1、租用云服务器
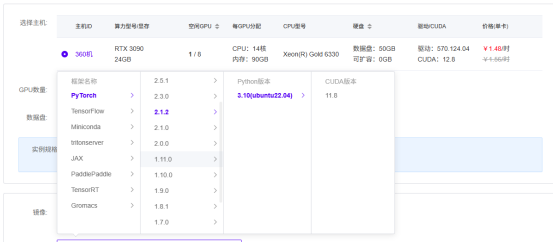
2、云端部署大模型
方案一:
可以直接尝试部署ollama这样的工具,他封住好了一系列加载、推理、下载大模型的代码,使用大模型非常方便。
方案二:
直接在云端下载大模型、然后自己写推理代码。
配置虚拟环境之类的就不说了。
(1)安装modelscope SDK
(这个相当于国内的hugging face,下载模型用)
pip install modelscope
(2)安装模型
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
这个可以根据的需要,在modelscope社区选择自己需要的模型。这里因为选择的显卡是24G的,所以没有选择非常大的模型。

我这里下载的模型名称是"DeepSeek-R1-Distill-Qwen-7B",这里的Deepseek-R1是教师模型,生成许多高质量的推理数据,Qwen是学生模型,学生模型基于Qwen-7B架构进行监督微调。
潜在问题:使用autodl平台,默认modelscope下载的模型在root/.cache/modelscope/hub路径下,如果模型太大,会导致系统盘空间不够,此时可以尝试在配置文件中重新指定modelscope下载的文件位置解决。
修改modelscope下载的模型位置
查询磁盘占用资源情况:
source ~/.bashrc
打开vim编辑器:
vim ~/.bashrc # 打开配置文件
在最后输入:
export MODELSCOPE_CACHE=/root/autodl-tmp/modelscope_cache
当然你也可以放到其他位置,autodl-tmp在autodl中属于数据盘,有较大空间。
退出vim编辑器:
按下"ESC",然后输入":wq"退出。
加载配置文件使其生效:
source ~/.bashrc
检查是否配置成功:
echo $MODELSCOPE_CACHE
记得重启一个终端,否则配置文件不生效。
(3)模型文件解释
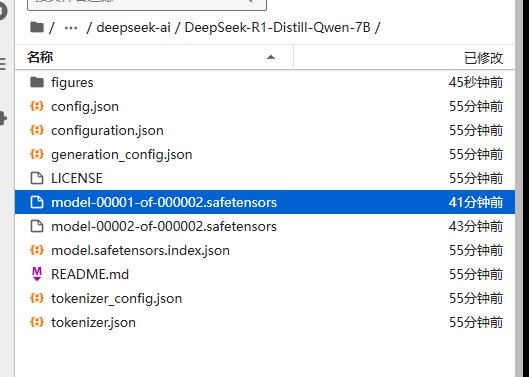
这一张图片就是下载好的模型文件,其中主要包含:
模型参数权重文件(分片文件,也就是图中的.safetensors后缀的文件,因为模型参数较大,所以可能会使用不止一个文件来存储。
model.safetensors.index.json,也就是存储前面分片信息的配置文件。
config.json,模型架构配置文件,定义模型的底层结构,隐藏层维度、注意力头数等信息。
configuration.json类似上面的配置文件。
generation_config.json推理配置文件,如定义了最大生成长度、temperature、top_p等信息。
tokenizer.json分词器核心字典,就是将token和ID对应起来的字典,里面存储了非常多切分好的token
tokenizer_config.json和上面那个文件配套的
(4)运行模型
这里需要先下载vLLM,这是一个高性能大模型推理工具,也可以用它实现部署大模型的API服务。
pip install vllm
下面的这个链接是vllm的操作手册,其中有最基本的如何使用本地下载的大模型进行推理的示例:
https://vllm.hyper.ai/docs/getting-started/quickstart/ # vllm中文手册
https://github.com/vllm-project/vllm/blob/main/examples/offline_inference/basic/basic.py # vllm推理示例
你可以按照vllm中给出的操作示例,然后在云服务平台中创建一个.py脚本,来执行这个推理过程。
潜在问题:显存不够
可以尝试在配置信息里修改max_model_len(模型最大处理的文本长度)、gpu_memory_utilization(显存利用率)之类的信息来完成推理。
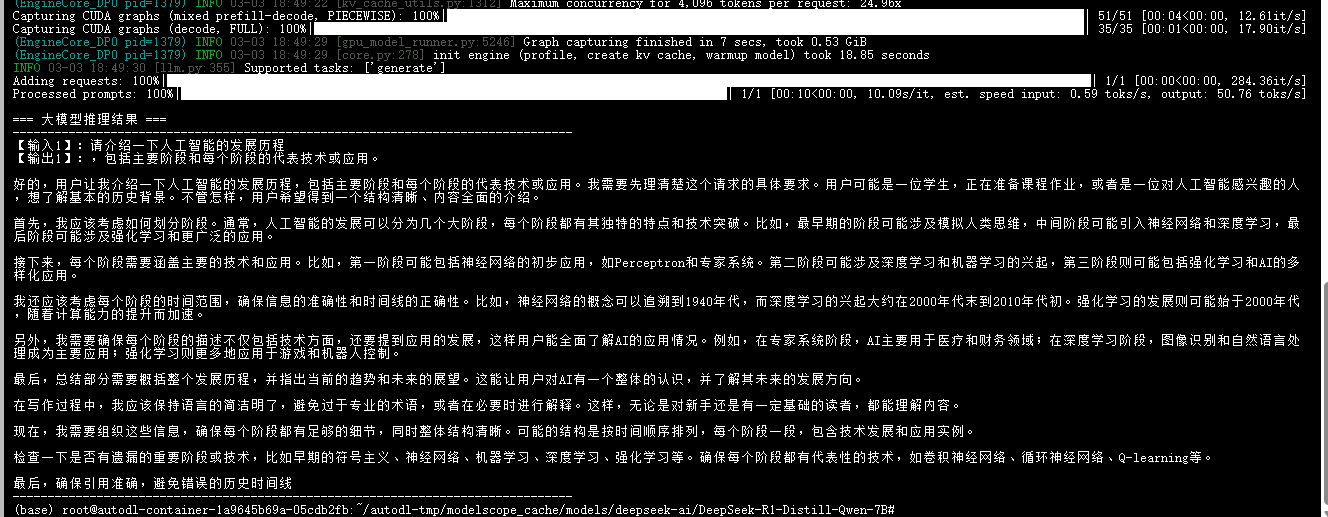
(5)显存不够的原因
由于这是一个7B的模型,显存占用大概就需要14GB(FP16,每个参数是两字节,7B×2字节 = 14GB),所以剩下的KV缓存空间不大。
这里的KV缓存就是注意力缓存,模型在生成文字的时候,每次都会看前面的内容来生成接下来的内容,所以vllm就会把"前面的内容"存储在缓存中,这样就能够推理的更快。当max_model_len设置的过大时,模型需要看较长的前文,就会导致KV缓存不够,所以通过降低max_model_len这个参数,能够有效的降低显存压力。
max_token这个参数是用来控制模型的最大输出长度的,对显存压力影响较小。
3、推理脚本
python
from vllm import LLM, SamplingParams
# ====================== 1. 自定义配置 ======================
# 替换成你在AutoDL上下载好的模型本地路径
MODEL_PATH = "/root/autodl-tmp/modelscope_cache/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
prompts = [
"请介绍一下人工智能的发展历程",
]
# 采样参数(控制生成效果,可根据需求调整)
# temperature:越大越随机(0=确定性输出,1=高随机性)
# top_p:核采样,0.95表示只选累计概率95%的token
# max_tokens:生成的最大token数,避免输出过长
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=256 # 限制生成长度,防止显存溢出
)
# ====================== 2. 核心推理函数 ======================
def main():
# 创建LLM实例(关键:指定本地模型路径,自动加载到GPU)
# tensor_parallel_size:指定使用的GPU数量(AutoDL一般是1卡,默认即可)
llm = LLM(
model=MODEL_PATH,
tensor_parallel_size=1, # AutoDL单卡环境设为1
gpu_memory_utilization=0.9, # 显存利用率,避免占满显存
max_model_len=4096
)
# 执行推理:传入提示词和采样参数
outputs = llm.generate(prompts, sampling_params)
# 打印推理结果
print("\n=== 大模型推理结果 ===\n" + "-" * 80)
for idx, output in enumerate(outputs):
prompt = output.prompt # 原始输入提示词
generated_text = output.outputs[0].text # 模型生成的文本
print(f"【输入{idx+1}】:{prompt}")
print(f"【输出{idx+1}】:{generated_text.strip()}")
print("-" * 80)
if __name__ == "__main__":
main()