引言
我们可以通过学习LangChain这样的框架轻松构建自己的AI应用。其中检索增强生成是一种让大语言模型能够利用外部知识库来回答问题的技术,它就像给AI装上了"搜索引擎",让回答更加准确、及时。本文从零开始,一步步实现一个完整的RAG系统,从加载文档到构建交互式问答应用,所有代码都基于LangChain和国内可用的通义千问模型。
一、文档加载
任何RAG系统的第一步都是获取数据。LangChain提供了丰富的文档加载器,可以轻松加载各种格式的文件。我们先从PDF和维基百科开始。
1、加载PDF文档
用LangChain社区库中的PyPDFLoader模块,加载PDF文件。通过创建加载器实例并调用load方法,将PDF文档内容提取为可处理的文档对象。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./llama2.pdf")
docs = loader.load()
print(docs[2].page_content) loader.load()会返回一个Document对象列表,每个对象包含page_content(文本内容)和metadata(元数据,如页码)。
2、加载维基百科词条
如果你想查询某个概念或人物,LangChain的WikipediaLoader可以直接抓取维基百科的内容。
from langchain_community.document_loaders import WikipediaLoader
loader = WikipediaLoader(query="周杰伦", load_max_docs=3, lang="zh")
docs = loader.load()
print(docs[0].page_content) # 查看第一个文档的内容
二、文本分割
加载的文档通常很长,直接喂给语言模型会超过上下文长度限制,而且不利于检索。因此我们需要将长文本切分成较小的块(chunks)。LangChain提供了多种分割器,最常用的是RecursiveCharacterTextSplitter。
用LangChain的RecursiveCharacterTextSplitter模块,创建一个文本分割器实例,并设置关键参数:每个文本块大小为500字符,块间重叠50字符,同时指定了从段落双换行、单换行到中文句号、感叹号、问号、逗号、顿号直至空字符的逐级分隔符顺序。随后调用split_documents方法,将之前加载的PDF文档docs按这些规则切分成多个文本块,并打印出分割后的文档列表。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ",", "、", ""]
)
texts = text_splitter.split_documents(docs)
print(texts) # 输出分割后的文档列表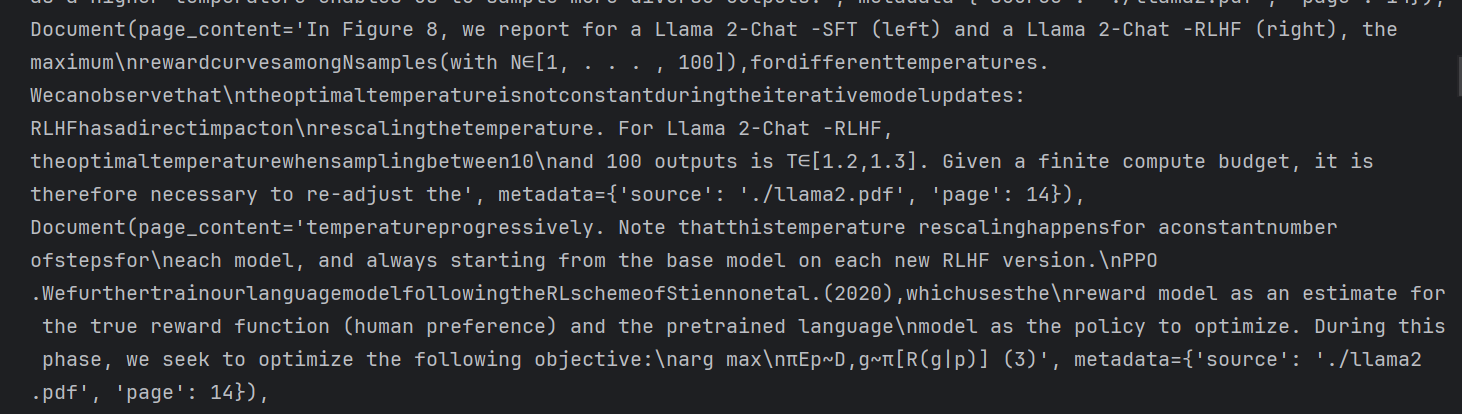
chunk_size=500:每个块的最大字符数。
chunk_overlap=50:块之间的重叠字符数,防止关键信息被切断。
separators:分割符优先级列表,从高到低尝试分割。
分割后,我们得到了一系列小文档,它们保留了原始文档的元数据,便于后续检索。
三、文本嵌入
文本不能直接被计算机理解,需要转换成向量形式。嵌入模型可以将文本映射到一个高维向量空间,使得语义相似的文本向量距离更近。
用LangChain库中的DashScopeEmbeddings模块,初始化一个嵌入模型,指定模型版本,并配置API密钥。随后调用embed_query方法对单个测试文本进行向量化,打印出生成的向量长度。接着使用embed_documents方法对包含两个文档的列表进行批量嵌入,输出向量数量以及第二个文档向量的长度。
from langchain_community.embeddings import DashScopeEmbeddings
embeddings_model = DashScopeEmbeddings(
model="text-embedding-v2",
dashscope_api_key="sk-你的API密钥"
)
text = "This is a test document."
query_result = embeddings_model.embed_query(text)
print("文本向量长度:", len(query_result))
doc_results = embeddings_model.embed_documents([
"My friends call me TOM",
"Hello World!"
])
print("文本向量数量:", len(doc_results), ",文本向量长度:", len(doc_results[1]))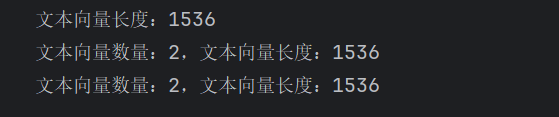
embed_query:为单个查询文本生成向量。
embed_documents:为多个文档生成向量,通常用于批量处理。
通义千问的嵌入模型支持中文和英文,默认向量维度为1024或1536(不同版本)。可以通过dimensions参数调整维度大小。
四、向量存储
有了文本向量,我们需要一个高效的存储和检索工具。FAISS是一个开源的向量库,专门用于相似性搜索。LangChain将其封装为FAISS类,使用起来非常方便。
from langchain_community.vectorstores import FAISS
db = FAISS.from_documents(texts, embeddings_model)
retriever = db.as_retriever()FAISS.from_documents:直接从文档列表创建向量数据库,它会自动为每个文档生成向量并建立索引。
as_retriever():将数据库转换为检索器,方便后续调用。
检索器可以根据你的查询,返回最相似的文档片段。例如:
retrieved_docs = retriever.invoke("卢浮宫这个名字怎么来的?")
print(retrieved_docs[0].page_content)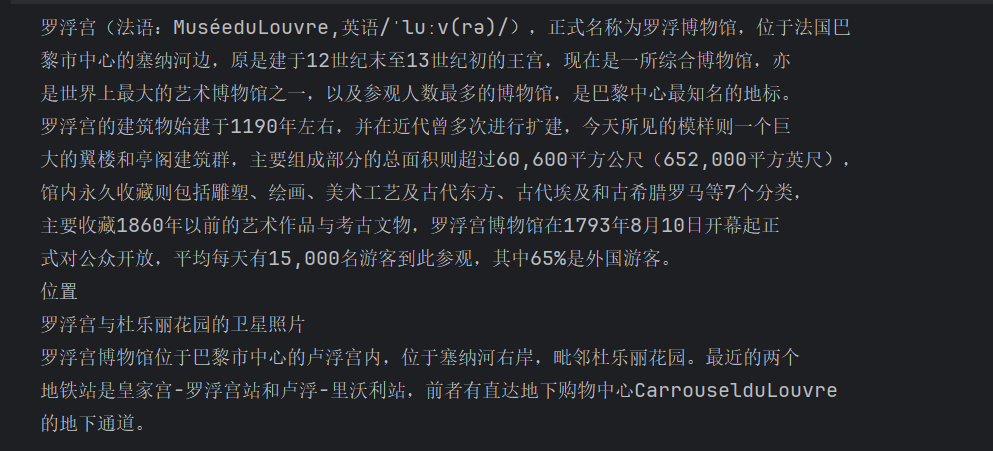
检索器会返回按相似度排序的文档列表,第一个就是最匹配的。
五、构建检索增强生成链
有了检索器,我们可以将其与大语言模型(LLM)结合,构建一个完整的问答系统。LangChain提供了ConversationalRetrievalChain,它不仅会基于检索到的文档回答问题,还能记住对话历史,实现多轮对话。
首先,初始化一个语言模型。这里我们使用通义千问的qwen3.5-plus模型,通过OpenAI兼容接口调用。
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="qwen3.5-plus",
openai_api_key="sk-你的API密钥",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)然后,我们需要一个记忆组件来存储对话历史。ConversationBufferMemory可以做到这一点。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
return_messages=True,
memory_key='chat_history',
output_key='answer'
)return_messages=True:以消息列表形式返回历史。
memory_key:在链中使用的历史变量名。
output_key:指定输出结果的键名。
最后,构建链:
from langchain.chains import ConversationalRetrievalChain
qa = ConversationalRetrievalChain.from_llm(
llm=model,
retriever=retriever,
memory=memory,
return_source_documents=True # 可选,返回参考的原文片段
)现在,我们可以向链提问了:
question = "卢浮宫博物馆位于什么地方?"
qa.invoke({"chat_history": memory, "question": question})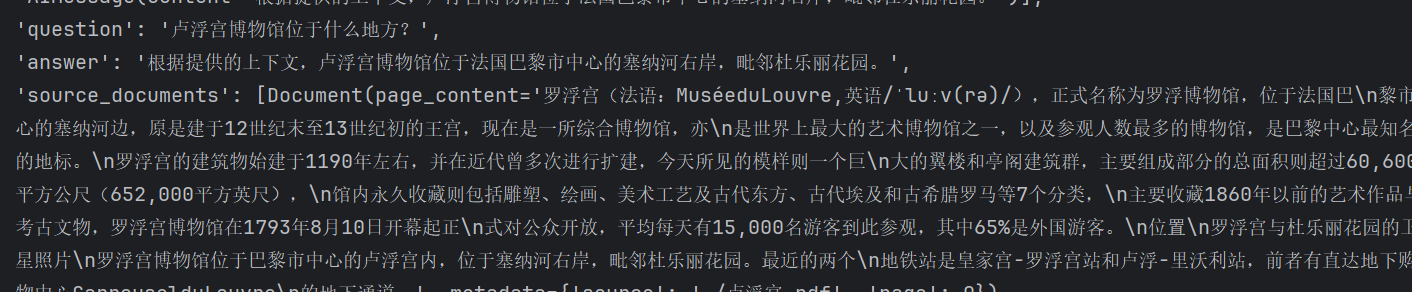
六、构建交互式应用
1、核心功能模块
定义一个函数,它接收OpenAI API密钥、对话记忆对象、上传的PDF文件以及用户问题。函数首先通过阿里云DashScope兼容接口初始化ChatOpenAI模型,使用qwen3.5-plus作为语言模型。随后将上传的PDF保存至临时文件,利用PyPDFLoader加载文档内容,并使用RecursiveCharacterTextSplitter将文本切分为500字符的块(重叠50字符)。接着,DashScopeEmbeddings将文本块转换为向量,并构建FAISS向量库作为检索器。最后,通过ConversationalRetrievalChain整合模型、检索器和记忆,调用invoke方法传入对话历史和问题,返回问答响应。
from langchain.chains import ConversationalRetrievalChain
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
def qa_agent(openai_api_key, memory, uploaded_file, question):
# 初始化模型
model = ChatOpenAI(
model="qwen3.5-plus",
openai_api_key="sk-0b717f29b6ee4852a2331cf1ffa30d4f",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 读取上传的文件
file_content = uploaded_file.read()
temp_file_path = "卢浮宫.pdf"
with open(temp_file_path, "wb") as temp_file:
temp_file.write(file_content)
# 加载PDF
loader = PyPDFLoader(temp_file_path)
docs = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n", "。", "!", "?", ",", "、", ""]
)
texts = text_splitter.split_documents(docs)
# 嵌入
embeddings_model = DashScopeEmbeddings(
model="text-embedding-v2",
dashscope_api_key="sk-0b717f29b6ee4852a2331cf1ffa30d4f"
)
# 创建向量库
db = FAISS.from_documents(texts, embeddings_model)
retriever = db.as_retriever()
# 构建问答链
qa = ConversationalRetrievalChain.from_llm(
llm=model,
retriever=retriever,
memory=memory
)
response = qa.invoke({"chat_history": memory, "question": question})
return response2、前端界面
构建了一个AI智能PDF问答工具的Web界面。首先初始化会话状态中的对话记忆和历史记录,随后设置页面标题和图标。用户需在侧边或主区域输入OpenAI API密钥,上传PDF文件并输入问题。当文件上传且问题提交后,若密钥有效,则调用自定义qa_agent函数处理问答,返回答案并更新历史记录。界面下方以折叠面板展示历史对话,每条消息标注角色,并提供清空历史按钮以重置记忆。
import streamlit as st
from langchain.memory import ConversationBufferMemory
from scripts import qa_agent
# 初始化会话状态
if "memory" not in st.session_state:
st.session_state["memory"] = ConversationBufferMemory(
return_messages=True,
memory_key="chat_history",
output_key="answer"
)
if "chat_history" not in st.session_state:
st.session_state["chat_history"] = []
st.set_page_config(page_title="AI智能PDF问答工具", page_icon="📑")
st.title("📑 AI智能PDF问答工具")
# API密钥输入
st.subheader("🔑 API设置")
api_key = st.text_input("请输入OpenAI API密钥", type="password", placeholder="sk-...")
st.divider()
# 文件上传
st.subheader("📁 文件上传")
uploaded_file = st.file_uploader("点击或拖拽PDF文件到此处", type="pdf")
# 问题输入
st.subheader("❓ 提问")
question = st.text_input("请输入您的问题...", disabled=not uploaded_file)
# 处理逻辑
if uploaded_file and question:
if not api_key:
st.warning("⚠️ 请先输入OpenAI API密钥")
else:
with st.spinner("🤖 AI正在思考中,请稍等..."):
try:
response = qa_agent(api_key, st.session_state["memory"], uploaded_file, question)
st.subheader("📝 答案")
st.write(response["answer"])
st.session_state["chat_history"] = response["chat_history"]
except Exception as e:
st.error(f"❌ 处理过程中发生错误: {str(e)}")
# 显示历史对话
if st.session_state["chat_history"]:
st.divider()
with st.expander("🗣️ 历史对话记录", expanded=False):
for i in range(0, len(st.session_state["chat_history"]), 2):
if i + 1 < len(st.session_state["chat_history"]):
human_msg = st.session_state["chat_history"][i]
ai_msg = st.session_state["chat_history"][i + 1]
st.markdown(f"**👤 你**: {human_msg.content}")
st.markdown(f"**🤖 AI**: {ai_msg.content}")
if i < len(st.session_state["chat_history"]) - 2:
st.write("---")
if st.button("🔄 清空对话历史"):
st.session_state["memory"] = ConversationBufferMemory(
return_messages=True, memory_key="chat_history", output_key="answer"
)
st.session_state["chat_history"] = []
st.experimental_rerun()