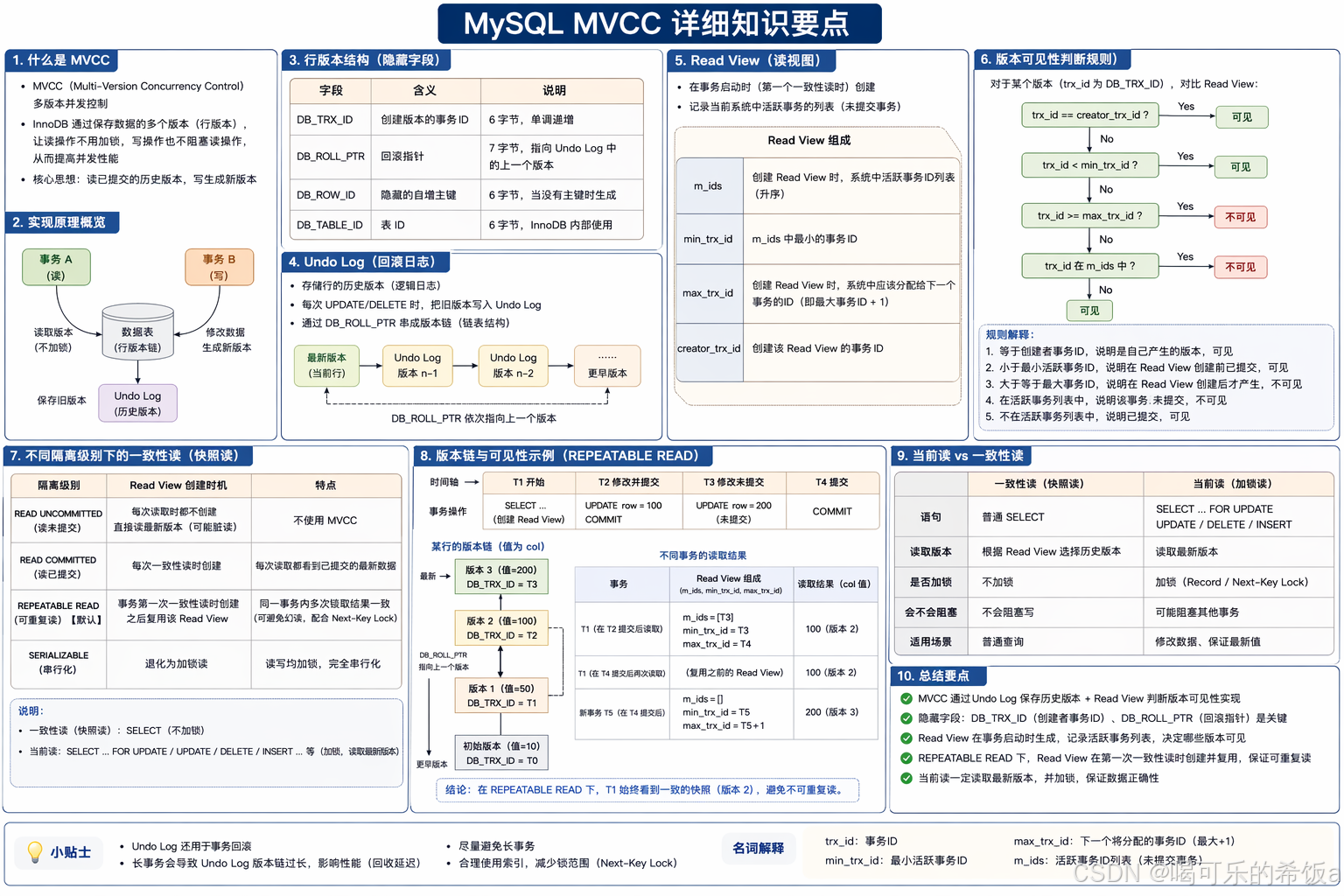



1. 为什么需要 MVCC:解决什么并发问题?
MySQL 的 InnoDB 要同时满足两件事:
- 高并发读:读操作尽量不阻塞写操作
- 一致性读:同一个事务在开始时刻看到"同一份数据快照"(在特定隔离级别下)
传统做法是读写都加锁(悲观锁),会造成大量等待;MVCC 的目标是:
读不加锁(或少加锁),写也不阻塞读,通过"版本"来实现一致性。
2. MVCC 的核心:版本 + 快照(Read View)
在 InnoDB 中,每条记录(更准确说是聚簇索引上的一行)不是只有一个值,而是可能存在多个版本:
- 新值来自 写事务 的更新
- 旧值保存在 undo log 里(用于回溯)
- 通过一个事务的 Read View(读视图) 来决定"读到哪个版本"
关键点一句话:
读事务不直接读最新值,而是根据自己的 Read View 去版本链(undo 链)里找"自己应该看到的那一版"。
3. InnoDB 数据结构相关:聚簇索引 + 记录版本字段
InnoDB 使用 聚簇索引(clustered index) 存数据,因此 MVCC 发生在聚簇索引记录层面。
每条记录(版本)会包含一些隐藏字段(不同版本略有差异,但概念一致):
- trx_id:这个版本是哪个事务生成的
- roll_ptr / undo_ptr:指向 undo log,用于回溯更旧版本
- 另外还有 delete 标记相关字段(用于判断"该版本是否已被删除")
当发生 UPDATE/DELETE 时,并不是原地覆盖最新值,而是形成新版本,并把旧版本信息写入 undo。
4. 写操作(UPDATE/DELETE)的 MVCC 行为:生成新版本 + undo
以 UPDATE 为例(简化流程):
- 事务在聚簇索引上找到目标记录
- InnoDB 对该行加必要的锁(细节取决于隔离级别与访问方式)
- 生成一个新版本(记录中的数据变更对外体现)
- 把"旧版本"写入 undo log
- 旧版本通过 undo 链保留下来,供并发读回溯使用
- 提交事务时,事务提交信息记录到事务系统中(commit_id/完成状态)
DELETE 同理:通常也是创建版本 + 通过 delete 标记让读者看见"已删除"状态。
总结:写会产生新版本,但旧版本并不会立即消失,而是保留在 undo 里直到被 purge 回收。
5. 读操作的关键:根据 Read View 决定可见版本
5.1 Read View 是什么?
Read View(读视图)通常在事务开始时确定(取决于隔离级别):
- 对于 REPEATABLE READ(可重复读,InnoDB 默认):通常在事务第一次读时创建,之后事务内保持不变
- 对于 READ COMMITTED(读已提交):通常每次执行查询都会生成新的 Read View
Read View 里通常包含类似信息(概念层面):
- 当前系统里仍未提交的事务列表(活跃事务集合)
- m_ids(最小活跃事务号)
- creator_trx_id(创建 Read View 的事务号)
- 边界值等
5.2 版本可见性规则(核心逻辑)
当读到某个版本时,要判断它是否对当前事务可见,常见判断逻辑如下(概念版):
假设当前版本由 trx_id 生成,那么对读事务来说可见当:
trx_id < m_ids
→ 表示该版本事务在 Read View 创建前就已提交,因此可见trx_id >= creator_trx_id
→ 表示该版本事务是当前事务自身(或未来),一般对当前事务可见/可见性处理取决于实现,但总体不会被屏蔽m_ids <= trx_id < creator_trx_id
→ 需要看trx_id是否在未提交事务列表中:- 不在未提交列表 → 已提交,可见
- 在未提交列表 → 尚未提交,不可见(需要回溯到更旧版本)
如果当前版本不可见,就顺着 undo_ptr 找更旧版本,直到找到可见版本或链结束。
因此你会看到:MVCC 读可能"多次回溯 undo",成本来自 undo 链长度和回溯次数。
6. undo、redo、purge:三者分别做什么?
6.1 undo log:保存旧版本,服务于一致性读与回滚
- UPDATE/DELETE 会写 undo
- SELECT 会通过 undo 回溯
- ROLLBACK 会用 undo 回滚
6.2 redo log:崩溃恢复(WAL 思想)
- 负责保证"已提交的事务"在宕机后可以恢复
- 不是用来给读回溯版本的
6.3 purge:清理不再需要的旧版本(回收 undo)
因为 undo 不能无限增长,所以后台会做 purge,把对所有事务都已经不可见的旧版本清掉。
purge 依赖:
- 最老活跃事务(oldest active transaction)的信息
- undo 版本链的可见性判断
如果长事务存在很久,最老活跃事务很老,purge 很难回收 undo,undo 会爆炸,导致性能下降(这是经典痛点)。
7. 不同隔离级别下的 MVCC 表现
7.1 READ COMMITTED(读已提交)
- 每次 SELECT 都创建新的 Read View
- 因此:同一事务里两次读可能读到不同结果(能看到别的事务提交的新数据)
- 通常 undo 回溯逻辑更"活跃",版本可见性会变化
7.2 REPEATABLE READ(可重复读,InnoDB 默认)
- 一致性快照在事务内保持
- 同一事务内多次 SELECT 看到的数据一致
- 但在一些情况下,仍然可能出现幻读问题的处理方式(InnoDB 通过 next-key lock / gap lock 等机制配合锁来解决)
注意:MVCC 解决"读取一致性",但幻读这种现象是否彻底避免,还要看加锁策略与隔离级别,尤其是涉及范围查询时。
8. 典型并发场景(用例帮助理解)
场景 A:一个事务在读,另一个事务在更新
- T1 开始读(生成 Read View)
- T2 更新同一行并提交
- T1 继续读:
- RR:T1 仍看旧值(因为 Read View 不变)
- RC:T1 下一次读可能看新值(因为 Read View 会更新)
场景 B:长事务导致 undo 爆炸
- T1 开启事务很久不提交
- T2 一直更新产生大量新版本/undo
- purge 无法删除旧版本(因为 T1 的 Read View 仍可能需要)
- 结果:undo 表空间变大、查询回溯更慢,系统性能下降
9. MVCC 与锁的关系:不是"完全无锁"
很多人以为 MVCC 就是"读不加锁",这只对一部分情况成立。
- 纯 SELECT 通常是通过 MVCC 读历史版本,不需要加锁(具体取决于隔离级别、SQL 类型)
- SELECT ... FOR UPDATE / LOCK IN SHARE MODE:需要加锁(用于阻止并发修改/保证一致性)
- UPDATE/DELETE:为了保证写正确性,会加行锁/索引锁
- 范围条件(尤其是可重复读 + 相关查询模式)还会涉及 next-key lock / gap lock 等
所以:
MVCC 是"让普通读使用一致性快照",而不是"消灭所有锁"。
10. 性能与注意事项(非常重要)
10.1 undo 链过长导致查询变慢
如果一行被频繁更新,读时可能回溯多次 undo 才找到可见版本。
10.2 长事务拖累 purge
这是最常见的生产问题之一:
- 大事务/游标/批处理不提交
- 事务里包含长时间等待(例如人为 sleep、外部调用)
- 读事务一直不结束
建议:
- 控制事务大小和持续时间
- 避免长时间保持事务打开
- 适当拆分批量操作
10.3 UPDATE 修改索引列会额外成本
虽然与 MVCC 机制本身无直接冲突,但更新导致索引变化会导致更多页分裂/写入与锁竞争,从而放大整体成本。
11. 一句话总结(把逻辑记牢)
- 写:生成新版本,把旧值放到 undo
- 读(MVCC):根据 Read View 判断版本是否可见,不可见则通过 undo 回溯旧版本
- purge:清理所有事务都不可能再访问到的旧版本
- 隔离级别:决定 Read View 创建时机,从而决定"看见哪些提交结果"