第二章
2.1 CPU对内存的硬件支持
2.1.1 cpu的内存控制器
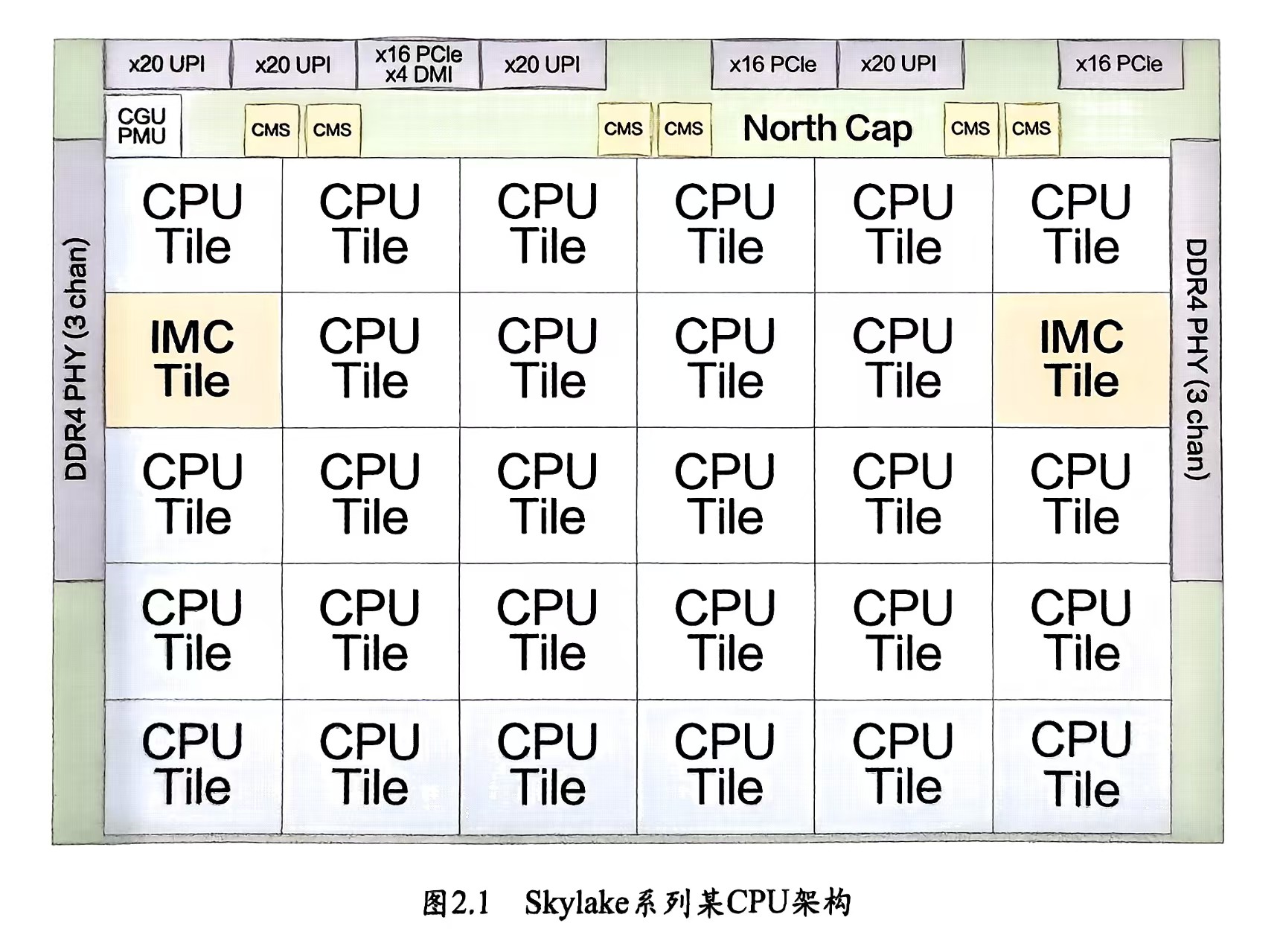
IMC 是现代 CPU 中的一个组件,负责管理 CPU 和系统内存(RAM)之间的通信。它取代了传统北桥芯片的内存控制功能,直接集成到处理器中。IMC 控制内存的读写操作、管理内存分配,并与操作系统内核(如 Linux 的 Buddy 分配器)协作。
DDR PHY 又是链接DDR内存条和内存控制器的桥梁。负责物理层通信,把 IMC 的指令转化为实际的电信号发送到内存模块。
2.1.2 CPU支持的内存代际
| 类型 | 基本频率范围 | 数据速率 | 主要特点 |
|---|---|---|---|
| SDR | 66--133 MHz | 66--133 MT/s | 单倍数据速率,每次时钟周期传输一次数据,电压 3.3V,早期 PC 内存标准。 |
| DDR | 100--200 MHz | 200--400 MT/s | 双倍数据速率(上升沿和下降沿传输),电压 2.5V,带宽翻倍,取代 SDR。 |
| DDR2 | 200--533 MHz | 400--1066 MT/s | 更高频率、更低功耗(1.8V),改进预取缓冲(4位),支持更高带宽。 |
| DDR3 | 400--1066 MHz | 800--2133 MT/s | 更低电压(1.5V),8位预取缓冲,性能提升,支持更高容量模块。 |
| DDR4 | 800--1600 MHz | 1600--3200 MT/s | 超低电压(1.2V),更高带宽和效率,支持更大容量(高达 128GB/条)。 |
| DDR5 | 1600--3200 MHz | 3200--6400+ MT/s | 电压降至 1.1V,双通道设计,效率更高,支持超高带宽和容量。 |
内存真正的工作频率是核心频率,时钟频率和数据频率都是在核心频率的基础上,通过技术手段放大出来的。内存越新,放大的倍数越多
2.2内存硬件内部结构
内存条上的标识:16G 2Rx8 PC4-3200AA-SE1-11
16G不过多的解释
2Rx8
- 2R 表示 2 Ranks
- x8 表示每个内存芯片的位宽为 8 bits(8位)也就是说每个内存芯片一次传输 8 位数据。x8 是常见的配置,相比 x4(4位)芯片,x8 芯片数量较少,通常成本更低。
PC4
- 表示这是 DDR4 内存
3200AA
- DDR4-3200 的基本频率是 1600 MHz(因为 DDR 是双倍数据速率,1600 MHz × 2 = 3200 MT/s)
SE1-11
- 产品系列或版本号 和 内存条的生产日期或修订版本
2.2.1 Rank
CPU能够对同一个Rank的所有Chip进行并行读写操作,需要Chip并行工作共同组成一个64比比特的数据给CPU。假如某笔记本内存条的这个参数是1Rx16,表示该内存条只有1个Rank。每个Chip内存颗粒的位宽是16比特。一个Rank需要提供64比特的数据,则需要64/16=4个Chp来组成一个Rank来同步工作。这个内存条只需4个黑色颗粒就够了。
2.2.2 Chip
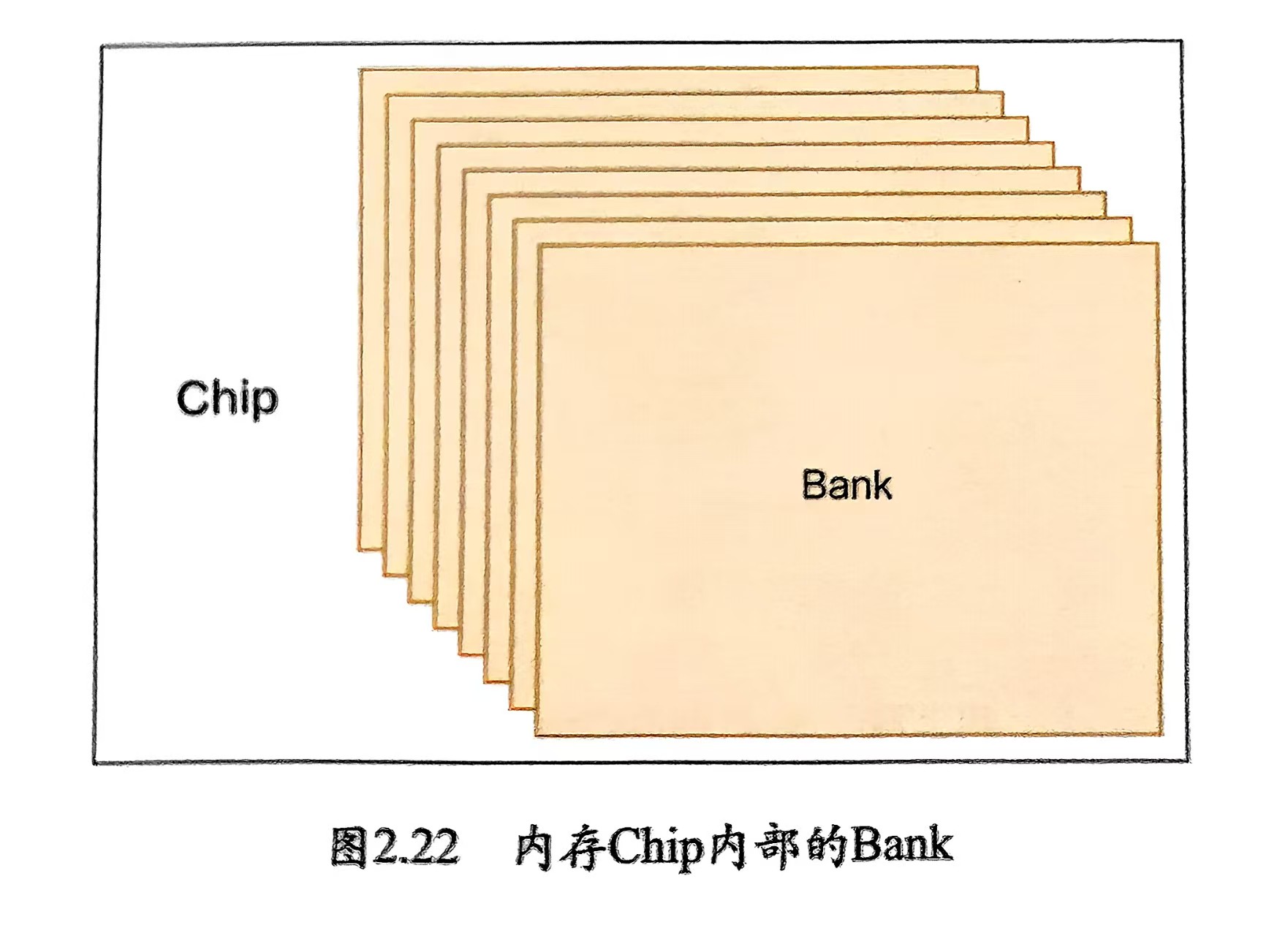
Chip内部又是一层层的Bank组成的,每个 Bank 内是一个二维数组,由行(Row)和列(Column)组成。
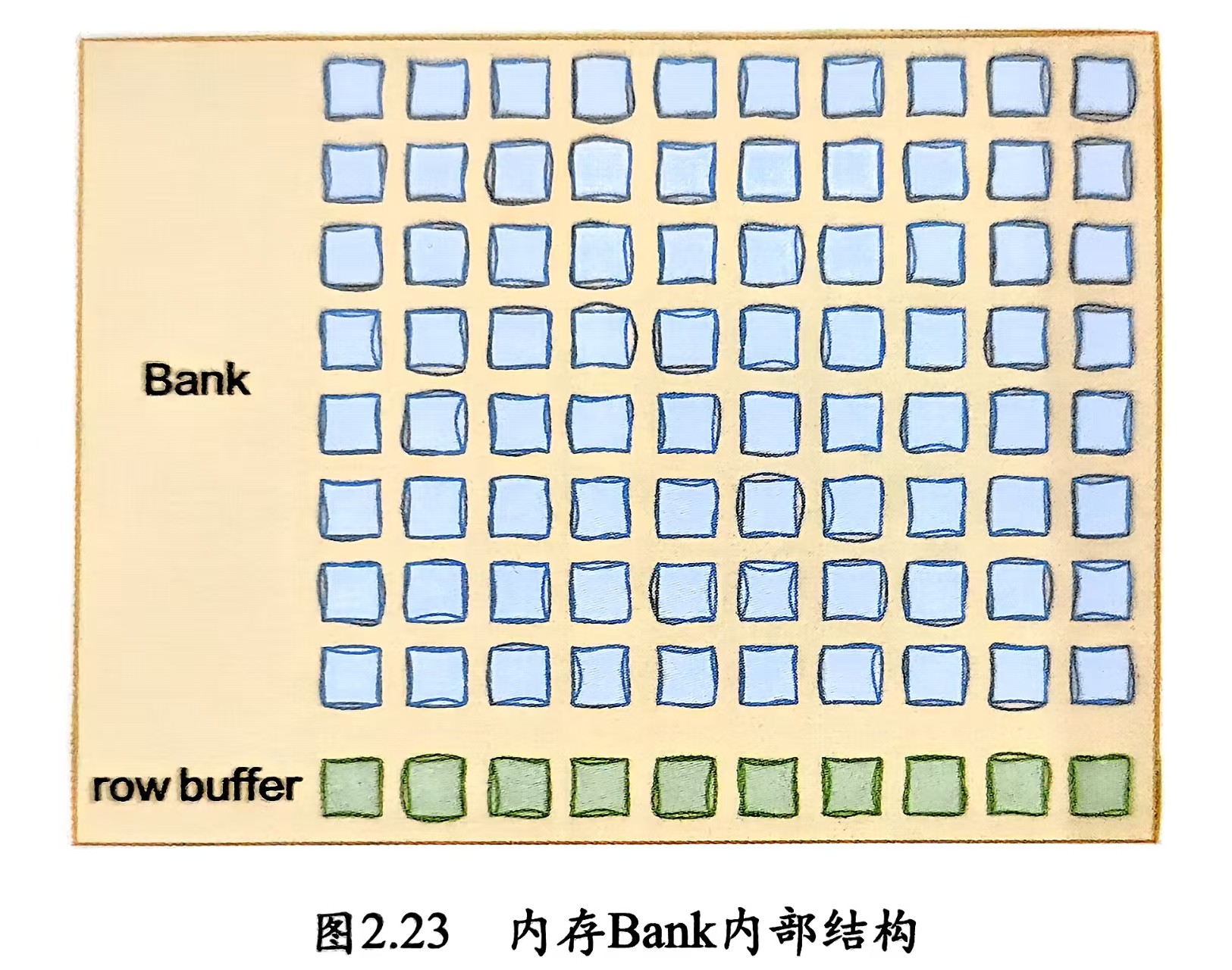
DRAM 芯片内部由 Rank → Bank → Row/Column → Cell 的层次组成。
2.3 内存IO原理
2.3.1 内存延迟
| 参数 | 定义 | 含义 |
|---|---|---|
| CL | 发送列地址到内存开始返回数据的时钟周期数 | 列地址选通延迟,表示从指定列地址到数据可用的时间。 |
| tRCD | 打开一行内存到访问列地址所需的最小时钟周期数 | 行地址到列地址延迟,衡量激活一行到定位列的准备时间。 |
| tRP | 发出预充电命令到打开下一行所需的最小时钟周期数 | 行预充电时间,表示关闭当前行到激活下一行之间的等待时间。 |
| tRAS | 行激活命令到发出预充电命令之间的最小时钟周期数 | 行活动时间,限制一行保持活动的最短时间,确保数据完整性。 |
2.3.2 内存IO过程
完整的读取内存地址0x0000的一个字节数据的过程
-
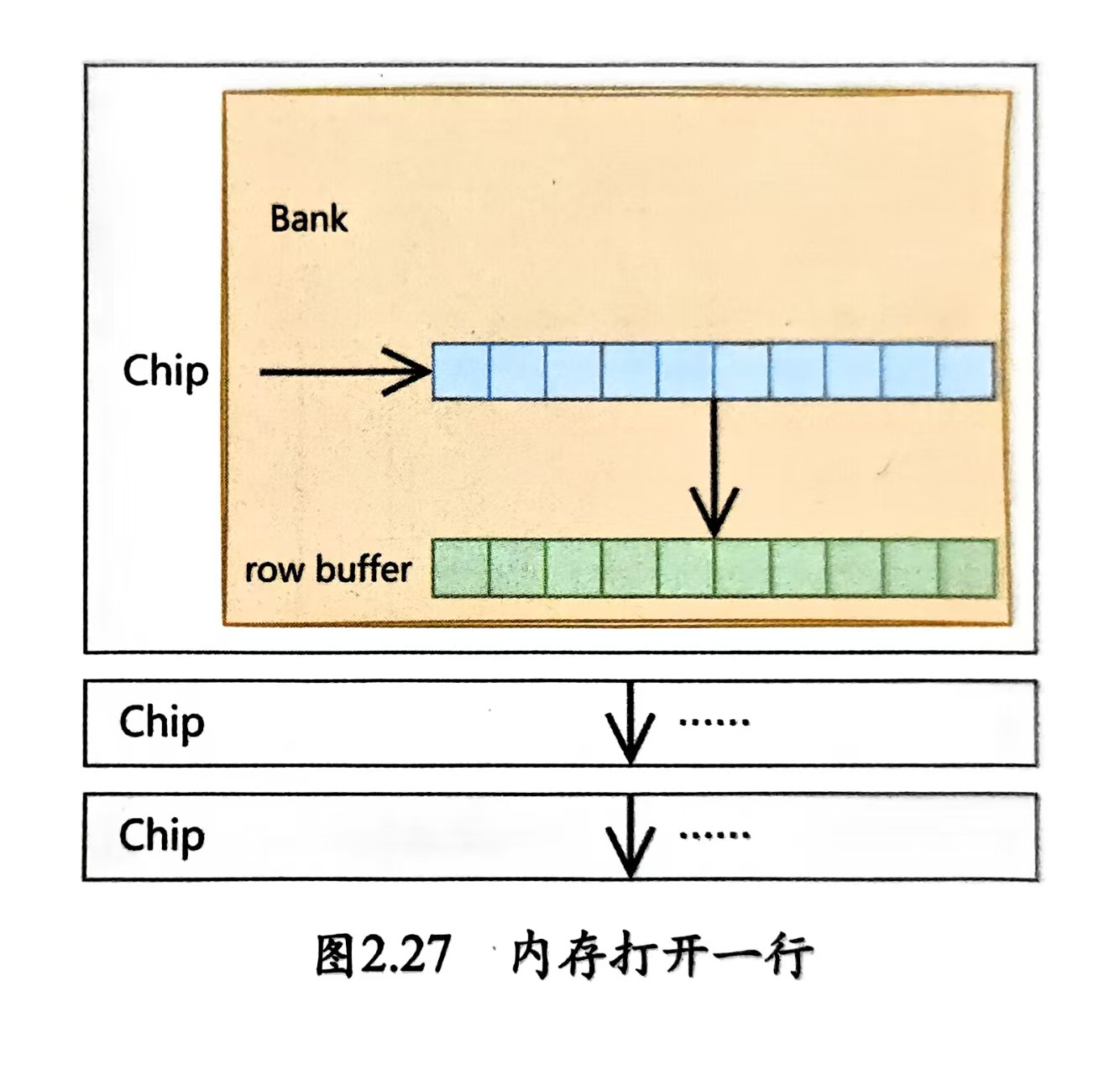
第一步、内存控制器对各个Chip中指定行地址的预充电,需要等待tRP个时钟周期
-
内存控制器再向各个Chip发出打开一行内存的命令,又需要等待tRCD个时钟周期
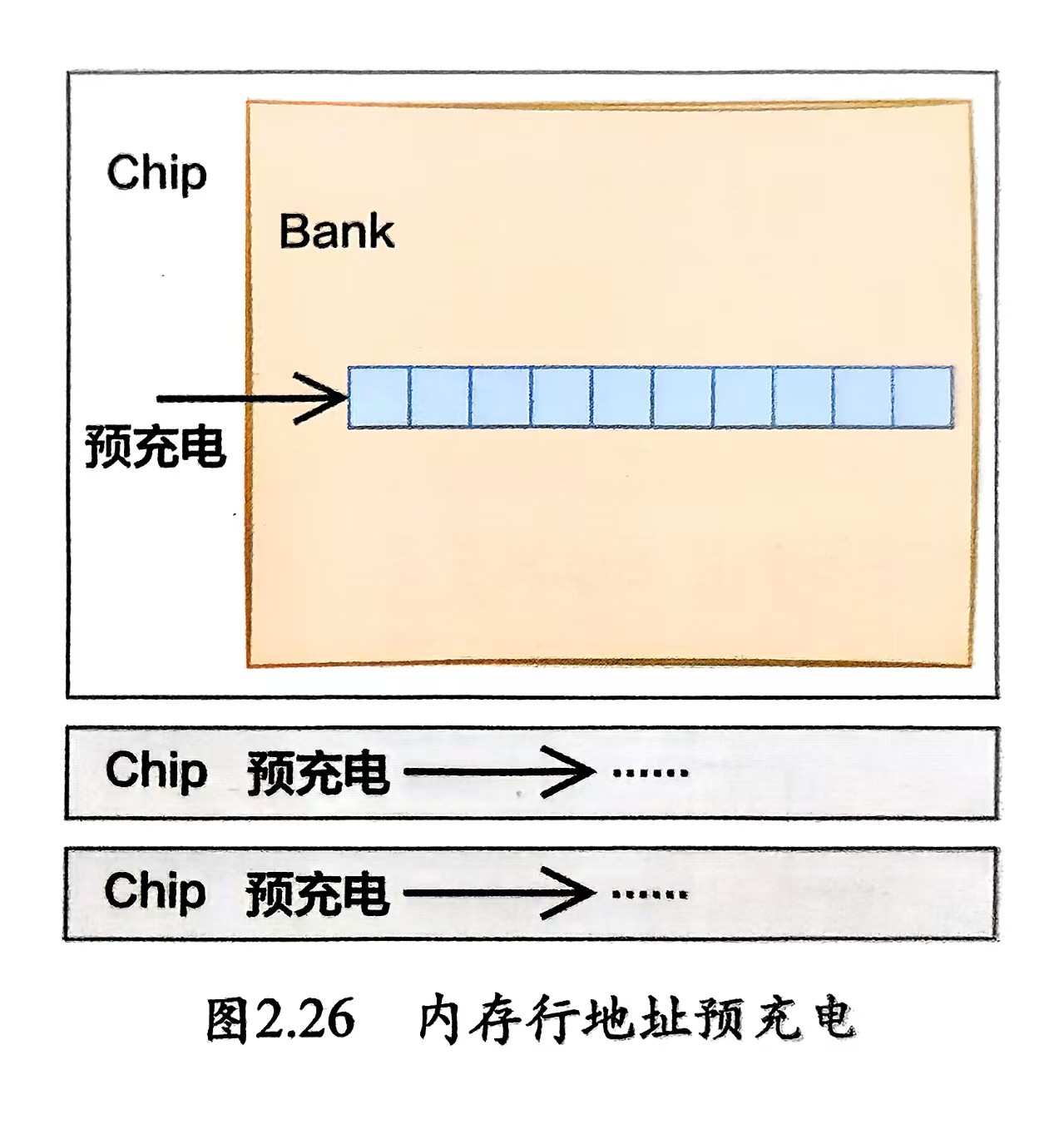
- 内存控制器接着发送列地址,再等待CL个周期后,各个Chip就把数据聚合好了
我们以一个 1Rx8 的内存为例来详细讲解内存的 IO 过程,这个内存的单个 Rank 中包含 8 个 DRAM Chip,每个内存颗粒的位宽为 8 比特,总共形成 64 位的总线宽度,正好匹配 DDR 内存的标准设计。假设 CPU 想要读取地址范围 0x0000 到 0x0007 这 8 个字节的数据,在理想情况下,这 8 个字节均匀分布在 8 个 Chip 上,内存控制器(IMC)会通过 DDR PHY 发送命令激活所有 Chip 中同一个 Bank 的某一行,然后一次性发出列地址读取请求,每个 Chip 同时工作,分别输出 8 bit 数据,比如 Chip 0 提供 0x0000 的 8 位,Chip 1 提供 0x0001 的 8 位,依此类推,直到 Chip 7 提供 0x0007 的 8 位,借助 DDR 的突发传输特性(通常是 BL8),这 64 位数据通过一次高效的操作并行传输到 CPU,完成读取,整个过程充分利用了 64 位总线宽度和 Chip 的并行性,IO 效率非常高,延迟可能仅为 tRCD 加 CL 的时间(例如 DDR4-3200 下约 20 纳秒)。
但是,如果这 8 个字节的数据恰好全部存储在同一个 Chip 中,情况就完全不同了,由于单个 Chip 的位宽只有 8 位,它只能每次读取 8 bit 数据,比如先读 0x0000 的 8 位,传输完成后再读 0x0001 的 8 位,如此重复 8 次才能凑齐完整的 64 位数据,这种串行读取的方式意味着其他 7 个 Chip 处于闲置状态,64 位总线的大部分带宽被浪费,每次读取还需经历完整的时序开销(如 tRCD 和 CL),总耗时可能高达 160 纳秒甚至更多,尤其当数据跨行或跨 Bank 时,还会额外受到 tRP 和 tRAS 的限制,速度相比并行读取慢得多,这种低效模式类似于内存中的"随机 IO",无法发挥 DDR 内存设计的高带宽优势。
2.3.3 随机IO和顺序IO
内存的随机 IO (Random IO)
-
定义 :
数据按非连续的内存地址读取或写入。例如,先访问 0x0000,再跳到 0x5000,再到 0x2000。 -
特点:
- 低效率: 每次访问可能需要激活不同的 Row 或 Bank,导致额外的寻址和切换开销。
- 高延迟: 随机访问会触发更多的行激活(Row Activation)和预充电(Precharge),受限于 tRCD、tRP 和 tRAS。
- 吞吐量下降: 无法充分利用突发传输,带宽利用率远低于理论值。
-
示例:
- 数据库索引的指针跳转。
- 多线程程序中分散的内存访问。
-
内存随机 IO (Random IO)
-
定义 :
数据按照非连续的地址进行读写。例如,先读第 10 块,再跳到第 500 块,再回到第 3 块。
-
特点
- 低吞吐量: 每次操作都需要重新寻址,增加了额外开销。
- 高延迟: 机械硬盘需要磁头频繁移动,SSD 虽无机械部件,但仍需处理分散的地址映射。
- 示例
- 数据库查询(如索引查找)。
- 操作系统启动时加载多个小文件。
-
2.3.4 内存 Burst IO
- 定义
- Burst IO(突发输入输出)是 DDR 内存的一项特性,指在一次读写操作中连续传输多个数据单元,而非单个数据。
- 工作原理
- 通过设定 突发长度(Burst Length,BL),通常为 8(BL8),每次操作传输多个周期的数据。
- 例如:DDR 内存总线宽 64 位,BL8 一次传输 64 字节(64 bit × 8)。
- 优点
- 高效率: 减少寻址开销,利用顺序访问填满总线带宽。
- 高吞吐量: 接近理论带宽,例如 DDR4-3200 可达 25.6 GB/s(3200 MT/s × 64 bit ÷ 8)。
- 缓存对齐: 与 CPU 缓存行(通常 64 字节)匹配,适合缓存填充。
- 应用场景
- 顺序 IO 任务,如大块数据传输、视频流处理或数组加载。
- 限制
- 在随机 IO 中效率降低,因地址不连续可能导致多次独立操作,受限于时序参数(如 CL、tRCD)。
- 实现
- 由内存控制器(IMC)和 DDR PHY 协调,从 DRAM 的 Bank 中按序输出数据。