目录
题目
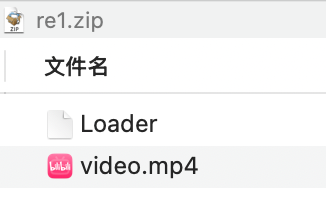
Loader ida分析
发现是打包的python源码,通过python3、ffmpeg等进行处理
逻辑如下:
1. 检查 video.mp4 文件是否存在
2. 解码嵌入的 Base64 数据 → 生成 stager.pyc
3. 设置执行权限 (chmod 0x1ED = 0755)
4. 通过 python3 stager.pyc 执行 Python 脚本提取中间的base64解码得到pyc文件
Qg0NCgAAAABK5llpWgkAAOMAAAAAAAAAAAAAAAAFAAAAQAAAAHN6AAAAZABkAWwAbQFaAQEAZABkAmwCWgJkAGQCbANaA2QAZAJsBFoEZABkAmwFWgZkAGQCbAdaB2QAZANsCG0IWggBAGQOZAlkCoQBWgllCmQLawJydmQMWgtlA2oMoA1lC6EBcmxlCWULgwEBAG4KZQSgDmQNoQEBAGQCUwApD+kAAAAAKQHaBUltYWdlTikB2gR0cWRt6YACAADp4AEAAOkIAAAA6QoAAAD6CXZpZGVvLm1wNGMGAAAAAAAAACAAAAALAAAAAwAAAHNwAgAAdABqAaACfAChAXMQZABTAHQAagGgA3wAoQF9BmQBfQd0BHwAZAKDAo9QiQB4SHQFdAaHAGYBZANkBIQIZAWDAnQHoAh8BmQGGwChAWQHZAhkCY0ERABdHH0IfAdkAaAJZApkC4QAfAhEAIMBoQE3AH0HcVZXAFcAZABRAFIAWABkDH0JZAF9CnhmdApkDXQLfAeDAWQOgwNEAF1SfQt8B3wLfAtkDhcAhQIZAH0IdAt8CIMBZA5rAnLkdAx8CGQPgwJ9DHQMfAlkD4MCfQ18DHwNQQB9DnwKfA5kEJsENwB9CnGafAp8CDcAfQpxmlcAfAp9B3wBfAMaAHwCfAMaABQAfQ90B6AIdAt8B4MBfA8bAKEBfRBnAH0RkAF4EHQFdAp8EIMBZBFkEo0CRABd/H0LfAt8DxQAfRJ8B3wSfBJ8DxcAhQIZAH0TdAt8E4MBfA9rAJABcmx8E2QTfA90C3wTgwEYABQAFwB9E3QNag5kFHwBfAJmAmQVZBaNA30UeJZ0CnwCfAMaAIMBRABdhn0VfBV8AXwDGgAUAH0WfBVkFxcAfAF8AxoAFAB9F3wTfBZ8F4UCGQB9GHhWdA98GIMBRABdSlwCfRl9GnwaZBhrApABctpkGW4CZBp9G3wZfAMUAHwVfAMUAAIAfRx9HXwUoBB8G3wcfB18HHwDFwB8HXwDFwBmBKECAQCQAXHEVwCQAXGOVwB8EaARdBKgE3wUoQGhAQEAkAFxLlcAdBRqFXwFfARkG2QcjQOPKH0eeCB0BXwRZB1kEo0CRABdEH0ffB6gFnwfoQEBAJACcU5XAFcAZABRAFIAWABkAFMAKR5O2gDaAnJiYwAAAAAAAAAAAAAAAAMAAAATAAAAcwoAAACIAKAAZAGhAVMAKQJOaQAEAAApAdoEcmVhZKkAKQHaAWZyDAAAAPodUGF5bG9hZF9Ub19QaXhlbENvZGVfdmlkZW8ucHnaCDxsYW1iZGE+EAAAAPMAAAAAeh9maWxlX3RvX3ZpZGVvLjxsb2NhbHM+LjxsYW1iZGE+chAAAABpAAQAAFoCS0J1DAAAAOivu+WPluaWh+S7tikE2ghpdGVyYWJsZVoFdG90YWxaBHVuaXTaBGRlc2NjAQAAAAAAAAACAAAAAwAAAHMAAABzFgAAAHwAXQ59AXwBZACbBFYAAQBxAmQBUwApAtoDMDhiTnIMAAAAKQLaAi4wWgRieXRlcgwAAAByDAAAAHIOAAAA+gk8Z2VuZXhwcj4TAAAAcwIAAAAEAHogZmlsZV90b192aWRlby48bG9jYWxzPi48Z2VuZXhwcj5aCDEwMTAxMDEwcgEAAAByBgAAAOkCAAAAchMAAAB1DwAAAOeUn+aIkOinhumikeW4pykBchIAAADaATBaA1JHQloFd2hpdGUpAdoFY29sb3LpAQAAANoBMSkDcgEAAAByAQAAAHIBAAAAKQPp/wAAAHIbAAAAchsAAABaB2xpYngyNjQpAtoDZnBz2gVjb2RlY3UPAAAA5YaZ5YWl6KeG6aKR5binKRfaAm9z2gRwYXRo2gZpc2ZpbGXaB2dldHNpemXaBG9wZW5yAwAAANoEaXRlctoEbWF0aFoEY2VpbNoEam9pbtoFcmFuZ2XaA2xlbtoDaW50cgIAAADaA25ld9oJZW51bWVyYXRlWgVwYXN0ZdoGYXBwZW5k2gJucFoFYXJyYXnaB2ltYWdlaW9aCmdldF93cml0ZXJaC2FwcGVuZF9kYXRhKSBaCmlucHV0X2ZpbGXaBXdpZHRoWgZoZWlnaHRaCnBpeGVsX3NpemVyHAAAANoLb3V0cHV0X2ZpbGVaCWZpbGVfc2l6ZVoNYmluYXJ5X3N0cmluZ9oFY2h1bmtaB3hvcl9rZXlaEXhvcl9iaW5hcnlfc3RyaW5n2gFpWgljaHVua19pbnRaB2tleV9pbnRaCnhvcl9yZXN1bHRaEHBpeGVsc19wZXJfaW1hZ2VaCm51bV9pbWFnZXNaBmZyYW1lc9oFc3RhcnTaBGJpdHNaA2ltZ9oBcloJcm93X3N0YXJ0Wgdyb3dfZW5k2gNyb3faAWPaA2JpdHIYAAAAWgJ4MVoCeTHaBndyaXRlctoFZnJhbWVyDAAAACkBcg0AAAByDgAAANoNZmlsZV90b192aWRlbwgAAABzUgAAAAABDAEEAgwCBAEMARQBDgEMASYCBAEEARYBEAEMAQoBCgEIAQ4CDAIEAhABEgIEAhgBCAEQAQ4BFAIUAhIBDAEQAQwCEgESARIBKAIWAhIBEgFyOgAAANoIX19tYWluX19aB3BheWxvYWRyGQAAACkFcgQAAAByBQAAAHIGAAAAcgcAAAByCAAAACkPWgNQSUxyAgAAAHIkAAAAch4AAADaA3N5c1oFbnVtcHlyLAAAAHItAAAAcgMAAAByOgAAANoIX19uYW1lX19aCmlucHV0X3BhdGhyHwAAANoGZXhpc3Rz2gRleGl0cgwAAAByDAAAAHIMAAAAcg4AAADaCDxtb2R1bGU+AQAAAHMWAAAADAEQAQgBCAEIAQwCCjgIAQQBDAEKAg==通过uncompyle6反编译得到源码:
uncompyle6 /Users/y5neko/draft/ctf222/stager.pyc
python
# uncompyle6 version 3.9.3
# Python bytecode version base 3.7.0 (3394)
# Decompiled from: Python 3.13.9 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 19:11:29) [Clang 20.1.8 ]
# Embedded file name: Payload_To_PixelCode_video.py
# Compiled at: 2026-01-04 12:02:18
# Size of source mod 2**32: 2394 bytes
from PIL import Image
import math, os, sys, numpy as np, imageio
from tqdm import tqdm
def file_to_video(input_file, width=640, height=480, pixel_size=8, fps=10, output_file='video.mp4'):
if not os.path.isfile(input_file):
return
file_size = os.path.getsize(input_file)
binary_string = ""
with open(input_file, "rb") as f:
for chunk in tqdm(iterable=(iter((lambda: f.read(1024)), b'')),
total=(math.ceil(file_size / 1024)), unit="KB", desc="读取文件"):
binary_string += "".join(((f"{byte:08b}") for byte in chunk))
xor_key = "10101010"
xor_binary_string = ""
for i in range(0, len(binary_string), 8):
chunk = binary_string[i[:i + 8]]
if len(chunk) == 8:
chunk_int = int(chunk, 2)
key_int = int(xor_key, 2)
xor_result = chunk_int ^ key_int
xor_binary_string += f"{xor_result:08b}"
else:
xor_binary_string += chunk
binary_string = xor_binary_string
pixels_per_image = width // pixel_size * (height // pixel_size)
num_images = math.ceil(len(binary_string) / pixels_per_image)
frames = []
for i in tqdm((range(num_images)), desc="生成视频帧"):
start = i * pixels_per_image
bits = binary_string[start[:start + pixels_per_image]]
if len(bits) < pixels_per_image:
bits = bits + "0" * (pixels_per_image - len(bits))
img = Image.new("RGB", (width, height), color="white")
for r in range(height // pixel_size):
row_start = r * (width // pixel_size)
row_end = (r + 1) * (width // pixel_size)
row = bits[row_start[:row_end]]
for c, bit in enumerate(row):
color = (0, 0, 0) if bit == "1" else (255, 255, 255)
x1, y1 = c * pixel_size, r * pixel_size
img.paste(color, (x1, y1, x1 + pixel_size, y1 + pixel_size))
frames.append(np.array(img))
with imageio.get_writer(output_file, fps=fps, codec="libx264") as ffmpeg:
for frame in tqdm(frames, desc="写入视频帧"):
writer.append_data(frame)
if __name__ == "__main__":
input_path = "payload"
if os.path.exists(input_path):
file_to_video(input_path)
else:
sys.exit(1)分析源码,逻辑如下:
1. 读取文件 → 转为二进制字符串 (每个字节 8 位)
2. XOR 加密 → 使用固定密钥 0xAA (二进制 10101010)
3. 像素映射 →
- 1 → 黑色像素 (0,0,0)
- 0 → 白色像素 (255,255,255)
4. 生成视频 → 640x480 分辨率,8x8 像素块,10fps直接编写脚本提取所有视频帧:
编写脚本解密:
python
#!/usr/bin/env python3
"""
视频隐写解码器
从 video.mp4 中提取隐藏的 payload
编码原理:
1. 文件按字节转为二进制字符串
2. 每 8 位用 XOR 密钥 0xAA 加密
3. 每位映射为 8x8 像素块(黑=1, 白=0)
4. 生成 640x480 视频帧
"""
from PIL import Image
import os
# 参数 (与编码器一致)
WIDTH, HEIGHT = 640, 480
PIXEL_SIZE = 8
XOR_KEY = 0xAA # 二进制 10101010
# 计算每帧的像素块数
blocks_per_row = WIDTH // PIXEL_SIZE # 80
blocks_per_col = HEIGHT // PIXEL_SIZE # 60
bits_per_frame = blocks_per_row * blocks_per_col # 4800 bits = 600 bytes
def extract_from_frames(frames_dir, output_file):
"""从帧图片中提取隐藏数据"""
binary_string = ""
frame_files = sorted([f for f in os.listdir(frames_dir) if f.endswith('.png')])
for frame_file in frame_files:
img = Image.open(os.path.join(frames_dir, frame_file))
pixels = img.load()
for row in range(blocks_per_col):
for col in range(blocks_per_row):
# 取每个块的左上角像素
x = col * PIXEL_SIZE
y = row * PIXEL_SIZE
r, g, b = pixels[x, y][:3]
# 判断黑白 (黑=1, 白=0)
if r < 128: # 黑色
binary_string += "1"
else: # 白色
binary_string += "0"
print(f"提取的二进制位数: {len(binary_string)}")
# XOR 解密
decrypted_binary = ""
for i in range(0, len(binary_string), 8):
chunk = binary_string[i:i+8]
if len(chunk) == 8:
byte_val = int(chunk, 2)
decrypted_byte = byte_val ^ XOR_KEY
decrypted_binary += f"{decrypted_byte:08b}"
else:
decrypted_binary += chunk
# 转换为字节
byte_data = bytearray()
for i in range(0, len(decrypted_binary), 8):
chunk = decrypted_binary[i:i+8]
if len(chunk) == 8:
byte_data.append(int(chunk, 2))
# 保存文件
with open(output_file, 'wb') as f:
f.write(byte_data)
print(f"解码完成! 输出: {output_file} ({len(byte_data)} bytes)")
return byte_data
def extract_from_video(video_path, output_file):
"""直接从视频文件提取隐藏数据"""
import imageio
frames_dir = '/tmp/video_frames'
os.makedirs(frames_dir, exist_ok=True)
# 提取帧
reader = imageio.get_reader(video_path, format='FFMPEG')
for i, frame in enumerate(reader):
imageio.imwrite(f'{frames_dir}/frame_{i:03d}.png', frame)
reader.close()
# 从帧提取数据
result = extract_from_frames(frames_dir, output_file)
# 清理临时文件
import shutil
shutil.rmtree(frames_dir)
return result
if __name__ == "__main__":
import sys
if len(sys.argv) < 3:
print("用法:")
print(f" {sys.argv[0]} <frames_dir> <output_file> # 从帧图片提取")
print(f" {sys.argv[0]} --video <video.mp4> <output_file> # 从视频提取")
print()
print("示例:")
print(f" {sys.argv[0]} ./frames extracted_payload")
print(f" {sys.argv[0]} --video video.mp4 extracted_payload")
sys.exit(1)
if sys.argv[1] == "--video":
extract_from_video(sys.argv[2], sys.argv[3])
else:
extract_from_frames(sys.argv[1], sys.argv[2])得到Linux可执行文件
ida反编译
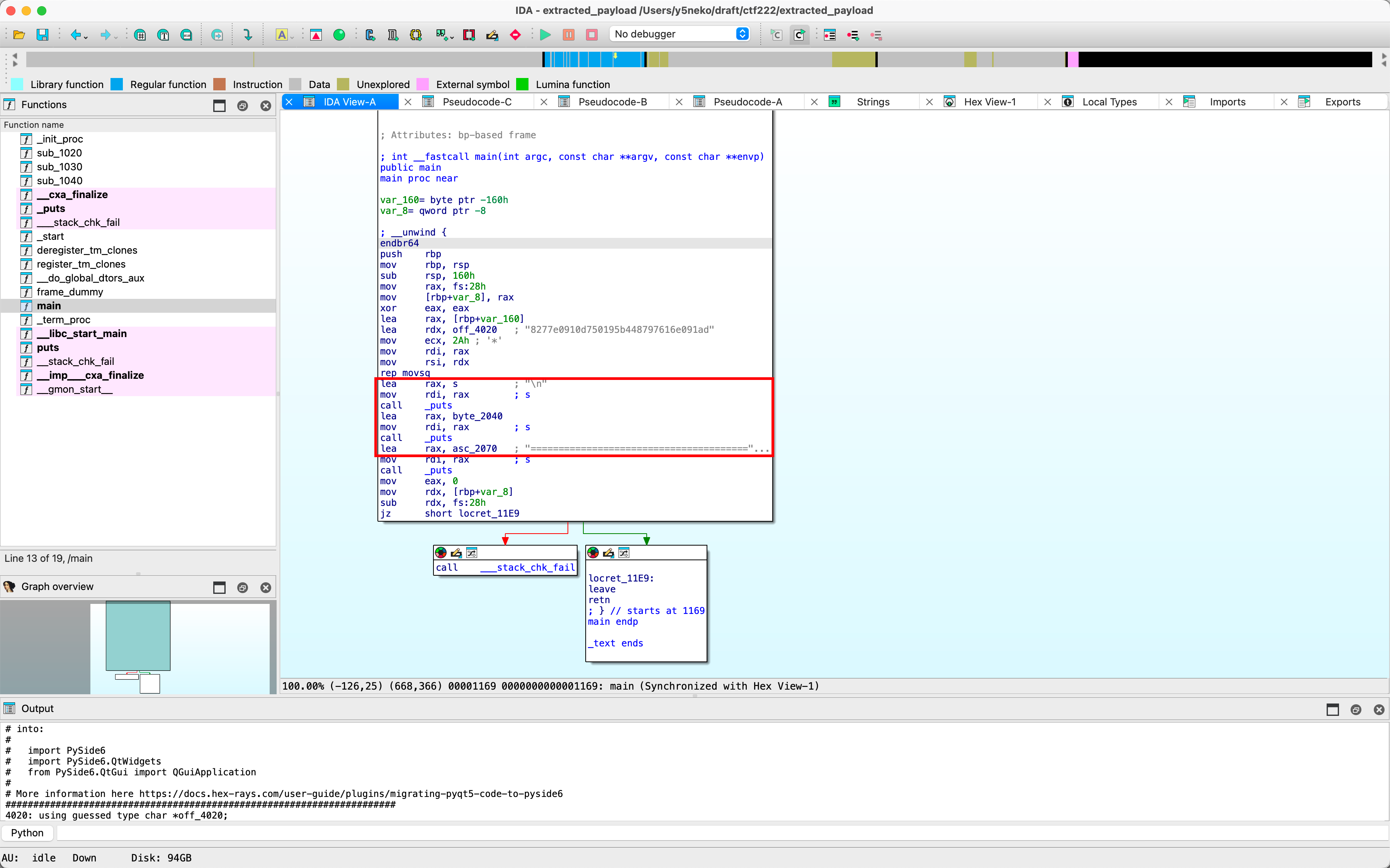
执行后输出了两句话
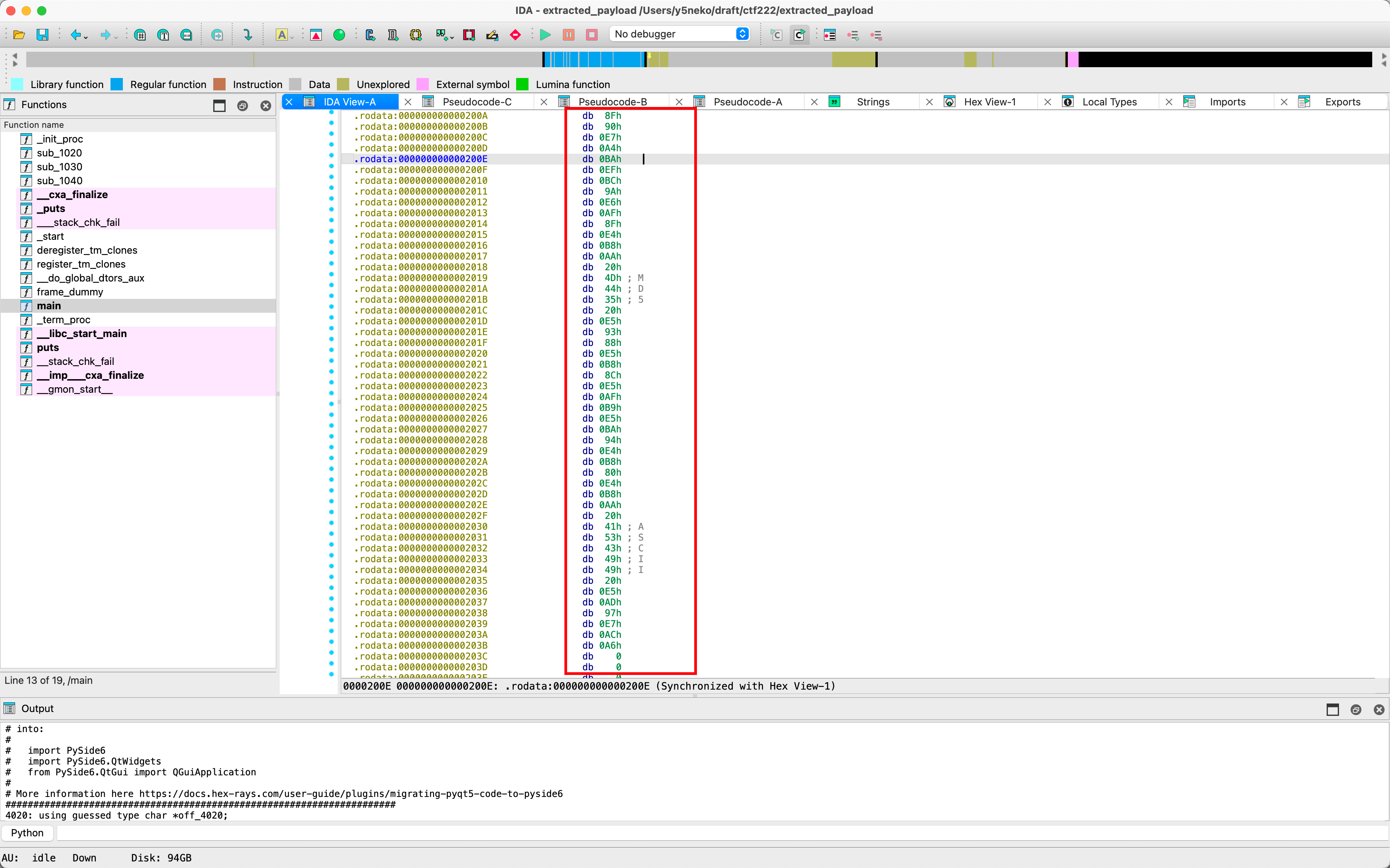
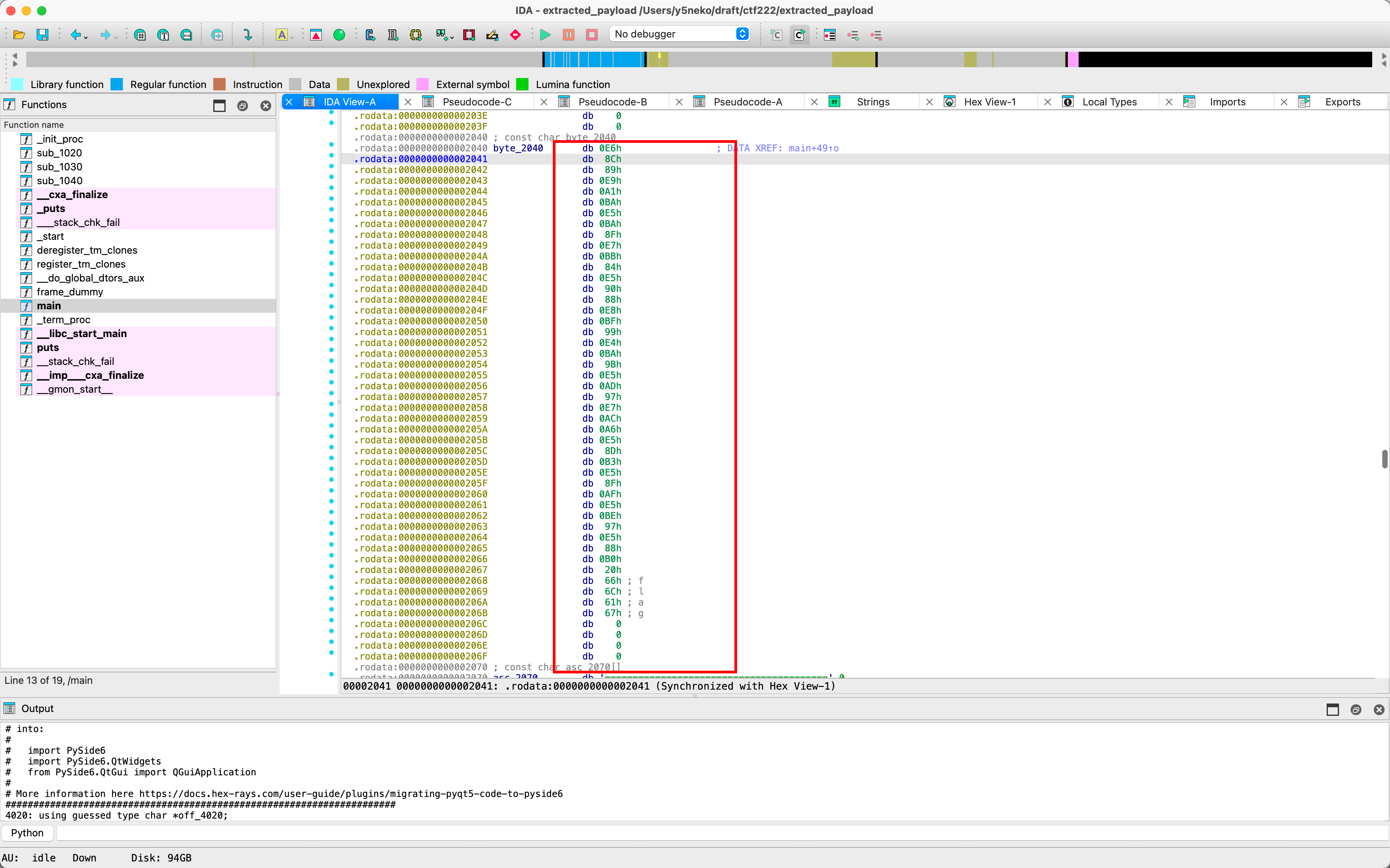
UTF8解码后得到提示:
提示:每个 MD5 哈希对应一个 ASCII 字符
按顺序组合这些字符即可得到 flag
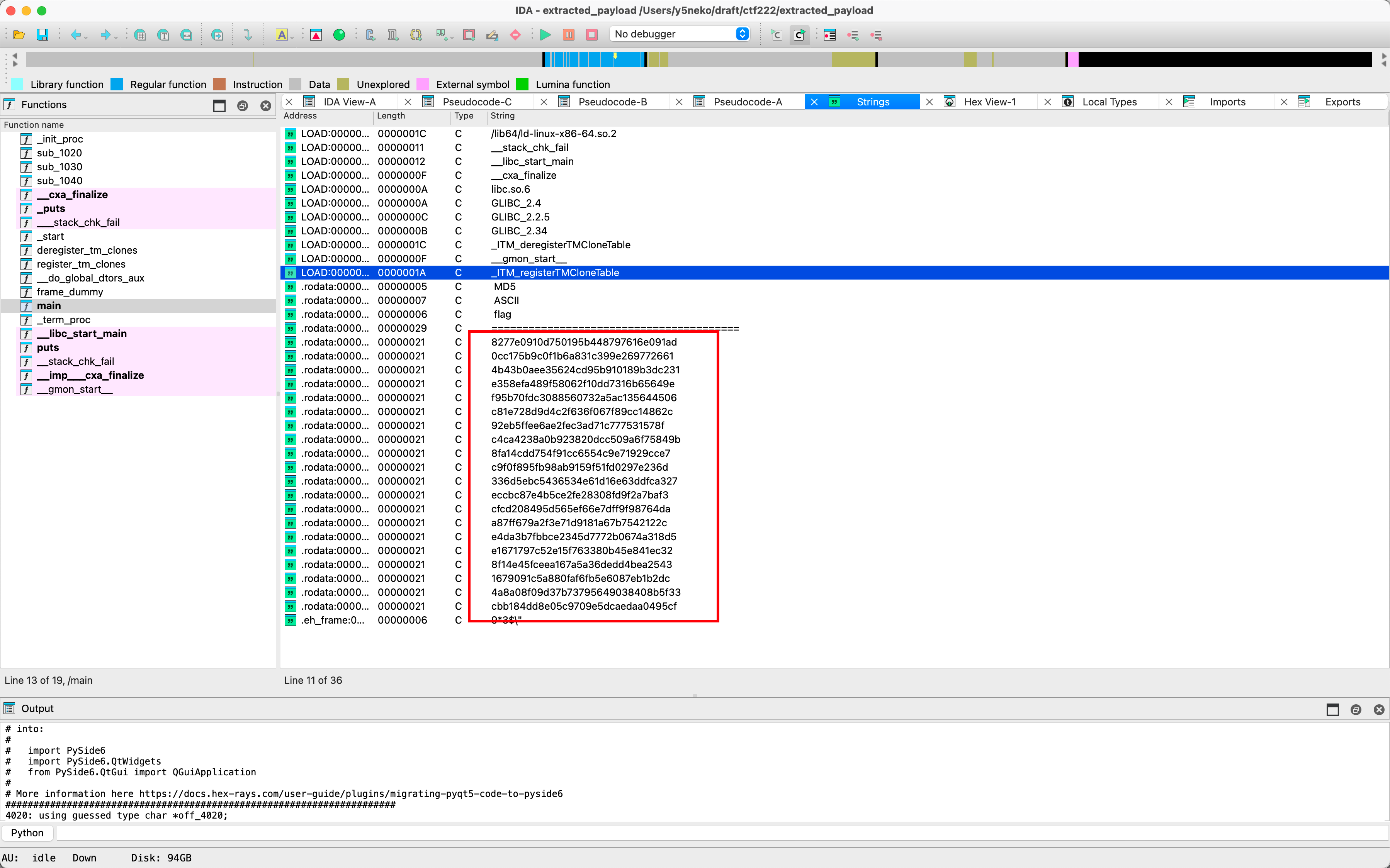
随后查找字符串发现了md5列表,编写脚本解密:
python
#!/usr/bin/env python3
"""
MD5 哈希解码器
通过预计算的 MD5 查找表解码 flag
原理:
- 每个 MD5 哈希对应一个 ASCII 字符
- 按顺序组合这些字符即可得到 flag
"""
import hashlib
def md5_char(c):
"""计算单个字符的 MD5"""
return hashlib.md5(c.encode()).hexdigest()
def build_lookup_table():
"""构建 MD5 -> 字符 的查找表"""
char_md5 = {}
# 可打印 ASCII 字符
for i in range(32, 127):
c = chr(i)
char_md5[md5_char(c)] = c
# 数字 0-9
for i in range(10):
c = str(i)
char_md5[md5_char(c)] = c
# 小写字母
for c in 'abcdefghijklmnopqrstuvwxyz':
char_md5[md5_char(c)] = c
# 大写字母
for c in 'ABCDEFGHIJKLMNOPQRSTUVWXYZ':
char_md5[md5_char(c)] = c
# 常见符号
for c in '{}_!@#$%^&*()-+=[]|;:,.<>?/~`':
char_md5[md5_char(c)] = c
return char_md5
def decode_md5_list(md5_list, lookup_table=None):
"""解码 MD5 列表"""
if lookup_table is None:
lookup_table = build_lookup_table()
result = []
unknown = []
for md5 in md5_list:
md5 = md5.lower().strip()
if md5 in lookup_table:
result.append(lookup_table[md5])
else:
result.append('?')
unknown.append(md5)
return ''.join(result), unknown
# 从 extracted_payload 中提取的 MD5 列表
MD5_LIST_FROM_PAYLOAD = [
"8277e0910d750195b448797616e091ad",
"0cc175b9c0f1b6a831c399e269772661",
"4b43b0aee35624cd95b910189b3dc231",
"e358efa489f58062f10dd7316b65649e",
"f95b70fdc3088560732a5ac135644506",
"c81e728d9d4c2f636f067f89cc14862c",
"92eb5ffee6ae2fec3ad71c777531578f",
"c4ca4238a0b923820dcc509a6f75849b",
"8fa14cdd754f91cc6554c9e71929cce7",
"c9f0f895fb98ab9159f51fd0297e236d",
"336d5ebc5436534e61d16e63ddfca327",
"eccbc87e4b5ce2fe28308fd9f2a7baf3",
"cfcd208495d565ef66e7dff9f98764da",
"a87ff679a2f3e71d9181a67b7542122c",
"e4da3b7fbbce2345d7772b0674a318d5",
"e1671797c52e15f763380b45e841ec32",
"8f14e45fceea167a5a36dedd4bea2543",
"1679091c5a880faf6fb5e6087eb1b2dc",
"4a8a08f09d37b73795649038408b5f33",
"cbb184dd8e05c9709e5dcaedaa0495cf",
]
def main():
import sys
# 检查是否有命令行参数(自定义 MD5 列表)
if len(sys.argv) > 1:
# 从文件读取 MD5 列表
if sys.argv[1].endswith('.txt'):
with open(sys.argv[1], 'r') as f:
md5_list = [line.strip() for line in f if line.strip()]
else:
# 从命令行参数读取
md5_list = sys.argv[1:]
else:
# 使用内置列表
md5_list = MD5_LIST_FROM_PAYLOAD
print("使用内置 MD5 列表 (从 extracted_payload 提取)")
print()
# 构建查找表
lookup_table = build_lookup_table()
# 解码
print("=" * 50)
print("MD5 解码结果:")
print("=" * 50)
for md5 in md5_list:
md5 = md5.lower().strip()
if md5 in lookup_table:
char = lookup_table[md5]
print(f"{md5} -> '{char}'")
else:
print(f"{md5} -> UNKNOWN")
# 输出 flag
flag, unknown = decode_md5_list(md5_list, lookup_table)
print()
print("=" * 50)
print(f"Flag: {flag}")
print("=" * 50)
if unknown:
print(f"\n未知 MD5 ({len(unknown)} 个):")
for u in unknown:
print(f" {u}")
if __name__ == "__main__":
main()FLAG
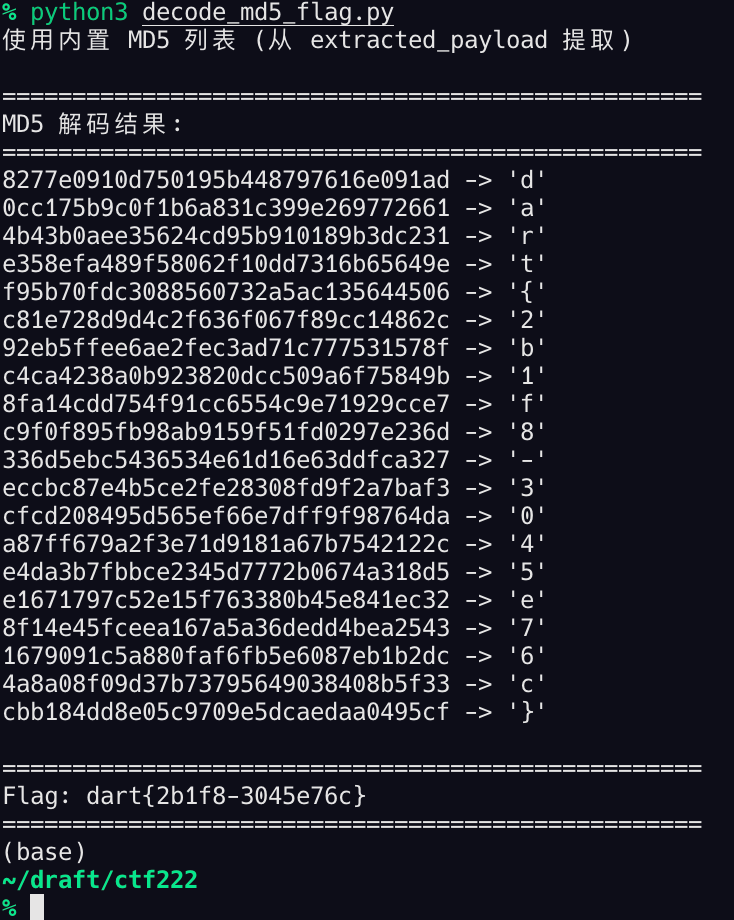
得到flag:dart{2b1f8-3045e76c}