注:本文为 " PINN " 相关合辑。
图片清晰度受引文原图所限。
略作重排,如有内容异常,请看原文。
PINN 解偏微分方程实例 1
喝过期的拉菲 于 2024-12-08 17:12:17 修改
本文介绍了 PINN(物理信息神经网络,Physics-Informed Neural Networks)求解偏微分方程的方法,通过二阶偏微分方程的具体实例,展示 PINN 的计算流程与损失函数构造方式。基于 PyTorch 框架实现了简易的 PINN 模型,涵盖内点与边界条件的处理、模型训练过程及结果评估等核心环节。
更新 2 :
近期基于下述代码框架完成了三类偏微分方程的求解,包括 Diffusion 方程、Burgers 方程与 Allen--Cahn 方程,并对求解结果进行了可视化展示(含多组可视化结果图);同时以 Burgers 方程为例,展示了偏微分方程反问题求解结果的可视化内容,具体可参见 PINN 解偏微分方程实例 5。
更新 1 :
近期基于下述代码框架完成了四类偏微分方程的求解,包括 Diffusion 方程、Burgers 方程、Allen--Cahn 方程与 Wave 方程;此外,重新编写了一套偏微分方程反问题求解的代码框架,并以 Burgers 方程为例进行验证,具体可参见 PINN 解偏微分方程实例 4。
1. PINN 简介
PINN 是一类结合物理规律约束的神经网络方法,常用于偏微分方程的数值求解,其计算流程如图 1 所示(以偏微分方程 (1) 为例)。
∂ u ∂ t + u ∂ u ∂ x = v ∂ 2 u ∂ x 2 (1) \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} = v \frac{\partial^2 u}{\partial x^2} \tag{1} ∂t∂u+u∂x∂u=v∂x2∂2u(1)
神经网络接收空间坐标 x , y , z x,y,z x,y,z 与时间 t t t 作为输入,输出偏微分方程解 u u u 在对应时空位置的数值解。
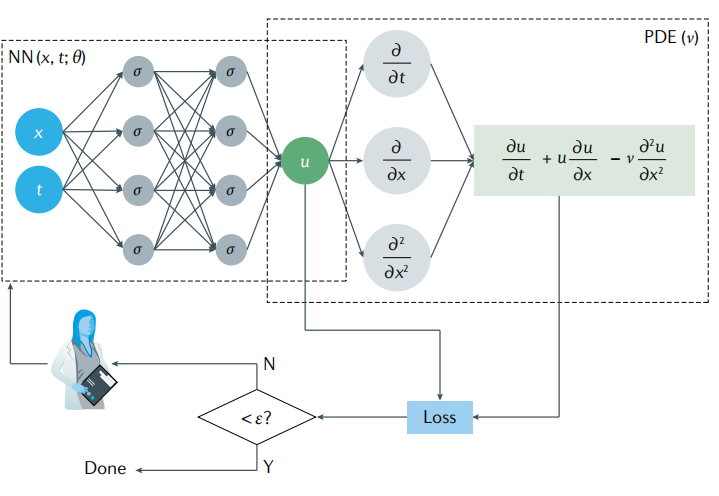
PINN 的损失函数由两部分构成:训练数据误差项与偏微分方程残差误差项,其数学形式如式 (2) 所示:
l = w d a t a l d a t a + w P D E l P D E (2) l = w_{data} l_{data} + w_{PDE} l_{PDE} \tag{2} l=wdataldata+wPDElPDE(2)
其中:
l d a t a = 1 N d a t a ∑ i = 1 N d a t a ( u ( x i , t i ) − u i ) 2 l P D E = 1 N P D E ∑ j = 1 N P D E ( ∂ u ∂ t + u ∂ u ∂ x − v ∂ 2 u ∂ x 2 ) 2 ∣ ( x j , t j ) \begin{array}{rl} l_{data} & = \frac{1}{N_{data}} \sum_{i=1}^{N_{data}} \left( u(x_i, t_i) - u_i \right)^2 \\6pt l_{PDE} & = \frac{1}{N_{PDE}} \sum_{j=1}^{N_{PDE}} \left. \left( \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} - v \frac{\partial^2 u}{\partial x^2} \right)^2 \right|_{(x_j, t_j)} \end{array} ldatalPDE=Ndata1∑i=1Ndata(u(xi,ti)−ui)2=NPDE1∑j=1NPDE(∂t∂u+u∂x∂u−v∂x2∂2u)2 (xj,tj)
2. 偏微分方程实例
考虑如下二阶偏微分方程:
∂ 2 u ∂ x 2 − ∂ 4 u ∂ y 4 = ( 2 − x 2 ) e − y \frac{\partial^2 u}{\partial x^2} - \frac{\partial^4 u}{\partial y^4} = (2 - x^2) e^{-y} ∂x2∂2u−∂y4∂4u=(2−x2)e−y
其边界条件定义为:
{ ∂ 2 u ∂ y 2 ( x , 0 ) = x 2 ∂ 2 u ∂ y 2 ( x , 1 ) = x 2 e u ( x , 0 ) = x 2 u ( x , 1 ) = x 2 e u ( 0 , y ) = 0 u ( 1 , y ) = e − y \begin{cases} \frac{\partial^2 u}{\partial y^2}(x, 0) = x^2 \\6pt \frac{\partial^2 u}{\partial y^2}(x, 1) = x^2 e \\6pt u(x, 0) = x^2 \\6pt u(x, 1) = x^2 e \\6pt u(0, y) = 0 \\6pt u(1, y) = e^{-y} \end{cases} ⎩ ⎨ ⎧∂y2∂2u(x,0)=x2∂y2∂2u(x,1)=x2eu(x,0)=x2u(x,1)=x2eu(0,y)=0u(1,y)=e−y
该偏微分方程的解析解为 u ( x , y ) = x 2 e − y u(x, y) = x^2 e^{-y} u(x,y)=x2e−y。在区域 0 , 1 × 0 , 1 0,1 \times 0,1 0,1×0,1 内随机采样配置点与数据点:配置点用于构造偏微分方程损失项 l 1 , l 2 , ... , l 7 l_1, l_2, \dots, l_7 l1,l2,...,l7,数据点用于构造数据损失项 l 8 l_8 l8,各损失项的数学形式如下:
l 1 = 1 N 1 ∑ ( x i , y i ) ∈ Ω ( u ^ x x ( x i , y i ; θ ) − u ^ y y y y ( x i , y i ; θ ) − ( 2 − x i 2 ) e − y i ) 2 l 2 = 1 N 2 ∑ ( x i , y i ) ∈ 0 , 1 × { 0 } ( u ^ y y ( x i , y i ; θ ) − x i 2 ) 2 l 3 = 1 N 3 ∑ ( x i , y i ) ∈ 0 , 1 × { 1 } ( u ^ y y ( x i , y i ; θ ) − x i 2 e ) 2 l 4 = 1 N 4 ∑ ( x i , y i ) ∈ 0 , 1 × { 0 } ( u ^ ( x i , y i ; θ ) − x i 2 ) 2 l 5 = 1 N 5 ∑ ( x i , y i ) ∈ 0 , 1 × { 1 } ( u ^ ( x i , y i ; θ ) − x i 2 e ) 2 l 6 = 1 N 6 ∑ ( x i , y i ) ∈ { 0 } × 0 , 1 ( u ^ ( x i , y i ; θ ) − 0 ) 2 l 7 = 1 N 7 ∑ ( x i , y i ) ∈ { 1 } × 0 , 1 ( u ^ ( x i , y i ; θ ) − e − y i ) 2 l 8 = 1 N 8 ∑ i = 1 N 8 ( u ^ ( x i , y i ; θ ) − u i ) 2 \begin{align*} l_1 &= \frac{1}{N_1} \sum_{(x_i, y_i) \in \Omega} \left( \hat{u}{xx}(x_i, y_i; \theta) - \hat{u}{yyyy}(x_i, y_i; \theta) - (2 - x_i^2) e^{-y_i} \right)^2 \\6pt l_2 &= \frac{1}{N_2} \sum_{(x_i, y_i) \in 0,1 \times \{0\}} \left( \hat{u}{yy}(x_i, y_i; \theta) - x_i^2 \right)^2 \\6pt l_3 &= \frac{1}{N_3} \sum{(x_i, y_i) \in 0,1 \times \{1\}} \left( \hat{u}{yy}(x_i, y_i; \theta) - x_i^2 e \right)^2 \\6pt l_4 &= \frac{1}{N_4} \sum{(x_i, y_i) \in 0,1 \times \{0\}} \left( \hat{u}(x_i, y_i; \theta) - x_i^2 \right)^2 \\6pt l_5 &= \frac{1}{N_5} \sum_{(x_i, y_i) \in 0,1 \times \{1\}} \left( \hat{u}(x_i, y_i; \theta) - x_i^2 e \right)^2 \\6pt l_6 &= \frac{1}{N_6} \sum_{(x_i, y_i) \in \{0\} \times 0,1} \left( \hat{u}(x_i, y_i; \theta) - 0 \right)^2 \\6pt l_7 &= \frac{1}{N_7} \sum_{(x_i, y_i) \in \{1\} \times 0,1} \left( \hat{u}(x_i, y_i; \theta) - e^{-y_i} \right)^2 \\6pt l_8 &= \frac{1}{N_8} \sum_{i=1}^{N_8} \left( \hat{u}(x_i, y_i; \theta) - u_i \right)^2 \end{align*} l1l2l3l4l5l6l7l8=N11(xi,yi)∈Ω∑(u^xx(xi,yi;θ)−u^yyyy(xi,yi;θ)−(2−xi2)e−yi)2=N21(xi,yi)∈0,1×{0}∑(u^yy(xi,yi;θ)−xi2)2=N31(xi,yi)∈0,1×{1}∑(u^yy(xi,yi;θ)−xi2e)2=N41(xi,yi)∈0,1×{0}∑(u^(xi,yi;θ)−xi2)2=N51(xi,yi)∈0,1×{1}∑(u^(xi,yi;θ)−xi2e)2=N61(xi,yi)∈{0}×0,1∑(u^(xi,yi;θ)−0)2=N71(xi,yi)∈{1}×0,1∑(u^(xi,yi;θ)−e−yi)2=N81i=1∑N8(u^(xi,yi;θ)−ui)2
3. 基于 PyTorch 的实现代码
python
"""
基于 PINN 求解如下二阶偏微分方程的数值解:
u_xx - u_yyyy = (2 - x^2) * exp(-y)
作者:ST
日期:2023/2/26
"""
import torch
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 超参数设置
epochs = 10000 # 训练轮数
h = 100 # 可视化网格密度
N = 1000 # 内点配置点数量
N1 = 100 # 边界点配置点数量
N2 = 1000 # PDE 数据点数量
def setup_seed(seed):
"""设置随机数种子以保证结果可复现"""
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
# 初始化随机数种子
setup_seed(888888)
# 区域采样函数
def interior(n=N):
"""采样偏微分方程内点,返回 (x, y, 右侧目标值)"""
x = torch.rand(n, 1)
y = torch.rand(n, 1)
cond = (2 - x ** 2) * torch.exp(-y)
return x.requires_grad_(True), y.requires_grad_(True), cond
def down_yy(n=N1):
"""采样边界 y=0 处的点,对应 u_yy(x,0)=x^2"""
x = torch.rand(n, 1)
y = torch.zeros_like(x)
cond = x ** 2
return x.requires_grad_(True), y.requires_grad_(True), cond
def up_yy(n=N1):
"""采样边界 y=1 处的点,对应 u_yy(x,1)=x^2/e"""
x = torch.rand(n, 1)
y = torch.ones_like(x)
cond = x ** 2 / torch.e
return x.requires_grad_(True), y.requires_grad_(True), cond
def down(n=N1):
"""采样边界 y=0 处的点,对应 u(x,0)=x^2"""
x = torch.rand(n, 1)
y = torch.zeros_like(x)
cond = x ** 2
return x.requires_grad_(True), y.requires_grad_(True), cond
def up(n=N1):
"""采样边界 y=1 处的点,对应 u(x,1)=x^2/e"""
x = torch.rand(n, 1)
y = torch.ones_like(x)
cond = x ** 2 / torch.e
return x.requires_grad_(True), y.requires_grad_(True), cond
def left(n=N1):
"""采样边界 x=0 处的点,对应 u(0,y)=0"""
y = torch.rand(n, 1)
x = torch.zeros_like(y)
cond = torch.zeros_like(x)
return x.requires_grad_(True), y.requires_grad_(True), cond
def right(n=N1):
"""采样边界 x=1 处的点,对应 u(1,y)=e^(-y)"""
y = torch.rand(n, 1)
x = torch.ones_like(y)
cond = torch.exp(-y)
return x.requires_grad_(True), y.requires_grad_(True), cond
def data_interior(n=N2):
"""采样内点数据点,对应解析解 u(x,y)=x^2*exp(-y)"""
x = torch.rand(n, 1)
y = torch.rand(n, 1)
cond = (x ** 2) * torch.exp(-y)
return x.requires_grad_(True), y.requires_grad_(True), cond
# 神经网络模型定义
class MLP(torch.nn.Module):
"""多层感知机模型,用于拟合偏微分方程的解"""
def __init__(self):
super(MLP, self).__init__()
self.net = torch.nn.Sequential(
torch.nn.Linear(2, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 1)
)
def forward(self, x):
"""前向传播,输入为 (x,y) 拼接的张量,输出为 u 的预测值"""
return self.net(x)
# 损失函数与梯度计算
loss_fn = torch.nn.MSELoss()
def gradients(u, x, order=1):
"""计算张量 u 对 x 的 order 阶导数"""
if order == 1:
return torch.autograd.grad(u, x, grad_outputs=torch.ones_like(u),
create_graph=True,
only_inputs=True)[0]
else:
return gradients(gradients(u, x), x, order=order - 1)
# 偏微分方程损失项定义
def l_interior(u):
"""PDE 内点损失项 l1"""
x, y, cond = interior()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(gradients(uxy, x, 2) - gradients(uxy, y, 4), cond)
def l_down_yy(u):
"""边界损失项 l2 (u_yy(x,0)=x^2)"""
x, y, cond = down_yy()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(gradients(uxy, y, 2), cond)
def l_up_yy(u):
"""边界损失项 l3 (u_yy(x,1)=x^2/e)"""
x, y, cond = up_yy()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(gradients(uxy, y, 2), cond)
def l_down(u):
"""边界损失项 l4 (u(x,0)=x^2)"""
x, y, cond = down()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(uxy, cond)
def l_up(u):
"""边界损失项 l5 (u(x,1)=x^2/e)"""
x, y, cond = up()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(uxy, cond)
def l_left(u):
"""边界损失项 l6 (u(0,y)=0)"""
x, y, cond = left()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(uxy, cond)
def l_right(u):
"""边界损失项 l7 (u(1,y)=e^(-y))"""
x, y, cond = right()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(uxy, cond)
# 数据损失项定义
def l_data(u):
"""数据损失项 l8"""
x, y, cond = data_interior()
uxy = u(torch.cat([x, y], dim=1))
return loss_fn(uxy, cond)
# 模型训练
u_model = MLP()
optimizer = torch.optim.Adam(params=u_model.parameters())
for i in range(epochs):
optimizer.zero_grad()
# 总损失 = 所有 PDE 损失项 + 数据损失项
total_loss = l_interior(u_model) + l_up_yy(u_model) + l_down_yy(u_model) + \
l_up(u_model) + l_down(u_model) + l_left(u_model) + \
l_right(u_model) + l_data(u_model)
total_loss.backward()
optimizer.step()
# 每 100 轮打印一次训练进度
if i % 100 == 0:
print(f"训练轮数: {i}, 总损失: {total_loss.item():.6f}")
# 结果推理与可视化
xc = torch.linspace(0, 1, h)
xm, ym = torch.meshgrid(xc, xc, indexing='ij') # 显式指定索引方式以保证兼容性
xx = xm.reshape(-1, 1)
yy = ym.reshape(-1, 1)
xy = torch.cat([xx, yy], dim=1)
# 预测值与解析解计算
u_pred = u_model(xy)
u_real = xx * xx * torch.exp(-yy)
u_error = torch.abs(u_pred - u_real)
# 维度重塑以适配可视化
u_pred_fig = u_pred.reshape(h, h)
u_real_fig = u_real.reshape(h, h)
u_error_fig = u_error.reshape(h, h)
# 打印最大绝对误差
max_abs_error = float(torch.max(u_error))
print(f"最大绝对误差: {max_abs_error:.8f}")
# 仅使用 PDE 损失时,最大绝对误差约为 0.00485295
# 加入数据损失后,最大绝对误差约为 0.00189161
# 绘制 PINN 数值解
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(xm.detach().numpy(), ym.detach().numpy(), u_pred_fig.detach().numpy(), cmap='viridis')
ax.set_title("PINN 数值解")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("u")
plt.savefig("PINN_solve.png", dpi=300, bbox_inches='tight')
plt.show()
# 绘制解析解
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(xm.detach().numpy(), ym.detach().numpy(), u_real_fig.detach().numpy(), cmap='viridis')
ax.set_title("解析解")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("u")
plt.savefig("real_solve.png", dpi=300, bbox_inches='tight')
plt.show()
# 绘制绝对误差图
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(xm.detach().numpy(), ym.detach().numpy(), u_error_fig.detach().numpy(), cmap='Reds')
ax.set_title("绝对误差分布")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("|u_pred - u_real|")
plt.savefig("abs_error.png", dpi=300, bbox_inches='tight')
plt.show()4. 数值解结果
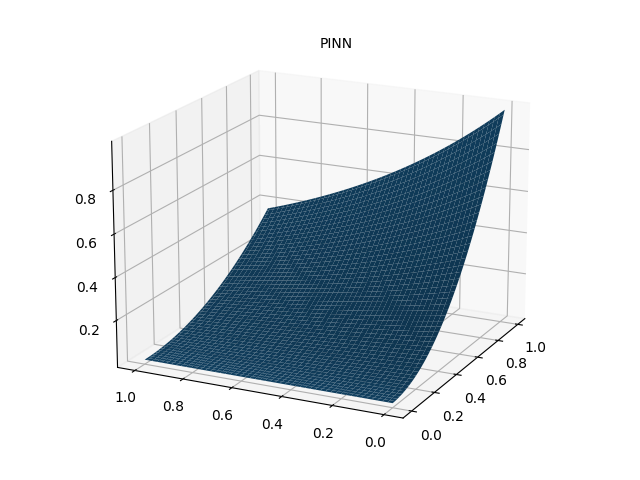
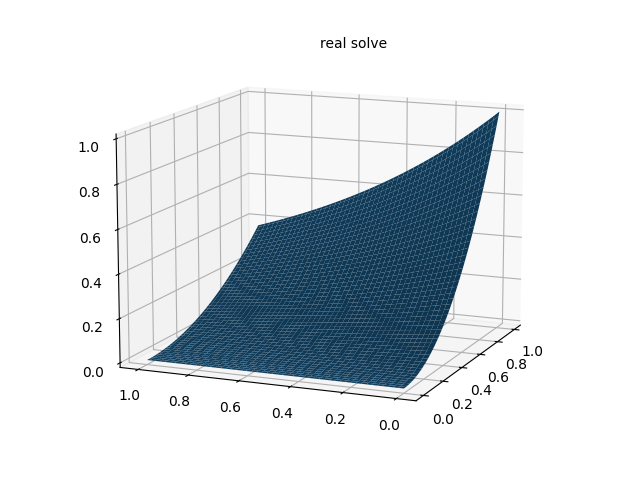
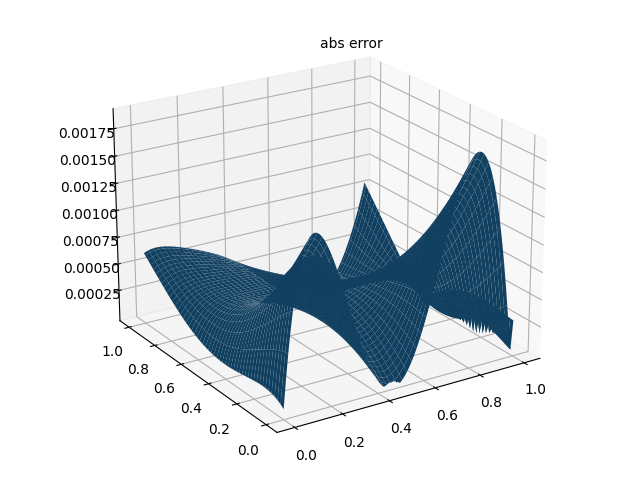
PINN 解偏微分方程实例 2(一维非线性薛定谔方程)
喝过期的拉菲 于 2023-12-09 22:06:03 修改
框架说明
TensorFlow-v2.9 是由 Google Brain 团队开发的开源机器学习框架,广泛应用于深度学习的研究与工程实践。该框架提供了灵活的计算图构建与自动微分机制,可支持各类机器学习模型的构建、训练与部署。
1. 一维非线性薛定谔方程
考虑如下一维非线性薛定谔方程:
i ∂ h ∂ t + 0.5 ∂ 2 h ∂ x 2 + ∣ h ∣ 2 h = 0 i \frac{\partial h}{\partial t} + 0.5 \frac{\partial^2 h}{\partial x^2} + |h|^2 h = 0 i∂t∂h+0.5∂x2∂2h+∣h∣2h=0
其初始条件与边界条件为:
{ h ( 0 , x ) = 2 sech ( x ) h ( t , − 5 ) = h ( t , 5 ) ∂ h ∂ x ( t , − 5 ) = ∂ h ∂ x ( t , 5 ) \begin{cases} h(0, x) = 2 \operatorname{sech}(x) \\6pt h(t, -5) = h(t, 5) \\6pt \frac{\partial h}{\partial x}(t, -5) = \frac{\partial h}{\partial x}(t, 5) \end{cases} ⎩ ⎨ ⎧h(0,x)=2sech(x)h(t,−5)=h(t,5)∂x∂h(t,−5)=∂x∂h(t,5)
其中,求解区域为 x ∈ − 5 , 5 x \in -5, 5 x∈−5,5, t ∈ 0 , π / 2 t \in 0, \\pi/2 t∈0,π/2。该方程为含周期性边界条件、初始条件且解为复数形式的偏微分方程。
2. 损失函数定义
PINN 的总损失函数定义为各分项损失的加权和:
MSE = MSE 0 + MSE b + MSE f \text{MSE} = \text{MSE}_0 + \text{MSE}_b + \text{MSE}_f MSE=MSE0+MSEb+MSEf
各分项损失的数学形式如下:
MSE 0 = 1 N 0 ∑ i = 1 N 0 ∣ h ( 0 , x 0 i ) − h 0 i ∣ 2 MSE b = 1 N b ∑ i = 1 N b ( ∣ h ( t b i , − 5 ) − h ( t b i , 5 ) ∣ 2 + ∣ ∂ h ∂ x ( t b i , − 5 ) − ∂ h ∂ x ( t b i , 5 ) ∣ 2 ) MSE f = 1 N f ∑ i = 1 N f ∣ f ( t f i , x f i ) ∣ 2 \begin{align*} \text{MSE}0 & = \frac{1}{N_0} \sum{i=1}^{N_0} \left| h(0, x_0^i) - h_0^i \right|^2 \\6pt \text{MSE}b & = \frac{1}{N_b} \sum{i=1}^{N_b} \left( \left| h(t_b^i, -5) - h(t_b^i, 5) \right|^2 + \left| \frac{\partial h}{\partial x}(t_b^i, -5) - \frac{\partial h}{\partial x}(t_b^i, 5) \right|^2 \right) \\6pt \text{MSE}f & = \frac{1}{N_f} \sum{i=1}^{N_f} \left| f(t_f^i, x_f^i) \right|^2 \end{align*} MSE0MSEbMSEf=N01i=1∑N0 h(0,x0i)−h0i 2=Nb1i=1∑Nb( h(tbi,−5)−h(tbi,5) 2+ ∂x∂h(tbi,−5)−∂x∂h(tbi,5) 2)=Nf1i=1∑Nf f(tfi,xfi) 2
其中:
- MSE 0 \text{MSE}_0 MSE0 为初始条件损失项;
- MSE b \text{MSE}_b MSEb 为周期性边界条件损失项;
- MSE f \text{MSE}_f MSEf 为偏微分方程残差损失项;
- f ( t , x ) = i ∂ h ∂ t + 0.5 ∂ 2 h ∂ x 2 + ∣ h ∣ 2 h f(t, x) = i \frac{\partial h}{\partial t} + 0.5 \frac{\partial^2 h}{\partial x^2} + |h|^2 h f(t,x)=i∂t∂h+0.5∂x2∂2h+∣h∣2h 为方程残差。
由于解 h ( t , x ) h(t, x) h(t,x) 为复数,可分解为实部与虚部: h ( t , x ) = u ( t , x ) + i v ( t , x ) h(t, x) = u(t, x) + iv(t, x) h(t,x)=u(t,x)+iv(t,x)。在代码实现中,损失函数可进一步分解为 8 个分项:
l = l 1 + l 2 + l 3 + l 4 + l 5 + l 6 + l 7 + l 8 l = l_1 + l_2 + l_3 + l_4 + l_5 + l_6 + l_7 + l_8 l=l1+l2+l3+l4+l5+l6+l7+l8
其中:
l 1 = 1 N 0 ∑ i = 1 N 0 ∣ u ( 0 , x 0 i ) − u 0 i ∣ 2 l 2 = 1 N 0 ∑ i = 1 N 0 ∣ v ( 0 , x 0 i ) − v 0 i ∣ 2 l 3 = 1 N b ∑ i = 1 N b ∣ u ( t b i , − 5 ) − u ( t b i , 5 ) ∣ 2 l 4 = 1 N b ∑ i = 1 N b ∣ v ( t b i , − 5 ) − v ( t b i , 5 ) ∣ 2 l 5 = 1 N b ∑ i = 1 N b ∣ ∂ u ∂ x ( t b i , − 5 ) − ∂ u ∂ x ( t b i , 5 ) ∣ 2 l 6 = 1 N b ∑ i = 1 N b ∣ ∂ v ∂ x ( t b i , − 5 ) − ∂ v ∂ x ( t b i , 5 ) ∣ 2 l 7 = 1 N f ∑ i = 1 N f ∣ u t + 0.5 v x x + ( u 2 + v 2 ) v ∣ 2 l 8 = 1 N f ∑ i = 1 N f ∣ − v t + 0.5 u x x + ( u 2 + v 2 ) u ∣ 2 \begin{align*} l_1 &= \frac{1}{N_0} \sum_{i=1}^{N_0} \left| u(0, x_0^i) - u_0^i \right|^2 \\6pt l_2 &= \frac{1}{N_0} \sum_{i=1}^{N_0} \left| v(0, x_0^i) - v_0^i \right|^2 \\6pt l_3 &= \frac{1}{N_b} \sum_{i=1}^{N_b} \left| u(t_b^i, -5) - u(t_b^i, 5) \right|^2 \\6pt l_4 &= \frac{1}{N_b} \sum_{i=1}^{N_b} \left| v(t_b^i, -5) - v(t_b^i, 5) \right|^2 \\6pt l_5 &= \frac{1}{N_b} \sum_{i=1}^{N_b} \left| \frac{\partial u}{\partial x}(t_b^i, -5) - \frac{\partial u}{\partial x}(t_b^i, 5) \right|^2 \\6pt l_6 &= \frac{1}{N_b} \sum_{i=1}^{N_b} \left| \frac{\partial v}{\partial x}(t_b^i, -5) - \frac{\partial v}{\partial x}(t_b^i, 5) \right|^2 \\6pt l_7 &= \frac{1}{N_f} \sum_{i=1}^{N_f} \left| u_t + 0.5 v_{xx} + (u^2 + v^2) v \right|^2 \\6pt l_8 &= \frac{1}{N_f} \sum_{i=1}^{N_f} \left| -v_t + 0.5 u_{xx} + (u^2 + v^2) u \right|^2 \end{align*} l1l2l3l4l5l6l7l8=N01i=1∑N0 u(0,x0i)−u0i 2=N01i=1∑N0 v(0,x0i)−v0i 2=Nb1i=1∑Nb u(tbi,−5)−u(tbi,5) 2=Nb1i=1∑Nb v(tbi,−5)−v(tbi,5) 2=Nb1i=1∑Nb ∂x∂u(tbi,−5)−∂x∂u(tbi,5) 2=Nb1i=1∑Nb ∂x∂v(tbi,−5)−∂x∂v(tbi,5) 2=Nf1i=1∑Nf ut+0.5vxx+(u2+v2)v 2=Nf1i=1∑Nf −vt+0.5uxx+(u2+v2)u 2
参数设置为 N 0 = N b = 50 N_0 = N_b = 50 N0=Nb=50, N f = 20000 N_f = 20000 Nf=20000; u 0 i , v 0 i u_0^i, v_0^i u0i,v0i 为通过谱方法计算的解析解,其余项为神经网络的预测值。
3. 实现代码
python
"""
基于 PINN 求解一维非线性薛定谔方程
原作者:Maziar Raissi
注释:ST
说明:通过谱方法计算 [0, pi/2] × [-5, 5] 区域的解析解,解析解维度为 201 × 256
"""
import sys
sys.path.insert(0, '../../Utilities/')
import tensorflow.compat.v1 as tf # 兼容 TensorFlow 1.x 代码
tf.disable_v2_behavior()
import numpy as np
import matplotlib.pyplot as plt
import scipy.io
from scipy.interpolate import griddata
from pyDOE import lhs # 拉丁超立方采样
from plotting import newfig, savefig
from mpl_toolkits.mplot3d import Axes3D
import time
import matplotlib.gridspec as gridspec
from mpl_toolkits.axes_grid1 import make_axes_locatable
# 设置随机数种子
np.random.seed(1234)
tf.set_random_seed(1234)
class PhysicsInformedNN:
"""物理信息神经网络类,用于求解非线性薛定谔方程"""
def __init__(self, x0, u0, v0, tb, X_f, layers, lb, ub):
"""
初始化函数
参数说明:
x0: 初始时刻采样点的 x 坐标 (N0, 1)
u0: 初始时刻采样点解的实部 (N0, 1)
v0: 初始时刻采样点解的虚部 (N0, 1)
tb: 边界时刻采样点的 t 坐标 (Nb, 1)
X_f: 拉丁超立方采样的内点坐标 (Nf, 2)
layers: 神经网络层结构,如 [2, 100, 100, 100, 100, 2]
lb: 求解区域下界 [x_min, t_min]
ub: 求解区域上界 [x_max, t_max]
"""
# 构造采样点坐标
X0 = np.concatenate((x0, 0 * x0), 1) # 初始时刻点 (x, 0)
X_lb = np.concatenate((0 * tb + lb[0], tb), 1) # 左边界点 (-5, t)
X_ub = np.concatenate((0 * tb + ub[0], tb), 1) # 右边界点 (5, t)
self.lb = lb
self.ub = ub
self.x0 = X0[:, 0:1]
self.t0 = X0[:, 1:2]
self.x_lb = X_lb[:, 0:1]
self.t_lb = X_lb[:, 1:2]
self.x_ub = X_ub[:, 0:1]
self.t_ub = X_ub[:, 1:2]
self.x_f = X_f[:, 0:1]
self.t_f = X_f[:, 1:2]
self.u0 = u0
self.v0 = v0
# 初始化神经网络权重与偏置
self.layers = layers
self.weights, self.biases = self.initialize_NN(layers)
# 定义 TensorFlow 占位符
self.x0_tf = tf.placeholder(tf.float32, shape=[None, self.x0.shape[1]])
self.t0_tf = tf.placeholder(tf.float32, shape=[None, self.t0.shape[1]])
self.u0_tf = tf.placeholder(tf.float32, shape=[None, self.u0.shape[1]])
self.v0_tf = tf.placeholder(tf.float32, shape=[None, self.v0.shape[1]])
self.x_lb_tf = tf.placeholder(tf.float32, shape=[None, self.x_lb.shape[1]])
self.t_lb_tf = tf.placeholder(tf.float32, shape=[None, self.t_lb.shape[1]])
self.x_ub_tf = tf.placeholder(tf.float32, shape=[None, self.x_ub.shape[1]])
self.t_ub_tf = tf.placeholder(tf.float32, shape=[None, self.t_ub.shape[1]])
self.x_f_tf = tf.placeholder(tf.float32, shape=[None, self.x_f.shape[1]])
self.t_f_tf = tf.placeholder(tf.float32, shape=[None, self.t_f.shape[1]])
# 构建计算图
self.u0_pred, self.v0_pred, _, _ = self.net_uv(self.x0_tf, self.t0_tf) # 初始条件预测
self.u_lb_pred, self.v_lb_pred, self.u_x_lb_pred, self.v_x_lb_pred = self.net_uv(self.x_lb_tf, self.t_lb_tf) # 左边界预测
self.u_ub_pred, self.v_ub_pred, self.u_x_ub_pred, self.v_x_ub_pred = self.net_uv(self.x_ub_tf, self.t_ub_tf) # 右边界预测
self.f_u_pred, self.f_v_pred = self.net_f_uv(self.x_f_tf, self.t_f_tf) # PDE 残差预测
# 定义损失函数
self.loss = tf.reduce_mean(tf.square(self.u0_tf - self.u0_pred)) + \
tf.reduce_mean(tf.square(self.v0_tf - self.v0_pred)) + \
tf.reduce_mean(tf.square(self.u_lb_pred - self.u_ub_pred)) + \
tf.reduce_mean(tf.square(self.v_lb_pred - self.v_ub_pred)) + \
tf.reduce_mean(tf.square(self.u_x_lb_pred - self.u_x_ub_pred)) + \
tf.reduce_mean(tf.square(self.v_x_lb_pred - self.v_x_ub_pred)) + \
tf.reduce_mean(tf.square(self.f_u_pred)) + \
tf.reduce_mean(tf.square(self.f_v_pred))
# 定义优化器
self.optimizer_Adam = tf.train.AdamOptimizer()
self.train_op_Adam = self.optimizer_Adam.minimize(self.loss)
# 初始化会话
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
log_device_placement=True))
init = tf.global_variables_initializer()
self.sess.run(init)
def initialize_NN(self, layers):
"""初始化神经网络权重与偏置(Xavier 初始化)"""
weights = []
biases = []
num_layers = len(layers)
for l in range(num_layers - 1):
W = self.xavier_init(size=[layers[l], layers[l+1]])
b = tf.Variable(tf.zeros([1, layers[l+1]], dtype=tf.float32), dtype=tf.float32)
weights.append(W)
biases.append(b)
return weights, biases
def xavier_init(self, size):
"""Xavier 权重初始化"""
in_dim = size[0]
out_dim = size[1]
xavier_stddev = np.sqrt(2 / (in_dim + out_dim))
return tf.Variable(tf.truncated_normal([in_dim, out_dim], stddev=xavier_stddev), dtype=tf.float32)
def neural_net(self, X, weights, biases):
"""前向传播函数"""
num_layers = len(weights) + 1
# 输入归一化到 [-1, 1]
H = 2.0 * (X - self.lb) / (self.ub - self.lb) - 1.0
for l in range(num_layers - 2):
W = weights[l]
b = biases[l]
H = tf.tanh(tf.add(tf.matmul(H, W), b))
W = weights[-1]
b = biases[-1]
Y = tf.add(tf.matmul(H, W), b)
return Y
def net_uv(self, x, t):
"""预测 u, v 及其一阶导数"""
X = tf.concat([x, t], 1)
uv = self.neural_net(X, self.weights, self.biases)
u = uv[:, 0:1]
v = uv[:, 1:2]
# 计算一阶偏导数
u_x = tf.gradients(u, x)[0]
v_x = tf.gradients(v, x)[0]
return u, v, u_x, v_x
def net_f_uv(self, x, t):
"""计算 PDE 残差"""
u, v, u_x, v_x = self.net_uv(x, t)
# 计算高阶偏导数
u_t = tf.gradients(u, t)[0]
u_xx = tf.gradients(u_x, x)[0]
v_t = tf.gradients(v, t)[0]
v_xx = tf.gradients(v_x, x)[0]
# 残差计算
f_u = u_t + 0.5 * v_xx + (u**2 + v**2) * v
f_v = v_t - 0.5 * u_xx - (u**2 + v**2) * u
return f_u, f_v
def callback(self, loss):
"""优化器回调函数,打印损失"""
print('Loss:', loss)
def train(self, nIter):
"""模型训练函数"""
tf_dict = {self.x0_tf: self.x0, self.t0_tf: self.t0,
self.u0_tf: self.u0, self.v0_tf: self.v0,
self.x_lb_tf: self.x_lb, self.t_lb_tf: self.t_lb,
self.x_ub_tf: self.x_ub, self.t_ub_tf: self.t_ub,
self.x_f_tf: self.x_f, self.t_f_tf: self.t_f}
start_time = time.time()
for it in range(nIter):
self.sess.run(self.train_op_Adam, feed_dict=tf_dict)
# 每 10 轮打印一次训练信息
if it % 10 == 0:
elapsed = time.time() - start_time
loss_value = self.sess.run(self.loss, feed_dict=tf_dict)
print(f'迭代次数: {it}, 损失值: {loss_value:.3e}, 耗时: {elapsed:.2f} s')
start_time = time.time()
def predict(self, X_star):
"""模型预测函数"""
# 预测 u, v
tf_dict = {self.x0_tf: X_star[:, 0:1], self.t0_tf: X_star[:, 1:2]}
u_star = self.sess.run(self.u0_pred, feed_dict=tf_dict)
v_star = self.sess.run(self.v0_pred, feed_dict=tf_dict)
# 预测 PDE 残差
tf_dict = {self.x_f_tf: X_star[:, 0:1], self.t_f_tf: X_star[:, 1:2]}
f_u_star = self.sess.run(self.f_u_pred, feed_dict=tf_dict)
f_v_star = self.sess.run(self.f_v_pred, feed_dict=tf_dict)
return u_star, v_star, f_u_star, f_v_star
if __name__ == "__main__":
# 噪声系数
noise = 0.0
# 求解区域边界
lb = np.array([-5.0, 0.0])
ub = np.array([5.0, np.pi/2])
# 采样点数量与网络结构
N0 = 50
N_b = 50
N_f = 20000
layers = [2, 100, 100, 100, 100, 2]
# 加载解析解数据
data = scipy.io.loadmat('../Data/NLS.mat')
t = data['tt'].flatten()[:, None] # (201, 1)
x = data['x'].flatten()[:, None] # (256, 1)
Exact = data['uu'] # (256, 201)
Exact_u = np.real(Exact) # 实部 (256, 201)
Exact_v = np.imag(Exact) # 虚部 (256, 201)
Exact_h = np.sqrt(Exact_u**2 + Exact_v**2) # 幅值
# 构造网格坐标
X, T = np.meshgrid(x, t)
X_star = np.hstack((X.flatten()[:, None], T.flatten()[:, None]))
u_star = Exact_u.T.flatten()[:, None]
v_star = Exact_v.T.flatten()[:, None]
h_star = Exact_h.T.flatten()[:, None]
# 采样初始条件点
idx_x = np.random.choice(x.shape[0], N0, replace=False)
x0 = x[idx_x, :]
u0 = Exact_u[idx_x, 0:1]
v0 = Exact_v[idx_x, 0:1]
# 采样边界条件点
idx_t = np.random.choice(t.shape[0], N_b, replace=False)
tb = t[idx_t, :]
# 拉丁超立方采样内点
X_f = lb + (ub - lb) * lhs(2, N_f)
# 初始化模型并训练
model = PhysicsInformedNN(x0, u0, v0, tb, X_f, layers, lb, ub)
start_time = time.time()
model.train(50000)
elapsed = time.time() - start_time
print(f'总训练时间: {elapsed:.4f} s')
# 模型预测
u_pred, v_pred, f_u_pred, f_v_pred = model.predict(X_star)
h_pred = np.sqrt(u_pred**2 + v_pred**2)
# 计算相对误差
error_u = np.linalg.norm(u_star - u_pred, 2) / np.linalg.norm(u_star, 2)
error_v = np.linalg.norm(v_star - v_pred, 2) / np.linalg.norm(v_star, 2)
error_h = np.linalg.norm(h_star - h_pred, 2) / np.linalg.norm(h_star, 2)
print(f'u 相对误差: {error_u:.2e}')
print(f'v 相对误差: {error_v:.2e}')
print(f'h 相对误差: {error_h:.2e}')
# 网格插值以可视化
U_pred = griddata(X_star, u_pred.flatten(), (X, T), method='cubic')
V_pred = griddata(X_star, v_pred.flatten(), (X, T), method='cubic')
H_pred = griddata(X_star, h_pred.flatten(), (X, T), method='cubic')
FU_pred = griddata(X_star, f_u_pred.flatten(), (X, T), method='cubic')
FV_pred = griddata(X_star, f_v_pred.flatten(), (X, T), method='cubic')
# 结果可视化
fig, ax = newfig(1.0, 0.9)
ax.axis('off')
# 幅值热力图
gs0 = gridspec.GridSpec(1, 2)
gs0.update(top=1-0.06, bottom=1-1/3, left=0.15, right=0.85, wspace=0)
ax = plt.subplot(gs0[:, :])
h_plot = ax.imshow(H_pred.T, interpolation='nearest', cmap='YlGnBu',
extent=[lb[1], ub[1], lb[0], ub[0]],
origin='lower', aspect='auto')
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.05)
fig.colorbar(h_plot, cax=cax)
# 标注采样时刻
ax.plot(X_u_train[:, 1], X_u_train[:, 0], 'kx', label=f'采样点 ({X_u_train.shape[0]} 个)', markersize=4)
line = np.linspace(x.min(), x.max(), 2)[:, None]
ax.plot(t[75] * np.ones((2, 1)), line, 'k--', linewidth=1)
ax.plot(t[100] * np.ones((2, 1)), line, 'k--', linewidth=1)
ax.plot(t[125] * np.ones((2, 1)), line, 'k--', linewidth=1)
ax.set_xlabel('$t$')
ax.set_ylabel('$x$')
ax.legend(frameon=False, loc='best')
ax.set_title('$|h(t,x)|$', fontsize=10)
# 不同时刻的幅值对比
gs1 = gridspec.GridSpec(1, 3)
gs1.update(top=1-1/3, bottom=0, left=0.1, right=0.9, wspace=0.5)
ax = plt.subplot(gs1[0, 0])
ax.plot(x, Exact_h[:, 75], 'b-', linewidth=2, label='解析解')
ax.plot(x, H_pred[75, :], 'r--', linewidth=2, label='PINN 预测解')
ax.set_xlabel('$x$')
ax.set_ylabel('$|h(t,x)|$')
ax.set_title(f'$t = {t[75][0]:.2f}$', fontsize=10)
ax.set_xlim([-5.1, 5.1])
ax.set_ylim([-0.1, 5.1])
ax = plt.subplot(gs1[0, 1])
ax.plot(x, Exact_h[:, 100], 'b-', linewidth=2)
ax.plot(x, H_pred[100, :], 'r--', linewidth=2)
ax.set_xlabel('$x$')
ax.set_ylabel('$|h(t,x)|$')
ax.set_xlim([-5.1, 5.1])
ax.set_ylim([-0.1, 5.1])
ax.set_title(f'$t = {t[100][0]:.2f}$', fontsize=10)
ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.8), ncol=2, frameon=False)
ax = plt.subplot(gs1[0, 2])
ax.plot(x, Exact_h[:, 125], 'b-', linewidth=2)
ax.plot(x, H_pred[125, :], 'r--', linewidth=2)
ax.set_xlabel('$x$')
ax.set_ylabel('$|h(t,x)|$')
ax.set_xlim([-5.1, 5.1])
ax.set_ylim([-0.1, 5.1])
ax.set_title(f'$t = {t[125][0]:.2f}$', fontsize=10)
# 保存图片
savefig('./figures/retest/reNLS')4. 实验细节及复现结果
模型采用 4 层全连接神经网络,输入层包含 2 个神经元(对应 x , t x, t x,t),输出层包含 2 个神经元(对应解的实部 u u u 与虚部 v v v),隐藏层每层包含 100 个神经元,激活函数为 Tanh。解析解由谱方法计算得到,维度为 256 × 201 256 \times 201 256×201(空间维度 × 时间维度)。模型训练 50000 轮后,输出结果如下:
Loss: 2.051247e-06
Error u: 1.408588e-03
Error v: 1.770550e-03
Error h: 1.101867e-03

5. 常见问题及解决方案
问题 1:Matplotlib 版本兼容问题
报错原因:Matplotlib 版本过高导致 newfig 等函数调用异常。
解决方案:安装指定版本的 Matplotlib:
bash
pip uninstall matplotlib
pip install matplotlib==3.4.3问题 2:无法导入 newfig 函数
报错信息:cannot import name 'newfig' from 'plotting'
解决方案:将 plotting.py 文件放置于代码同级目录(具体见评论区)。
问题 3:LaTeX 渲染异常
报错信息:LaTeX 相关的字体/渲染错误。
解决方案:
- 安装 TeX Live 套件;
- 在 Python 环境中安装 LaTeX 相关依赖:
bash
pip install latexPINN 解偏微分方程实例 3(Allen-Cahn 方程)
喝过期的拉菲 于 2023-11-14 16:23:34 修改
本文详细介绍基于物理信息神经网络(PINN)求解 Allen-Cahn 方程的方法,包括方程定义、损失函数构建及实验设置。PINN 结合神经网络的拟合能力与物理方程的约束条件,可有效求解偏微分方程的数值解,文中给出了完整的实现代码与实验结果。
1. Allen-Cahn 方程
考虑如下 Allen-Cahn 方程:
∂ u ∂ t − 0.0001 ∂ 2 u ∂ x 2 + 5 u 3 − 5 u = 0 \frac{\partial u}{\partial t} - 0.0001 \frac{\partial^2 u}{\partial x^2} + 5 u^3 - 5 u = 0 ∂t∂u−0.0001∂x2∂2u+5u3−5u=0
其初始条件与边界条件为:
{ u ( 0 , x ) = x 2 cos ( π x ) u ( t , − 1 ) = u ( t , 1 ) ∂ u ∂ x ( t , − 1 ) = ∂ u ∂ x ( t , 1 ) \begin{cases} u(0, x) = x^2 \cos(\pi x) \\6pt u(t, -1) = u(t, 1) \\6pt \frac{\partial u}{\partial x}(t, -1) = \frac{\partial u}{\partial x}(t, 1) \end{cases} ⎩ ⎨ ⎧u(0,x)=x2cos(πx)u(t,−1)=u(t,1)∂x∂u(t,−1)=∂x∂u(t,1)
其中,求解区域为 x ∈ − 1 , 1 x \in -1, 1 x∈−1,1, t ∈ 0 , 1 t \in 0, 1 t∈0,1。该方程为含周期性边界条件与初始条件的偏微分方程,本文采用 PINN 论文中提出的离散时间模型进行求解。
2. 损失函数定义
总损失函数定义为:
SSE = SSE n + SSE b \text{SSE} = \text{SSE}_n + \text{SSE}_b SSE=SSEn+SSEb
其中:
- SSE n \text{SSE}_n SSEn 为偏微分方程残差损失项(数值损失);
- SSE b \text{SSE}_b SSEb 为周期性边界条件损失项(边界损失)。
各分项损失的数学形式为:
SSE n = ∑ j = 1 q + 1 ∑ i = 1 N n ∣ u j n ( x n , i ) − u n , i ∣ 2 , SSE b = ∑ i = 1 q ∣ u n + c i ( − 1 ) − u n + c i ( 1 ) ∣ 2 + ∣ u n + 1 ( − 1 ) − u n + 1 ( 1 ) ∣ 2 + ∑ i = 1 q ∣ ∂ u n + c i ∂ x ( − 1 ) − ∂ u n + c i ∂ x ( 1 ) ∣ 2 + ∣ ∂ u n + 1 ∂ x ( − 1 ) − ∂ u n + 1 ∂ x ( 1 ) ∣ 2 . \begin{align*} \text{SSE}n & = \sum{j=1}^{q+1} \sum_{i=1}^{N_n} \left| u_j^n(x^{n,i}) - u^{n,i} \right|^2, \\ \text{SSE}b & = \sum{i=1}^{q} \left| u^{n+c_i}(-1) - u^{n+c_i}(1) \right|^2 + \left| u^{n+1}(-1) - u^{n+1}(1) \right|^2 \\ & \quad + \sum_{i=1}^{q} \left| \frac{\partial u^{n+c_i}}{\partial x}(-1) - \frac{\partial u^{n+c_i}}{\partial x}(1) \right|^2 + \left| \frac{\partial u^{n+1}}{\partial x}(-1) - \frac{\partial u^{n+1}}{\partial x}(1) \right|^2. \end{align*} SSEnSSEb=j=1∑q+1i=1∑Nn ujn(xn,i)−un,i 2,=i=1∑q un+ci(−1)−un+ci(1) 2+ un+1(−1)−un+1(1) 2+i=1∑q ∂x∂un+ci(−1)−∂x∂un+ci(1) 2+ ∂x∂un+1(−1)−∂x∂un+1(1) 2.
其中:
- { x n , i , u n , i } i = 1 N n \{x^{n,i}, u^{n,i}\}_{i=1}^{N_n} {xn,i,un,i}i=1Nn 为 t n t^n tn 时刻的采样点与解析解;
- u j n ( x n , i ) u_j^n(x^{n,i}) ujn(xn,i) 由 Runge-Kutta 离散格式计算:
u n + c i = u n − Δ t ∑ j = 1 q a i j N u n + c j , i = 1 , 2 , ... , q u n + 1 = u n − Δ t ∑ j = 1 q b j N u n + c j \begin{align*} u^{n+c_i} &= u^n - \Delta t \sum_{j=1}^q a_{ij} \mathcal{N}u\^{n+c_j}, \quad i=1,2,\dots,q \\6pt u^{n+1} &= u^n - \Delta t \sum_{j=1}^q b_j \mathcal{N}u\^{n+c_j} \end{align*} un+ciun+1=un−Δtj=1∑qaijNun+cj,i=1,2,...,q=un−Δtj=1∑qbjNun+cj
N u n + c j \mathcal{N}u\^{n+c_j} Nun+cj 为方程残差算子:
N u n + c j = − 0.0001 ∂ 2 u n + c j ∂ x 2 + 5 ( u n + c j ) 3 − 5 u n + c j \mathcal{N}u\^{n+c_j} = -0.0001 \frac{\partial^2 u^{n+c_j}}{\partial x^2} + 5 (u^{n+c_j})^3 - 5 u^{n+c_j} Nun+cj=−0.0001∂x2∂2un+cj+5(un+cj)3−5un+cj
参数设置为 N n = 200 N_n = 200 Nn=200, q = 100 q = 100 q=100, Δ t = 0.8 \Delta t = 0.8 Δt=0.8;神经网络结构为:输入层 1 个神经元,4 个隐藏层(每层 100 个神经元),输出层 101 个神经元。
3. 实现代码
python
"""
基于 PINN 求解 Allen-Cahn 方程
原作者:Maziar Raissi
注释:ST
说明:计算 [0,1] × [-1,1] 区域的解析解,解析解维度为 201 × 256
"""
import sys
sys.path.insert(0, '../../Utilities/')
import tensorflow.compat.v1 as tf # 兼容 TensorFlow 1.x
tf.disable_v2_behavior()
import numpy as np
import matplotlib.pyplot as plt
import time
import scipy.io
from plotting import newfig, savefig
import matplotlib.gridspec as gridspec
from mpl_toolkits.axes_grid1 import make_axes_locatable
# 设置随机数种子
np.random.seed(1234)
tf.set_random_seed(1234)
class PhysicsInformedNN:
"""物理信息神经网络类,求解 Allen-Cahn 方程"""
def __init__(self, x0, u0, x1, layers, dt, lb, ub, q):
"""
初始化函数
参数说明:
x0: 初始时刻采样点 x 坐标 (200, 1)
u0: 初始时刻采样点解析解 (200, 1)
x1: 边界点坐标 [-1, 1] (2, 1)
layers: 神经网络结构 [1, 200, 200, 200, 200, 101]
dt: 时间步长 0.8
lb: 空间下界 -1.0
ub: 空间上界 1.0
q: Runge-Kutta 阶数 100
"""
self.lb = lb
self.ub = ub
self.x0 = x0
self.x1 = x1
self.u0 = u0
self.layers = layers
self.dt = dt
self.q = max(q, 1)
# 初始化神经网络
self.weights, self.biases = self.initialize_NN(layers)
# 加载 IRK 权重
tmp = np.float32(np.loadtxt('../../Utilities/IRK_weights/Butcher_IRK%d.txt' % q, ndmin=2))
self.IRK_weights = np.reshape(tmp[0:q**2+q], (q+1, q))
self.IRK_times = tmp[q**2+q:]
# 定义 TensorFlow 会话与占位符
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
log_device_placement=True))
self.x0_tf = tf.placeholder(tf.float32, shape=(None, self.x0.shape[1]))
self.x1_tf = tf.placeholder(tf.float32, shape=(None, self.x1.shape[1]))
self.u0_tf = tf.placeholder(tf.float32, shape=(None, self.u0.shape[1]))
self.dummy_x0_tf = tf.placeholder(tf.float32, shape=(None, self.q)) # 前向梯度占位符
self.dummy_x1_tf = tf.placeholder(tf.float32, shape=(None, self.q+1)) # 前向梯度占位符
# 构建计算图
self.U0_pred = self.net_U0(self.x0_tf) # 内点预测 (200, 101)
self.U1_pred, self.U1_x_pred = self.net_U1(self.x1_tf) # 边界预测 (2, 101)
# 定义损失函数
self.loss = tf.reduce_sum(tf.square(self.u0_tf - self.U0_pred)) + \
tf.reduce_sum(tf.square(self.U1_pred[0, :] - self.U1_pred[1, :])) + \
tf.reduce_sum(tf.square(self.U1_x_pred[0, :] - self.U1_x_pred[1, :]))
# 定义优化器
self.optimizer_Adam = tf.train.AdamOptimizer()
self.train_op_Adam = self.optimizer_Adam.minimize(self.loss)
# 初始化变量
init = tf.global_variables_initializer()
self.sess.run(init)
def initialize_NN(self, layers):
"""初始化神经网络权重(Xavier 初始化)"""
weights = []
biases = []
num_layers = len(layers)
for l in range(num_layers - 1):
W = self.xavier_init(size=[layers[l], layers[l+1]])
b = tf.Variable(tf.zeros([1, layers[l+1]], dtype=tf.float32), dtype=tf.float32)
weights.append(W)
biases.append(b)
return weights, biases
def xavier_init(self, size):
"""Xavier 权重初始化"""
in_dim = size[0]
out_dim = size[1]
xavier_stddev = np.sqrt(2 / (in_dim + out_dim))
return tf.Variable(tf.truncated_normal([in_dim, out_dim], stddev=xavier_stddev), dtype=tf.float32)
def neural_net(self, X, weights, biases):
"""神经网络前向传播"""
num_layers = len(weights) + 1
# 输入归一化
H = 2.0 * (X - self.lb) / (self.ub - self.lb) - 1.0
for l in range(num_layers - 2):
W = weights[l]
b = biases[l]
H = tf.tanh(tf.add(tf.matmul(H, W), b))
W = weights[-1]
b = biases[-1]
Y = tf.add(tf.matmul(H, W), b)
return Y
def fwd_gradients_0(self, U, x):
"""计算前向梯度(内点)"""
g = tf.gradients(U, x, grad_ys=self.dummy_x0_tf)[0]
return tf.gradients(g, self.dummy_x0_tf)[0]
def fwd_gradients_1(self, U, x):
"""计算前向梯度(边界点)"""
g = tf.gradients(U, x, grad_ys=self.dummy_x1_tf)[0]
return tf.gradients(g, self.dummy_x1_tf)[0]
def net_U0(self, x):
"""内点预测函数,结合 Runge-Kutta 离散格式"""
U1 = self.neural_net(x, self.weights, self.biases)
U = U1[:, :-1]
U_x = self.fwd_gradients_0(U, x)
U_xx = self.fwd_gradients_0(U_x, x)
# 计算方程残差
F = 5.0 * U - 5.0 * U**3 + 0.0001 * U_xx
# Runge-Kutta 离散格式
U0 = U1 - self.dt * tf.matmul(F, self.IRK_weights.T)
return U0
def net_U1(self, x):
"""边界点预测函数"""
U1 = self.neural_net(x, self.weights, self.biases)
U1_x = self.fwd_gradients_1(U1, x)
return U1, U1_x
def callback(self, loss):
"""优化器回调函数"""
print(f'损失值: {loss:.6f}')
def train(self, nIter):
"""模型训练函数"""
tf_dict = {self.x0_tf: self.x0, self.u0_tf: self.u0, self.x1_tf: self.x1,
self.dummy_x0_tf: np.ones((self.x0.shape[0], self.q)),
self.dummy_x1_tf: np.ones((self.x1.shape[0], self.q+1))}
start_time = time.time()
for it in range(nIter):
self.sess.run(self.train_op_Adam, feed_dict=tf_dict)
# 每 10 轮打印训练信息
if it % 10 == 0:
elapsed = time.time() - start_time
loss_value = self.sess.run(self.loss, feed_dict=tf_dict)
print(f'迭代次数: {it}, 损失值: {loss_value:.3e}, 耗时: {elapsed:.2f} s')
start_time = time.time()
def predict(self, x_star):
"""模型预测函数"""
U1_star = self.sess.run(self.U1_pred, feed_dict={self.x1_tf: x_star})
return U1_star
if __name__ == "__main__":
# 超参数设置
q = 100
layers = [1, 200, 200, 200, 200, q+1]
lb = np.array([-1.0])
ub = np.array([1.0])
N = 200 # 内点采样数量
# 加载解析解数据
data = scipy.io.loadmat('../Data/AC.mat')
t = data['tt'].flatten()[:, None] # 时间坐标 (201, 1)
x = data['x'].flatten()[:, None] # 空间坐标 (512, 1)
Exact = np.real(data['uu']).T # 解析解 (201, 512)
# 时间步长设置
idx_t0 = 20
idx_t1 = 180
dt = t[idx_t1] - t[idx_t0] # dt = 0.8
# 采样初始条件点
noise_u0 = 0.0
idx_x = np.random.choice(Exact.shape[1], N, replace=False)
x0 = x[idx_x, :]
u0 = Exact[idx_t0:idx_t0+1, idx_x].T
u0 = u0 + noise_u0 * np.std(u0) * np.random.randn(u0.shape[0], u0.shape[1])
# 边界点
x1 = np.vstack((lb, ub))
# 测试数据
x_star = x
# 初始化模型并训练
model = PhysicsInformedNN(x0, u0, x1, layers, dt, lb, ub, q)
model.train(10000) # 训练 10000 轮
# 模型预测
U1_pred = model.predict(x_star)
# 计算相对误差
error = np.linalg.norm(U1_pred[:, -1] - Exact[idx_t1, :], 2) / np.linalg.norm(Exact[idx_t1, :], 2)
print(f'相对误差: {error:.6e}')
# 结果可视化
fig, ax = newfig(1.0, 1.2)
ax.axis('off')
# 解析解热力图
gs0 = gridspec.GridSpec(1, 2)
gs0.update(top=1-0.06, bottom=1-1/2 + 0.1, left=0.15, right=0.85, wspace=0)
ax = plt.subplot(gs0[:, :])
h = ax.imshow(Exact.T, interpolation='nearest', cmap='seismic',
extent=[t.min(), t.max(), x_star.min(), x_star.max()],
origin='lower', aspect='auto')
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.05)
fig.colorbar(h, cax=cax)
# 标注时间点
line = np.linspace(x.min(), x.max(), 2)[:, None]
ax.plot(t[idx_t0] * np.ones((2, 1)), line, 'w-', linewidth=1)
ax.plot(t[idx_t1] * np.ones((2, 1)), line, 'w-', linewidth=1)
ax.set_xlabel('$t$')
ax.set_ylabel('$x$')
ax.set_title('$u(t,x)$', fontsize=10)
# 不同时刻的解对比
gs1 = gridspec.GridSpec(1, 2)
gs1.update(top=1-1/2-0.05, bottom=0.15, left=0.15, right=0.85, wspace=0.5)
ax = plt.subplot(gs1[0, 0])
ax.plot(x, Exact[idx_t0, :], 'b-', linewidth=2)
ax.plot(x0, u0, 'rx', linewidth=2, label='采样数据')
ax.set_xlabel('$x$')
ax.set_ylabel('$u(t,x)$')
ax.set_title(f'$t = {t[idx_t0][0]:.2f}$', fontsize=10)
ax.set_xlim([lb-0.1, ub+0.1])
ax.legend(loc='upper center', bbox_to_anchor=(0.8, -0.3), ncol=2, frameon=False)
ax = plt.subplot(gs1[0, 1])
ax.plot(x, Exact[idx_t1, :], 'b-', linewidth=2, label='解析解')
ax.plot(x_star, U1_pred[:, -1], 'r--', linewidth=2, label='PINN 预测解')
ax.set_xlabel('$x$')
ax.set_ylabel('$u(t,x)$')
ax.set_title(f'$t = {t[idx_t1][0]:.2f}$', fontsize=10)
ax.set_xlim([lb-0.1, ub+0.1])
ax.legend(loc='upper center', bbox_to_anchor=(0.1, -0.3), ncol=2, frameon=False)
# 保存图片
savefig('./figures/retest/reAC')4. 实验细节及复现结果
模型采用 4 层全连接神经网络,输入层 1 个神经元(对应空间坐标 x x x),输出层 101 个神经元(对应 q + 1 q+1 q+1 个离散时间点的解),隐藏层每层 200 个神经元。解析解由谱方法计算得到,维度为 256 × 201 256 \times 201 256×201(空间维度 × 时间维度)。模型训练 10000 轮后,输出结果如下:
Loss: 0.004521864
Error: 4.147326e-03相对误差计算公式为:
Error = ∥ U − U ext ∥ 2 ∥ U ext ∥ 2 \text{Error} = \frac{\| U - U_{\text{ext}} \|2}{\| U{\text{ext}} \|_2} Error=∥Uext∥2∥U−Uext∥2
其中, U ∈ R 512 × 1 U \in \mathbb{R}^{512 \times 1} U∈R512×1 为 t = 0.9 t=0.9 t=0.9 时刻 PINN 预测解, U ext ∈ R 512 × 1 U_{\text{ext}} \in \mathbb{R}^{512 \times 1} Uext∈R512×1 为同时刻的解析解。

PINN 解偏微分方程实例 4------Diffusion、Burgers、Allen--Cahn、Wave 方程及反问题代码
喝过期的拉菲 于 2025-03-14 18:59:41 发布
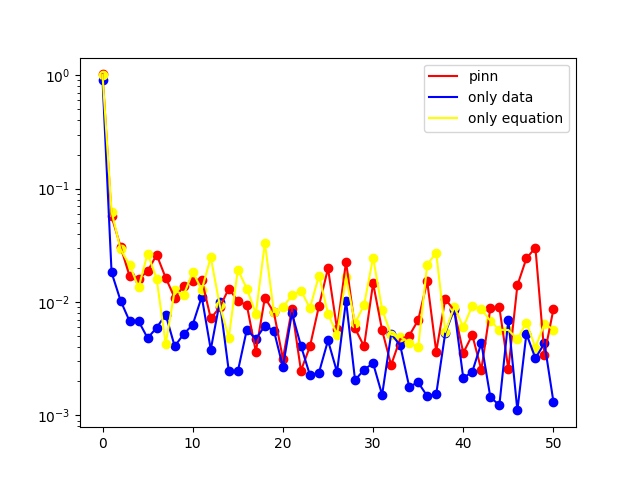
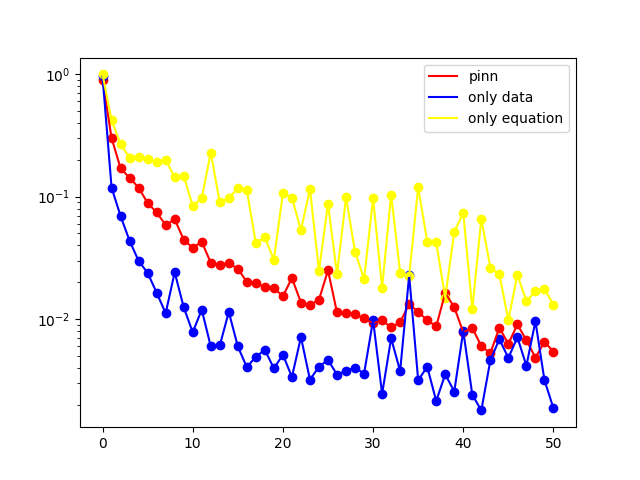
本文基于《PINN 解偏微分方程实例 1》中给出的代码框架,求解了四类典型偏微分方程(Diffusion 方程、Burgers 方程、Allen--Cahn 方程、Wave 方程)的正问题,并以 Burgers 方程为例编写了反问题求解代码。
本文展示的结果为 L 2 L_2 L2 误差曲线,包含三类误差形式:
- pinn:损失函数同时受方程约束与数据约束;
- only data:损失函数仅受数据约束;
- only equation:损失函数仅受方程约束。
误差曲线横坐标为 epoch 除以 1000 得到的数值,本文所有算例的训练迭代次数均设置为 50000 epoch,使用者可根据实际需求调整 epoch 数值以优化求解结果。
一、正问题
1. Diffusion equation
一维扩散方程的数学形式如下:
∂ u ∂ t = ∂ 2 u ∂ x 2 + e − t ( − sin ( π x ) + π 2 sin ( π x ) ) , x ∈ − 1 , 1 , t ∈ 0 , 1 u ( x , 0 ) = sin ( π x ) u ( − 1 , t ) = u ( 1 , t ) = 0 \begin{array}{l} \frac{\partial u}{\partial t}=\frac{\partial^{2} u}{\partial x^{2}}+e^{-t}\left(-\sin (\pi x)+\pi^{2} \sin (\pi x)\right), \quad x \in-1,1, t \in0,1 \\6pt u(x, 0)=\sin (\pi x) \\6pt u(-1, t)=u(1, t)=0 \end{array} ∂t∂u=∂x2∂2u+e−t(−sin(πx)+π2sin(πx)),x∈−1,1,t∈0,1u(x,0)=sin(πx)u(−1,t)=u(1,t)=0
式中, u u u 表示扩散物质的浓度,该方程的精确解为 u ( x , t ) = sin ( π x ) e − t u(x,t)=\sin(\pi x)e^{-t} u(x,t)=sin(πx)e−t。
2. Burgers' equation
Burgers 方程的数学定义为:
∂ u ∂ t + u ∂ u ∂ x = v ∂ 2 u ∂ x 2 , x ∈ − 1 , 1 , t ∈ 0 , 1 , u ( x , 0 ) = − sin ( π x ) , u ( − 1 , t ) = u ( 1 , t ) = 0 , \begin{array}{l} \frac{\partial u}{\partial t}+u \frac{\partial u}{\partial x}=v \frac{\partial^{2} u}{\partial x^{2}}, \quad x \in-1,1, t \in0,1, \\6pt u(x, 0)=-\sin (\pi x), \\6pt u(-1, t)=u(1, t)=0, \end{array} ∂t∂u+u∂x∂u=v∂x2∂2u,x∈−1,1,t∈0,1,u(x,0)=−sin(πx),u(−1,t)=u(1,t)=0,
式中, u u u 为流体流速, ν ν ν 为流体的运动粘度系数,本文算例中取值为 ν = 0.01 / π ν = 0.01/\pi ν=0.01/π。
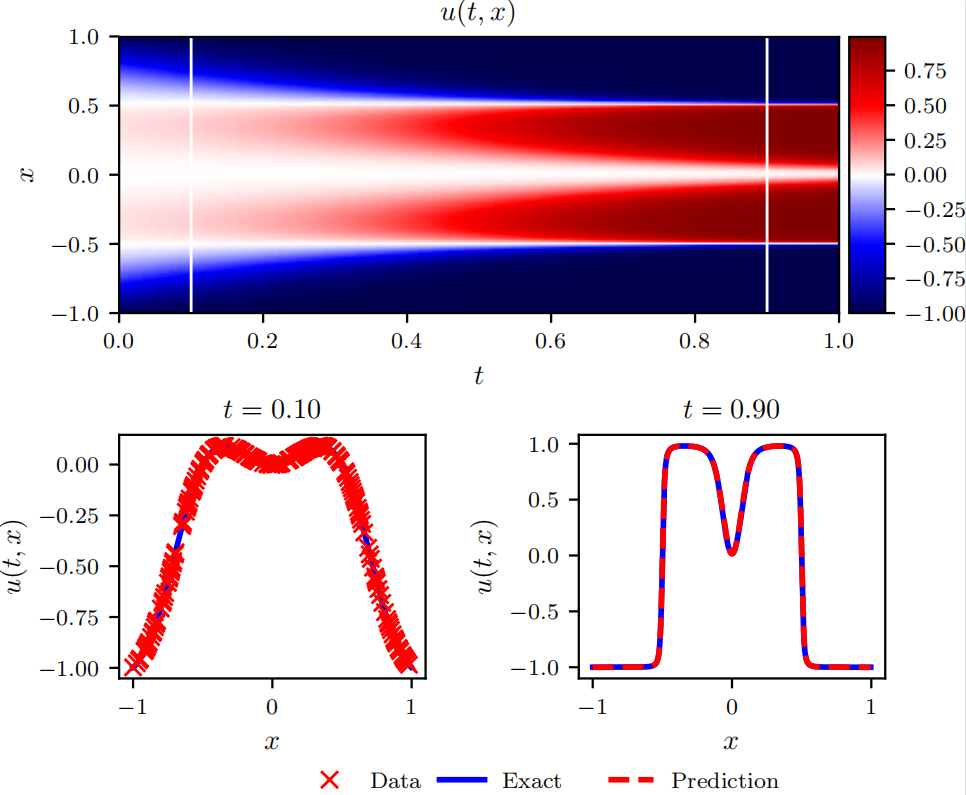
3. Allen--Cahn equation
Allen--Cahn 方程的数学形式如下:
∂ u ∂ t = D ∂ 2 u ∂ x 2 + 5 ( u − u 3 ) , x ∈ − 1 , 1 , t ∈ 0 , 1 , u ( x , 0 ) = x 2 cos ( π x ) , u ( − 1 , t ) = u ( 1 , t ) = − 1 , \begin{array}{l} \frac{\partial u}{\partial t}=D \frac{\partial^{2} u}{\partial x^{2}}+5\left(u-u^{3}\right), \quad x \in-1,1, t \in0,1, \\6pt u(x, 0)=x^{2} \cos (\pi x), \\6pt u(-1, t)=u(1, t)=-1, \end{array} ∂t∂u=D∂x2∂2u+5(u−u3),x∈−1,1,t∈0,1,u(x,0)=x2cos(πx),u(−1,t)=u(1,t)=−1,
式中,扩散系数 D D D 取值为 0.001 0.001 0.001。
4. Wave equation
一维波动方程的数学形式如下:
∂ 2 u ∂ t 2 − 4 ∂ 2 u ∂ x 2 = 0 , x ∈ 0 , 1 , t ∈ 0 , 1 , u ( 0 , t ) = u ( 1 , t ) = 0 , t ∈ 0 , 1 , u ( x , 0 ) = sin ( π x ) + 1 2 sin ( 4 π x ) , x ∈ 0 , 1 , ∂ u ∂ t ( x , 0 ) = 0 , x ∈ 0 , 1 , \begin{array}{l} \frac{\partial^{2} u}{\partial t^{2}}-4 \frac{\partial^{2} u}{\partial x^{2}}=0, \quad x \in0,1, t \in0,1, \\6pt u(0, t)=u(1, t)=0, \quad t \in0,1, \\6pt u(x, 0)=\sin (\pi x)+\frac{1}{2} \sin (4 \pi x), \quad x \in0,1, \\6pt \frac{\partial u}{\partial t}(x, 0)=0, \quad x \in0,1, \end{array} ∂t2∂2u−4∂x2∂2u=0,x∈0,1,t∈0,1,u(0,t)=u(1,t)=0,t∈0,1,u(x,0)=sin(πx)+21sin(4πx),x∈0,1,∂t∂u(x,0)=0,x∈0,1,
该方程的精确解为:
u ( x , t ) = sin ( π x ) cos ( 2 π t ) + 1 2 sin ( 4 π x ) cos ( 8 π t ) . u(x, t)=\sin (\pi x) \cos (2 \pi t)+\frac{1}{2} \sin (4 \pi x) \cos (8 \pi t) . u(x,t)=sin(πx)cos(2πt)+21sin(4πx)cos(8πt).
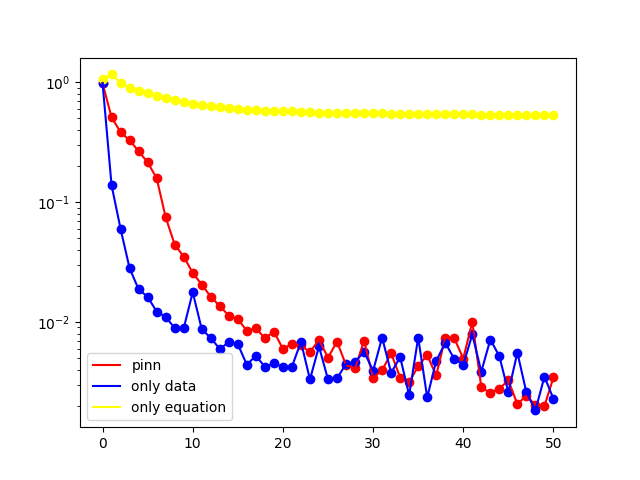
二、反问题
1. Burgers' equation
Burgers 方程的数学定义为:
∂ u ∂ t + u ∂ u ∂ x = v ∂ 2 u ∂ x 2 , x ∈ − 1 , 1 , t ∈ 0 , 1 , u ( x , 0 ) = − sin ( π x ) , u ( − 1 , t ) = u ( 1 , t ) = 0 , \begin{array}{l} \frac{\partial u}{\partial t}+u \frac{\partial u}{\partial x}=v \frac{\partial^{2} u}{\partial x^{2}}, \quad x \in-1,1, t \in0,1, \\6pt u(x, 0)=-\sin (\pi x), \\6pt u(-1, t)=u(1, t)=0, \end{array} ∂t∂u+u∂x∂u=v∂x2∂2u,x∈−1,1,t∈0,1,u(x,0)=−sin(πx),u(−1,t)=u(1,t)=0,
式中, u u u 为流体流速, ν ν ν 为流体的运动粘度系数。
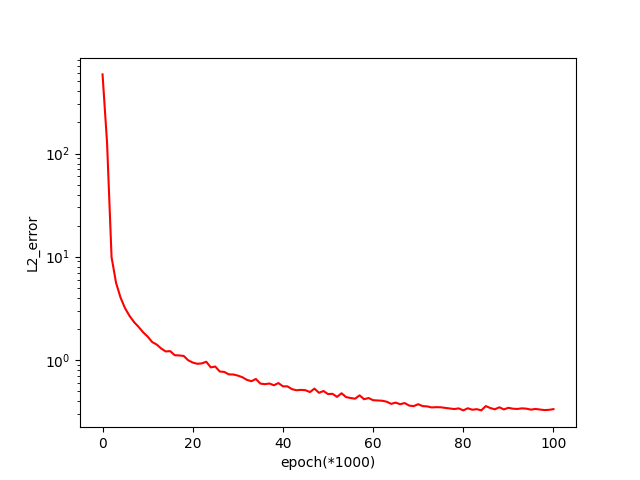
本算例中假设粘度系数 v v v 为未知参数,求解目标为同时得到方程的数值解与参数 v v v 的估计值。

三、部分代码示例
python
import torch
import numpy as np
import matplotlib.pyplot as plt
sin = torch.sin
cos = torch.cos
exp = torch.exp
pi = torch.pi
epochs = 50000 # 训练迭代次数,需设置为 1000 的整数倍
h = 100 # 绘图网格密度
N = 30 # 内点配置点数
N1 = 10 # 边界点配置点数
N2 = 5000 # 数据点数量
# 用于存储不同约束条件下的 L2 误差
L2_error = []
L2_error_data = []
L2_error_eq = []
# 训练过程 1:损失函数同时受方程与数据约束(pinn)
u = MLP()
opt = torch.optim.Adam(params=u.parameters())
xt, u_real = test_data(x_inf=-1, x_sup=1, t_inf=0, t_sup=1, h=h)
print("**************** equation+data ********************")
for i in range(epochs):
opt.zero_grad()
l = l_interior(u) \
+ l_down(u) \
+ l_left(u) \
+ l_right(u) \
+ l_data(u)
l.backward()
opt.step()
if (i+1) % 1000 == 0 or i == 0:
u_pred = u(xt)
error = l2_relative_error(u_real, u_pred.detach().numpy())
L2_error.append(error)
print("L2 相对误差: ", error)
# 训练过程 2:损失函数仅受数据约束(only data)
u1 = MLP()
opt = torch.optim.Adam(params=u1.parameters())
print("**************** data ********************")
for i in range(epochs):
opt.zero_grad()
l = l_data(u1)
l.backward()
opt.step()
if (i+1) % 1000 == 0 or i == 0:
u_pred = u1(xt)
error = l2_relative_error(u_real, u_pred.detach().numpy())
L2_error_data.append(error)
print("L2 相对误差: ", error)
# 训练过程 3:损失函数仅受方程约束(only equation)
u2 = MLP()
opt = torch.optim.Adam(params=u2.parameters())
print("**************** equation ********************")
for i in range(epochs):
opt.zero_grad()
l = l_interior(u2) \
+ l_down(u2) \
+ l_left(u2) \
+ l_right(u2)
l.backward()
opt.step()
if (i+1) % 1000 == 0 or i == 0:
u_pred = u2(xt)
error = l2_relative_error(u_real, u_pred.detach().numpy())
L2_error_eq.append(error)
print("L2 相对误差: ", error)
# 输出最终误差结果
print("********************************")
print("PINN 相对误差为: ", L2_error[-1])
print("equation 相对误差为: ", L2_error_eq[-1])
print("data 相对误差为: ", L2_error_data[-1])
print("********************************")
# 绘制 L2 误差曲线
x = range(int(epochs / 1000 + 1))
plt.plot(x, L2_error, c='red', label='pinn')
plt.plot(x, L2_error_data, c='blue', label='only data')
plt.plot(x, L2_error_eq, c='yellow', label='only equation')
plt.scatter(x, L2_error, c='red')
plt.scatter(x, L2_error_data, c='blue')
plt.scatter(x, L2_error_eq, c='yellow')
plt.yscale('log')
plt.legend()
plt.show()完整代码目录如下:
PINN 解偏微分方程实例 5------Diffusion、Burgers、Allen--Cahn 方程及反问题
喝过期的拉菲 于 2025-03-14 18:58:14
本文采用 PINN 方法求解了三类偏微分方程的正问题与一类反问题,其中正问题包括 Diffusion 方程、Burgers 方程、Allen--Cahn 方程,反问题以 Burgers 方程为例展开求解。
本文展示了各方程对应的 PINN 数值解、精确解及误差分布图像,具体内容如下。
一、正问题
1. Diffusion equation
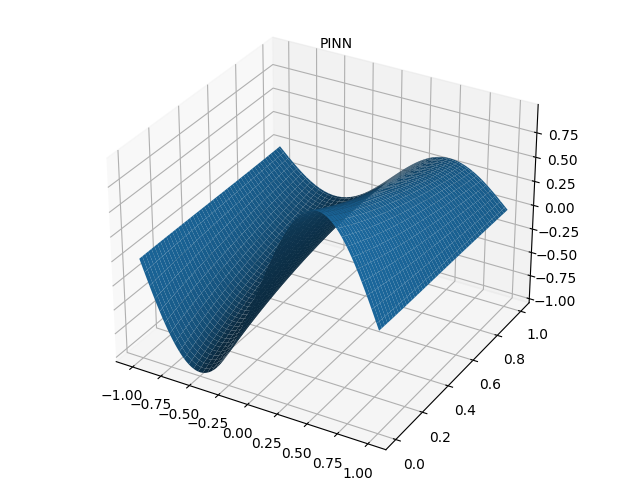
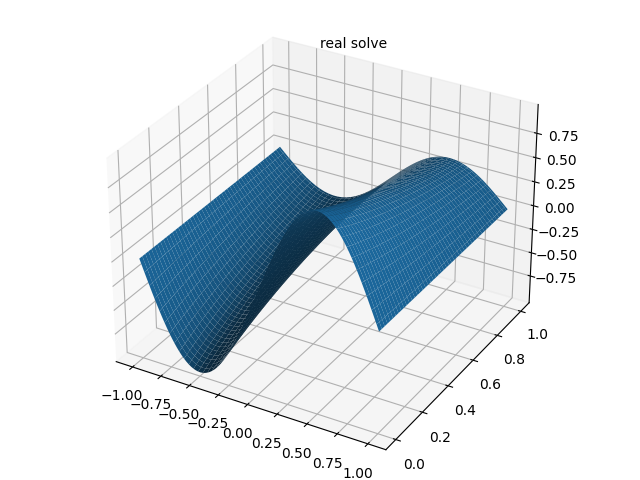
一维扩散方程的数学形式如下:
∂ u ∂ t = ∂ 2 u ∂ x 2 + e − t ( − sin ( π x ) + π 2 sin ( π x ) ) , x ∈ − 1 , 1 , t ∈ 0 , 1 u ( x , 0 ) = sin ( π x ) u ( − 1 , t ) = u ( 1 , t ) = 0 \begin{array}{l} \frac{\partial u}{\partial t}=\frac{\partial^{2} u}{\partial x^{2}}+e^{-t}\left(-\sin (\pi x)+\pi^{2} \sin (\pi x)\right), \quad x \in-1,1, t \in0,1 \\6pt u(x, 0)=\sin (\pi x) \\6pt u(-1, t)=u(1, t)=0 \end{array} ∂t∂u=∂x2∂2u+e−t(−sin(πx)+π2sin(πx)),x∈−1,1,t∈0,1u(x,0)=sin(πx)u(−1,t)=u(1,t)=0
式中, u u u 表示扩散物质的浓度,该方程的精确解为 u ( x , t ) = sin ( π x ) e − t u(x,t)=\sin(\pi x)e^{-t} u(x,t)=sin(πx)e−t。
- PINN 数值解
- 精确解
- 误差分布

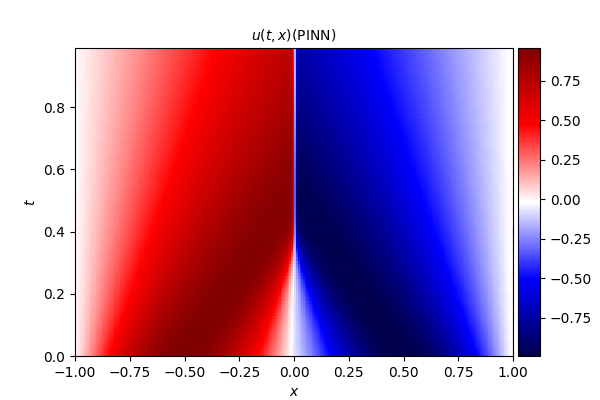
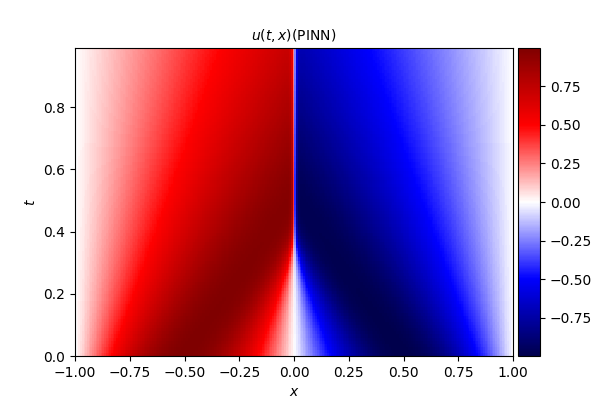
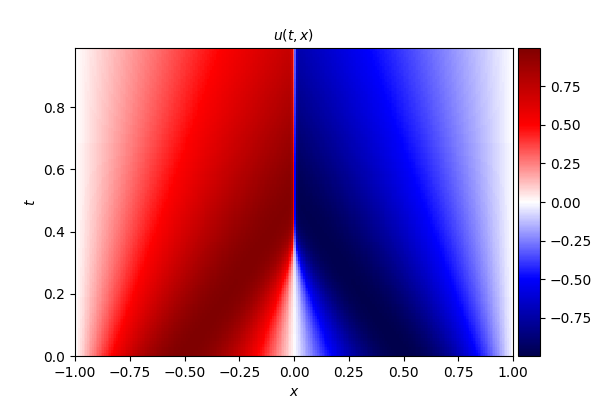
2. Burgers' equation
Burgers 方程的数学定义为:
∂ u ∂ t + u ∂ u ∂ x = v ∂ 2 u ∂ x 2 , x ∈ − 1 , 1 , t ∈ 0 , 1 , u ( x , 0 ) = − sin ( π x ) , u ( − 1 , t ) = u ( 1 , t ) = 0 , \begin{array}{l} \frac{\partial u}{\partial t}+u \frac{\partial u}{\partial x}=v \frac{\partial^{2} u}{\partial x^{2}}, \quad x \in-1,1, t \in0,1, \\6pt u(x, 0)=-\sin (\pi x), \\6pt u(-1, t)=u(1, t)=0, \end{array} ∂t∂u+u∂x∂u=v∂x2∂2u,x∈−1,1,t∈0,1,u(x,0)=−sin(πx),u(−1,t)=u(1,t)=0,
式中, u u u 为流体流速, ν ν ν 为流体的运动粘度系数,本文算例中取值为 ν = 0.01 / π ν = 0.01/\pi ν=0.01/π。
- PINN 数值解
- 精确解
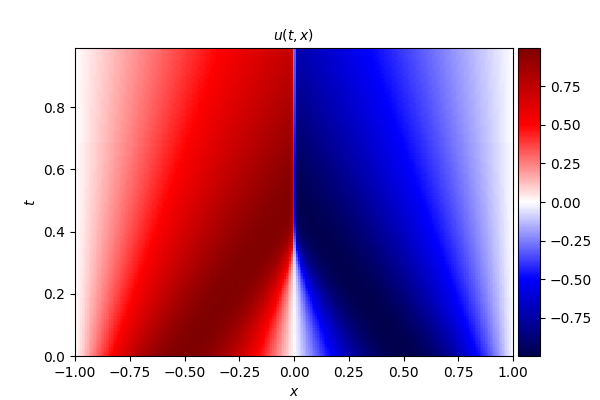
- 误差分布
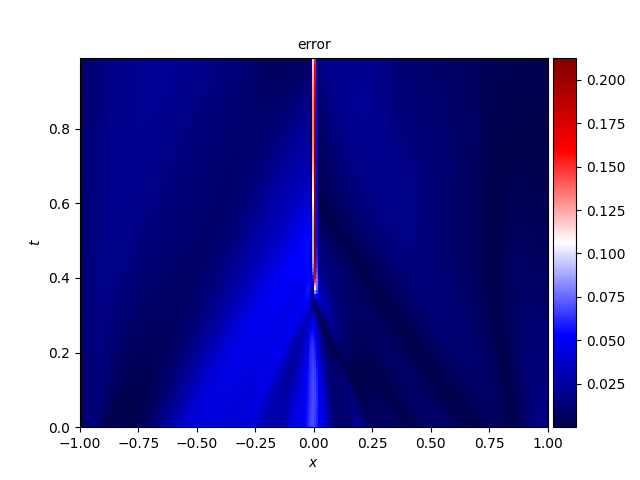
3. Allen--Cahn equation
Allen--Cahn 方程的数学形式如下:
∂ u ∂ t = D ∂ 2 u ∂ x 2 + 5 ( u − u 3 ) , x ∈ − 1 , 1 , t ∈ 0 , 1 , u ( x , 0 ) = x 2 cos ( π x ) , u ( − 1 , t ) = u ( 1 , t ) = − 1 , \begin{array}{l} \frac{\partial u}{\partial t}=D \frac{\partial^{2} u}{\partial x^{2}}+5\left(u-u^{3}\right), \quad x \in-1,1, t \in0,1, \\6pt u(x, 0)=x^{2} \cos (\pi x), \\6pt u(-1, t)=u(1, t)=-1, \end{array} ∂t∂u=D∂x2∂2u+5(u−u3),x∈−1,1,t∈0,1,u(x,0)=x2cos(πx),u(−1,t)=u(1,t)=−1,
式中,扩散系数 D D D 取值为 0.001 0.001 0.001。
- PINN 数值解
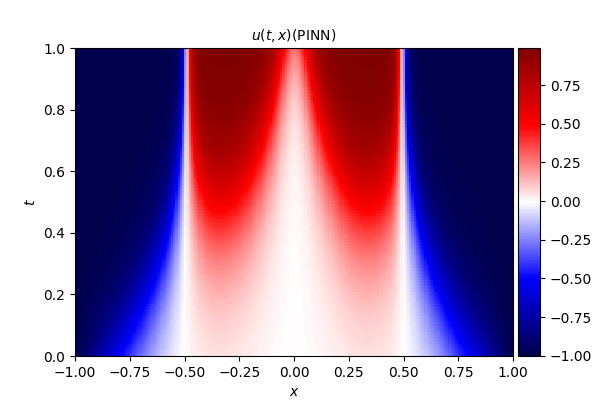
- 精确解
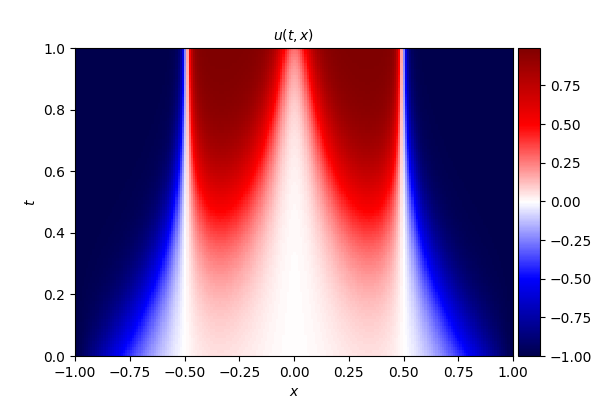
- 误差分布
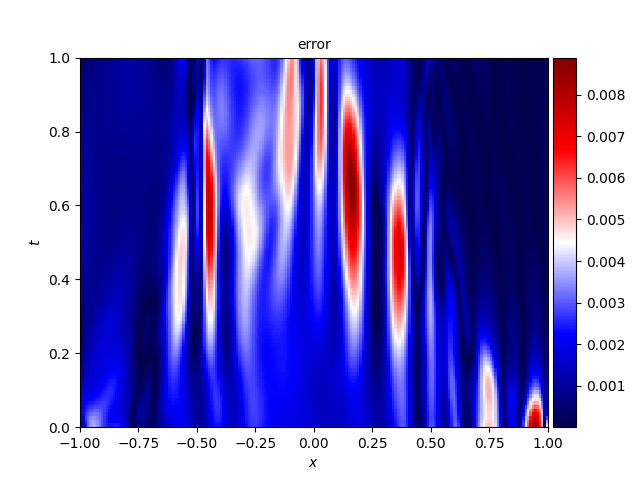
二、反问题
1. Burgers' equation
Burgers 方程的数学定义为:
∂ u ∂ t + u ∂ u ∂ x = v ∂ 2 u ∂ x 2 , x ∈ − 1 , 1 , t ∈ 0 , 1 , u ( x , 0 ) = − sin ( π x ) , u ( − 1 , t ) = u ( 1 , t ) = 0 , \begin{array}{l} \frac{\partial u}{\partial t}+u \frac{\partial u}{\partial x}=v \frac{\partial^{2} u}{\partial x^{2}}, \quad x \in-1,1, t \in0,1, \\6pt u(x, 0)=-\sin (\pi x), \\6pt u(-1, t)=u(1, t)=0, \end{array} ∂t∂u+u∂x∂u=v∂x2∂2u,x∈−1,1,t∈0,1,u(x,0)=−sin(πx),u(−1,t)=u(1,t)=0,
式中, u u u 为流体流速, ν ν ν 为流体的运动粘度系数(真实值为 ν = 0.01 / π ν = 0.01/\pi ν=0.01/π)。
本算例中假设粘度系数 v v v 为未知参数,求解目标为同时得到方程的数值解与参数 v v v 的估计值。

- 参数 v v v 的 L 2 L_2 L2 相对误差随迭代次数的变化曲线
- PINN 数值解
- 精确解
- 误差分布
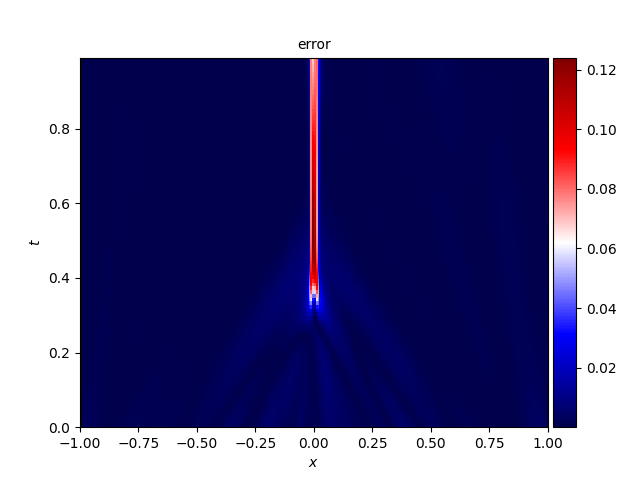
三、代码目录
本文所有代码及图片资源可通过作者的工坊获取。
作者推介
代码获取:可通过作者的工坊获取完整代码。
配套视频:可在 b 站观看相关讲解视频。
上一合辑
- 偏微分方程 | PINN(1)-CSDN博客
https://blog.csdn.net/u013669912/article/details/159172646
reference
- PINN 解偏微分方程实例 1-CSDN 博客
https://blog.csdn.net/qq_49323609/article/details/129327571 - PINN 解偏微分方程实例 2(一维非线性薛定谔方程)_薛定谔方程 pinn-CSDN 博客
https://blog.csdn.net/qq_49323609/article/details/129468890 - PINN 解偏微分方程实例 3(Allen-Cahn 方程)-CSDN 博客
https://blog.csdn.net/qq_49323609/article/details/129518537 - PINN 解偏微分方程实例 4--Diffusion,Burgers,Allen--Cahn 和 Wave 方程和反问题代码_pinn 求解偏微分方程代码-CSDN 博客
https://blog.csdn.net/qq_49323609/article/details/139906996 - PINN 解偏微分方程实例 5--Diffusion,Burgers,Allen--Cahn 方程和反问题_allen-cahn equation-CSDN 博客
https://blog.csdn.net/qq_49323609/article/details/140388725 - 1 Physics-informed machine learning J. Nature Reviews Physics, 2021, 3(6): 422-440. https://www.nature.com/articles/s42254-021-00314-5
- 2 知乎-PaperWeekly. 物理信息神经网络 (PINN) 详解 EB/OL. https://zhuanlan.zhihu.com/p/468748367