1、请解释缓存穿透、缓存击穿和缓存雪崩的区别。针对每种情况,你的预防和解决方案是什么?
缓存穿透
大量请求查询一个数据库中根本不存在的数据(如id=-1)。导致请求直接穿透缓存,每次都访问数据库,给DB带来巨大压力。
缓存穿透-解决方案
接口校验
在API层对请求参数进行校验,过滤非法请求(如id<=0)
缓存空值
即使数据库查询为空,也将这个空结果(如null)进行缓存,并设置一个较短的过期时间(如1-5分钟)。后续请求将直接取到空值而不会访问DB。
布隆过滤器(Bloom Filter)
将所有可能存在的key哈希到一个足够大的bitmap中。收到请求时,先经过布隆过滤器校验:如果key一定不存在,则直接返回;如果可能存在,才继续后续流程。
缓存击穿
一个热点key在缓存过期的瞬间,大量请求同时涌入,全部直接打到数据库,仿佛击穿了缓存。
缓存击穿--解决方案
永不过期
对真正的热点key不设置过期时间,或者由逻辑程序异步地更新缓存。
互斥锁(Mutex Lock)
当缓存失效时,不是所有线程都去查询DB,而是只有一个线程(通过Redis的setnx或分布式锁) 去查询数据库并重建缓存,其他线程等待并轮询缓存,直到缓存被重建成功。
缓存雪崩
缓存中大量key在同一时间(或时间段)过期,导致所有请求都落到数据库上,引起数据库压力激增甚至崩溃。
缓存雪崩--解决方案
差异化过期时间
给缓存设置过期时间时,加上一个随机值(如基础时间 + 随机1-5分钟),避免大量key同时失效。
Redis高可用
搭建Redis集群(如哨兵模式、Cluster模式),保证即使部分节点宕机,缓存服务仍然可用。
服务降级与熔断
在应用层,当检测到DB压力过大时,对非核心业务的数据请求直接返回预定义默认值(降级),或暂停访问(熔断),保护DB。
2、请从生产者、Broker、消费者三个角度阐述,Kafka是如何保证消息不丢失的?
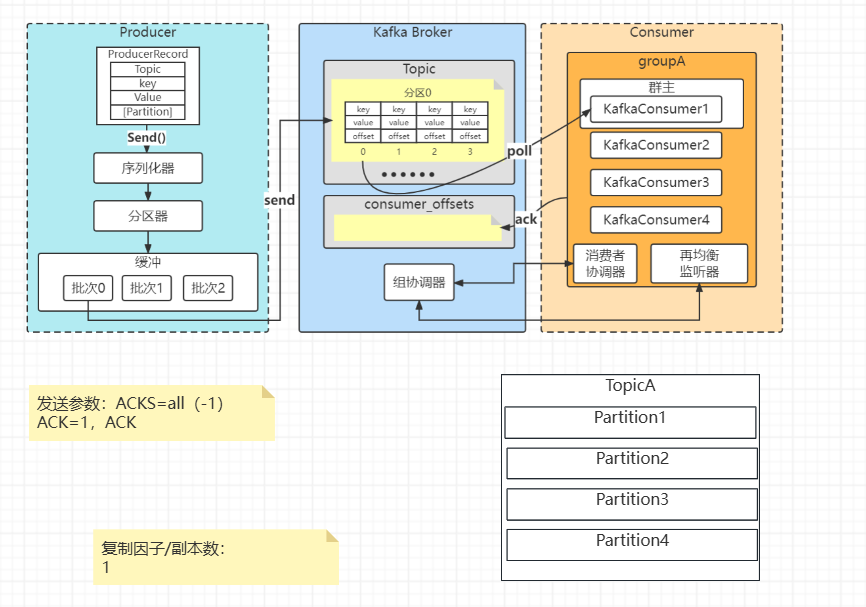
生产者 (Producer)
○设置 acks=all(或 -1)。这意味着Leader副本必须等待所有ISR(In-Sync Replicas)副本都成功收到消息后,才会向生产者发送确认。这是最强的持久化保证。 ○设置 retries 为一个较大的值(如 Integer.MAX_VALUE),使生产者在遇到可重试异常时能自动重试。 ○在回调函数中处理发送失败的情况,并做好日志记录和告警。
Broker 角度:
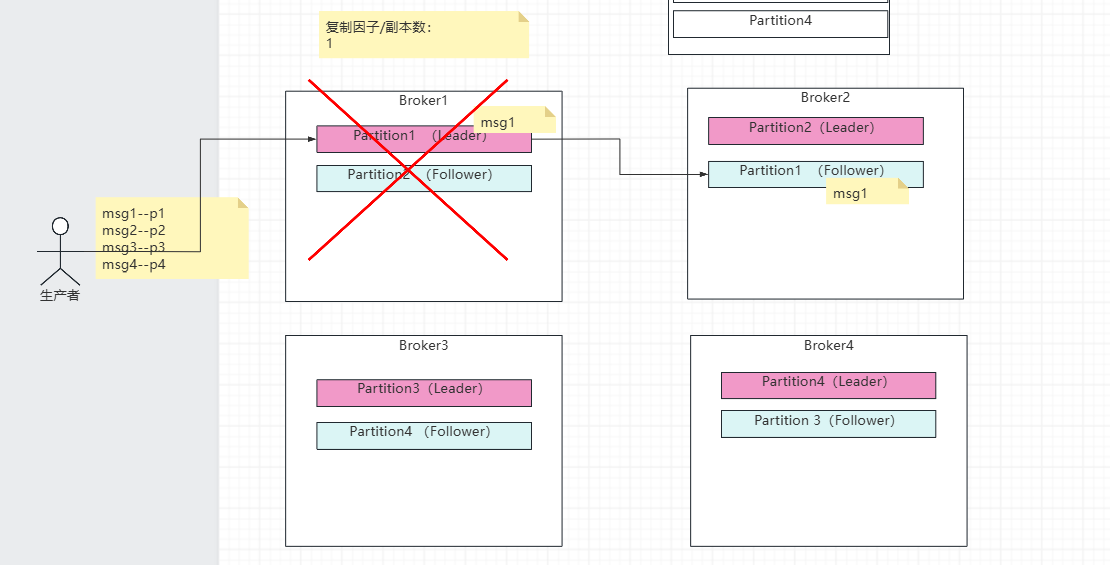
○设置 unclean.leader.election.enable=false。防止非ISR中的副本(可能落后很多)被选举为Leader,从而导致数据丢失。 ○设置 replication.factor >= 3。保证每个分区有足够多的副本,提高数据可靠性。 ○设置 min.insync.replicas > 1(例如2)。这意味着至少需要多少个ISR副本存在,生产者才能成功写入。与 acks=all 配合,构成了一个"至少成功写入N个副本才算成功"的强一致性保证。
消费者 (Consumer) 角度
○关闭自动提交(enable.auto.commit=false)。 ○采用手动提交偏移量 (Offset)。只有在消息被业务逻辑成功处理完毕之后,再调用 consumer.commitSync() 来提交偏移量。这样可以避免消息被消费但业务处理失败,而偏移量又被提交导致的"丢失"(实际上是没被真正处理)。
java
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 类说明:消费者入门
*/
public class ConsumerCommit {
public static void main(String[] args) {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器的地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置String的反序列化
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"ConsumerOffsets");
/*取消自动提交*/
properties.put("enable.auto.commit",false);
// 构建kafka消费者对象
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);
try {
consumer.subscribe(Collections.singletonList("msb"));
// 调用消费者拉取消息
while(true){
// 每隔1秒拉取一次消息
ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));
for(ConsumerRecord<String, String> record:records){
String key = record.key();
String value = record.value();
System.out.println("接收到消息: key = " + key + ", value = " + value);
}
consumer.commitAsync();//异步提交:不阻塞我们的应用程序的线程,不会重试(有可能失败)
}
}catch (CommitFailedException e) {
System.out.println("Commit failed:");
e.printStackTrace();
}finally {
try {
consumer.commitSync();//同步提交: 会阻塞我们的应用的线程,并且会重试(一定会成功)
} finally {
consumer.close();
}
}
}
}
2.1、MQ是如何保证消息不重复的?
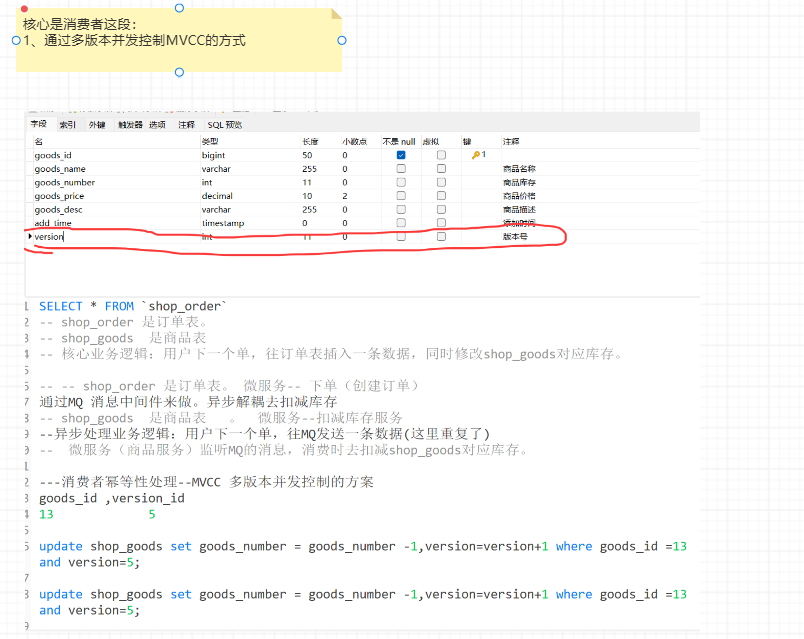
1. MVCC:
多版本并发控制,乐观锁的一种实现,在生产者发送消息时进行数据更新时需要带上数据的版本号,消费者去更新时需要去比较持有数据的版本号,版本号不一致的操作无法成功。例如博客点赞次数自动+1的接口:
public boolean addCount(Long id, Long version);
update blogTable set count= count+1,version=version+1 where id=321 and version=123
每一个version只有一次执行成功的机会,一旦失败了生产者必须重新获取数据的最新版本号再次发起更新。
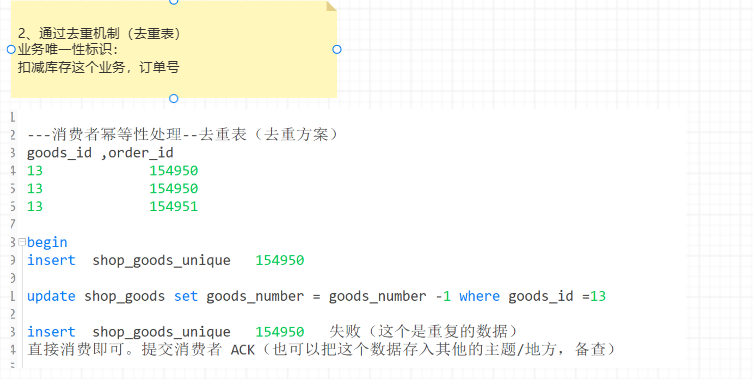
2. 去重表:
利用数据库表单的特性来实现幂等,常用的一个思路是在表上构建唯一性索引,保证某一类数据一旦执行完毕,后续同样的请求不再重复处理了(利用一张日志表来记录已经处理成功的消息的ID,如果新到的消息ID已经在日志表中,那么就不再处理这条消息。)
以电商平台为例子,电商平台上的订单id就是最适合的token。当用户下单时,会经历多个环节,比如生成订单,减库存,减优惠券等等。每一个环节执行时都先检测一下该订单id是否已经执行过这一步骤,对未执行的请求,执行操作并缓存结果,而对已经执行过的id,则直接返回之前的执行结果,不做任何操作。这样可以在最大程度上避免操作的重复执行问题,缓存起来的执行结果也能用于事务的控制等。
3、线上发现Kafka某个Topic的消息出现了大量积压,作为开发者,你的排查思路和应急方案是什么?
排查思路
确定问题范围
使用 kafka-consumer-groups 命令查看是哪个Consumer Group的哪个Topic分区出现了Lag。
检查消费者状态
■监控:检查消费者应用的CPU、内存、GC情况,看是否有异常。 ■日志:查看消费者应用日志,是否有大量的错误日志(如网络异常、处理业务时抛异常、频繁Full GC)。
分析业务逻辑
检查最近是否有发版,消费逻辑是否变慢(如新引入了耗时操作:数据库慢查询、调用外部API超时等)。
应急方案
扩容
■紧急扩容消费者
增加Consumer Group的消费者实例数量(但不能超过分区数),以提高消费能力。这是最直接的方案。 ■扩容分区
如果分区数不足,可以先扩容Topic的分区数,然后再扩容消费者。(注意:分区数只能增不能减,且可能改变key的顺序性)
降级
临时修改消费逻辑,跳过非核心业务(例如只处理核心字段,记录日志后续补偿),提高消费速度。
紧急修复
如果是代码BUG导致消费失败,立即回滚或修复BUG上线。
4、请简述RPC框架的工作原理。在Dubbo等RPC框架中,有哪些常见的服务容错机制?
RPC工作原理:
RPC(远程过程调用)的核心是伪装,让调用远程服务像调用本地方法一样。 ○代理:客户端通过动态代理,将方法调用封装成一个网络请求。 ○序列化:将调用信息(类名、方法名、参数等)序列化成二进制数据。 ○网络传输:通过网络(如Netty)将请求发送到服务端。 ○反序列化:服务端收到后反序列化请求数据。 ○反射调用:通过反射机制找到目标类和方法并执行。 ○返回结果:将执行结果序列化后返回给客户端,客户端再反序列化得到结果。
手写代码
java
import java.io.Serializable;
/**
* 用户信息
*/
public class User implements Serializable {
private static final long serialVersionUID = -21765049447197900L;
private Integer id;
private String name;
public User(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.net.Socket;
//客户端
public class client {
public static void main(String[] args) throws Exception {
IUserService service = Stub.getStub(IUserService.class);//可以根据不同的类,拿不同的代理
User user=service.findUserByID(123);//调用远程的方法,跟调用本地的方法类似: 加入了代理的概念
System.out.println(user.getName());
}
}
import java.io.*;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.net.Socket;
public class Stub {
public static IUserService getStub(Class clazz) throws Exception{
InvocationHandler handler = new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//TCP的网络连接
Socket socket = new Socket("127.0.0.1",8888);
//发送请求
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
String methodName= method.getName();//方法
Class[] parametersTypes = method.getParameterTypes();//参数类型
//格式(0: 类名 1:方法名、2、方法参数类型 3、参数值)
objectOutputStream.writeUTF(clazz.getName());
objectOutputStream.writeUTF(methodName);
objectOutputStream.writeObject(parametersTypes);
objectOutputStream.writeObject(args);
objectOutputStream.flush();
//处理响应
ObjectInputStream dataInputStream = new ObjectInputStream( socket.getInputStream());
Object o = dataInputStream.readObject();
//响应端 对象不就行了
objectOutputStream.close();
socket.close();
return o;
}
};
//执行动态代理(传入类加载器、接口、代理对象、返回对象)
Object o = Proxy.newProxyInstance(IUserService.class.getClassLoader(),
new Class[]{IUserService.class}, handler);
return (IUserService) o;
}
}
import java.io.*;
import java.lang.reflect.Method;
import java.net.ServerSocket;
import java.net.Socket;
//服务端(远程的用户服务)
public class Server {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(8888);//监听8888端口
while (true){
Socket socket =serverSocket.accept();//网络请求过来了,使用socket通道(没有则阻塞)
//业务的处理
process(socket);
socket.close();//记得关闭
}
}
private static void process(Socket socket) throws Exception{
InputStream inputStream = socket.getInputStream();//客户端送过的信息
OutputStream outputStream= socket.getOutputStream();//响应客户端
ObjectInputStream dataInputStream = new ObjectInputStream(inputStream);
ObjectOutputStream dataOutputStream = new ObjectOutputStream(outputStream);
System.out.println("process");
//格式(0: 类名 1:方法名、2、方法参数类型 3、参数值)
String clazzName = dataInputStream.readUTF();
String methodName = dataInputStream.readUTF();
Class[] parametersTypes =(Class[]) dataInputStream.readObject();
Object[] args=(Object[]) dataInputStream.readObject();
//通过反射去调用
//这里一般会从服务的注册表中去找(RPC框架中, 服务的注册中心)
Class clazz = UserServiceImpl.class;
Method method = clazz.getMethod(methodName,parametersTypes);
User user = (User)method.invoke(clazz.newInstance(),args);//通过反射调用
dataOutputStream.writeObject(user);//这里就需要根据不同的类,
dataOutputStream.flush();//刷新缓冲区
}
}
/**
* 接口实现类
*/
public class UserServiceImpl implements IUserService {
@Override
public User findUserByID(Integer id) {
return new User(id,"lijin6666");
}
}
package com.msb.rpc;
/**
* 查询用户 接口
*/
public interface IUserService {
public User findUserByID(Integer id);
//其他的接口
}
public class RpcDemo {
public static void main(String[] args) {
IUserService service = (IUserService) new UserServiceImpl();
//本地调用
service.findUserByID(13);
//Http调用--远程
// RequestParam param = new RequestParam();
// ......
// HttpClient.get(url, param,.....);
//RPC调用 service 封装 调用远程接口 和调用本地接口一样的
service.findUserByID(13);//具体的实现已经在另外一台服务器上
}
}