目录
- 前言:为什么AI工程师需要懂计算系统
- [🗝 手写卷积算子------从"暴力循环"到矩阵乘法(im2col)](#🗝 手写卷积算子——从“暴力循环”到矩阵乘法(im2col))
- [🗝 实现im2col卷积](#🗝 实现im2col卷积)
- 🗝用profile看性能
- 🗝混合精度与梯度累加
前言:为什么AI工程师需要懂计算系统
很多同学只关注算法的Loss降了多少,却不知道代码在底层是怎么运行的。
在显存受限或大规模集群环境下,工程优化能力决定了算法的落地可能。
🗝 手写卷积算子------从"暴力循环"到矩阵乘法(im2col)
- 使用Numpy定义了输入图像和Kernel。
- 通过嵌套循环实现了滑动窗口。
- 发现:5×5的图片经过 3×3卷积后变成了 3×3。
python
import numpy as np
# 1. 准备数据:5x5 的图片
image = np.array([
[1, 1, 1, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 0],
[0, 1, 1, 0, 0]
])
# 2. 准备滤镜:3x3 的卷积核
kernel = np.array([
[1, 0, 1],
[0, 1, 0],
[1, 0, 1]
])
# 3. 初始化输出:5-3+1 = 3x3 的结果
output = np.zeros((3, 3))
# 4. 暴力循环:滑动窗口
for i in range(3): # 行滑动
for j in range(3): # 列滑动
# 提取当前覆盖的 3x3 区域 (切片)
window = image[i:i+3, j:j+3]
# 核心:对应相乘并求和
output[i, j] = np.sum(window * kernel)
print("✨ 卷积结果:\n", output)- 虽然结果正确,但这种 2 层 for 循环在处理大图(如 1080P 图像)时,会产生数百万次计算。在工业界,这种'暴力'写法会被 im2col 或硬件厂商提供的算子库(如 cuDNN)降维打击。这就是为什么 AI 后端需要关注底层性能。
- 总结:卷积核的深度(Depth)由输入决定,卷积核的宽度/高度(W/H)决定了输出的尺寸,而卷积核的个数(Count)决定了输出的深度。
🗝 实现im2col卷积
im2col:将滑动转化为瞬移 进阶版算子实现。
核心逻辑:为什么要费劲转成矩阵?
- 痛点 :在底层 C++/CUDA 中,for 循环会导致内存地址跳跃,无法利用 CPU 的 SIMD(单指令多数据) 扩展指令集,也无法触发 GPU 的 Tensor Core 加速。
- 黑科技 :计算机算 「矩阵乘法(GEMM)」 的速度快到离谱。im2col 的目标就是:牺牲一点空间(内存),换取极致的时间(速度)。
- 第一步:把窗口拉成行
我们要把图像中每一个 3x3 的滑动区域,全部「暴力」提取出来,摊平变成一个长向量。 - 第二步:代码实现
python
import numpy as np
# 1. 准备数据 (5x5 图像)
image = np.array([
[1, 1, 1, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 0],
[0, 1, 1, 0, 0]
])
# 2. 准备滤镜 (3x3 卷积核),并将其拉直成一个列向量
kernel = np.array([
[1, 0, 1],
[0, 1, 0],
[1, 0, 1]
])
kernel_col = kernel.flatten().reshape(-1, 1) # 变成 9x1 的列
# 3. 执行 im2col:手动提取所有窗口并堆叠成矩阵
rows = []
for i in range(3):
for j in range(3):
# 提取窗口并拉直
window = image[i:i+3, j:j+3].flatten()
rows.append(window)
# 核心:这就是 im2col 矩阵 (形状为 9x9)
# 每一行代表一个滑动位置,每一列代表那个位置的像素值
im2col_matrix = np.array(rows)
# 4. 见证奇迹:一次矩阵乘法解决所有卷积
# (9x9 矩阵) @ (9x1 向量) -> (9x1 结果)
res_flattened = im2col_matrix @ kernel_col
# 5. 把长条结果还原成 3x3 图像
output = res_flattened.reshape(3, 3)
print("✨ im2col 卷积结果:\n", output)性能飞跃的重点:
- 空间换时间:你会发现 im2col_matrix 里的很多数字是重复的(因为窗口滑动有重叠)。这虽然多占了内存,但它让内存变得连续了。
- 算力对齐:现在的计算卡(如你的 4060)内部有专门的矩阵乘法单元。通过 im2col,我们把"卷积问题"成功骗过了编译器,变成了"矩阵乘法问题"。
- 多通道扩展:如果是彩色图,只需把 R、G、B 的三个 9x1向量接在一起,变成一个 27x1 的向量,原理完全一样。
im2col 有什么缺点?
- 它的缺点是显存占用会膨胀(大约膨胀 k×k 倍)。但在现代高性能计算中,相比于 CPU/GPU 的主频瓶颈,内存开销通常是次要矛盾。此外,现代框架(如 cuDNN)会使用 Implicit im2col(隐式 im2col) 技术,在不真正开辟大块内存的情况下,利用寄存器和缓存实现类似的矩阵化加速。
🗝用profile看性能
python
import torch
import torch.nn as nn
from torch.profiler import profile, record_function, ProfilerActivity
# 模拟一个简单的模型
model = nn.Sequential(nn.Linear(1024, 1024), nn.ReLU(), nn.Linear(1024, 10)).cuda()
inputs = torch.randn(64, 1024).cuda()
# 开启"全身检查"
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], record_shapes=True) as prof:
with record_function("model_inference"):
for _ in range(10): # 跑10次查看平均性能
model(inputs)
# 打印最耗时的前 10 个操作
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))以下是运行结果:
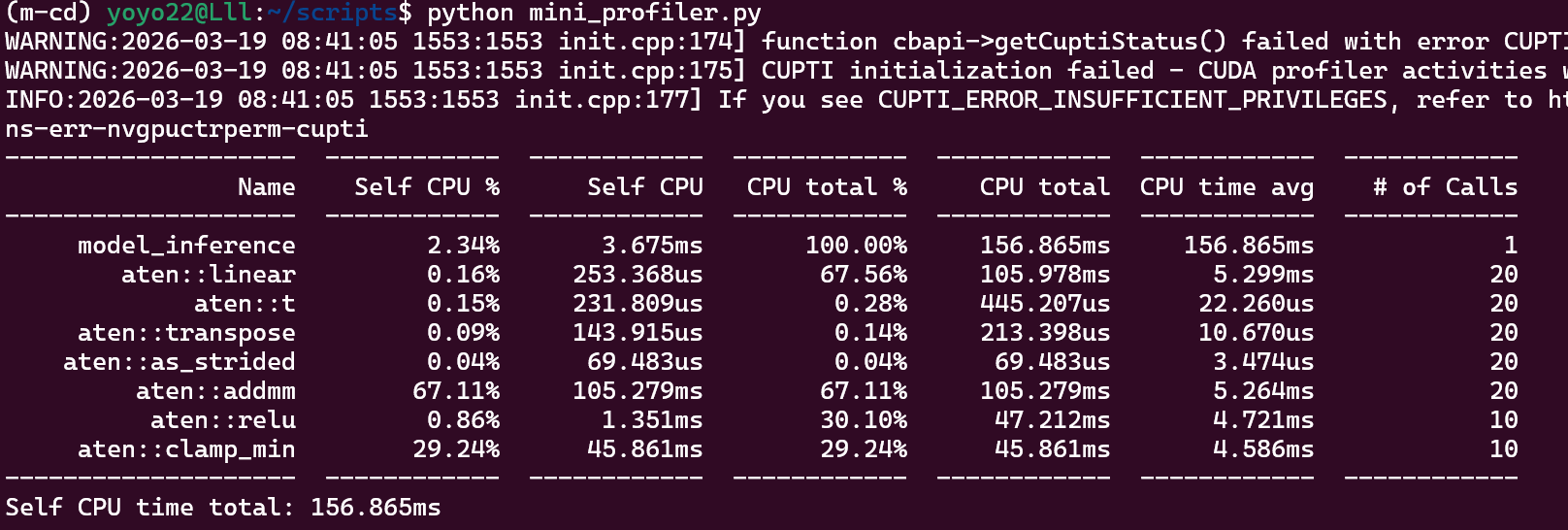
可以看到:
- 代码里写的 nn.Linear,但表里占比最高的是aten::addmn:
Linear 层的本质就是 Matrix-Matrix Multiplication(矩阵乘法)+ Bias Addition(偏置加法)。addmm 就是这个动作在 PyTorch 底层 C++ 库(Aten)里的名字。
- aten::relu 占了 30.10%,而下面紧跟着一个 aten::clamp_min (29.24%)
ReLU 的数学定义是 max(0,x)。在底层实现时,它被转化为了一个"截断"操作(clamp),即把所有小于 0 的值都强行"夹"在 0 上。

- 性能瓶颈分析:CPU total 显示 model_inference 总共耗时 156.865ms。
注意 Self CPU % 这一列。aten::addmm 的 Self CPU 占比极高(67.11%)。这说明计算压力完全集中在矩阵运算本身。如果这个时间太长,你下一步的优化方向应该是:使用混合精度(AMP)来缩减矩阵运算量。
🗝混合精度与梯度累加
python
import torch
import time
# 1. 基础环境锁定
device = "cuda" if torch.cuda.is_available() else "cpu"
assert device == "cuda", "🚨 错误:未检测到显卡,请检查驱动!"
# 2. 构造重型炼金炉 (8192 维度的矩阵,足以填满 4060 的吞吐量)
model = torch.nn.Sequential(
torch.nn.Linear(8192, 8192),
torch.nn.ReLU(),
torch.nn.Linear(8192, 8192),
torch.nn.ReLU(),
torch.nn.Linear(8192, 1024)
).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
loss_fn = torch.nn.MSELoss()
# 准备 128 个样本的大 Batch
inputs = torch.randn(128, 8192).to(device)
targets = torch.randn(128, 1024).to(device)
def run_benchmark(mode="fp32"):
# 预热 (Warmup):把显卡从节能状态叫醒
for _ in range(10):
_ = model(inputs)
torch.cuda.synchronize() # 【关键】战前清场
start_time = time.time()
if mode == "fp32":
for _ in range(200): # 运行 200 次
optimizer.zero_grad()
out = model(inputs)
loss = loss_fn(out, targets)
loss.backward()
optimizer.step()
else:
# 使用最新版本的 AMP API
scaler = torch.amp.GradScaler('cuda')
for _ in range(200):
optimizer.zero_grad()
with torch.amp.autocast('cuda'):
out = model(inputs)
loss = loss_fn(out, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
torch.cuda.synchronize() # 【关键】战后结算
return time.time() - start_time
print("⚔️ 4060 终极性能测试开始...")
print("🐢 正在进行标准 FP32 战斗...")
t_fp32 = run_benchmark(mode="fp32")
print(f"✅ FP32 耗时: {t_fp32:.4f}s")
print("🚀 正在进行混合精度 AMP 冲刺...")
t_amp = run_benchmark(mode="amp")
print(f"✅ AMP 耗时: {t_amp:.4f}s")
speedup = (t_fp32 / t_amp - 1) * 100
print(f"\n📊 最终战果:AMP 比 FP32 快了 {speedup:.2f}%")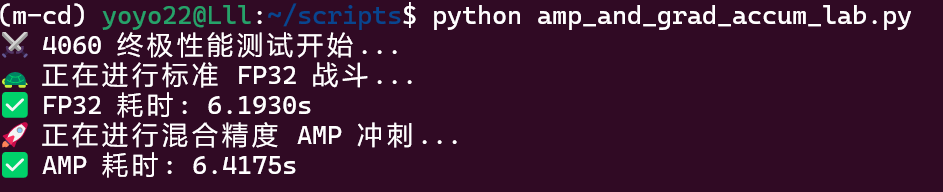
- 实验观察:在自定义的 8192 维全连接神经网络测试中,AMP 混合精度不仅没有带来预期的翻倍加速,反而产生了 3.6% 的性能退化。
- 推论:
- 优化不是魔法:任何优化技术都有其"盈亏平衡点"。对于计算强度不足以填满 Tensor Core 管道的任务,管理开销(Overhead)会成为主导因素。
- 工程选型建议:在 AI 后端开发中,不能盲目开启AMP。对于小型推理模型或浅层网络,保持 FP32 往往能获得更稳定的响应延迟。
- 环境对齐的意义:通过 synchronize()获得的真实数据告诉我,与其盲目调优,不如先看清硬件的真实反馈。