
文章目录
-
- 介绍
-
- [1. **背景与动机:生命的语言太难懂**](#1. 背景与动机:生命的语言太难懂)
- [2. **Evo 2的诞生:一个"生物学通才"**](#2. Evo 2的诞生:一个“生物学通才”)
- [3. **它能做什么?------预测与设计的统一**](#3. 它能做什么?——预测与设计的统一)
- [4. **模型的"可解释性":揭开黑箱**](#4. 模型的“可解释性”:揭开黑箱)
- [5. **安全与伦理考量**](#5. 安全与伦理考量)
- 故事的结尾与未来展望
- 代码
- 参考
介绍
1. 背景与动机:生命的语言太难懂
- 尽管我们已经能够测序、合成和编辑DNA,但对基因组的"语法"和"语义"理解仍然非常有限。
- 现有方法难以预测基因组变化的后果,也无法智能地设计新的生物系统。
- 科学家们希望构建一个能够"理解生命语言"的AI模型,就像大型语言模型理解自然语言一样。
2. Evo 2的诞生:一个"生物学通才"
- 训练数据 :Evo 2 在 9万亿个DNA碱基对 上训练,涵盖细菌、古菌、真核生物和噬菌体,构建了一个名为 OpenGenome2 的高质量数据集。
- 模型规模 :
- Evo 2 7B:70亿参数
- Evo 2 40B:400亿参数
- 上下文长度 :支持 100万个token(碱基对),使其能够捕捉从基因到整个基因组的长期依赖关系。
- 架构创新 :采用 StripedHyena 2 混合架构,兼顾效率和长序列建模能力。
3. 它能做什么?------预测与设计的统一
Evo 2不仅能"读懂"DNA,还能"写出"DNA,具备以下能力:
预测能力(Zero-shot)
- 突变效应预测:无需微调,Evo 2能预测单核苷酸变异对基因功能的影响,识别致病突变(如BRCA1基因)。
- 跨物种泛化:在细菌、古菌、真核生物中都能准确预测突变对蛋白质、RNA和基因essentiality的影响。
- 人类临床变异 :在ClinVar、SpliceVarDB等数据集中,Evo 2在编码区、非编码区、插入/缺失等变异类型上表现优异,尤其在非SNV变异上领先。
生成能力
- 基因补全:给定基因上游序列,Evo 2能生成完整的基因序列,且氨基酸恢复率高。
- 基因组生成 :
- 成功生成人类线粒体基因组,包含正确的基因数量、顺序和结构。
- 生成 Mycoplasma genitalium(约58万bp) 和 酵母染色体III(约33万bp) 的完整基因组,生成基因的功能和结构与天然基因高度相似。
- 染色质可及性设计 :结合Enformer/Borzoi模型,Evo 2能设计出具有特定染色质开放模式的DNA序列,并在小鼠和人类细胞中实验验证成功,甚至能"写入"莫尔斯电码(如"EVO2"、"ARC")。
4. 模型的"可解释性":揭开黑箱
- 使用稀疏自编码器(SAE) 解析Evo 2内部神经元的活动,发现其学会了识别:
- 基因结构(外显子、内含子、边界)
- 调控元件(转录因子结合位点)
- 蛋白质结构(α螺旋、β折叠)
- 移动遗传元件(如原噬菌体、CRISPR间隔序列)
- 这些特征不仅能泛化到不同物种(如猛犸象),还能用于基因组注释。
5. 安全与伦理考量
- 数据过滤:剔除了感染真核生物的病毒序列,防止模型被用于设计致病病毒。
- 测试验证:Evo 2在人类病毒相关任务上表现差(高困惑度、低生成恢复率),说明过滤措施有效。
- 种族偏见评估:模型在变异效应预测中未表现出明显的祖先偏见。
故事的结尾与未来展望
Evo 2 不仅是技术的突破,更是生物学研究与工程设计的通用工具 。它统一了分子、细胞、组织、个体乃至物种层面的信息表示,预示着一个可编程生物学的未来。
未来方向包括:
- 结合功能实验数据(如CRISPR筛选、RNA-seq)增强模型能力;
- 使用强化学习或微调优化生成序列的功能性;
- 探索多模态模型,整合基因组、表观组、转录组等多层次信息;
- 持续推动开源、安全、负责任的AI生物技术发展。
生物体的所有生命活动都通过 DNA 来编码信息。尽管基因测序、合成和编辑工具已经改变了生物研究的方式,但我们对于基因组所编码的极其复杂的结构仍缺乏足够的理解,无法预测许多类别的基因组变化所产生的影响,也无法智能地构建新的生物系统。从不同生物体的基因序列中学习信息的人工智能模型在预测和设计能力方面已经取得了显著的进步1,2。在此,我们介绍 Evo 2,这是一款基于涵盖所有生命领域的一份精心整理的基因图谱中的 9 万亿个 DNA 碱基对进行训练的生物基础模型,具有 100 万个标记的上下文窗口和单核苷酸分辨率。Evo 2 能够准确预测基因变异(从非编码致病突变到具有临床意义的 BRCA1 变异)的功能影响,无需针对特定任务进行微调。机制可解释性分析表明,Evo 2 学习与生物学特征相关的表示,包括外显子-内含子边界、转录因子结合位点、蛋白质结构元素和噬菌体基因组区域。Evo 2 的生成能力能够在基因组层面生成线粒体、原核生物和真核生物的序列,其自然度和连贯性比以往的方法更高。Evo 2 还在预测模型3、4 的引导下以及在推理时间搜索的辅助下,能够生成经过实验证实的染色质可及性模式。我们已将 Evo 2 完全开放,包括模型参数、训练代码5、推理代码以及 OpenGenome2 数据集,以加速对生物复杂性的探索和设计。
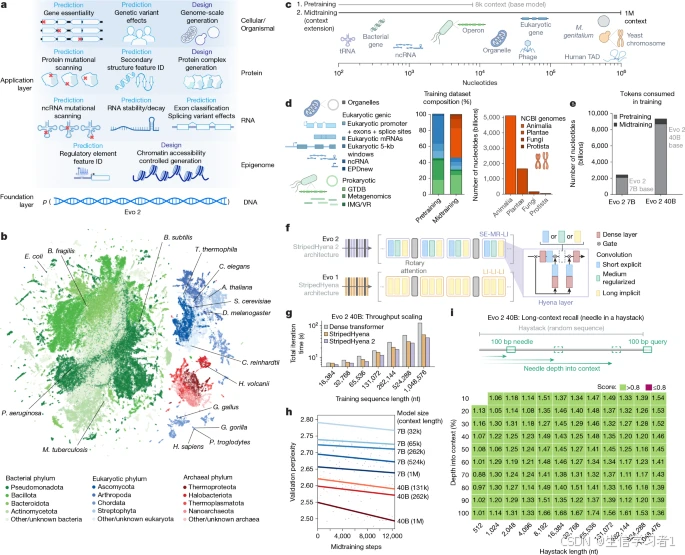
生物研究涵盖了从分子到系统再到生物体的不同尺度,旨在理解并设计生命各个领域中的功能组件。要创建一台能够跨越生命多样性设计功能的机器,就需要它学习一种深度的、通用的生物复杂性表示。尽管这种复杂性超出了人类直觉的理解范围,但人工智能领域的进步提供了一个通用框架,该框架利用大规模的数据和计算来揭示更高层次的模式6,7。我们推断,训练具有这些能力的模型需要涵盖生物多样性全范围的数据,以发现类似于其他领域中发现的涌现特性8。
我们之前已经证明,基于原核生物基因组序列训练的机器学习模型能够模拟 DNA、RNA 和蛋白质的功能,以及它们之间相互作用所形成的复杂分子机器1,2。在此,我们推出了 Evo 2 这一生物基础模型,该模型基于涵盖所有生命领域的代表性基因组样本进行训练。我们通过数据整理、模型架构、大规模预训练、高级可解释性方法以及推理时的预测和生成方法等进步,将序列建模范式扩展到了真核生物基因组的规模和复杂性上。
Evo 2 更加注重综合能力而非针对特定任务的优化,这在生物序列建模领域中是一个重要的里程碑,为与中心法则所有形式相关的预测和设计任务奠定了广泛的基础,这些任务涵盖了从分子到基因组规模的范围,并且能够在所有生命领域中通用。
代码
https://github.com/arcinstitute/evo2
参考
- Genome modelling and design across all domains of life with Evo 2
- https://github.com/arcinstitute/evo2