引言
在 RAG 中,结果质量取决于嵌入(embeddings) 。嵌入是内容的数学表示,它能够在高维向量空间中捕捉语义、上下文以及关系。当文档被转换为嵌入之后,它们就不再只是字符串,而是变成了空间中的点,在这个空间里,点与点之间的距离代表相似性。
如果没有嵌入,检索系统就像一座没有目录的图书馆:内容丰富,却难以高效导航。而有了高质量的嵌入,系统就能够基于提示生成有意义的响应。
在 RAG 系统中,嵌入充当着知识库与语言模型之间的连接器。无论原始文本写得多好,在被编码为能表达语义的数值向量之前,它对于检索系统而言都没有意义。嵌入使得系统能够基于"意义"而非精确关键词匹配来存储、比较和检索信息。
你选择如何生成、存储和查询嵌入,将显著影响 RAG 流水线的准确性、速度和成本。一个设计不佳的嵌入策略可能导致查询缓慢、结果无关,或者带来不必要的计算开销;相反,一个经过良好优化的策略,即便面对大量数据,也能提供几乎即时、且上下文准确的响应。
结构
本章将涵盖以下主题:
- 软件要求
- 将文本转换为嵌入
- 将一组文档嵌入为向量
- 使用 FAISS 的嵌入
- 适用于离线使用的嵌入模型
- 在 LangChain 中自定义嵌入函数
- 高效地批量嵌入大型文档
- 只嵌入一次并持久化存储
- 结合嵌入与元数据以获得更好的过滤效果
- 仅嵌入摘要
- 通过预归一化实现抗噪嵌入
- 嵌入块图(embedding chunk graphs)
学习目标
到本章结束时,读者将全面理解嵌入如何在 RAG 系统中支撑语义搜索与检索。本章旨在解释嵌入表示背后的原理,并讨论一些关键因素,例如维度、训练数据和领域适配。读者将学习如何为自己的场景选择、生成和微调嵌入,以及如何评估嵌入质量对检索性能的影响。完成本章后,读者应能够设计出在真实应用中最大化检索准确率、可扩展性和鲁棒性的嵌入策略。
软件要求
本书中的每个概念后面都会配有相应的 recipe,也就是用 Python 编写的可运行代码。你会在所有 recipe 中看到代码注释,这些注释将逐行解释每一行代码的作用。
运行这些 recipe 需要以下软件环境:
- 系统配置:至少 16.0 GB 内存的系统
- 操作系统:Windows
- Python:Python 3.13.3 或更高版本
- LangChain:1.0.5
- LLM 模型 :Ollama 的
llama3.2:3b - 程序输入文件:程序中使用的输入文件可在本书的 Git 仓库中获取
要运行程序,请执行 Python 命令 pip install <packages name> 安装 recipe 中提到的依赖包。安装完成后,在你的开发环境中运行 recipe 中提到的 Python 脚本(.py 文件)即可。
图 4.1 展示了嵌入策略:
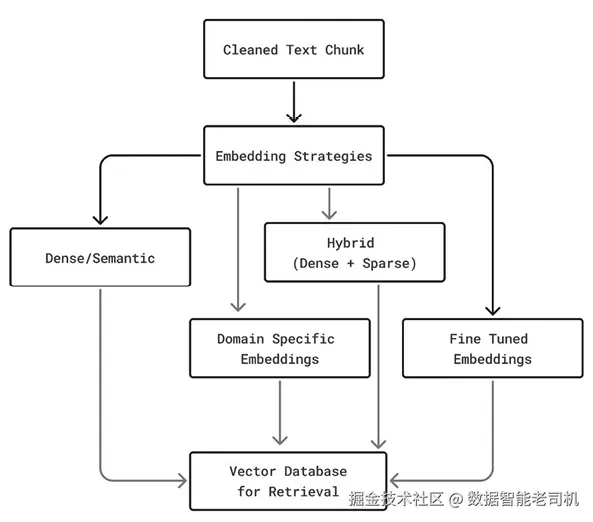
图 4.1:嵌入策略
将文本转换为嵌入
将文本转换为嵌入,是指把文本转化为大语言模型能够理解和处理的高维向量(数字列表)的过程。
其过程如下:
- 将来自不同来源的文本输入到预训练嵌入模型中;
- 模型使用神经网络对文本进行处理;
- 嵌入模型生成一个向量(即数字列表),用于捕捉输入文本的上下文、语气和语义含义;
- 这些向量随后被存储,并用于检索、搜索和分类。
Recipe 41
本 recipe 演示如何将文本转换为嵌入:
初始化嵌入模型。这里使用的是 all-MiniLM-L6-v2,这是一个轻量级模型,适合生成嵌入。
定义要转换为嵌入的文本。这段文本将被转换为向量表示。
为该文本生成嵌入向量。embed_query 方法会将文本转换为数值向量。
打印生成的嵌入向量。嵌入是一个浮点数列表,用于在高维空间中表示文本。
安装所需依赖:
pip install langchain sentence-transformersconvert_text_to_embeddings.py
请参考以下代码:
python
# convert_text_to_embeddings.py
# This code demonstrates how to convert text into embeddings using the
# HuggingFaceEmbeddings class from LangChain.
# It initializes the embedding model, provides a sample text, and
# generates the corresponding embedding vector.
from langchain_huggingface import HuggingFaceEmbeddings
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Initialize the embedding model
# The model 'all-MiniLM-L6-v2' is a lightweight model suitable for generating embeddings.
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 2. Define the text to be converted into embeddings
# This text will be transformed into a vector representation.
text = "Retrieval-Augmented Generation is a powerful technique for combining retrieval with language models."
# 3. Generate the embedding vector for the text
# The embed_query method converts the text into a numerical vector.
embedding = embedding_model.embed_query(text)
# 4. Print the resulting embedding vector
# The embedding is a list of floating-point numbers representing the text in a high-dimensional space.
print(f"Embedding dimension: {len(embedding)}")
print(f"First 10 values of the embedding:\n{embedding[:10]}")输出:
sql
Embedding dimension: 384
First 10 values of the embedding:
[-0.04551849886775017, -0.04808536171913147, -0.008631237782537937, 0.07327593117952347, -0.024926472455263138, 0.13953249156475067, 0.035609278827905655, -0.01994621567428112, 0.02263304404914379, -0.07439490407705307]将一组文档嵌入为向量
这个过程是指将一组文本文档转换为数值向量表示(即嵌入),这些向量能够捕捉文档的语义含义。每篇文档,无论其长度或结构如何,都会通过一个嵌入模型处理,并映射到高维空间中。
Recipe 42
本 recipe 演示如何将一组文档嵌入为向量:
加载预训练模型和 tokenizer。这里使用的 sentence-transformers/all-MiniLM-L6-v2 适合生成嵌入。你也可以替换为 Hugging Face 上的其他模型。
定义一个待嵌入的文档列表。每个文档都是一段将被转换为向量表示的字符串。
对文档进行分词。tokenizer 会将文档列表转换为模型可处理的格式。
嵌入这些文档。
为文档列表生成嵌入。通过对文档列表调用 embed_documents 函数来获得嵌入结果。
打印生成的嵌入。每个嵌入都是对应文档的向量表示。
安装所需依赖:
pip install transformers torchembed_list_of_documents.py
请参考以下代码:
ini
# embed_list_of_documents.py
# This code demonstrates how to embed a list of documents using the
# HuggingFace Transformers library.
from transformers import AutoTokenizer, AutoModel
import torch
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Load the pre-trained model and tokenizer
# The model 'sentence-transformers/all-MiniLM-L6-v2' is suitable for generating embeddings.
# You can replace it with any other model available in HuggingFace.
model_name = "sentence-transformers/all-MiniLM-L6-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# 2. Define a list of documents to be embedded
# Each document is a string that will be transformed into a vector
# representation.
documents = [
"RAG is a powerful technique for combining retrieval with language models.",
"Document embeddings enable efficient semantic search.",
"Transformers provide contextualized token representations."
]
# 3. Tokenize the documents
# The tokenizer converts the list of documents into a format
# suitable for the model.
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size())
return (token_embeddings * input_mask_expanded).sum(1) / input_mask_expanded.sum(1)
# 4. Embed the documents
def embed_documents(docs):
encoded = tokenizer(docs, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
output = model(**encoded)
return mean_pooling(output, encoded['attention_mask'])
# 5. Generate embeddings for the list of documents
# The embed_documents function is called with the list of documents to
# get their embeddings.
embeddings = embed_documents(documents)
# 6. Print the resulting embeddings
# Each embedding is a vector representation of the corresponding
# document.
for i, vec in enumerate(embeddings):
print(f"Document {i+1} vector (first 5 dims): {vec[:5]}")输出:
scss
Document 1 vector (first 5 dims): tensor([-0.2326, 0.1575, 0.2014, -0.0072, -0.3706])
Document 2 vector (first 5 dims): tensor([-0.0191, 0.0753, 0.1106, 0.3735, 0.2065])
Document 3 vector (first 5 dims): tensor([-0.6854, 0.1885, 0.0701, -0.0921, 0.0231])使用 FAISS 的嵌入
FAISS(Facebook AI Similarity Search)是 Meta AI 开发的一款高性能库,用于对稠密向量进行高效相似度搜索和聚类。在 RAG 流水线中,FAISS 在存储和检索文档嵌入以实现语义搜索方面发挥着关键作用。
整个工作流从生成嵌入开始,即利用某个嵌入模型(如 OpenAI 的 text-embedding 模型、Hugging Face Transformers 或 SentenceTransformers)将文本转换为向量表示。随后,这些嵌入会被存储到 FAISS 索引中,而该索引针对高维空间中的近邻搜索进行了优化。
当用户发出查询时,查询文本也会被嵌入为向量,随后 FAISS 会在其索引中搜索与该查询向量语义最接近的文档向量。
通过基于"意义"而非关键词匹配来检索最相关的文档,FAISS 能够为大型知识库提供高精度的上下文检索能力。
Recipe 43
本 recipe 演示如何编写一个使用 FAISS 进行嵌入的程序:
加载预训练模型。这里使用的 all-MiniLM-L6-v2 适合生成嵌入。
定义一个待嵌入的文档列表。每个文档都是一个将被转换为向量表示的字符串。
对文档进行嵌入。model.encode 方法会为文档列表生成嵌入。
创建一个 FAISS 索引。该索引将存储嵌入,并支持高效相似度搜索。
将嵌入添加到 FAISS 索引中,以便后续检索。
定义一个查询示例,用于搜索 FAISS 索引。
搜索索引。search 方法会为查询向量返回 k 个最近邻。
打印结果。结果将展示与查询最相似的文档及其距离值。
安装所需依赖:
pip install sentence-transformers faiss-cpugenerate_store_embeddings_using_faiss.py
请参考以下代码:
ini
# generate_store_embeddings_using_faiss.py
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Load the pre-trained model
# The model 'all-MiniLM-L6-v2' is suitable for generating embeddings.
model = SentenceTransformer("all-MiniLM-L6-v2")
# 2. Define a list of documents to be embedded
# Each document is a string that will be transformed into a vector
# representation.
documents = [
"RAG combines retrieval with generative models.",
"FAISS enables fast similarity search.",
"Embedding turns text into numeric vectors.",
"Transformers are powerful for NLP tasks."
]
# 3. Embed the documents
# The model.encode method generates embeddings for the list of
# documents.
embeddings = model.encode(documents, convert_to_numpy=True)
# 4. Create a FAISS index
# The index will store the embeddings and allow for efficient
# similarity search.
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
# 5. Add embeddings to the FAISS index
# The embeddings are added to the index for later retrieval.
index.add(embeddings)
# 6. Example query to search the FAISS index
query = "How to search a vector embeddings?"
query_vector = model.encode([query])
k = 2 # top-k matches
# 7. Search the index
# The search method retrieves the k nearest neighbors for the query
# vector.
distances, indices = index.search(query_vector, k)
# 8. Print the results
# The results show the documents that are most similar to the query
# along with their distances.
print(f"\nQuery: {query}")
for i, idx in enumerate(indices[0]):
print(f"Match {i+1}: '{documents[idx]}' (distance: {distances[0][i]:.4f})")输出:
vbnet
Query: How to search a vector embeddings?
Match 1: 'Embedding turns text into numeric vectors.' (distance: 1.0279)
Match 2: 'FAISS enables fast similarity search.' (distance: 1.3194)适用于离线使用的嵌入模型
适用于离线使用的嵌入模型,使 RAG 系统能够在无需持续联网或依赖云端 API 的情况下生成文本的向量表示。这种方式对于涉及敏感数据、受限网络环境或成本优化的场景尤为重要。
离线嵌入通常通过下载并在本地运行预训练模型来实现,常用框架包括 Hugging Face Transformers 或 SentenceTransformers。这些模型可以直接在本地硬件上处理文本,从而确保数据隐私和合规性。一旦模型被加载,就可以用来为文档、查询或摘要生成稠密向量,并将其存储到本地向量数据库(如 FAISS 或 ChromaDB)中。
离线运行嵌入不仅可以降低延迟,还能让开发者完全掌控模型版本、自定义方式以及微调策略。这使得离线嵌入成为构建自包含、安全且高性能 RAG 流水线的有力选择。
Recipe 44
本 recipe 演示如何编写一个使用离线嵌入模型的程序:
加载一个可离线运行的预训练 SentenceTransformer 模型。这个轻量级开源模型(all-MiniLM-L6-v2)可在本地运行,在速度与准确率之间取得良好平衡。
加载一个预训练的 SentenceTransformer 模型。你可以根据自己的需求(速度、大小、准确率)选择模型。
准备一些示例文本以生成嵌入。
为示例文本生成嵌入。model.encode 方法会处理这些文本并返回其嵌入。
打印生成的嵌入。
安装所需依赖:
pip install sentence-transformersembeddings_offline_using_sentencetransformers.py
请参考以下代码:
python
# embeddings_offline_using_sentencetransformers.py
# This script demonstrates how to use the SentenceTransformers
# library to generate text embeddings offline.
from sentence_transformers import SentenceTransformer
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Load an offline, pre-trained SentenceTransformer model
# This lightweight open-source model ("all-MiniLM-L6-v2") runs locally,
# offering a good balance between speed and accuracy
model = SentenceTransformer("all-MiniLM-L6-v2")
# 2. Sample texts to generate embeddings
texts = [
"LangChain enables RAG pipelines.",
"Embedding converts text into vectors.",
"You can run models offline with SentenceTransformers."
]
# 3. Generate embeddings for sample texts
# The model.encode method processes the texts and returns their
# embeddings
embeddings = model.encode(texts)
# 4. Print the generated embeddings
for i, emb in enumerate(embeddings):
print(f"\nText {i+1}: {texts[i]}")
print(f"Embedding shape: {emb.shape}")
print(f"First 5 dimensions: {emb[:5]}")输出:
yaml
Text 1: LangChain enables RAG pipelines.
Embedding shape: (384,)
First 5 dimensions: [-0.10397299 0.04662139 0.06613942 -0.043853 -0.11685354]
Text 2: Embedding converts text into vectors.
Embedding shape: (384,)
First 5 dimensions: [ 0.01791174 -0.00639516 0.00353186 -0.00265993 0.06178101]
Text 3: You can run models offline with SentenceTransformers.
Embedding shape: (384,)
First 5 dimensions: [-0.03651717 -0.10334706 -0.05222886 0.02248381 0.01239715]在 LangChain 中自定义嵌入函数
在 LangChain 中自定义嵌入函数,可以让开发者按照特定领域数据、性能需求或基础设施约束,定制文本转向量表示的方式。默认情况下,LangChain 集成了 OpenAI、Hugging Face 和 SentenceTransformers 等常见嵌入提供方,但开发者也可以用自己的嵌入逻辑来覆盖默认实现。
这种自定义可以包括:切换为首选模型、应用诸如 token 规范化或停用词移除等预处理步骤、为提升效率而对大型数据集进行批处理,甚至引入多模态嵌入以同时处理文本和图像。实际使用中,你可以定义一个自定义类或函数,实现 LangChain 的嵌入接口,以确保与 FAISS 或 Chroma 之类的向量存储兼容。
通过自定义嵌入函数,RAG 流水线在准确率、速度、隐私和成本之间可以获得更大的灵活性,从而能够集成专有模型、针对特定语言进行优化,并适应多样化的检索场景。这种方式对于法律、医疗或金融等专业领域尤其有价值,因为通用嵌入往往难以满足需求。
Recipe 45
本 recipe 演示如何编写一个在 LangChain 中自定义嵌入函数的程序:
创建一个使用 Sentence Transformers 的自定义嵌入类。该类实现了 LangChain 的 embeddings 接口。
定义一个待嵌入的文档列表。每个文档都是一个将被转换为向量表示的字符串。
创建自定义嵌入函数的实例。这会初始化 SentenceTransformer 模型以生成嵌入。
使用自定义嵌入函数创建一个 FAISS 向量存储。该向量存储将基于嵌入执行高效相似度搜索。
定义一个查询示例,用于搜索向量存储。该查询会基于嵌入找到与输入文本相似的文档。
打印结果。结果会展示与查询最相似的文档。
安装所需依赖:
pip install langchain sentence-transformers faiss-cpucustom_embedding_function_using_sentencetransformers.py
请参考以下代码:
python
# custom_embedding_function_using_sentencetransformers.py
# This code demonstrates how to create a custom embedding function
# using the Sentence Transformers library.
from langchain.embeddings.base import Embeddings
from typing import List
from sentence_transformers import SentenceTransformer
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Custom embedding class that uses Sentence Transformers
# This class implements the LangChain Embeddings interface.
class CustomSentenceTransformerEmbedding(Embeddings):
def __init__(self, model_name: str = "all-MiniLM-L6-v2"):
self.model = SentenceTransformer(model_name)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return self.model.encode(texts).tolist()
def embed_query(self, text: str) -> List[float]:
return self.model.encode([text])[0].tolist()
# 3. Define a list of documents to be embedded
# Each document is a string that will be transformed into a vector
# representation.
docs = [
Document(page_content="LangChain is powerful for building RAG."),
Document(page_content="Embeddings turn text into vectors."),
]
# 4. Create an instance of the custom embedding function
# This initializes the SentenceTransformer model for generating
# embeddings.
embedding_fn = CustomSentenceTransformerEmbedding()
# 5. Create a FAISS vector store using the custom embedding function
# The vector store will use the embeddings to allow for efficient
# similarity search.
vector_store = FAISS.from_documents(docs, embedding=embedding_fn)
# 6. Example query to search the vector store
# This query will find documents similar to the input text based on their
# embeddings.
query = "What is LangChain used for?"
results = vector_store.similarity_search(query, k=1)
# 7. Print the results
# The results show the documents that are most similar to the query.
for res in results:
print("Query:", query)
print("Match:", res.page_content)输出:
vbnet
Query: What is LangChain used for?
Match: LangChain is powerful for building RAG.高效地批量嵌入大型文档
对大型文档进行批量嵌入,是构建可扩展且高性能 RAG 系统的关键步骤。与逐个嵌入文档相比,批处理会将多个文本片段组合起来,同时转换为向量表示,从而显著减少处理时间和资源消耗。
这种方式利用了现代嵌入模型的并行处理能力,并能有效帮助管理 API 速率限制、减少网络开销、降低使用付费嵌入服务时的成本。
在实践中,大型文档通常会先被切分为更小且在语义上有意义的 chunk,以确保嵌入能够捕捉相关上下文。随后,这些 chunk 会以批次形式进行处理,并将结果存储到 FAISS 或 Chroma 等向量数据库中,以支持快速检索。
通过批量嵌入,开发者可以处理从 GB 到 TB 级别的大规模数据,而不会压垮系统资源,从而确保 RAG 流水线既具响应性又具成本效益。这种方法在实时摄取流水线、大型企业文档库或频繁内容更新场景中特别有价值。
Recipe 46
本 recipe 演示如何编写一个用于批量嵌入大型文档的程序:
定义嵌入模型。这里我们使用 SentenceTransformer 来进行批处理。
创建一个大型文档。通过重复较短文本来模拟大型文档。
将大型文档切分为可管理的 chunk。RecursiveCharacterTextSplitter 确保文档被拆分成带重叠的小块,足够小以便嵌入模型高效处理。
使用 FAISS 创建带批量嵌入的向量存储,以支持高效相似度搜索。
执行相似度搜索。在向量存储中搜索某个特定查询。
安装所需依赖:
pip install langchain sentence-transformers faiss-cpu tqdmbatch_embedding_large_documents.py
请参考以下代码:
python
# batch_embedding_large_documents.py
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.embeddings.base import Embeddings
from langchain_core.documents import Document
from sentence_transformers import SentenceTransformer
from langchain_community.vectorstores import FAISS
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Define the embedding model
# Using SentenceTransformer for batch processing
class BatchedSentenceTransformerEmbedding(Embeddings):
def __init__(self, model_name: str = "all-MiniLM-L6-v2", batch_size: int = 32):
self.model = SentenceTransformer(model_name)
self.batch_size = batch_size
def embed_documents(self, texts):
embeddings = []
for i in tqdm(range(0, len(texts), self.batch_size), desc="Embedding Batches"):
batch = texts[i: i + self.batch_size]
batch_embeddings = self.model.encode(batch)
embeddings.extend(batch_embeddings)
return embeddings
def embed_query(self, text):
return self.model.encode([text])[0]
# 2. Create a large document
# Simulating a large document by repeating a smaller text
large_text = "LangChain is powerful.\n" * 50 # Simulate repetition
# 3. Split the large document into manageable chunks
# RecursiveCharacterTextSplitter ensures that the document is broken
# into overlapping chunks small enough for the embedding model to handle efficiently.
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=50)
chunks = splitter.split_text(large_text)
documents = [Document(page_content=chunk) for chunk in chunks]
# 4. Create the vector store with batched embeddings
# Using FAISS for efficient similarity search
embedding_model = BatchedSentenceTransformerEmbedding()
vectorstore = FAISS.from_documents(documents, embedding=embedding_model)
# 5. Perform a similarity search
# Searching for a specific query in the vector store
results = vectorstore.similarity_search("What is LangChain?", k=1)
print("\nBest Match:", results[0].page_content)输出:
dart
Best Match: LangChain is powerful.
LangChain is powerful.
LangChain is powerful.
LangChain is powerful.
LangChain is powerful.
LangChain is powerful.
LangChain is powerful.
LangChain is powerful.只嵌入一次并持久化存储
在构建 RAG 流水线时,最有效的实践之一就是:文档只嵌入一次,并将这些嵌入持久化存储。嵌入模型通常计算开销较大,尤其是在处理大规模数据时,反复为相同数据生成嵌入会同时浪费时间和资源。
在这一过程中,文档在完成处理(切分、规范化并转换为向量)之后,生成的嵌入会被存储到持久化向量数据库中,例如 FAISS 或 Chroma。这些向量存储会同时保存数值嵌入及其关联元数据,使未来查询可以在无需重新计算的前提下被即时响应。
这种方式不仅降低延迟,也能在使用付费嵌入 API 时减少成本。它确保只有在文档被新增、删除或修改时,向量存储才需要更新,而不是在每次搜索时都重复生成嵌入。
通过只嵌入一次并将向量持久化,开发者能够为可扩展且可靠的语义搜索打下基础,从而使 RAG 系统能够在不进行冗余处理的情况下处理大规模且不断演化的数据集。
Recipe 47
本 recipe 演示如何编写一个"只嵌入一次并持久化存储"的程序。以下是用于存储嵌入的程序:
创建一个大型文档并将其切分为多个 chunk。这里通过重复一句话来模拟大型文档。
将大型文本切分为更小的块以进行嵌入。这是必要的,因为大型文档可能超过嵌入模型可处理的大小。
初始化嵌入模型。这里使用 HuggingFaceEmbeddings 类为文本块生成嵌入。
从嵌入后的文档创建一个 FAISS 向量存储。FAISS 向量存储支持跨文档嵌入的快速相似度搜索。
将 FAISS 索引保存到磁盘。这样后续可以直接复用,而无需重新计算嵌入。
从文档创建一个 FAISS 向量存储。该向量存储将允许基于嵌入进行高效相似度搜索。将其保存到磁盘后,后续便无需重新计算嵌入。
安装所需依赖:
pip install langchain faiss-cpu sentence-transformersembed_and_save.py
请参考以下代码:
ini
# embed_and_save.py
# This script demonstrates how to create embeddings for a large
# document,
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
from langchain_community.vectorstores import FAISS
import os
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Create a large document and split it into chunks
# This simulates a large document by repeating a phrase
# multiple times.
large_text = "Generative models laid the foundation for today's LLMs.\n" * 2
# 2. Split the large text into smaller chunks for embedding
# This is necessary because large documents can be too big for
# embedding models.
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=50)
chunks = splitter.split_text(large_text)
documents = [Document(page_content=chunk) for chunk in chunks]
# 3. Initialize the embedding model
# This uses the HuggingFaceEmbeddings class to create embeddings for
# the text chunks.
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 4. Create a FAISS vector store from the embedded documents
# The FAISS vector store enables fast similarity search across document
# embeddings
vectorstore = FAISS.from_documents(documents, embedding=embedding_model)
# 5. Save the FAISS index to disk
# This allows reusing the stored embeddings later without recomputation.
faiss_index_path = "embed_faiss_index"
vectorstore.save_local(faiss_index_path)
print("Embeddings created and saved to disk.")输出:
css
Embeddings created and saved to disk.以下是使用前述程序所保存嵌入的程序:
初始化嵌入模型。这里使用与上一个脚本相同的嵌入模型,以确保兼容性。
从保存路径中加载 FAISS 索引。这假设索引已在前一步中保存完成。
执行相似度搜索。该查询会基于嵌入找到与输入文本相似的文档。
请参考以下代码:
load_and_search.py
ini
# load_and_search.py
# This script demonstrates how to load a saved FAISS index and
# perform a similarity search.
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Initialize the embedding model
# This uses the same embedding model as in the previous script
# to ensure compatibility.
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 2. Load the FAISS index from the saved path
# This assumes the index was saved in the previous step.
faiss_index_path = "embed_faiss_index"
vectorstore = FAISS.load_local(faiss_index_path, embedding_model, allow_dangerous_deserialization=True)
# 3. Perform a similarity search
# This query will find documents similar to the input text
# based on their embeddings.
results = vectorstore.similarity_search("What does Generative models do?", k=1)
print("\nBest Match:", results[0].page_content)输出:
rust
Best Match: Generative models laid the foundation for today's LLMs.
Generative models laid the foundation for today's LLMs.结合嵌入与元数据以获得更好的过滤效果
在 RAG 流水线中,嵌入负责捕捉文本的语义含义,但仅靠嵌入本身可能还不足以提供精确结果,尤其是在用户需要特定上下文答案时。通过将嵌入与元数据结合,我们可以同时借助语义相似度与结构化过滤来提升检索准确率。
元数据是与每个文档或 chunk 关联的结构化属性,例如作者姓名、发布日期、类别、标签或来源类型。嵌入帮助我们找到"相关内容",而元数据则使我们能够根据精确条件进一步过滤结果。
包括 FAISS 或 Chroma 在内的大多数向量存储,都支持将元数据与嵌入一同存储。这样,开发者就可以执行结合语义搜索与精确过滤优势的混合查询。
通过将基于嵌入的相似度搜索与元数据约束结合起来,RAG 应用能够交付更相关、更贴近领域需求的结果,使检索过程既智能又具备上下文感知能力。
Recipe 48
本 recipe 演示如何编写一个结合嵌入与元数据过滤的程序:
创建带有元数据的文档。这些文档将用于展示在 FAISS 向量存储中进行元数据过滤。
初始化嵌入模型。这里使用 HuggingFaceEmbeddings 类为文本块创建嵌入。
从文档创建 FAISS 向量存储。该向量存储允许在嵌入文档上执行高效相似度搜索。
运行一次相似度搜索,以获取与查询最相似的 top-k chunk。
在带有元数据过滤的条件下查询向量存储。该查询会基于嵌入找到与输入文本相似的文档,并结合元数据进行过滤。
打印带元数据的结果。这将同时展示文档内容及其元数据。
安装所需依赖:
pip install langchain faiss-cpu sentence-transformersembeddings_with_metadata_filtering.py
请参考以下代码:
ini
# embeddings_with_metadata_filtering.py
# This script demonstrates how to create embeddings with metadata
# filtering using FAISS.
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Create documents with metadata
# These documents will be used to demonstrate metadata filtering
# in the FAISS vector store.
docs = [
Document(page_content="LangChain enables LLM applications.", metadata={"source": "docs/langchain.md", "topic": "LangChain"}),
Document(page_content="Hugging Face provides transformer models.", metadata={"source": "docs/huggingface.md", "topic": "Transformers"}),
Document(page_content="OpenAI offers GPT models for developers.", metadata={"source": "docs/openai.md", "topic": "OpenAI"}),
]
# 2. Initialize the embedding model
# This uses the HuggingFaceEmbeddings class to create embeddings for
# the text chunks.
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 3. Create a FAISS vector store from the documents
# The FAISS vector store will allow for efficient similarity
# search on the embedded documents.
vectorstore = FAISS.from_documents(docs, embedding=embedding_model)
# 4. Run a similarity search to retrieve the top-k most similar chunks
# for the query.
query = "How to use transformer models?"
results = vectorstore.similarity_search(query, k=2)
# 5. Print the results with metadata
# This will display the content of the documents along with
# their metadata.
print("\n=== Semantic Search with Metadata ===")
for res in results:
print(f"- Content: {res.page_content}")
print(f" Metadata: {res.metadata}")输出:
css
=== Semantic Search with Metadata ===
- Content: Hugging Face provides transformer models.
Metadata: {'source': 'docs/huggingface.md', 'topic': 'Transformers'}
- Content: OpenAI offers GPT models for developers.
Metadata: {'source': 'docs/openai.md', 'topic': 'OpenAI'}仅嵌入摘要
在某些 RAG 工作流中,嵌入整篇文档可能效率不高,尤其当源文本很长、重复较多或包含无关部分时。更节省资源的做法是:先为每篇文档生成简洁摘要,再只把这些摘要嵌入到向量存储中。
这种策略减少了存储占用,并加快了检索速度,因为嵌入只表示最重要的信息。摘要可以通过基于 LLM 的摘要工具、抽取式算法或领域特定启发式方法生成。一旦这些摘要被嵌入,它们仍然保留了原始文档的核心语义,使检索步骤在避免无关噪声的同时仍能保持语义准确。
例如,与其嵌入一份完整的 50 页技术报告,我们可以只存储一段 500 词左右的摘要,以捕捉其核心发现。查询时,系统先检索相关摘要,然后在需要时再引用对应的完整原文进行展开。
只嵌入摘要这一策略在处理大型语料库、资源受限环境或高度冗余数据集时特别有用。它能让 RAG 流水线在不牺牲相关性的前提下,更快、更轻量、更具成本效益。
Recipe 49
本 recipe 演示如何编写一个"仅嵌入摘要"的程序:
定义若干篇长文档,并对其进行摘要。这些文档作为源文本,用于生成简洁摘要,之后这些摘要会被嵌入到 FAISS 向量存储中,以供语义搜索使用。
创建带有元数据的文档。这些文档将用于展示在 FAISS 向量存储中的元数据使用方式。
初始化摘要流水线。这里使用预训练模型为文档生成摘要。
为文档生成摘要。这将为每篇文档创建简洁摘要。
根据这些摘要创建一个 FAISS 向量存储。该向量存储将允许在嵌入后的摘要上执行高效相似度搜索。
在向量存储中执行语义搜索。该查询会基于嵌入找到与输入文本相似的文档。
打印带摘要的结果。
安装所需依赖:
pip install langchain faiss-cpu sentence-transformers transformers tqdm huggingface_hubembed_auto_summaries.py
请参考以下代码:
ini
# embed_auto_summaries.py
# This script demonstrates how to create embeddings with automatic
# summaries using FAISS.
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_huggingface import HuggingFaceEmbeddings
from transformers.pipelines import pipeline
from sentence_transformers import SentenceTransformer
from typing import List
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Define several long-form documents that will be summarized.
# These serve as source texts for generating concise summaries,
# which will later be embedded into a FAISS vector store for semantic search.
documents = [
Document(page_content="""
LangChain is an open-source framework that helps developers create
applications powered by large language models (LLMs).
It provides components and integrations to connect LLMs to external
data, manage memory, and create agents.
"""),
Document(page_content="""
FAISS (Facebook AI Similarity Search) is a library that enables fast
similarity search and clustering of dense vectors.
It's widely used in AI applications that need to search through
vectorized text or image data efficiently.
"""),
Document(page_content="""
Transformers are a type of deep learning model that revolutionized NLP.
Based on self-attention, they allow for parallel processing and improved performance
in text classification, translation, and more.
""")
]
# 2. Initialize the summarization pipeline
# This uses a pre-trained model to generate summaries of the documents.
summarizer = pipeline("summarization", model="sshleifer/distilbart-cnn-12-6")
# 3. Generate summaries for the documents
# This will create concise summaries for each document.
def generate_summaries(docs: List[Document]) -> List[str]:
summaries = []
for doc in docs:
summary = summarizer(doc.page_content, max_length=50, min_length=20, do_sample=False)[0]['summary_text']
summaries.append(summary)
return summaries
summaries = generate_summaries(documents)
# 4. Create a FAISS vector store from the summaries
# The FAISS vector store will allow for efficient similarity
# search on the embedded summaries.
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = FAISS.from_texts(texts=summaries, embedding=embedding_model, metadatas=[doc.metadata for doc in documents])
# 5. Perform semantic search on the vector store
# This query will find documents similar to the input text
# based on their embeddings.
query = "What are transformers used for?"
results = vectorstore.similarity_search(query, k=1)
# 6. Print the results with summaries
print("\nBest Match (from Summary):", results[0].page_content)输出:
sql
Best Match (from Summary): Transformers are a type of deep learning model that revolutionized NLP. They allow for parallel processing and improved performance in text classification, translation, and more.通过预归一化实现抗噪嵌入
在 RAG 系统中,嵌入是连接用户查询与相关文档块之间的桥梁。然而,真实世界数据往往并不干净:它可能包含拼写错误、大小写不一致、格式伪影,甚至来自传感器或 OCR 的噪声,这些都会削弱嵌入质量,进而降低检索准确率。
**预归一化(pre-normalization)**是一种在嵌入进入相似度搜索或下游流水线之前对其进行稳定化处理的技术。
在 RAG 流水线中,预归一化可以应用在多个层面,具体如下:
- 在编码器输出端实施,以确保所有嵌入在被存入向量数据库之前都具有统一的向量范数;
- 在查询侧实施,使用户查询的嵌入在进入 RAG 系统检索之前被归一化;
- 在模型层面实现,以生成更稳定的嵌入。
Recipe 50
本 recipe 演示如何编写一个通过预归一化实现抗噪嵌入的程序:
加载一个预训练 SentenceTransformer 模型。该模型用于为句子生成嵌入,并因其在性能与速度之间取得平衡而被选用。
定义一组带有噪声的句子(如标点、额外空格等)。这些句子将被用于生成嵌入。噪声包括标点变化、多余空格以及大小写差异。
定义一个归一化函数;该函数将嵌入归一化为单位长度。
为这些句子生成嵌入,模型会将其编码为稠密向量表示。
对嵌入进行归一化。这会将每个嵌入向量缩放到单位长度(L2 范数 = 1),从而确保向量幅值一致,并使相似度比较更加稳定。
打印归一化后的嵌入。
为了简洁起见,只展示每个归一化嵌入的前 5 个维度。
安装所需依赖:
pip install sentence-transformers numpynoiseresistantembeddings_with_prenormalization.py
请参考以下代码:
python
# noiseresistantembeddings_with_prenormalization.py
# This script demonstrates how to create noise-resistant embeddings using pre-normalization.
from sentence_transformers import SentenceTransformer
import numpy as np
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Load a pre-trained SentenceTransformer model
# This model is used to generate embeddings for sentences.
# The model is chosen for its balance between performance and speed.
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# 2. Define a set of sentences with noise (punctuation, extra spaces, etc.)
# These sentences will be used to generate embeddings.
# The noise includes punctuation variations, extra spaces, and
# capitalization differences.
sentences = [
"Retrieval Augmented Generation (RAG) is an architecture!",
"Retrieval Augmented Generation (RAG) is an architecture!!! ", # extra punctuation & spaces
"RETRIEVAL AUGMENTED GENERATION (RAG) IS AN ARCHITECTURE", # all caps
]
# 3. Define a normalization function
# This function normalizes the embeddings to unit length.
def normalize(vecs: np.ndarray) -> np.ndarray:
norms = np.linalg.norm(vecs, axis=1, keepdims=True)
return vecs / norms
# 4. Generate embeddings for the sentences
# The model encodes the sentences into dense vector representations.
embeddings = model.encode(sentences)
# 5. Normalize the embeddings
# This scales each embedding vector to unit length (L2 norm = 1),
# ensuring consistent magnitude and stable similarity comparisons
normalized_embeddings = normalize(embeddings)
# 6. Print the normalized embeddings
# Displaying the first 5 dimensions of each normalized embedding for
# brevity
for i, vec in enumerate(normalized_embeddings):
print(f"Sentence {i+1} (norm={np.linalg.norm(vec):.2f}):")
print(vec[:5], "...") # first 5 dims
print()输出:
ini
Sentence 1 (norm=1.00):
[-0.11171343 0.01787068 -0.02697249 0.0171152 -0.0706844 ] ...
Sentence 2 (norm=1.00):
[-0.11091074 0.01590041 -0.02369356 0.002776 -0.07597825] ...
Sentence 3 (norm=1.00):
[-0.11298969 0.01687417 -0.04100865 0.02022843 -0.07349404] ...嵌入块图
嵌入块图(embedding chunk graphs)是一种高级技术,它将文档片段(chunks)表示为图结构中的相互连接节点,然后生成嵌入,使其不仅捕捉每个 chunk 的局部语义,也能反映 chunk 之间的关系。这种方法同时保留语义相似性与文档上下文流,从而使检索系统能够回答那些需要多跳推理或上下文关联的问题。
本 recipe 首先使用 SentenceTransformer 为每个 chunk 独立生成嵌入,然后根据余弦相似度阈值,把相似 chunk 连接起来构建成图。图中的节点代表 chunk,边代表这些独立嵌入之间的语义相似性。这个图对于探索性任务很有用,例如查找相关 chunk、分析连通性或进行图遍历;但在本 recipe 中,chunk 本身的嵌入不会因为图结构而被修改。
并不是所有查询都需要使用最强大(也最昂贵)的嵌入模型。本 recipe 还展示了一种两阶段检索思路:首先用轻量级本地模型(如 all-MiniLM-L6-v2)快速检索候选文档;然后用更高质量的 API 型模型(如 OpenAI 或 Cohere embeddings)对前若干候选结果进行重排序,以提升准确率与相关性。
Recipe 51
本 recipe 演示如何编写一个实现嵌入块图的程序:
加载文本文档。
使用 RecursiveCharacterTextSplitter 将文本切分为多个 chunk,生成可管理的文本块。
加载一个预训练 SentenceTransformer 模型。该模型用于为文本块生成嵌入。
基于余弦相似度为文本块创建图。这里使用 NetworkX 创建一个图,其中节点代表 chunk,边代表相似度关系。
打印图中的边。展示相似度高于阈值的边。
打印各个 chunk。展示每个 chunk 的文本内容以供参考。
安装所需依赖:
pip install sentence-transformers networkx numpyembedding_chunk_graphs.py
请参考以下代码:
python
# embedding_chunk_graphs.py
# This script demonstrates how to create a graph of text chunks based
# on their embeddings.
from sentence_transformers import SentenceTransformer
from langchain_text_splitters import RecursiveCharacterTextSplitter
import numpy as np
import networkx as nx
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 1. Load text document
text = """
RAG (Retrieval-Augmented Generation) is a technique to improve LLM responses
by retrieving relevant context from a knowledge base.
It involves steps like loading documents, splitting them into chunks,
embedding,
and storing in a vector database.
Chunk embeddings help in semantic search.
You can also build a graph of chunks based on similarity,
which can be used to find related topics and context paths.
"""
# 2. Split text into chunks
# Using RecursiveCharacterTextSplitter to create manageable text chunks.
splitter = RecursiveCharacterTextSplitter(chunk_size=80, chunk_overlap=20)
chunks = splitter.split_text(text)
# 3. Load a pre-trained SentenceTransformer model
# This model is used to generate embeddings for the text chunks.
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(chunks)
# 4. Create a graph of text chunks based on cosine similarity
# Using NetworkX to create a graph where nodes are chunks and edges
# represent similarity.
def cosine_sim(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
threshold = 0.7 # similarity cutoff
G = nx.Graph()
for i, chunk in enumerate(chunks):
G.add_node(i, text=chunk)
for i in range(len(chunks)):
for j in range(i + 1, len(chunks)):
sim = cosine_sim(embeddings[i], embeddings[j])
if sim >= threshold:
G.add_edge(i, j, weight=sim)
# 5. Print the graph edges
# Displaying edges with similarity above the threshold.
print("Graph edges based on similarity >= 0.7:")
for u, v, data in G.edges(data=True):
print(f"Chunk {u} ↔ Chunk {v} | similarity: {data['weight']:.2f}")
# 6. Print the chunks
# Displaying the text of each chunk for reference.
print("\nChunks:")
for idx, c in enumerate(chunks):
print(f"{idx}: {c}")输出:
vbnet
Graph edges based on similarity >= 0.7:
Chunks:
0: RAG (Retrieval-Augmented Generation) is a technique to improve LLM responses
1: by retrieving relevant context from a knowledge base.
2: It involves steps like loading documents, splitting them into chunks,
3: them into chunks, embedding,
4: and storing in a vector database.
5: Chunk embeddings help in semantic search.
6: You can also build a graph of chunks based on similarity,
7: which can be used to find related topics and context paths.选择合适的嵌入策略,取决于你的数据类型、领域以及约束条件。下表提供了一个快速决策方式,帮助你判断哪种方法最适合你的场景:
| 场景 | 推荐策略 | 为什么有效 |
|---|---|---|
| 数据是通用文本(例如 FAQ、文章、商品描述) | 预训练通用嵌入 | 速度快、成本低,对于通用场景通常已经足够。 |
| 数据高度专业化(例如法律、医疗、金融) | 领域专用或微调后的嵌入 | 更能捕捉领域术语与语义差异。 |
| 预算有限或存在隐私约束 | 离线/本地模型(例如 all-MiniLM-L6-v2、bge-base) |
避免 API 成本与数据共享风险,同时仍能提供合理性能。 |
| 需要搜索或排序的最高准确率 | 混合或重排序流水线(例如 dense + sparse retrieval、bge-reranker) |
结合稠密嵌入的精度与关键词方法的召回率。 |
| 多模态数据(文本 + 图像/音频) | 多模态嵌入(例如 CLIP、BLIP 或 OpenAI 的多模态模型) | 支持跨模态搜索以及超越文本的上下文理解。 |
| 大规模或生产级 RAG 系统 | 高效模型 + FAISS/Chroma + 缓存 | 在规模化场景下平衡速度、成本与检索准确率。 |
表 4.1:多种策略对比
结论
在本章中,我们探讨了嵌入策略如何构成 RAG 系统中语义检索的基础。通过理解嵌入背后的原理、其维度、训练相关考量以及领域适配,我们明确了:精心选择的嵌入能够提升检索准确率、可扩展性和鲁棒性。
在建立了嵌入策略的坚实基础之后,下一步便是研究这些嵌入如何被存储、管理并高效查询。下一章《用于语义检索的向量存储》将聚焦于那些专门的数据库与索引技术,它们使得嵌入得以持久化,并让真实世界 RAG 应用中的快速、可扩展语义搜索成为可能。
如果你愿意,我可以继续把下一章 Vector Stores for Semantic Retrieval 也按同样风格给你精译出来。