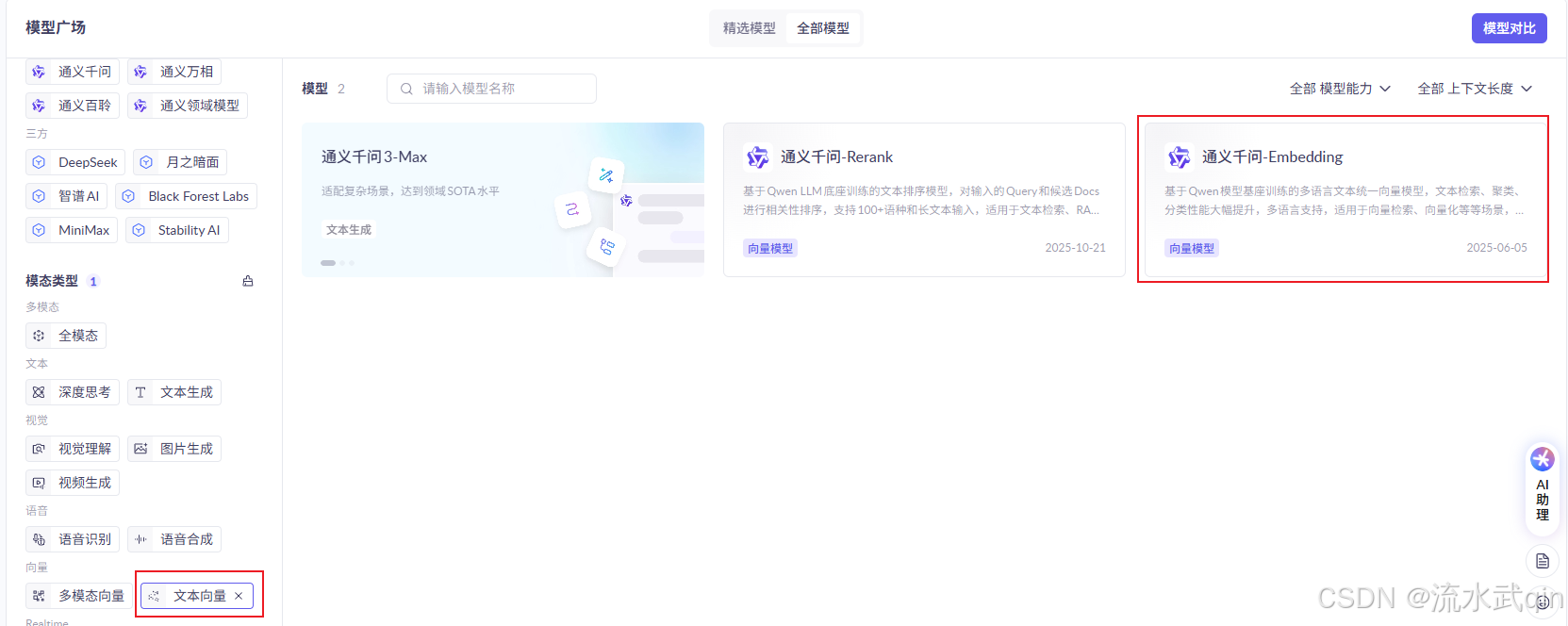
比如这里的通义千问-Embedding。Embedding就是向量的意思。
1.2 向量模型使用测试
- 在application.yml中添加配置
yaml
spring:
application:
name: demo-ai
ai:
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key:
chat:
options:
model: qwen-max # 模型名称
temperature: 0.8 # 模型温度,值越大,输出结果越随机
embedding:
options:
model: text-embedding-v4
dimensions: 1024主要配置的就是这一部分:
yaml
embedding:
options:
model: text-embedding-v4
dimensions: 1024这里的模型我选择的是最新的文本向量模型text-embedding-v4:
- pom文件配置
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
<version>1.0.1</version>
</dependency>- 基础单元测试
java
@SpringBootTest
class DemoAi2ApplicationTests {
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Test
void contextLoads() {
System.out.println(Arrays.toString(embeddingModel.embed("你好")));
}
}输出如下,会把文本拆分为1024个空间向量。

- 欧式距离和余弦距离的比较
java
public class VectorDistanceUtils {
// 防止实例化
private VectorDistanceUtils() {}
// 浮点数计算精度阈值
private static final double EPSILON = 1e-12;
/**
* 计算欧氏距离
* @param vectorA 向量A(非空且与B等长)
* @param vectorB 向量B(非空且与A等长)
* @return 欧氏距离
* @throws IllegalArgumentException 参数不合法时抛出
*/
public static double euclideanDistance(float[] vectorA, float[] vectorB) {
validateVectors(vectorA, vectorB);
double sum = 0.0;
for (int i = 0; i < vectorA.length; i++) {
double diff = vectorA[i] - vectorB[i];
sum += diff * diff;
}
return Math.sqrt(sum);
}
/**
* 计算余弦距离
* @param vectorA 向量A(非空且与B等长)
* @param vectorB 向量B(非空且与A等长)
* @return 余弦距离,范围[0, 2]
* @throws IllegalArgumentException 参数不合法或零向量时抛出
*/
public static double cosineDistance(float[] vectorA, float[] vectorB) {
validateVectors(vectorA, vectorB);
double dotProduct = 0.0;
double normA = 0.0;
double normB = 0.0;
for (int i = 0; i < vectorA.length; i++) {
dotProduct += vectorA[i] * vectorB[i];
normA += vectorA[i] * vectorA[i];
normB += vectorB[i] * vectorB[i];
}
normA = Math.sqrt(normA);
normB = Math.sqrt(normB);
// 处理零向量情况
if (normA < EPSILON || normB < EPSILON) {
throw new IllegalArgumentException("Vectors cannot be zero vectors");
}
// 处理浮点误差,确保结果在[-1,1]范围内
double similarity = dotProduct / (normA * normB);
similarity = Math.max(Math.min(similarity, 1.0), -1.0);
return similarity;
}
// 参数校验统一方法
private static void validateVectors(float[] a, float[] b) {
if (a == null || b == null) {
throw new IllegalArgumentException("Vectors cannot be null");
}
if (a.length != b.length) {
throw new IllegalArgumentException("Vectors must have same dimension");
}
if (a.length == 0) {
throw new IllegalArgumentException("Vectors cannot be empty");
}
}
}
java
@SpringBootTest
class AiDemoApplicationTests {
// 自动注入向量模型
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Test
public void testEmbedding() {
// 1.测试数据
// 1.1.用来查询的文本,国际冲突
String query = "global conflicts";
// 1.2.用来做比较的文本
String[] texts = new String[]{
"哈马斯称加沙下阶段停火谈判仍在进行 以方尚未做出承诺",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典"入约"问题进行谈判",
"日本航空基地水井中检测出有机氟化物超标",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
};
// 2.向量化
// 2.1.先将查询文本向量化
float[] queryVector = embeddingModel.embed(query);
// 2.2.再将比较文本向量化,放到一个数组
List<float[]> textVectors = embeddingModel.embed(Arrays.asList(texts));
// 3.比较欧氏距离
// 3.1.把查询文本自己与自己比较,肯定是相似度最高的
System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, queryVector));
// 3.2.把查询文本与其它文本比较
for (float[] textVector : textVectors) {
System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, textVector));
}
System.out.println("------------------");
// 4.比较余弦距离
// 4.1.把查询文本自己与自己比较,肯定是相似度最高的
System.out.println(VectorDistanceUtils.cosineDistance(queryVector, queryVector));
// 4.2.把查询文本与其它文本比较
for (float[] textVector : textVectors) {
System.out.println(VectorDistanceUtils.cosineDistance(queryVector, textVector));
}
}
}输出如下:

可以看到,和global conflicts向量距离越接近的内容,向量距离是越近的。
二、向量数据库
向量数据库的主要作用有两个:
- 存储向量数据
- 基于相似度检索数据
刚好符合我们的需求。
SpringAI支持很多向量数据库,并且都进行了封装,可以用统一的API去访问:
- Azure Vector Search - The Azure vector store.
- Apache Cassandra - The Apache Cassandra vector store.
- Chroma Vector Store - The Chroma vector store.
- Elasticsearch Vector Store - The Elasticsearch vector store.
- GemFire Vector Store - The GemFire vector store.
- MariaDB Vector Store - The MariaDB vector store.
- Milvus Vector Store - The Milvus vector store.
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store.
- Neo4j Vector Store - The Neo4j vector store.
- OpenSearch Vector Store - The OpenSearch vector store.
- Oracle Vector Store - The Oracle Database vector store.
- PgVector Store - The PostgreSQL/PGVector vector store.
- Pinecone Vector Store - PineCone vector store.
- Qdrant Vector Store - Qdrant vector store.
- Redis Vector Store - The Redis vector store.
- SAP Hana Vector Store - The SAP HANA vector store.
- Typesense Vector Store - The Typesense vector store.
- Weaviate Vector Store - The Weaviate vector store.
- SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes.
这些库都实现了统一的接口:VectorStore,因此操作方式一模一样,大家学会任意一个,其它就都不是问题。
不过,除了最后一个库以外,其它所有向量数据库都是需要安装部署的。每个企业用的向量库都不一样。
2.1 SimpleVectorStore
最后一个SimpleVectorStore向量库是基于内存实现,是一个专门用来测试、教学用的库,非常适合用来了解原理。
使用的话可以直接修改CommonConfiguration,添加一个VectorStore的Bean:
java
@Bean
public VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}2.2 VectorStore接口
这样一来就可以使用VectorStore中的各种功能了,可以参考SpringAI官方文档:
https://docs.spring.io/spring-ai/reference/api/vectordbs.html
这是VectorStore中声明的方法:
java
public interface VectorStore extends DocumentWriter {
default String getName() {
return this.getClass().getSimpleName();
}
// 保存文档到向量库
void add(List<Document> documents);
// 根据文档id删除文档
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { ... };
// 根据条件检索文档
List<Document> similaritySearch(String query);
// 根据条件检索文档
List<Document> similaritySearch(SearchRequest request);
default <T> Optional<T> getNativeClient() {
return Optional.empty();
}
}2.3 基于SpringAI 1.0,3 配置VectorStore
首先,需要安装一个Redis Stack,这是Redis官方提供的拓展版本,其中有向量库的功能。
可以使用Docker安装:
docker run -d --name redis-stack-server -p 6389:6379 -p 8001:8001 redis/redis-stack:latest安装完成后,你可以通过命令行访问:
Bash
docker exec -it redis-stack redis-cli也可以通过浏览器访问控制台:http://localhost:8001
然后,你可以在项目中引入RedisVectorStore的依赖:
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-store</artifactId>
</dependency>
<!-- 添加Jedis依赖用于RedisVectorStore -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.2.0</version>
</dependency>在application.yml配置Redis:
yaml
spring:
ai:
vectorstore:
redis:
index: spring_ai_index # 向量库索引名
initialize-schema: true # 是否初始化向量库索引结构
prefix: "doc:" # 向量库key前缀
data:
redis:
redis:
host: localhost
# password: ${REDIS_PWD}
port: 6389接下来,声明bean就可以使用VectorStore了:
java
@Bean
public JedisPooled jedisPooled() {
return new JedisPooled("127.0.0.1", 6389);
}
@Bean
public VectorStore vectorStore(JedisPooled jedisPooled, EmbeddingModel embeddingModel) {
return RedisVectorStore.builder(jedisPooled, embeddingModel)
.indexName("custom-index") // Optional: defaults to "spring-ai-index"
.prefix("custom-prefix") // Optional: defaults to "embedding:"
.metadataFields( // Optional: define metadata fields for filtering
RedisVectorStore.MetadataField.tag("country"),
RedisVectorStore.MetadataField.numeric("year"))
.initializeSchema(true) // Optional: defaults to false
.batchingStrategy(new TokenCountBatchingStrategy()) // Optional: defaults to TokenCountBatchingStrategy
.build();
}2.4 测试VectorStore
java
@SpringBootTest
class AiDemoApplicationTests {
// 自动注入向量模型
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Autowired
private VectorStore vectorStore;
@Test
public void testVectorStore() {
// 1.创建pdf读取器
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/笔记.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1) // 每一页PDF作为一个Document
.build());
// 2.读取PDF文件,拆分为document
List<Document> documents = pdfReader.read();
// 3.写入向量库
vectorStore.add(documents);
// 4.查询向量库
SearchRequest request = SearchRequest.builder()
.query("论语中教育的目的是什么")
.topK(1) // 只要最接近的一条
.similarityThreshold(0.6) // 超过0.6分的才
.filterExpression("file_name == '笔记.pdf'")
.build();
List<Document> docs = vectorStore.similaritySearch("request");
if (docs.isEmpty()) {
System.out.printf("查询'%s'没有结果", "论语中教育的目的是什么");
return;
}
for (Document doc : docs) {
System.out.println(doc.getId());
System.out.println(doc.getScore());
System.out.println(doc.getText());
}
}
}这里的filterExpression("file_name == '笔记.pdf'")指定检索的文件是哪个,防止不同文件内容互相影响。
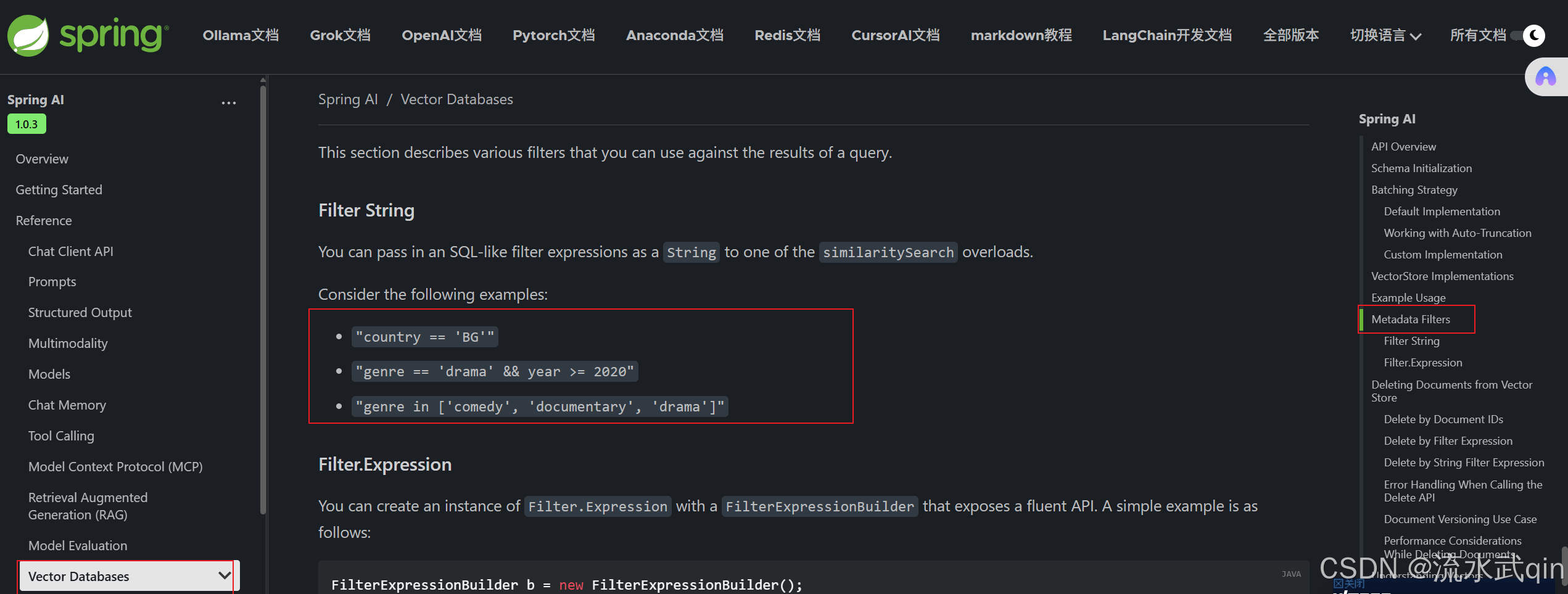
关于过滤表达式filterExpression官方文档中有详细的使用说明: