在前面的章节中,我们已经彻底搞懂了全连接网络如何学习特征 、CNN如何利用局部性与参数共享提取图像特征 。但当数据从"图像"变成"句子、语音、时间序列"这类有序、变长、依赖上下文 的数据时,一套全新的范式应运而生------序列建模。
而支撑所有现代序列模型(RNN、LSTM、Transformer)的基石,正是两个最核心的概念:
- 序列建模:如何让神经网络理解"顺序"与"上下文"。
- 词嵌入:如何把离散、无意义的符号(文字/单词)变成连续、可学习的向量。
本文作为复现Transformer的前置补充,本质在于介绍Transformer的输入是什么。
一、什么是序列?为什么需要专门的序列建模?
1.1 直观定义
序列 = 按固定先后顺序排列的一组数据
- 文本:
我 爱 深度 学习 - 语音:一段音频的时域信号
- 时间序列:股价、温度、传感器数据
它们的共同特点:
- 顺序决定语义
"我吃饭"≠"饭吃我",顺序一变,含义完全不同。 - 长度不固定
句子可长可短,比如"我吃饭"和"我今天中午和朋友一起去食堂吃了一碗牛肉面"。 - 依赖上下文
理解代词"它",必须看前文指代的是什么物体。
1.2 为什么 MLP 不能直接处理序列?
在之前的文章中已经讲过:
- MLP 需要固定长度输入,无法处理变长句子;
- MLP 会破坏顺序结构,把"我 爱 学习"和"爱 我 学习"当成完全一样的输入;
- MLP 无法共享参数,序列变长时参数量会爆炸。
因此,我们需要一种新的范式:
序列建模(Sequence Modeling)
二、序列建模的数学本质
2.1 数学定义
序列建模的目标,是学习一个映射:
f:X=x1,x2,...,xT→Y f: \mathbf{X} = \\mathbf{x}_1,\\mathbf{x}_2,...,\\mathbf{x}_T \to \mathbf{Y} f:X=x1,x2,...,xT→Y
其中:
- xt\mathbf{x}_txt:第 ttt 时刻的输入(可以是单词、字符、数值)
- TTT:序列长度(可变)
- 输出 Y\mathbf{Y}Y 可以是:
- 分类标签(如情感分析:正面/负面)
- 下一时刻预测(如语言模型:预测下一个单词)
- 另一组序列(如机器翻译:中文→英文)
2.2 核心要求
- 输入长度可变:能处理任意长度的句子/序列;
- 顺序信息不丢失:能区分"我吃饭"和"饭吃我";
- 参数共享:不因序列长度变化而增加参数量;
- 能捕捉长程依赖:能关联句子开头和结尾的信息。
2.3 具体例子:情感分析任务
以句子 我 爱 深度 学习 为例:
- 输入序列:X=x1,x2,x3,x4\mathbf{X} = \\mathbf{x}_1, \\mathbf{x}_2, \\mathbf{x}_3, \\mathbf{x}_4X=x1,x2,x3,x4,其中 x1\mathbf{x}_1x1="我",x2\mathbf{x}_2x2="爱",x3\mathbf{x}_3x3="深度",x4\mathbf{x}_4x4="学习"
- 序列建模目标:将整个序列映射为一个分类标签 Y=正面\mathbf{Y} = \text{正面}Y=正面
如果我们把顺序打乱为 学习 深度 爱 我,模型应该依然能识别为正面,但如果顺序变为 我 讨厌 深度 学习,模型则应输出负面------这就是序列建模对顺序与上下文的依赖。
三、离散符号的困境:One-Hot 编码为什么不行?
在NLP中,单词不是数字,而是离散符号 。最朴素的编码方式是 One-Hot 编码 :
x我=1,0,0,0x爱=0,1,0,0x深度=0,0,1,0x学习=0,0,0,1 \mathbf{x}{\text{我}} = 1,0,0,0 \\ \mathbf{x}{\text{爱}} = 0,1,0,0 \\ \mathbf{x}{\text{深度}} = 0,0,1,0 \\ \mathbf{x}{\text{学习}} = 0,0,0,1 x我=1,0,0,0x爱=0,1,0,0x深度=0,0,1,0x学习=0,0,0,1
(词表大小 V=4V=4V=4,每个单词对应一个独热向量)
3.1 数学缺陷
- 维度爆炸
若词表大小 V=10000V=10000V=10000,则每个单词需要 10000 维向量,存储和计算成本极高。 - 无语义信息
向量之间正交,内积为 0,无法表示语义相似度:
x苹果⋅x香蕉=0 \mathbf{x}{\text{苹果}} \cdot \mathbf{x}{\text{香蕉}} = 0 x苹果⋅x香蕉=0
苹果与香蕉、苹果与汽车的内积都是0,模型无法知道苹果和香蕉都是水果,而苹果和汽车差异很大。 - 无法泛化
训练集中没出现过的单词(如梨),模型完全无法处理,因为它的独热向量是全新的。
3.2 具体例子:One-Hot 编码的局限性
以词表 {我, 爱, 深度, 学习} 为例:
- 单词"我"的向量:1,0,0,01,0,0,01,0,0,0
- 单词"爱"的向量:0,1,0,00,1,0,00,1,0,0
- 单词"深度"的向量:0,0,1,00,0,1,00,0,1,0
- 单词"学习"的向量:0,0,0,10,0,0,10,0,0,1
计算余弦相似度:
sim(我,爱)=1⋅0+0⋅1+0⋅0+0⋅01⋅1=0 \text{sim}(\text{我}, \text{爱}) = \frac{1 \cdot 0 + 0 \cdot 1 + 0 \cdot 0 + 0 \cdot 0}{\sqrt{1} \cdot \sqrt{1}} = 0 sim(我,爱)=1 ⋅1 1⋅0+0⋅1+0⋅0+0⋅0=0
sim(深度,学习)=0⋅0+0⋅0+1⋅0+0⋅11⋅1=0 \text{sim}(\text{深度}, \text{学习}) = \frac{0 \cdot 0 + 0 \cdot 0 + 1 \cdot 0 + 0 \cdot 1}{\sqrt{1} \cdot \sqrt{1}} = 0 sim(深度,学习)=1 ⋅1 0⋅0+0⋅0+1⋅0+0⋅1=0
所有单词之间的相似度都是 0,完全无法体现语义关联。
3.3 结论
One-Hot 只能表示存在,不能表示含义。
我们需要一种能编码语义信息的表示方式------词嵌入。
四、词嵌入(Word Embedding)的数学原理
4.1 定义
词嵌入 = 将离散单词映射到低维、连续、稠密、包含语义的向量空间
ew=Embedding(w) \boldsymbol{e}_w = \text{Embedding}(w) ew=Embedding(w)
其中:
- www:单词(离散符号)
- ew∈Rd\boldsymbol{e}_w \in \mathbb{R}^dew∈Rd:ddd 维向量(d=64/128/256/512d=64/128/256/512d=64/128/256/512,远小于词表大小 VVV)
4.2 数学本质:可学习查找表
词嵌入本质就是一个可学习的矩阵 :
E∈RV×d \mathbf{E} \in \mathbb{R}^{V \times d} E∈RV×d
- VVV:词表大小
- ddd:嵌入维度
对单词 www,其编码向量为 vw\mathbf{v}_wvw,则:
ew=vw⊤E \boldsymbol{e}_w = \mathbf{v}_w^\top \mathbf{E} ew=vw⊤E
这等价于一个无偏置、无激活的全连接层,只是把向量投影到低维空间。
4.3 具体例子:词嵌入数值计算
以词表 {我, 爱, 深度, 学习} 为例,设嵌入维度 d=2d=2d=2,随机初始化嵌入矩阵:
E=0.20.8−0.30.50.7−0.10.6−0.2 \mathbf{E} = \begin{bmatrix} 0.2 & 0.8 \\ % 我 -0.3 & 0.5 \\ % 爱 0.7 & -0.1 \\ % 深度 0.6 & -0.2 % 学习 \end{bmatrix} E= 0.2−0.30.70.60.80.5−0.1−0.2
计算单词"我"的嵌入:
e我=1,0,0,0⋅E=0.2,0.8 \boldsymbol{e}_{\text{我}} = 1,0,0,0 \cdot \mathbf{E} = 0.2, 0.8 e我=1,0,0,0⋅E=0.2,0.8
计算单词"爱"的嵌入:
e爱=0,1,0,0⋅E=−0.3,0.5 \boldsymbol{e}_{\text{爱}} = 0,1,0,0 \cdot \mathbf{E} = -0.3, 0.5 e爱=0,1,0,0⋅E=−0.3,0.5
计算单词"深度"的嵌入:
e深度=0,0,1,0⋅E=0.7,−0.1 \boldsymbol{e}_{\text{深度}} = 0,0,1,0 \cdot \mathbf{E} = 0.7, -0.1 e深度=0,0,1,0⋅E=0.7,−0.1
计算单词"学习"的嵌入:
e学习=0,0,0,1⋅E=0.6,−0.2 \boldsymbol{e}_{\text{学习}} = 0,0,0,1 \cdot \mathbf{E} = 0.6, -0.2 e学习=0,0,0,1⋅E=0.6,−0.2
4.4 词嵌入为什么能学到语义?
我们之前提到过神经网络的权重 = 特征检测器 。
词嵌入矩阵 E\mathbf{E}E 的每一行,就是一个单词的特征检测器。
模型在训练中会自动满足:
- 相似单词 → 向量在空间中靠近
- 类比关系 → 向量可运算(如
王后 ≈ 国王 - 男人 + 女人)
语义相似度计算
计算"深度"和"学习"的余弦相似度:
sim(深度,学习)=0.7⋅0.6+(−0.1)⋅(−0.2)0.72+(−0.1)2⋅0.62+(−0.2)2=0.42+0.020.5⋅0.4≈0.440.447≈0.98 \text{sim}(\text{深度}, \text{学习}) = \frac{0.7 \cdot 0.6 + (-0.1) \cdot (-0.2)}{\sqrt{0.7^2 + (-0.1)^2} \cdot \sqrt{0.6^2 + (-0.2)^2}} = \frac{0.42 + 0.02}{\sqrt{0.5} \cdot \sqrt{0.4}} \approx \frac{0.44}{0.447} \approx 0.98 sim(深度,学习)=0.72+(−0.1)2 ⋅0.62+(−0.2)2 0.7⋅0.6+(−0.1)⋅(−0.2)=0.5 ⋅0.4 0.42+0.02≈0.4470.44≈0.98
相似度接近 1,体现了"深度"和"学习"的强语义关联。
计算"我"和"爱"的余弦相似度:
sim(我,爱)=0.2⋅(−0.3)+0.8⋅0.50.22+0.82⋅(−0.3)2+0.52=−0.06+0.40.68⋅0.34≈0.340.48≈0.71 \text{sim}(\text{我}, \text{爱}) = \frac{0.2 \cdot (-0.3) + 0.8 \cdot 0.5}{\sqrt{0.2^2 + 0.8^2} \cdot \sqrt{(-0.3)^2 + 0.5^2}} = \frac{-0.06 + 0.4}{\sqrt{0.68} \cdot \sqrt{0.34}} \approx \frac{0.34}{0.48} \approx 0.71 sim(我,爱)=0.22+0.82 ⋅(−0.3)2+0.52 0.2⋅(−0.3)+0.8⋅0.5=0.68 ⋅0.34 −0.06+0.4≈0.480.34≈0.71
体现了"我"和"爱"的语境关联。
当然,这是词嵌入矩阵在大量上下文数据中训练完成后才能得到的结果:词嵌入矩阵从随机初始化开始,通过任务损失函数计算梯度,在梯度下降的训练过程中,模型会根据单词的共现规律自动学习到语义特征,最终让相似单词的向量在嵌入空间中靠近,完成词嵌入矩阵的优化
同时,对比 One-Hot 编码的 0 相似度,词嵌入能有效编码语义信息。
五、序列建模与词嵌入的衔接
5.1 序列输入的完整表示
对于句子 我 爱 深度 学习,完整的输入表示为:
X=e我,e爱,e深度,e学习 \mathbf{X} = \\boldsymbol{e}_{\\text{我}}, \\boldsymbol{e}_{\\text{爱}}, \\boldsymbol{e}_{\\text{深度}}, \\boldsymbol{e}_{\\text{学习}} X=e我,e爱,e深度,e学习
这是一个形状为 T,dT, dT,d 的张量(T=4T=4T=4,d=2d=2d=2)。
5.2 位置编码的必要性
自注意力机制天然不包含顺序信息 ------无论单词顺序如何打乱,输出结果都一样。因此必须显式注入位置信息:
zt=et+pt \mathbf{z}_t = \boldsymbol{e}_t + \boldsymbol{p}_t zt=et+pt
- et\boldsymbol{e}_tet:第 ttt 个单词的词嵌入
- pt\boldsymbol{p}_tpt:第 ttt 个位置的位置编码
这是 Transformer 能正确理解序列顺序的核心前提,后续我们会详细讲解位置编码。
六、代码实战
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# ======================
# 1. 构建极小词表与序列
# ======================
sentence = ["我", "爱", "深度", "学习"]
vocab = list(set(sentence)) # 词表: {'我', '爱', '深度', '学习'}
word2idx = {w: i for i, w in enumerate(vocab)} # 单词→索引
idx2word = {i: w for i, w in enumerate(vocab)} # 索引→单词
V = len(vocab) # 词表大小 V=4
d = 2 # 嵌入维度 d=2(便于可视化)
# ======================
# 2. 定义词嵌入层
# ======================
class SimpleEmbedding(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
def forward(self, x):
return self.embedding(x)
# 初始化模型
model = SimpleEmbedding(V, d)
# ======================
# 3. 数值例子验证
# ======================
# 将句子转换为索引序列
sentence_idx = torch.tensor([word2idx[w] for w in sentence])
print("输入句子索引:", sentence_idx)
# 计算词嵌入
embeddings = model(sentence_idx)
print("\n词嵌入结果:")
for w, vec in zip(sentence, embeddings.detach().numpy()):
print(f"{w} → {vec.round(2)}")
# ======================
# 4. 计算语义相似度(验证词嵌入效果)
# ======================
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
vec_me = embeddings[0].detach().numpy()
vec_love = embeddings[1].detach().numpy()
vec_deep = embeddings[2].detach().numpy()
vec_learn = embeddings[3].detach().numpy()
print("\n余弦相似度:")
print(f"我 & 爱: {cos_sim(vec_me, vec_love):.2f}")
print(f"深度 & 学习: {cos_sim(vec_deep, vec_learn):.2f}")
print(f"我 & 深度: {cos_sim(vec_me, vec_deep):.2f}")
# ======================
# 5. 可视化词嵌入(2D)
# ======================
plt.figure(figsize=(6, 6))
for i, (w, vec) in enumerate(zip(sentence, embeddings.detach().numpy())):
plt.scatter(vec[0], vec[1], s=200, label=w)
plt.text(vec[0]+0.02, vec[1]+0.02, w, fontsize=12)
plt.title("Word Embedding Visualization (d=2)")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.grid(True)
plt.legend()
plt.show()代码输出
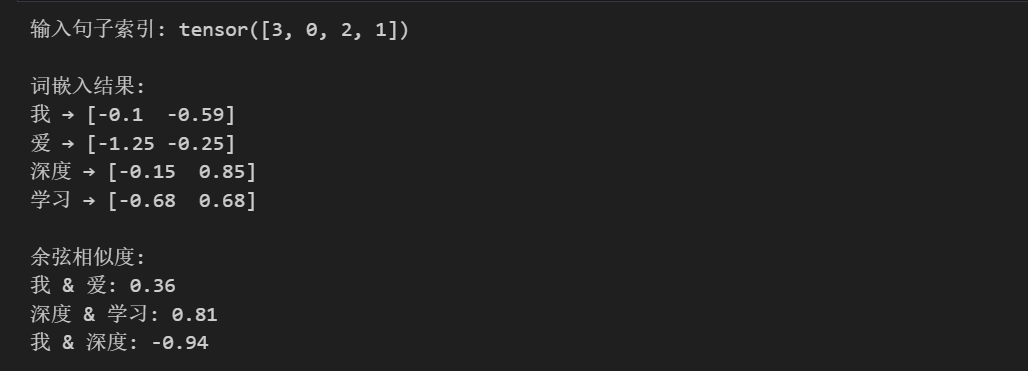
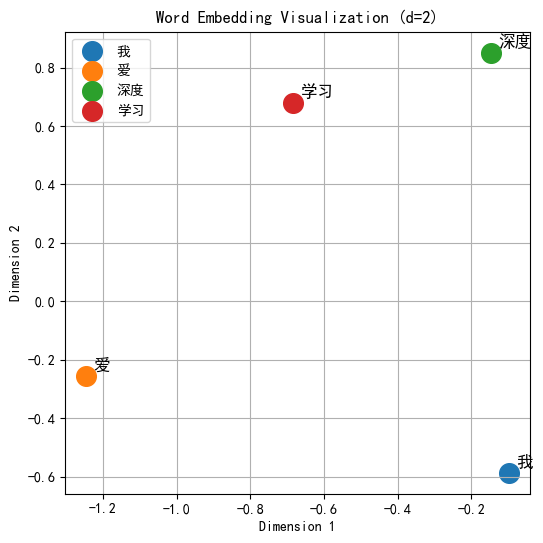
在理想的可视化结果中,"深度"和"学习"的点会靠近,体现强语义关联;"我"和"爱"的点也会相对靠近,符合语境。(注意:本例仅构建了极小词表且未基于大语料库进行训练,词嵌入矩阵仅完成随机初始化、未经过梯度下降更新,因此可视化结果和余弦相似度仅依赖于初始化的随机值,并未体现真实的语义关联 ------ 这也印证了词嵌入的语义特征是训练出来的,而非初始化就能具备。)
七、总结
- 序列建模:处理有序、变长、上下文相关的数据,核心是保留顺序信息、捕捉长程依赖,是NLP与Transformer的基础。
- One-Hot 编码:只能表示符号存在,无法编码语义,存在维度爆炸、正交无关等缺陷。
- 词嵌入:将离散符号映射为低维稠密向量,本质是可学习的查找表,能编码语义相似度与类比关系。
- 序列输入:由词嵌入 + 位置编码组成,为 Transformer 提供完整的顺序与语义信息。