
在人形机器人系统中,感知能力和任务规划能力的协同是实现智能行为的核心。仅靠视觉、点云或语言理解并不能完成复杂任务,机器人必须将感知结果与任务规划紧密结合,实现"感知---语义---决策"闭环。这种联动不仅包括识别和定位目标,还涉及理解任务意图、分解子任务以及实时调整策略。通过将大模型的多模态理解能力与规划模块对接,机器人能够在复杂、动态环境中完成高层次操作和交互任务。
10.4.1 从语言指令到视觉目标的Grounding
在人形机器人系统中,语言指令通常是抽象的、高层次的表达,例如"把桌子上的红色杯子放到左边的架子上"。机器人需要将这些语言符号映射到实际环境中的视觉目标、空间位置和物理对象,这一过程被称为Grounding(落地绑定)。Grounding 是实现语言驱动操作的关键环节,它直接影响机器人能否准确识别目标、执行任务并处理环境变化。
Grounding 面临的挑战包括:
- 语言抽象性:指令中包含高层语义或模糊描述,如"左边"、"附近"等方位概念。
- 多模态对齐:语言与视觉信息属于不同模态,需要在统一语义空间中实现匹配。
- 动态环境:目标可能移动或被遮挡,机器人必须实时调整Grounding结果。
因此,从语言到视觉目标的 Grounding 不仅需要多模态对齐,还需要空间推理和上下文理解。
- 语言特征编码
机器人首先需要将自然语言指令转换为可计算的向量表示。利用语言编码器(如BERT、GPT 或大模型嵌入层),将指令映射为高维特征向量:
e L = f L ( Instruction*)∈* Rd 
其中,e L 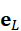 包含了语言指令的语义信息,包括目标属性(如"红色杯子")、动作意图(如"抓取")和空间关系(如"左边")。
包含了语言指令的语义信息,包括目标属性(如"红色杯子")、动作意图(如"抓取")和空间关系(如"左边")。
- 视觉特征编码
与此同时,机器人对场景进行视觉感知,提取图像或点云的高层语义特征。视觉特征通常通过卷积网络、视觉Transformer或多模态编码器获得:
Z I = f I ( Image*)∈* RN I ×d , Z P = f P ( PointCloud*)∈* RN P×d 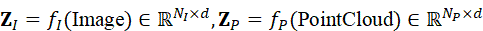
这里,Z I 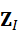 和Z P
和Z P 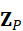 分别表示图像和点云的 token 化序列,每个 token 对应局部区域或关键点的特征。
分别表示图像和点云的 token 化序列,每个 token 对应局部区域或关键点的特征。
- 多模态语义对齐
Grounding的核心是将语言特征与视觉特征在统一语义空间中对齐。通过计算语言特征与每个视觉 token 的相似度,可以找到最可能对应的视觉目标:
Similarity*(* e L , z i )= e L ⋅ z i ∥e L ∥∥z i ∥,i=1,2,..., NI 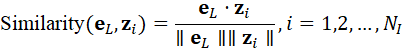
视觉token相似度最高的元素z target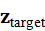 即为语言指令对应的视觉目标。对点云token同理:
即为语言指令对应的视觉目标。对点云token同理:
p target*=* arg max j Similarity*(* e L , p j ),j=1,2,..., NP 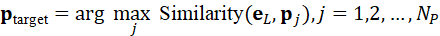
这种跨模态对齐使机器人能够将抽象的语言指令落到具体物体和三维位置上。
- 空间关系约束
Grounding不仅要求识别目标,还需要考虑语言中包含的空间关系。例如,"左边"、"上方"等相对位置,需要在三维空间中进行推理:
p grounded*=* p target*+* Δrelation*(* 指令中的空间约束*)* 
其中,Δrelation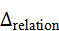 可以通过几何计算或神经网络预测,将目标位置调整到符合指令约束的实际位置。
可以通过几何计算或神经网络预测,将目标位置调整到符合指令约束的实际位置。
- 动态更新与多步Grounding
在实际场景中,目标可能移动或被遮挡,因此 Grounding 需要动态更新。机器人通过持续感知生成序列表示:
p grounded*,t+1* = Update*(* p grounded*,t* , Z I,t+1 , Z P,t+1) 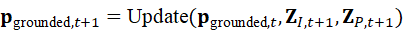
这一机制保证了Grounding结果随环境变化实时调整,使机器人在抓取、导航或交互任务中保持精确目标定位。
-
机器人应用场景
-
抓取任务:根据语言指令定位桌面目标物体,实现精确抓取;
-
导航任务:通过语言描述确定目的地或避障目标;
-
交互任务:识别语言指令对应的环境元素,实现智能交互,如"请将书放到书架上右侧"。
-
Grounding是机器人从语言理解到动作执行的桥梁,是闭环任务执行的起点。
总之,从语言指令到视觉目标的 Grounding 是多模态机器人系统的核心能力。通过语言特征编码、视觉特征提取、多模态对齐、空间约束推理和动态更新,机器人能够将抽象语言指令映射到具体物体和空间位置,实现精确目标定位。Grounding 为任务分解、操作规划和闭环决策提供基础支撑,是实现语言驱动操作的关键环节。
10.4.2 基于大模型的任务分解与意图理解
在人形机器人执行复杂任务时,单条指令往往包含多个子任务或隐含目标。例如,"清理桌面上的物品并放回原位"包含"识别物品"、"抓取物品"、"移动物品"、"放置物品"等子步骤。机器人若仅靠单步 Grounding 或固定规则规划,很难理解任务意图并生成可执行操作序列。
因此,引入大模型(Large Language Model, LLM)或多模态大模型,可以基于自然语言和感知结果进行任务分解与意图理解。大模型不仅能解析复杂语义,还能将语言与视觉、空间和动作信息融合,为每个子任务生成明确目标和动作策略。这一能力使机器人能够在开放环境下完成多步骤、跨模态的操作任务,并处理指令中的模糊性或不完整信息。
- 任务意图提取
机器人首先需要理解指令的高层意图,即区分动作类型、目标对象和约束条件。通过语言编码器将指令转换为高维语义向量:
e L = f L ( Instruction*)∈* Rd 
然后输入大模型生成任务意图表示:
h intent*=* LLM*(* e L) 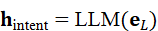
其中,h intent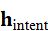 包含了指令的动作类别、目标优先级、空间约束和时间顺序等信息,为后续子任务分解提供基础。
包含了指令的动作类别、目标优先级、空间约束和时间顺序等信息,为后续子任务分解提供基础。
- 任务分解与子任务生成
基于意图向量 h intent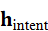 ,大模型将高层指令拆解为可执行的子任务序列:
,大模型将高层指令拆解为可执行的子任务序列:
T={ T 1 , T 2 ,..., T n }, T i = g i ( h intent*,* Z multi*)* 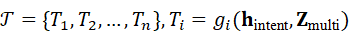
这里,Z multi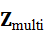 为机器人多模态感知结果,包括视觉、点云和触觉联合表示。每个子任务Ti
为机器人多模态感知结果,包括视觉、点云和触觉联合表示。每个子任务Ti 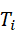 包含:
包含:
- 目标对象或区域p i
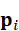 ;
; - 期望动作类型(抓取、移动、旋转等);
- 时间或顺序约束。
例如指令"清理桌面",可能生成如下子任务序列:
- T1
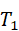 :抓取红色杯子;
:抓取红色杯子; - T2
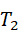 :移动杯子到水槽;
:移动杯子到水槽; - T3
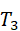 :抓取笔筒;
:抓取笔筒; - T4
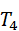 :放回抽屉。
:放回抽屉。
通过任务分解,机器人将抽象指令转化为具体可执行操作。
- 跨模态信息融合支持分解
任务分解不仅依赖语言,还需要结合视觉、点云和触觉信息,确保子任务可执行。联合多模态表示 Z multi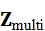 提供环境状态、物体属性和空间约束:
提供环境状态、物体属性和空间约束:
T i = g i ( h intent*,* Z multi*)=* Decoding*(* h intent*,* Z I , Z P , Z T) 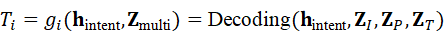
这种融合确保每个子任务既符合语言意图,又考虑环境几何与物理约束,实现任务与感知的无缝对接。
- 层次化任务表示与规划接口
为了便于动作规划,子任务通常以层次化表示形式输入规划模块:
T hier*={(* T i , p i , constraintsi ) } i=1n 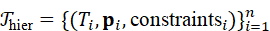
每个子任务包含目标位置、动作类型和执行约束。规划器可以在此基础上生成动作轨迹 a i =π( T i) 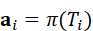 ,实现从意图到动作的完整映射。
,实现从意图到动作的完整映射。
- 动态调整与执行反馈
在实际操作中,任务执行可能受环境变化影响,如目标移动、障碍出现或操作失败。大模型结合实时感知可以动态调整子任务序列:
T i t 1 = Update*(* T i t , Z multi*,t+1)* 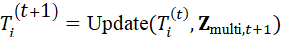
这种动态分解与调整机制,使机器人能够在复杂场景下持续理解意图并生成可执行计划。
-
机器人应用场景
-
家庭清理任务:理解"整理桌面"指令,将抽象任务分解为抓取、移动、放置子任务;
-
仓储搬运:基于指令"将货物从A区搬到B区"自动分解路径规划、抓取和运输步骤;
-
协作交互:在协作任务中理解人类语言意图,分解为可共享的动作序列,实现协同操作。
总之,基于大模型的任务分解与意图理解,使机器人能够将抽象语言指令转化为具体、可执行的子任务序列。通过语言特征编码、意图向量生成、多模态感知融合和层次化任务表示,机器人实现从语义理解到动作规划的桥梁,并在动态环境中实时调整任务执行策略。这一能力是复杂操作任务和语言驱动智能行为的核心支撑。
10.4.3 感知结果驱动的实时决策(闭环VLM)
在实际应用中,人形机器人面对的环境是动态的、复杂的且充满不确定性。即便 Grounding 精确、任务分解合理,如果机器人不能根据实时感知结果调整动作策略,也无法保证任务成功。闭环 VLM(Vision-Language Model)决策机制应运而生,它将语言、视觉、点云和触觉等多模态信息整合,形成感知---计划---执行的闭环,使机器人能够在动态环境中实时优化决策,提升操作精度和鲁棒性。
闭环决策的核心理念是:机器人在执行任务过程中不断感知环境状态,根据最新信息动态调整动作策略,而动作执行又会影响环境状态,为下一步决策提供输入,形成持续反馈循环。
- 多模态联合表示的实时更新
机器人在执行任务的每一个时间步t 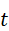 都会采集最新的多模态感知数据,包括:
都会采集最新的多模态感知数据,包括:
- 图像token Z I,t
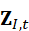
- 点云token Z P,t
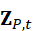
- 触觉token Z T,t
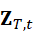
这些数据通过联合编码形成多模态表示:
Z multi*,t* =* **Z** *I,t* *;* **Z** *P,t* *;* **Z** *T,t* *∈ R*(* N I + N P + N T)×d 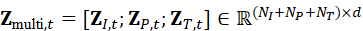
该表示不仅包含当前环境的视觉、几何和触觉信息,还可以与语言意图向量h intent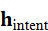 联合输入决策模块,实现语言驱动的实时决策。
联合输入决策模块,实现语言驱动的实时决策。
- 闭环决策机制
闭环决策依赖于一个策略函数 π 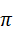 或深度强化学习网络,将多模态感知和历史状态映射到动作空间:
或深度强化学习网络,将多模态感知和历史状态映射到动作空间:
a t =π( Z multi*,t* , H t-1) 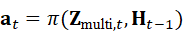
其中,H t-1 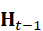 表示上一步的隐藏状态或任务上下文,可通过递归神经网络(RNN)、Transformer编码器或大模型实现。动作a t
表示上一步的隐藏状态或任务上下文,可通过递归神经网络(RNN)、Transformer编码器或大模型实现。动作a t 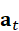 包括抓取、移动、旋转、导航或其他操作指令。
包括抓取、移动、旋转、导航或其他操作指令。
执行动作后,机器人感知环境变化,生成新的多模态表示Z multi*,t+1* 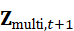 ,进入下一步决策循环:
,进入下一步决策循环:
H t+1 = f update*(* H t , Z multi*,t+1* , a t) 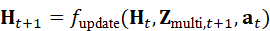
该循环保证了机器人能够在环境变化或任务干扰下保持连续、高效的操作能力。
- 环境约束与安全性集成
闭环VLM决策还需要结合环境约束与安全性判断,例如避免碰撞、限制力矩或保持物体稳定。策略函数可集成约束函数C( a t , Environment*)* 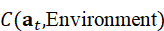 :
:
a t * = arg max a t R(* **Z** multi*,t* *,* **a** *t* *)-λC(* **a** *t* *,* Environment*) 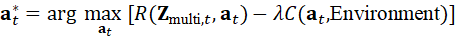
其中,R(⋅) 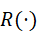 为奖励函数或任务目标评价,λ
为奖励函数或任务目标评价,λ 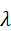 为约束权重。这种方式保证闭环决策既追求任务完成,又遵循安全和物理约束。
为约束权重。这种方式保证闭环决策既追求任务完成,又遵循安全和物理约束。
- 多步规划与前瞻性决策
闭环 VLM 不仅是单步决策,还可以实现多步预测和前瞻性规划。通过对未来多模态状态序列Z multi*,t:t+K* 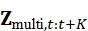 进行建模,机器人可以预测潜在障碍、目标移动或任务冲突,并提前调整动作策略:
进行建模,机器人可以预测潜在障碍、目标移动或任务冲突,并提前调整动作策略:
a t =π( Z multi*,t:t+K* , H t-1) 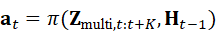
这种前瞻性机制提高了机器人在动态场景中的适应能力和任务成功率。
-
机器人应用场景
-
抓取与操作闭环:在抓取易滑物体时,触觉和视觉反馈驱动实时调整抓取力度与手臂轨迹。
-
动态导航:机器人在移动过程中实时感知障碍物变化,通过闭环策略调整路径和速度。
-
人机协作:机器人根据人类动作和语言指令变化实时调整操作顺序,确保安全和效率。
通过使用闭环VLM,使机器人能够在真实环境中持续感知、预测和调整行为,显著提升操作鲁棒性和智能水平。
总之,感知结果驱动的实时决策(闭环VLM)是人形机器人实现智能行为的核心机制。通过多模态联合表示、语言意图引导、动作策略生成和实时反馈循环,机器人可以在动态、复杂环境中持续优化操作,实现感知---计划---执行闭环。闭环VLM不仅保证任务完成,还整合安全性、前瞻性规划和环境适应能力,是多模态感知与大模型驱动任务执行的关键支撑。