接下来我要对Superstore Sales Dataset这一经典数据集进行数据分析
网址:https://www.kaggle.com/datasets/rohitsahoo/sales-forecasting/data
完整的数据分析工作流(7个阶段)
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 1. 业务理解 │ -> │ 2. 数据获取 │ -> │ 3. 数据清洗 │ -> │ 4. 探索性分析 │
│ (问对问题) │ │ (拿到数据) │ │ (准备数据) │ │ (EDA) │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
│
▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 7. 报告与呈现 │ <- │ 6. 提出建议 │ <- │ 5. 诊断分析 │ <- │ 4. 完成 │
│ (讲故事) │ │ (怎么办) │ │ (找原因) │ │ │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘每个阶段具体做什么
阶段1: 业务理解
- 目标:搞清楚为什么要分析、要解决什么问题。
- 你的思考:管理层想知道什么?是销售额为什么下降?还是哪个产品最好卖?还是哪些客户最值钱?
- 产出:清晰的分析目标和要回答的问题清单。
阶段2: 数据获取
- 目标:拿到需要的原始数据。
- 你的情况 :你已经有了
train.csv文件,这一步已经完成了。
阶段3: 数据清洗
- 目标:把脏数据变成干净、规范、可用的数据。
- 你的问题 :这一步就是你刚才问的那9个步骤。这是你目前所处的阶段。
阶段4: 探索性分析
- 目标 :快速了解数据的全貌,发现初步的规律和异常。这是你之前觉得"只是摆图表"的那个阶段。
- 具体操作 :
- 计算各种统计指标(总和、平均值、最大/最小值)。
- 制作各种基础图表(柱状图、折线图、饼图)。
- 做单维度的分析(比如只看每年的销售额)。
- 关键点 :这个阶段主要是描述性分析 ,回答"发生了什么?" 比如:2017年销售额最高,Technology品类最赚钱,西部地区业绩最好。
阶段5: 诊断分析
- 目标 :深入挖掘,找出数据背后隐藏的原因和关联。这是真正的分析深度所在。
- 具体操作 :
- 多维度交叉分析:比如把地区、品类、时间三个维度放在一起看。
- 对比分析:业绩好的地区和业绩差的地区到底差在哪里?
- 归因分析:销售额增长,主要是由客户数变多了,还是客户买得更贵了?
- 关键点 :这个阶段回答"为什么会发生?" 比如:Central地区业绩差,是因为它的Furniture品类销售额远低于其他地区。
阶段6: 提出建议
- 目标:基于诊断分析的结果,给出可执行的商业建议。
- 具体操作 :
- 把分析发现翻译成业务语言。
- 针对问题提出解决方案。
- 针对机会提出优化方向。
- 关键点 :这个阶段回答"应该怎么办?" 比如:建议供应链部门优化Central地区的家具物流成本,或者市场部在该地区做家具品类的促销活动。
阶段7: 报告与呈现
- 目标:把整个分析过程和结论清晰地呈现给老板或客户。
- 具体操作 :
- 制作仪表板(Dashboard),把最关键的信息放在一页上。
- 写分析报告,用故事线串联起你的发现。
- 用简洁的语言总结核心结论,而不是罗列所有数据。
数据清洗与准备的 9 个标准步骤
1. 数据预览与理解
- 目标:对数据集有一个整体印象。
- 具体操作 :
- 查看数据集有多少行、多少列。
- 浏览每列的数据内容,了解每一列代表什么含义(比如是日期、文本、数字还是代码)。
- 查看每列的数据类型(Excel中通常"常规"、"文本"、"日期"、"数字")。
- 观察数据是否有明显的异常(比如本该是数字的列出现了文字)。
2. 处理缺失值
- 目标:处理空白的单元格。
- 具体操作 :
- 识别:可以使用条件格式或筛选功能,找出所有为空的单元格。
- 决策与处理 (根据情况选择一种):
- 删除:如果某行或某列缺失的数据太多,或者缺失的数据对分析不重要,可以直接删除该行或列。
- 填充 :如果缺失少量数据,可以用合理的值填充。例如:
- 数值型数据:可以用平均值、中位数填充。
- 分类型数据:可以用众数(出现次数最多的值)填充,或者用"未知"填充。
- 保留:有些缺失值本身就有意义(比如"没有备注"),可以保留,但在分析时需要注意。
3. 处理重复值
- 目标:确保每一条记录都是唯一的(根据业务逻辑)。
- 具体操作 :
- 识别:使用Excel的"删除重复值"功能(数据选项卡 -> 删除重复项),或者使用条件格式高亮重复值。
- 注意 :在删除重复值之前,要确认这些行是真的重复(所有列都一样),还是只是某一列重复但其他列不同(例如同一个客户有多个订单,这是正常的)。永远不要盲目删除!
4. 数据类型转换
- 目标:确保每一列的数据类型正确,方便后续计算和分析。
- 具体操作 :
- 文本型数字转数值:如果数字单元格左上角有绿色小三角,说明它是文本格式。可以使用"分列"功能或乘1的方法将其转换为真正的数字。
- 文本型日期转日期 :如果日期列是文本(比如"2023/01/01"),需要使用
DATEVALUE函数或"分列"功能将其转换为Excel可识别的日期格式。 - 数值转文本:某些情况(如邮政编码、身份证号)需要保留为文本,避免前导0丢失。
5. 处理异常值
- 目标:发现并处理那些明显不合理的数据点。
- 具体操作 :
- 识别 :
- 逻辑判断:比如销售额为负数、年龄为200岁、下单日期晚于发货日期等,这些明显不符合逻辑。
- 统计方法:可以通过排序、筛选,或者用箱线图、标准差等方法找出极端值。
- 处理 :
- 核实:如果可能,回到数据源头确认是否录入错误。
- 删除:如果确认是错误且无法修正,可以删除该行。
- 修正:如果能找到正确值,就修正。
- 保留:有些极端值可能是真实的(比如大额订单),需要保留,但在分析时要考虑其影响。
- 识别 :
6. 数据格式统一
- 目标:让同一列的数据看起来一致,方便分组和透视。
- 具体操作 :
- 文本大小写统一:例如,将所有"consumer"、"Consumer"、"CONSUMER"统一为"Consumer"。
- 去除空格 :使用
TRIM函数去除单元格内容前后和中间多余的空格,避免因空格导致两个明明一样的内容被视为不同。 - 分类值统一:比如将"NY"和"New York"统一为"New York"。
7. 创建新特征
- 目标:从现有数据中衍生出对分析更有用的新列。
- 具体操作 :
- 拆分:从完整的地址中拆分出城市、街道;从日期中拆分出年份、月份、星期、季度。
- 合并:将姓和名合并成全名。
- 计算:计算两个日期之间的天数(如运送时长);计算折扣后的实际销售额(如果有折扣列的话)。
- 分类:根据数值范围创建等级(如根据销售额将客户分为高、中、低价值)。
8. 数据排序与筛选(可选但建议)
- 目标:对数据进行初步整理,方便后续操作。
- 具体操作 :
- 按某一列排序(如按日期排序),便于观察时间趋势。
- 使用筛选功能,临时排除一些不需要分析的数据(如测试数据)。
9. 保存清洗后的数据
- 目标:保留一份干净的数据副本,原始数据永远不动。
- 具体操作 :
- 在Excel中,将清洗好的数据另存为一个新文件,文件名可以加上"_cleaned"后缀。
- 或者,在同一工作簿中新建一个工作表,命名为"CleanData",将处理好的数据粘贴过去(选择性粘贴 -> 数值),避免公式链断裂。
初学者小贴士
- 永远不要直接在原始数据上修改! 复制一份到新的工作表再操作。
- 记录你的操作:在Excel的旁边新建一个"数据清洗日志"工作表,简单记下你做了哪些修改(比如"删除了5行销售额为负的异常数据"、"将日期列转换为日期格式")。这会让你的工作更专业,也方便以后复查。
- 一步一步来:不要想一口气完成所有步骤。按顺序操作,每完成一步,都可以保存一下。
什么是EDA(探索性数据分析)?
定义 :EDA是在对数据进行清洗之后、进行复杂建模或深入诊断之前,通过可视化图表 和基础统计指标,自由地探索数据、发现规律、提出假设的过程。
一个比喻:
- 数据清洗 → 把一堆乱糟糟的食材洗干净、切好。
- EDA → 把食材摆出来,看一看、闻一闻、尝一尝:颜色好不好?有没有异味?大概能做什么菜?
- 诊断分析 → 然后才开始思考:为什么这个菜有点苦?是不是盐放少了?
核心思想 :"让数据自己说话"。先不要急着下结论,而是通过看图表和数字,产生疑问,然后再去验证。
EDA要回答什么问题?
在EDA阶段,你主要问的是描述性问题 ,也就是 "发生了什么?"。例如:
- 总销售额是多少?平均每单卖多少钱?
- 销售额是逐年增长还是下降?有没有季节性规律?
- 哪个地区的客户最多?哪个产品卖得最好?
- 消费者和公司客户,谁买得更多?
- 有没有什么异常值(比如一笔订单金额特别高)?
这些问题都是单维度或简单双维度的探索,目的是快速掌握数据的基本面貌。
EDA在Excel中的完整操作指南
在Excel里做EDA,主要依靠两个武器:数据透视表 和 图表。下面我把EDA分解成几个标准任务,每一步都用Superstore数据集举例说明。
任务1:整体概况
- 目标:看一眼数据的"体型"和主要指标。
- 操作 :
- 统计总行数:看最后一行的Row ID。
- 总销售额:对Sales列求和。
- 总订单数:对Order ID去重计数(可以使用"删除重复值"功能复制一份出来数,或者用数据透视表把Order ID拖到行,再计数)。
- 平均客单价:总销售额 / 总订单数。
任务2:单变量分析(看每一列的分布)
- 目标:了解每一列数据的分布情况,发现异常或有趣的点。
- 对于数值型变量(如Sales) :
- 最小值、最大值、平均值 :用
MIN、MAX、AVERAGE函数。 - 分布直方图:用数据透视表将Sales分组(比如0-100, 100-200...),然后做柱状图,看看大多数订单集中在哪个金额段。
- 识别异常值:对Sales列降序排序,看看有没有特别大的订单,是正常的团购还是录入错误?
- 最小值、最大值、平均值 :用
- 对于分类型变量(如Region、Category) :
- 频数统计:用数据透视表,把该字段拖到"行",把Row ID或Order ID拖到"值"计数,看看每个类别有多少条记录。
- 占比图:把频数统计结果做成饼图或环形图,直观看到各部分的份额。
任务3:双变量分析(看两列之间的关系)
- 目标:发现两个变量之间的关联,为后续诊断提供线索。
- 类别 vs 数值(如 Region vs Sales) :
- 分组汇总:用数据透视表,行放Region,值放Sales(求和/平均值)。然后做柱状图,一眼看出哪个地区销售额最高/最低。
- 时间 vs 数值(如 Year vs Sales) :
- 趋势图:用数据透视表,行放Year,值放Sales(求和),然后插入折线图,看年度变化。
- 月度季节性:行放Month,值放Sales(平均值或总和),折线图看淡旺季。
- 类别 vs 类别(如 Region vs Category) :
- 交叉表:用数据透视表,行放Region,列放Category,值放Sales(求和)。这是一个矩阵,可以快速看出哪个品类在哪个地区强/弱。
任务4:多变量初步探索
- 目标:看三个以上维度的组合,但Excel里通常用颜色或重复透视来实现。
- 操作 :
- 在数据透视表中,把时间(Year)也放到列或行,形成更复杂的交叉表。
- 例如:行是Region,列是Category,下面再分Year,看看各地区各品类的年度变化趋势。
任务5:记录观察和假设
- 目标:把你在看图表过程中产生的疑问和初步想法记下来,这些就是下一步诊断分析的线索。
- 操作 :新建一个Excel工作表,命名"EDA_Notes",随时记录。
- "Central地区销售额最低 → 需要深挖原因"
- "Technology品类在2017年增长特别快 → 是不是有大客户?"
- "9月销售额有明显峰值 → 可能是开学季促销的效果"
EDA的关键原则
- 不要急着下结论:EDA是探索,不是最终答案。你看到的只是表象,需要后续验证。
- 保持好奇心:多问"为什么",多尝试不同的分组和图表。
- 先整体后局部:先看总体,再看各个部分,最后看异常点。
- 可视化优先:人眼对图形比对数字敏感,尽量用图表说话。
- 记录你的发现:把看到的规律和疑问写下来,避免后面忘记。
一个EDA小例子(以Superstore为例)
假设你现在正在做EDA:
-
你用数据透视表看了 Category 的销售额,发现 Technology 最高,Furniture 次之,Office Supplies 最低。
- 观察:Technology是公司的收入主力。
- 疑问:但Office Supplies虽然总销售额低,订单数是不是很多?(因为单价低)
-
你又看了 Region vs Category 的交叉表,发现 Central 地区的 Furniture 销售额明显低于其他地区。
- 观察:Central地区家具卖得不好。
- 疑问:是因为Central地区的客户不喜欢买家具,还是我们在这个地区家具定价太高,或者根本没有投放好的家具产品?
-
你看了 Monthly Sales 的折线图,发现 9月、11月、12月 有三个明显的波峰。
- 观察:存在季节性销售高峰。
- 疑问:这三个月的销售额主要是由哪个品类拉动的?是不是和美国的返校季、黑五、圣诞有关?
好的!诊断分析是从"发生了什么"到"为什么发生"的关键一跃。下面我给你详细解释。
什么是诊断分析?
定义 :诊断分析是在EDA(探索性分析)的基础上,针对发现的异常、趋势、规律 ,通过多维度交叉、对比、拆解,找出背后的原因和驱动因素。
和EDA的区别:
| EDA(探索性分析) | 诊断分析 | |
|---|---|---|
| 问题 | 发生了什么? | 为什么会发生? |
| 目标 | 发现现象、描述现状 | 寻找原因、解释现象 |
| 方法 | 单维度、简单双维度图表 | 多维度交叉、对比、拆解、漏斗 |
| 例子 | "Central地区销售额最低。" | "Central地区销售额最低,是因为它的家具品类销售额远低于其他地区,可能是当地物流成本高或竞争激烈。" |
一个比喻:
- EDA:医生给病人量体温、测血压,发现"体温38.5℃"。
- 诊断分析:医生开始问"有没有咳嗽?喉咙痛不痛?最近去过哪里?",然后开化验单,最终诊断"是细菌感染引起的肺炎"。
诊断分析要回答什么问题?
在诊断分析阶段,你主要问的是解释性问题。例如:
- 为什么2017年销售额增长特别快?(是客户变多了?还是老客户买得更贵了?)
- 为什么Central地区业绩最差?(是订单数量少?还是客单价低?还是某个品类完全卖不动?)
- 为什么Technology品类是收入主力?(是单价高?还是卖得多?)
- 为什么9月是销售旺季?(是哪个品类在拉动?是哪个客户群在买?)
这些问题都需要你把多个维度组合起来 看,找到真正的驱动因素。
诊断分析的核心方法
在Excel里做诊断分析,主要有5种核心方法:
方法1:维度下钻
- 定义:从粗粒度下钻到细粒度,一层层找到问题所在。
- 操作:像剥洋葱一样,一层层往下看。
- 例子 :
- 第一层:Central地区业绩差(地区维度)。
- 第二层:下钻到Category,发现Central地区的Furniture尤其差。
- 第三层:再下钻到Sub-Category,发现是"Tables"和"Bookcases"这两个子类别最差。
- 结论:Central地区业绩差,主要是Tables和Bookcases卖不动。
方法2:对比分析
- 定义:没有对比就没有伤害。把好的和差的放在一起比,找出差异点。
- 操作:找基准(平均值、最好地区、去年同期)进行对比。
- 例子 :
- 把Central地区的Furniture销售额占比(25%),和West地区的占比(40%)对比。
- 把2017年的Technology销售额增长率(30%),和2016年的增长率(10%)对比。
- 结论:Central地区家具占比明显偏低,这是它的核心短板。
方法3:拆解分析
- 定义:把一个指标拆解成几个组成部分,看哪个部分贡献最大变化。
- 常用公式 :
- 销售额 = 订单数 × 客单价
- 订单数 = 客户数 × 人均下单频次
- 操作:分别计算每个部分的数值和变化率。
- 例子 :Central地区销售额低,是因为订单数少(1000单),还是客单价低(200)?对比West地区(订单数2000单,客单价250),发现主要是订单数太少。再进一步拆解:是因为客户数少,还是老客户复购率低?
方法4:归因分析
- 定义:找出哪个因素对结果的影响最大。
- 操作:观察不同因素的变化和结果变化的关系。
- 例子 :2017年销售额增长30%。分别看:
- Consumer客户增长贡献了多少?
- Corporate客户增长贡献了多少?
- 如果Corporate贡献了80%的增长,那么主要归因于公司客户的爆发。
方法5:异常值追踪
- 定义:针对EDA中发现的异常点,追查具体是哪个订单、哪个客户导致的。
- 操作:排序、筛选,找到具体记录。
- 例子:你在EDA发现有个订单销售额特别高($20,000)。现在就去找到这个订单,看看是哪个客户、买了什么产品。也许是个大公司一次性采购了一批服务器和椅子,这就可以解释为什么那天Technology和Furniture同时出现高峰。
诊断分析在Excel中的完整操作指南
假设你在EDA中发现:Central地区业绩最差。现在开始诊断:
步骤1:维度下钻(地区 → 品类 → 子品类)
- 创建数据透视表:
- 行:
Region(先看地区) - 值:
Sales求和 - 发现:Central最低
- 行:
- 把
Category拖到列:- 发现:Central的Furniture尤其低
- 把
Category拖走,把Sub-Category拖到行,筛选Region为Central:- 发现:Tables和Bookcases是最低的两个子品类
步骤2:对比分析(和最好地区比)
- 新建一个工作表,对比Central和West(最好地区)的各品类销售额。
- 计算差额和差额百分比:
- Central Furniture销售额 = $X
- West Furniture销售额 = $Y
- Central比West低 (Y-X),低了 (Y-X)/Y %
- 如果发现Furniture的差额占总差额的80%,说明家具是主要问题。
步骤3:拆解分析(销售额 = 订单数 × 客单价)
- 针对Central地区的Furniture品类:
- 计算订单数(Count of Order ID)
- 计算客单价(
Sales平均值) - 和West地区对比:
- 如果订单数明显少 → 问题在于购买人数/频次不足。
- 如果客单价明显低 → 问题在于买的东西便宜(可能是折扣多,或者买的是低价产品)。
步骤4:提出初步假设
根据以上分析,你可能会有几个假设:
- 假设1:Central地区没有好的家具供应商,导致产品选择少。
- 假设2:Central地区的家具物流成本高,导致定价比其他地区高,客户不买。
- 假设3:Central地区的客户主要是Consumer(个人消费者),不像Corporate那样大量采购家具。
步骤5:验证假设
- 验证假设1:需要数据外的信息(行业调研),目前无法验证。
- 验证假设2:需要成本数据,目前没有,先保留。
- 验证假设3:把
Segment也拉入分析,看看Central地区和其他地区的客户细分构成是否不同。- 如果发现Central地区的Corporate客户占比确实低,那么这个假设就成立了。
诊断分析后,你要输出什么?
完成诊断分析后,你应该能写出这样的结论:
【核心诊断结论】
Central地区业绩垫底的核心原因是家具品类销售额严重落后 ,尤其以"Tables"和"Bookcases"最为突出。进一步拆解发现,该地区家具品类的订单数 仅为West地区的1/3,但客单价相近。这说明问题不在于卖得便宜,而在于购买人数或频次不足。结合客户细分分析,Central地区的Corporate客户占比较低,可能影响了需要集中采购的家具品类的销量。
【初步建议方向】
- 调研Central地区Corporate客户的市场潜力,考虑设立大客户销售团队。
- 评估Central地区家具产品的投放策略,是否因为物流原因导致热门型号缺货。
- 针对Central地区的Consumer客户,推出家具品类的组合促销,尝试提升订单数。
总结:诊断分析的三步曲
- 定位问题:从EDA中发现需要深挖的现象(如某个地区差、某个时间点异常)。
- 拆解对比:用维度下钻、拆解公式、对比基准等方法,找到具体的差异点。
- 提出假设并验证:基于数据提出可能的原因,并尽可能用数据验证。
什么是好的建议?
好的建议不是"应该多卖点东西",而是具体、可执行、有数据支撑、能衡量效果的行动方案。
| 不好的建议 | 好的建议 |
|---|---|
| "Central地区应该多卖家具。" | "针对Central地区Tables品类订单数仅为West地区1/3的问题,建议在该地区投放'办公桌+椅子'组合促销,预算$5000,目标提升该品类订单数30%。" |
| "要抓住旺季多卖货。" | "9月返校季销售高峰主要由Technology品类拉动,建议提前在8月向学生群体投放Technology产品折扣邮件,预计带来$50万增量销售额。" |
| "要提高客户价值。" | "Top 10%的客户贡献了60%的销售额,建议为这些高价值客户建立专属客服通道,并每季度推送新品目录,目标将复购率提升15%。" |
提出建议的核心框架
从诊断结论到建议,可以遵循以下四步框架:
第1步:明确问题/机会
- 从诊断分析中提炼出1-3个最核心的发现。
- 每个发现要同时包含现象 和原因。
第2步:思考方向
- 针对问题/机会,思考可能的行动方向。一般有四个方向:
- 改善短板:问题出在哪?怎么补?
- 放大优势:什么做得好?怎么做得更好?
- 抓住机会:有什么潜力可以挖掘?
- 规避风险:有什么隐患需要提前预防?
第3步:细化建议
- 把方向变成具体的行动。要回答:
- 做什么?(具体行动)
- 谁来做?(哪个部门负责)
- 什么时候做?(时间节点)
- 预期效果?(怎么衡量成功)
- 需要什么资源?(预算、人力)
第4步:优先级排序
- 建议可能有很多,需要按投入产出比 或紧急程度排序。
- 通常可以分为:
- Quick Wins:容易做、见效快
- Major Projects:需要投入、但回报高
- Long-term Initiatives:长期布局
- Nice to Have:锦上添花
用Superstore项目实战演示
假设你在诊断分析阶段得出以下三个核心结论:
| 编号 | 诊断结论 |
|---|---|
| 1 | Central地区业绩垫底,核心原因是Furniture品类(特别是Tables和Bookcases)的订单数仅为West地区的1/3,但客单价相近,说明问题在于购买人数不足。 |
| 2 | Technology品类是公司收入主力(占总销售额35%),且在2017年增长最快,主要由Corporate客户的大额采购拉动。 |
| 3 | 9月、11月、12月是全年销售峰值,主要由Technology和Furniture品类的Corporate客户贡献,疑似与返校季、黑五、圣诞采购有关。 |
现在,针对每个结论推导建议:
结论1:Central地区家具品类订单数不足
第1步:明确问题
- Central地区Tables和Bookcases卖不动,不是单价问题,是买的人太少。
第2步:思考方向
- 改善短板:为什么买的人少?是产品选择少?价格没优势?还是客户不知道我们有这些产品?
第3步:细化建议
| 建议 | 做什么 | 谁来做 | 何时做 | 预期效果 | 所需资源 |
|---|---|---|---|---|---|
| 建议1.1(Quick Win) | 针对Central地区投放家具品类促销邮件,重点推Tables和Bookcases,并提供限时免运费(物流是家具购买的关键决策因素)。 | 市场部 | 下个月开始 | 家具品类订单数提升20% | 邮件设计费用+运费补贴预算$3000 |
| 建议1.2(Major Project) | 调研Central地区家具供应链,评估是否因为物流成本高导致定价缺乏竞争力,或热门型号缺货。 | 供应链部 | 本季度完成 | 优化后客单价提升10%,订单数提升15% | 调研人力+可能的供应商调整成本 |
| 建议1.3(Long-term) | 在Central地区建立区域仓储中心,降低家具配送成本和时间。 | 运营部 | 明年规划 | 长期提升该地区家具竞争力 | 数百万级投资,需单独评估 |
结论2:Technology是收入主力,由Corporate客户拉动
第1步:明确机会
- Corporate客户是Technology品类的核心驱动力,他们买得多、买得贵。
第2步:思考方向
- 放大优势:怎么让Corporate客户买得更多?怎么让更多公司成为我们的客户?
第3步:细化建议
| 建议 | 做什么 | 谁来做 | 何时做 | 预期效果 | 所需资源 |
|---|---|---|---|---|---|
| 建议2.1(Quick Win) | 梳理现有Corporate客户的购买记录,针对他们常买的Technology产品(如Phones、Copiers),推送相关配件和升级款的优惠信息。 | 销售部/市场部 | 下个月 | 现有Corporate客户客单价提升10% | 数据分析时间+邮件设计 |
| 建议2.2(Major Project) | 成立大客户销售团队,专门跟进Top 100的Corporate客户,定期回访、了解需求、提供专属折扣。 | 销售部 | 本季度组建 | Top客户复购率提升20%,销售额增长15% | 2-3名销售人员的薪资 |
| 建议2.3(Opportunity) | 针对Central地区Corporate客户占比低的问题,在该地区开展"企业采购月"活动,重点推广Technology产品。 | 市场部+销售部 | 结合建议1.1的时间 | Central地区Corporate客户数提升30% | 活动预算$8000 |
结论3:9月、11月、12月是销售旺季
第1步:明确机会
- 旺季规律明显,主要由Corporate客户拉动。
第2步:思考方向
- 抓住机会:怎么在旺季前做好准备,把销售额最大化?
第3步:细化建议
| 建议 | 做什么 | 谁来做 | 何时做 | 预期效果 | 所需资源 |
|---|---|---|---|---|---|
| 建议3.1(Quick Win) | 每年8月(旺季前一个月)开始向Corporate客户推送"开学季/年末采购指南",提前锁定订单。 | 市场部 | 每年8月 | 9-12月销售额额外增长10% | 邮件内容制作 |
| 建议3.2(Operational) | 根据去年旺季的销售数据,提前预测热门产品(如Phones、Chairs)的销量,确保旺季不缺货。 | 供应链部 | 每年7月完成预测和备货 | 避免因缺货导致的销售损失 | 数据分析+库存成本 |
| 建议3.3(Strategic) | 分析旺季中Consumer客户的购买行为,如果Consumer也有明显增长,可以考虑在旺季也向个人消费者推送促销,进一步放大销售。 | 市场部 | 今年旺季前 | 新增Consumer旺季销售增量 | 促销预算 |
如何写好建议?5个技巧
- 用数据说话:每条建议都要有数据支撑。"基于我们发现Central地区家具订单数仅为West的1/3,建议......"
- 具体化:不要说"加强促销",要说"在Central地区投放家具品类免运费促销,预算$3000"。
- 分清轻重缓急:在报告里把建议按优先级排序,让决策者知道先做什么。
- 考虑可行性:提建议时要考虑公司有没有资源做。如果没资源,可以提一个小规模试点方案。
- 可衡量:每条建议都要有明确的目标,比如"提升订单数20%",方便后续评估效果。
最终输出:建议清单
在最终的报告里,你可以用一个表格来呈现所有建议:
| 优先级 | 建议 | 针对问题/机会 | 预期效果 | 负责部门 | 所需资源 |
|---|---|---|---|---|---|
| 高 | Central地区家具品类免运费促销 | 家具订单数不足 | 订单数+20% | 市场部 | $3000 |
| 高 | 成立大客户销售团队 | Corporate客户潜力大 | 销售额+15% | 销售部 | 2-3人薪资 |
| 中 | Central地区供应链调研 | 家具竞争力不足 | 优化后销售额+25% | 供应链部 | 调研人力 |
| 低 | Central建区域仓储中心 | 长期竞争力 | 长期改善 | 运营部 | 数百万投资 |
总结:提出建议的四步曲
- 明确问题/机会:从诊断结论出发
- 思考方向:改善短板/放大优势/抓住机会/规避风险
- 细化建议:做什么、谁做、何时做、预期效果、所需资源
- 排序输出:按优先级整理成表格
正式分析开始
太棒了!作为一个Excel数据分析的学习者,通过模拟真实的商业项目来提升实力,是一个非常高效的路径。
我为你设计了一个名为 " Superstore 运营诊断与战略优化项目 " 的模拟分析方案。这个项目将带你模拟一家全国性零售连锁店的初级数据分析师,你需要通过分析历史销售数据,为管理层提供决策支持。
整个项目分为六大模块,难度从易到难,层层递进。请你严格按照题目要求,在Excel中操作,不要直接看答案。
项目背景设定
你是一家名为"Superstore"的全国性零售公司的数据分析师。公司销售办公用品、家具和电子产品,客户遍布全美。目前,管理层希望了解2015年至2018年的整体运营状况,找出最具价值的客户群体和产品,发现各地区的问题,并为下一年的战略规划提供数据支持。
数据集简介
你手头有一份名为 train.csv 的数据集,包含了从2015年到2018年的部分订单详情。主要字段包括:
- 订单信息 :
Row ID,Order ID,Order Date,Ship Date,Ship Mode - 客户信息 :
Customer ID,Customer Name,Segment(客户细分),Region(地区) - 地理位置 :
Country,State,City,Postal Code - 产品信息 :
Product ID,Category(类别),Sub-Category(子类别),Product Name - 核心指标 :
Sales(销售额)
项目题目:Superstore 销售数据分析与商业洞察
模块一:数据清洗与准备 (Data Cleaning & Preparation)
目标:将原始数据处理成可以分析的干净表格。
- 日期格式处理 :
Order Date和Ship Date列目前是文本格式(如08/11/2017)。请使用Excel函数(如DATEVALUE或分列功能)将它们转换为真正的日期格式。 - 计算运送时间 :添加一个新列,命名为
Shipping Days。计算从下单到发货的实际天数 (Ship Date-Order Date)。 - 提取年份和月份 :为了进行年度和月度趋势分析,请从
Order Date中提取两个新列:Year和Month。 - 检查数据完整性 :快速浏览所有列,检查是否存在空值或明显错误的数据(例如,销售额为负数或零)。如果发现少量缺失值,思考一下是删除还是填充?(缺失值可以直接用下面的方法来检测)
比如这里,我们检测之后发现Postal Code这一列有缺失,集中在Vermont,这个时候我们就可以在State列中检索Vermont,看有没有其他Vermont有邮政编码,但是我们发现就是全部缺失,所以就只能去网上寻找此地邮政编码并找一个填补上
然后由于邮政编码为05401,作为数字的话前面的0会被消除,所以我们要把整一列的数据类型更改为文本,最后再集合空缺值填补即可
模块二:整体销售表现 (Overall Sales Performance)
目标:从宏观角度了解公司的销售状况。
-
总销售额 :计算整个数据集的总销售额 (
SUM of Sales)。 -
年度销售趋势 :使用数据透视表,以
Year为行,计算每年的总销售额。哪一年的销售额最高?哪一年的增长最显著?
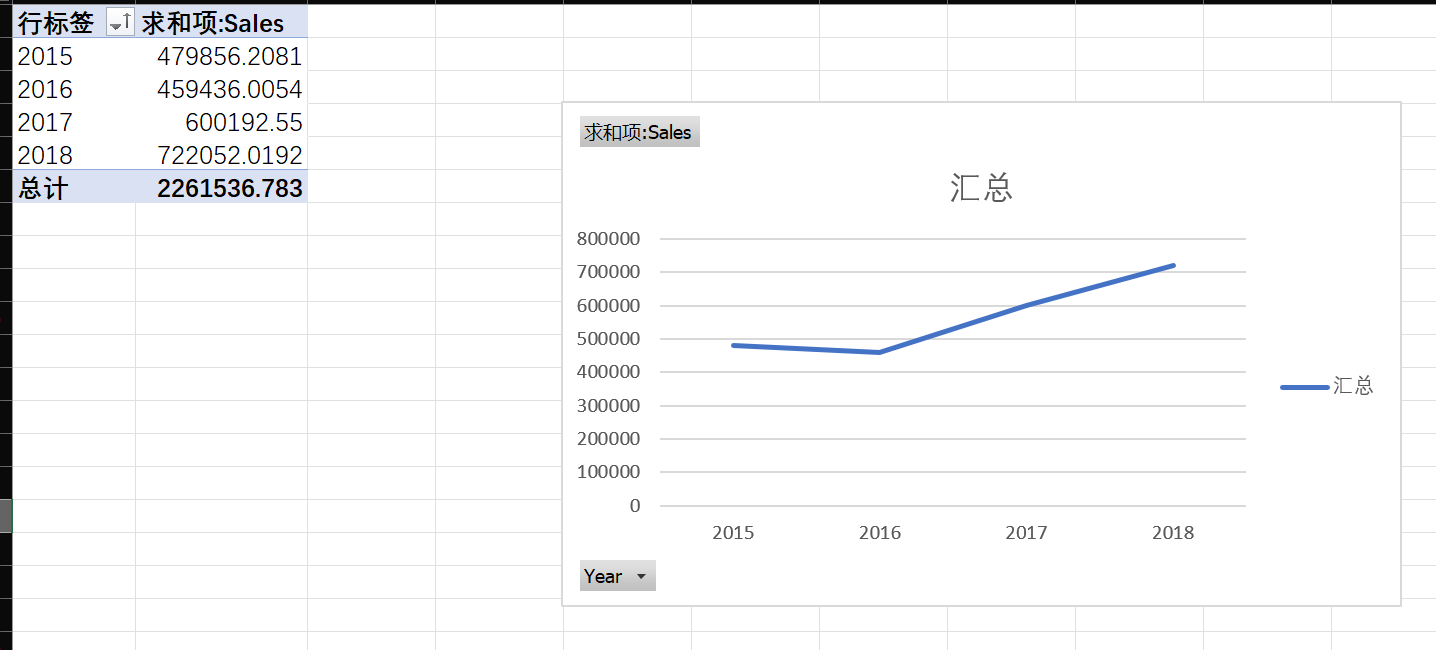
如果想知道那一年的增长最显著,那就需要计算环比增长率
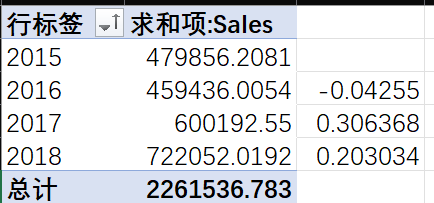
比如2016年的环比增长率 = 2016 -2015的销售额 / 2015的销售额
这么一看2017年增长最显著,而2018年销售额最高
-
月度销售规律 :以
Month为行,计算所有年份加总后每个月的平均销售额。哪个月份是全年销售旺季?哪个月份是淡季?
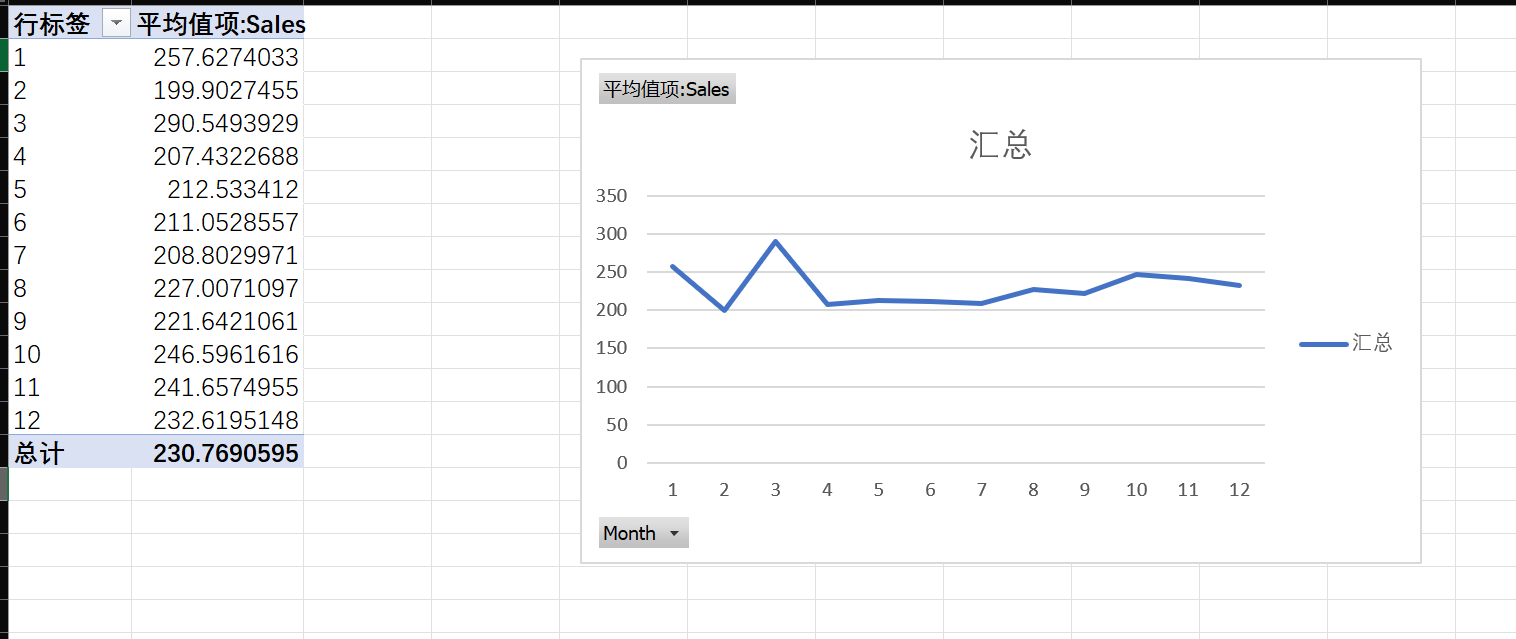
可以看出来三月份是全年销售旺季,而二月份则是淡季
-
不同运送方式的表现 :分析不同
Ship Mode的订单数量和平均销售额。哪种运送方式使用得最多?哪种方式带来的单均销售额最高?
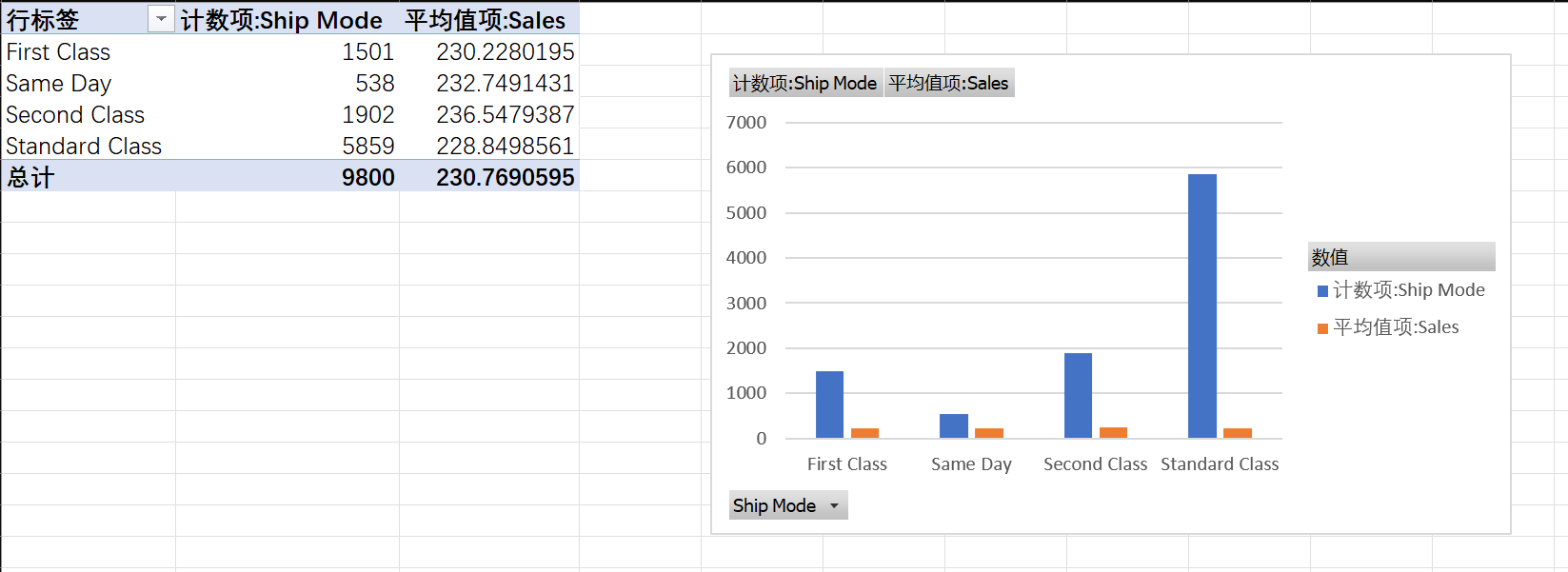
可以看出最多的是Standard Class,单均销售额还是Second Class最多
模块三:客户与细分市场分析 (Customer & Segment Analysis)
目标:识别最重要的客户群体。
-
客户细分贡献 :分析不同
Segment(消费者、公司、家庭办公室) 的总销售额和订单数占比。哪个细分市场是公司的"金主"?
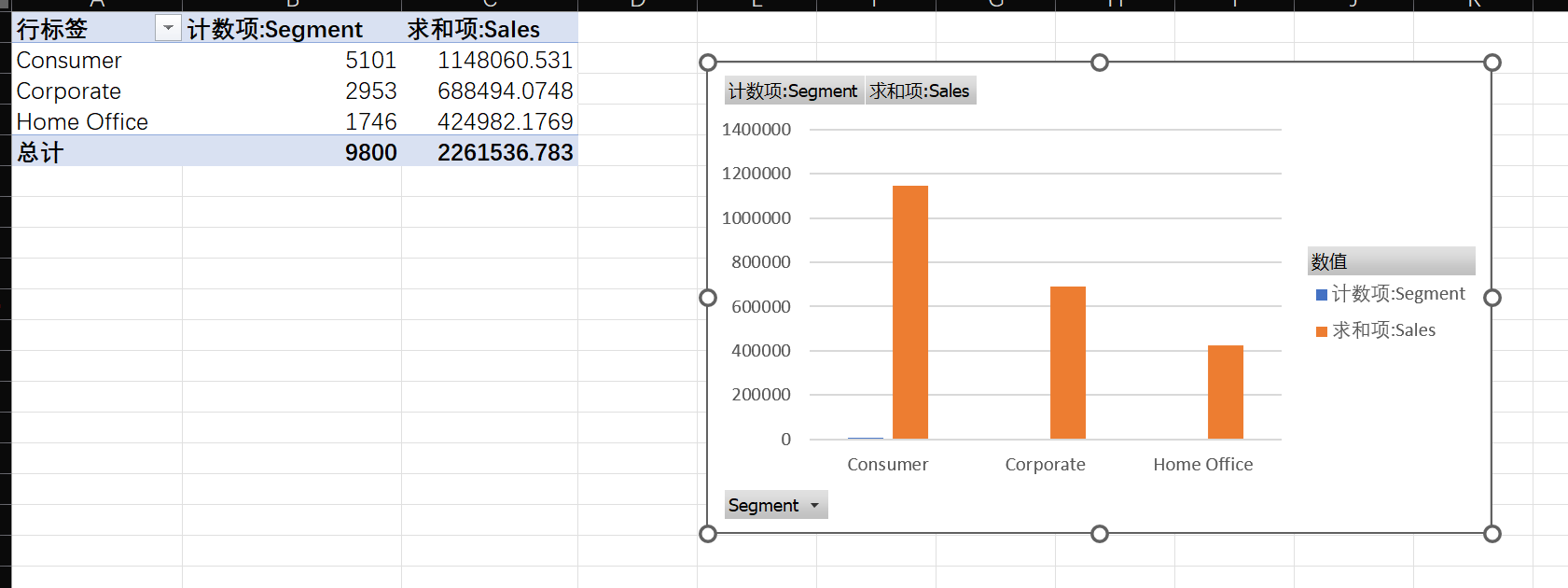
可以看出销售额占比最高的还是Consumer,订单数占比最高的也是Consumer
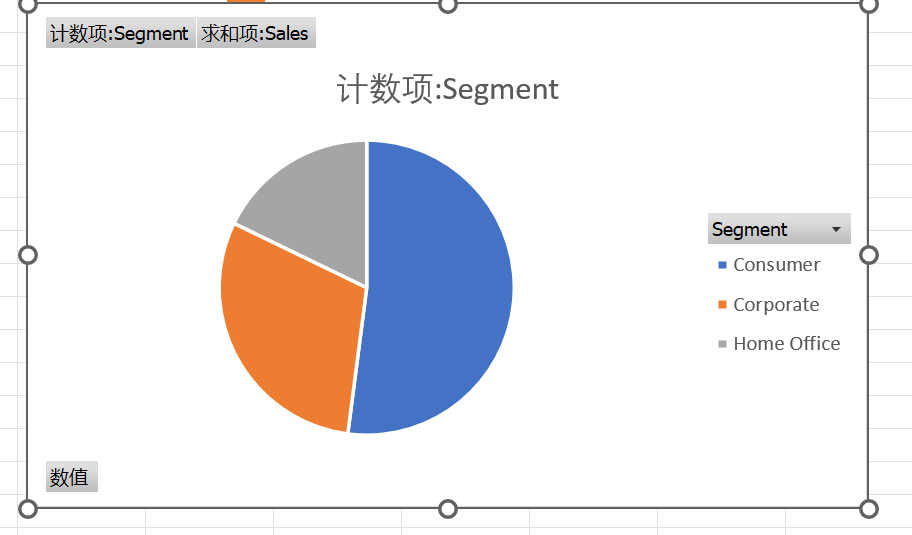
当然你也可以直接用饼图看,虽然无法同时显示sales和Segment计数,但是切换在透视表中的顺序就可以了
-
高价值客户识别 (RFM模型思想简化版):
- 找出回头客 :找出那些
Customer Name在数据集中出现次数超过5次的客户。他们是谁?
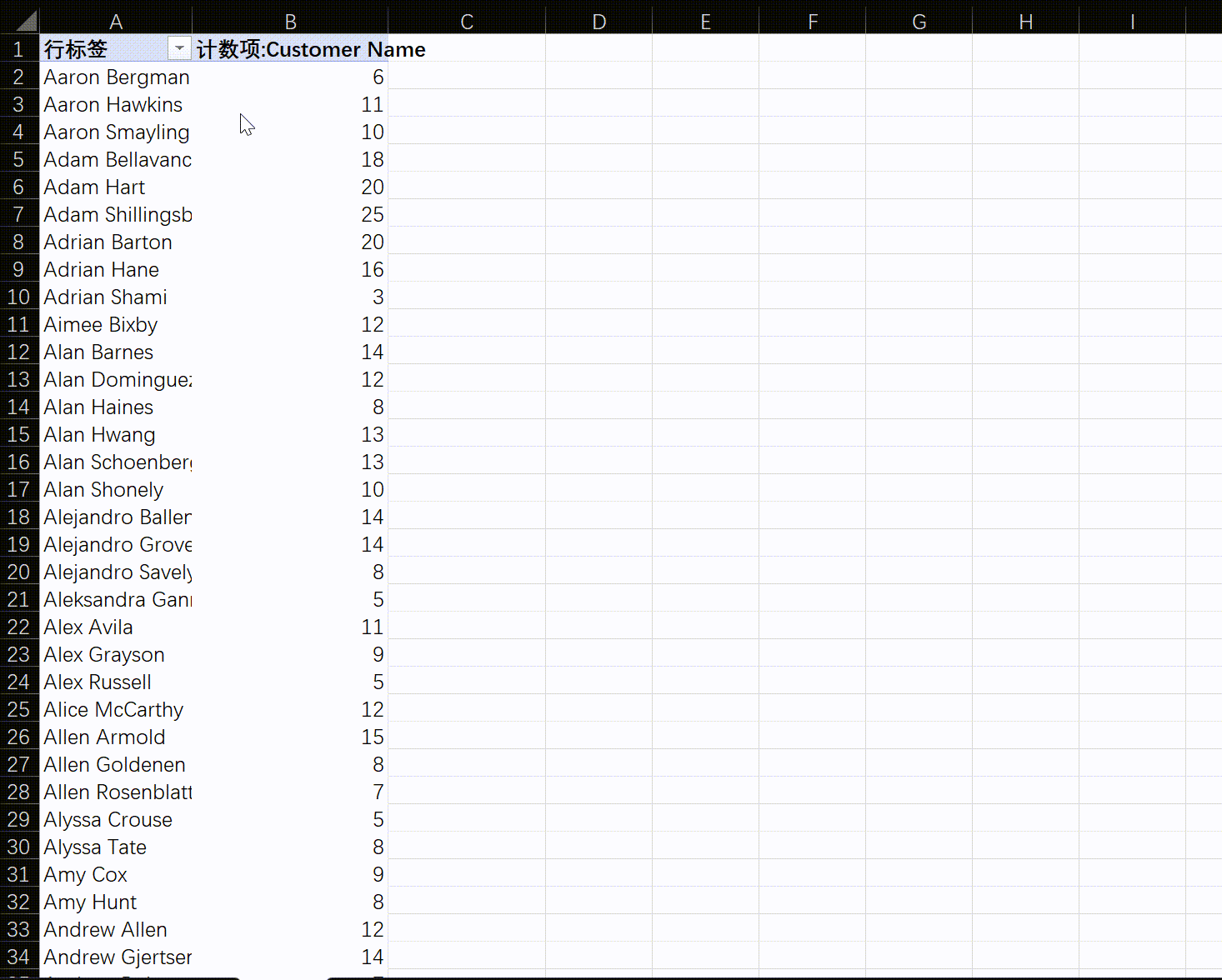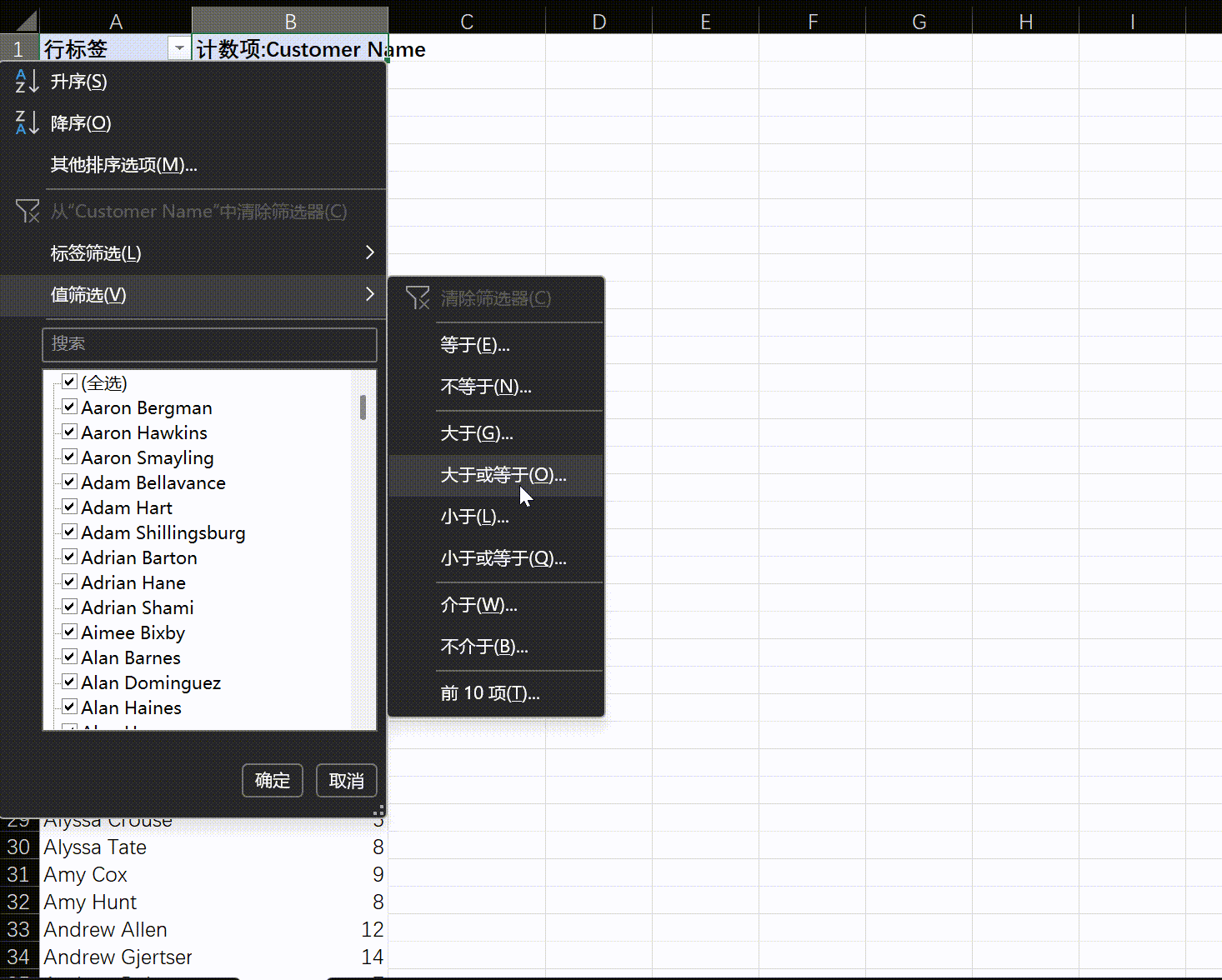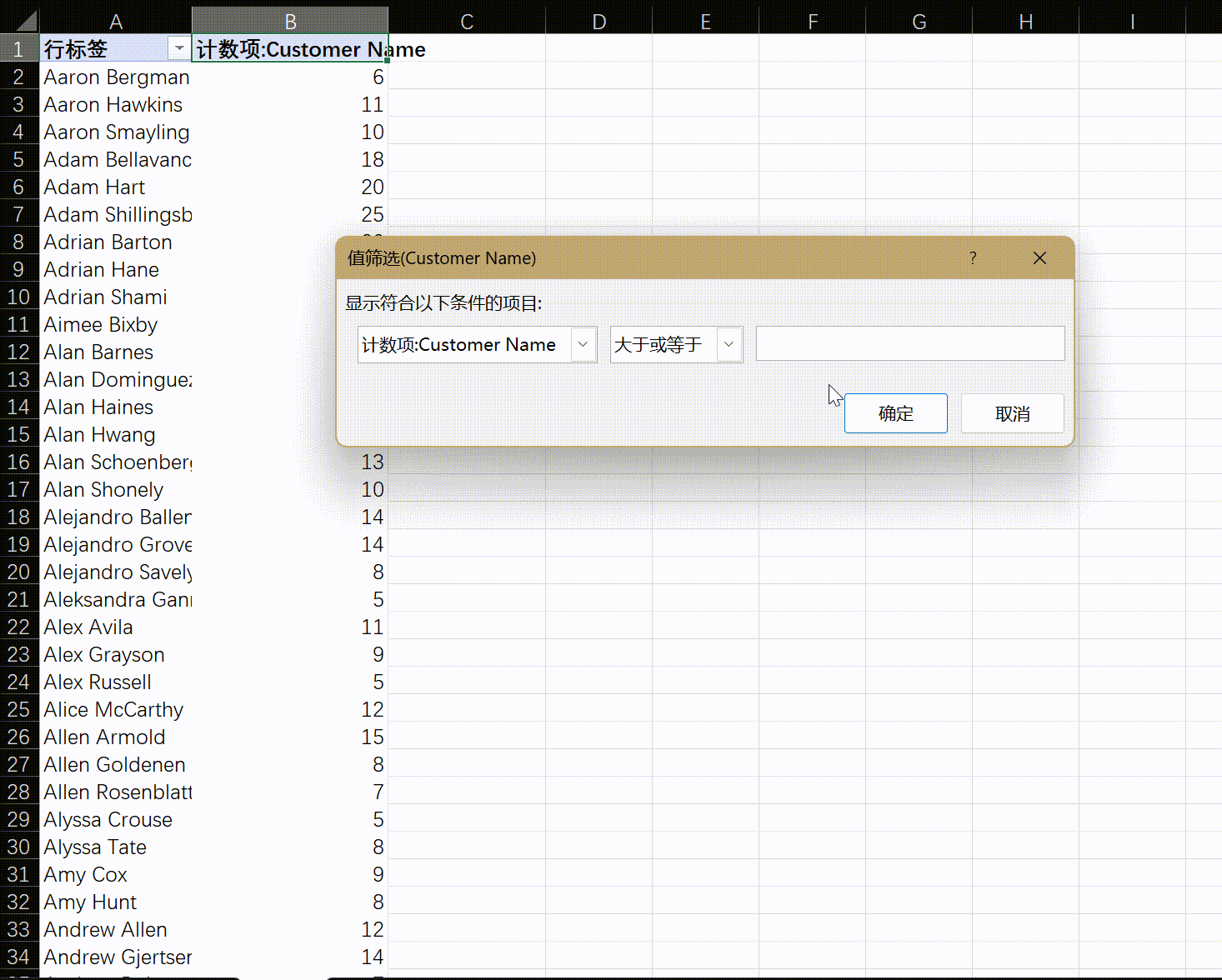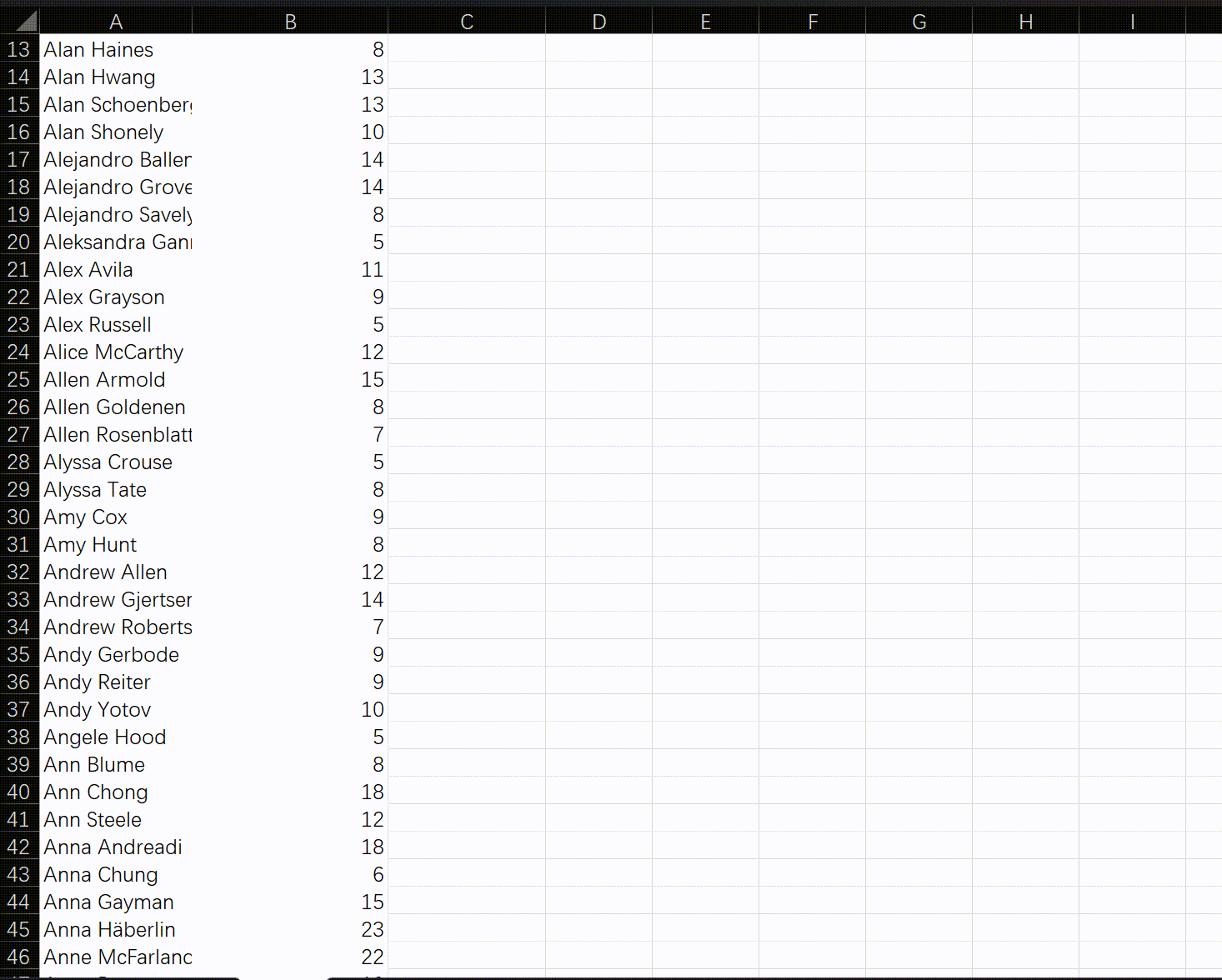
透视表会自己删除重复的项,无需担心重复名字 - 找出大客户 :找出总消费额排名前10的客户。他们主要属于哪个
Segment?主要购买哪个Category的产品?
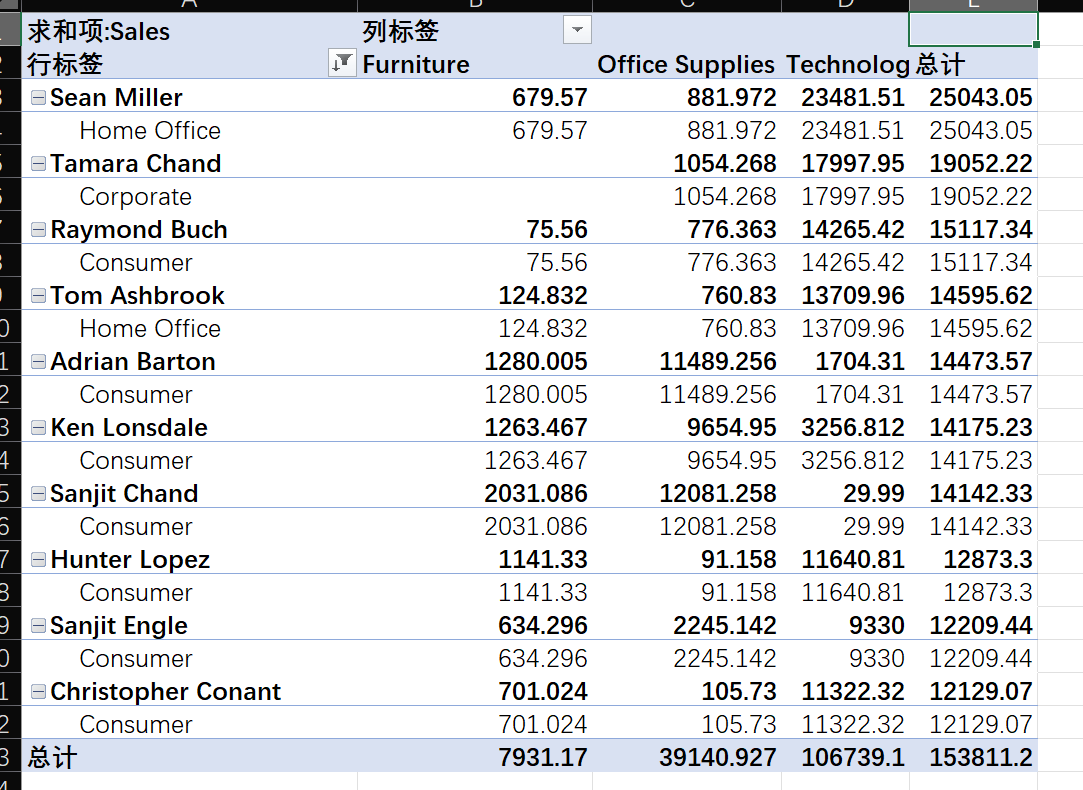
首先按照总计销售额进行倒序排序,然后再提出前10个即可,行为Customer Name以及Segment,而列则为Category
- 找出回头客 :找出那些
可以看出来果然还是Consumer居多,根据列总计发现Technology的种类产品买的最多
- 地区销售差异 :分析不同
Region(地区) 的销售总额。哪个地区的业绩最好?哪个地区最差?对于业绩差的地区,你能初步想到什么原因?
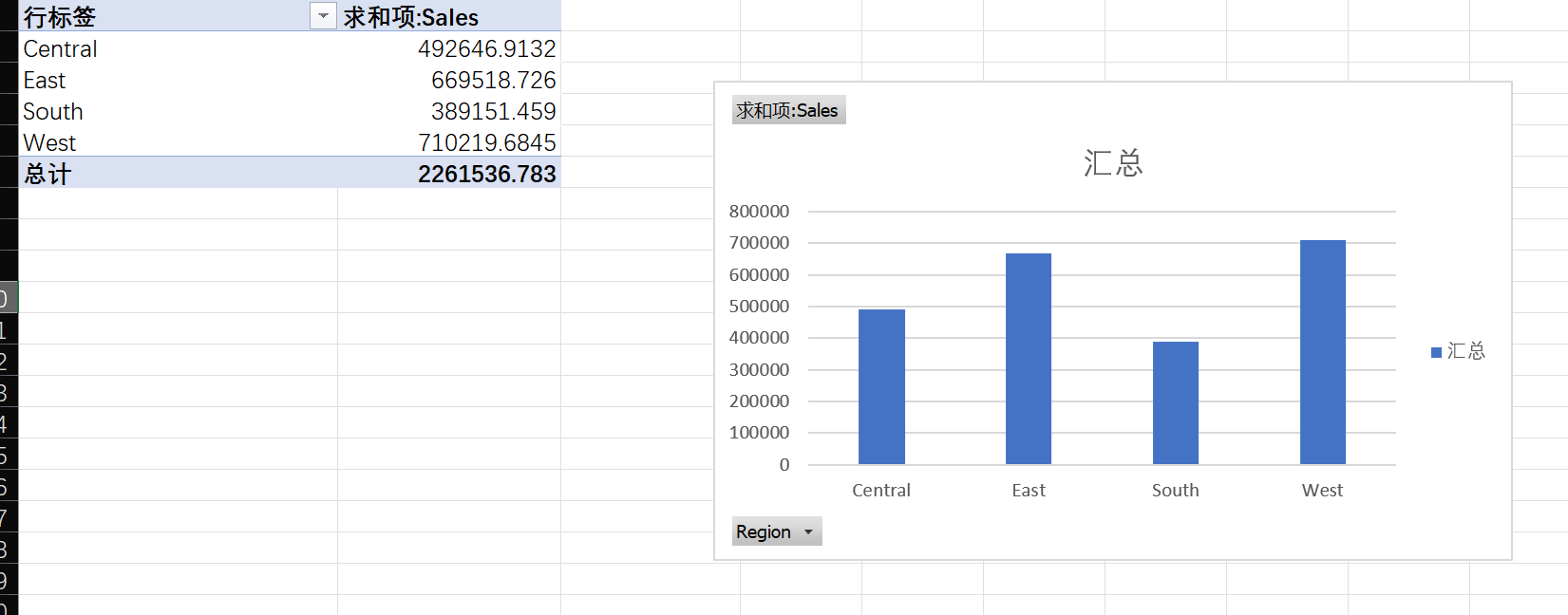
很明显能够看出来,West业绩最好,而South业绩最差
我认为原因可能在于
① 订单量少
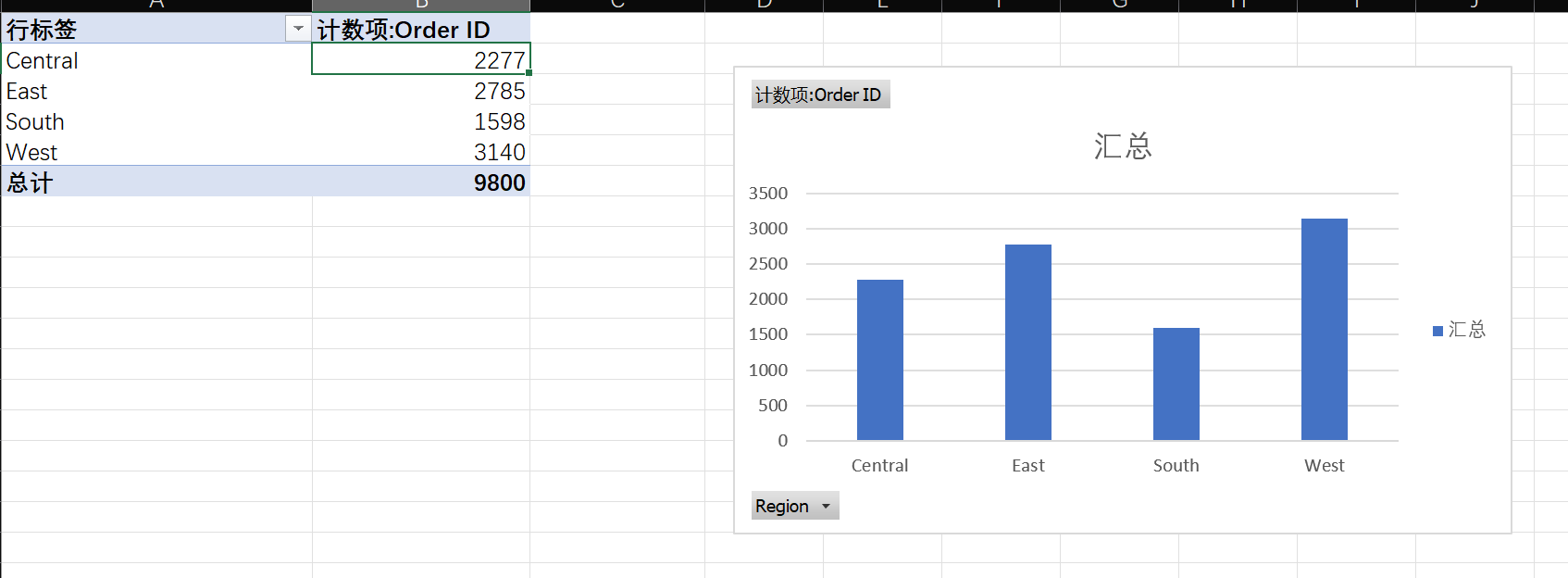
②复购率低
CustomerID成为值标签,而列标签则包含Region、CustomerID
右键South,只保留这个项目之后,通过唯一计数会发现,South地区的Customer一共有509个,而对South值筛选筛选出计数>=2的用户过后,即可计算(记住这里不要用行标签进行值筛选,不然的话就会忽略之前我们筛选的South值)
简单起见,我们筛选只够买过1次的人,发现有142个人,那么回购率就是(509-142)/ 509
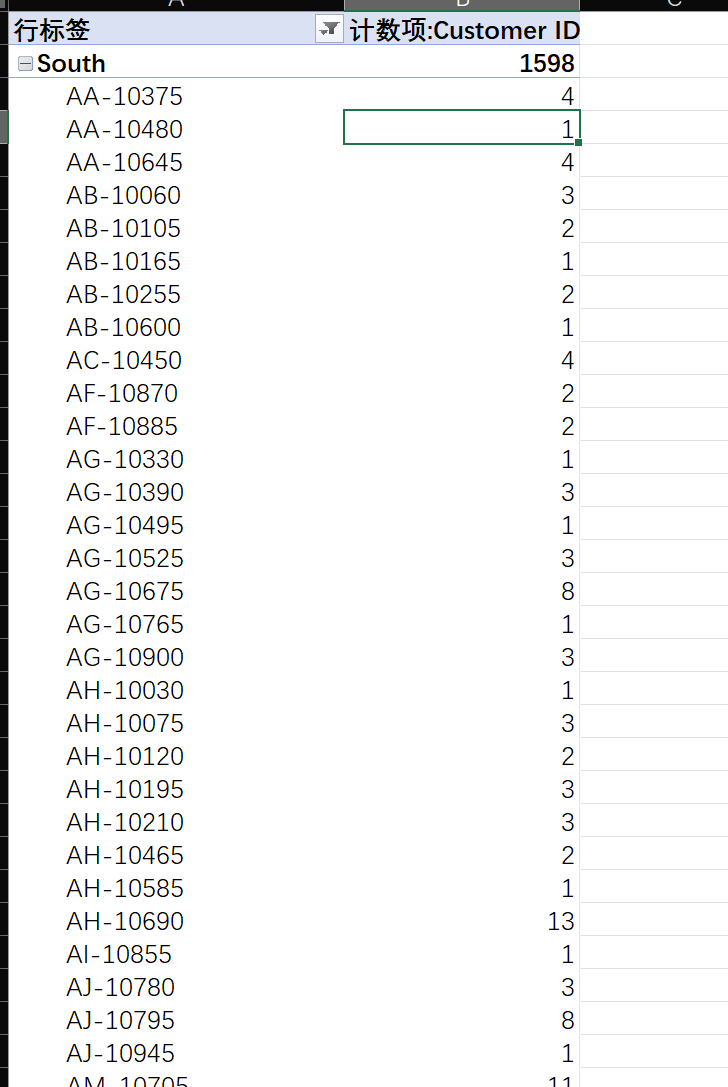
③只依赖于头部城市,其他城市市场开发不足
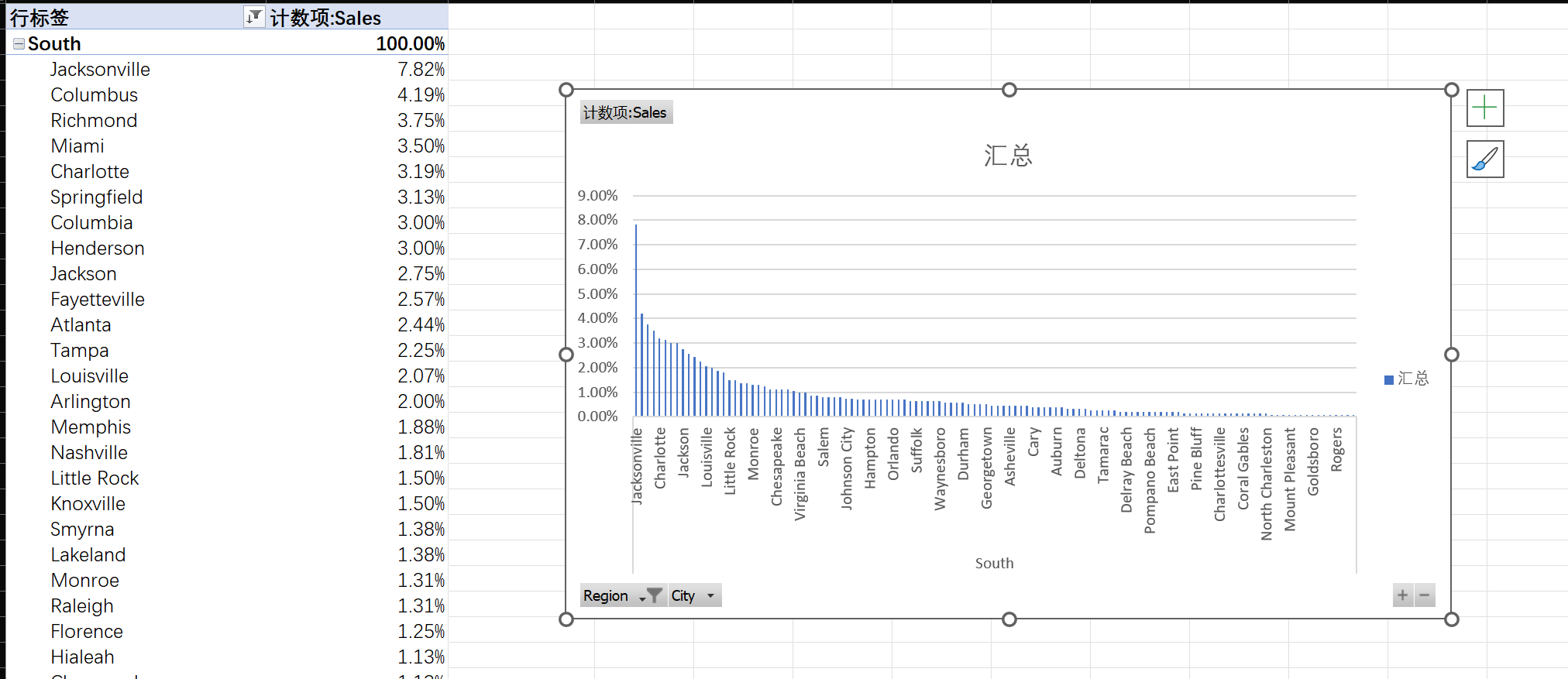
并且主力城市也并没有像其他Region的主力城市一样提供很高的比例
模块四:产品分析 (Product Analysis)
目标:发现明星产品和问题产品。
-
品类销售结构 :分析不同
Category( Furniture, Office Supplies, Technology) 的总销售额和销量(订单数)。哪个品类最赚钱(销售额最高)?
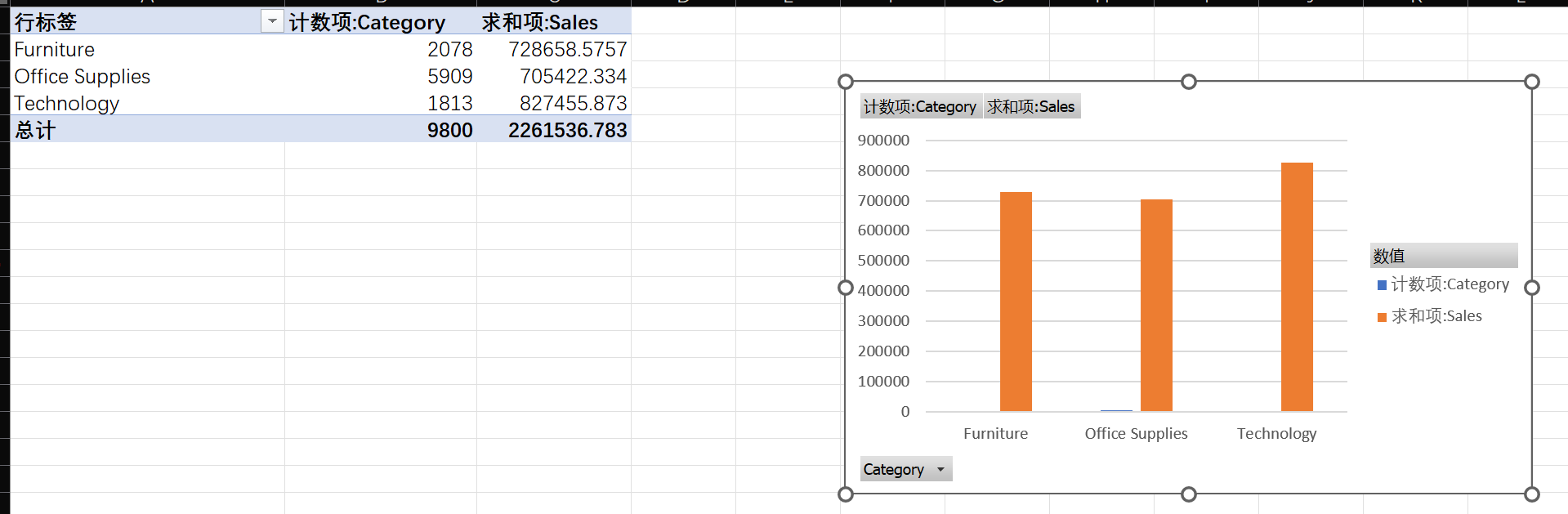
这里可以看出,虽然Office Supplies订单数占比超过一半,但是可能平均客单价低,导致其低于其他两个品类的销售额,而最赚钱的品类是Technology,凭借最少的订单数却获得了最高的销售额,可见其平均客单价之高
-
子类别深度挖掘:
-
明星产品 :在
Sub-Category层面,找出销售额排名前5的子类别。
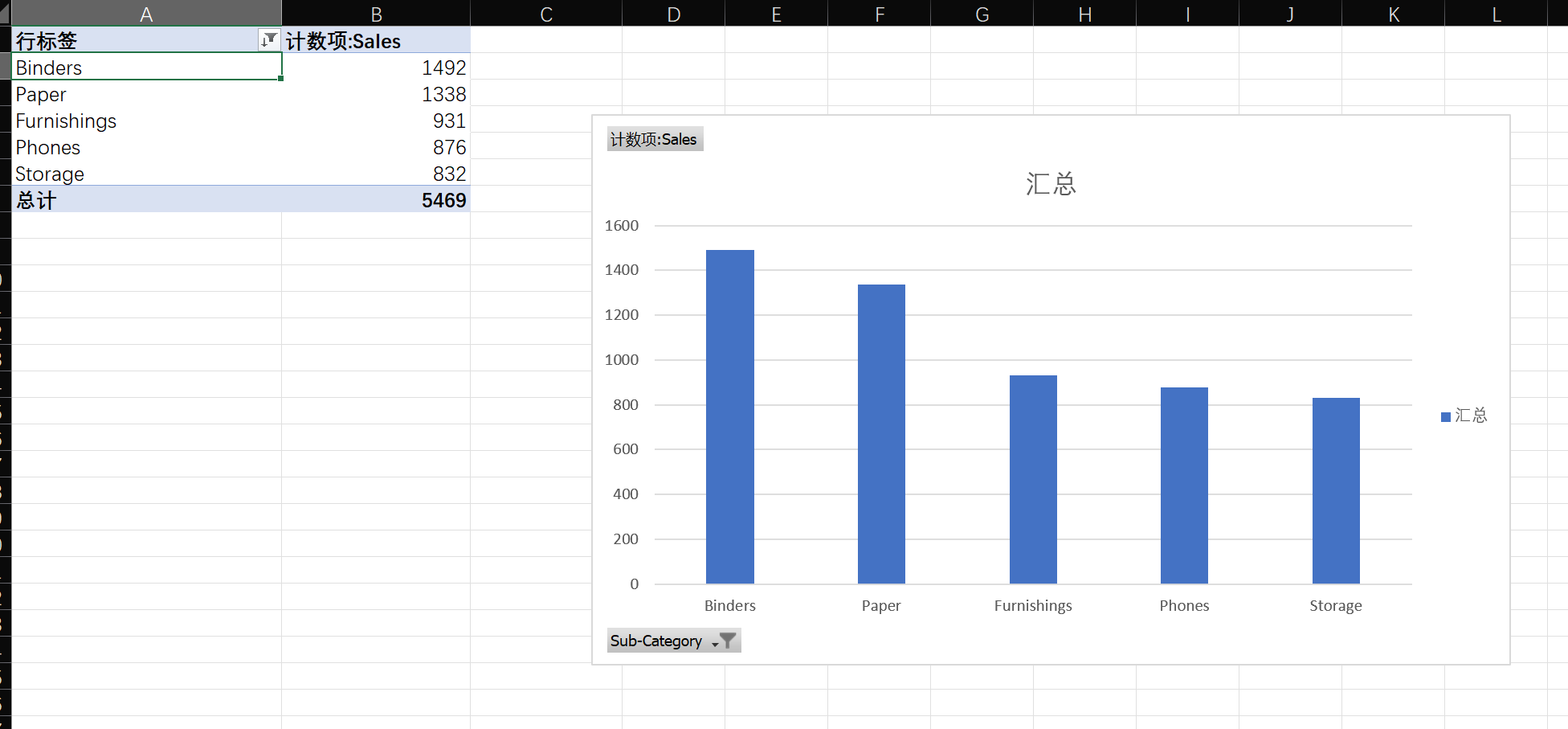
-
潜力/问题产品 :找出销售额排名倒数5名的子类别。
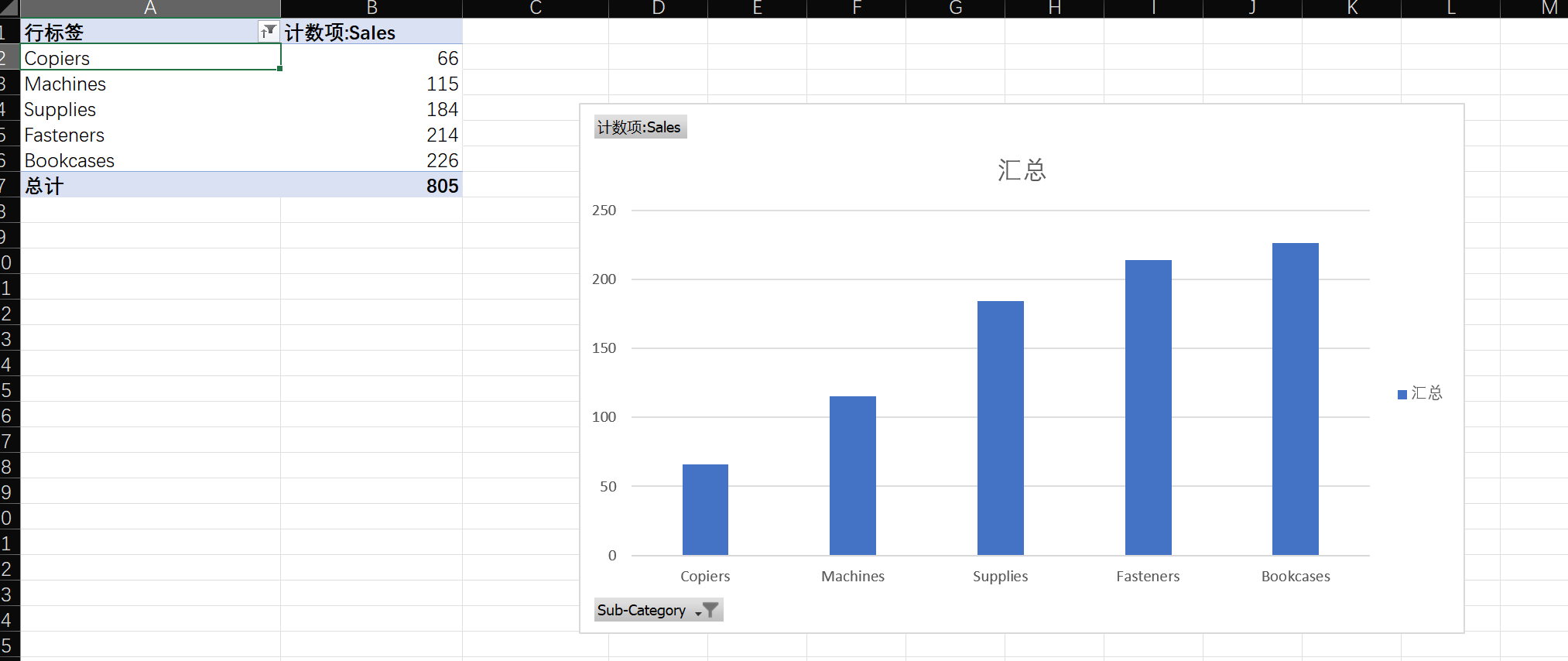
-
-
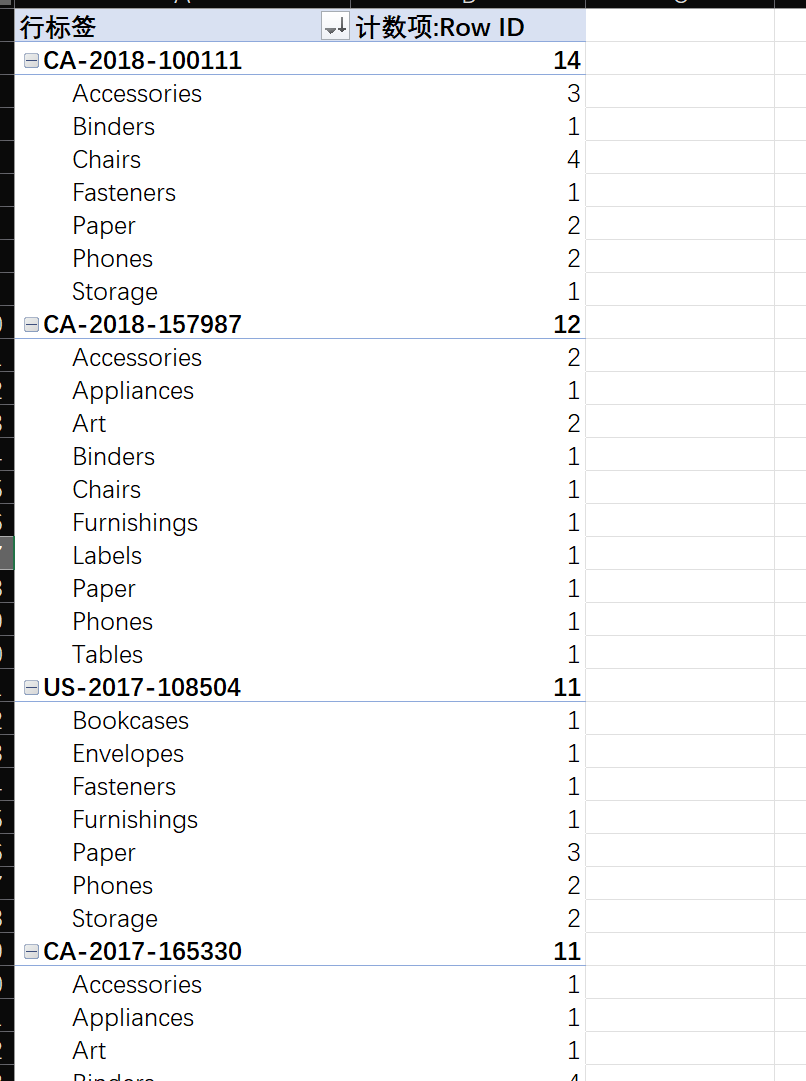
产品相关性初探 :寻找同一个
Order ID下,最常被一起购买的产品组合。例如,买了"Binders"的订单,是不是也经常买"Paper"?(提示:可以使用数据透视表,将Order ID拖到行,Product Name或Sub-Category拖到列,值区域放Row ID的计数,然后手动观察几笔大订单。)
模块五:综合诊断与洞察 (Diagnosis & Insights)
目标:结合多个维度,找出更深层次的问题。
- 地区+产品交叉分析 :制作一个二维表,行是
Region,列是Category,值是总销售额。
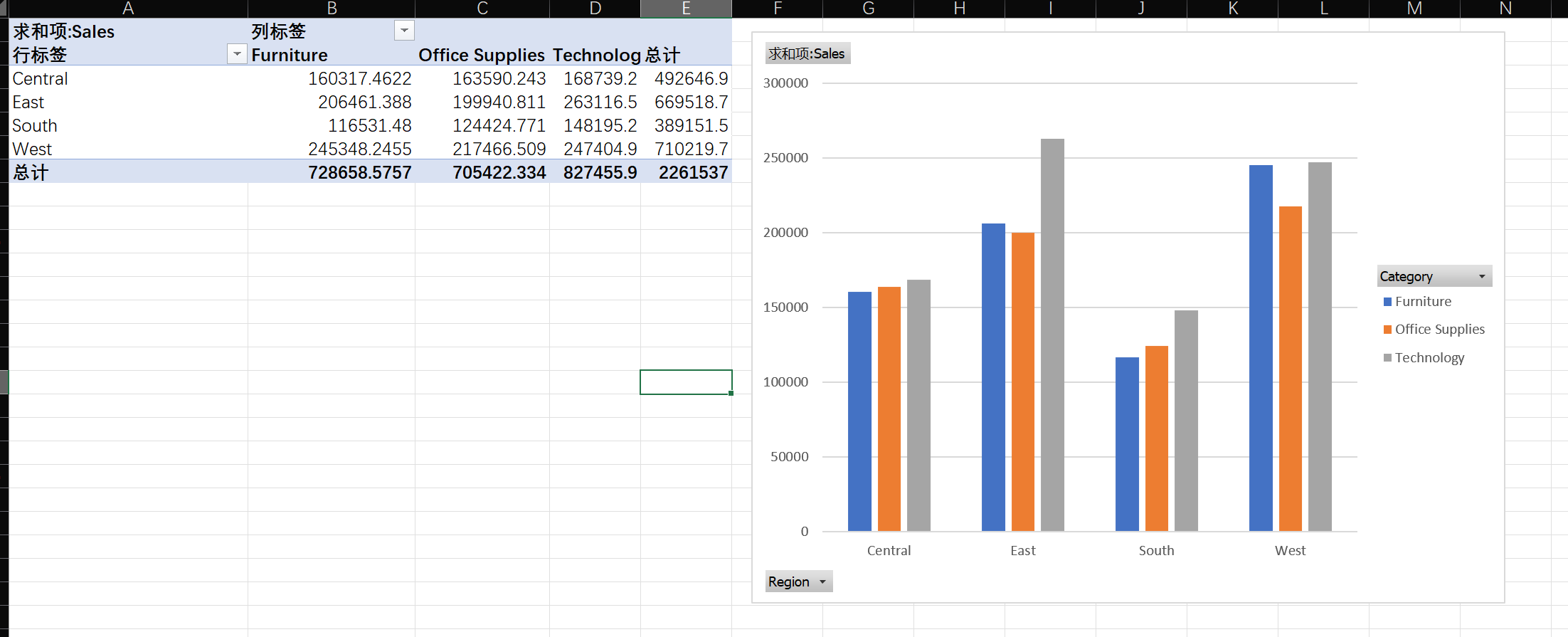
- 哪个品类在哪个地区表现最好?
Furniture在West,Office Supplies也在West,Technology在East - 哪个品类在哪个地区表现最差?这可能是需要重点关注的市场。
Furniture在South,Office Supplies在South,Technology也在South
可能是因为South和Central潜力都还没有被发掘出来
- 哪个品类在哪个地区表现最好?
- 客户+产品交叉分析 :分析不同的
Segment最喜欢购买哪个Sub-Category的产品?(例如,Corporate客户是否更倾向于买Technology产品?)
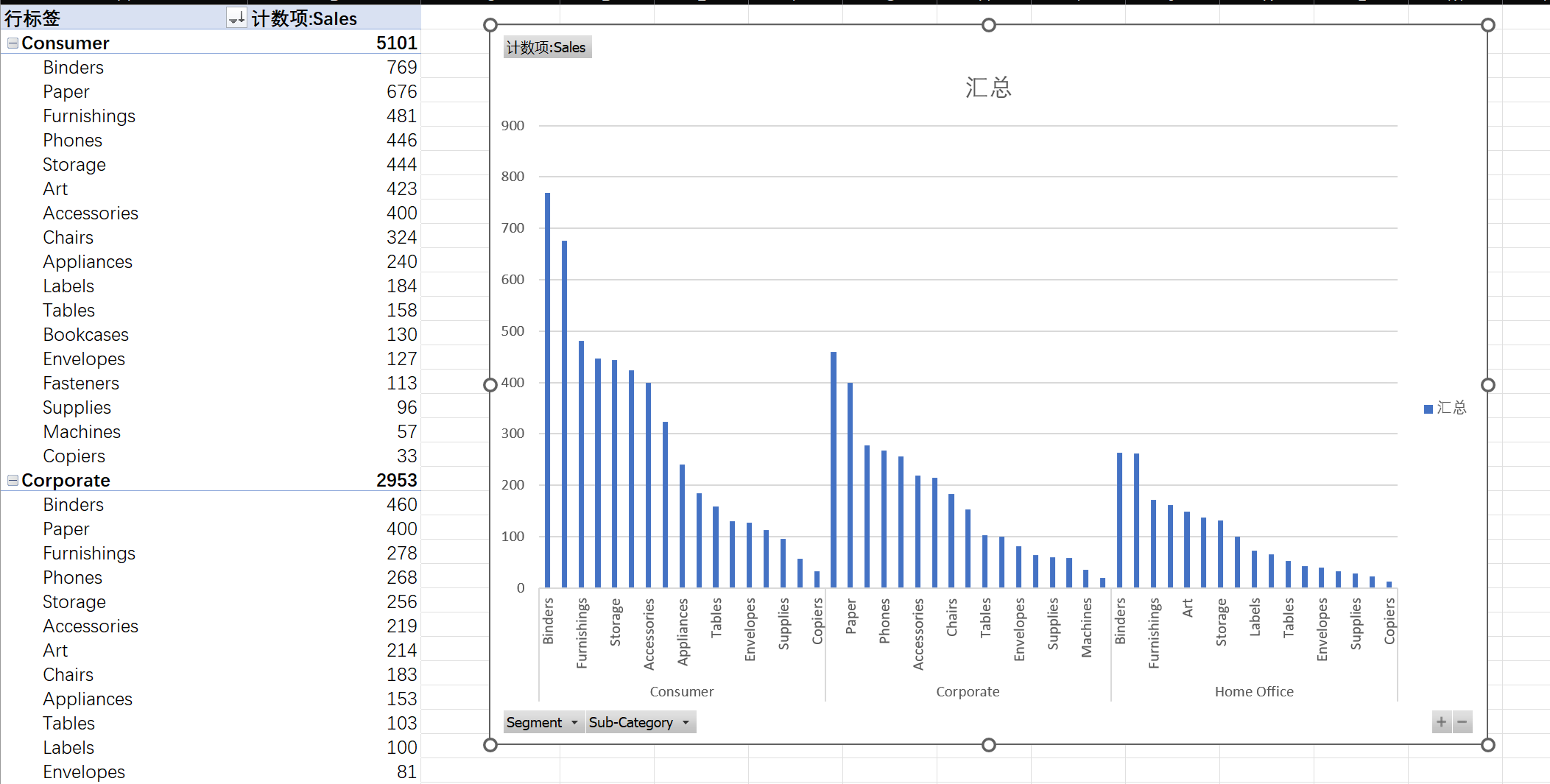
模块六:为管理层制作报告 (Reporting)
目标:将分析结果转化为清晰的可视化报告。
- 制作仪表板 :在一个新的Excel工作表 (Sheet) 中,制作一个简易的仪表板。至少包含以下元素:
- 关键指标卡片 (KPI Card):总销售额、总订单数、平均每个订单的销售额。
- 趋势图 :按
Year和Month的销售额折线图。 - 占比图 :按
Segment和Category的销售额占比环形图或柱状图。 - 排行榜:销售额Top 5 的子类别和 Bottom 5 的子类别列表。
- 撰写一句话洞察:为仪表板上的每一个图表,在旁边用一句话写下你的核心发现。例如:"Technology品类是公司收入的核心支柱,但中西部地区表现明显弱于其他地区。"