
🎈主页传送门**:良木生香**
🔥个人专栏:《C语言》 《数据结构-初阶》 《程序设计》《鼠鼠的C++学习之路》
🌟人为善,福随未至,祸已远行;人为恶,祸虽未至,福已远离

前言:我们为了更加高效的入门C++,特意花费了三篇文章的篇幅讲解C语言和C++的不同之处,以及C++针对C语言的不足做出了哪些改变,有命名空间、输入输出、缺省参数等等方面的内容,具体的文章链接我会放在本篇文章的最后,大家可以继续参考。有了前三这篇文章的铺垫,我们就可以正式入门C++了!那么我们就从最基础的"类和对象"开始学习。在"类和对象这一板块中,我将花费大约三篇文章的篇幅进行讲解,话不多说,直接进入今天的主题吧:类和对象(上)。
一、类的定义
1.1、类定义格式
类其实我们不用把它看得太复杂,其实它就是一个加强版的结构体。类又是有什么构成的呢?请看下面:
cpp
class Stack {
//类中的内容
};
cpp
struct Stack {
//结构体中的内容
};这样一对比,两者其实非常相似。要注意的是,{}之后的分号不能被省略。下面我们通过数据结构中的栈(Stack)为例子为大家更详细地介绍类以及对象。
cpp
#include<iostream>
using namespace std;
//定义类
class Stack {
//成员函数
void Init();
void Push();
//成员变量
int a;
int top;
int capacity;
};
int main() {
Stack s1;//这里的Stack就是类,s1就是对象
Stack s2;//s2也是对象
return 0;
}在上面的代码中:class是定义类的关键字,Stack为类的名称,**{}**中的内容为类的主体,也可以理解为类所包含的事物(这一类中含有那些东西),类中的变量称为成员变量或类的属性,类中的函数称为成员函数或类的方法
在主函数中,Stack就是类名,但同时也是类型(类名即类型),可以直接用类的名称做类型来定义对象,不像C语言中的结构体(struct)还要typedef 一下才能使用结构体名。那如何在主函数中使用对象呢?这样:
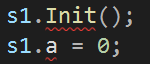
抛开红素警告波浪线不谈,这句话的语法是这样的:s1为对象,","为访问符,Init()和a为类的成员。但是就我们现在的代码,为什么会有红色波浪线?我们编译看看是什么问题:

想要解决这个问题,那就不得不讲到类和对象中的一个重点内容了:访问限定符
1.2、访问限定符
在C++中引入了封装这一个概念,我们知道,C++是一个面向对象的编程语言,那它就会有面向对象的三大特性:封装、继承 、多态,而C++的访问限定符就体现了封装这一特性。
C++的限定访问符分为三种:public、private、protected。
public有"公共的"的意思,那么在C++中就说明在public下的成员是公共的,是可以在类外直接进行访问的,protected和private是不允许在类外直接进行访问的(即我们不希望被修改的成员就放到这两个限定访问符下),在我们阶段中,两者没有什么差别,具体的内容等在后面我们讲到继承的再展开讲讲。
我们该如何使用访问限定符?C++中规定,访问权限作⽤域从该访问限定符出现的位置开始直到下⼀个访问限定符出现时为⽌,如果后⾯没有访问限定符,作⽤域就到 }即类结束。就像下面这样:
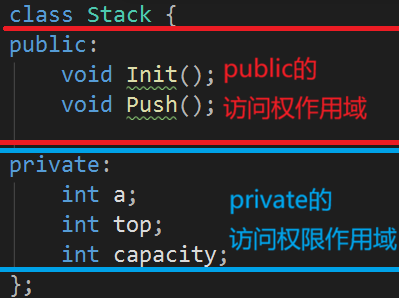
如果没有private,那么就是这样:

我们知道,struct在C++中是兼容C语言的,它既可以像C语言那样使用,也可以像C++中的class类这样使用,那么,当类中什么访问限定符都没有的时候,在class中是默认为私有(private),而struct中则是默认为共有(public)。当struct作为类使用时,两者仅仅在这点上有所不同,其他完全相同,在C++中大多数都使用class,但有些情况用struct会更好,像:
cpp
struct ListNode{
ListNode* next;//不用像C语言那样写完struct ListNode* next;
Elemtype data;
};这样的场景就是不需要对数据继续保护,写struct反而效率更高。
那么回到1.1最后的问题,为什么直接访问Init()会编译错误?就是因为在1.1的代码中,class类里没有加上访问限定符,默认里面的成员全部都是私有的,不可被访问的,才导致编译错误。
1.3、成员命名
我们在编写代码的时候习惯在类里面的成员前面加上标识符,像一些公司是这么做的:
cpp
class Stack{
int* _a;//百度
int capacity;//谷歌,阿里
int mcapacity;//其他公司的命名方法
int m_capacity;
}注:这里展示的代码是为了让大家更好的看出公司之间的明明差异,所以并未规范定义类中成员。
那为什么要给这些成员加上前缀或后缀标识符呢?就是为了应对以下这种场景:
cpp
class Stack {
public:
void Init(int capacity) {
a = nullptr;
top = 0;
capacity = capacity;//在这里我们无法分辨哪个是形参那个是实参
}
private:
int* a;
int top;
int capacity;
};当成员函数中的形参和成员变量同名时,我们就无法分辨出哪个是实参哪个是形参了,虽然我们编写的时候能分得清,但是下一个接手我们代码的同事就不一定看得懂了,所以应该改成这样:
cpp
class Stack {
public:
void Init(int capacity) {
//...
_capacity = capacity;
}
private:
int* _a;//在成员变量的名字上都加上标识符
int _top;
int _capacity;
};这样一来我们就能分得清哪个是实参哪个是形参了。
一般公司都会采用以下两种命名法:
驼峰命名法:
小驼峰命名法:lowerCamelCase
第一个单词首字母小写,后面每个单词的首字母大写(常用于变量名、函数名)
大驼峰命名法:UpperCamelCase
每个单词首字母都大写,包括第一个单词(用于类名、构造函数名等)
蛇形命名法:
单词之间用下划线相连接:stack_init();
小贴士:成员函数在类里面是默认为inline函数(内联函数),但是具体是不是内联函数就要看编译器的决定和函数的代码量了(具体介绍在上一篇文章中有所体现)。
1.4、类域
我们在C++入门基础这一块就说了C++有四个域:全局域,局部域,命名空间域,类域。前三个我们都讲过了,类域之所以留到现在来讲,是因为之前没学习到类和对象,直接上手反而会适得其反。
类域是支持声明与定义分离的,即在不同的源文件中。我们来看看下面的代码:
cpp
#include<iostream>
#include<stdlib.h>
using namespace std;
//定义类
class Stack {
public:
void Init(int capacity);
void Push();
private:
int* a;
int top;
int capacity;
};
//定义Init()函数
//如果仅仅是void Init(int n)是会报错的
void Stack::Init(int n) {
capacity = n;
a = (int*)malloc(sizeof(int) * capacity);
top = 0;
}
int main() {
int n = 10;
Stack s;
s.Init(n);
return 0;
}我们在Stack类中声明了Init()函数,并没有在类中实现它,这样是可以的,但是要注意的一点是,在类外面定义函数要给函数指定类域,否则会编译错误,像注释上说的。
本来是可以直接在类中进行定义函数的,但为什么还要将函数放到外面来定义呢?为什么会出现"类域"这种概念呢?
那是因为,在定义类时可能会产生同名变量或者同名函数(又是我们也会将函数称之为"接口"),在项目工程中,由于庞大的代码量,就要建立.h文件和.cpp文件,这时候如果不将一部分函数的声明与定义分开,在编译的时候可能就会编译失败。
二、类的实例化
2.1、实例化的概念
现在我们来思考一个问题:如何判断类中的变量是定义还是声明?我们要知道,只有作为对象的一部分才是定义,因为系统为它开了空间。
讲到这里,我们就要对类和对象做一个新的理解:
类:是描述这一类事物的属性,即这类事物是什么,叫什么。相当于设计图纸,蓝图。
对象:是根据类的定义所产生的,是对类的实现,将类中的事物具体化。相当于根据设计图纸创造出具体事物。
像这段代码中:
cpp
#include<iostream>
using namespace std;
//类的定义
class Stack {
public:
void Init();
void Push();
private:
//这里只是声明,没开空间
int* a;
int top;
int capacity;
};
int main() {
Stack s; //实例化出s
s.Init();
return 0;
}我们class的Stack就是设计出了设计图纸,Stack s的s就是根据图纸创造出的一个实体,是Stack的具体实现,这个过程我们称之为类的实例化。一个类可以实例化出多个对象,是一对多的关系。实例化出的对象系统会为其分配空间
2.2、对象大小
我们想要计算对象的大小,该怎么计算?如果有成员变量和成员函数同时出现呢?又该怎么计算?
首先,成员函数被编译之后是一段指令,无法在对象中存储,这些指令都单独存储在一个独立的代码段,对象如果非要存储的话,那就只能存储指针, 但是如果实例化出100个对象,就要有100个函数指针,则不是闹嘛,所以成员函数是不包含在对象中的。
其次,由于成员变量是不确定的值,都有独立的存储空间,所以成员变量是包含在对象中的。
那现在知道了对象中只包含成员变量,那又该怎么计算呢?符合内存对齐规则即可。
内存对齐规则:
- 第⼀个成员在与结构体偏移量为0的地址处。
- 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
- 注意:对⻬数 = 编译器默认的⼀个对⻬数 与 该成员⼤⼩的较⼩值。
- VS中默认的对⻬数为8
- 结构体总⼤⼩为:最⼤对⻬数(所有变量类型最⼤者与默认对⻬参数取最⼩)的整数倍。
如果嵌套了结构体的情况,嵌套的结构体对⻬到⾃⼰的最⼤对⻬数的整数倍处,结构体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体的对⻬数)的整数倍。
三、this指针
我们依旧先看这段代码:
cpp
#include<iostream>
using namespace std;
class Data {
public:
void Init(int year, int month, int day) {
_year = year;
_month = month;
_day = day;
}
void Print() {
cout << _year << ' ' << _month << ' ' << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main() {
Data d1;
Data d2;
d1.Init(2026, 1, 1);
d1.Print();
d2.Init(2026,12,31);
d2.Print();
return 0;
}在代码中,我对d1和d2都传入了参数,下面是运行结果:
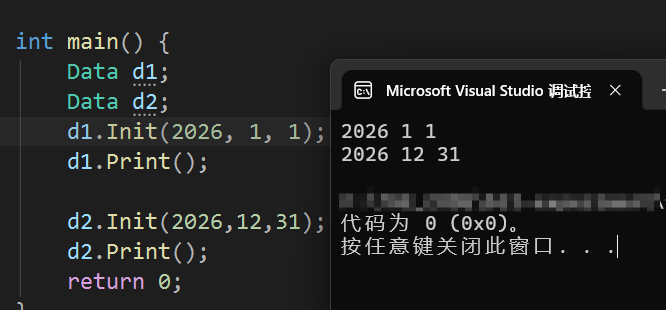
那么问题来了,d1在传入参数给Init()时,它是怎么知道这是d1的?d2传入参数的时候,它又是怎么知道这时d2的?
这就是C++的一个"秘籍"------this指针
编译器会在第一个参数的位置加上this指针,那么在类里面的时候就是这样子的:
cpp
void Init(Data* const this,int year,int month,int day);这里使用const修饰this指针,就是不希望this不会被修改,保护this指针一直指向对应的对象。那么对象在传参的时候就是这样的:
cpp
d1.Init(&d1,2026,1,1);那么类中的成员函数在访问成员变量都是通过this指针进行访问的:
cpp
class Data {
public:
void Init(int year, int month, int day) {
//相当于this->_year = year;
_year = year;
this->_month = month;
this->_day = day;
}
void Print() {
cout << _year << ' ' << _month << ' ' << _day << endl;
}
private:
int _year;
int _month;
int _day;
};这时候就有同学问了,那我不想让编译器这么累,我能不能在写代码的时候自己加上this指针啊?像这样:
cpp
class Data{
public:
void Init(Data* const this,int year,int month,int day){
this = nullptr;
//....
}
private:
//...
}
int main(){
Data s1;
s1.Init(&s1,2026,4,25);
return 0;
}答:不能!!!
C++中规定,不能在形参和实参的位置显式写上this指针,编译器会自己处理,但是可以在函数体内显式使用,就像上两段代码展示的一样。
有了前面的铺垫,我们来看看两道题:
Qustion1 :
1.下⾯程序编译运⾏结果是(C)
A、编译报错 B、运⾏崩溃 C、正常运⾏
cpp
#include<iostream>
using namespace std;
class A
{
public:
void Print()
{
cout << "A::Print()" << endl;
}
private:
int _a;
};
int main()
{
A* p = nullptr;
p->Print();
//(*p)->Print(); 也是一样的答案
return 0;
}答案是:正常运行。为什么?因为:虽然p是类A定义下的空指针,但是在调用函数的时候并不会有解引用这个过程,因为在成员函数的地址实在编译的时候就已经确定好了的,而且与对象是分离开的,当我用空指针去执行打印,是不会访问到类中的变量的,因此就没有解引用这一说法,同时也将会将p的地址传进Print()中,就相当于你拿着空的快递单号去快递找你,跟老板说我要找快递,然后老板就念一遍你的快递单号而已,并不会怎么样。但如果再加上这一行代码:
cpp
cout<<_a<<endl;那就错了,因为这段代码相当于:
cpp
cout<< this->_a <<endl;是要通过this解引用找到_a的,但是this传进来的是nullptr(0),就不能解引用了,这是后就会运行崩溃。
Qustion2:
2.下⾯程序编译运⾏结果是(B)
A、编译报错 B、运⾏崩溃 C、正常运⾏
cpp
#include<iostream>
using namespace std;
class A
{
public:
void Print()
{
cout << "A::Print()" << endl;
cout << _a << endl;
}
private:
int _a;
};
int main()
{
A* p = nullptr;
p->Print();
return 0;
}这段代码正确答案是B,运行崩溃。为什么?因为p是一个空指针,在执行到cout<<_a<<endl;这句话的时候其实是:cout<<this->_a<<endl;在Print()中,p直接将指针传入this形参中,this这时候就是空指针,空指针是不能解引用的,所以会运行崩溃。
但是为什么不是编译报错呢?因为编译报错是在语法层面的错误,但是编译器在编译的时候是无法检测出空指针的错误的,只有在运行时才能检查出来。
Qustion3:
- this指针存在内存哪个区域的 (A)
A. 栈 B.堆 C.静态区 D.常量区 E.对象里面
四、C++和C语言实现Stack对比
先上代码:
C语言实现Stack:
cpp
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->top = 0;
ps->capacity = 0;
}
void STDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
void STPush(ST* ps, STDataType x)
{
assert(ps);
// 满了, 扩容
if (ps->top == ps->capacity)
{
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType * tmp = (STDataType*)realloc(ps->a, newcapacity *sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
ps->a = tmp;
ps->capacity = newcapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
bool STEmpty(ST * ps)
{
assert(ps);
return ps->top == 0;
}
void STPop(ST * ps)
{
assert(ps);
assert(!STEmpty(ps));
ps->top--;
}
STDataType STTop(ST * ps)
{
assert(ps);
assert(!STEmpty(ps));
return ps->a[ps->top - 1];
}
int STSize(ST * ps)
{
assert(ps);
return ps->top;
}
int main()
{
ST s;
STInit(&s);
STPush(&s, 1);
STPush(&s, 2);
STPush(&s, 3);
STPush(&s, 4);
while (!STEmpty(&s))
{
printf("%d\n", STTop(&s));
STPop(&s);
}
STDestroy(&s);
return 0;
}C++是实现Stack代码:
cpp
#include<iostream>
using namespace std;
typedef int STDataType;
class Stack
{
public:
// 成员函数
void Init(int n = 4)
{
_a = (STDataType*)malloc(sizeof(STDataType) * n);
if (nullptr == _a)
{
perror("malloc申请空间失败");
return;
}
_capacity = n;
_top = 0;
}
void Push(STDataType x)
{
if (_top == _capacity)
{
int newcapacity = _capacity * 2;
STDataType * tmp = (STDataType*)realloc(_a, newcapacity *
sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
_a = tmp;
_capacity = newcapacity;
}
_a[_top++] = x;
}
void Pop()
{
--_top;
}
bool Empty()
{
return _top == 0;
}
int Top()
{
return _a[_top - 1];
}
void Destroy()
{
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
private:
// 成员变量
STDataType * _a;
size_t _capacity;
size_t _top;
};
int main()
{
Stack s;
s.Init();
s.Push(1);
s.Push(2);
s.Push(3);
s.Push(4);
while (!s.Empty())
{
printf("%d\n", s.Top());
s.Pop();
}
s.Destroy();
return 0;
}C++中数据和函数都放到了类⾥⾯,通过访问限定符进⾏了限制,不能再随意通过对象直接修改据,这是C++封装的⼀种体现,这个是最重要的变化。这⾥的封装的本质是⼀种更严格规范的管理,避免出现乱访问修改的问题。当然封装不仅仅是这样的,我们后⾯还需要不断的去学习。
同时C++中有⼀些相对⽅便的语法,⽐如Init给的缺省参数会⽅便很多,成员函数每次不需要传对象地址,因为this指针隐含的传递了,⽅便了很多,使⽤类型不再需要typedef⽤类名就很⽅便
那么以上就是本次所有的内容了
文章是自己写的哈,有什么描述不对的、不恰当的地方,恳请大佬指正,看到后会第一时间修改,感谢您的阅读~