目录
[一、为什么 TCC 需要额外的防御设计?](#一、为什么 TCC 需要额外的防御设计?)
[二、空回滚:对一次从未发生的 Try 执行 Cancel](#二、空回滚:对一次从未发生的 Try 执行 Cancel)
[2.1 它是怎么发生的](#2.1 它是怎么发生的)
[2.2 朴素实现为什么不够](#2.2 朴素实现为什么不够)
[2.3 解决方案:事务状态表](#2.3 解决方案:事务状态表)
[三、悬挂:Try 在 Cancel 之后才执行](#三、悬挂:Try 在 Cancel 之后才执行)
[3.1 悬挂比空回滚更危险](#3.1 悬挂比空回滚更危险)
[3.2 墓碑记录的双重作用](#3.2 墓碑记录的双重作用)
[3.3 深层根因:顺序的不可保证性](#3.3 深层根因:顺序的不可保证性)
[4.1 幂等性不是可选项,是必选项](#4.1 幂等性不是可选项,是必选项)
[4.2 三个接口的幂等性各有不同](#4.2 三个接口的幂等性各有不同)
[4.3 幂等的深层哲学:结果等价,而非操作相同](#4.3 幂等的深层哲学:结果等价,而非操作相同)
[6.1 状态表的查询是热点](#6.1 状态表的查询是热点)
[6.2 超时参数的设置是一门艺术](#6.2 超时参数的设置是一门艺术)
[6.3 框架能帮你多少?](#6.3 框架能帮你多少?)
[6.4 TCC 适合什么场景?](#6.4 TCC 适合什么场景?)
前言(以清晰的流程图辅助理解):
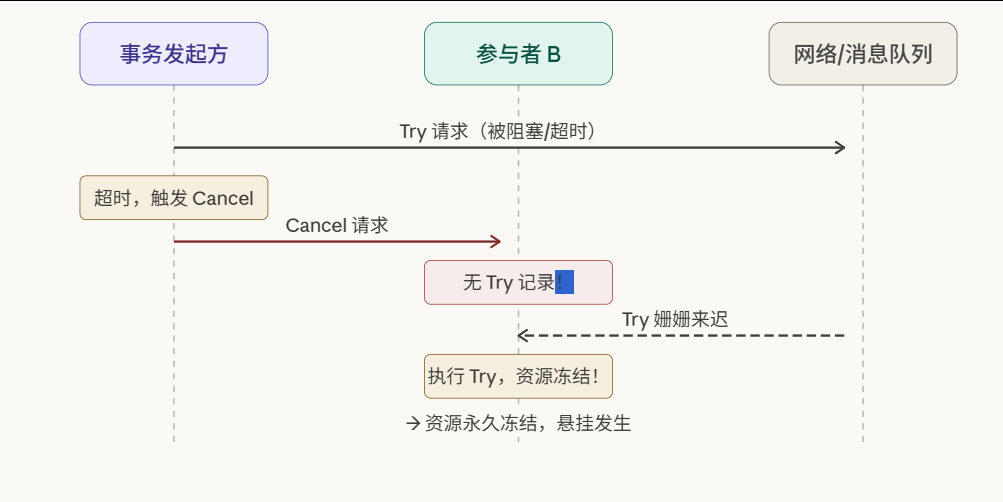
一、为什么 TCC 需要额外的防御设计?
在分布式系统里,"要么全成功,要么全回滚"是一句几乎所有工程师都认同的口号。TCC(Try-Confirm-Cancel)作为柔性事务的主流实现方案,用"预留资源 → 确认提交 → 释放回滚"三段式协议,换来了比 2PC 更好的性能和可用性。
但 TCC 并非银弹。它把事务的原子性责任,从数据库引擎转移给了应用层代码。这意味着:凡是 2PC 依赖锁和日志自动处理的边界情况,TCC 都必须由开发者亲自设防。
空回滚、悬挂、幂等,正是这三道最容易被忽视、一旦触发便难以排查的暗礁。
二、空回滚:对一次从未发生的 Try 执行 Cancel
2.1 它是怎么发生的
上图展示了空回滚的典型发生路径:Try 请求因为网络抖动、节点宕机或 GC 停顿,在到达参与者之前就"卡住了"。事务协调者(或发起方)等待超时后,认为事务失败,触发全局回滚,向各参与者发出 Cancel 请求。
此时参与者收到了 Cancel,但它根本没有执行过任何 Try------数据库里没有任何冻结记录,也没有任何中间状态。如果参与者的 Cancel 实现中直接写了"回滚预留资源"的逻辑,它要么抛出异常,要么操作一个不存在的数据行。
核心矛盾在于:协调者视角的"回滚",与参与者视角的"啥也没干"之间,存在一个无法对齐的认知差。
2.2 朴素实现为什么不够
最直觉的防御------"Cancel 时检查 Try 记录,如果不存在就报错"------会让问题更糟。Cancel 失败会导致协调者重试,而重试期间 Try 请求可能还在路上。这条路径会演变成第三个问题:悬挂。
正确的做法是空回滚必须成功返回,同时留下一个"已回滚但未 Try"的墓碑标记。这个墓碑的作用在第三节讲悬挂时会变得清晰。
2.3 解决方案:事务状态表
sql
CREATE TABLE tcc_transaction (
gid VARCHAR(64) PRIMARY KEY, -- 全局事务 ID
branch_id VARCHAR(64) NOT NULL, -- 分支事务 ID
status TINYINT NOT NULL, -- 0:初始 1:Try 2:Confirm 3:Cancel
created_at TIMESTAMP,
updated_at TIMESTAMP,
UNIQUE KEY uk_gid_branch (gid, branch_id)
);Cancel 逻辑变为:
java
public void cancel(String gid, String branchId) {
TccTransaction tx = txRepo.findByGidAndBranch(gid, branchId);
if (tx == null) {
// 空回滚:插入一条 status=CANCEL 的墓碑记录,然后直接返回成功
txRepo.insertTombstone(gid, branchId, Status.CANCEL);
return; // ← 关键:返回成功,不做任何业务回滚
}
if (tx.getStatus() == Status.CANCEL) {
return; // 幂等保护:已经回滚过了
}
// 正常回滚业务逻辑
doBusinessCancel(gid, branchId);
txRepo.updateStatus(gid, branchId, Status.CANCEL);
}三、悬挂:Try 在 Cancel 之后才执行

3.1 悬挂比空回滚更危险
空回滚是"对空气挥拳"------什么都没发生,但回滚成功了,系统保持一致。悬挂则是"无人认领的资源"------Try 成功执行,资产被冻结,但协调者已经不再关心这笔事务,后续的 Confirm 和 Cancel 永远不会来。
悬挂的危险在于它不会立刻报错。库存被扣减了,余额被预扣了,数据库里有一行状态为"预留中"的记录,但系统日志显示事务已经"回滚成功"。这种表面正常、实则异常的状态,在生产环境里可能安静地躺上几天,直到某次对账才被发现。
3.2 墓碑记录的双重作用
这里就体现了上一节留下墓碑的真正价值。Try 逻辑需要在执行前检查:这笔事务是否已经被 Cancel 过?
java
public void tryReserve(String gid, String branchId, long amount) {
TccTransaction tx = txRepo.findByGidAndBranch(gid, branchId);
if (tx != null && tx.getStatus() == Status.CANCEL) {
// 检测到悬挂:Cancel 先于 Try 到达,拒绝执行
// 直接返回,不预留任何资源
log.warn("Hanging detected: gid={}, branchId={}", gid, branchId);
return;
}
// 正常执行 Try
txRepo.insertTrying(gid, branchId);
doBusinessTry(amount);
}这里有一个微妙的并发问题:如果 Try 和 Cancel 几乎同时到达,在 Try 查询"无记录"之后、插入 Try 记录之前,Cancel 完成了墓碑写入------那么 Try 仍然会执行。解决方法是将"检查 + 插入 Try 记录"做成一个数据库事务,并用唯一索引保证:如果 Cancel 已写入墓碑(唯一键冲突),Try 的插入就会失败,从而阻止悬挂。
3.3 深层根因:顺序的不可保证性
空回滚和悬挂,本质上都是同一个根因的两个侧面------在异步、不可靠的网络中,消息的抵达顺序无法保证。TCC 协议假设 Try 先于 Cancel 到达,但这个假设在分布式系统里是不成立的。任何依赖消息顺序的协议,都必须在应用层自行实现顺序的"重建"或"防御"。
四、幂等:同一个请求执行多次,结果必须相同
4.1 幂等性不是可选项,是必选项
理解了空回滚和悬挂之后,我们来看第三个问题:幂等性(Idempotency)。
协调者(TM)在网络不确定性下,通常会对 Try、Confirm、Cancel 进行重试。原因很简单:它收不到响应,并不知道参与者是"没有收到请求"还是"执行成功了但回包丢了"。对协调者来说,两者都表现为超时,而它必须假设前者并重试,否则就无法保证最终一致性。
这意味着你的 Try、Confirm、Cancel 三个接口,天然就会收到重复调用。如果你的实现是非幂等的,每次重试都会导致:库存被扣多次、金额被扣双份、日志被写重复、消息被发两遍......
4.2 三个接口的幂等性各有不同
幂等性的实现不是一个通用公式,三个接口的业务语义不同,处理方式也不同。
Try 的幂等:Check-Then-Act 模式。先查询是否已存在 Try 记录,如果存在则直接返回成功,不再重复预留。关键是"查询和插入"必须是原子操作(通过数据库唯一键约束实现),防止并发重试导致双重预留。
Confirm 的幂等:这是最简单的一个。Confirm 是一个"最终提交"的动作,业务上通常表现为状态机的单向跳转(从"预留"变为"已确认")。重复 Confirm 只需要检查当前状态,如果已经是"已确认",直接返回成功即可。
Cancel 的幂等:上文已经处理了大部分情况(通过状态检查)。需要额外注意的是,当 Cancel 涉及资源的释放时(比如增加库存),要确保增加操作不会被执行两次------同样依赖状态检查和数据库事务保证。
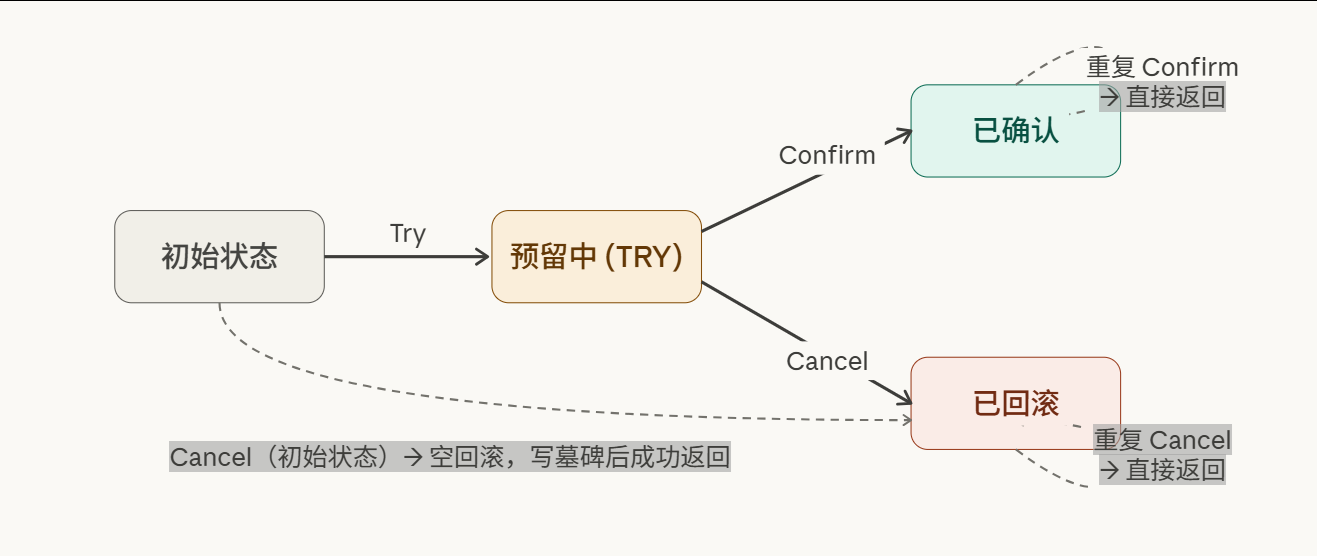
4.3 幂等的深层哲学:结果等价,而非操作相同
一个值得深思的细节:幂等的定义是"多次执行的结果 相同",而不是"多次执行的过程相同"。这意味着,第二次 Confirm 调用完全可以什么都不做,只要它返回的结果与第一次一致。
这个区分在涉及副作用时尤为重要。比如,一个 Confirm 接口还要发送一条"支付成功"的短信通知。如果你的幂等实现是"先发短信,再更新状态",那么第二次重试会发出第二条短信。正确的做法是先更新状态(用数据库唯一性保证),成功后再发送短信------这样第二次重试在数据库层面就被拦截了,用户只会收到一条短信。
副作用的幂等,比核心业务的幂等更难保证,也更容易被忽视。
五、三者的统一视角:一张防御表解决所有问题
回顾三个问题,会发现它们的解决方案高度收敛------都依赖同一张"分支事务状态表"。这不是巧合,而是因为三个问题都源于同一个根本挑战:在不可靠的分布式环境中,重建局部的因果顺序和执行状态。
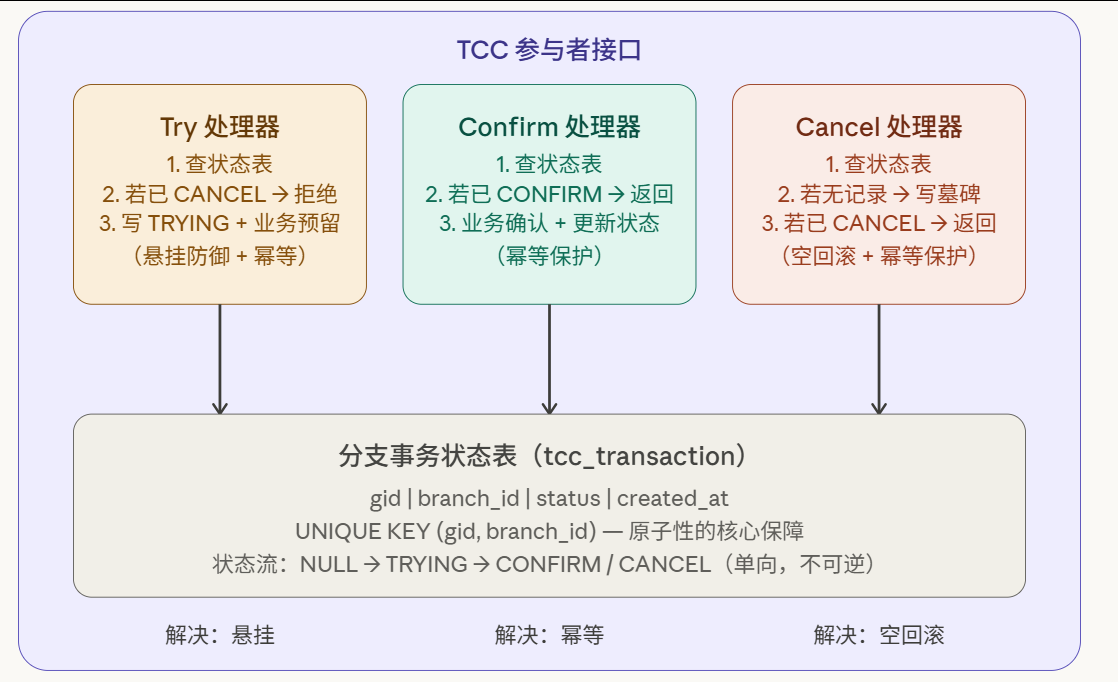
这张图揭示了一个优雅的设计原则:一张状态表,三重防线。每次 Try、Confirm、Cancel 的第一步,都是"先查状态表"。状态表是参与者的"记忆",也是整个防御体系的基础。
六、工程实践中的进阶思考
6.1 状态表的查询是热点
每个 TCC 接口调用都要先查这张表,在高并发场景下这张表极易成为性能瓶颈。工程上的应对策略包括:使用 Redis 做状态缓存(以最终一致性换性能)、按 gid 分库分表、以及利用数据库的覆盖索引优化查询。但引入缓存的同时也引入了缓存与数据库的一致性问题,需要谨慎权衡。
6.2 超时参数的设置是一门艺术
协调者的超时时间直接影响空回滚和悬挂的发生频率。设得太短,正常的慢请求会触发不必要的 Cancel;设得太长,异常事务占用资源的时间就更久。业界通常的做法是:Cancel 超时 > Try 超时 > 单次网络往返的 P99 延迟,同时结合服务的 SLA 要求来调整。
6.3 框架能帮你多少?
主流的分布式事务框架(如 Seata)会帮你处理大部分通用逻辑:状态表的创建和管理、重试逻辑、超时检测。但有一点框架无法替代:你的业务代码必须自己保证 Try/Confirm/Cancel 的语义正确性------预留是否正确、释放是否完整、副作用是否可控,这些都是领域逻辑,框架触及不到。
6.4 TCC 适合什么场景?
最后值得反思的是:TCC 的高开发成本是否值得?答案取决于业务对一致性的要求程度和对性能的敏感程度。对于资金、库存等强一致性场景,TCC 的防御设计虽然复杂,但是必要的投入。对于日志记录、通知推送等允许最终一致的场景,基于消息的柔性事务(Saga 或本地消息表)往往是更轻量的选择。
七、结语
空回滚、悬挂、幂等,听起来是三个独立的问题,本质上都是同一个问题的不同呈现:在无法保证顺序和可靠性的网络中,如何让分布式事务的参与者做出正确的决策。
解法的精髓在于:用持久化的状态记录来替代对消息顺序的假设。只要参与者在做任何决策之前,都先查询"自己曾经做过什么",这三个问题就都有了确定性的答案。
这种"先查状态、再做决定、最后更新状态"的范式,不仅仅适用于 TCC,它是分布式系统中处理不确定性的一个普遍模式------在幂等性服务、消息去重、分布式锁等场景中,你会一遍又一遍地看到它的影子。
理解了这一点,你对分布式事务的认知就不只是"会用框架",而是真正理解了它在与什么样的困难作战。