目录
-
节点:数据域 + 指针域(指向下一个节点)
-
头指针:指向第一个节点的指针(链表的入口)
-
空指针:最后一个节点的next指向NULL
二:两种实现方式
1. 不带头节点的单链表
-
head直接指向第一个数据节点
-
空链表时 head = NULL
-
插入/删除第一个节点时需要修改head
2. 带头节点的单链表
-
头节点:数据域不存有效数据,next指向第一个数据节点
-
空链表时 head->next = NULL
-
统一了插入/删除的代码逻辑(不用单独处理第一个节点)
三:核心操作及代码要点
接下来我会从节点的结构、链表的头插、尾插、尾删、头删、查找、销毁等各方面给大家详细介绍所有的知识点
这里的代码和我们之前介绍的顺序表的文件结构差不多,要是创建三个文件,一个头文件,一个测试文件,一个主体文件,下面的话大家自己应该可以分辨出具体是哪一个文件,所以我就不写文件具体是哪一个了
1.定义节点的结构
代码如下:
cpp
typedef int SLDataType; //由于数据类不止一种,所以这里重新定义一个数据类型
typedef struct SListNode
{
SLDataType data; //由于数据类不止一种,所以这里重新定义一个数据类型
struct SListNode* next; //结构体指针
}SLTNode; //为了SListNode 后续的书写,这里改一个简单的名字 SLTNode
void SLTPrint(SLTNode* phead);// 打印节点数据 phead是头节点参数代码解析:
cpp
typedef int SLDataType; //由于数据类不止一种,所以这里重新定义一个数据类型-
作用 :给
int起了一个别名SLDataType -
意图 :以后如果要修改链表存储的数据类型(比如改成
char或double),只需要改这一行,不用在代码里到处找int去替换 -
好处:提高了代码的可维护性
cpp
typedef struct SListNode
{
SLDataType data; //由于数据类不止一种,所以这里重新定义一个数据类型
struct SListNode* next; //结构体指针
}SLTNode; //为了SListNode后续的书写,这里改一个简单的名字 SLTNode-
:
typedef struct SListNode告诉编译器要定义一个结构体类型,名字叫struct SListNode -
:
SLDataType data;数据域,存储实际数据,类型是上面定义的SLDataType(也就是int) -
:
struct SListNode* next;指针域,存放下一个节点的地址
结构示意图:
┌─────────────────┐
│ SLTNode │
├────────┬────────┤
│ data │ next │───→ 下一个节点
└────────┴────────┘
cpp
void SLTPrint(SLTNode* phead); // 打印节点数据 phead是头节点参数-
函数名 :
SLTPrint(Singly Linked List Print) -
返回值 :
void不返回任何值 -
参数 :
SLTNode* phead接收链表的头指针-
如果传进来的
phead == NULL,说明是空链表 -
如果不为空,则通过遍历打印所有节点的数据
-
-
作用 :遍历链表并打印每个节点的
data值(用于调试和观察链表状态)
打印链表内容的主体代码如下:
cpp
//链表的主体
void SLTPrint(SLTNode* phead)
{
SLTNode* pcur = phead;
while (pcur)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}解析:
cpp
void SLTPrint(SLTNode* phead)第1行:函数头
-
参数 :
SLTNode* phead- 接收链表的头指针 -
返回值 :
void- 只打印,不返回数据 -
作用:遍历整个链表并打印每个节点的数据
cpp
SLTNode* pcur = phead;第2行:创建遍历指针
- 定义一个
pcur指针,初始指向头节点
cpp
while (pcur)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}第3-7行:遍历循环
循环条件 :while (pcur)
-
等价于
while (pcur != NULL) -
当
pcur为 NULL 时,说明已经遍历到链表末尾,循环结束
循环体:
-
printf("%d->", pcur->data);-
打印当前节点的数据
-
%d对应SLDataType是int类型 -
->是链表打印的常见格式,表示指向下一个
-
-
pcur = pcur->next;-
核心操作:将指针移动到下一个节点
-
这是链表遍历的关键一步
-
执行过程示例
假设链表为:5 -> 12 -> 8 -> NULL
| 循环次数 | pcur指向 | 打印 | 执行后pcur指向 |
|---|---|---|---|
| 初始 | 节点5 | - | 节点5 |
| 第1次 | 节点5 | 5-> |
节点12 |
| 第2次 | 节点12 | 12-> |
节点8 |
| 第3次 | 节点8 | 8-> |
NULL |
| 第4次 | NULL | 循环结束 | - |
最终输出:5->12->8->NULL
节点的手动创建
代码如下:
cpp
void SListTest01()
{
//由于链表是由一个一个的节点组成,所以这里我们先创建几个节点
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode)); //申请空间,强制转换类型
node1->data = 1;
SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));
node2->data = 2;
SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));
node3->data = 3;
SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));
node4->data = 4;
//此时我们需要将四个节点链接起来
node1->next = node2; //结构体的解引用,相当于 int a =b b=c c=d d=NULL
node2->next = node3;
node3->next = node4;
node4->next = NULL;//这里我们只创建了四个节点,所以最后面是NULL指针
//调用链表的打印
SLTNode* plist = node1; //相当于 node1 = plist 这里我们用新的变量去打印方便后面的修改
SLTPrint(plist); //将node1参数传过去,即plist参数传过去
}解析:
这个函数演示了最原始、最直观的链表创建方式:
-
手动创建4个节点
-
给每个节点的data赋值
-
手动链接节点(指定next指针)
-
调用打印函数验证结果
第4-5行:创建节点1
cpp
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode)); //申请空间,强制转换类型
node1->data = 1;-
malloc(sizeof(SLTNode)):在堆上申请一块足够存放一个节点大小的内存 -
(SLTNode*):将malloc返回的void*强制转换为SLTNode*类型 -
node1->data = 1;:给数据域赋值为1 -
此时node1的next是随机值(未初始化),不能直接使用
第7-15行:重复上述过程创建node2、node3、node4
-
分别赋值2、3、4
-
每个节点的next都还是随机值
第18-21行:链接节点
cpp
node1->next = node2; //结构体的解引用,相当于 int a =b b=c c=d d=NULL
node2->next = node3;
node3->next = node4;
node4->next = NULL; //这里我们只创建了四个节点,所以最后面是NULL指针-
核心操作:将每个节点的next指针指向下一个节点
-
node1->next = node2:节点1指向节点2 -
node4->next = NULL:最后一个节点的next必须置NULL,否则遍历时会越界 -
注释中的比喻:
int a = b; b = c; c = d; d = NULL其实不太准确,指针是"指向"关系,不是赋值
链接后的内存结构
node1 node2 node3 node4
┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐
│ 1 │ ──→ │ 2 │ ──→ │ 3 │ ──→ │ 4 │NULL│
└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
第24-25行:调用打印函数
cpp
//调用链表的打印
SLTNode* plist = node1; //相当于 node1 = plist 这里我们用新的变量去打印方便后面的修改
SLTPrint(plist); //将node1参数传过去,即plist参数传过去-
SLTNode* plist = node1;:定义plist指向链表的第一个节点node1 -
注释说"用新的变量去打印方便后面的修改":这是一种好习惯------保留原始的node1指针,用plist去操作
-
SLTPrint(plist);:调用打印函数,预期输出1->2->3->4->
综上所有的代码,可以得出一下输出结果:
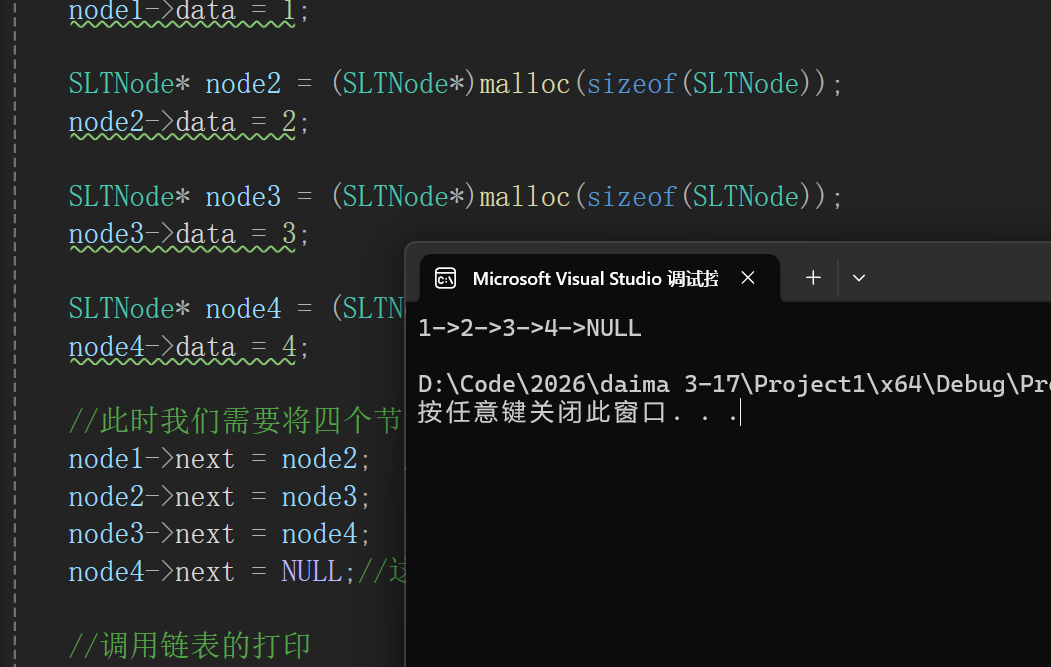
以上的代码都是最原始的节点创建,是非常简单的,我会在后面一节里面会讲解一个更加方便的灵活的节点创建的代码!!!