目录
[二、XA 协议与 JTA:历史的基石](#二、XA 协议与 JTA:历史的基石)
[2.1 XA 是什么?](#2.1 XA 是什么?)
[2.2 XA 的核心优势与致命弱点](#2.2 XA 的核心优势与致命弱点)
[3.1 Seata 的核心架构](#3.1 Seata 的核心架构)
[四、AT 模式:Seata 的核心创新](#四、AT 模式:Seata 的核心创新)
[4.1 Undo Log:AT 模式的灵魂](#4.1 Undo Log:AT 模式的灵魂)
[4.2 AT 模式的隔离机制:全局锁](#4.2 AT 模式的隔离机制:全局锁)
[4.3 AT 模式的真实适用范围](#4.3 AT 模式的真实适用范围)
[五、TCC 模式:精细控制的代价](#五、TCC 模式:精细控制的代价)
[5.1 TCC 模式在 Seata 中的定位](#5.1 TCC 模式在 Seata 中的定位)
[5.2 AT vs TCC:不是优劣,是场景匹配](#5.2 AT vs TCC:不是优劣,是场景匹配)
[六、Saga 模式:长事务的工程解法](#六、Saga 模式:长事务的工程解法)
[6.1 状态机驱动是 Seata Saga 的关键设计](#6.1 状态机驱动是 Seata Saga 的关键设计)
[6.2 Saga 的隔离性问题与缓解策略](#6.2 Saga 的隔离性问题与缓解策略)
[七、XA 模式:Seata 对传统 XA 的改良](#七、XA 模式:Seata 对传统 XA 的改良)
[7.1 Seata XA 模式的差异在哪里?](#7.1 Seata XA 模式的差异在哪里?)
[7.2 XA 模式的真实定位](#7.2 XA 模式的真实定位)
[9.1 框架不能替代设计](#9.1 框架不能替代设计)
[9.2 AT 模式的"脏写"陷阱](#9.2 AT 模式的"脏写"陷阱)
[9.3 TC 的高可用不是"免费"的](#9.3 TC 的高可用不是"免费"的)
[9.4 Seata AT 与 MySQL 的一个微妙边界](#9.4 Seata AT 与 MySQL 的一个微妙边界)
一、为什么需要框架?手写分布式事务的痛点
在理解各种框架之前,先想清楚一个问题:如果没有框架,我们手写分布式事务会面临什么?
答案是一张无休止的清单:全局事务 ID 的生成与传播、分支事务的注册与状态同步、各种异常下的重试与补偿、空回滚与悬挂的防御......这些机制每实现一次都需要数百行代码,而且极难测试正确性。更关键的是,这些代码与业务逻辑深度耦合,修改业务逻辑时极易破坏事务语义。
框架存在的意义,就是把这张清单里"与业务无关的通用机制"提取出来,让开发者只需关注业务语义本身。理解了这个出发点,再看各种框架的设计取舍,就会有完全不同的视角。
二、XA 协议与 JTA:历史的基石
2.1 XA 是什么?
XA 是 X/Open 组织在 1991 年提出的分布式事务规范,定义了事务管理器(TM)与资源管理器(RM,通常是数据库)之间的接口。JTA(Java Transaction API)是 Java 平台对 XA 规范的标准封装。
XA 的核心是两阶段提交协议,但与应用层 2PC 不同,它把协议的执行深入到了数据库驱动层。
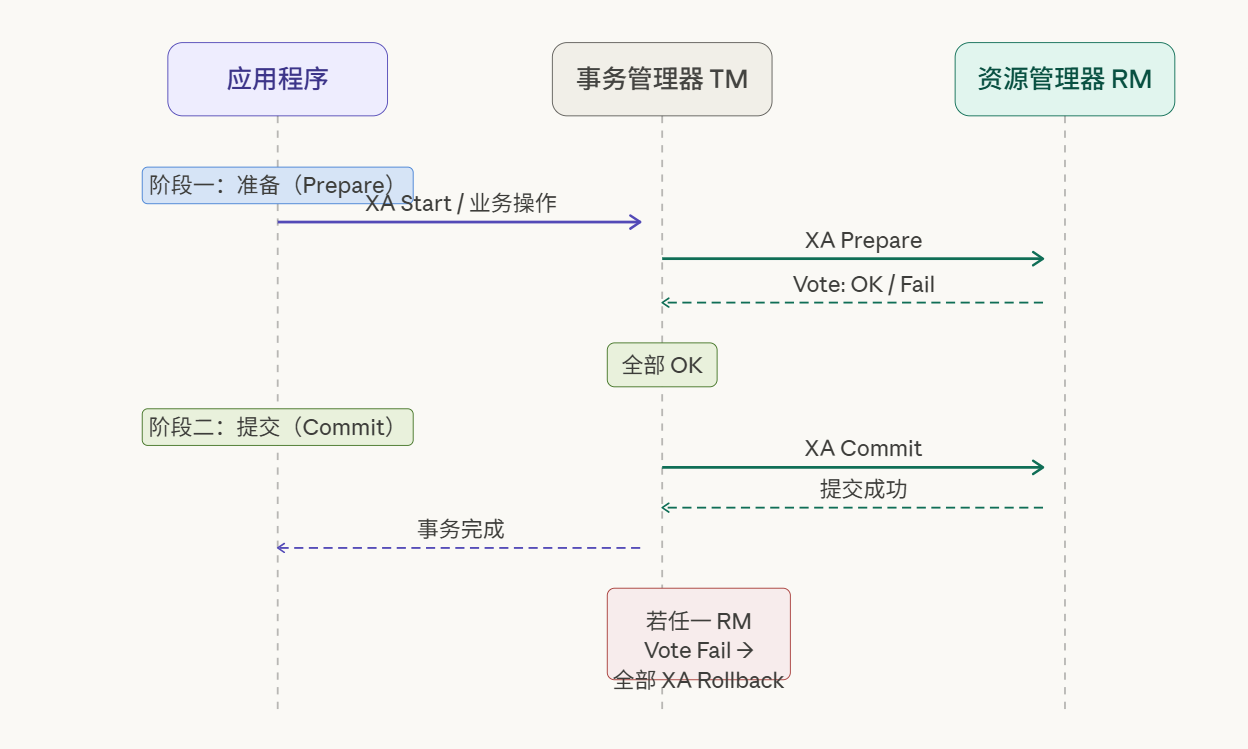
2.2 XA 的核心优势与致命弱点
XA 的最大优点是真正的 ACID ------事务的隔离性、原子性完全由数据库引擎保证,对应用层完全透明。Spring + Atomikos/Bitronix 的组合可以让你像写单机事务一样写分布式事务,@Transactional 一加就完事。
但 XA 有两个几乎无解的问题:
第一是性能。XA Prepare 之后,参与的数据库会持有数据库级别的行锁,直到 XA Commit 或 XA Rollback 到来。在网络调用期间,所有相关行都被锁定。这意味着其他任何事务试图修改这些行都会被阻塞------并发量一上来,锁等待时间会指数级增长。
第二是协调者的单点脆弱性。TM 在第一阶段结束、第二阶段开始之间崩溃,所有 RM 都持有锁等待指令,没有超时机制,系统陷入不确定的无限等待。这在生产环境不是理论问题,而是随时可能触发的灾难。
正因如此,XA/JTA 在互联网高并发系统中逐渐被抛弃,只在对强一致性要求极高、并发量相对可控的传统金融系统中保留使用。
三、Seata:为分布式事务而生的框架
3.1 Seata 的核心架构
Seata(Simple Extensible Autonomous Transaction Architecture)是阿里在 2019 年开源的分布式事务框架,其设计目标是:在保证最终一致性的前提下,最大程度降低对业务代码的侵入和对性能的影响。
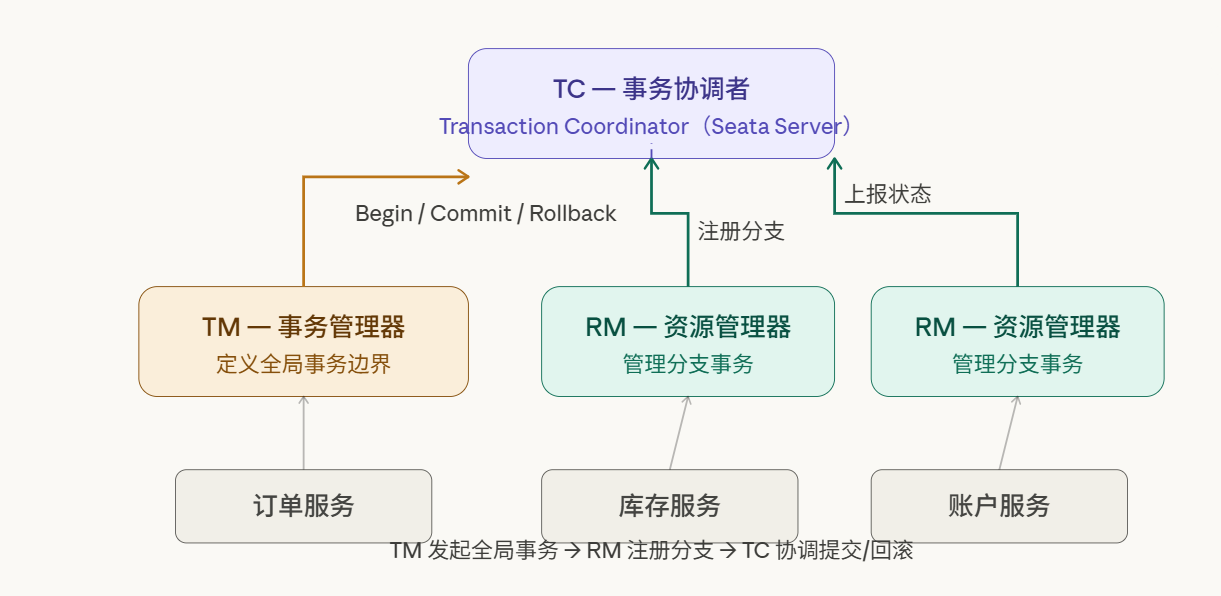
Seata 的三角色模型是理解所有模式的基础:TC(Transaction Coordinator)是独立部署的 Seata Server,是全局事务的"大脑";TM(Transaction Manager)嵌入在发起方服务中,负责开启和结束全局事务;RM(Resource Manager)嵌入在各参与方服务中,负责管理本地分支事务并与 TC 通信。
Seata 目前支持四种模式:AT、TCC、Saga、XA。它们共享同一套 TC/TM/RM 架构,但在"如何实现分支事务"这个问题上采取了截然不同的策略。
四、AT 模式:Seata 的核心创新
AT 模式(Automatic Transaction)是 Seata 最具代表性的模式,也是默认模式。它的核心思想是:让框架自动生成数据回滚所需的信息,从而实现对业务代码零侵入的最终一致性。
4.1 Undo Log:AT 模式的灵魂
AT 模式在每个参与方数据库中,要求额外创建一张 undo_log 表。框架通过代理数据库连接,在每条 DML 执行前后,自动记录数据的前镜像(BeforeImage)和后镜像(AfterImage)。

4.2 AT 模式的隔离机制:全局锁
AT 模式的第一阶段在本地事务提交后就释放了数据库行锁,这带来了一个新问题:在全局事务提交之前,另一个事务读到了这行已经修改但尚未全局提交的数据------这是"全局脏读"。
Seata 的解法是引入一个全局锁(Global Lock):RM 在注册分支事务时,向 TC 申请对相关数据行的全局锁。在全局事务完成之前,任何其他 AT 模式事务想要修改同一行数据,都必须等待全局锁释放。
这个设计非常精妙,也非常有争议。它在读已提交与可重复读之间找到了一个工程上的平衡点:本地数据库锁持有时间极短(仅在业务 SQL 执行期间),全局锁只用于协调跨服务的写冲突。代价是:全局锁的申请和释放需要额外的网络往返,TC 成为全局锁的单点,在写冲突严重的场景下依然会有明显的等待。
4.3 AT 模式的真实适用范围
AT 模式的文档经常写着"无侵入",但这个说法需要审慎理解。AT 模式有几个重要的前提条件:
数据库必须支持 UNDO_LOG(MySQL、PostgreSQL 支持,Oracle 有限制)。业务 SQL 必须是标准 DML,复杂的存储过程、触发器、级联操作可能导致 BeforeImage/AfterImage 生成不准确。undo_log 表必须与业务表在同一个数据源,不支持跨数据库实例的 AT 模式。
最隐蔽的限制是:AT 模式生成的反向 SQL 依赖于 BeforeImage,如果 AfterImage 与数据库实际状态不一致(比如有其他非 Seata 管理的操作改了这行数据),回滚会失败或产生错误结果 。Seata 对此有一个"脏数据校验"机制(afterImage 与实际数据库数据做 diff),但这又引入了额外的查询开销和复杂度。
五、TCC 模式:精细控制的代价
5.1 TCC 模式在 Seata 中的定位
Seata 的 TCC 模式与上篇文章讨论的"手写 TCC"本质相同,区别在于:Seata 提供了 TCC 的框架骨架,承担了全局事务协调、分支注册、超时检测、重试调度等通用职责,开发者只需实现 Try、Confirm、Cancel 三个接口的业务逻辑。
java
@LocalTCC
public interface InventoryService {
@TwoPhaseBusinessAction(
name = "deductStock",
commitMethod = "confirmDeduct",
rollbackMethod = "cancelDeduct"
)
boolean tryDeduct(BusinessActionContext ctx,
@BusinessActionContextParameter("itemId") Long itemId,
@BusinessActionContextParameter("count") int count);
boolean confirmDeduct(BusinessActionContext ctx);
boolean cancelDeduct(BusinessActionContext ctx);
}@LocalTCC 注解让 Seata 知道这是一个 TCC 接口;@TwoPhaseBusinessAction 声明了三个阶段的方法映射;@BusinessActionContextParameter 将参数保存到事务上下文,确保 Confirm/Cancel 执行时能够获取到原始参数。
5.2 AT vs TCC:不是优劣,是场景匹配
这两种模式在生产环境中是互补的,而不是替代关系。
AT 模式的"无侵入"是有代价的:它依赖自动生成的 Undo Log 来实现回滚,这意味着回滚的精度和正确性受限于框架的 SQL 解析能力。当业务逻辑涉及非幂等的外部调用(发送短信、调用第三方支付),AT 模式无能为力------它只能回滚数据库数据,不能撤销已经发出的外部调用。
TCC 模式的 Cancel 是你自己写的,你完全控制回滚的语义。你可以在 Cancel 里调用退款接口、撤销短信、通知第三方------任何业务意义上的"撤销"都可以实现。代价是:每个参与者都要实现三个方法,还要处理空回滚、悬挂、幂等这三个经典问题。

六、Saga 模式:长事务的工程解法
6.1 状态机驱动是 Seata Saga 的关键设计
Seata 的 Saga 模式不是简单的"执行 + 补偿"链条,而是基于一个显式的状态机(State Machine)。整个业务流程被建模为一张有向图,每个状态(State)是一个服务调用,每条边是状态之间的转换条件(成功 / 失败)。
这个状态机的定义以 JSON 格式存储,Seata 提供了可视化设计器。一个机票 + 酒店 + 支付的旅行预订流程大致如下:
java
{
"Name": "TravelBookingSaga",
"StartState": "BookFlight",
"States": {
"BookFlight": {
"Type": "ServiceTask",
"ServiceName": "flightService",
"ServiceMethod": "book",
"CompensateState": "CancelFlight",
"Next": "BookHotel"
},
"BookHotel": {
"Type": "ServiceTask",
"ServiceName": "hotelService",
"ServiceMethod": "book",
"CompensateState": "CancelHotel",
"Next": "ProcessPayment",
"Catch": [{ "Exceptions": ["Exception"], "Next": "CompensationTrigger" }]
},
"ProcessPayment": { "Type": "ServiceTask", ... },
"CompensationTrigger": { "Type": "CompensationTrigger" }
}
}状态机方式的优势是整个流程的业务语义清晰可追溯,每个状态的执行结果都被持久化,故障恢复时可以从上次失败的状态重新开始,而不必重放整个流程。
6.2 Saga 的隔离性问题与缓解策略
Saga 模式最被诟病的是缺乏隔离性。在正向流程执行过程中,已完成的步骤数据对外可见,而补偿流程尚未开始------这个时间窗口内的数据状态,可能被其他事务读取并基于它做出决策。
这在金融场景里尤为危险:用户 A 的账户刚被扣款(Saga 步骤 3),此时用户 B 的服务读取了 A 的余额并认为余额充足,然后 A 的 Saga 因步骤 4 失败而触发了补偿回滚------B 此时已经基于错误的数据做了决策。
Seata Saga 提供了一种"向前补偿"优化:对于部分步骤,可以通过重试(而不是回滚)来推进事务完成。这在幂等性有保证的情况下是可行的,且避免了部分补偿场景下的隔离性问题。
另一个工程上的常见做法是使用"语义锁":在第一个 Saga 步骤里,将相关业务数据打上"处理中"的标记,阻止其他流程基于这个数据做决策;只有整个 Saga 成功或补偿完毕后,才解除这个标记。这等于在业务层实现了一个粗粒度的隔离机制。
七、XA 模式:Seata 对传统 XA 的改良
7.1 Seata XA 模式的差异在哪里?
Seata 4.0 后引入了原生 XA 模式,与传统 XA 的最大区别是:Seata 接管了 XA 协调者(TM)的职责,并提供了完善的故障恢复机制。
传统 XA 的致命问题------协调者崩溃导致无限锁等待------在 Seata XA 模式中通过 TC 的持久化日志得到了部分缓解。Seata TC 将每个全局事务的状态持久化,重启后可以查询所有处于中间状态(Prepared)的 XA 分支,并推进它们到终态(Commit 或 Rollback)。
同时,Seata XA 模式通过复用已有的 TC/TM/RM 注册机制,让 XA 事务也能享受 Seata 的监控、告警、事务追踪等生态能力。
7.2 XA 模式的真实定位
尽管 Seata 改良了 XA,但 XA 模式在 Seata 中的定位依然是"当你有强一致性需求且无法接受业务侵入时的保底选项"。性能问题没有被解决,只是被管理得更好。
Seata 官方也明确建议:如果 AT 模式能满足需求,就不要使用 XA 模式。
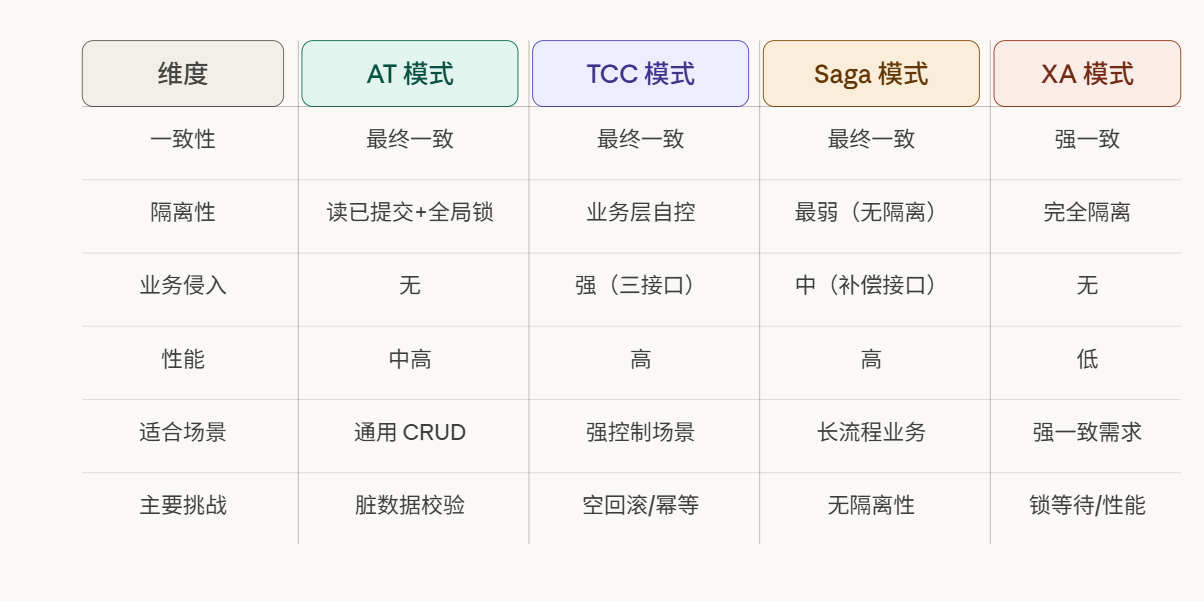
八、四模式横向对比与选型指南
九、生产实践中的深层思考
9.1 框架不能替代设计
Seata 的出现让分布式事务的门槛大幅降低,但这也带来了一种危险的倾向:用框架的存在来掩盖系统设计上的问题。
最典型的反模式是:把本可以通过合理的数据库设计放在同一个服务内解决的事务,硬拆成跨服务的分布式事务,然后用 Seata 来"修复"。这不是解决问题,是把问题复杂化后再用工具解决。
在引入 Seata 之前,一定要问自己:这个跨服务事务是业务领域边界决定的,还是过度拆分的产物? 许多场景通过合理的服务合并、领域聚合设计,可以完全消除分布式事务的需求。
9.2 AT 模式的"脏写"陷阱
AT 模式有一个容易被忽略的极端情况:非 Seata 管理的操作与 Seata AT 事务并发修改同一行数据。
假设事务 A(AT 模式)修改了库存行,生成了 AfterImage 并释放了本地锁。此时,一个不在 Seata 管理范围内的查询(或者直连数据库的运维操作)修改了同一行数据。随后事务 A 因某种原因需要回滚,Seata 会用 BeforeImage 生成反向 SQL,将数据恢复到事务 A 执行之前的状态------这次回滚会直接覆盖那次"插队修改",造成数据静默丢失。
Seata 的"脏数据校验"(afterImage diff)可以检测到这种情况并报警而不是强制回滚,但需要主动开启,且这个报警需要配套完善的告警处理流程,否则只是让问题变得"有迹可循",而不是真正解决了它。
9.3 TC 的高可用不是"免费"的
Seata Server(TC)是整个系统的核心协调者,它的可用性直接决定所有分布式事务的可用性。Seata 提供了集群模式,通过数据库或 Redis 进行状态共享,确保 TC 的高可用。
但这意味着:在极端情况下(TC 集群全部故障),所有正在进行的分布式事务会被悬挂,等待 TC 恢复后重试。对于低延迟要求的业务,这个等待窗口是不可接受的。因此,高可用的 Seata 部署需要额外的基础设施投入(数据库主备、Redis 集群),以及完善的监控告警体系。
9.4 Seata AT 与 MySQL 的一个微妙边界
AT 模式通过 SELECT ... FOR UPDATE 查询 BeforeImage,以确保读取的是加锁后的最新数据。但在 MySQL 默认的 RR 隔离级别下,SELECT ... FOR UPDATE 的行为有一些需要注意的细节:
当 WHERE 条件走了索引时,加的是行锁;当 WHERE 条件没有走索引(或者查询条件导致全表扫描)时,MySQL 会加表锁。在高并发场景下,一个写错的 SQL 导致 BeforeImage 查询走了全表扫描,会让整张表被锁住,瞬间引发大面积锁等待。这是 AT 模式在生产环境中需要特别注意的性能陷阱。
十、结语:框架是工具,理解才是武器
从 XA 到 Seata 四模式,这条演化路线的本质,是对同一个不可能三角------强一致性、高可用性、低侵入性------在不同场景下的不同取舍。
XA 选了强一致性,牺牲了可用性和吞吐量。AT 模式选了低侵入性,用全局锁换来了相对合理的一致性。TCC 模式选了精细控制,把复杂度显式化地交给了开发者。Saga 选了高可用和长事务支持,接受了最弱的隔离性。
理解每种模式背后"放弃了什么",比记住"它能做什么"重要得多。框架选型的本质是:找到你的业务最不能接受哪个妥协,然后选择在那个维度上保留最强保证的方案。
这也是为什么所有关于框架的对比文章,最后都会回到那句朴素的结论:没有最好的方案,只有最适合的方案。但能说清楚"为什么适合",才是真正理解了分布式事务这个领域。