大家好,我是双越。wangEditor 作者,前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP,前端面试派 作者。
我正致力于两个项目的开发和升级,感兴趣的可以私信我,加入项目小组。
本文介绍 AI 智能体 tools 工具模块的架构和流程。
tools 在 agent 中的价值和作用
在 AI Agent 架构中,LLM 本身只是一个"大脑"------它能理解意图、制定计划、进行推理,但它无法直接感知外部世界,也无法执行任何实际操作。Tools(工具)是 Agent 的"手脚" ,是连接 LLM 推理能力与真实世界的桥梁。
没有 tools,Agent 只能输出文字;有了 tools,Agent 才能真正完成任务:搜索信息、操作文件、执行代码、调用 API、控制浏览器......这正是 Manus 类 Agent 之所以强大的根本原因。
Tools 的核心价值体现在三个层面:
能力扩展:突破 LLM 的知识截止日期和上下文限制,让 Agent 能够实时获取信息、与外部系统交互。
任务执行:将 LLM 的规划结果落地为真实的系统操作,完成从"知道怎么做"到"真正做到"的转化。
状态感知:通过工具返回的结果,让 Agent 感知当前环境状态,从而进行下一步推理,形成"思考 → 行动 → 观察"的闭环。
5 个常见的 Agent Tools 示例
1. shell_exec --- 终端执行工具 执行 shell 命令,是 Agent 操作操作系统的核心能力。可用于运行脚本、安装依赖、编译代码、管理进程等,是实现"自动化编程助手"的基础。
2. browser_navigate --- 浏览器控制工具 基于 Playwright 驱动无头浏览器,实现页面导航、内容抓取、表单填写、截图等操作。让 Agent 具备像人一样浏览网页的能力。
3. file_read / file_write --- 文件系统工具 读写本地文件,是 Agent 持久化信息、处理文档的基础工具。配合代码执行工具,可实现完整的文件处理工作流。
4. web_search --- 网络搜索工具 调用搜索引擎 API 获取实时信息,弥补 LLM 知识截止日期的缺陷。是 Agent 获取最新资讯、事实核查的核心途径。
5. code_execute --- 代码执行工具 在沙箱环境中运行 Python/JavaScript 等代码,让 Agent 具备数学计算、数据分析、图像处理等复杂计算能力。
整体架构设计
Tools 模块并非简单的函数集合,而是一个由四个阶段组成的完整调度系统:
markdown
┌─────────────────────────────────────────────────────────────┐
│ Agent Core │
└──────────────────────────┬──────────────────────────────────┘
│
┌─────────────────▼──────────────────┐
│ 1. 注册阶段 │
│ Tool定义 → Schema校验 → 向量化 │
└─────────────────┬──────────────────┘
│
┌─────────────────▼──────────────────┐
│ 2. RAG 筛选阶段 │
│ 语义检索 → 规则过滤 → 注入LLM │
└─────────────────┬──────────────────┘
│
┌─────────────────▼──────────────────┐
│ 3. 调用阶段 │
│ 参数校验 → 权限检查 → 缓存 → 入队 │
└─────────────────┬──────────────────┘
│
┌─────────────────▼──────────────────┐
│ 4. 执行阶段 │
│ 沙箱执行 → 并发控制 → 重试 → 结果 │
└────────────────────────────────────┘注册阶段
注册阶段发生在 Agent 启动时,是一次性的初始化过程。它将所有工具的元信息、执行逻辑、安全配置统一纳入 Registry 管理,并为后续的 RAG 筛选做好准备。
注册流程
开发者编写符合 ToolDefinition 规范的工具文件,调用 registry.register(tool) 进行注册。Registry 首先对 Tool 的 Schema 进行合法性校验,检查参数定义是否符合 JSON Schema 规范、名称是否唯一、必填字段是否完整。校验通过后,工具被写入 tools Map,并按 category 建立分类索引。
与此同时,Registry 将 Tool 的 name + description + category 拼接后进行向量化(调用 embedding 模型),并将向量存入 Vector DB(如 Qdrant、Chroma)。这一步是 RAG 筛选的数据基础。
最后,Registry 将每个 Tool 的参数 Schema 转换为 LLM 能理解的 function_call 格式(兼容 Claude tool_use / OpenAI function calling),备用于注入 LLM context。
ToolDefinition 数据结构(伪代码)
js
interface ToolDefinition {
// ------ 基本信息 ------
name: string // 唯一标识,snake_case,如 "file_read"
version: string // 版本号,如 "1.0.0"
description: string // 自然语言描述,供 LLM 和向量化使用
category: ToolCategory // filesystem | browser | shell | search | code | api
// ------ 参数定义(JSON Schema) ------
parameters: {
type: "object"
properties: Record<string, JSONSchema>
required: string[]
}
// ------ 安全配置 ------
security: {
level: "safe" | "moderate" | "dangerous"
requireConfirm: boolean // 执行前是否需用户确认
sandbox: boolean // 是否在 Worker 沙箱中运行
allowedPaths?: string[] // 文件操作路径白名单
rateLimit?: {
maxCalls: number
windowMs: number
}
}
// ------ 执行配置 ------
execution: {
timeout: number // 超时时间(ms)
retryable: boolean // 是否支持重试
maxRetries: number // 最大重试次数
cacheable: boolean // 结果是否可缓存
cacheTTL?: number // 缓存有效期(ms)
}
// ------ 实际执行函数 ------
execute: (params: unknown, context: ToolContext) => Promise<ToolResult>
}
// 执行上下文,由框架注入
interface ToolContext {
sessionId: string
workDir: string
signal: AbortSignal // 支持外部取消
logger: Logger
emit: (event: string, data: unknown) => void // 流式输出
}
// 统一返回结构
interface ToolResult {
success: boolean
data?: unknown
error?: {
code: string
message: string
retryable: boolean
suggestion?: string // 给 LLM 的错误建议,引导下一步
}
metadata?: {
duration: number
cached: boolean
}
}RAG 筛选阶段
为何需要 RAG 筛选?
当 Agent 的工具数量达到 50 个甚至更多时,如果每次都将全部 tool schema 注入 LLM context,会带来三个严重问题:
Token 浪费 :每个 tool 的 schema 描述约占 200500 tokens,50 个工具就是 10,00025,000 tokens 的固定开销,在每一轮对话中重复消耗。
LLM 决策干扰:过多无关工具会稀释 LLM 的注意力,使其更容易选错工具,甚至产生工具幻觉(调用一个并不存在的工具名)。
上下文窗口压力:工具列表占据了宝贵的 context 窗口,压缩了历史对话和任务信息的空间。
RAG 筛选的核心思想是:每次只给 LLM 提供与当前任务最相关的 10~15 个工具,动态组合、按需供给。
筛选过程
第一步:向量化 query 将用户的当前任务描述(或 Agent 当前的子任务目标)通过 embedding 模型转换为向量,使用与注册时相同的模型,保证向量空间一致。
第二步:语义相似度检索(Top-K 召回) 在 Vector DB 中计算 query 向量与所有 tool 描述向量的余弦相似度,召回相似度最高的 Top-20 个候选工具。
第三步:规则二次过滤 仅靠语义相似度不够可靠,需要叠加规则过滤:排除当前任务场景不需要的 category;排除超出当前权限的 dangerous 级别工具;保留与当前工作目录或环境相关的工具。最终将候选工具缩减至 10~15 个。
第四步:注入 LLM context 将筛选后的工具 schema 动态拼装,注入本轮 LLM 请求的 tools 参数中。
兜底机制 :若 LLM 返回了不在本次筛选结果中的 tool_name(幻觉),Executor 捕获 ToolNotFoundError 后,自动触发一次扩大范围的重新检索(放宽 Top-K 至 40),再次筛选后重试,而不是直接报错给用户。
调用阶段
调用阶段是 LLM 返回 tool_use 后、实际执行前的前置验证层,核心职责是"拦截一切不合法或不安全的调用"。
权限检查
根据 Tool 的 security.level 进行分级校验:safe 级别直接通过;moderate 级别检查当前 session 是否有对应 category 的操作权限;dangerous 级别检查是否已获得用户的显式确认,未确认则暂停并向上层请求授权。
安全检查
权限通过后,进行具体的安全防护:
- 路径白名单校验 :对文件类工具,将输入路径
path.resolve()后与allowedPaths比对,防止路径穿越攻击(如../../etc/passwd) - 命令注入检测 :对 shell 类工具,扫描命令中是否包含
;、&&、|、$()等危险字符 - 输出脱敏:对所有工具的返回内容,过滤可能包含的 API Key、密码、Token 等敏感信息
是否命中缓存?
若该工具标记了 cacheable: true,则以 toolName + hash(params) 为 key 查询 LRU 缓存。命中则直接返回缓存结果,跳过后续所有执行步骤,显著提升重复调用的响应速度。
放入 Queue 队列
所有通过前置检查的调用,统一放入基于 p-queue 实现的并发队列中。可以按 category 设置独立的并发上限(例如 browser 工具最多 3 个并发,shell 工具最多 5 个),避免资源争抢。限流超出时返回 RATE_LIMIT_EXCEEDED 错误,携带建议等待时间。
执行阶段
统一的执行引擎
所有 Tool 的 execute() 函数都由 ToolExecutor 统一调度,而非直接调用。执行引擎负责包裹四层保障机制:
错误重试(Exponential Backoff) :网络超时、临时性服务不可用等可重试错误,按指数退避策略(1s → 2s → 4s)自动重试,最多重试 maxRetries 次。不可重试的错误直接返回。
沙箱机制(Worker Isolation) :对 security.sandbox: true 的危险工具,在独立的 worker_thread 中运行,设置内存上限(256MB)和执行时间上限。沙箱崩溃不影响主进程。
并发控制(p-queue) :通过队列的 concurrency 参数限制同类工具的并发数,配合 AbortSignal 支持外部取消正在排队或执行中的任务。
缓存结果写入 :执行成功后,若 cacheable: true,将结果以 LRU 策略写入内存缓存,设置 cacheTTL 过期时间。
执行引擎伪代码
js
class ToolExecutor {
async execute(toolName, params, context) {
const tool = this.registry.get(toolName)
if (!tool) throw new ToolNotFoundError(toolName)
// 前置校验(调用阶段)
await this.validateParams(tool, params)
await this.checkPermission(tool, context)
await this.checkSecurity(tool, params, context)
// 缓存命中
if (tool.execution.cacheable) {
const cached = this.cache.get(cacheKey(toolName, params))
if (cached) return { ...cached, metadata: { cached: true } }
}
// 限流
await this.rateLimiter.check(toolName, context.sessionId)
// 入队执行
return this.queue.add(() => this.runWithGuards(tool, params, context))
}
private async runWithGuards(tool, params, context, attempt = 1) {
// Timeout + 外部取消 双重守护
const timeoutSignal = AbortSignal.timeout(tool.execution.timeout)
const signal = AbortSignal.any([context.signal, timeoutSignal])
try {
// 沙箱 or 直接执行
const result = tool.security.sandbox
? await this.sandboxExecute(tool, params, { ...context, signal })
: await tool.execute(params, { ...context, signal })
// 写缓存
if (tool.execution.cacheable) {
this.cache.set(cacheKey(tool.name, params), result, tool.execution.cacheTTL)
}
return { ...result, metadata: { duration: elapsed(), cached: false } }
} catch (err) {
const normalized = normalizeError(err)
// 可重试 & 未超上限
if (tool.execution.retryable
&& attempt <= tool.execution.maxRetries
&& isRetryableError(normalized)) {
await sleep(exponentialBackoff(attempt)) // 1s, 2s, 4s...
return this.runWithGuards(tool, params, context, attempt + 1)
}
// 最终失败,返回结构化错误(含 LLM 建议)
return {
success: false,
error: {
code: normalized.code,
message: normalized.message,
retryable: false,
suggestion: buildSuggestion(normalized) // 告诉 LLM 下一步怎么做
}
}
}
}
}详细流程图
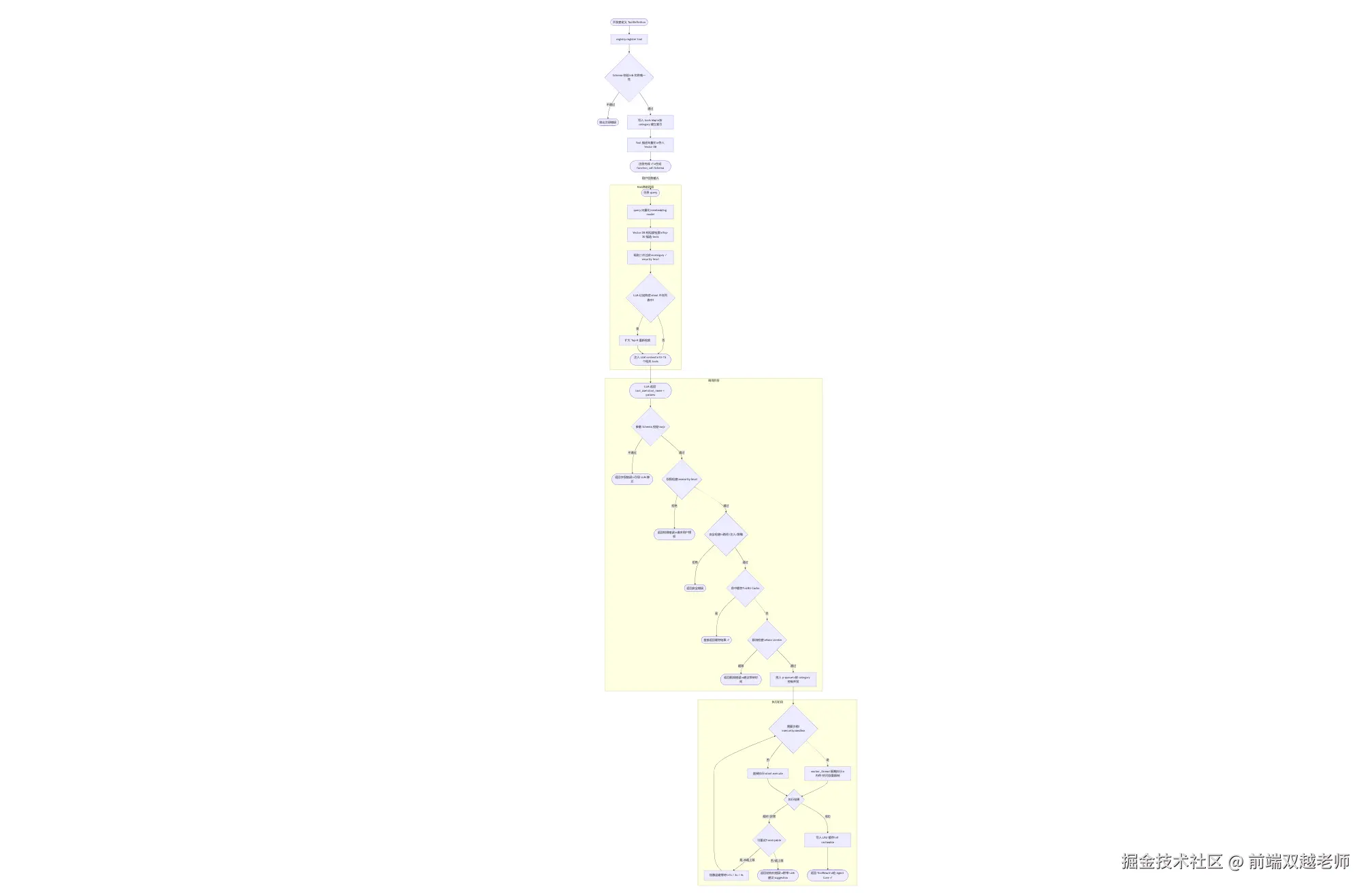
看不清楚的,可以把以下代码复制到这个网站 mermaid.live/
css
flowchart TD
A([开发者定义 ToolDefinition]) --> B[registry.register tool]
B --> C{Schema 校验\n& 名称唯一性}
C -- 不通过 --> D([抛出注册错误])
C -- 通过 --> E[写入 tools Map\n按 category 建立索引]
E --> E2[Tool 描述向量化\n存入 Vector DB]
E2 --> F([注册完成 ✓\n生成 function_call Schema])
F -.->|用户任务输入| G
subgraph RAG筛选阶段
G([任务 query]) --> G1[query 向量化\nembedding model]
G1 --> G2[Vector DB 相似度检索\nTop-20 候选 tools]
G2 --> G3[规则二次过滤\ncategory / security level]
G3 --> G4{LLM 幻觉兜底\ntool 不在列表中?}
G4 -- 否 --> G5([注入 LLM context\n10~15 个相关 tools])
G4 -- 是 --> G6[扩大 Top-K 重新检索] --> G5
end
G5 --> H
subgraph 调用阶段
H([LLM 返回 tool_use\ntool_name + params]) --> I{参数 Schema 校验\najv}
I -- 不通过 --> J([返回字段错误\n引导 LLM 修正])
I -- 通过 --> K{权限检查\nsecurity.level}
K -- 拒绝 --> L([返回权限错误\n请求用户授权])
K -- 通过 --> K2{安全检查\n路径/注入/脱敏}
K2 -- 拒绝 --> L2([返回安全错误])
K2 -- 通过 --> M{命中缓存?\nLRU Cache}
M -- 是 --> N([直接返回缓存结果 ✓])
M -- 否 --> M2{限流检查\nRate Limiter}
M2 -- 超限 --> M3([返回限流错误\n建议等待时间])
M2 -- 通过 --> O[放入 p-queue\n按 category 控制并发]
end
subgraph 执行阶段
O --> P{需要沙箱?\nsecurity.sandbox}
P -- 是 --> P1[worker_thread 隔离执行\n内存/时间双重限制]
P -- 否 --> P2[直接执行\ntool.execute]
P1 --> Q
P2 --> Q
Q{执行结果} -- 超时/异常 --> R{可重试?\nretryable}
R -- 是,未超上限 --> S[指数退避等待\n1s / 2s / 4s]
S --> P
R -- 否/超上限 --> T([返回结构化错误\n附带 LLM 建议 suggestion])
Q -- 成功 --> U[写入 LRU 缓存\nif cacheable]
U --> V([返回 ToolResult\n给 Agent Core ✓])
end最后
通过以上四个阶段的拆解,可以清楚地看到:Tools 模块绝不是一堆简单的执行函数,而是一个完整的调度系统。
它需要在注册时完成规范化与向量索引,在调用前完成安全防线,在执行中完成容错保障,在整个生命周期内完成智能筛选。每一层都有其不可或缺的价值:
- 没有 RAG 筛选,工具数量一旦增多,token 消耗和 LLM 决策质量都会急剧恶化
- 没有 安全检查层,LLM 的任何一次幻觉或恶意 prompt 都可能变成系统级风险
- 没有 执行引擎的重试与沙箱,脆弱的单次调用无法支撑复杂的长程任务
- 没有 缓存与并发控制,Agent 在高频、并发场景下的性能会成为瓶颈
一个真正生产可用的 Agent,其 Tools 模块的复杂度往往不亚于业务逻辑本身。把这个调度系统做扎实,是 Agent 从"能用"走向"好用"的关键基础。