引言:物联网时代的"数据洪流"挑战
随着工业4.0、智能网联汽车以及智慧城市建设的深入推进,全球产生的数据量正呈现指数级增长。在这些数据中,带有时间戳的时序数据(Time-Series Data)占据了绝大多数。从工厂传感器的毫秒级震动读数,到电网设备的实时负荷监控,再到车联网的海量轨迹记录,如何高效地存储、查询和分析这些"数据洪流",成为了企业数字化转型的关键瓶颈。
在面对如此庞大的数据规模时,传统的关系型数据库(如MySQL、PostgreSQL)往往显得力不从心,其在写入吞吐量、压缩率以及时序查询性能上的局限性,迫使架构师们将目光转向专门的时序数据库(TSDB)。然而,市场上的时序数据库产品琳琅满目,既有国外的老牌强者,也有国内的新兴势力。企业在进行技术选型时,往往面临着生态兼容性、大规模集群能力、运维成本以及国产化适配等多重考量。本文将站在大数据架构演进的角度,结合国际视野,深入探讨时序数据库的选型标准,并重点分析为何 Apache IoTDB 能够成为当下处理海量时序数据的首选方案。
目录
-
- 引言:物联网时代的"数据洪流"挑战
- 一、时序数据库选型的核心维度
-
- [1. 原生大数据生态融合能力](#1. 原生大数据生态融合能力)
- [2. 极致的压缩与存储成本](#2. 极致的压缩与存储成本)
- [3. 查询语言的功能性与易用性](#3. 查询语言的功能性与易用性)
- [4. 云边端协同架构](#4. 云边端协同架构)
- 二、国际视野下的技术对比与突破
-
- [1. 专为时序设计的文件格式:TsFile](#1. 专为时序设计的文件格式:TsFile)
- [2. "端 - 边 - 云"原生协同](#2. “端 - 边 - 云”原生协同)
- [三、实战演示:如何使用 IoTDB 构建高效数据管道](#三、实战演示:如何使用 IoTDB 构建高效数据管道)
-
- [3.1 数据模型定义与写入](#3.1 数据模型定义与写入)
- [3.2 复杂时序查询与分析](#3.2 复杂时序查询与分析)
- [3.3 架构集成流程图](#3.3 架构集成流程图)
- [四、为什么选择 Apache IoTDB?](#四、为什么选择 Apache IoTDB?)
一、时序数据库选型的核心维度
在进行数据库选型时,不能仅看基准测试(Benchmark)中的峰值写入速度,更需要从系统架构的长期稳定性、生态融合度以及业务场景的适配性出发。以下是几个关键的评估维度:
1. 原生大数据生态融合能力
在大数据领域,Hadoop、Spark、Flink 等组件构成了事实上的标准。一款优秀的时序数据库,不应是信息孤岛,而应能无缝融入现有的大数据生态。
- 集成难度:是否支持标准的 JDBC/ODBC?能否作为 Spark 或 Flink 的数据源(Source)和汇(Sink)直接运行?
- 文件格式兼容:是否支持与 HDFS、S3 等对象存储的交互?能否直接读写 Parquet、TsFile 等列式存储格式?
2. 极致的压缩与存储成本
时序数据的特点是"写多读少"且随时间无限增长。存储成本是企业的核心痛点。
- 压缩算法:是否针对时序数据特征(如单调递增的时间戳、变化缓慢的传感器值)设计了专用压缩算法?
- 存储效率:在同等硬件条件下,谁能将数据压缩得更小,谁就能为企业节省大量的磁盘和云存储费用。
3. 查询语言的功能性与易用性
复杂的业务逻辑需要强大的查询语言支持。除了基础的聚合查询(AVG, MAX, MIN),是否支持降采样、插值、复杂事件处理(CEP)以及用户自定义函数(UDF)?语法是否贴近 SQL,以降低开发人员的学习曲线?
4. 云边端协同架构
现代物联网架构往往是分层的。数据在边缘端产生,在云端汇聚。数据库是否具备"端 - 边 - 云"一体化部署能力,支持数据在边缘侧轻量存储、自动同步至云端,是衡量其架构先进性的关键指标。
二、国际视野下的技术对比与突破
放眼全球,InfluxDB 和 TimescaleDB 是国外极具代表性的时序数据库产品。InfluxDB 以其高性能写入著称,但在早期版本中闭源策略及集群版的昂贵授权费让许多中小企业望而却步;TimescaleDB 基于 PostgreSQL 构建,SQL 兼容性好,但在超大规模数据量的原生压缩和特定时序算子优化上,仍受限于关系型模型的重叠开销。
相比之下,Apache IoTDB 作为源自清华大学、后捐赠给 Apache 基金会的顶级开源项目,走出了一条独特的技术路线。它并非基于现有关系型数据库的修改,而是从底层存储引擎开始,专为物联网时序数据量身打造。
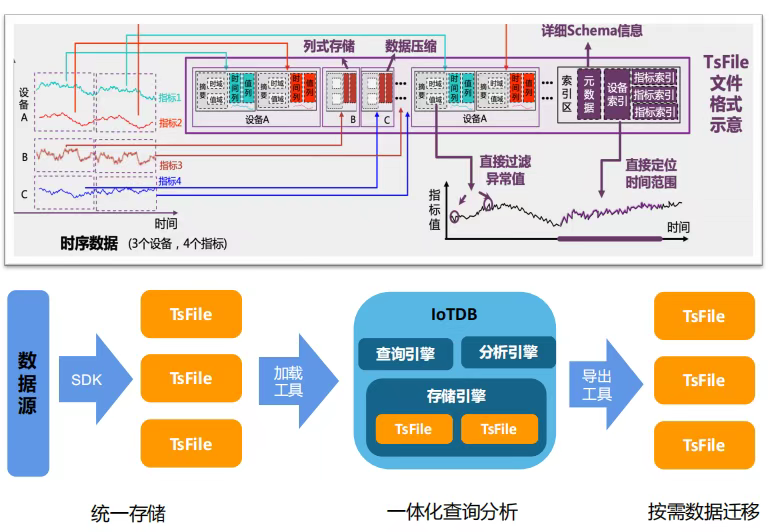
1. 专为时序设计的文件格式:TsFile
IoTDB 引入了自研的列式存储文件格式 TsFile。与通用的 Parquet 或 ORC 不同,TsFile 针对时序数据进行了深度优化:
- 动态分块:根据数据波动性动态调整编码策略。
- 高精度压缩:采用戈伦布编码、游程编码等多种算法组合,在工业实测中,其压缩比通常优于通用列存格式 3-5 倍,极大地降低了存储成本。
2. "端 - 边 - 云"原生协同
这是 IoTDB 区别于大多数国外产品的显著优势。在国外产品中,边缘端往往需要使用轻量级代理(如 Telegraf)收集数据再发送至中心数据库。而 IoTDB 提供了同一套内核在不同算力设备上的运行能力:
- 端侧:可在资源受限的网关甚至嵌入式设备上运行,实现本地持久化。
- 边侧:进行初步的数据清洗和聚合。
- 云侧 :汇聚全局数据,进行深度分析。
这种架构天然支持断网续传和数据自动同步,完美契合了网络环境复杂的工业现场。
三、实战演示:如何使用 IoTDB 构建高效数据管道
为了更直观地展示 IoTDB 的易用性与强大功能,以下通过一段代码示例,演示如何定义数据模型、写入数据并进行复杂的时序分析。
3.1 数据模型定义与写入
IoTDB 采用树状结构管理元数据,路径清晰直观。以下使用 SQL 风格的语言进行操作:
sql
-- 1. 创建设备模板(类似于建表,但更灵活)
CREATE DEVICE TEMPLATE vehicle_template (
speed FLOAT encoding=RLE,
temperature FLOAT encoding=SDT,
status BOOLEAN encoding=PLAIN
);
-- 2. 将模板应用到具体设备路径
SET DEVICE TEMPLATE vehicle_template TO root.vehicle.beijing.truck_001;
-- 3. 插入模拟数据(支持批量插入)
INSERT INTO root.vehicle.beijing.truck_001(time, speed, temperature, status)
VALUES
(1710840000000, 65.5, 88.2, true),
(1710840001000, 66.1, 88.5, true),
(1710840002000, 64.8, 87.9, true);3.2 复杂时序查询与分析
利用 IoTDB 丰富的内置函数,我们可以轻松完成降采样和异常检测:
sql
-- 查询过去一小时内,每5分钟的平均速度和最高温度
SELECT AVG(speed), MAX(temperature)
FROM root.vehicle.beijing.truck_001
WHERE time >= NOW() - 1h
GROUP BY ([NOW() - 1h, NOW()], 5m);
-- 使用窗口函数检测温度突变(连续两个点温差超过5度)
SELECT DIFF(temperature)
FROM root.vehicle.beijing.truck_001
HAVING DIFF(temperature) > 5.0;3.3 架构集成流程图
在实际的大数据架构中,IoTDB 通常扮演核心存储角色,与 Flink/Spark 紧密协作:
MQTT/CoAP
WAL Sync
Read/Write
Read
Export
JDBC Query
传感器/设备
Edge IoTDB
Cloud IoTDB Cluster
Flink Real-time Job
Spark Batch Analysis
S3/HDFS Cold Storage
Grafana/Tableau
如上图所示,数据在边缘侧即可被 IoTDB 接收并缓存,随后同步至云端集群。流计算引擎 Flink 可实时读取 IoTDB 数据进行报警,而离线分析工具 Spark 则可直接挂载 IoTDB 进行历史数据挖掘,真正实现了"一套数据,多种用法"。
四、为什么选择 Apache IoTDB?
综上所述,Apache IoTDB 凭借其原生大数据生态集成 、极致的存储压缩率 以及独特的端边云协同架构,在时序数据库选型中脱颖而出。它不仅解决了海量数据写入的性能瓶颈,更通过开放源码和活跃的社区(Apache 顶级项目),消除了企业对供应商锁定的顾虑。对于追求自主可控、需要处理亿级甚至万亿级数据点的中国企业而言,IoTDB 无疑是构建下一代物联网数据底座的最佳选择。
无论是从技术先进性还是从落地实践来看,IoTDB 都已经具备了与国际顶尖产品抗衡甚至超越的实力。如果您正在寻找一款能够支撑未来十年业务增长的时序数据库,不妨亲自体验一下。
立即下载体验:
- 📥 Apache IoTDB 下载链接 :https://iotdb.apache.org/zh/Download/
- 🏢 企业版官网(获取更多商业支持与高级功能) :https://timecho.com