缓存模拟
时间限制: 1.0 秒
空间限制: 512 MiB
相关文件: 题目目录
题目背景
西西艾弗岛半导体制造厂近期正在研发一种新型的处理器产品。该处理器的缓存,计划采用组相连 的方式。 为了选定合适的组相连参数,我们需要对缓存的工作过程进行模拟,进而推算其性能。
处理器的缓存 ,存储着内存 中的部分数据。当处理器的运行需要访问内存 中的数据时,如果所需数据已经存储在缓存 中,则可以用更为快捷的缓存 访问代替内存访问,来提高处理器性能。
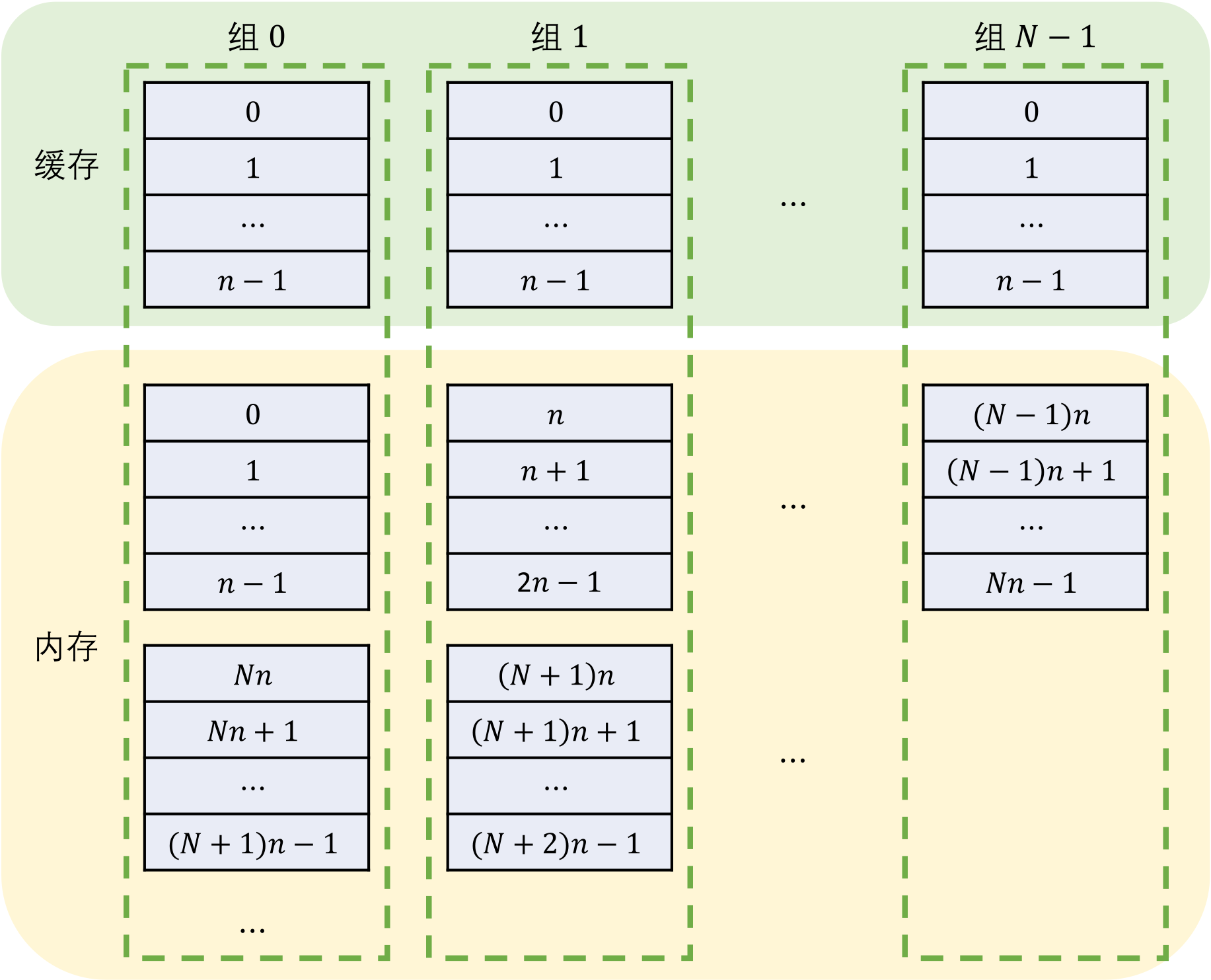
处理器的缓存包含若干缓存行 ,每个缓存行 存储特定大小的数据。为了便于叙述,我们认为处理器对内存的访问,也是以缓存行 为单位进行的。 以缓存行 的大小为单位,将全部内存空间划分为若干块(编号从 00 开始),这样每个内存块 的数据便可以恰好存储在一个缓存行中。
nn-路组相联 是这样的一种缓存结构:每 nn 个缓存行 划分为一组。假设共有 NN 个这样的组 (编号从 00 到 N−1N−1),那么编号为 kk 的内存块 仅可以被存储在编号为 (k÷n)(k÷n) 的组 这 nn 个缓存行 的任意一个中。其中,÷÷ 表示忽略余数的整除运算, 表示整除取余数运算。一般而言,nn 和 NN 是 22 的幂次。例如,当 n=4n=4、N=8N=8 时,编号为 0、1、2、3、32、33、34、35 的内存块 可以被存储在组 0 的任意缓存行 中;编号为 4、5、6、7、36、37、38、39 的内存块 可以被存储在组 1 的任意缓存行中。
题目描述
具体而言,给定要读取 或写入的内存块编号,即可确定该内存块可能位于的缓存行组的编号。此时,可能存在的情况有两种:
- 该缓存行组的某个缓存行已经存储了该内存块的数据,即命中;
- 该缓存行组的所有缓存行都没有存储该内存块的数据,即未命中。
当发生命中 时,处理器可以直接使用或修改该缓存行中的数据,而不需要实际读写内存。 当发生未命中 时,处理器需要从内存中读取数据 ,并将其存储到该缓存行组中的一个缓存行中,然后再使用或修改该缓存行中的数据。这个将内存中的数据读入到缓存的过程称为载入。
当执行载入 操作时,如果该缓存行组中有尚未存储数据的缓存行,那么将数据存储到其中一个尚未存储数据的缓存行中,并在缓存行中记录所存储的数据块的编号;否则,按照一定方法,选择该组中的一个缓存行,并将数据存储到其中,这一过程称为替换。
当发生替换 时,需要考虑被替换的缓存行是否发生过修改,即执行过写 操作。如果发生过修改,则需要先将缓存行中的数据写入内存中的对应位置;然后忽略该缓存行中的数据、将新读入的数据存入其中,并记录所存储数据块的编号。
在一个缓存行组中选择被替换的缓存行的方法有很多种,该种处理器采用的是最近最少使用(LRU)方法。该方法将一个缓存行组中存有数据的缓存行排成一队,每次读或写一个缓存行时,都将该缓存行移动到队列的最前端。当需要替换缓存行时,选择队列的最后一个缓存行(最久没被读写)进行替换。
本题目中,将给出一系列的处理器运行时遇到的对内存的读写指令,并假定初始时处理器的缓存为空。你需要根据上文描述的缓存工作过程,给出处理器对内存的实际读写操作序列。
输入格式
从标准输入读入数据。
输入的第一行包含空格分隔的三个整数 n,N,qn,N,q,分别表示组相联的路数 nn 和组数 NN,以及要处理的读写指令的数量 qq。
接下来 qq 行,每行包含空格分隔的两个整数 oo 和 aa。其中,oo 表示读写指令的类型,aa 表示要读写的内存块的编号。oo 为 00 或 11,分别表示读和写操作。
输出格式
输出到标准输出。
输出若干行,每行包含空格分隔的两个整数 o′o′ 和 a′a′,表示实际处理器对内存的读写操作。o′o′ 为 00 或 11,分别表示读和写操作;a′a′ 表示要读写的内存块的编号。
样例输入
4 8 8
0 0
0 1
1 2
0 1
1 0
0 32
1 33
0 34样例输出
0 0
0 1
0 2
0 32
1 2
0 33
0 34样例解释
该处理器的缓存为 4 路组相联,共有 8 组。初始时,处理器的缓存为空。共需要处理 8 条指令:
- 第 1 条指令为读取内存块 0,未命中,要实际读取内存块 0,并存储到组 0 的一个缓存行;
- 第 2 条指令为读取内存块 1,未命中,要实际读取内存块 1,并存储到组 0 的另一个缓存行;
- 第 3 条指令为写入内存块 2,未命中,要实际读取内存块 2,并存储到组 0 的第三个缓存行,然后根据指令在缓存中对其进行修改;
- 第 4 条指令为读取内存块 1,命中,直接从缓存中调取数据;
- 第 5 条指令为写入内存块 0,命中,直接修改缓存中的数据;
- 第 6 条指令为读取内存块 32,未命中,要实际读取内存块 32,并存储到组 0 的第四个缓存行;
- 第 7 条指令为写入内存块 33,未命中,此时组 0 中的 4 个缓存行都保存了数据:最近使用的是保存有内存块 32 的缓存行,其次是保存有内存块 0 的缓存行,然后是 1,最后是 2,因此选择替换保存有内存块 2 的缓存行。注意到该缓存行在执行第 3 条指令时被修改过,因此需要先将其写入内存,然后再读取内存块 33 的数据存储到该缓存行中;
- 第 8 条指令为读取内存块 34,未命中,此时组 0 中的 4 个缓存行都保存了数据,按照同样的办法,选择保存有内存块 1 的缓存行替换。注意到该缓存行未被修改过,因此可以直接读取内存块 34 的数据存储到该缓存行中。
子任务
对于 20% 的数据,有 n=1,N=1n=1,N=1;
对于 40% 的数据,有 n=1n=1;
另外 20% 的数据,有 N=1,q≤nN=1,q≤n;
对于 100% 的数据,有 1≤n,N,n×N≤655361≤n,N,n×N≤65536,且 n,Nn,N 为 2 的幂次;1≤q≤1051≤q≤105,0≤a<2300≤a<230。
cpp
#include<iostream>
#include<vector>
#include<unordered_map>
#include<list>
#include<cstring>
using namespace std;
#define dashu 100005
int n,N,q;//n cachesize; N cacheline amount; q amount of command
struct danyuan{
list<int>::iterator weizhi;//队列内部的迭代器,end()是无效的
int dirty;
//int bianhao;//对应的内存块编号
//int val;//模拟不需要考虑
};
struct custom_hash {
size_t operator()(int x) const {
x = ((x >> 16) ^ x) * 0x45d9f3b;
x = ((x >> 16) ^ x) * 0x45d9f3b;
x = (x >> 16) ^ x;
return (size_t)x;
}
};
struct cache_line{
list<int> que;
unordered_map<int,danyuan,custom_hash> xuhaozhi;
};
void out(cache_line &hang){
cout<<"list: ---------"<<endl;
for(auto it:hang.que){
cout<<it<<' ';
}cout<<endl;
cout<<"hash: ---------"<<endl;
for(auto it:hang.xuhaozhi){
int val=it.first;
cout<<val<<' ';
}cout<<endl;
cout<<endl;
}
//cache_line zuxianglian[dashu];
void read(int num){
printf("0 %d\n",num);
}
void write(int num){
printf("1 %d\n",num);
}
//输入序号,O(1)时间查到内存块是否在缓存行中
bool hit(int xuhao,cache_line &hang){
auto it=hang.xuhaozhi.find(xuhao);
if(it==hang.xuhaozhi.end()){
//cout<<xuhao<<"not in dict"<<endl;
return false;
}
//string res=(it->second.weizhi!=hang.que.end())?" hit":" not hit";
//cout<<xuhao<<res<<endl;
return (it->second.weizhi!=hang.que.end());
}
//通过哈希表找到list中相应的迭代器,保证list头插入该迭代器
void hitmod(int caozuo,int xuhao,cache_line &hang){
auto it=hang.xuhaozhi[xuhao].weizhi;
hang.que.splice(hang.que.begin(),hang.que,it);
if(hang.xuhaozhi[xuhao].dirty==0&&caozuo==1)
hang.xuhaozhi[xuhao].dirty=1;
}
void addnode(int caozuo,int xuhao,cache_line& hang){
read(xuhao);
hang.que.push_front(xuhao);
auto it=hang.que.begin();
hang.xuhaozhi[xuhao]={it,caozuo};
//cout<<xuhao<<' '<<&(*it)<<endl;
}
int LRUvic(cache_line& hang){
return *hang.que.rbegin();
}
void delmod(int victim){
write(victim);
}
//忽略缓存单元旧的值,把新的值放上去,顺便换到队首
void delnode(int caozuo,int xuhao,int victim,cache_line &hang){
read(xuhao);
auto it=hang.xuhaozhi[victim].weizhi;
*it=xuhao;
//链表把删除的节点替换到最前面
hang.que.splice(hang.que.begin(),hang.que,it);
//哈希表删除旧内存块索引,更新新的内存块索引
hang.xuhaozhi.erase(victim);
hang.xuhaozhi[xuhao]={it,caozuo};
}
void solve(int caozuo,int xuhao,cache_line &hang){
//cout<<caozuo<<' '<<xuhao<<endl;
if(hit(xuhao,hang)) {
hitmod(caozuo,xuhao,hang);
return;
}
//load
if((signed)hang.que.size()<n){
addnode(caozuo,xuhao,hang);
//cout<<"addnode "<<caozuo<<" " <<xuhao<<" "<<&(hang)<<endl;
return;
}
//replace
int victim=LRUvic(hang);//返回队尾的内存块编号
//未命中,满队列替换,写回绝对要考虑脏位
//队列里绝对没有这个内存块
danyuan vict=hang.xuhaozhi[victim];
if(vict.dirty){
delmod(victim);
}
delnode(caozuo,xuhao,victim,hang);
return;
}
int main(){
//freopen("1.in","r",stdin);
ios_base::sync_with_stdio(0); cin.tie(0);
scanf("%d %d %d",&n,&N,&q);
//试试模块化,一步步来
//初始化一下
vector<cache_line> zuxianglian(N);
for (int i = 0; i < N; i++) {
zuxianglian[i].xuhaozhi.reserve(n * 2); // 提前分配足够桶
zuxianglian[i].xuhaozhi.max_load_factor(0.25); // 降低负载率,减少碰撞
}
for(int i=1;i<=q;i++){
int caozuo,xuhao;//操作 序号
scanf("%d %d",&caozuo,&xuhao);
int formatxuhao=xuhao%(n*N);
int gn=formatxuhao/n;
auto &hang=zuxianglian[gn];
//cout<<"start----- "<<caozuo<<' '<<xuhao<<endl;
solve(caozuo,xuhao,hang);
//out(hang);
//cout<<caozuo<<' '<<xuhao<<' '<<gn<<endl;
}
return 0;
}非常奇怪,不使用哈希表是90分,用了哈希表也是90,红黑树也是90,Claude生成了双向链表和手搓哈希表,加快读都没过,非常奇怪,不知道性能瓶颈在哪里。也构造了新的哈希函数避免哈希被卡。太奇怪了,百思不得其解