😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文讲解【强化学习】强化学习基本概念,20W字总结(一),期待与你一同探索、学习、进步,一起卷起来叭!
🎯 把我的博客装进你的 Claude Code,它就是你的 AI 学习搭子想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code------它会自动生成一个本地 SKILL。RSS 自动同步最新内容,不用手动存任何文件。
text请为这个 CSDN 博客创建一个本地 SKILL(存到 .claude/skills/csdn-blog/SKILL.md): RSS 源:https://rss.csdn.net/m0_51517236/rss/map 支持三件事:① 列出最新文章(标题+链接+摘要);② 按关键词搜索; ③ 抓取指定文章全文,作为 AI 学习助手 / 面试官深度讲解并出题考核我。 SKILL.md 里写清楚 RSS URL、调用方式和示例。生成完就能用自然语言搜文章了。一键订阅,长期可用。🚀
目录
什么是强化学习?
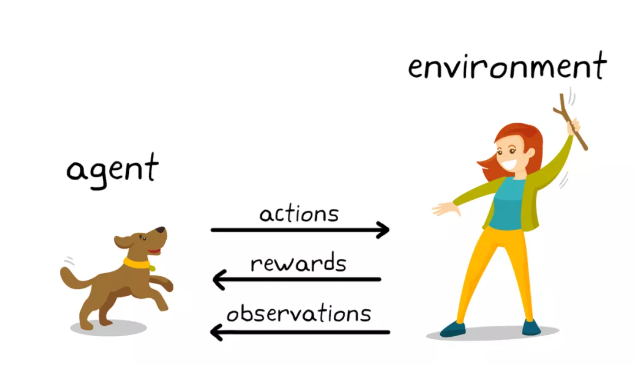
强化学习讨论的核心问题很简单:一个智能体(agent),怎么在复杂、不确定的环境(environment)中,拿到尽可能多的奖励?
就这么一句话。但这句话背后,藏着 AlphaGo 击败李世石的秘诀,藏着 ChatGPT 对齐人类偏好的 RLHF 技术,也藏着自动驾驶决策系统的核心框架。
强化学习由两部分组成:智能体 和环境。它俩一直在互动------智能体观察环境的状态,做出一个动作(action);环境接收到动作后,返回下一个状态和当前动作带来的奖励(reward)。智能体的目标只有一个:拿更多的奖励。
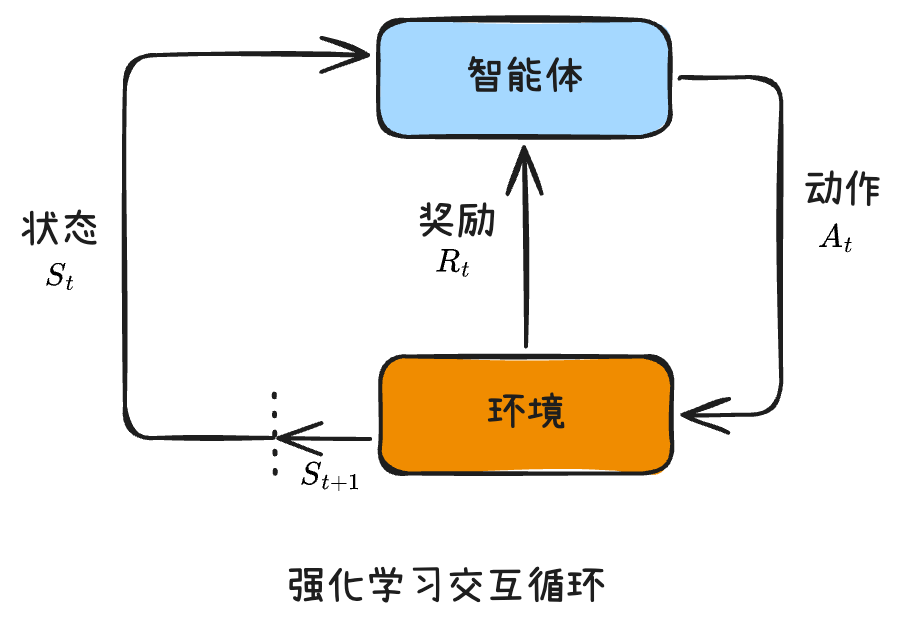
一个最经典的例子------倒立摆(CartPole)。
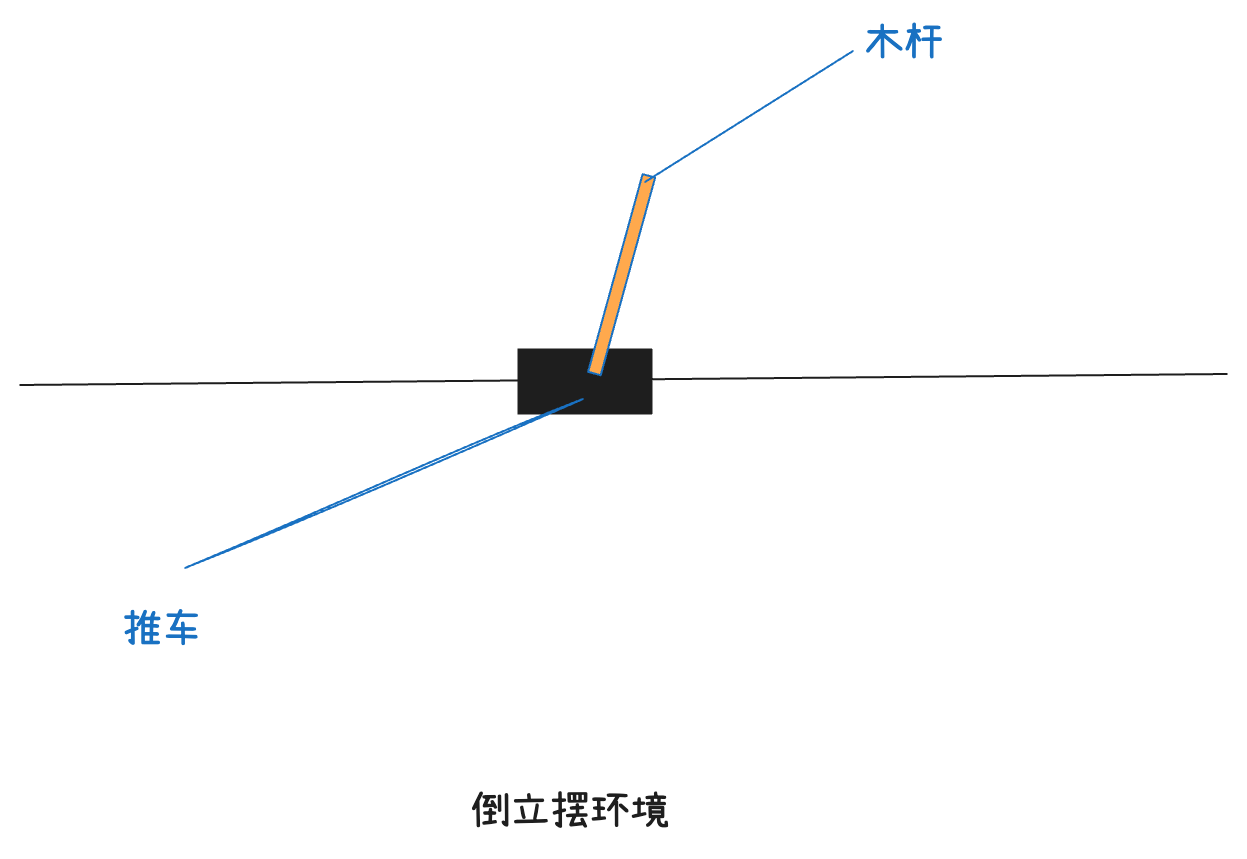
想象你用手掌托着一根木杆,你要不断移动手掌的位置让杆子不倒。在倒立摆环境中,智能体就是那辆推车:
| 要素 | 倒立摆环境中的含义 |
|---|---|
| 动作空间 | 推车有两个动作:向左推 和 向右推 |
| 状态 | 4 维浮点数:推车位置、推车速度、杆子角度、杆子角速度 |
| 奖励 | 每推一步,只要杆子没倒,奖励就是 1 |
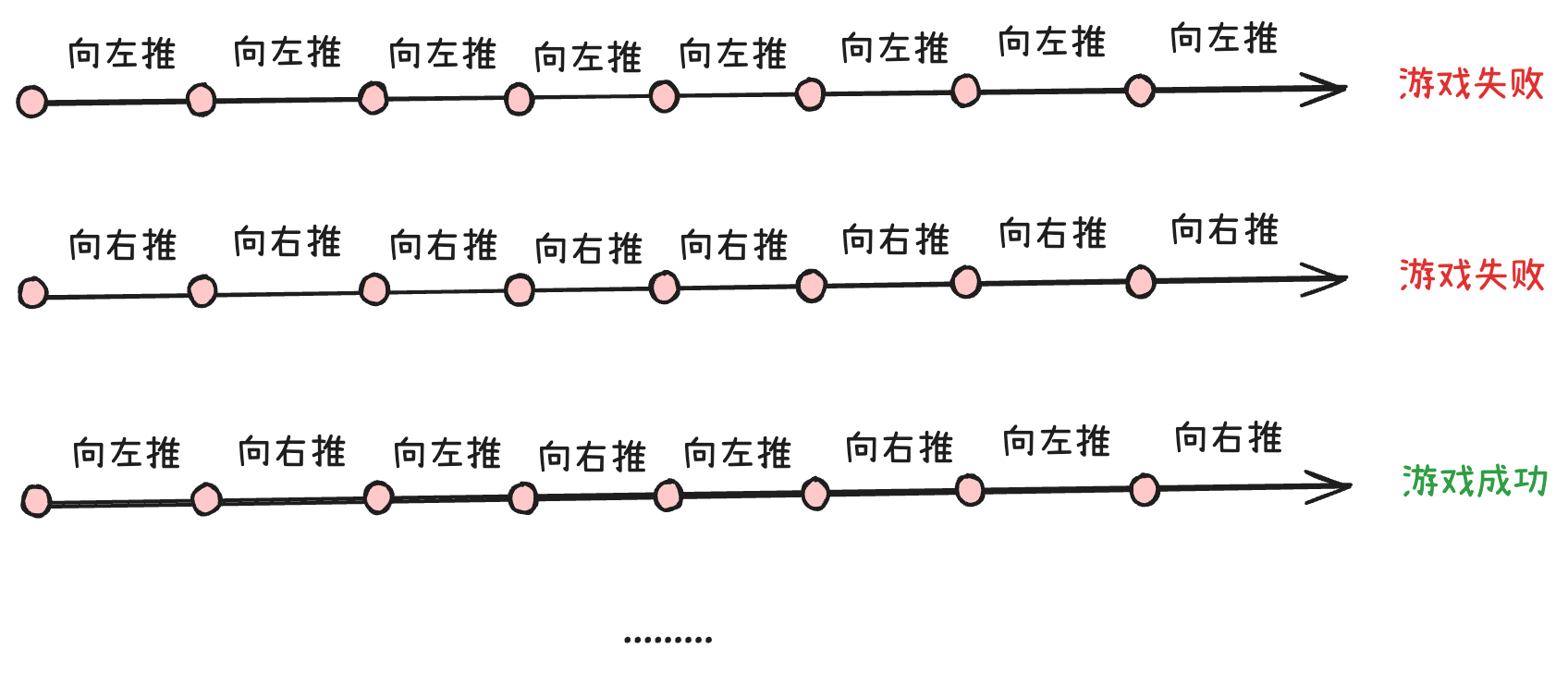
游戏结束条件:
- 推车把杆子推出了屏幕 → 失败
- 杆子倒下 → 失败
- 推了 200 步,杆子还站着 → 成功
所以问题来了:推车该用什么策略,才能让杆子撑住不倒?
核心概念:策略、动作与概率
策略是一个函数
推车每次要做什么动作,取决于环境当前的状态。杆子往左偏了,你可能得往左推才能稳住。换句话说,策略(policy)是一个函数------输入状态,输出动作。
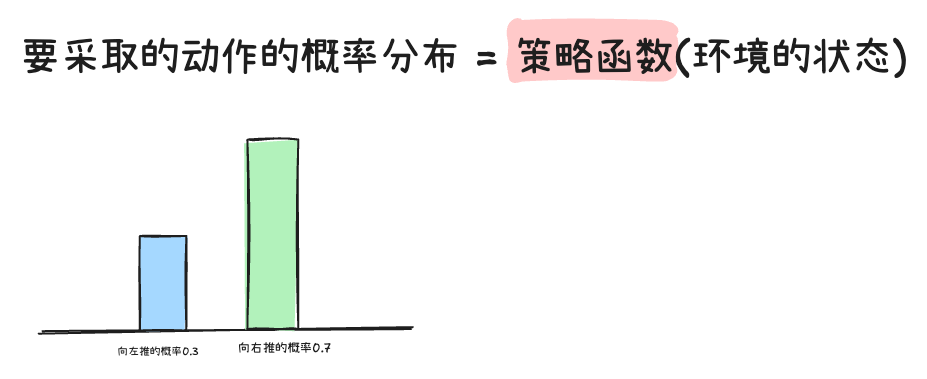
但这里有个关键点:输出的不是一个确定的动作,而是一个概率分布。比如:向左推的概率 0.7,向右推的概率 0.3。然后从这个分布中采样一个动作出来。
为什么不直接选概率最大的?因为只顾眼前利益、从不探索新策略,可能会错过更好的选择。
什么是"从概率分布中采样"?
假设向左推概率 0.7、向右推概率 0.3。采样一次,有 70% 的概率输出"向左推",30% 的概率输出"向右推"。
打个比方:你每次都去最熟悉的那家馆子吃饭,体验稳定但很难有惊喜。偶尔去试一家新店,可能踩雷,也可能发现新大陆。在舒适区只利用不探索,就是固步自封。冒险可能受伤,但长期看可能获得更大回报。
这个"利用 vs 探索"的权衡,贯穿整个强化学习。
策略的数学表示
策略用数学符号 π \pi π 表示,所以策略就是 π \pi π 函数:
π ( a ∣ s ) = p ( a t = a ∣ s t = s ) \pi(a | s) = p(a_t = a \mid s_t = s) π(a∣s)=p(at=a∣st=s)
输入状态 s s s,输出在状态 s s s 下采取动作 a a a 的概率。比如:
π ( a = a 向左推 ∣ s ) = 0.7 π ( a = a 向右推 ∣ s ) = 0.3 \begin{aligned} \pi(a=a_{\text{向左推}} \mid s) &= 0.7 \\ \pi(a=a_{\text{向右推}} \mid s) &= 0.3 \end{aligned} π(a=a向左推∣s)π(a=a向右推∣s)=0.7=0.3
如果这个 π \pi π 函数是一个神经网络,那就是 深度学习 + 强化学习 = 深度强化学习。当今 AI 界最热门的话题,没有之一。

轨迹:一个回合的完整记录
推车在倒立摆环境里玩一个完整的回合(episode) ,过程是这样的:环境给出初始状态 S 0 S_0 S0,推车根据策略选择动作 A 0 A_0 A0,拿到奖励 R 0 R_0 R0;环境转移到下一个状态 S 1 S_1 S1,推车再选动作 A 1 A_1 A1,拿奖励 R 1 R_1 R1......以此类推。
把它们按顺序排成一串,就是一条轨迹(trajectory) ,符号是 τ \tau τ(读作"掏"):
τ = ( S 0 , A 0 , R 0 , S 1 , A 1 , R 1 , S 2 , A 2 , R 2 , ... ) \boxed{ \tau = (S_0, A_0, R_0, S_1, A_1, R_1, S_2, A_2, R_2, \dots) } τ=(S0,A0,R0,S1,A1,R1,S2,A2,R2,...)
因为动作是从概率分布中采样的,所以同一个环境、同一个策略,能产生无数条不同的轨迹。
价值函数:这个状态值多少?
回报(Return)
在某个时刻 t t t,环境处于状态 S t S_t St,之后一直按策略执行,未来总共能拿多少奖励?
有个问题:未来的奖励不如现在的香。所以得打折 。从时刻 t t t 开始的回报定义如下:
G t = R t + γ R t + 1 + γ 2 R t + 2 + ⋯ \boxed{ G_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \cdots } Gt=Rt+γRt+1+γ2Rt+2+⋯
γ \gamma γ 是折扣因子 ,取值 0 , 1 0, 1 0,1。它让远期的奖励指数级衰减。比如 γ = 0.9 \gamma = 0.9 γ=0.9:
G t = R t + 0.9 ⋅ R t + 1 + 0.81 ⋅ R t + 2 + ⋯ G_t = R_t + 0.9 \cdot R_{t+1} + 0.81 \cdot R_{t+2} + \cdots Gt=Rt+0.9⋅Rt+1+0.81⋅Rt+2+⋯
为什么要打折?两个原因:
- 数学上 :防止连续任务的回报发散到无穷大( γ = 1 \gamma=1 γ=1 时求和可能不收敛)
- 直觉上:今天的 10000 块比一年后的 20000 块更有吸引力------这就是折扣因子在人类行为中的体现
状态价值函数
回报 G t G_t Gt 是随机的------每次采样轨迹不同,回报也不同。那怎么评估"在状态 s s s 下一直按策略 π \pi π 行动,预期回报是多少"?
答案是取期望。这就得到了状态价值函数:
V π ( s ) = E π G t ∣ S t = s = E π ∑ k = 0 ∞ γ k R t + k ∣ S t = s \boxed{ V_{\pi}(s) = \mathbb{E}{\pi}\leftG_t \\mid S_t = s\\right = \mathbb{E}{\pi}\left\\sum_{k=0}\^{\\infty} \\gamma\^{k} R_{t+k} \\mid S_t = s\\right } Vπ(s)=EπGt∣St=s=Eπk=0∑∞γkRt+k∣St=s
一句话:状态价值函数衡量的是------在某个状态下,一直按某个策略走,最终能拿到多少回报的期望值。
它还有一个等价形式,叫贝尔曼期望方程:
V π ( S t ) = E π R t + γ V π ( S t + 1 ) ∣ S t V_\pi(S_t) = \mathbb{E}_\piR_t + \\gamma V_\\pi(S_{t+1}) \\mid S_t Vπ(St)=EπRt+γVπ(St+1)∣St
翻译成人话:
当前状态对你的价值 = 当前这一步给的奖励 + 打折后的"下一状态对你的价值"
用上班类比就秒懂:
你对公司的评估 = 公司现在给你的钱 + 折扣因子 × 你对公司未来的估值
- 现在工资低,但你觉得前景不错( γ = 0.99 \gamma=0.99 γ=0.99) → 估值不低
- 现在工资高,但你觉得公司快黄了 → 估值也高不了
- 现在工资低,公司大概率要倒,但万一不倒就起飞 → 这就是高风险高回报
机智如你,很容易想到💡------价值函数其实就是强化学习里的"估值体系"。

总结
这篇文章我们理清了强化学习的核心概念:
| 概念 | 一句话解释 | |
|---|---|---|
| 智能体(Agent) | 做决策的主体 | |
| 环境(Environment) | 智能体所处的世界,返回状态和奖励 | |
| 状态(State) | 环境当前的情况 | |
| 动作(Action) | 智能体的选择 | |
| 奖励(Reward) | 环境对动作的反馈 | |
| 策略(Policy) | 从状态到动作概率分布的函数 π ( a ∣ s ) \pi(a\mid s) π(a∣s) | |
| 轨迹(Trajectory) | 一个回合中状态-动作-奖励的完整序列 | |
| 回报(Return) | 从某时刻起未来奖励的打折总和 G t G_t Gt | |
| 价值函数(Value Function) | 在某状态下按策略行事的预期回报 V π ( s ) V_\pi(s) Vπ(s) |
一句话总结 :强化学习的本质,就是智能体在环境里不断试错,通过调整策略 π \pi π 来最大化回报 G t G_t Gt。
下一篇我们会给这些直觉装上数学骨架------马尔可夫决策过程(MDP)、贝尔曼方程的完整推导,还有 CartPole 编程实战。理论 + 代码,把手弄脏。

📌 笔者 文艺倾年
📃 更新 2026.0613
❌ 勘误 /* 暂无 */
📜 声明 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!
