1 题目
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。
示例 1:
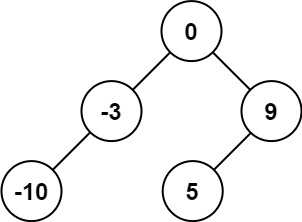
输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:示例 2:
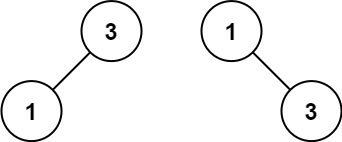
输入:nums = [1,3]
输出:[3,1]
解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums按 严格递增 顺序排列
2 代码实现
c++
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
TreeNode* buildBST(vector<int>& nums, int l ,int r ){
if (l > r ){
return nullptr;
}
int mid = l + (r - l ) / 2 ;
TreeNode* root = new TreeNode(nums[mid]);
root -> left = buildBST(nums, l , mid -1 );
root -> right = buildBST(nums, mid + 1 , r );
return root ;
}
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
return buildBST(nums , 0 , nums.size() - 1 ) ;
}
};js
javascript
/**
* Definition for a binary tree node.
* function TreeNode(val, left, right) {
* this.val = (val===undefined ? 0 : val)
* this.left = (left===undefined ? null : left)
* this.right = (right===undefined ? null : right)
* }
*/
/**
* @param {number[]} nums
* @return {TreeNode}
*/
var sortedArrayToBST = function(nums) {
const buildBST = (l, r ) => {
if (l > r ) return null ;
const mid = l + Math.floor((r - l ) / 2 );
const root = new TreeNode(nums[mid]);
root.left = buildBST(l , mid - 1 );
root.right = buildBST(mid + 1, r );
return root ;
};
return buildBST(0, nums.length - 1);
};思考
我隐约记得二叉搜索树的中序遍历就是有序数组。。然后呢,怎么返回去构造?
题解
问题分析与解题思路
要将升序数组转换为平衡二叉搜索树(BST),核心思路是利用 BST 和平衡树的特性:
- BST 特性:中序遍历结果为升序数组,因此数组的中间元素作为根节点,左半部分为左子树,右半部分为右子树。
- 平衡特性:每次选择数组中点作为根节点,能保证左右子树的节点数差不超过 1,天然满足平衡要求。
具体步骤:
- 找到当前数组的中间元素,作为当前子树的根节点。
- 递归处理左半数组,构建左子树。
- 递归处理右半数组,构建右子树。
- 返回当前根节点。
完整 C++ 代码实现
#include <vector>
using namespace std;
// 定义二叉树节点结构(LeetCode默认定义)
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
// 调用递归函数,初始范围是整个数组[0, nums.size()-1]
return buildBST(nums, 0, nums.size() - 1);
}
private:
// 递归构建BST:参数为数组、当前处理区间的左边界l、右边界r
TreeNode* buildBST(vector<int>& nums, int l, int r) {
// 递归终止条件:左边界 > 右边界,说明当前区间无元素,返回空节点
if (l > r) {
return nullptr;
}
// 选择中间位置作为根节点(整数除法向下取整,也可以用(l + r + 1)/2选右中点,结果也正确)
int mid = l + (r - l) / 2; // 等价于(l+r)/2,避免溢出
// 创建当前根节点
TreeNode* root = new TreeNode(nums[mid]);
// 递归构建左子树:左区间[l, mid-1]
root->left = buildBST(nums, l, mid - 1);
// 递归构建右子树:右区间[mid+1, r]
root->right = buildBST(nums, mid + 1, r);
// 返回当前根节点
return root;
}
};
// 测试代码(可选,用于验证)
#include <iostream>
// 中序遍历验证BST特性(结果应与输入数组一致)
void inorderTraversal(TreeNode* root) {
if (root == nullptr) return;
inorderTraversal(root->left);
cout << root->val << " ";
inorderTraversal(root->right);
}
int main() {
vector<int> nums = {-10, -3, 0, 5, 9};
Solution sol;
TreeNode* root = sol.sortedArrayToBST(nums);
// 中序遍历输出:-10 -3 0 5 9(验证BST正确性)
inorderTraversal(root);
return 0;
}代码关键部分解释
- 递归终止条件 :
if (l > r) return nullptr,当区间无元素时,返回空节点,结束当前递归分支。 - 中间节点选择 :
int mid = l + (r - l) / 2,避免直接用(l + r) / 2导致整数溢出(比如 l 和 r 都是大数时),同时保证每次选中点作为根,满足平衡要求。 - 递归构建子树 :
- 左子树:处理
[l, mid-1]区间,对应数组左半部分,值都小于根节点(符合 BST 左子树值更小的特性)。 - 右子树:处理
[mid+1, r]区间,对应数组右半部分,值都大于根节点(符合 BST 右子树值更大的特性)。
- 左子树:处理
- 测试验证:通过中序遍历输出结果,若与输入升序数组一致,说明 BST 构建正确;平衡特性由 "选中点" 的逻辑天然保证。
总结
- 核心逻辑:利用升序数组的中点作为根节点,递归构建左右子树,既满足 BST 的中序遍历特性,又保证平衡(左右子树高度差≤1)。
- 关键细节 :选择中点时用
l + (r - l)/2避免溢出,递归终止条件是区间无元素(l > r)。 - 灵活性 :中点也可选择
(l + r + 1)/2(右中点),最终结果不同但仍满足 "平衡 BST" 要求(如示例中两种答案均正确)。
js版本
问题分析与解题思路(JS 版)
核心思路和 C++ 版本完全一致:利用升序数组 + 中点作为根节点的特性,递归构建平衡二叉搜索树(BST)。
- BST 特性:中序遍历是升序数组,因此中点为根,左半数组构建左子树,右半数组构建右子树。
- 平衡特性:每次选中点作为根,左右子树节点数差≤1,天然满足平衡要求。
完整 JavaScript 代码实现
// 定义二叉树节点类(模拟LeetCode的TreeNode结构)
class TreeNode {
constructor(val, left = null, right = null) {
this.val = val;
this.left = left;
this.right = right;
}
}
/**
* @param {number[]} nums
* @return {TreeNode}
*/
var sortedArrayToBST = function(nums) {
// 递归构建BST的辅助函数
const buildBST = (l, r) => {
// 递归终止条件:左边界 > 右边界,无元素可构建,返回null
if (l > r) return null;
// 计算中点(避免(l + r)溢出,JS中数字范围大,但习惯用这种写法)
const mid = l + Math.floor((r - l) / 2);
// 创建当前根节点
const root = new TreeNode(nums[mid]);
// 递归构建左子树(左区间:[l, mid-1])
root.left = buildBST(l, mid - 1);
// 递归构建右子树(右区间:[mid+1, r])
root.right = buildBST(mid + 1, r);
// 返回当前根节点
return root;
};
// 初始调用:处理整个数组[0, nums.length-1]
return buildBST(0, nums.length - 1);
};
// 测试代码(验证功能)
// 中序遍历验证BST特性(输出应与输入数组一致)
const inorderTraversal = (root) => {
const res = [];
const traverse = (node) => {
if (!node) return;
traverse(node.left);
res.push(node.val);
traverse(node.right);
};
traverse(root);
return res;
};
// 测试示例1
const nums1 = [-10, -3, 0, 5, 9];
const root1 = sortedArrayToBST(nums1);
console.log(inorderTraversal(root1)); // 输出:[-10, -3, 0, 5, 9]
// 测试示例2
const nums2 = [1, 3];
const root2 = sortedArrayToBST(nums2);
console.log(inorderTraversal(root2)); // 输出:[1, 3]代码关键部分解释
- TreeNode 类 :模拟 LeetCode 中二叉树节点的结构,包含
val(节点值)、left(左子节点)、right(右子节点)三个属性。 - 递归辅助函数
buildBST:- 参数
l/r:当前处理数组的左 / 右边界(闭区间),避免频繁切割数组(提升性能)。 - 终止条件:
l > r时返回null,表示当前区间无元素,结束递归。 - 中点计算:
Math.floor((r - l) / 2)保证取整数中点(JS 中除法会返回浮点数,需向下取整)。
- 参数
- 测试验证 :
inorderTraversal函数通过中序遍历输出节点值,结果应与输入升序数组一致,验证 BST 构建正确;平衡特性由 "选中点" 逻辑天然保证。
总结
- 核心逻辑:JS 版本和 C++ 版本思路完全一致,通过递归选数组中点作为根节点,分别构建左右子树。
- JS 特有细节 :需手动定义
TreeNode类,除法后用Math.floor取整,避免浮点数问题。 - 性能优化 :通过边界索引(
l/r)而非切割数组,减少数组拷贝开销,时间复杂度O(n)(每个节点构建一次),空间复杂度O(logn)(递归栈深度,平衡树的高度)。
3 题目
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
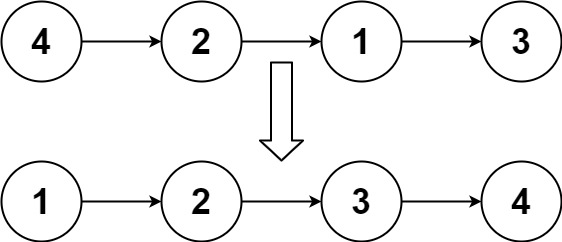
输入:head = [4,2,1,3]
输出:[1,2,3,4]示例 2:
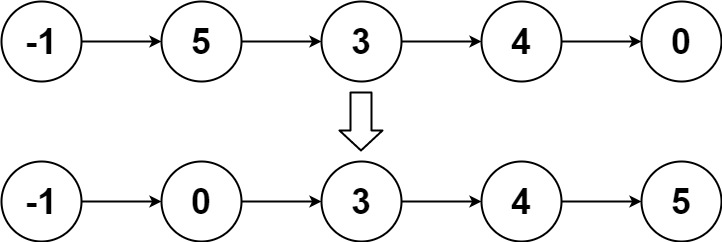
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]示例 3:
输入:head = []
输出:[]提示:
- 链表中节点的数目在范围
[0, 5 * 104]内 -105 <= Node.val <= 105
进阶: 你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
4 代码实现
c++
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
private:
ListNode* findMid (ListNode* head ){
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* slow = head ;
ListNode* fast = head -> next ;
while (fast != nullptr && fast -> next != nullptr ){
slow = slow -> next ;
fast = fast -> next -> next ;
}
return slow ;
}
ListNode* merge (ListNode* l1, ListNode* l2 ){
ListNode* dummy = new ListNode(0);
ListNode* cur = dummy ;
while (l1 != nullptr && l2 != nullptr){
if (l1 -> val <= l2 -> val ){
cur -> next = l1 ;
l1 = l1 -> next ;
}else {
cur -> next = l2 ;
l2 = l2 -> next ;
}
cur = cur -> next ;
}
cur -> next = (l1 != nullptr )? l1 : l2 ;
ListNode* res = dummy -> next ;
delete dummy ;
return res ;
}
public:
ListNode* sortList(ListNode* head) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* mid = findMid(head);
ListNode* rightHead = mid -> next ;
mid -> next = nullptr ;
ListNode* left = sortList(head);
ListNode* right = sortList(rightHead);
return merge(left ,right);
}
};js
javascript
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
var sortList = function(head) {
if (head === null || head.next === null) {
return head;
}
const midNode = findMiddle(head);
const rightHead = midNode.next;
midNode.next = null;
const leftSorted = sortList(head);
const rightSorted = sortList(rightHead);
return mergeTwoSortedLists(leftSorted, rightSorted);
};
/**
* @param {ListNode} head
* @return {ListNode}
*/
function findMiddle(head) {
if (head === null || head.next === null) {
return head;
}
let slow = head;
let fast = head.next;
while (fast !== null && fast.next !== null) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
/**
* @param {ListNode} l1
* @param {ListNode} l2
* @return {ListNode}
*/
function mergeTwoSortedLists(l1, l2) {
const dummy = new ListNode(-1);
let current = dummy;
while (l1 !== null && l2 !== null) {
if (l1.val <= l2.val) {
current.next = l1;
l1 = l1.next;
} else {
current.next = l2;
l2 = l2.next;
}
current = current.next;
}
current.next = l1 !== null ? l1 : l2;
return dummy.next;
}思考
如果是数组就很简单了,可是这是链表,各种指针要改,怎么办呢?
我说实话这个对我又太难了。
题解
分治的核心思路和数组的归并排序完全一致,只是链表的 "分割" 需要用快慢指针找中点,而不是直接索引:
- 分(Divide):用快慢指针找到链表中点,将链表拆分为左右两个子链表;
- 治(Conquer):递归排序左右两个子链表;
- 合(Merge):将两个排序好的子链表合并为一个有序链表。
完整 C++ 代码(分治版归并排序)
cpp
#include <iostream>
#include <vector>
using namespace std;
// 链表节点定义(LeetCode默认)
struct ListNode {
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution {
public:
ListNode* sortList(ListNode* head) {
// 递归终止条件:空链表 或 只有一个节点(天然有序)
if (head == nullptr || head->next == nullptr) {
return head;
}
// 1. 分:找中点,拆分链表为左、右两部分
ListNode* mid = findMid(head);
ListNode* rightHead = mid->next;
mid->next = nullptr; // 切断链表,分为 [head, mid] 和 [rightHead, ...]
// 2. 治:递归排序左、右子链表
ListNode* left = sortList(head);
ListNode* right = sortList(rightHead);
// 3. 合:合并两个有序子链表
return merge(left, right);
}
private:
// 快慢指针找链表中点(关键:慢指针最终停在中间偏左的节点)
ListNode* findMid(ListNode* head) {
if (head == nullptr || head->next == nullptr) {
return head;
}
ListNode* slow = head; // 慢指针:每次走1步
ListNode* fast = head->next; // 快指针:每次走2步(这样拆分后左右更均衡)
while (fast != nullptr && fast->next != nullptr) {
slow = slow->next;
fast = fast->next->next;
}
return slow; // 最终slow指向链表中点(偶数长度时指向中间偏左)
}
// 合并两个有序链表(和之前的merge函数完全一致,经典逻辑)
ListNode* merge(ListNode* l1, ListNode* l2) {
ListNode* dummy = new ListNode(0); // 虚拟头节点,简化合并逻辑
ListNode* cur = dummy;
// 逐个比较两个链表的节点,取较小值接入结果
while (l1 != nullptr && l2 != nullptr) {
if (l1->val <= l2->val) {
cur->next = l1;
l1 = l1->next;
} else {
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
// 拼接剩余未处理的节点(l1或l2可能还有剩余)
cur->next = (l1 != nullptr) ? l1 : l2;
ListNode* res = dummy->next;
delete dummy; // 释放虚拟节点,避免内存泄漏
return res;
}
};
// 测试代码(和之前一致,方便验证)
void printList(ListNode* head) {
while (head != nullptr) {
cout << head->val << " ";
head = head->next;
}
cout << endl;
}
ListNode* createList(vector<int>& nums) {
ListNode* dummy = new ListNode(0);
ListNode* cur = dummy;
for (int num : nums) {
cur->next = new ListNode(num);
cur = cur->next;
}
ListNode* res = dummy->next;
delete dummy;
return res;
}
int main() {
vector<int> nums1 = {4,2,1,3};
ListNode* head1 = createList(nums1);
Solution sol;
ListNode* sortedHead1 = sol.sortList(head1);
printList(sortedHead1); // 输出:1 2 3 4
vector<int> nums2 = {-1,5,3,4,0};
ListNode* head2 = createList(nums2);
ListNode* sortedHead2 = sol.sortList(head2);
printList(sortedHead2); // 输出:-1 0 3 4 5
return 0;
}关键部分拆解(新手友好版)
1. 找中点:快慢指针的核心逻辑
为什么用 fast = head->next 而不是 fast = head?
- 如果用
fast = head,偶数长度链表(如 4 个节点)的中点会偏右,拆分后左链表更长,可能导致递归深度增加; - 用
fast = head->next,偶数长度时中点偏左(比如 4 个节点时,slow 停在第 2 个节点),拆分后左右链表长度更均衡。
举个例子:链表 4→2→1→3
- slow 初始 = 4,fast 初始 = 2;
- 第一次循环:slow=2,fast=3;
- fast->next=null,循环结束,slow=2(中点),拆分后左链表
4→2,右链表1→3。
2. 递归的 "分 - 治 - 合" 过程(以 4,2,1,3 为例)
bash
初始:sortList(4→2→1→3)
分:找中点2,拆分为 4→2 和 1→3
治:
sortList(4→2):
分:找中点4,拆分为4 和 2
治:sortList(4)=4,sortList(2)=2
合:merge(4,2) → 2→4
sortList(1→3):
分:找中点1,拆分为1 和 3
治:sortList(1)=1,sortList(3)=3
合:merge(1,3) → 1→3
合:merge(2→4, 1→3) → 1→2→3→43. 合并两个有序链表(最核心的基础操作)
比如合并 2→4 和 1→3:
- dummy 初始 = 0,cur=0;
- 比较 2 和 1 → cur->next=1,cur=1,l2=3;
- 比较 2 和 3 → cur->next=2,cur=2,l1=4;
- 比较 4 和 3 → cur->next=3,cur=3,l2=null;
- 拼接剩余的 4 → cur->next=4;
- 最终返回 dummy->next → 1→2→3→4。
总结
- 分治核心:用快慢指针找中点拆分链表(分),递归排序子链表(治),合并有序子链表(合);
- 关键技巧:快慢指针找中点是链表分治的核心,虚拟头节点简化合并操作;
- 复杂度:时间 O (n log n)(和自底向上版一致),空间 O (log n)(递归栈深度,平衡拆分时栈深度为 log n)。
这个版本虽然空间复杂度略高,但逻辑更直观,先理解这个版本,再回头看自底向上版会容易很多。你可以先把 "找中点" 和 "合并有序链表" 这两个基础操作练熟,再结合递归,整个逻辑就通了。
嘶,好复杂,不想看😵。其实就是先分,拆两个链表,然后再转化成合并两个链表,内部排序呢怎么做,万一最小的在尾部呢?
你这个问题问到了核心!很多新手都会疑惑:拆分后的子链表本身是无序的,怎么保证合并后整体有序?最小的元素在尾部,排序能覆盖到吗?
答案很简单:递归的「治」阶段会把链表拆到「最小粒度」(单个节点),单个节点天然有序;再通过「合」阶段的合并操作,从最小的有序单元开始,层层合并成更大的有序链表。
1. "内部排序" 是怎么实现的?------ 拆到最小单元,再合并
你担心 "最小的元素在尾部",但递归会把链表拆到只剩一个节点,此时每个节点都是 "有序链表"(只有自己),合并时会从这些最小单元开始,把小的元素优先拼接,自然能覆盖到尾部的最小值。
举个极端例子:链表 [5,4,3,2,1](最小值 1 在尾部),我们一步步看递归怎么处理:
bash
初始:sortList(5→4→3→2→1)
分:找中点3 → 拆分为 5→4→3 和 2→1
治:
处理 5→4→3:
分:找中点4 → 拆分为 5→4 和 3
治:
处理 5→4:
分:找中点5 → 拆分为 5 和 4
治:5(有序)、4(有序)
合:merge(5,4) → 4→5
处理 3:3(有序)
合:merge(4→5, 3) → 3→4→5
处理 2→1:
分:找中点2 → 拆分为 2 和 1
治:2(有序)、1(有序)
合:merge(2,1) → 1→2
合:merge(3→4→5, 1→2) → 1→2→3→4→5你看:最小值 1 在最开始的链表尾部,但递归拆到单个节点后,合并时会先比较 1 和 2,把 1 放在前面;最终合并 3→4→5 和 1→2 时,又会把 1→2 放在最前面,完全覆盖到尾部的最小值。
2. 为什么拆分到单个节点就够了?
- 单个节点没有 "内部元素",本身就是有序的(这是递归的终止条件);
- 合并操作的核心是「把两个有序链表合并成一个有序链表」------ 只要输入的两个子链表是有序的,合并后的结果就一定有序;
- 递归的过程就是 "拆到最小有序单元 → 合并成更大的有序单元 → 最终合并成完整有序链表"。
用 "可视化流程" 帮你理解(以 5,4,3,2,1 为例)
我们用 "拆分→最小有序单元→合并" 的流程,看最小值 1 怎么被找出来:
| 拆分阶段(分) | 最小有序单元(治) | 合并阶段(合) |
|---|---|---|
| 5→4→3→2→1 → 5→4→3 + 2→1 | - | - |
| 5→4→3 → 5→4 + 32→1 → 2 + 1 | - | - |
| 5→4 → 5 + 4 | 5(有序)、4(有序)、3(有序)、2(有序)、1(有序) | - |
| - | - | 5+4 → 4→52+1 → 1→2 |
| - | - | 4→5 + 3 → 3→4→5 |
| - | - | 3→4→5 + 1→2 → 1→2→3→4→5 |
关键:合并函数的 "有序性保证"
合并两个有序链表的函数(mergeTwoSortedLists)是整个排序的 "核心发动机",它的逻辑决定了:只要输入的两个链表是有序的,输出一定是有序的。
再拆解合并函数的逻辑(以合并 3→4→5 和 1→2 为例):
dummy = -1,current = -1
l1 = 3→4→5,l2 = 1→2
第一步:比较 3 和 1 → current.next = 1,current=1,l2=2
第二步:比较 3 和 2 → current.next = 2,current=2,l2=null
第三步:l2 为空,拼接 l1 剩余节点 → current.next = 3→4→5
最终结果:1→2→3→4→5哪怕 l1 是 3→4→5(整体比 l2 大),合并函数也会先把 l2 的所有小元素拼在前面,完全覆盖 "最小值在另一个链表" 的情况。
总结(回答你的核心疑问)
- 内部排序的本质:不是 "直接给无序链表内部排序",而是通过递归把链表拆成单个节点(天然有序),再通过合并操作,从最小有序单元开始,层层拼接成有序链表;
- 最小值在尾部也能覆盖:拆分到单个节点后,最小值会变成一个独立的有序单元,合并时会被优先比较并放在前面;
- 核心保证:合并函数能保证 "两个有序输入 → 一个有序输出",递归的层层合并最终让整个链表有序。
简单记:拆到不能再拆(单个节点),合到不能再合(完整链表) ------ 这就是归并排序的核心,不管是数组还是链表,逻辑完全一致,只是链表拆分需要用快慢指针而已。
5 小结
对我来说有点难了,明天清醒的时候再回头看看。。。分,治。