这是我《Linux 驱动实战》专栏字符设备驱动相关的第二篇文章,上一篇我们一起写了一个只有躯壳的字符设备,
/dev/my_cdev_device设备节点只能看不能摸。今天我们要给这个躯壳补上灵魂,让用户程序能通过文件操作来实现用户态与内核态的数据交互。相比上一篇文章,本篇文章的代码量也增加了一倍,考虑到直接放一大坨代码上来大家可能会看的头晕,我决定采用分块讲解的形式,但最后会附上完整可运行的代码。我们话不多说,直接进入正题。
1. 本文目标
每次看《Linux 设备驱动程序》这种经典著作,看到各种复杂的底层架构,总是会忍不住怀疑人生,我就想从简单的驱动开始慢慢学,有必要搞的这么复杂吗?
后来我明白了,学习驱动最好的方法就是先跑通一个极简、完整的程序,俗称 麻雀虽小,五脏俱全。
之前也看过不少的教程,但是上来就是点灯,要问点灯这个项目基础不基础?得分情况,对于单片机来说,点灯还是可以拿来作为入门项目练手的;但是对于 Linux 驱动开发来说,你才刚接触这个方向,就让你学习写一个字符设备驱动来控制 LED ,这显然不合理,也不符合事物的发展规律。因为这时候你可能根本都不了解字符设备驱动的框架,不知道字符设备是个什么东西,甚至连字符设备这个名词都不知道什么含义。
经过这段时间的学习,我感受到,我们不能一上来就搞点灯,我们需要循序渐进。正如我现在采用的办法,我们得先知道字符设备是什么吧,这正是我上一篇文章开头讲过的;我们还得知道字符设备的基础框架吧,知道要创建一个字符设备我们都需要干什么;我们还得知道当字符设备初始化到每一个阶段,你的文件系统的某个位置发生了什么变化吧,这也是上一篇文章我用测试程序验证过的。
上篇文章我们只学到怎样为用户层提供一个操作字符设备的接口,却没有实现操作本身,今天我们来实现这个操作本身。
最终我们会达到这样的效果:
- 先用命令简单测试,通过
echo命令向/dev/my_cdev_device写入内容,然后通过cat读出来。 - 然后写一个用户层的程序,实现打开文件,写入数据,读出数据的操作。
这样,我们就彻底打通了 用户空间应用程序到虚拟文件系统,再到咱们自己写的底层驱动 这条路,以后的各种真实传感器驱动,不过是在这个框架上添砖加瓦罢了。
2. 核心逻辑拆解
本章我们将完整的代码分成几个大块进行学习,包括函数的一些逻辑,以及新接触到的一些 API。
2.1 定义结构体
如下面代码块,我们将需要用到的信息打包进一个代码块:
c
#define BUFFER_SIZE 1024
struct my_cdev{
dev_t dev_num;//设备号
struct cdev cdev;//字符设备核心结构体
struct class *class;//设备类
struct device *device;//设备节点
char *buffer;//用来存储数据
size_t data_size;//实际存的数据量
};这个结构体相比我们之前用的新加入了三个成员。我下面一一介绍一下:
struct cdev cdev:定义一个struct cdev类型的成员cdev,这是字符设备核心结构体。后面我们会用cdev_init将它与文件操作结构体关联起来,然后再用cdev_add将它添加到内核的全局哈希表中。char *buffer: 这是用来存储数据的,当用户程序向设备节点文件写入内容时,把内容就放在这,当用户程序读取设备节点文件的内容时,我们把这里面的内容传给用户程序。size_t data_size:表示buffer中当前存储的字节数,我们只需要在用户程序向设备节点文件写入内容时更新它即可。
剩下的三个成员都是我们之前讲过的,都是注册一个字符设备并在/dev目录下自动创建节点文件必备的东西。
2.2 驱动的灵魂
要让设备真正活起来,响应用户层的 cat、echo 或者 C 语言里的 open、read、write,我们必须搞懂一套核心机制:file_operations 以及它绑定的函数指针。
2.2.1 open 与 release
先上代码:
c
//定义全局结构体
struct my_cdev my_cdev;
static int my_cdev_open(struct inode* inode,struct file* file)
{
//把结构体指针存入file->private_data,方便别的函数使用
file->private_data = &my_cdev;
printk(KERN_INFO "open success!\n");
return 0;
}
static int my_cdev_release(struct inode* inode, struct file* file)
{
printk(KERN_INFO "release success!\n");
return 0;
}我们最终达成的目的是当我们在用户程序中使用 open 打开 /dev/my_cdev_device 时,函数 my_cdev_open 会被执行;当我们使用 close 关闭 /dev/my_cdev_device 时,函数 my_cdev_release 会被执行。
但是现在还不行,我们现在还只是实现了这两个函数,后面还需要将这两个函数的填充到 file_operations 结构体中去,再与 cdev 结构体绑定,最后注册到内核中。
我们看看这两个函数。
乍一看这两个函数其实很简单,没什么技术含量,不就是用 printk 打印提示信息吗?但是请千万别小看 my_cdev_open 函数里那句不起眼的 file->private_data = &my_cdev ,这可以算是字符设备驱动框架的一部分。
要知道在 Linux 中,同一个驱动可以同时支持多个同类设备,而 struct file 又代表一个 打开的文件实例 ,因此当我们在 open 时将 &my_cdev 装入 file 结构体,又在 read 和 write 中把它取出来操作,那么以后对这个字符设备的操作就不会影响到别的同类设备了。
现在的话理解起来可能有点难度,但是随着时间推移,一定能理解的,而且正如我所说,这是字符设备驱动框架的一部分,可以先形成肌肉记忆,以后再慢慢理解。
2.2.2 write
代码如下:
c
static ssize_t my_cdev_write(struct file* file, const char __user* buf, size_t count, loff_t* offset)
{
//把上面存进去的东西取出来
struct my_cdev* dev = file->private_data;
size_t len;//实际要写的字节数
//打印当前偏移量和计划写入的字节数
printk(KERN_INFO "my_cdev: [write] offset=%lld count=%zu\n", *offset, count);
//偏移量超过缓冲区大小
if(*offset >= BUFFER_SIZE)
{
return 0;
}
//计算实际要写的字节数,min里面的参数数据类型要严格相同
len = min(count, (size_t)(BUFFER_SIZE - *offset));
//这里下面详细讲
if(copy_from_user((dev->buffer)+(*offset), buf, len))
{
return -EFAULT;
}
*offset += len;//更新偏移量
//写完了要更新缓冲区数据的字节数
if(*offset >= dev->data_size)
{
dev->data_size = *offset;//更新数据大小
}
return len;//规矩,write要返回写入的字节数。
}
下面我们有重点的了解一下这个函数:
- 首先,我们一定要区分开我们 计划写入的字节数 和 实际能写入的字节数 ,这个逻辑占据了
write函数代码量的一半。这个函数是内核调用的,参数也是内核传进来的。 第一个参数无需多言,第二个参数是用户的缓冲区地址,由于用户态与内核态是 隔离 的,我们不能直接操作它,这也是后面使用copy_from_user的原因第三个参数count代表计划写入的字节数,第四个参数代表偏移量也就是说我们计划 从文件的哪个位置开始写 。 - 当偏移量超过缓冲区大小
BUFFER_SIZE,也就是1024时,这说明光标已经指向缓冲区末尾甚至是缓冲区外面了,我们不能再写了,这时直接返回 0,表示写入 0 个字节。 - 如果偏移量没有超过缓冲区大小,还需要进一步判断缓冲区能不能容纳下我们计划写入的字节数。我们使用
min找出count和 缓冲区剩余容量 中较小的那一个。 - 之后,使用
copy_from_user将用户态的数据拷贝到内核缓冲区中,也就是buffer里面,这里不用着急,我们在初始化函数中会为buffer分配内存。 copy_from_user的第一个参数是内核空间的目标地址,我们要把数据拷贝到这里;第二个参数是用户空间的地址,也就是数据的来源;第三个是要拷贝的字节数。- 在拷贝完成之后,我们要更新偏移量,将光标移到我们刚写入的数据后面。最后还要更新缓冲区数据的字节数。
我觉得还需要再深入了解一下偏移量 offset ,重点来了 :当我们使用 open 打开一个文件时,内核会创建一个 struct file 结构体用来记录这个打开的文件实例,这个文件可以被同一个或者不同的进程同时打开,并且每个打开的实例都会有一个 struct file ,而偏移量 offset 这个struct file 结构体中的成员之一,用来记录这个打开的文件实例的光标偏移量。
当我们使用 open 打开文件时,光标默认在文件开头,也就是说偏移量为 0,我们在用户态每写入一些数据,偏移量都要增加相应的字节数,这也就是为什么 copy_from_user 的参数要传 (dev->buffer)+(*offset) ,如果不这样做,每次向文件写入数据时都会间过前面的内容覆盖掉。
2.2.3 read
代码如下:
c
static ssize_t my_cdev_read(struct file* file, char __user* buf, size_t count, loff_t* offset)
{
struct my_cdev* dev = file->private_data;
size_t len;//实际能读的字节数
//打印偏移量,计划读的字节数和当前缓冲区内有的字节数
printk(KERN_INFO "my_cdev: [read] offset=%lld count=%zu data_size=%zu\n", *offset, count, dev->data_size);
//如果读到文件末尾,返回0,表示文件结束
if(*offset >= dev->data_size)
{
return 0;
}
//计算实际可读的字节数
len = min(count,(size_t)((dev->data_size)-(*offset)));
if(copy_to_user(buf, (dev->buffer) + (*offset), len))
{
return -EFAULT;
}
*offset += len;//更新偏移量
return len;//规矩,read返回读到的字节数
}下面讲一下这个函数:
- 我们依旧把重点放到偏移量上面。我们都知道
read在读到文件末尾时要返回 0,我们要在驱动程序中实现这个特性,当偏移量大于或等于内核缓冲区内容的字节数时,说明读到末尾了,read直接返回 0。 - 如果没读到末尾,就计算实际可读的字节数,找出
count和 缓冲区中光标后面内容字节数 二者较小的那一个。 - 然后使用
copy_to_user,将内容拷贝到用户空间。它的第一个参数是用户空间的目标地址,第二个参数是内核空间的数据源地址,第三个参数是要拷贝的字节数。 - 读完之后更新偏移量,这是标准流程。
这里我们一定要区分开 copy_from_user 和 copy_to_user ,数据流向的示意图如下:
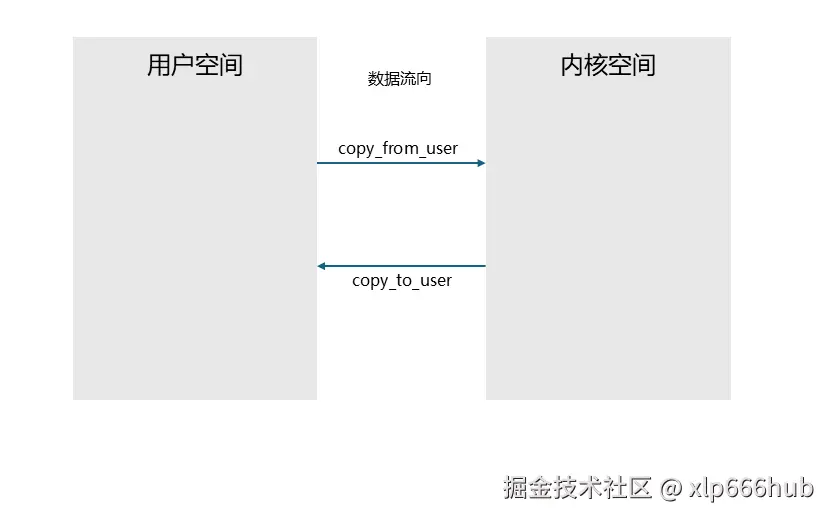
可以结合 to 和 from 来理解,还是挺形象的。
2.2.4 file_operations
如下:
c
static struct file_operations my_cdev_fops = {
.owner = THIS_MODULE,
.open = my_cdev_open,
.release = my_cdev_release,
.read = my_cdev_read,
.write = my_cdev_write,
.llseek = default_llseek,//使用系统默认的偏移量操作
};到这里,我们可以梳理一下整个流程了:用户空间使用 open 打开一个字符设备时,虚拟文件系统通过 open 传入的路径查找该字符设备对应的 struct inode 节点,然后遍历内核哈希表cdev_map,根据inode结构体中的dev_t设备编号找到struct cdev对象,再创建struct file,系统采用一个数组来管理一个进程中多个被打开的设备,每个文件描述符作为数组的下标标识一个字符设备对象,然后将struct file结构体中的file_operations成员指向struct inode结构体中的file_operations成员,最终执行回调函数,file->fops->open。
当我们对这个打开的文件实例执行read和write操作时,调用的就是各自对应的驱动函数。
2.3 init和exit函数
关于init函数和exit函数,上篇文章我们已经讲的很透彻了,大部分操作都是固定框架,只是有个别地方需要注意下,这里篇幅已经挺长了,我挑重点讲一下。
首先,在 init 函数中要为我们的buffer分配内存并初始化缓冲区字节数为 0:
c
my_cdev.buffer = kmalloc(BUFFER_SIZE, GFP_KERNEL);
if(!my_cdev.buffer)
{
printk(KERN_INFO "kmalloc failed!\n");
return -ENOMEM;
}
memset(my_cdev.buffer, 0, BUFFER_SIZE);
my_cdev.data_size = 0;其次,我们上篇文章没讲过的还有cdev_init和cdev_add,但本文前面我也讲了他们的作用了,cdev_init用于将cdev结构体与file_operations结构体绑定起来,而cdev_add用于将该字符设备添加到内核的全局哈希表中,二者缺一不可。下面看看代码实现:
c
//cdev初始化
cdev_init(&(my_cdev.cdev), &my_cdev_fops);
my_cdev.cdev.owner = THIS_MODULE;
//cdev添加到内核
ret = cdev_add(&(my_cdev.cdev), my_cdev.dev_num, 1);
if(ret < 0)
{
printk(KERN_INFO "cdev add failed!\n");
goto err_cdev_add;
}这里比较简单,就不讲参数了。
3. 完整代码与编译
3.1 完整驱动代码
代码如下:
c
#include <linux/module.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/device.h>
#include <linux/cdev.h>
#include <linux/fs.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#include <linux/string.h>
#define BUFFER_SIZE 1024
struct my_cdev{
dev_t dev_num;
struct cdev cdev;
struct class *class;
struct device *device;
char *buffer;
size_t data_size;
};
struct my_cdev my_cdev;
static int my_cdev_open(struct inode* inode,struct file* file)
{
//把结构体指针存入file->private_data,方便别的函数使用
file->private_data = &my_cdev;
printk(KERN_INFO "open success!\n");
return 0;
}
static int my_cdev_release(struct inode* inode, struct file* file)
{
printk(KERN_INFO "release success!\n");
return 0;
}
static ssize_t my_cdev_read(struct file* file, char __user* buf, size_t count, loff_t* offset)
{
struct my_cdev* dev = file->private_data;
size_t len;//实际能读的字节数
printk(KERN_INFO "my_cdev: [read] offset=%lld count=%zu data_size=%zu\n", *offset, count, dev->data_size);
//如果读到文件末尾,返回0,表示文件结束
if(*offset >= dev->data_size)
{
return 0;
}
len = min(count,(size_t)((dev->data_size)-(*offset)));
if(copy_to_user(buf, (dev->buffer) + (*offset), len))
{
return -EFAULT;
}
*offset += len;//更新偏移量
return len;
}
static ssize_t my_cdev_write(struct file* file, const char __user* buf, size_t count, loff_t* offset)
{
struct my_cdev* dev = file->private_data;
size_t len;
printk(KERN_INFO "my_cdev: [write] offset=%lld count=%zu\n", *offset, count);
//偏移量超过缓冲区大小
if(*offset >= BUFFER_SIZE)
{
return 0;
}
len = min(count, (size_t)(BUFFER_SIZE - *offset));
if(copy_from_user((dev->buffer)+(*offset), buf, len))
{
return -EFAULT;
}
*offset += len;
if(*offset >= dev->data_size)
{
dev->data_size = *offset;//更新数据大小
}
return len;
}
static struct file_operations my_cdev_fops = {
.owner = THIS_MODULE,
.open = my_cdev_open,
.release = my_cdev_release,
.read = my_cdev_read,
.write = my_cdev_write,
.llseek = default_llseek,
};
static int __init my_cdev_init(void)
{
int ret;
//分配缓冲区
my_cdev.buffer = kmalloc(BUFFER_SIZE, GFP_KERNEL);
if(!my_cdev.buffer)
{
printk(KERN_INFO "kmalloc failed!\n");
return -ENOMEM;
}
memset(my_cdev.buffer, 0, BUFFER_SIZE);
my_cdev.data_size = 0;
ret = alloc_chrdev_region(&(my_cdev.dev_num), 0, 1, "my_cdev");
if(ret < 0)
{
printk(KERN_INFO "alloc failed!\n");
goto err_alloc;
}
//打印主次设备号
printk(KERN_INFO "Major:%d \t Minor:%d\n",MAJOR(my_cdev.dev_num),MINOR(my_cdev.dev_num));
//cdev初始化
cdev_init(&(my_cdev.cdev), &my_cdev_fops);
my_cdev.cdev.owner = THIS_MODULE;
//cdev添加到内核
ret = cdev_add(&(my_cdev.cdev), my_cdev.dev_num, 1);
if(ret < 0)
{
printk(KERN_INFO "cdev add failed!\n");
goto err_cdev_add;
}
my_cdev.class = class_create(THIS_MODULE, "my_cdev_class");
if(IS_ERR(my_cdev.class))
{
ret = PTR_ERR(my_cdev.class);
printk(KERN_INFO "class create failed!\n");
goto err_class;
}
my_cdev.device = device_create(my_cdev.class, NULL, my_cdev.dev_num, NULL, "my_cdev_device");
if(IS_ERR(my_cdev.device))
{
ret = PTR_ERR(my_cdev.device);
printk(KERN_INFO "device create failed!\n");
goto err_device;
}
printk(KERN_INFO "init success!\n");
return 0;
err_device:
class_destroy(my_cdev.class);
err_class:
cdev_del(&my_cdev.cdev);
err_cdev_add:
unregister_chrdev_region(my_cdev.dev_num,1);
err_alloc:
kfree(my_cdev.buffer);
return ret;
}
static void __exit my_cdev_exit(void)
{
device_destroy(my_cdev.class, my_cdev.dev_num);
class_destroy(my_cdev.class);
cdev_del(&my_cdev.cdev);
unregister_chrdev_region(my_cdev.dev_num,1);
kfree(my_cdev.buffer);
printk(KERN_INFO "resource freed!\n");
}
module_init(my_cdev_init);
module_exit(my_cdev_exit);
MODULE_LICENSE("GPL");3.2 Makefile
Makefile 如下:
c
KERNEL_DIR := /home/xlp/workspace/kernel
obj-m := cdev.o
all:
make -C $(KERNEL_DIR) M=$(PWD) ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- modules
clean:
make -C $(KERNEL_DIR) M=$(PWD) clean3.3 编译
编译后的结果如下:
看到这个界面就说明编译成功了。
然后我们把需要的 cdev.ko 拷贝到板子上就可以运行了。
4. 运行
4.1 加载模块
加载模块需要root权限,我们先用下面命令切换到root:
bash
sudo su然后加载模块:
bash
insmod cdev.ko执行状况与内核日志如下:


日志中打印了 "init success",这说明我们的init函数已经成功执行了。
4.2 写入数据并读取
然后我们尝试向/dev/my_cdev_device写入数据并读取:

成功读出来了。
我们再看内核日志,驱动程序中write和read函数中的printk的内容也成功打印了:
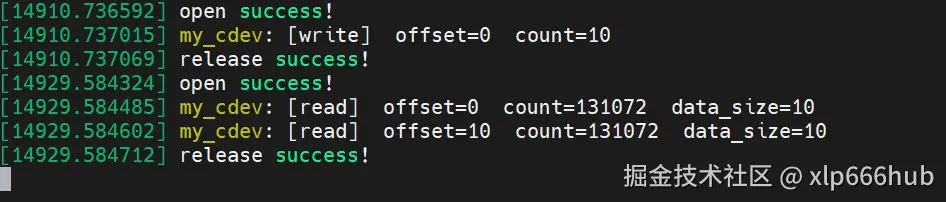
从这张内核日志的截图中我们还能得到重量级结论:
-
第一,
echo和cat的底层其实也是一系列系统调用,先open文件,然后read或者write,最后close文件。 -
第二,相信大家已经发现了,日志中
echo引起的write调用只有一次,而cat引起的read调用却有两次,这是为什么呢?实际上,当cat执行时,因为当前它的目标是一个字符设备,而不是普通的文件,cat并不知道它要读取的内容有多少,但是有一点,它要全部读完,因此,它准备了一个超级大的缓冲区,日志中可以看到这个缓冲区大小为 131072 字节,也就是128KB ,但实际上只读了10个字节,因为我们的内核缓冲区中只有 10 个字节。cat拿到这 10 个字节后还没有停手,它要验证是否已经读到文件的末尾了,于是它发起了第二次read,但是此时offset已经为 10 了,就进入了我们代码中的这个逻辑:cif(*offset >= dev->data_size) { return 0; //触发EOF }cat收到返回的 0 之后,它明白已经读到文件末尾了,于是调用close关闭文件。
试想一下: 如果在第二次 read 的时候,我们没有返回 0,而是随便返回了一个大于 0 的数,或者忘了判断 offset,cat 就会一直以为还有数据,不断发起第三次、第四次、第一万次 read,你的屏幕就会瞬间卡死。这就是驱动开发中 状态管理 最生动的体现。
4.3 卸载模块
最后我们使用rmmod卸载模块:

内核日志显示,我们的exit函数已经成功调用了,资源释放完成。
4.4 小补充
如果想使用echo追加写入,那么需要在驱动程序的write函数中加一段代码:
c
//如果发现是以追加模式打开的,我们就强行把光标移到数据的末尾
if (file->f_flags & O_APPEND) {
*offset = dev->data_size;
}5. 编写应用程序测试
这一章,我们要用 C 语言写一个用户态的应用程序来调用我们的底层驱动。
代码如下:
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#define DEV_NAME "/dev/my_cdev_device"
int main()
{
int fd;
char write_buf[] = "hello xlp";
char read_buf[100] = {0};
int ret;
fd = open(DEV_NAME,O_RDWR);//可读可写
if(fd < 0)
{
printf("open failed!\n");
return -1;
}
//写入内容
ret = write(fd,write_buf,strlen(write_buf));
if(ret < 0)
{
printf("write failed!\n");
close(fd);
return -1;
}
printf("写入 %d 个字节:%s\n",ret,write_buf);
//读取
lseek(fd,0,SEEK_SET);//需要将光标移动到文件开头
ret = read(fd,read_buf,sizeof(read_buf));
if(ret < 0)
{
printf("read failed!\n");
close(fd);
return -1;
}
printf("读出 %d 个字节:%s\n",ret,read_buf);
close(fd);
//再打开关闭测试一下
fd = open(DEV_NAME,O_RDWR);
if(fd<0)
{
return -1;
}
close(fd);
return 0;
}这个程序直接在板子上编译即可。
我们先加载模块,然后运行这个应用程序,再查看内核日志:

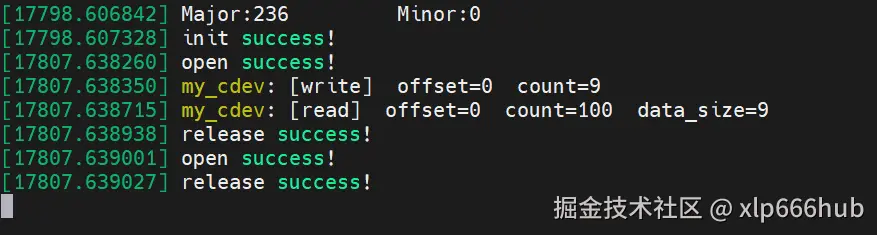
可以看到,我们的应用程序完美的调用的我们的驱动程序,内核日志打印的信息和我们应用程序的逻辑完全一样。
6. 总结
这篇文章写到现在也就快结束了,我想谈谈我的看法。
以前,当我在终端敲下 cat /dev/xxx 时,我只是单纯的觉得这是一个系统命令。
但现在,我的脑海里会立刻浮现出一幅生动的画面:shell 帮我调用了 open,内核通过文件路径查找inode进而找到cdev ,同时也就找到了cdev里面的file_operations ,找到了对应的驱动程序,接着 cat 带着一个 128KB 的缓冲区发起 read ,直到驱动给出一个 return 0 的 EOF 标志,它才 close 文件,最后结束。
这种 看透事物底层运转逻辑 的感觉,我不知道大家什么啥想法,反正我很享受。
最后,如果这篇文章帮助到你了,可以看一下我的专栏《Linux 驱动开发》,感兴趣的朋友可以订阅一下,如果可以的话也请给我点个关注,点赞收藏一下文章,可以以后隔一段时间回顾一下,温故而知新嘛!谢谢大家了~
本文结束