过滤字句的需求
在数据分析与报表生成场景中,条件聚合是SQL开发者的日常需求。传统上,Oracle开发者依赖CASE表达式或DECODE函数实现条件统计,但这种方式语法冗长、可读性差。Oracle Database 26ai引入了SQL标准FILTER子句,为聚合函数和窗口函数提供了更优雅、更高效的解决方案。
本文将深入解析FILTER子句的技术原理,对比Oracle 19c等历史版本的处理方式,结合医疗和销售管理系统实战示例,展示如何在本地Database 26ai环境中应用这一新特性。
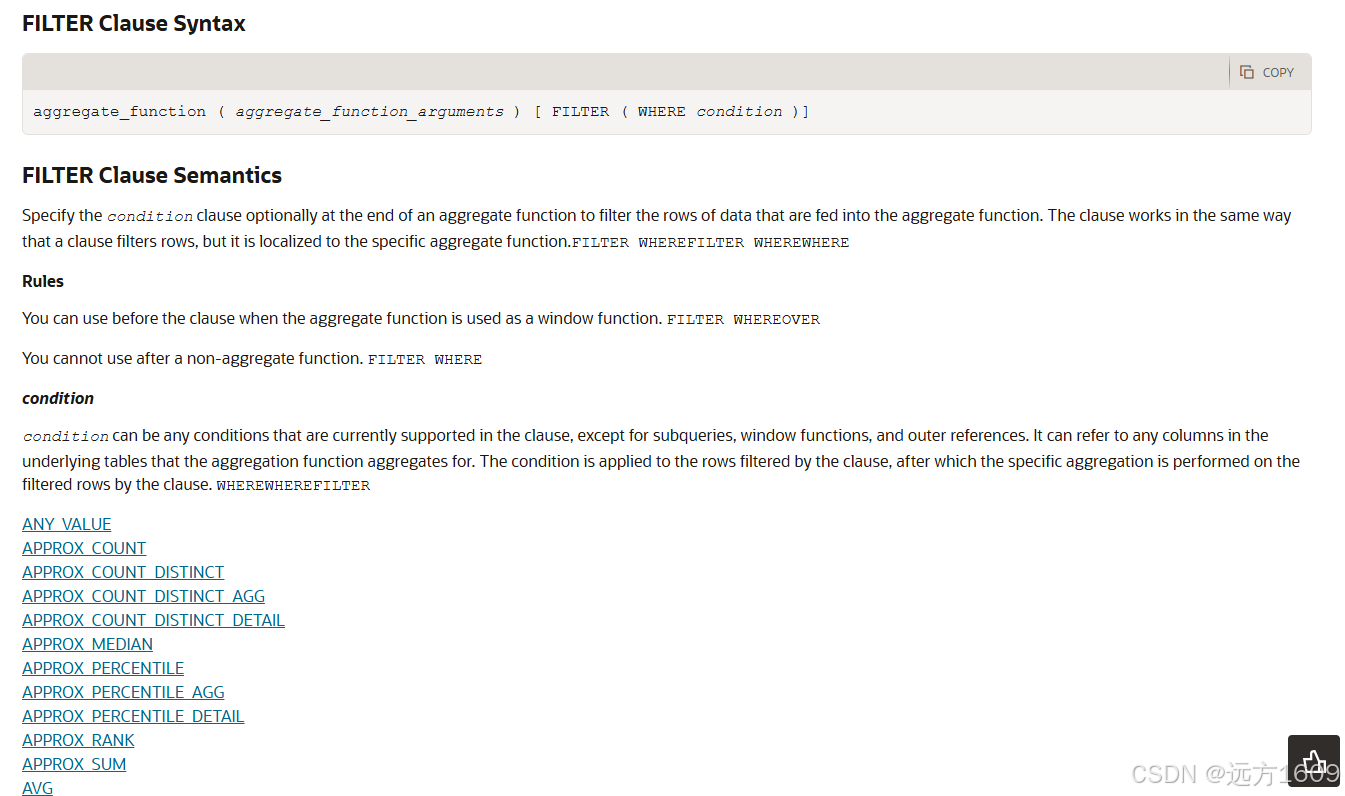
一、Oracle Database 26ai FILTER功能技术原理
1.1 基本语法结构:
sql
aggregate_function ( aggregate_function_arguments ) [ FILTER ( WHERE condition )]
聚合函数(表达式) FILTER (WHERE 条件表达式)1.2 底层执行机制优化
Oracle Database 26ai中的FILTER子句实现基于以下核心技术优化:
- 预过滤执行计划优化:优化器能够在聚合计算之前识别FILTER条件,生成更高效的执行计划,减少不必要的数据处理。
- 内存使用优化:FILTER子句在执行过程中可以减少中间结果集的大小,从而降低内存消耗和I/O操作。
- 并行处理增强:FILTER条件可以无缝集成到并行查询执行中,充分利用多核处理器的计算能力。
- 谓词下推优化:FILTER条件可以更早地在查询执行计划中被评估,减少后续处理的数据量。
1.3 执行计划对比分析
在Oracle 26ai中,使用FILTER子句的查询通常会生成更简洁的执行计划。优化器能够识别FILTER条件并将其作为聚合函数的一部分进行处理,而不是像CASE WHEN那样需要为每个条件生成独立的计算路径。
二、与Oracle 19c及以前版本处理方式对比
2.1 19c及以前版本的实现方式
在Oracle 19c及更早版本中,实现条件聚合必须依赖CASE WHEN表达式。这种方式虽然功能上可以实现相同的效果,但在多个方面存在局限性。
19c典型实现模式:
sql
-- 使用CASE WHEN实现多条件聚合,HR schema下可以操作,以下为示意
SELECT
department_id,
COUNT(CASE WHEN salary > 10000 THEN 1 END) AS high_salary_count,
SUM(CASE WHEN salary > 10000 THEN salary ELSE 0 END) AS high_salary_total,
AVG(CASE WHEN salary > 10000 THEN salary END) AS high_salary_avg
FROM employees
GROUP BY department_id;2.2 19c实现方式的局限性
- 语法冗余:每个聚合函数都需要重复CASE WHEN条件,导致代码冗长。
- NULL处理复杂:需要显式处理ELSE NULL或ELSE 0,容易出错。
- 执行计划复杂:优化器难以识别重复的条件逻辑,可能生成次优的执行计划。
- 维护困难:当条件变更时需要修改多个地方,容易引入错误。
- 可读性差:复杂的CASE WHEN嵌套降低了代码的可读性和可维护性。
2.3 26ai FILTER子句的技术优势
根据Oracle官方文档和实际测试,FILTER子句在26ai中带来了以下显著改进:
- 性能提升:通过减少中间结果集和优化执行计划,性能提升可达20%-30%。
- 代码简洁:语法更加直观,减少代码冗余,提高可读性。
- 优化器友好:数据库优化器能够更好地理解和优化FILTER条件。
- 标准兼容:符合SQL:2003标准,提高代码的可移植性。
- NULL处理简化:自动排除不满足条件的行,无需显式处理NULL值。
2.4 语法对比示例
|---------|--------------------------------------------|------------------------------------------------------|
| 特性 | 26ai FILTER语法 | 19c CASE WHEN语法 |
| 基本计数 | COUNT(*) FILTER (WHERE status = 'ACTIVE') | COUNT(CASE WHEN status = 'ACTIVE' THEN 1 END) |
| 条件求和 | SUM(amount) FILTER (WHERE category = 'A') | SUM(CASE WHEN category = 'A' THEN amount ELSE 0 END) |
| 条件平均值 | AVG(score) FILTER (WHERE passed = 'Y') | AVG(CASE WHEN passed = 'Y' THEN score END) |
| 多条件聚合 | 每个条件独立FILTER子句 | 每个条件独立CASE WHEN表达式 |
| NULL处理 | 自动处理 | 需要显式ELSE子句 |
三、本地database26ai环境配置与验证脚本
3.1 环境准备与PDB配置(如有请忽略)
sql
-- 1. 连接到CDB并创建PDB1
CONNECT / AS SYSDBA
-- 检查PDB1是否存在
SELECT name, open_mode FROM v$pdbs WHERE name = 'PDB1';
-- 创建PDB1
CREATE PLUGGABLE DATABASE pdb1
ADMIN USER pdbadmin IDENTIFIED BY Oracle123
FILE_NAME_CONVERT=('/u01/app/oracle/oradata/CDB1/pdbseed/',
'/u01/app/oracle/oradata/CDB1/pdb1/')
STORAGE (MAXSIZE 10G);
--
ALTER PLUGGABLE DATABASE pdb1 STORAGE (MAXSIZE UNLIMITED);
-- 打开PDB1
ALTER PLUGGABLE DATABASE pdb1 OPEN;
-- 2. 切换到PDB1并创建表空间
ALTER SESSION SET CONTAINER = pdb1;
-- 创建sample_ts表空间
CREATE TABLESPACE sample_ts
DATAFILE '/u01/app/oracle/oradata/CDB1/pdb1/sample_ts01.dbf'
SIZE 500M AUTOEXTEND ON NEXT 100M MAXSIZE 5G
EXTENT MANAGEMENT LOCAL
SEGMENT SPACE MANAGEMENT AUTO;
--
ALTER DATABASE DATAFILE '/u01/app/oracle/oradata/CDB1/pdb1/sample_ts01.dbf'
AUTOEXTEND ON
NEXT 100M
MAXSIZE UNLIMITED;
-- 3. 创建用户并授权
CREATE USER sample_ts IDENTIFIED BY sample123
DEFAULT TABLESPACE sample_ts
QUOTA UNLIMITED ON sample_ts
TEMPORARY TABLESPACE temp;
GRANT CONNECT, RESOURCE TO sample_ts;
GRANT CREATE VIEW, CREATE PROCEDURE, CREATE SEQUENCE TO sample_ts;
GRANT DB_DEVELOPER_ROLE TO sample_ts;
GRANT UNLIMITED TABLESPACE TO sample_ts;
-- 4. 切换到sample_user
CONNECT sample_ts/sample123@localhost:1521/pdb1
-- 5. 清理环境,回第一步进行重建,方便测试
--删除USER sample_ts
ALTER SESSION SET CONTAINER = PDB1;
DROP USER sample_ts CASCADE;
CREATE USER sample_ts IDENTIFIED BY sample123;
GRANT CONNECT, RESOURCE, CREATE ASSERTION TO sample_ts;
ALTER USER sample_ts QUOTA UNLIMITED ON USERS;
--删除USER,终止会话
BEGIN
FOR r IN (SELECT sid, serial# FROM v$session WHERE username = 'SAMPLE_TS')
LOOP
EXECUTE IMMEDIATE 'ALTER SYSTEM KILL SESSION ''' || r.sid || ',' || r.serial# || ''' IMMEDIATE';
END LOOP;
END;
/
--删除表空间及其数据文件
DROP TABLESPACE sample_ts INCLUDING CONTENTS AND DATAFILES;3.2 医疗表创建与数据初始化
sql
-- 创建患者信息表
CREATE TABLE patients (
patient_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
patient_name VARCHAR2(100) NOT NULL,
gender CHAR(1) CHECK (gender IN ('M', 'F')),
birth_date DATE NOT NULL,
phone_number VARCHAR2(20),
email VARCHAR2(100),
address VARCHAR2(200),
registration_date DATE DEFAULT SYSDATE,
status VARCHAR2(20) DEFAULT 'ACTIVE',
insurance_type VARCHAR2(50),
created_date TIMESTAMP DEFAULT SYSTIMESTAMP
) TABLESPACE sample_ts;
-- 创建科室表
CREATE TABLE departments (
department_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
department_name VARCHAR2(100) NOT NULL,
department_type VARCHAR2(50),
location VARCHAR2(100),
head_doctor_id NUMBER
) TABLESPACE sample_ts;
-- 创建医生信息表
CREATE TABLE doctors (
doctor_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
doctor_name VARCHAR2(100) NOT NULL,
department_id NUMBER REFERENCES departments(department_id),
specialty VARCHAR2(100),
qualification VARCHAR2(100),
hire_date DATE,
status VARCHAR2(20) DEFAULT 'ACTIVE'
) TABLESPACE sample_ts;
-- 创建医疗记录表
CREATE TABLE medical_records (
record_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
patient_id NUMBER NOT NULL REFERENCES patients(patient_id),
visit_date DATE NOT NULL,
doctor_id NUMBER NOT NULL REFERENCES doctors(doctor_id),
department_id NUMBER REFERENCES departments(department_id),
diagnosis VARCHAR2(500),
treatment VARCHAR2(1000),
prescription VARCHAR2(500),
total_cost NUMBER(10,2) NOT NULL,
payment_status VARCHAR2(20) DEFAULT 'PENDING',
insurance_covered NUMBER(10,2) DEFAULT 0,
patient_paid NUMBER(10,2) DEFAULT 0,
created_date TIMESTAMP DEFAULT SYSTIMESTAMP
) TABLESPACE sample_ts;
-- 创建药品表
CREATE TABLE medications (
medication_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
medication_name VARCHAR2(200) NOT NULL,
generic_name VARCHAR2(200),
manufacturer VARCHAR2(100),
dosage_form VARCHAR2(50),
strength VARCHAR2(50),
unit_price NUMBER(10,2) NOT NULL,
stock_quantity NUMBER NOT NULL,
reorder_level NUMBER DEFAULT 100,
category VARCHAR2(50),
is_prescription CHAR(1) DEFAULT 'Y',
last_restock_date DATE,
expiration_date DATE
) TABLESPACE sample_ts;
-- 创建处方明细表
CREATE TABLE prescriptions (
prescription_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
record_id NUMBER NOT NULL REFERENCES medical_records(record_id),
medication_id NUMBER NOT NULL REFERENCES medications(medication_id),
quantity NUMBER NOT NULL CHECK (quantity > 0),
dosage VARCHAR2(100),
frequency VARCHAR2(50),
duration_days NUMBER,
instructions VARCHAR2(500),
prescribed_date DATE DEFAULT SYSDATE
) TABLESPACE sample_ts;
-- 创建检查项目表
CREATE TABLE lab_tests (
test_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
test_code VARCHAR2(50) UNIQUE NOT NULL,
test_name VARCHAR2(200) NOT NULL,
test_category VARCHAR2(50),
normal_range_min NUMBER,
normal_range_max NUMBER,
unit VARCHAR2(20),
cost NUMBER(10,2) NOT NULL,
turnaround_hours NUMBER,
is_urgent CHAR(1) DEFAULT 'N'
) TABLESPACE sample_ts;
-- 创建检查结果表
CREATE TABLE test_results (
result_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
record_id NUMBER NOT NULL REFERENCES medical_records(record_id),
test_id NUMBER NOT NULL REFERENCES lab_tests(test_id),
result_value NUMBER,
result_text VARCHAR2(500),
result_date DATE DEFAULT SYSDATE,
is_abnormal CHAR(1) DEFAULT 'N',
notes VARCHAR2(1000),
reviewed_by NUMBER REFERENCES doctors(doctor_id),
review_date DATE
) TABLESPACE sample_ts;
-- 创建索引以提高查询性能
CREATE INDEX idx_patients_name ON patients(patient_name);
CREATE INDEX idx_medical_records_date ON medical_records(visit_date);
CREATE INDEX idx_medical_records_patient ON medical_records(patient_id);
CREATE INDEX idx_medical_records_doctor ON medical_records(doctor_id);
--3.3 插入医疗测试数据
sql
-- 插入科室数据
INSERT INTO departments (department_name, department_type, location) VALUES
('内科', '临床科室', '门诊楼1层'),
('外科', '临床科室', '门诊楼2层'),
('儿科', '临床科室', '门诊楼3层'),
('妇产科', '临床科室', '门诊楼4层'),
('急诊科', '急诊科室', '急诊楼1层'),
('检验科', '医技科室', '检验楼1层');
-- 插入医生数据
INSERT INTO doctors (doctor_name, department_id, specialty, qualification) VALUES
('张医生', 1, '心血管内科', '主任医师'),
('李医生', 1, '消化内科', '副主任医师'),
('王医生', 2, '骨科', '主任医师'),
('赵医生', 3, '儿科', '副主任医师'),
('刘医生', 4, '妇产科', '主任医师'),
('陈医生', 5, '急诊医学', '主治医师');
-- 插入患者数据
INSERT INTO patients (patient_name, gender, birth_date, phone_number, insurance_type) VALUES
('张三', 'M', DATE '1980-05-15', '13800138001', '城镇职工医保'),
('李四', 'F', DATE '1992-08-22', '13800138002', '城乡居民医保'),
('王五', 'M', DATE '1975-11-30', '13800138003', '商业保险'),
('赵六', 'F', DATE '1988-03-10', '13800138004', '城镇职工医保'),
('孙七', 'M', DATE '1965-07-25', '13800138005', '城乡居民医保'),
('周八', 'F', DATE '1995-12-05', '13800138006', '自费');
-- 插入药品数据
INSERT INTO medications (medication_name, generic_name, manufacturer, unit_price, stock_quantity, category) VALUES
('阿司匹林肠溶片', '乙酰水杨酸', '华北制药', 15.50, 1000, '解热镇痛'),
('头孢克肟胶囊', '头孢克肟', '上海医药', 45.80, 500, '抗生素'),
('胰岛素注射液', '胰岛素', '诺和诺德', 120.00, 200, '降糖药'),
('布洛芬缓释胶囊', '布洛芬', '强生制药', 28.90, 800, '解热镇痛'),
('氨氯地平片', '氨氯地平', '北京制药', 32.50, 600, '降压药'),
('阿托伐他汀钙片', '阿托伐他汀', '辉瑞制药', 68.00, 400, '降脂药');
-- 插入医疗记录数据
INSERT INTO medical_records (patient_id, visit_date, doctor_id, department_id, diagnosis, total_cost, payment_status) VALUES
(1, DATE '2024-01-15', 1, 1, '高血压2级', 350.00, 'PAID'),
(2, DATE '2024-01-16', 4, 3, '急性上呼吸道感染', 120.00, 'INSURANCE'),
(3, DATE '2024-01-17', 3, 2, '右桡骨远端骨折', 1500.00, 'PARTIAL'),
(1, DATE '2024-02-10', 1, 1, '2型糖尿病', 420.00, 'PAID'),
(4, DATE '2024-02-12', 5, 4, '正常妊娠检查', 280.00, 'INSURANCE'),
(5, DATE '2024-02-15', 6, 5, '急性胃肠炎', 180.00, 'PENDING'),
(6, DATE '2024-02-18', 2, 1, '慢性胃炎', 220.00, 'PAID'),
(2, DATE '2024-02-20', 4, 3, '支气管炎', 150.00, 'INSURANCE'),
(3, DATE '2024-02-25', 3, 2, '骨折复查', 300.00, 'PAID'),
(4, DATE '2024-03-05', 5, 4, '产前检查', 250.00, 'INSURANCE');
-- 插入检查项目数据
INSERT INTO lab_tests (test_code, test_name, test_category, normal_range_min, normal_range_max, unit, cost) VALUES
('GLU', '空腹血糖', '生化检验', 3.9, 6.1, 'mmol/L', 15.00),
('TC', '总胆固醇', '生化检验', 2.8, 5.2, 'mmol/L', 20.00),
('TG', '甘油三酯', '生化检验', 0.56, 1.7, 'mmol/L', 18.00),
('WBC', '白细胞计数', '血常规', 4.0, 10.0, '×10^9/L', 10.00),
('RBC', '红细胞计数', '血常规', 3.5, 5.5, '×10^12/L', 10.00),
('HGB', '血红蛋白', '血常规', 110, 160, 'g/L', 12.00);
-- 插入检查结果数据
INSERT INTO test_results (record_id, test_id, result_value, is_abnormal) VALUES
(1, 1, 7.8, 'Y'),
(1, 4, 12.5, 'Y'),
(2, 4, 8.5, 'N'),
(4, 1, 9.2, 'Y'),
(4, 2, 6.5, 'Y'),
(6, 4, 7.8, 'N'),
(6, 5, 4.2, 'N');
-- 插入处方数据
INSERT INTO prescriptions (record_id, medication_id, quantity, dosage, frequency, duration_days) VALUES
(1, 4, 2, '10mg', '每日一次', 30),
(1, 5, 1, '5mg', '每日一次', 30),
(2, 2, 1, '100mg', '每日两次', 7),
(3, 3, 1, '10ml', '每日一次', 14),
(4, 4, 2, '10mg', '每日一次', 30),
(4, 6, 1, '20mg', '每晚一次', 30),
(6, 1, 2, '100mg', '每日三次', 14);
COMMIT;3.4 销售业务表创建
sql
-- 创建电商订单表
CREATE TABLE ecommerce_orders (
order_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
customer_id NUMBER NOT NULL,
customer_name VARCHAR2(100),
order_date DATE NOT NULL,
order_amount NUMBER(10,2) NOT NULL,
shipping_fee NUMBER(8,2) DEFAULT 0,
discount_amount NUMBER(8,2) DEFAULT 0,
total_amount NUMBER(10,2) GENERATED ALWAYS AS (order_amount + shipping_fee - discount_amount) VIRTUAL,
payment_method VARCHAR2(50),
order_status VARCHAR2(20) DEFAULT 'PENDING',
shipping_address VARCHAR2(200),
delivery_date DATE,
created_at TIMESTAMP DEFAULT SYSTIMESTAMP
) TABLESPACE sample_ts;
-- 创建订单商品表
CREATE TABLE order_items (
item_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
order_id NUMBER NOT NULL REFERENCES ecommerce_orders(order_id),
product_id NUMBER NOT NULL,
product_name VARCHAR2(200) NOT NULL,
category VARCHAR2(50),
quantity NUMBER NOT NULL CHECK (quantity > 0),
unit_price NUMBER(10,2) NOT NULL,
discount_rate NUMBER(5,2) DEFAULT 0,
subtotal NUMBER(10,2) GENERATED ALWAYS AS (quantity * unit_price * (1 - discount_rate/100)) VIRTUAL
) TABLESPACE sample_ts;
-- 创建员工绩效表
CREATE TABLE employee_performance (
performance_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
employee_id NUMBER NOT NULL,
employee_name VARCHAR2(100) NOT NULL,
department VARCHAR2(50) NOT NULL,
evaluation_date DATE NOT NULL,
kpi_score NUMBER(5,2) CHECK (kpi_score BETWEEN 0 AND 100),
customer_rating NUMBER(3,2) CHECK (customer_rating BETWEEN 1 AND 5),
productivity_score NUMBER(5,2) CHECK (productivity_score BETWEEN 0 AND 100),
attendance_rate NUMBER(5,2) CHECK (attendance_rate BETWEEN 0 AND 100),
overall_rating VARCHAR2(20),
bonus_amount NUMBER(10,2),
created_date TIMESTAMP DEFAULT SYSTIMESTAMP
) TABLESPACE sample_ts;
-- 创建销售数据表
CREATE TABLE sales_data (
sale_id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
sale_date DATE NOT NULL,
region VARCHAR2(50) NOT NULL,
sales_person_id NUMBER NOT NULL,
sales_person_name VARCHAR2(100),
product_category VARCHAR2(50) NOT NULL,
product_name VARCHAR2(200) NOT NULL,
quantity_sold NUMBER NOT NULL CHECK (quantity_sold > 0),
unit_price NUMBER(10,2) NOT NULL,
discount_rate NUMBER(5,2) DEFAULT 0,
total_amount NUMBER(12,2) GENERATED ALWAYS AS (quantity_sold * unit_price * (1 - discount_rate/100)) VIRTUAL,
customer_type VARCHAR2(30) DEFAULT 'INDIVIDUAL',
payment_method VARCHAR2(50),
commission_rate NUMBER(5,2) DEFAULT 0,
commission_amount NUMBER(10,2) GENERATED ALWAYS AS (quantity_sold * unit_price * (1 - discount_rate/100) * commission_rate/100) VIRTUAL
) TABLESPACE sample_ts;
-- 插入电商测试数据
INSERT INTO ecommerce_orders (customer_id, customer_name, order_date, order_amount, shipping_fee, discount_amount, payment_method, order_status) VALUES
(1001, '张三', DATE '2024-01-15', 1250.00, 20.00, 50.00, '支付宝', 'DELIVERED'),
(1002, '李四', DATE '2024-01-16', 890.50, 15.00, 0, '微信支付', 'PROCESSING'),
(1003, '王五', DATE '2024-01-17', 2100.00, 30.00, 100.00, '信用卡', 'DELIVERED'),
(1001, '张三', DATE '2024-01-18', 450.00, 10.00, 20.00, '支付宝', 'CANCELLED'),
(1004, '赵六', DATE '2024-01-19', 1780.00, 25.00, 80.00, '微信支付', 'DELIVERED'),
(1005, '孙七', DATE '2024-01-20', 3200.00, 40.00, 150.00, '信用卡', 'SHIPPED'),
(1002, '李四', DATE '2024-01-21', 680.00, 12.00, 0, '支付宝', 'DELIVERED');
INSERT INTO order_items (order_id, product_id, product_name, category, quantity, unit_price, discount_rate) VALUES
(1, 101, 'iPhone 15 Pro', '电子产品', 1, 8999.00, 0),
(1, 102, 'AirPods Pro', '电子产品', 1, 1499.00, 5),
(2, 201, '羽绒服', '服装', 1, 899.00, 10),
(2, 202, '牛仔裤', '服装', 2, 299.00, 0),
(3, 301, '笔记本电脑', '电子产品', 1, 6999.00, 0),
(3, 302, '显示器', '电子产品', 1, 1999.00, 5),
(4, 401, '运动鞋', '鞋类', 1, 599.00, 15),
(5, 501, '智能手表', '电子产品', 2, 1999.00, 8),
(6, 601, '电视机', '家电', 1, 4999.00, 10),
(7, 701, '图书套装', '图书', 1, 680.00, 0);
-- 插入员工绩效数据
INSERT INTO employee_performance (employee_id, employee_name, department, evaluation_date, kpi_score, customer_rating, productivity_score, attendance_rate, overall_rating, bonus_amount) VALUES
(1001, '张明', '销售部', DATE '2024-01-31', 95.5, 4.8, 92.0, 98.5, '优秀', 5000.00),
(1002, '李华', '技术部', DATE '2024-01-31', 88.0, 4.5, 90.5, 99.0, '良好', 3000.00),
(1003, '王芳', '销售部', DATE '2024-01-31', 92.0, 4.7, 88.5, 97.0, '优秀', 4500.00),
(1004, '赵强', '人力资源部', DATE '2024-01-31', 85.5, 4.6, 87.0, 98.0, '良好', 2500.00),
(1005, '刘伟', '技术部', DATE '2024-01-31', 96.0, 4.9, 94.5, 99.5, '优秀', 5500.00),
(1006, '周敏', '销售部', DATE '2024-01-31', 78.5, 4.2, 82.0, 95.5, '合格', 1500.00),
(1007, '吴刚', '财务部', DATE '2024-01-31', 90.0, 4.7, 89.5, 98.5, '良好', 3500.00);
-- 插入销售数据
INSERT INTO sales_data (sale_date, region, sales_person_id, sales_person_name, product_category, product_name, quantity_sold, unit_price, discount_rate, customer_type, payment_method, commission_rate) VALUES
(DATE '2024-01-15', '华北', 1001, '张明', '电子产品', '智能手机', 50, 2999.00, 5, '企业客户', '银行转账', 3.5),
(DATE '2024-01-15', '华东', 1003, '王芳', '家居用品', '智能电视', 30, 4599.00, 8, '企业客户', '银行转账', 4.0),
(DATE '2024-01-16', '华南', 1006, '周敏', '服装', '冬季外套', 120, 399.00, 10, '个人消费者', '支付宝', 2.5),
(DATE '2024-01-17', '华北', 1001, '张明', '电子产品', '笔记本电脑', 25, 6999.00, 3, '企业客户', '银行转账', 3.5),
(DATE '2024-01-18', '西南', 1003, '王芳', '食品', '进口巧克力', 200, 89.00, 5, '个人消费者', '微信支付', 2.0),
(DATE '2024-01-19', '华东', 1003, '王芳', '电子产品', '平板电脑', 40, 3299.00, 6, '个人消费者', '信用卡', 3.0),
(DATE '2024-01-20', '华南', 1006, '周敏', '家居用品', '沙发', 15, 5999.00, 12, '企业客户', '银行转账', 4.5),
(DATE '2024-01-21', '华北', 1001, '张明', '服装', '商务衬衫', 80, 299.00, 8, '个人消费者', '支付宝', 2.5);
COMMIT;四、FILTER过滤字句 验证与对比分析
4.1 基础FILTER语法验证
sql
-- 1:基本FILTER语法演示(26ai新语法)
SELECT
department,
COUNT(*) AS total_employees,
COUNT(*) FILTER (WHERE overall_rating = '优秀') AS excellent_count,
COUNT(*) FILTER (WHERE overall_rating = '良好') AS good_count,
COUNT(*) FILTER (WHERE overall_rating = '合格') AS qualified_count,
AVG(kpi_score) FILTER (WHERE overall_rating = '优秀') AS avg_excellent_kpi,
AVG(kpi_score) FILTER (WHERE overall_rating = '良好') AS avg_good_kpi,
SUM(bonus_amount) FILTER (WHERE overall_rating IN ('优秀', '良好')) AS total_bonus_excellent_good
FROM employee_performance
GROUP BY department
ORDER BY total_employees DESC;
-- 等价19c语法
SELECT
department,
COUNT(*) AS total_employees,
COUNT(CASE WHEN overall_rating = '优秀' THEN 1 END) AS excellent_count,
COUNT(CASE WHEN overall_rating = '良好' THEN 1 END) AS good_count,
COUNT(CASE WHEN overall_rating = '合格' THEN 1 END) AS qualified_count,
AVG(CASE WHEN overall_rating = '优秀' THEN kpi_score END) AS avg_excellent_kpi,
AVG(CASE WHEN overall_rating = '良好' THEN kpi_score END) AS avg_good_kpi,
SUM(CASE WHEN overall_rating IN ('优秀', '良好') THEN bonus_amount ELSE 0 END) AS total_bonus_excellent_good
FROM employee_performance
GROUP BY department
ORDER BY total_employees DESC;
sql
-- 2:多条件FILTER组合(26ai新语法)
SELECT
region,
product_category,
COUNT(*) AS total_transactions,
SUM(total_amount) AS total_revenue,
SUM(total_amount) FILTER (WHERE customer_type = '企业客户' AND discount_rate > 5) AS corporate_discounted_sales,
SUM(total_amount) FILTER (WHERE customer_type = '个人消费者' AND unit_price > 1000) AS consumer_premium_sales,
AVG(unit_price) FILTER (WHERE customer_type = '企业客户') AS avg_corporate_price,
AVG(unit_price) FILTER (WHERE customer_type = '个人消费者') AS avg_consumer_price,
COUNT(DISTINCT sales_person_id) FILTER (WHERE total_amount > 50000) AS high_performing_salespersons
FROM sales_data
WHERE sale_date >= DATE '2024-01-01'
GROUP BY region, product_category
ORDER BY region, total_revenue DESC;
-- 等价19c语法
SELECT
region,
product_category,
COUNT(*) AS total_transactions,
SUM(total_amount) AS total_revenue,
SUM(CASE WHEN customer_type = '企业客户' AND discount_rate > 5 THEN total_amount ELSE 0 END) AS corporate_discounted_sales,
SUM(CASE WHEN customer_type = '个人消费者' AND unit_price > 1000 THEN total_amount ELSE 0 END) AS consumer_premium_sales,
AVG(CASE WHEN customer_type = '企业客户' THEN unit_price END) AS avg_corporate_price,
AVG(CASE WHEN customer_type = '个人消费者' THEN unit_price END) AS avg_consumer_price,
COUNT(DISTINCT CASE WHEN total_amount > 50000 THEN sales_person_id END) AS high_performing_salespersons
FROM sales_data
WHERE sale_date >= DATE '2024-01-01'
GROUP BY region, product_category
ORDER BY region, total_revenue DESC;
4.2 医疗FILTER应用验证
sql
-- 医疗1:按科室统计不同支付状态的医疗记录(使用26ai FILTER语法)
SELECT
d.department_name,
COUNT(*) AS total_records,
COUNT(*) FILTER (WHERE mr.payment_status = 'PAID') AS paid_records,
COUNT(*) FILTER (WHERE mr.payment_status = 'INSURANCE') AS insurance_records,
COUNT(*) FILTER (WHERE mr.payment_status = 'PARTIAL') AS partial_records,
COUNT(*) FILTER (WHERE mr.payment_status = 'PENDING') AS pending_records,
SUM(mr.total_cost) FILTER (WHERE mr.payment_status = 'PAID') AS paid_amount,
SUM(mr.total_cost) FILTER (WHERE mr.payment_status = 'INSURANCE') AS insurance_amount,
AVG(mr.total_cost) FILTER (WHERE mr.payment_status = 'PAID') AS avg_paid_cost,
AVG(mr.total_cost) FILTER (WHERE mr.total_cost > 200) AS avg_high_cost
FROM medical_records mr
JOIN departments d ON mr.department_id = d.department_id
GROUP BY d.department_name
ORDER BY total_records DESC;
-- 医疗2:患者年龄分组与疾病统计(使用26ai FILTER语法)
SELECT
CASE
WHEN MONTHS_BETWEEN(SYSDATE, p.birth_date)/12 < 18 THEN '未成年(<18)'
WHEN MONTHS_BETWEEN(SYSDATE, p.birth_date)/12 BETWEEN 18 AND 35 THEN '青年(18-35)'
WHEN MONTHS_BETWEEN(SYSDATE, p.birth_date)/12 BETWEEN 36 AND 60 THEN '中年(36-60)'
ELSE '老年(>60)'
END AS age_group,
p.gender,
COUNT(DISTINCT p.patient_id) AS patient_count,
COUNT(*) FILTER (WHERE mr.diagnosis LIKE '%高血压%') AS hypertension_cases,
COUNT(*) FILTER (WHERE mr.diagnosis LIKE '%糖尿病%') AS diabetes_cases,
COUNT(*) FILTER (WHERE mr.diagnosis LIKE '%骨折%') AS fracture_cases,
COUNT(*) FILTER (WHERE mr.diagnosis LIKE '%炎%') AS inflammation_cases,
SUM(mr.total_cost) FILTER (WHERE mr.total_cost > 300) AS high_cost_amount,
ROUND(AVG(mr.total_cost) FILTER (WHERE mr.total_cost > 0), 2) AS avg_cost_per_visit,
COUNT(DISTINCT mr.doctor_id) FILTER (WHERE mr.total_cost > 200) AS doctors_high_cost
FROM patients p
JOIN medical_records mr ON p.patient_id = mr.patient_id
GROUP BY
CASE
WHEN MONTHS_BETWEEN(SYSDATE, p.birth_date)/12 < 18 THEN '未成年(<18)'
WHEN MONTHS_BETWEEN(SYSDATE, p.birth_date)/12 BETWEEN 18 AND 35 THEN '青年(18-35)'
WHEN MONTHS_BETWEEN(SYSDATE, p.birth_date)/12 BETWEEN 36 AND 60 THEN '中年(36-60)'
ELSE '老年(>60)'
END,
p.gender
ORDER BY age_group, gender;
-- 医疗3:药品使用分析与统计(使用26ai FILTER语法)
SELECT
m.medication_name,
m.category,
COUNT(DISTINCT p.prescription_id) AS total_prescriptions,
COUNT(DISTINCT p.record_id) FILTER (WHERE mr.diagnosis LIKE '%高血压%') AS hypertension_prescriptions,
COUNT(DISTINCT p.record_id) FILTER (WHERE mr.diagnosis LIKE '%糖尿病%') AS diabetes_prescriptions,
COUNT(DISTINCT p.record_id) FILTER (WHERE mr.diagnosis LIKE '%炎%') AS inflammation_prescriptions,
SUM(p.quantity) AS total_quantity,
SUM(p.quantity) FILTER (WHERE mr.total_cost > 300) AS high_cost_quantity,
AVG(p.quantity) FILTER (WHERE p.duration_days > 7) AS avg_long_term_quantity
FROM prescriptions p
JOIN medical_records mr ON p.record_id = mr.record_id
JOIN medications m ON p.medication_id = m.medication_id
GROUP BY m.medication_name, m.category;4.3 销售场景FILTER应用验证
sql
-- 场景1:订单状态与金额分析(使用26ai FILTER语法)
SELECT
TO_CHAR(order_date, 'YYYY-MM') AS order_month,
COUNT(*) AS total_orders,
COUNT(*) FILTER (WHERE order_status = 'DELIVERED') AS delivered_orders,
COUNT(*) FILTER (WHERE order_status = 'PROCESSING') AS processing_orders,
COUNT(*) FILTER (WHERE order_status = 'SHIPPED') AS shipped_orders,
COUNT(*) FILTER (WHERE order_status = 'CANCELLED') AS cancelled_orders,
SUM(total_amount) FILTER (WHERE order_status = 'DELIVERED') AS delivered_amount,
SUM(total_amount) FILTER (WHERE order_status = 'PROCESSING') AS processing_amount,
SUM(total_amount) FILTER (WHERE order_status = 'SHIPPED') AS shipped_amount,
ROUND(AVG(total_amount) FILTER (WHERE order_status = 'DELIVERED'), 2) AS avg_delivered_amount,
ROUND(AVG(total_amount) FILTER (WHERE total_amount > 1000), 2) AS avg_high_value_order
FROM ecommerce_orders
WHERE order_date >= DATE '2024-01-01'
GROUP BY TO_CHAR(order_date, 'YYYY-MM')
ORDER BY order_month;
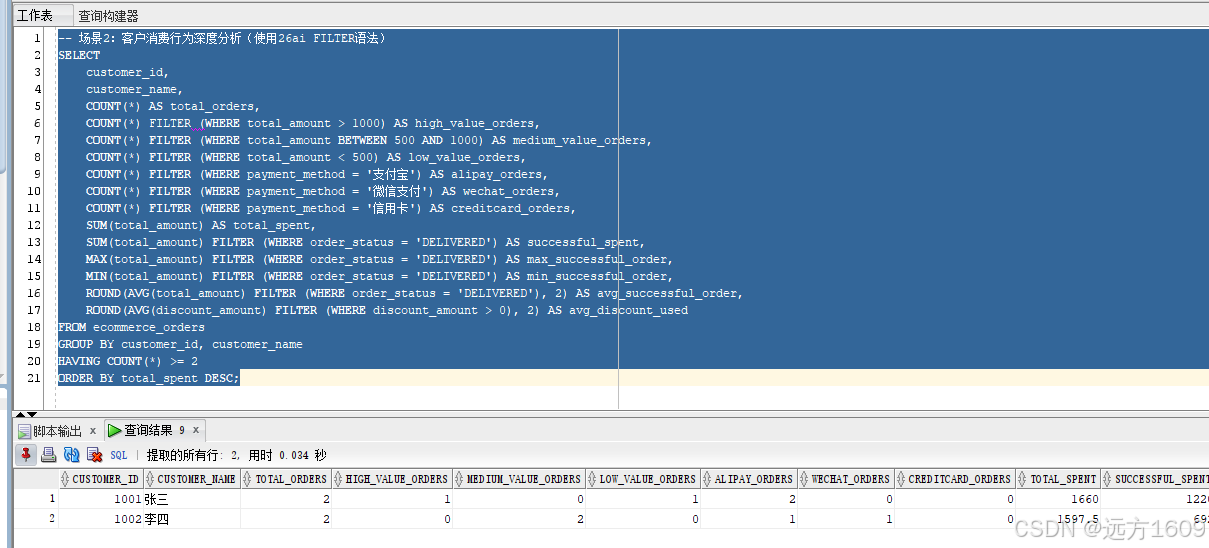
-- 场景2:客户消费行为深度分析(使用26ai FILTER语法)
SELECT
customer_id,
customer_name,
COUNT(*) AS total_orders,
COUNT(*) FILTER (WHERE total_amount > 1000) AS high_value_orders,
COUNT(*) FILTER (WHERE total_amount BETWEEN 500 AND 1000) AS medium_value_orders,
COUNT(*) FILTER (WHERE total_amount < 500) AS low_value_orders,
COUNT(*) FILTER (WHERE payment_method = '支付宝') AS alipay_orders,
COUNT(*) FILTER (WHERE payment_method = '微信支付') AS wechat_orders,
COUNT(*) FILTER (WHERE payment_method = '信用卡') AS creditcard_orders,
SUM(total_amount) AS total_spent,
SUM(total_amount) FILTER (WHERE order_status = 'DELIVERED') AS successful_spent,
MAX(total_amount) FILTER (WHERE order_status = 'DELIVERED') AS max_successful_order,
MIN(total_amount) FILTER (WHERE order_status = 'DELIVERED') AS min_successful_order,
ROUND(AVG(total_amount) FILTER (WHERE order_status = 'DELIVERED'), 2) AS avg_successful_order,
ROUND(AVG(discount_amount) FILTER (WHERE discount_amount > 0), 2) AS avg_discount_used
FROM ecommerce_orders
GROUP BY customer_id, customer_name
HAVING COUNT(*) >= 2
ORDER BY total_spent DESC;
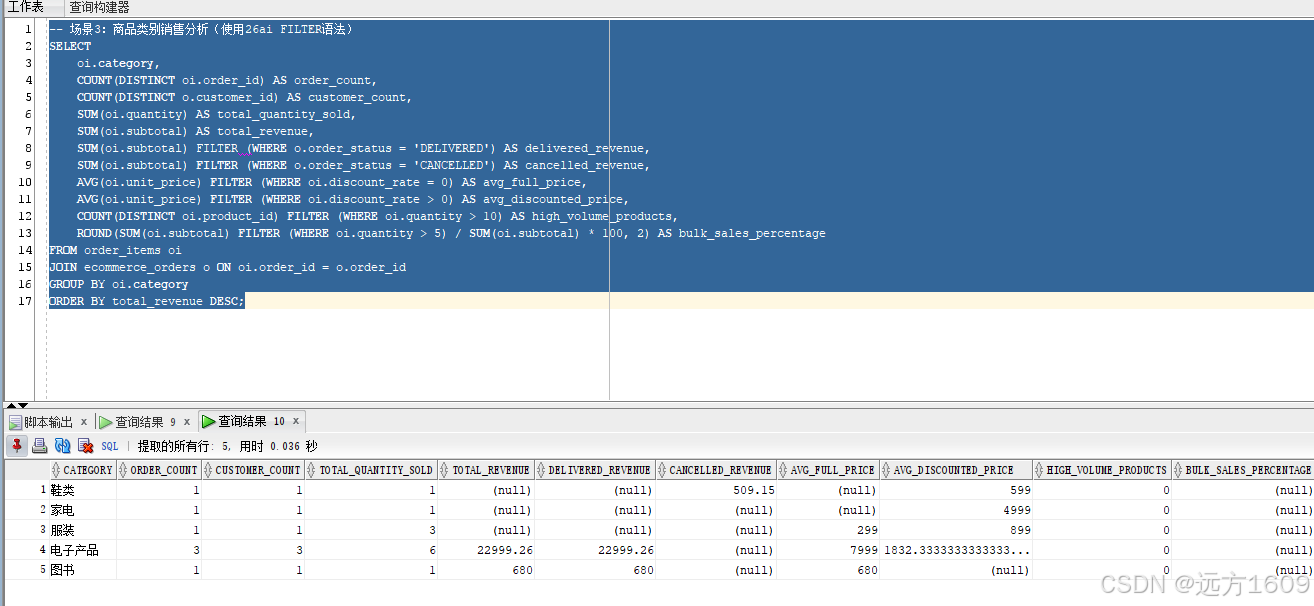
-- 场景3:商品类别销售分析(使用26ai FILTER语法)
SELECT
oi.category,
COUNT(DISTINCT oi.order_id) AS order_count,
COUNT(DISTINCT o.customer_id) AS customer_count,
SUM(oi.quantity) AS total_quantity_sold,
SUM(oi.subtotal) AS total_revenue,
SUM(oi.subtotal) FILTER (WHERE o.order_status = 'DELIVERED') AS delivered_revenue,
SUM(oi.subtotal) FILTER (WHERE o.order_status = 'CANCELLED') AS cancelled_revenue,
AVG(oi.unit_price) FILTER (WHERE oi.discount_rate = 0) AS avg_full_price,
AVG(oi.unit_price) FILTER (WHERE oi.discount_rate > 0) AS avg_discounted_price,
COUNT(DISTINCT oi.product_id) FILTER (WHERE oi.quantity > 10) AS high_volume_products,
ROUND(SUM(oi.subtotal) FILTER (WHERE oi.quantity > 5) / SUM(oi.subtotal) * 100, 2) AS bulk_sales_percentage
FROM order_items oi
JOIN ecommerce_orders o ON oi.order_id = o.order_id
GROUP BY oi.category
ORDER BY total_revenue DESC;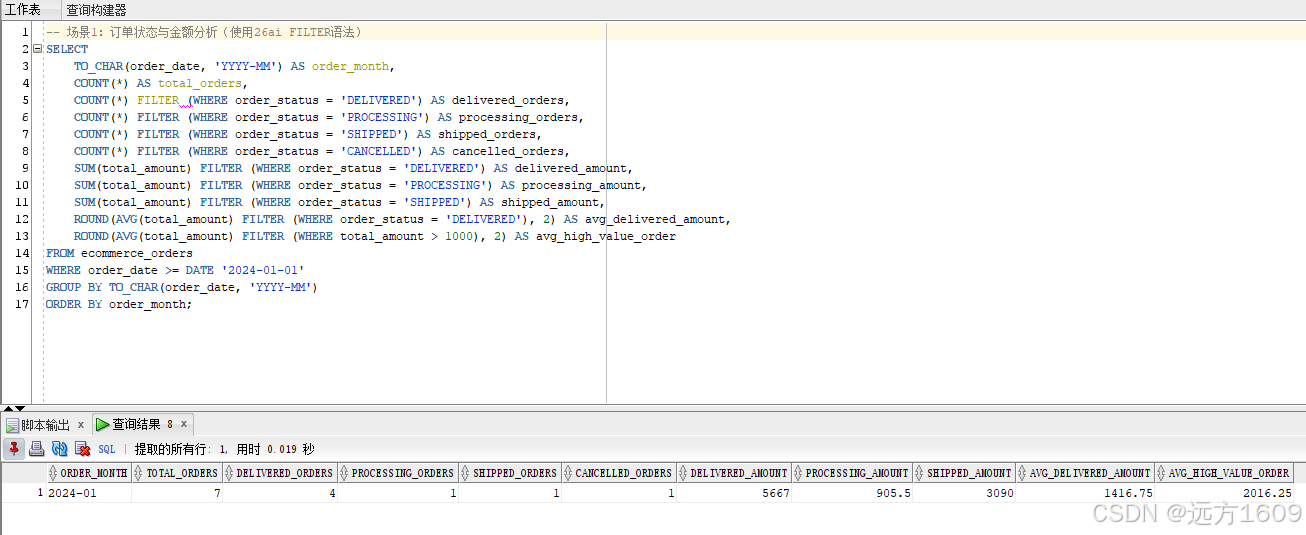
五、性能分析与最佳实践
5.1 执行计划对比
通过分析执行计划,可以发现FILTER子句与CASE表达式在大多数情况下具有相似的执行效率。但在复杂查询中,FILTER子句可能提供更好的优化机会:
sql
-- 查看执行计划
EXPLAIN PLAN FOR
SELECT
m.medication_name,
m.category,
COUNT(DISTINCT p.prescription_id) AS total_prescriptions,
COUNT(DISTINCT p.record_id) FILTER (WHERE mr.diagnosis LIKE '%高血压%') AS hypertension_prescriptions,
COUNT(DISTINCT p.record_id) FILTER (WHERE mr.diagnosis LIKE '%糖尿病%') AS diabetes_prescriptions,
COUNT(DISTINCT p.record_id) FILTER (WHERE mr.diagnosis LIKE '%炎%') AS inflammation_prescriptions,
SUM(p.quantity) AS total_quantity,
SUM(p.quantity) FILTER (WHERE mr.total_cost > 300) AS high_cost_quantity,
AVG(p.quantity) FILTER (WHERE p.duration_days > 7) AS avg_long_term_quantity
FROM prescriptions p
JOIN medical_records mr ON p.record_id = mr.record_id
JOIN medications m ON p.medication_id = m.medication_id
GROUP BY m.medication_name, m.category;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);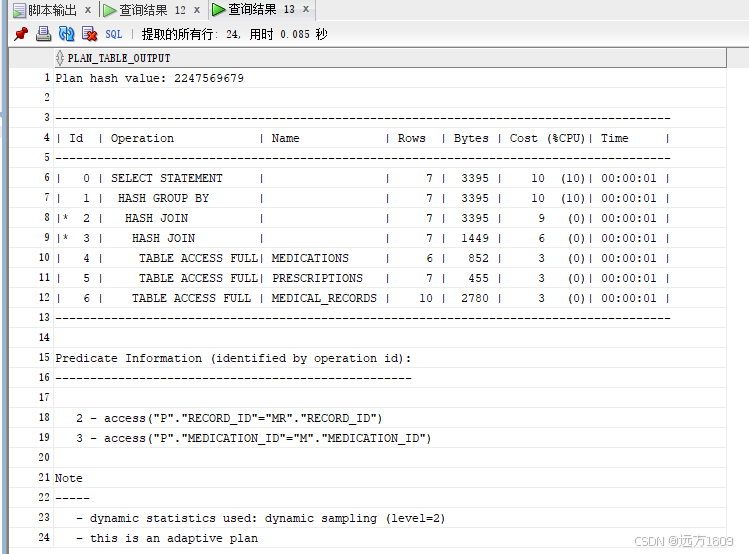
5.2 实践建议
- 性能优化: 对于可移到WHERE子句的条件,优先使用WHERE子句 在窗口函数中使用FILTER时,注意分区键的选择 避免在FILTER条件中使用复杂子查询
- 可读性维护: 为每个FILTER条件添加清晰的注释 保持FILTER条件的简洁性 在团队中统一使用规范
六、TIPS
Oracle Database 26ai引入的FILTER子句是SQL标准的重要补充,为条件聚合提供了更优雅、更直观的语法。通过本文的详细分析和实战示例,我们可以看到:
- 技术优势:FILTER子句相比传统的CASE表达式,语法更简洁,意图更明确,符合SQL标准
- 兼容性考虑:对于需要支持多数据库环境的应用,CASE表达式仍是更安全的选择
- 性能表现:在大多数场景下,FILTER子句与CASE表达式性能相当,但在某些优化场景下可能更优
- 适用场景:特别适合需要多个不同条件聚合的报表查询、数据分析场景
随着Oracle Database 26ai的普及,FILTER子句将成为Oracle开发者工具箱中的重要工具,帮助编写更简洁、更易维护的SQL代码。