前言
前面分别讲了 AdvancedRAG 基于检索前和检索中的优化。当然,在检索后也有需要优化的点。
与检索前处理相对应,这是在完成检索后对检索出的相关知识块做必要补充处理 的阶段。比如,对检索的结果借助更专业的排序模型与算法进行重排序或者过滤掉一些不符合条件的知识块等,使得最需要、最合规的知识块处于上下文的最前端,这有助于提高大模型的输出质量。
Rerank-重排序
重排序 接收初步检索返回的Top-K个候选文档(例如前50或100个),使用一个更强大、更精细的模型重新评估每个文档与用户查询的相关性,并据此重新排序,最终只将Top-N个(例如前3或5个)最相关的文档送入 LLM 生成答案。
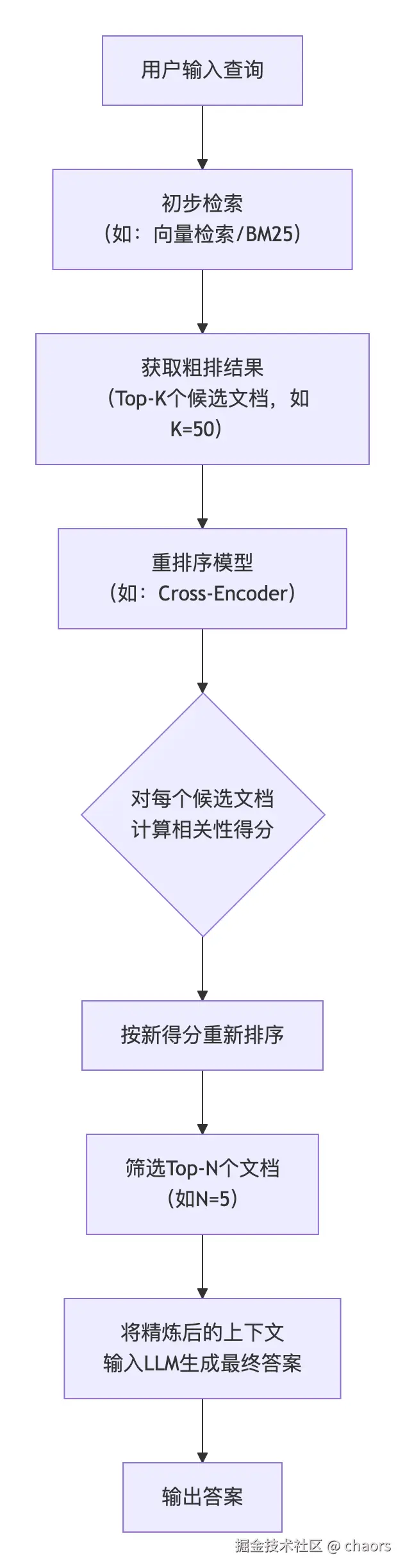
那么,为什么要进行重排序呢?其优化的点在哪呢?
-
本质:质量守门员
-
语义鸿沟:向量相似度高不代表真正相关。🌰:
- query:"苹果手机怎么截图?"
- result:可能含关于"水果苹果"的文档
- reason:"苹果"一词的向量表征相近
-
召回与精度的矛盾 :为了提高召回率(Recall),我们通常需要扩大初步检索的范围(增大K值),但这会引入大量噪声 文档,直接喂给LLM会降低生成质量,甚至导致 "幻觉"
- query(K=5):"感冒了怎么办?"
- result(K=5):可能漏掉**"流感"相关治疗、"高烧"相关应对**
- reason:"流感"、"高烧" 和 "感冒"向量距离有一定差距
- query(opt_K=50):"感冒了怎么办?"
- result(opt_K=5):返回大量相关信息,包括"感冒了真难受 "等无用信息。recall提升,但精度不达标。且这些信息直接投喂也会造成不必要的Token成本
- reason:"感冒"向量相关
-
缺乏深度交互 :Bi-Encoder 将查询和文档分别编码为向量再计算相似度,两者在编码过程中没有任何交互,无法捕捉细粒度的语义逻辑关系(如因果关系、否定关系)。🌰:
- query:"我不喜欢《飞驰人生》这部电影"
- result:可能将 "《飞驰人生》太棒了,我很喜欢" 排在最前面
- reason:"飞驰人生"、"喜欢"这两个词的权重可能极高。Bi-Encoder在编码时忽略了"不"这个否定词对"喜欢"的修饰
Bi-Encoder 思考🤔
Bi-Encoder(双塔模型)是信息检索(IR)和自然语言处理(NLP)中的一种经典架构。
- 目标:解决大规模语义匹配的效率问题
- 核心:独立编码,向量内积
RAG 系统中的向量检索就是使用的 Bi-Encoder 。前面也说到由于 Bi-Encoder 无法捕捉细粒度语义逻辑的缺陷会导致我们得到相反的答案。
- query:"我不喜欢《飞驰人生》这部电影"
- result:可能将 "《飞驰人生》太棒了,我很喜欢" 排在最前面
- reason:"飞驰人生"、"喜欢"这两个词的权重可能极高。Bi-Encoder在编码时忽略了"不"这个否定词对"喜欢"的修饰
那么这里就有两个疑问❓了:
- Bi-Encoder 难道没有自注意力机制吗? 为什么会忽略"不"对"喜欢"的修饰
- Bi-Encoder 虽有自注意力,但其输出的是
静态向量。 - 编码:自注意力让"不"关注到"喜欢",将整句编码成含否定语义的向量
V_Q_NOT。 - 检索:由于
向量表征模糊性,V_Q_NOT包含"电影"、"喜欢"、"不";V_D包含了"电影"、"喜欢";"电影"和"喜欢"这两个强正向信号占据了主导地位 ,发生了向量坍缩
- Bi-Encoder 虽有自注意力,但其输出的是
- 即使 Bi-Encoder忽略。那么,我们本身是将"query + document"一起抛给 LLM的,LLM 自身不会察觉这种矛盾吗?
- LLM 当然能察觉到这种语义冲突,但他是后置 的,且是极其消耗Token的。用昂贵的LLM去读垃圾文档,是巨大的资源浪费。相反,
重排序模型(如BGE-Reranker)通常只有几百MB,推理一次的成本是 LLM 的千分之一甚至万分之一。
- LLM 当然能察觉到这种语义冲突,但他是后置 的,且是极其消耗Token的。用昂贵的LLM去读垃圾文档,是巨大的资源浪费。相反,
RAG-Fusion
RAG-Fusion 通过使用多 重查询生成和互惠排名融合(Reciprocal Rank Fusion) 对搜索结果进行重新排序。在Multi Query的基础上,对其检索结果进行重新排序(即reranking)后输出Top K个最相关文档,最后将这top k个文档喂给LLM并生成最终的答案。
是不是从定义就能看出,RAG-Fusion 常与检索前查询优化的多路召回相结合。其实检索后重排序往往都会与多路召回相结合。
rag-fusion-query-generation
这个模板是RAG-Fusion(检索增强生成融合) 技术栈中的一个核心组件。该模板定义了一个提示词(Prompt),专门指导大语言模型(LLM)基于用户的原始单一问题,生成多个相关但角度不同的查询**。当然,我们也可以自定义生成 PromptTemplate。
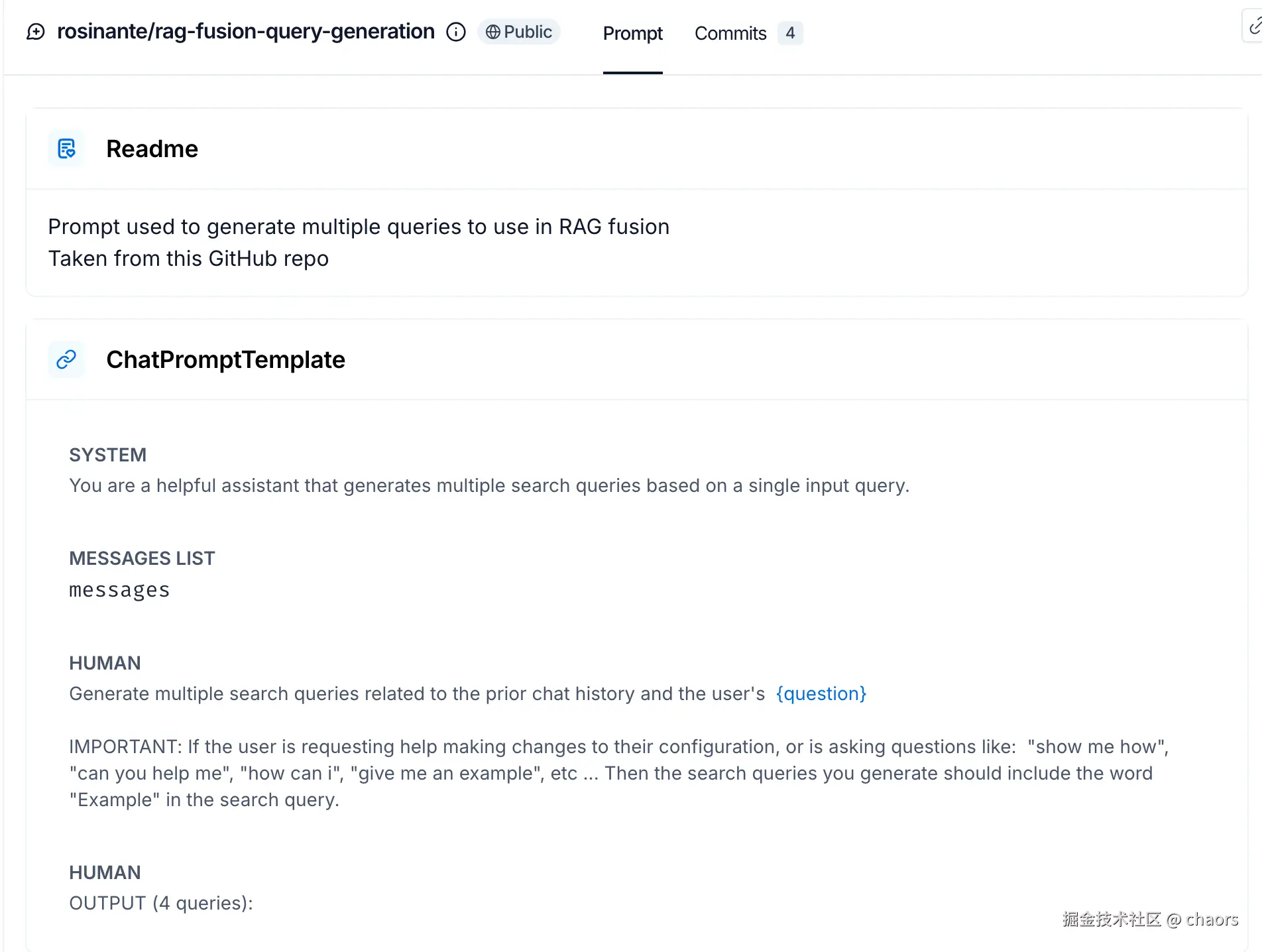
更多在线 PromptTemplate 详见 LangChain Hub。
hub
旧有的在线 PromptTemplate 加载方式。Langcchain 1.0后 hub 已经放到了 langchain_classic 兼容包,可见其边缘化。
ini
prompt = hub.pull("langchain-ai/rag-fusion-query-generation")LangSmith
LangSmith 是一个AI应用开发平台,提供链的跟踪、评估、监控等功能。Langcchain 1.0 后,LangSmith 平台正在整合 Hub 的功能。后续关于 hub 的使用推荐使用 LangSmith 组件。
-
api_key申请和配置:官网 - Settings(左下角) - API Keys。然后在本地 Bash配置- export LANGSMITH_API_KEY="lsv2_pt_你的实际密钥"
- export LANGSMITH_TRACING="true"
-
Clent
ini
def get_langsimth_client():
return Client(
api_key=os.getenv(LANGSMITH_API_KEY_OS_VAR_NAME), # 如果传入,会覆盖环境变量
api_url=LANGSMITH_API_URL, # 覆盖端点
)- Hub 使用
ini
langsimth_client = get_langsimth_client()
prompt = langsimth_client.pull_prompt("langchain-ai/rag-fusion-query-generation")Coding
RRF算法
python
@chain
def reciprocal_rank_fusion(results: list[list], k=60):
"""互逆排序融合算法,用于合并多个排序文档列表
Args:
results: 包含多个排序文档列表的二维列表
k: 融合公式中的平滑参数(默认60),值越小排名影响越大
Returns:
按融合分数降序排列的文档列表,每个元素为(文档对象, 分数)元组
"""
# 初始化融合分数字典(key=序列化文档,value=累计分数)
fused_scores = {}
# 遍历每个检索结果列表(每个查询对应的结果)
for docs in results:
# 对当前结果列表中的文档进行遍历(rank从0开始计算)
for rank, doc in enumerate(docs):
# 序列化文档对象为字符串(用于唯一标识)
doc_str = dumps(doc)
# 初始化文档得分(如果是首次出现)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# 计算并累加RRF分数:1 / (当前排名 + k)
# 排名越靠前(rank值小)的文档获得的分数越高
fused_scores[doc_str] += 1 / (rank + k)
# 按融合分数降序排序(分数越高排名越前)
reranked_results = [
(loads(doc), score) # 反序列化还原文档对象
for doc, score in sorted(fused_scores.items(),
key=lambda x: x[1],
reverse=True)
]
return reranked_results核心调用
python
original_query = "人工智能的应用"
'''
generate_queries会生成4个多角度的query,
retriever.map()的作用是根据generate_queries的结果映射出4个retriever(可以理解为同时复制出4个retriever)
与generate_queries生成的4个query对应,
并为每个query检索出来的一组相关文档集(默认为4个相关文档),
那么4个query总共可以生成16个相关文档。
最后会经过RRF算法重新排序后输出最相关的文档
'''
chain = generate_queries | retriever.map() | reciprocal_rank_fusion
# 输入结果列表
result_list = chain.invoke({"original_query": original_query})
# 提取文档内容和对应分数
contents = [doc[0].page_content for doc in result_list]
scores = [doc[1] for doc in result_list]
combined_tuples = list(zip(contents, scores))
print("--"*15,"最相关的文档及其得分:")
for item in combined_tuples:
print(item)Rerank Model
除了 RAG-Fusion 这样的重排技术,我们也可以让一个轻量级的大模型来帮我们重排序。一个经过精调的、参数规模相对较小的 LM 就是我们常说的重排序模型(🌰:阿里-gte-rerank-v2)。
- 目标:为"查询-文档"对计算一个精细的相关性分数,而不生成文本
- 核心:
-
上下文语义:理解query中"保养"和文档中"维护"、"清洁"是同义。
-
意图匹配:判断用户问的是"故障排除"还是"操作指南"。
-
逻辑蕴含 :识别文档是否真正回答了query中的核心问题。
-
重排序模型
python
def get_ali_rerank(top_n=3):
'''
通过LangChain获得一个阿里重排序模型的实例
:return: 阿里通义千问嵌入模型的实例
'''
return DashScopeRerank(
model=ALI_TONGYI_RERANK_MODEL, dashscope_api_key=os.getenv(ALI_TONGYI_API_KEY_OS_VAR_NAME),
top_n=top_n
)示例代码
ini
reranker = get_ali_rerank()
query = "孕妇感冒了怎么办"
documents = [
"感冒应该吃999感冒灵",
"高血压患者感冒了吃什么",
"感冒了可以吃感康,但是孕妇禁用",
"感冒了可以咨询专业医生"
]
scores = reranker.rerank(documents,query)
print(scores)
documents = [
Document(
page_content="感冒应该吃999感冒灵",
metadata={"source": "999感冒灵"},
),
Document(
page_content="高血压患者感冒了吃什么",
metadata={"source": "高血压患者"},
),
Document(
page_content="感冒了可以吃感康,但是孕妇禁用",
metadata={"source": "感康"},
),
Document(
page_content="感冒了可以咨询专业医生",
metadata={"source": "专业建议"},
),
]
scores = reranker.compress_documents(documents, query)
print(scores)LongContextReorder
不同于重排序模型,LongContextReorder 关注的是上下文本身,本质上他并不进行重新排序(使用模型或者其他维度),旨在解决注意力偏差。
- 本质:简单的交叉替换
代码示例
ini
# 按相关性排序5,4,3,2,1,5是最相关的,相关性依次递减
documents = [
"相关性:5",
"相关性:4",
"相关性:3",
"相关性:2",
"相关性:1",
]
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(documents)注意力偏差
检索结果变成了 5, 3, 2, 1, 4,这样的结果投喂给 LLM 真的能提升答案的准确性吗?
研究发现,当 LLM 处理长序列输入(如多个检索到的文档)时,其对信息的关注度并非均匀分布。模型关注倾向于呈现显著的U型曲线:
-
首因效应 (Primacy Bias) :模型对输入序列开头的 token 关注度最高。
-
近因效应 (Recency Bias) :模型对输入序列末尾的 token 关注度次高。
-
"迷失在中间" (Lost in the Middle) :位于序列中间部分的信息,无论其本身多重要,都容易被忽略,导致检索和推理性能大幅下降。
那为什么会出现这样的注意力偏差呢?
- 每个token的"注意力预算竞争 "。LLM 在预训练过程中学会高效的资源分配方式,将有限的注意力资源,优先分配给最可能预测下一个词的token。而在自然语言里,开头和结尾就成了理解的重头。
- 位置编码的"远程衰减"。
明白了上述原理,就能理解 LongContextReorder 的骚操作了。简而言之,就是这么一回事:
- 人类相关性:5(最相关), 4(次相关),3, 2, 1
- LongContextReorder 摸透了 LLM 的心思,预先做了处理
- LLM 接收序:5, 3, 1, 2, 4
- 由于 LLM 的注意力偏差 问题,导致:
- 将开头的 5 认为最相关
- 将结尾的 4 认为次相关
- 其实自然语言的相关性顺序并未改变
Prompt Engineering 耦合性
这里之所以提到 Prompt Engineering,是因为我理解了 Prompt Engineering 又衍生了新的问题。
- 原始 Prompt:query
- RAG 检索 Doc:5, 4, 3, 2, 1
- LongContextReorder 处理:5, 3, 1,2, 4
- 终极 Prompt:query 应该在哪里???
一般标准的 RAG 流程产出的Prompt为:"5, 3, 1,2, 4 + query"。
-
首先逻辑上符合"基于所有这些上下文,请回答以下问题。"的工作模式
-
有效信息最大化利用
-
开头5 :为生成答案提供了最核心、最可能被用到的知识基元。
-
结尾Query :在模型短期记忆最鲜活的时候,提供了生成答案所需的最终指令和筛选器。
这形成了一个高效的认知流水线:先加载知识(开头),最后接收指令(结尾),然后开始执行(生成) 。如果将Query放在开头,模型在阅读漫长上下文时,可能已经模糊了最初的问题。
-
-
丢失原"次要文档4"权衡:
- 损失 :文档4获得的注意力,只是略低于它在原始序列末尾的位置。
- 收益 :Query 获得了最高优先级的注意力位置之一,确保了问题被清晰理解。一个被误解的问题,即使有完美的上下文,也必然导致错误的答案。
- 权衡:用一个次重要文档的少量注意力衰减,换取了任务指令(Query)的注意力保障
上下文压缩过滤
我们划分文档块的时候,通常不知道用户的查询,这意味着,与查询最相关的信息可能隐藏在一个包含大量不相关文本的文档中,这样会导致大量冗余、无关甚至冲突的信息稀释了关键信号,不仅增加计算成本和延迟,还可能引发模型幻觉。
这个时候就需要上下文压缩过滤,使用给定查询的上下文来压缩它们,以便只返回相关信息,而不是立即按原样返回检索到的文档。
- 核心:
- 内容压缩:减少单个文档内部的冗余,如删除无关句子、合并重复表述。
- 文档过滤:直接移除完全不相关的整个文档块
LLMChainExtractor
LLMChainExtractor 是 LangChain 框架中用于实现 "提取式"上下文压缩的核心类。他可以针对问题提取出其中最相关的句子或段落。
- 核心:"提问-提取"循环
- 流程:
- 输入:接收一个原始查询(query)和一组由基础检索器(如向量库检索器)返回的原始文档(documents)。
- 处理 :利用一个大语言模型(LLM),针对每个原始文档 提出一个本质相同的问题:"给定当前查询,这个文档中哪些部分是相关的? "
- 输出 :LLM 会分析文档内容,并直接提取(extract) 出与查询相关的原文片段(可以是句子或段落),过滤掉所有不相关的内容。最终,返回一个由这些精炼片段组成的新文档列表。
ini
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"deepseek的发展历程"
)
print("-------------------压缩后--------------------------")
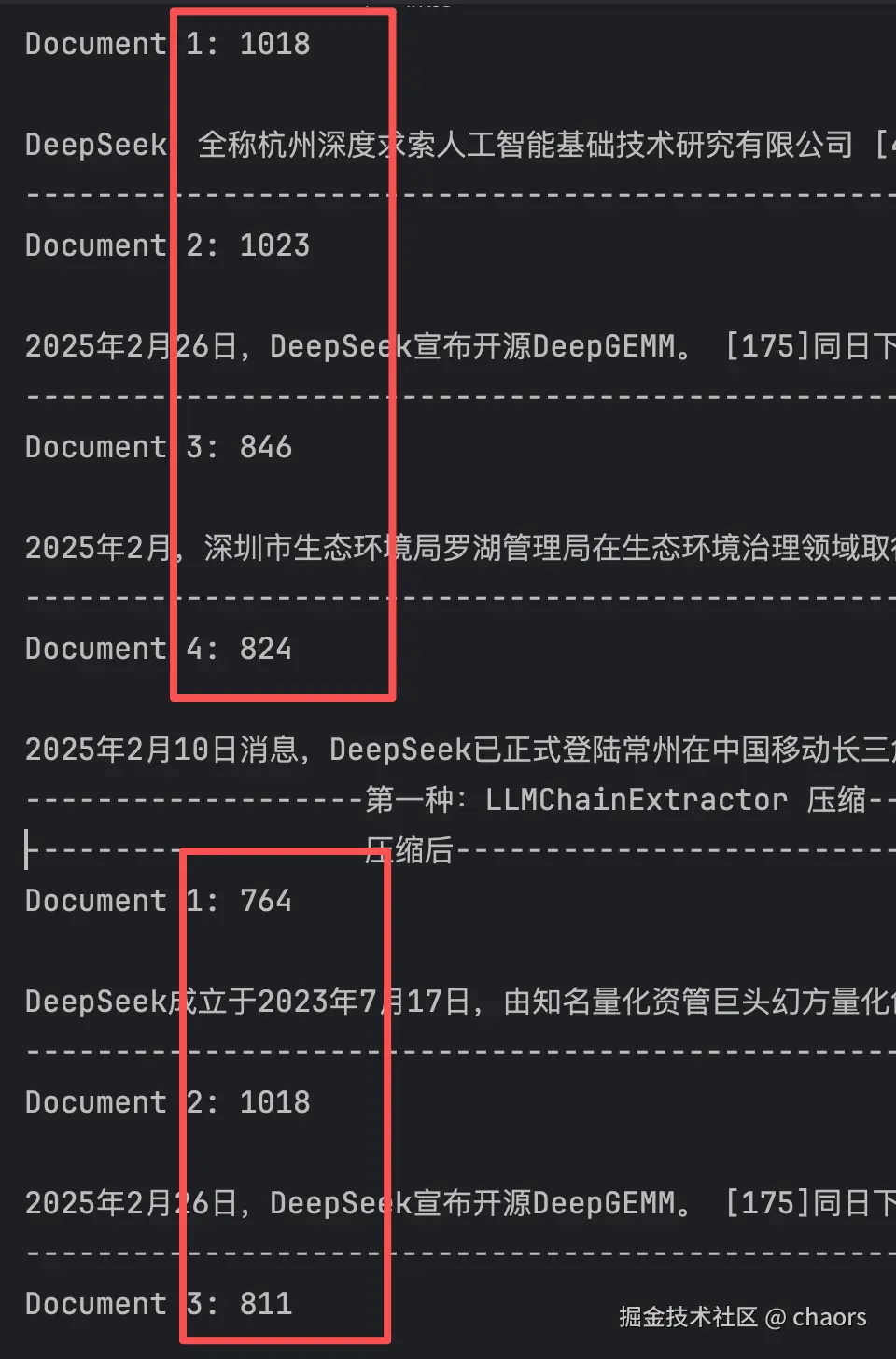
pretty_print_docs(compressed_docs)我们看到,压缩收文档1从 1018 压缩到了 764。
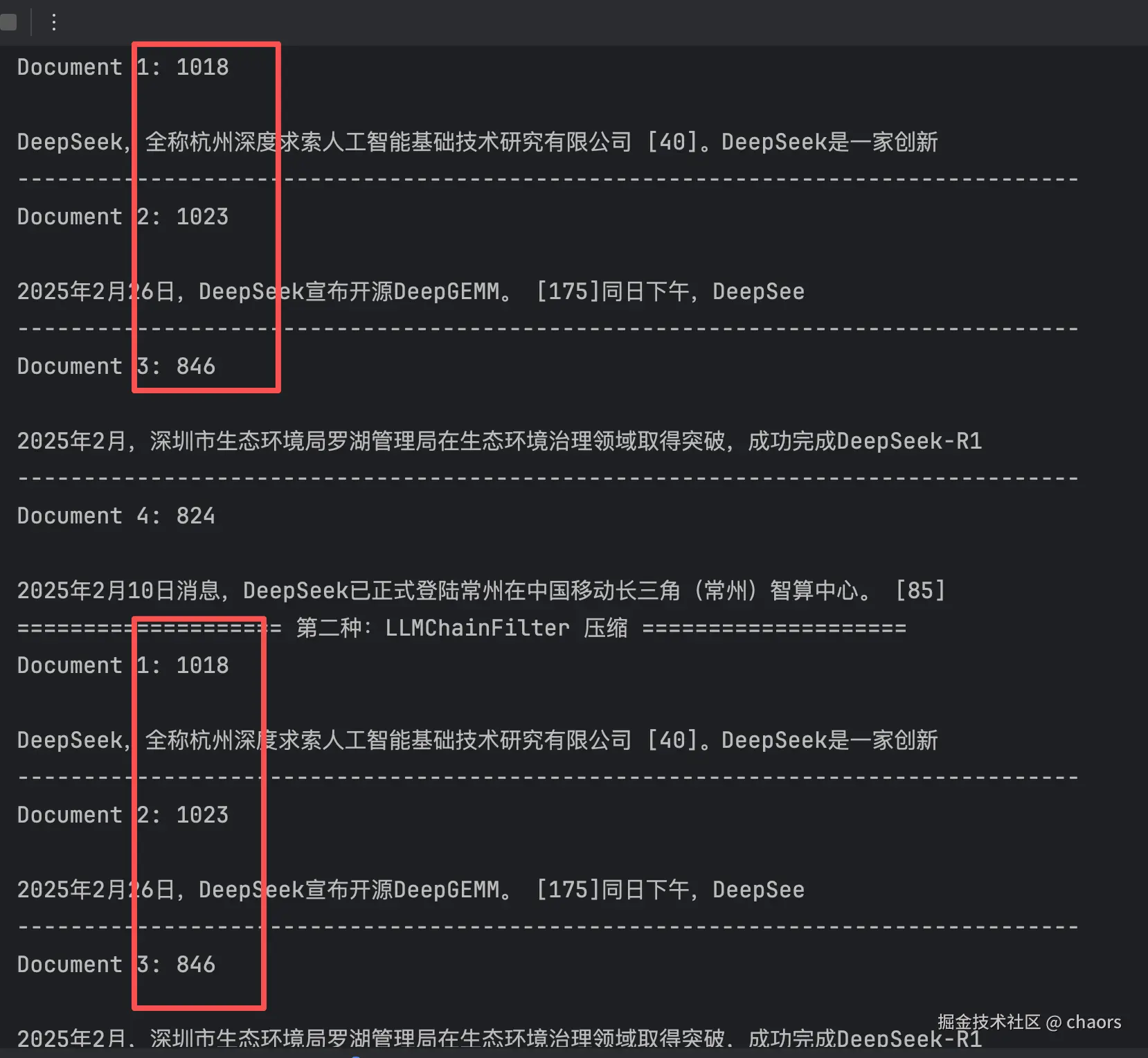
LLMChainFilter
LLMChainFilter 是LangChain的 retrievers.document_compressors模块中实现 "过滤式"上下文压缩的核心类。他只针对文档作出"是否相关 "的结论,输出"是/否"。 核心流程:
-
输入:接收一个用户查询(Query)和一组通过向量检索或其他方式初步获取的文档列表。
-
处理 :针对每一个检索到的文档,构造一个特定的提示(Prompt),交由一个大语言模型(LLM)进行判断。这个提示通常包含查询和文档内容,要求LLM判断"该文档是否与回答查询相关"。
-
输出:LLM给出一个"是/否"的二值判断。LLMChainFilter会收集所有被判断为"是"的文档,过滤掉被判断为"否"的文档,最终返回一个精炼后的、相关性更高的文档子集。
ini
_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter,
base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"deepseek的发展历程"
)
pretty_print_docs(compressed_docs)我们发现。文档内容实际并没有被压缩。这也是其"只过滤,不修改"的本质,几个文档整体都与问题相关,所以保留。只有文档整体不相关时才会被过滤。
EmbeddingsFilter
EmbeddingsFilter 是 Langchain 中一种更高效的筛选器。它绕开了复杂的LLM推理,直接依赖于词向量(Embeddings)相似度,并加入一个阈值判断:
- similarity_threshold:所有相似度大于等于此阈值的文档被保留,低于此阈值的文档被过滤掉。
ini
embeddings_filter = EmbeddingsFilter(
embeddings=embeddings_model,
similarity_threshold=0.69)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter,
base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"人工智能的应用?"
)
pretty_print_docs(compressed_docs)
组合压缩
就是几种压缩方式可以组合使用。
- EmbeddingsRedundantFilter:对文档内容进行过滤
- DocumentCompressorPipeline:定义执行管道,管道会按顺序执行每个压缩器。
我们以下面的代码为例,简单看下混合压缩的流程:
- CharacterTextSplitter先文档分割
- EmbeddingsRedundantFilter去除重复文档
- EmbeddingsFilter再对留下的文档进行query相关性过滤
- DocumentCompressorPipeline用于编排一个管道,顺序执行以上操作
ini
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings_model)
relevant_filter = EmbeddingsFilter(
embeddings=embeddings_model,
similarity_threshold=0.6)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor,
base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"deepseek的发展历程"
)
pretty_print_docs(compressed_docs)小结
以下是LLMChainExtractor、LLMChainFilter、EmbeddingsFilter、EmbeddingsRedundantFilter四种文档处理工具的对比总结:
以下是精简后的对比总结:
| 工具名称 | 核心功能 | 典型应用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| LLMChainExtractor | 内容提取 | 需从长文档中极致压缩、提炼核心信息的场景。 | 信息密度最高,大幅节省Token。 | LLM调用成本最高,可能丢失原文结构。 |
| LLMChainFilter | 相关性过滤 | 对少量关键文档进行高精度、基于深度语义的最终筛选。 | 判断最精准灵活,能理解复杂逻辑和语境。 | LLM调用成本高,不适合处理大量文档。 |
| EmbeddingsFilter | 相似性过滤 | 对大量文档进行低成本、高效率的初步筛选(前置粗筛)。 | 速度极快 ,成本极低,适合大规模初筛。 | 精度依赖模型与阈值,无法处理复杂语义。 |
| EmbeddingsRedundantFilter | 冗余去重 | 检索结果存在大量内容重复文档,需提升信息多样性的场景。 | 有效节省上下文窗口,避免信息重复 | 计算复杂度高(O(n²)),阈值需仔细调试。 |
核心选择指南:
- 追求极致压缩 选 LLMChainExtractor。
- 追求精准判断 选 LLMChainFilter。
- 追求初步高效 选 EmbeddingsFilter。
- 追求去除重复 选 EmbeddingsRedundantFilter。
在实际的RAG管道中,它们常被组合使用,例如:
EmbeddingsFilter(去无关) -> EmbeddingsRedundantFilter(去重复) -> LLMChainFilter(精筛) -> LLMChainExtractor(提炼),形成高效的处理流水线。