系列前言
当我们谈论 AI Agent 时,我们到底在说什么?当我们真正开始开发 AI Agent 时,又应该从哪里开始?
网上关于 Agent 的文章越来越多,但其中相当一部分要么缺乏系统性,要么直接从框架教程开始。我们跟着教程复制代码,很快就能跑起一个 Demo,却很难真正理解:代码为什么能工作?Agent 的能力到底从何而来?
本系列文章希望做一件不同的事情:
从 LLM 的基础原理出发,一步步搞清楚 Agent 的能力是如何建立起来的。
在这个过程中,我们一边理解这些原理,以便动手实现一个可运行的 Agent,由浅入深,把抽象概念落地成真正的项目。
本系列主要面向对 Agent 开发还不熟悉,或者处于"似懂非懂"阶段的朋友。我们不会一开始就使用 LangChain等框架,因为这些框架封装了大量细节。如果完全不了解它们的底层机制,就很难把项目真正做的出色。当然我们的目标不是重复造轮子,而是:先理解轮子是怎么转的,再决定什么时候使用现成的轮子。
本篇主旨
读完这篇,你会清楚地知道:
- LLM 本质上是什么,它能做什么,不能做什么
- 认识 Token
- Temperature、Top-P、Top-K 这些参数在底层做了什么
- 什么是上下文
- 什么是系统提示词,它将如何演变
LLM 的本质
理解 Agent 之前,必须先把 LLM 的本质搞清楚。我们可能用了很久网页端或应用端的 ChatGPT、Claude,对他们表现出的能力赞叹不已,以至于我们自然的认为LLM 天生就是这么智能强大。首先要建立的观念就是LLM 远不是这么强大,它并不支持记忆,无法调用工具,更无法主动行动。它本身没有状态,每次调用都是独立推理。
在开发层面来看,LLM 的调用过程,归根结底就是一个函数。 我们向LLM提供指令输入(即Prompt),LLM返回响应结果。
scss
f(输入文本) → 响应TokenLLM本质上就是一个在海量文本上训练出来的、极其复杂的概率预测机器 。 给它一段文字,它会预测并挑选接下来最可能出现的词(Token),然后把这个词加到文字末尾,再预测下一个,如此循环,直到生成一个完整的回答。这就是所谓的自回归生成,当前主流LLM的结果生成方式。
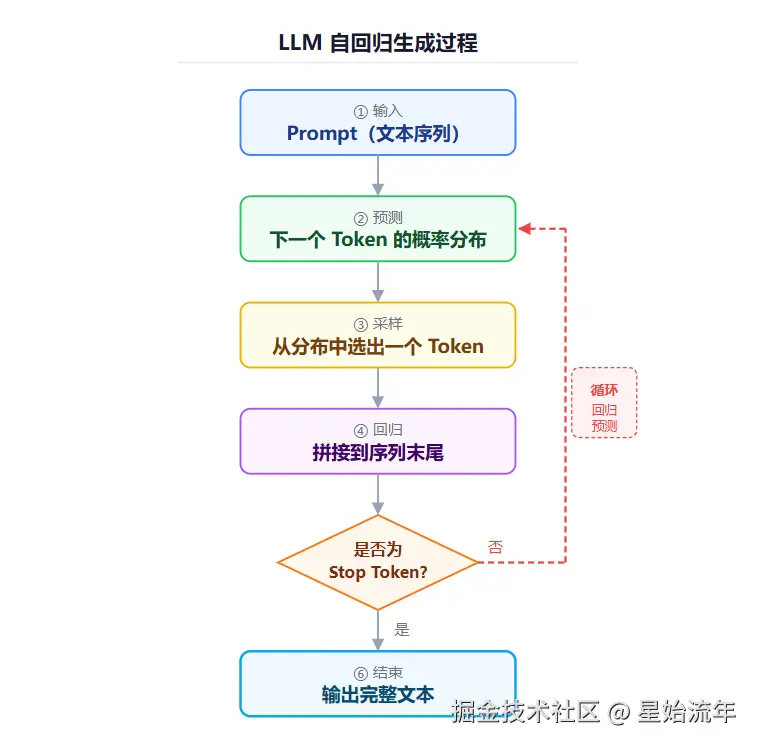
什么是Token
在使用LLM时,你一定会频繁遇到一个概念:Token 。模型处理文本的基本单位并不是字符,也不是单词,而是 Token 。Token 可以理解为一种 介于字符和单词之间的文本片段,它是模型进行计算、理解和生成文本时的最小处理单元。
在进行估算时,我们通常可以 粗略地把一个英文单词或一个汉字看作一个 Token 。但我们必须知道这并不完全准确,因为 Token 的划分方式取决于模型所使用的 分词算法(Tokenizer) 。
下面通过一个 Claude Token 计算器的例子来直观感受这一点: 

同样由 7 个中文字符组成的句子,其对应的 Token 数量并不一定是 7。甚至在只替换其中一个字(例如将"今"替换为"昨")的情况下,Token 数量也发生了变化。
此外,不同的大模型使用的 Tokenizer 并不相同,因此 同一段文本在不同模型中的 Token 数量也可能不同。
理解 Token 的概念非常重要,因为 大模型的很多核心机制都是围绕 Token 设计的:
- 计费单位:绝大多数 LLM API 的调用费用都是按照 Token 计算的。输入的 Token 数量和模型生成的 Token 数量,都会直接影响最终的调用成本。
- 上下文长度:模型能够一次处理的最大文本长度(Context Window)也是以 Token 为单位进行限制的。例如 128K Token 即代表模型接受的最大上下文长度为128K个Token,超出这个限制,模型就无法获得完整的信息。
- 处理速率:我们通常以模型每秒能吐出多少个 Token 来评估模型的生成速度。
选词的核心------------概率分布
我们之前就提到过,当 LLM 生成文本时,并不是一次性输出完整句子,而是 逐个 Token 生成 。他的本质是根据当前上下文,预测"下一个 Token 出现的概率分布"。在生成一个 Token 时,模型会对整个词表中的所有候选 Token 计算概率。例如,假设有如下句子:
csharp
The sky is ___模型可能得到如下概率分布的候选词:
erlang
"blue" → 28.36%
"cloudy" → 23.63%
"falling" → 18.90%
"a" → 13.50%
"an" → 10.80%
"green" → 3.38%
"42" → 1.35%
"xyz" → 0.06%
...(省略剩余词汇)那么问题来了,我们如何从这个概率分布中选出满足我们要求的 Token?
几个关键参数
以上提到的选出满足条件 Token的过程叫做采样。在调用LLM API 时,以下参数发挥了极其重要的作用。
Temperature
Temperature 在数学上是一个概率分布的缩放因子,它不会改变候选词的排序,但会改变 高概率词和低概率词之间的差距。我们继续以刚刚的候选词作为例子(假设只有数个候选词)。
Temperature = 1 :使用原始概率分布。此时概率分布如图示:
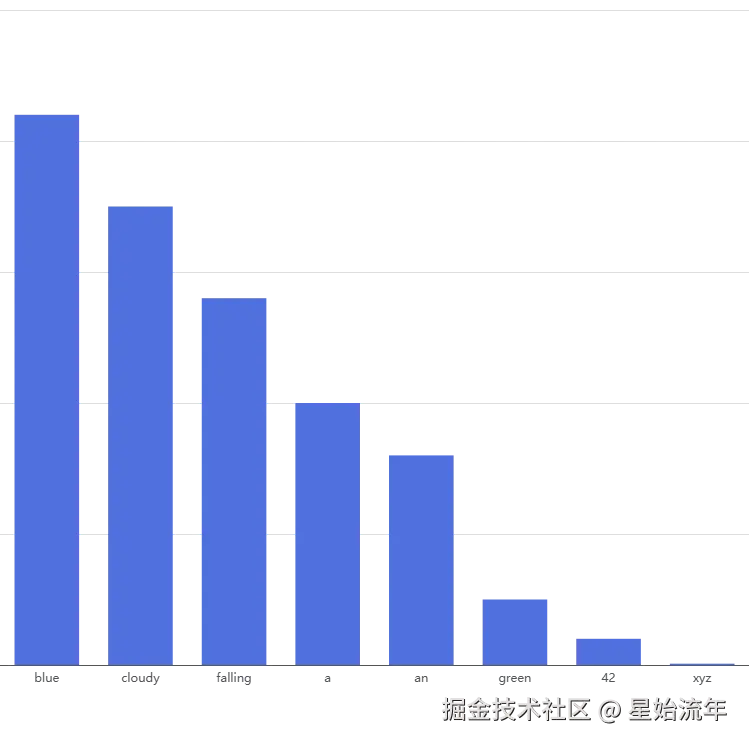
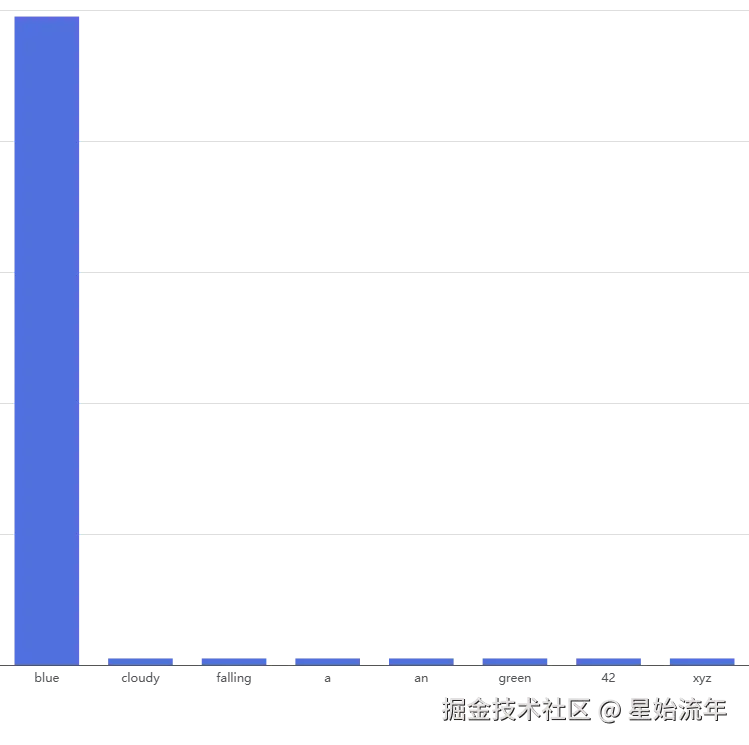
Temperature → 0(极低) :概率分布被「压尖」。最高概率的词会无限接近 100%,其他词趋近于 0。输出几乎完全确定,每次调用同一个 prompt 得到相同结果。
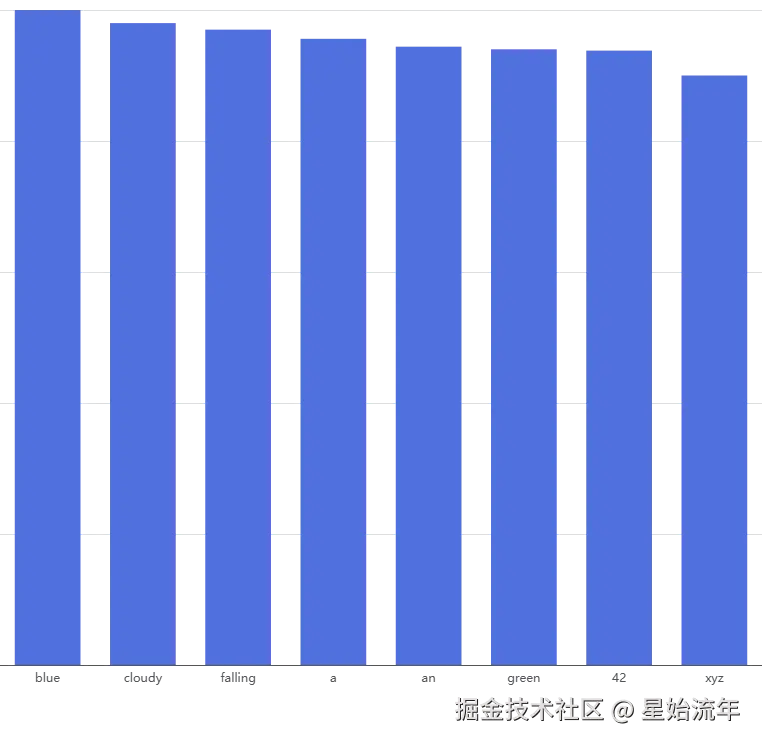
Temperature → 2(极高) :概率分布被「拉平」。所有词的概率趋于接近,此时生成的文本会更加 多样化,但也更容易出现不合理内容。
在实际开发中,针对同任务需要不同程度的确定性:
| 场景 | 推荐 Temperature | 原因 |
|---|---|---|
| 结构化输出(JSON) | 0 ~ 0.1 | 格式必须稳定精确 |
| 代码生成 | 0.1 ~ 0.3 | 逻辑正确优先 |
| 问答、摘要 | 0.3 ~ 0.7 | 准确性和自然度兼顾 |
| Agent 任务规划 | 0.2 ~ 0.5 | 需要一定创造力 |
| 头脑风暴、创意写作 | 0.7 ~ 1.2 | 鼓励多样化的想法 |
这些值也不是固定的,模型输出不理想时可以根据实际情况进行调整。还有就是不同模型支持的Temperature值范围也不一样,但它们都遵循同一条规则值越小输出越稳定,值越大输出越随机。
Top-P
Top-P 也叫 Nucleus Sampling (核采样),是另一种控制随机性的方式,但机制与 Temperature 不同。它的思路不是改变概率分布,而是 限制候选词的范围。
它的工作原理大致为:把所有词按概率从高到低排序,然后从最高概率开始累加,累计概率达到 p 值时,其后的词不再考虑,采样时只会在这些选中的"核"中进行。
继续刚才的例子,假设Top-P为0.9,按照累计概率,核中的候选词为"blue"/"cloudy"/"falling"/"a"/"an"。处理过程如下:
erlang
"blue" → 28.36% → 累计28.36%
"cloudy" → 23.63% → 累计51.99%
"falling" → 18.90% → 累计70.89%
"a" → 13.50% → 累计84.39%
"an" → 10.80% → 累计95.19% ⬅ 触发截断,之后的不再考虑
"green" → 3.38%
"42" → 1.35%
"xyz" → 0.06%
"..."有了Temperature之后,我们为什么还需要Top-P?首先要明确Temperature和Top-P是从两个不同的独立的角度去处理候选词的。在某些情况下,有时候概率分布本身就很"平",很多词概率接近。如果只用 Temperature,模型仍然可能选到一些 极低概率的奇怪词汇 。此时通过Top-P 截断长尾概率,可以有效避免这种情况。
在实践中一般建议,只调Temperature和Top-P中的其中一个,另一个保持默认。
Top-K
Top-K 是另一种直接粗暴的截断方式。每次生成时,只保留概率最高的 K 个词从中采样,完全忽略其他所有词。
例如当Top-K的值为3时,只会保留概率由高至低的前三个值"blue"/"cloudy"/"falling",无论其他词概率多少,一律排除。
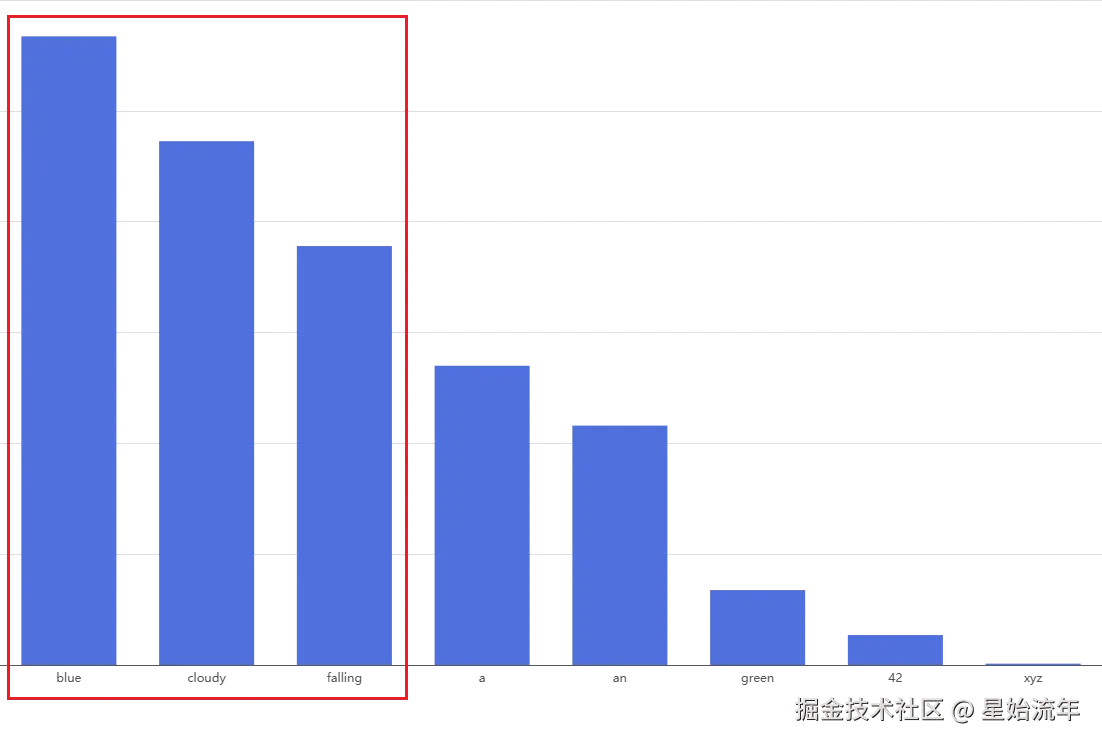
Top-K 使用 固定数量截断,但没有考虑概率分布的形状。可能出现两种情况,排序靠前的词概率很大时(比如第一个词的概率为98%),Top-K 过大时会引入大量无意义候选词;另一种分布很平的情况下,所有候选词概率差不多,此时 Top-K 若过小又会过早截断,排除很多合理选项。另外就是,并不是所有的模型都支持这个参数,Agent开发时请务必以api文档优先。
在我们调整参数时,一般应按照如下优先级进行调整Temperature → Top-P → Top-K。没有固定的参数搭配,一切从实践中出真知。
上下文窗口
理解 Token 之后,上下文窗口(Context Window,也被称为上下文长度) 就很好理解了。它指的是: 模型在一次推理过程中,最多能够处理的 Token 数量。
在大模型调用过程中,一个基础的上下文窗口通常由固定的开销(System Prompt)以及用户输入组成,在某些情况下,我们还会添加RAG等手段产出的额外信息,这些都会挤占上下文窗口。
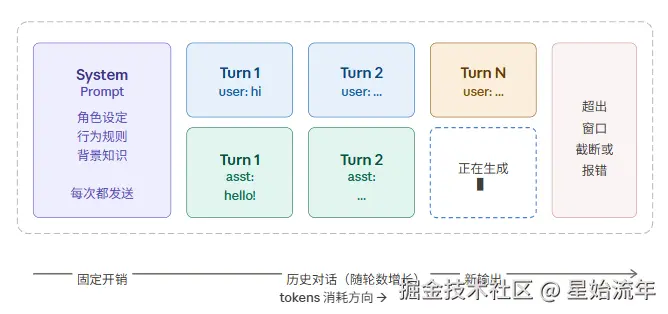
不同模型的上下文窗口亦不尽相同,但上下文窗口越来越大是目前大模型发展的一个趋势。比如早期的模型只支持128K的上下文长度,但时至今日,Claude Ops 4.6已支持1M上下文长度,Gemini更是有支持2M上下文长度的模型。不论上下文多大,目前来看,其都是一个有限的值,再大的上下文窗口都会触及其上限,因为我们说过LLM是无状态的,它本身不支持记忆功能。为了人为实现记忆功能,就需要将历史对话同时传递给大模型。
粗暴的将所有信息都填充到上下文中并不是一种好的方案 。过长的上下文会导致模型很难从其中捕捉到有效信息,从而使得性能降低。另一方面,不要忘了,长上下文代表着更多的Token,这也会导致成本暴增。如何在以上条件之间取得平衡,这就是 长对话管理(Long-context Management) 所要解决的问题。
系统提示词
时至今日,很多朋友仍然没有认识到如何写出一份有效的高质量的提示词,对于提提示词的理解,仍然停留在让大模型完成简单角色扮演的程度,比如:你是一个有帮助的 AI 助手,请尽可能回答用户的问题。 诚然,这个提示词会产生一定作用,但实际上很难充分发挥大模型的能力。
在 Agent 应用中,我们多数时候希望模型的行为更加稳定和可预测。这时就需要一份清晰的提示词,它应该是明确的、具体的、结构化的,一般来说可以由以下四个模块构成:
| 模块 | 作用 |
|---|---|
| 身份定义 | 模型扮演什么角色 |
| 行为规则 | 回答时必须遵守的原则 |
| 输出格式 | 结构化要求 |
| 边界限制 | 不允许做的事情 |
这并不代表一份好的提示词是复杂的,或者说越长越好,实践过程中我们需要从一份简短清晰的提示词开发,按照预期的输出对提示词进行评估,逐步地去迭代优化提示词,直至满足需求。在编写提示词时,也有一些技巧范式,比如:思维链(COT)、少样本(few-shot)等等 参考:[www.promptingguide.ai/zh](https://link.juejin.cn?target=https%3A%2F%2Fwww.promptingguide.ai%2Fzh "https://www.promptingguide.ai/zh") 。
不过随着模型能力的提升,其中一些技巧已经过时,比如现在主流模型本身就支持推理,再去编制思维链提示词反而会限制它的发挥。可以预见,未来关于 Prompt 设计 的"技巧工程"会进一步衰退,但Prompt仍然会有举足轻重的地位,其在"系统约束层面"的重要性会进一步上升。 System Prompt 的主要作用已经逐渐从"提示模型如何完成任务"转变为"定义模型应该遵循的行为协议"。这也正是我们之前提到的,当下设计 System Prompt 时,一般由身份定义、行为规则、输出格式以及边界限制四个模块构成的原因。在这种架构下,System Prompt 不再是唯一的输出控制手段,而成为了整个上下文系统中的一个组成部分。这也反映了当前的另一个趋势:提示词工程(Prompt Engineering) 正在被提示词工程(Context Engineering)所替代。
本篇结语
到这里,我们已经把 LLM 的一些关键基础概念梳理了一遍:Token、概率采样、上下文窗口以及 System Prompt。这些内容看起来零散,但实际上共同构成了 大模型工作的底层逻辑 。理解这些机制之后,我们就不再只是"调用一个会聊天的 API",而是开始真正理解 模型是如何生成结果的,以及我们可以如何影响它的行为。
不过,还是那句话,LLM 本身仍然只是一个 概率生成器 。Agent 的核心价值,正是在 LLM 之上构建一层能力系统,让模型能够 规划任务、调用工具,并在多轮交互中持续完成目标。
在下一篇中,我们将正式开始进入 Agent 的世界 :从零搭建一个最基础的 Agent 项目,实现 对话调用、多轮对话以及结构化输出,把前面理解的原理一步步落到真实代码之中。