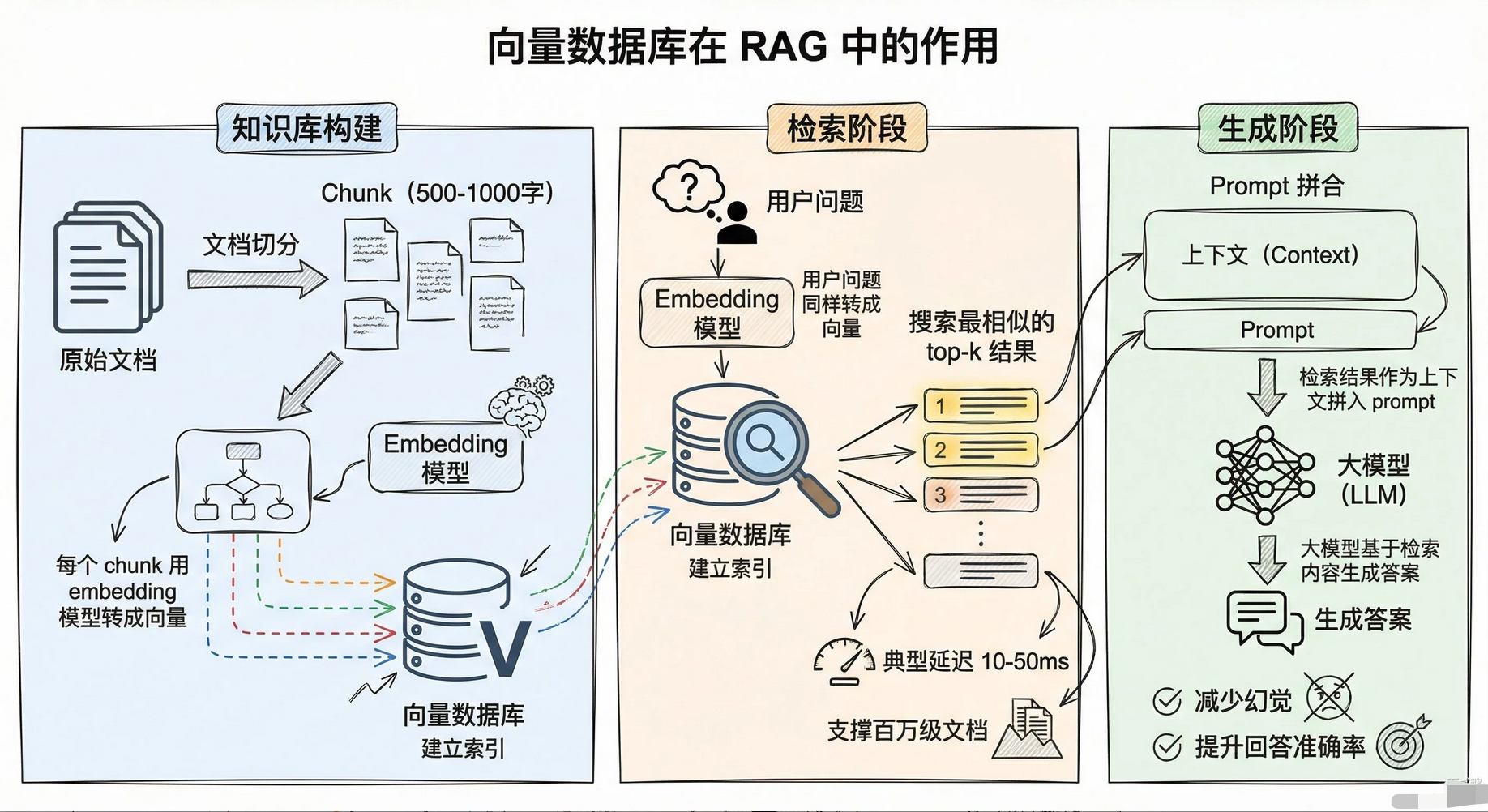
基础定义
向量数据库 :专门用于存储和检索高维向量 的数据库,核心能力是语义相似性搜索。
- 非结构化数据(文本、图片、音频等)→ 通过 Embedding 模型 → 高维向量(如 768/1536 维)
- 检索时:根据向量间的距离(余弦相似度、欧氏距离等)快速匹配语义最相关的内容,而非关键词匹配。
其他:
-
与传统数据库的区别:
-
- 传统数据库做精确匹配,向量数据库做相似匹配;
- 传统数据库索引基于结构化字段,向量数据库基于向量索引(如 HNSW、IVF)。
-
典型场景:RAG、推荐系统、图像检索、多模态搜索。
大模型应用中的三大核心问题
- 给大模型补上「长期记忆」
- 原生问题:大模型上下文窗口有限(如 GPT-4 最多 128K token),无法直接承载企业级海量文档。
- 解决方式:
- 文档切片 → 生成向量 → 存入向量库
- 用户提问时,先检索 Top-K 最相关片段
- 将片段作为上下文喂给大模型 → 生成答案(RAG 核心链路)
-
补充:
-
- 切片策略:按语义 / 段落 / 固定长度拆分,避免语义断裂
- 检索精度:影响最终回答质量,是 RAG 优化的关键环节
- 突破知识时效性限制
-
原生问题:大模型知识截止到训练时间点,无法获取实时 / 新增知识(如最新新闻、政策、产品更新)。
-
解决方式:向量数据库支持实时增量写入,新数据可快速入库并被检索到,无需重新训练大模型。
-
补充:
-
- 可对接实时数据流(如日志、新闻接口),实现「动态知识库」
- 配合大模型,做到「训练数据不变,外部知识实时更新」
- 降低推理成本
-
原生问题:若将全部背景知识塞进 Prompt,Token 消耗极高,推理速度慢、费用昂贵。
-
解决方式:仅检索最相关的少量片段(通常 5-10 条),大幅减少 Token 消耗,推理成本可降低一个数量级。
-
补充:
-
- Token 节省:10 万条文档全量塞入需数百万 Token,检索后仅需约 2000 Token
- 推理速度:上下文变短,大模型生成速度显著提升
工作流程
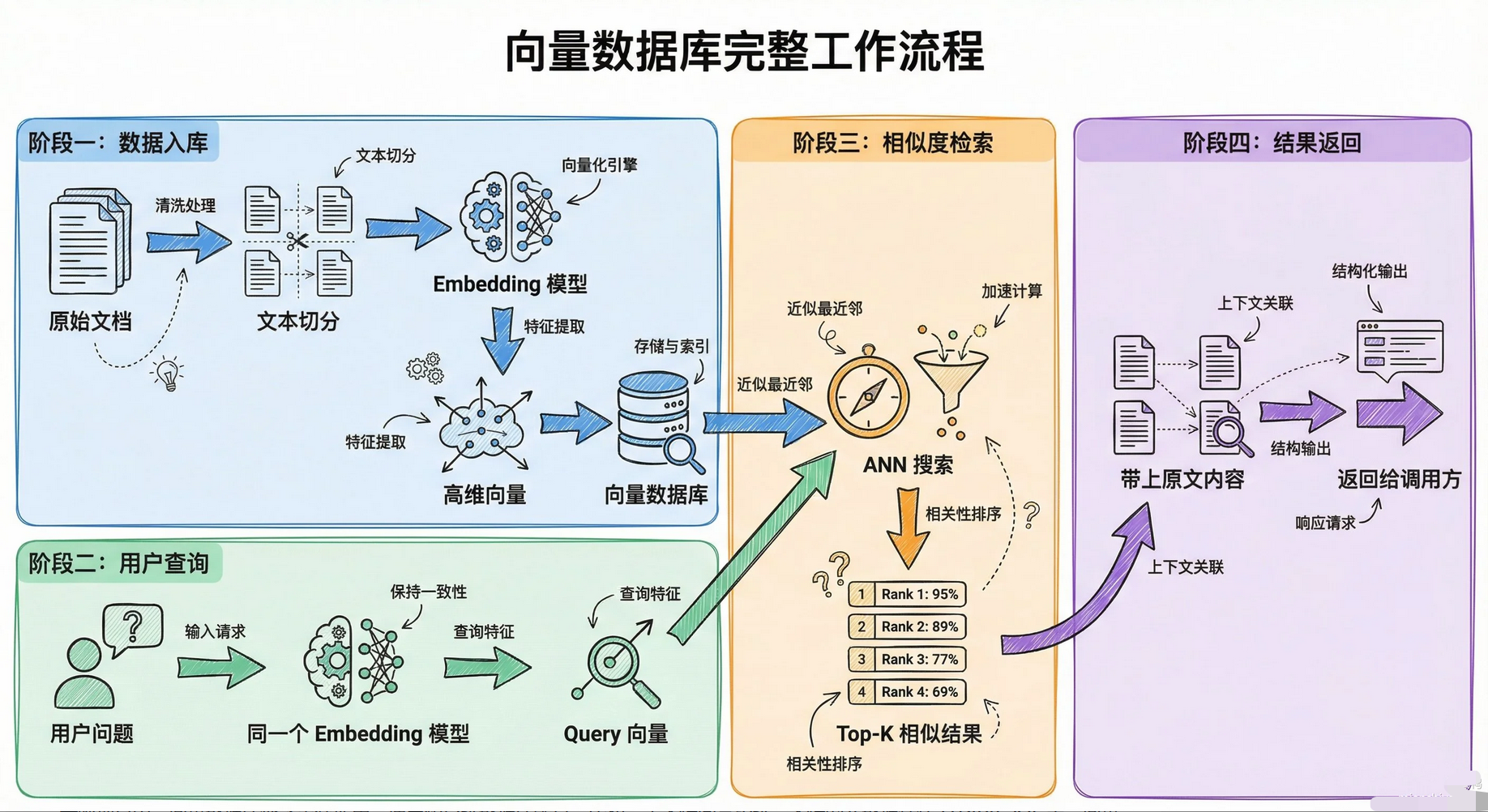
向量检索的底层原理
传统数据库用 B+ 树做索引,支持精确匹配和范围查询。
向量数据库用的是近似最近邻(KNN)算法 ,因为在几百维的空间里做精确最近邻搜索,计算量是 O (n×d),1000 万条 1536 维向量精确搜一遍要几分钟,生产环境根本用不了。
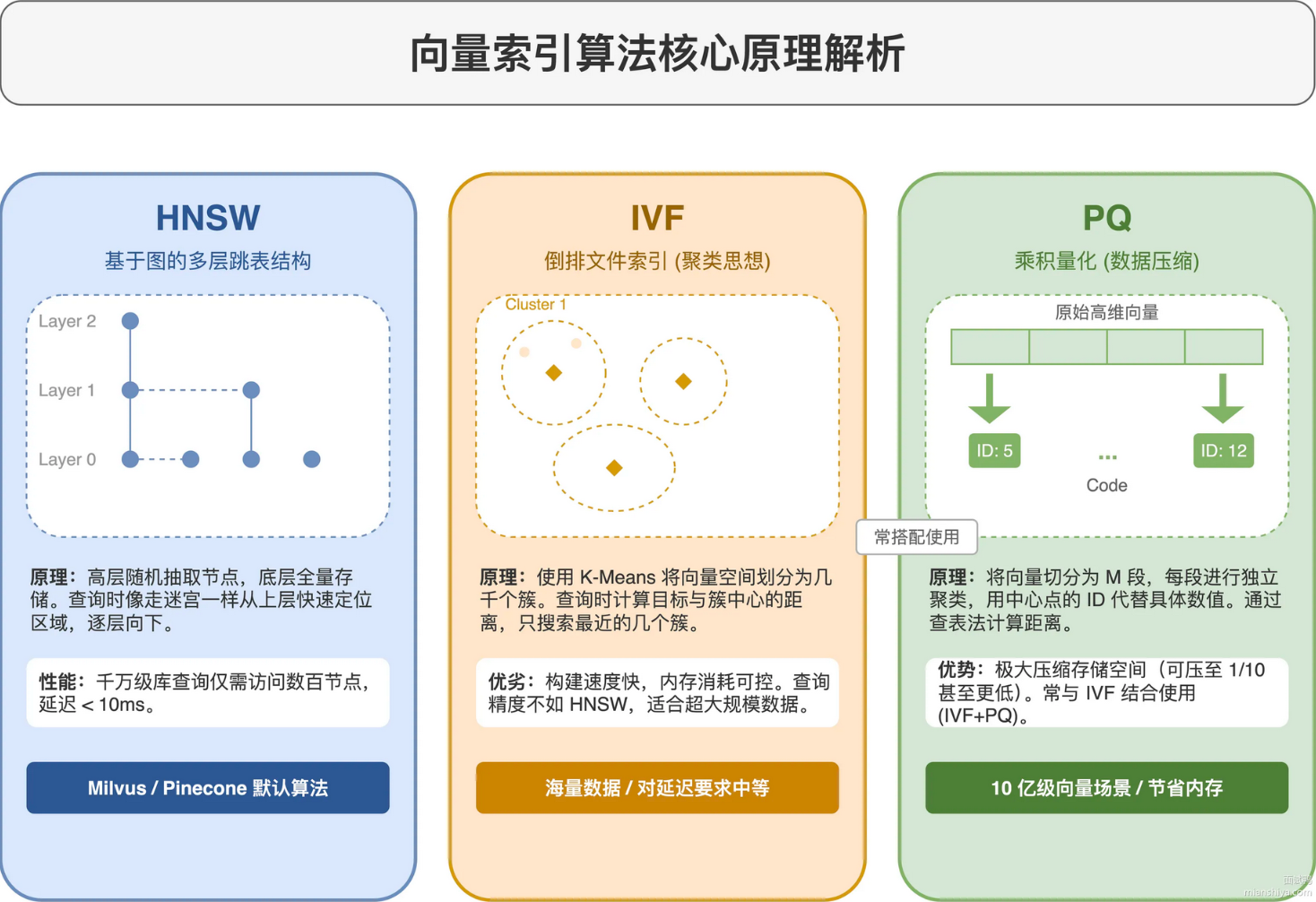
近似最近邻牺牲一点准确率换速度,常见算法有三类:
- HNSW 是目前最主流的算法 ,构建一个多层跳表 结构。最底层存所有向量,往上每层随机抽取部分节点,查询时从最顶层开始,像走迷宫一样一层层往下找。1000 万向量的库,查询只需要访问几百个节点,延迟在 10ms 以内。Milvus、Pinecone、Weaviate 默认都用 HNSW。
- IVF 先用 K-Means 把向量聚成几千个簇,查询时只在最相似的几个簇里搜索。建索引快,但查询精度不如 HNSW。适合向量数据量特别大、对延迟要求没那么高的场景。
- PQ 把高维向量拆成多个子向量,每个子向量用聚类中心的 ID 代替,压缩存储空间。10 亿级向量的场景会用 IVF+PQ 的组合,内存占用能压到原来的 1/10。
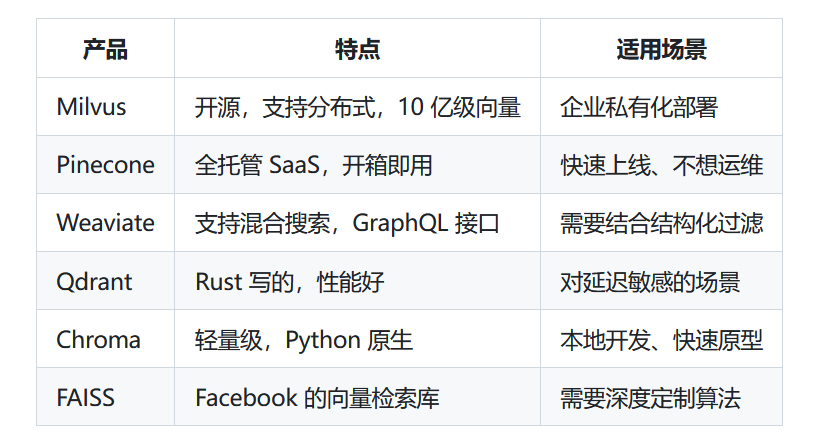
主流向量数据库
embedding 模型的选择
向量数据库只负责存储和检索 ,向量本身是 embedding 模型生成的。模型选得不好,检索效果再好也没用。
OpenAI 的 text-embedding-3-large 是目前效果最好的通用模型,1536 维或 3072 维可选。缺点是调 API 有成本,100 万 token 大概 0.13 美元。
开源模型推荐 BGE 系列,智源发布的,中英文效果都不错。bge-large-zh-v1.5 在中文场景下效果接近 OpenAI,可以本地部署,成本低很多。
还有个容易踩的坑:query 和 document 要用同一个模型生成向量,不能混用。不同模型的向量空间不一样,混着用检索效果会很差。
实际项目中,向量数据库很少单独使用,通常和传统数据库配合。比如一个文档问答系统,文档的元数据存在 PostgreSQL 里,向量存在 Milvus 里。查询时先在向量库里检索语义相似的 chunk,再根据 chunk ID 去关系库里捞完整的文档信息。
有些向量数据库支持 metadata filtering,可以在向量检索的同时加上结构化条件。比如 "只在 2024 年的文档里搜索",先按时间过滤,再在过滤后的子集里做向量检索。Weaviate 和 Qdrant 这方面做得比较好。
一些疑惑
提问:HNSW 和 IVF 具体怎么选?什么场景用哪个?
回答:主要看数据量和对召回率的要求。
1000 万以内的向量,HNSW 无脑选,召回率高、延迟低 。超过 1 亿的向量,HNSW 的内存占用会很夸张,每个向量除了本身的数据还要存一堆邻居指针,1 亿条 1536 维向量光 HNSW 索引就要几百 GB 内存。这时候用 IVF+PQ,牺牲一点召回率,内存能省一个数量级。还有个考量是更新频率,HNSW 增量插入比较友好,IVF 的聚类中心是建索引时固定的,数据分布变化大了得重建索引。
问:检索出来的结果语义相关但答非所问,怎么优化?
回答:这个问题通常出在三个地方。
一是 chunk 切分粒度不对 ,切太细丢失上下文,切太粗检索不精准,一般 500-1000 字比较合适,还可以加上滑动窗口重叠。
二是 embedding 模型和业务场景不匹配,通用模型对垂直领域术语理解不好,可以换成领域微调过的 embedding 模型,或者在 query 前面加上领域关键词做 query expansion。
三是只靠向量相似度不够 ,可以加上 BM25 关键词匹配做混合检索,Weaviate 和 Elasticsearch 都支持 hybrid search。
提问:向量数据库的数据怎么保证一致性和持久化?
回答:不同产品实现不一样。
Milvus 用 etcd 存元数据,用 MinIO 或 S3 存向量数据和索引,写入时先落 WAL 再异步刷盘。
Pinecone 是全托管的,底层细节不公开,但官方承诺 99.99% 的可用性。开源方案要自己做好备份和灾备。
Milvus 支持跨集群复制,也可以定期把数据 dump 出来存到对象存储。一致性方面,大多数向量数据库是最终一致性,写入后不能立刻检索到,有几十毫秒到几秒的延迟,强一致性场景不太适用。