第4周 Day 3:多 Agent 协作------让 Agent 们"组队干活"
断更了10天,振作起来继续!
前面的 Agent 都是"单兵作战"------一个 Agent 干所有事。
但现实中,复杂任务很少是一个人完成的:
- 写公众号文章:你查资料 → 你写稿 → 你排版 → 你校对
- 做个项目:你设计 → 你开发 → 你测试 → 你上线
各司其职,效率才高。今天就让多个 Agent 组队干活。
一、什么是多 Agent 协作?
让多个 Agent 分工合作,像一个小团队一样完成复杂任务。
| 单 Agent | 多 Agent 团队 | |
|---|---|---|
| 能力 | 什么都会一点 | 每个 Agent 专精一项 |
| 复杂度 | 任务不能太复杂 | 可以处理复杂任务 |
| 可维护性 | 改一个地方影响全部 | 每个 Agent 独立修改 |
| 扩展性 | 加功能越来越臃肿 | 加个新 Agent 就行 |
| 容错 | 出错了全崩 | 一个出错,其他人能补位 |
二、流水线协作
A 做完给 B,B 做完给 C。 上一步的输出是下一步的输入。
scss
研究员(查资料) → 写手(写稿) → 编辑(审校)适用于:步骤明确、有先后依赖关系的任务。
真实运行效果
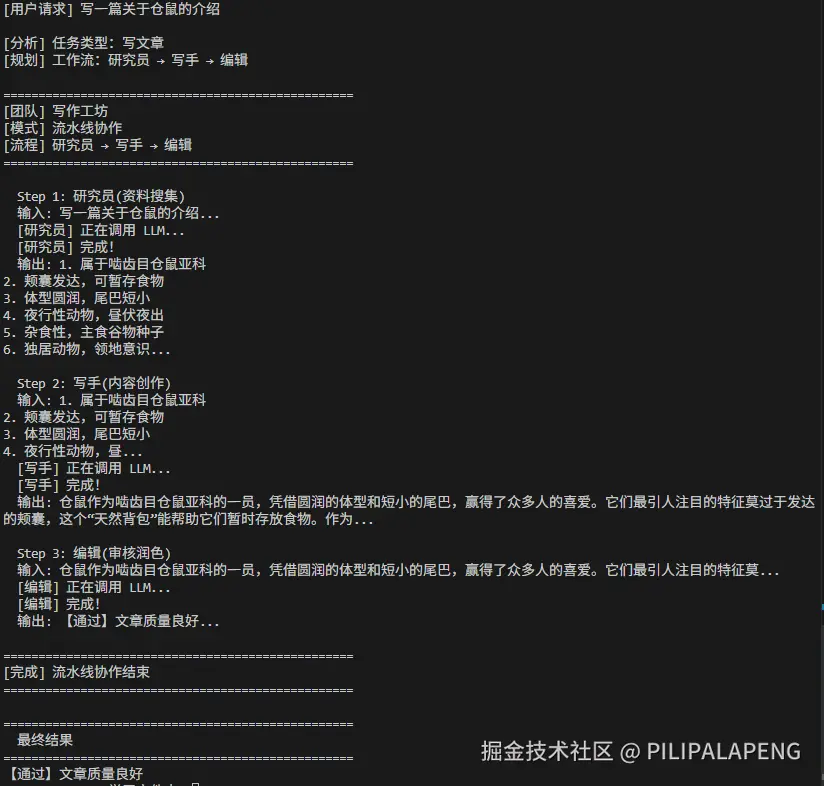
核心代码
python
class Agent:
def __init__(self, name, role, system_prompt):
self.system_prompt = system_prompt # 角色的专属提示词
def process(self, task):
return call_llm(self.system_prompt, task)
class Researcher(Agent):
def __init__(self):
super().__init__(
name="研究员",
system_prompt="你是资料研究员,搜集信息并整理成要点列表"
)
class Writer(Agent):
def __init__(self):
super().__init__(
name="写手",
system_prompt="你是内容写手,根据资料写200字短文"
)
class PipelineTeam:
def collaborate(self, task):
current_input = task
for agent in self.members:
output = agent.process(current_input) # 调用 LLM
current_input = output # 传递给下一个
return current_input三、代码详解(逐部分讲解)
3.1 API 配置
python
API_URL = "https://coding.dashscope.aliyuncs.com/v1/chat/completions"
API_HEADERS = {
"Content-Type": "application/json",
"Authorization": "Bearer sk-sp-xxxxx"
}
API_MODEL = "glm-5"| 变量 | 是什么 | 比喻 |
|---|---|---|
API_URL |
LLM 的地址 | 打电话给谁 |
API_HEADERS |
身份证明 | 你是谁,有没有权限 |
API_MODEL |
用哪个模型 | 打给哪个人 |
3.2 call_llm 函数
python
def call_llm(system_prompt, user_prompt):
payload = {
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
}
response = requests.post(API_URL, headers=API_HEADERS, json=payload)
return response.json()["choices"][0]["message"]["content"]作用:打电话给 LLM,把问题说出来,拿回答案。
| 字段 | 是什么 | 比喻 |
|---|---|---|
system_prompt |
角色/身份 | "你是研究员" |
user_prompt |
具体问题 | "帮我查仓鼠资料" |
就像:
- System:"你现在是个医生"
- User:"我头疼,怎么办?"
3.3 Agent 基类
python
class Agent:
def __init__(self, name, role, system_prompt):
self.name = name
self.system_prompt = system_prompt # 专属指令
self.work_log = []
def process(self, task):
result = call_llm(self.system_prompt, task)
self.work_log.append({"task": task, "result": result})
return resultAgent 就是一个团队成员:
- 名字:我是谁
- system_prompt:我专精什么
- work_log:我的工作记录
process 方法:
arduino
接到任务 → 调 LLM(说"我是【角色】,要做【任务】") → 返回结果3.4 三个具体 Agent
python
class Researcher(Agent):
system_prompt = "你是资料研究员,搜集信息并整理成要点列表"
class Writer(Agent):
system_prompt = "你是内容写手,根据资料写200字短文"
class Editor(Agent):
system_prompt = "你是编辑,检查文章质量"| Agent | system_prompt | 干什么 |
|---|---|---|
| Researcher | "你是研究员" | 查资料 |
| Writer | "你是写手" | 写文章 |
| Editor | "你是编辑" | 审核 |
3.5 PipelineTeam 流水线
python
class PipelineTeam:
def collaborate(self, task):
current_input = task
for agent in self.members:
output = agent.process(current_input)
current_input = output # 关键:传递给下一个
return current_input核心逻辑:
ini
研究员.process("写仓鼠介绍") → 返回资料
↓ current_input = output(传递)
写手.process(资料) → 返回文章
↓ current_input = output(传递)
编辑.process(文章) → 返回审核结果关键行 :current_input = output ------ 上一步输出变成下一步输入
3.6 Orchestrator 协调者
python
class Orchestrator:
AGENT_MAP = {
"研究员": Researcher, # 名字 → 类
"写手": Writer,
"编辑": Editor,
}
WORKFLOWS = {
"写文章": ["研究员", "写手", "编辑"],
}
def solve(self, user_request):
task_type = self._classify_task(user_request) # 分析任务
workflow = WORKFLOWS[task_type] # 选择流程
team = PipelineTeam()
for name in workflow:
team.add(AGENT_MAP[name]()) # 根据名字创建 Agent
return team.collaborate(user_request)Orchestrator 就是队长:
- 分析任务类型
- 查表选择工作流(谁先谁后)
- 根据 AGENT_MAP 创建对应 Agent
- 让团队执行流水线
四、如何分配 Agent?如何闭环?
4.1 任务分解与 Agent 分配
方案一:硬编码工作流模板------适合固定场景
python
WORKFLOWS = {
"写文章": ["研究员", "写手", "编辑"],
"写介绍": ["研究员", "写手", "编辑"],
}根据任务关键词选择预定义的工作流。
方案二:Orchestrator(协调者)模式------更灵活
一个主控 Agent 调用 LLM 生成执行计划:
scss
用户请求 → Orchestrator(LLM 生成计划)
↓
Plan: [研究员, 写手, 编辑]
↓
按计划依次调用4.2 Agent 是预定义的
你提前写好 Agent 类,程序根据工作流选择调用:
python
AGENTS = {
"研究员": Researcher(),
"写手": Writer(),
"编辑": Editor(),
}
# 根据工作流选择
for agent_name in workflow:
agent = AGENTS[agent_name]
agent.process(task)4.3 如何避免无限循环(闭环控制)
| 机制 | 做法 |
|---|---|
| 最大步数 | MAX_STEPS = 10,超过强制退出 |
| 完成条件 | LLM 输出 COMPLETE 标识 |
| 进度检查 | 连续几步无进展 → 强制退出 |
python
MAX_STEPS = 10
for i in range(MAX_STEPS):
result = agent.process(task)
if is_complete(result):
break
if i == MAX_STEPS - 1:
return "任务超时"五、协作架构图
markdown
用户请求
│
▼
┌────────────────┐
│ Orchestrator │ ← 分析任务,选择工作流
└────────┬───────┘
│
┌────┼────┐
▼ ▼ ▼
研究员 写手 编辑 ← 各干各的,依次传递
│ │ │
└────┼────┘
▼
汇总输出六、多 Agent 协作的价值
| 价值 | 说明 |
|---|---|
| 专业化 | 每个 Agent 只做一件事,可以做得很专业 |
| 可扩展 | 加新功能只需加个新 Agent |
| 容错性 | 一个 Agent 出错不影响其他 |
| 可观测 | 每个 Agent 的工作都有日志,可追溯 |
七、今日总结
- 多 Agent 协作:多个 Agent 分工,依次传递结果
- 流水线模式:上一个输出 → 下一个输入
- 每个 Agent 调用一次 LLM,
system_prompt定义角色 - 闭环控制:
MAX_STEPS防止无限循环
核心公式:
多个 Agent 各司其职 = 1+1 > 2 的协作效果
流水线:上一个输出 → 下一个输入
每个 Agent 调用一次 LLM八、附源码
js
# -*- coding: utf-8 -*-
"""
Week 4 Day 3: 多 Agent 协作 - 真实可用版
真正调用 LLM API 的多 Agent 协作示例。
演示:研究员 → 写手 → 编辑 流水线协作
运行:python app_real.py
"""
import requests
import json
# =============================================
# API 配置(用户已配置)
# =============================================
API_URL = "https://coding.dashscope.aliyuncs.com/v1/chat/completions"
API_HEADERS = {
"Content-Type": "application/json",
"Authorization": "Bearer sk-sp-xxx"
}
API_MODEL = "glm-5"
# =============================================
# LLM 调用
# =============================================
def call_llm(system_prompt: str, user_prompt: str) -> str:
"""调用 LLM API"""
payload = {
"model": API_MODEL,
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
"max_tokens": 1024,
"temperature": 0.7
}
try:
response = requests.post(API_URL, headers=API_HEADERS, json=payload, timeout=30)
if response.status_code != 200:
raise Exception(f"API 调用失败: {response.status_code} - {response.text}")
result = response.json()
# 根据返回格式解析
if "choices" in result:
return result["choices"][0]["message"]["content"]
elif "output" in result:
return result["output"]["text"]
else:
return str(result)
except requests.exceptions.Timeout:
raise Exception("API 调用超时")
except Exception as e:
raise Exception(f"API 调用出错: {str(e)}")
# =============================================
# Agent 定义
# =============================================
class Agent:
"""Agent 基类"""
def __init__(self, name: str, role: str, system_prompt: str):
self.name = name
self.role = role
self.system_prompt = system_prompt
self.work_log = []
def process(self, task: str) -> str:
"""执行任务,调用真实 LLM"""
print(f" [{self.name}] 正在调用 LLM...")
result = call_llm(self.system_prompt, task)
self.work_log.append({"task": task[:50], "result": result[:100]})
print(f" [{self.name}] 完成!")
return result
class Researcher(Agent):
"""研究员:搜集整理资料"""
def __init__(self):
super().__init__(
name="研究员",
role="资料搜集",
system_prompt="你是资料研究员。任务:搜集用户需要的信息,整理成清晰的要点列表(每条不超过20字)。输出格式:1. xxx 2. xxx 3. xxx,不要开头结尾废话。"
)
class Writer(Agent):
"""写手:根据资料写内容"""
def __init__(self):
super().__init__(
name="写手",
role="内容创作",
system_prompt="你是内容写手。任务:根据提供的资料写一篇200字左右的短文,语言流畅自然。直接输出文章,不要标题和废话。"
)
class Editor(Agent):
"""编辑:审核润色"""
def __init__(self):
super().__init__(
name="编辑",
role="审核润色",
system_prompt="你是编辑。任务:检查文章是否有明显错误。如果通过输出「【通过】文章质量良好」;如果有问题输出「【修改】xxx问题已修正」。"
)
# =============================================
# 协作模式:流水线
# =============================================
class PipelineTeam:
"""流水线协作:A → B → C"""
def __init__(self, name: str):
self.name = name
self.members = []
def add(self, agent: Agent):
self.members.append(agent)
def collaborate(self, task: str) -> str:
"""执行流水线"""
print(f"\n{'='*50}")
print(f"[团队] {self.name}")
print(f"[模式] 流水线协作")
print(f"[流程] {' → '.join([m.name for m in self.members])}")
print(f"{'='*50}")
current_input = task
for i, agent in enumerate(self.members, 1):
print(f"\n Step {i}: {agent.name}({agent.role})")
print(f" 输入: {current_input[:50]}...")
output = agent.process(current_input)
print(f" 输出: {output[:80]}...")
current_input = output
print(f"\n{'='*50}")
print(f"[完成] 流水线协作结束")
print(f"{'='*50}")
return current_input
# =============================================
# Orchestrator:协调者
# =============================================
class Orchestrator:
"""协调者:规划任务,分配 Agent"""
AGENT_MAP = {
"研究员": Researcher,
"写手": Writer,
"编辑": Editor,
}
WORKFLOWS = {
"写文章": ["研究员", "写手", "编辑"],
"写介绍": ["研究员", "写手", "编辑"],
}
MAX_STEPS = 10 # 最大步数限制(闭环控制)
def solve(self, user_request: str) -> str:
"""解决用户请求"""
# 1. 分析任务类型
task_type = self._classify_task(user_request)
print(f"\n[分析] 任务类型:{task_type}")
# 2. 选择工作流
workflow = self._select_workflow(task_type)
print(f"[规划] 工作流:{' → '.join(workflow)}")
# 3. 组建团队
team = PipelineTeam("写作工坊")
for agent_name in workflow:
agent_class = self.AGENT_MAP[agent_name]
team.add(agent_class())
# 4. 执行协作(有步数限制)
if len(team.members) > self.MAX_STEPS:
print(f"[警告] 工作流超过 {self.MAX_STEPS} 步,强制截断")
team.members = team.members[:self.MAX_STEPS]
result = team.collaborate(user_request)
return result
def _classify_task(self, request: str) -> str:
"""关键词分类"""
if "写" in request or "介绍" in request:
return "写文章"
return "写文章"
def _select_workflow(self, task_type: str) -> list:
return self.WORKFLOWS.get(task_type, ["研究员", "写手", "编辑"])
# =============================================
# 主程序
# =============================================
def main():
print("\n" + "="*50)
print(" 多 Agent 协作系统 - 真实可用版")
print("="*50)
print(f"\n API: {API_URL}")
print(f" 模型: {API_MODEL}")
print("="*50)
# 测试任务
task = "写一篇关于仓鼠的介绍"
print(f"\n[用户请求] {task}")
# 执行协作
orchestrator = Orchestrator()
final_result = orchestrator.solve(task)
# 显示最终结果
print("\n" + "="*50)
print(" 最终结果")
print("="*50)
print(final_result)
if __name__ == "__main__":
main()写于 2026-05-20,学习多个 Agent 分工