1.字段保留
bash
syntax = "proto3";
package test.unknown_fields;
message UserInfoV1 {
int64 id = 1;
string name = 2;
}
message UserInfoV2 {
int64 id = 1;
string name = 2;
int32 age = 3; // 新增字段
}
cpp
#include <iostream>
#include <string>
#include "test.pb.h"
using namespace test::unknown_fields;
int main() {
GOOGLE_PROTOBUF_VERIFY_VERSION;
// 1. v2 序列化(含新增 age 字段)
UserInfoV2 v2_data;
v2_data.set_id(1001);
v2_data.set_name("张三");
v2_data.set_age(25);
std::string v2_bytes;
v2_data.SerializeToString(&v2_bytes);
// 2. v1 反序列化v2 数据 → 产生未知字段
UserInfoV1 v1_data;
v1_data.ParseFromString(v2_bytes);
std::cout << "v1解析结果:id=" << v1_data.id() << ", name=" << v1_data.name() << std::endl;
// 3. 获取未知字段字节数(旧版本正确写法)
std::string unknown_str;
v1_data.unknown_fields().SerializeToString(&unknown_str); // 旧版用这个
std::cout << "v1中未知字段字节数:" << unknown_str.size() << std::endl;
// 4. v1 序列化(保留未知字段)
std::string v1_bytes;
v1_data.SerializeToString(&v1_bytes);
// 5. v2 反序列化→ 恢复 age 字段
UserInfoV2 v2_data2;
v2_data2.ParseFromString(v1_bytes);
std::cout << "v2解析结果:age=" << v2_data2.age() << std::endl;
google::protobuf::ShutdownProtobufLibrary();
return 0;
}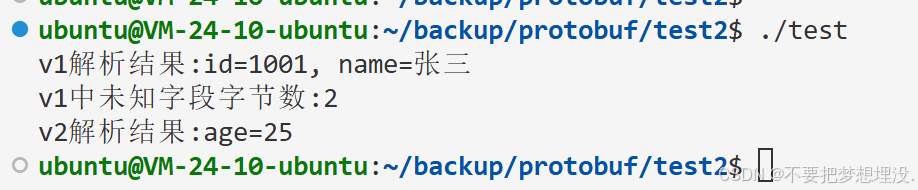
UserInfoV1(后续简称v1)比 UserInfoV2(后续简称v2)少一个字段
v2对象序列化之后v1反序列化 解析不了自己没有的字段(未知字段) 这个勉强能理解
但是为什么v1对象序列化之后 v2却能反序列化得到v1不存在的字段呢???
核心原因:Protobuf 的未知字段保留机制(这是它向后兼容的关键),用通俗的话给你讲明白,结合你的 proto 和代码,一点不复杂:
1. 先搞懂:V1 解析 V2 数据时,没定义的 age 字段去哪了?
你的 V1 只定义了 id(字段号 1)、name(字段号 2),而 V2 新增了 age(字段号 3)。
当 V2 序列化数据(包含 id=1001、name = 张三、age=25)后,会把「字段号 + 字段类型 + 字段值」一起编码成二进制(比如 age=25 会编码成「字段号 3 + 类型 int32 + 值 25」的二进制字节)。
当 V1 去解析这个二进制数据时:
- 能识别字段号 1(id)、字段号 2(name),会正常解析并存储;
- 不认识字段号 3(age),不会丢弃这个字段 ,而是把它的「字段号 + 类型 + 值」的二进制字节,存到 V1 消息的「未知字段集合」(就是你代码里的
unknown_fields())中。
简单说:V1 虽然 "看不懂" age,但会把它的二进制数据 "存起来",不弄丢。
2. 再明白:V2 为啥能反序列化出 V1 保存的 age 值?
你的代码里,V1 解析完 V2 数据后,又做了一步「V1 序列化」(v1_data.SerializeToString(&v1_bytes))。这一步的关键:V1 序列化时,会把自己的已知字段(id、name)和保存的未知字段(age 的二进制),一起序列化到二进制数据里。
当 V2 去解析这个 V1 序列化后的二进制数据时:
- 能识别字段号 1(id)、字段号 2(name),正常解析;
- 能识别字段号 3(age)------ 因为 V2 定义了这个字段,所以会从二进制数据里,找到 V1 保存的「字段号 3 + 类型 + 值 25」,解析出 age=25。
单纯 V1 序列化(V1 本身没有任何未知字段),V2 反序列化后,不会解析出任何 "额外的未知字段"(比如 age) ------ 因为 V1 本身就没有定义 age,也没有保存过任何未知字段,序列化后的数据里,只有 V1 自己的已知字段(id、name)。
2.前后兼容
- 向前兼容(重点,你代码里已体现)
就是 新版本数据,旧版本能正常解析(你代码里的核心场景):
对应你的情况:V2(有 age 字段)序列化的数据,V1(无 age 字段)能正常解析,不会报错。
原理:V1 虽然没有 age 定义,但会把 age 对应的二进制数据(字段 3)当作「未知字段」保存起来,不丢弃、不报错,
这就是向前兼容的核心 ------新版本新增的字段,不会影响旧版本的解析。
举个具体例子:你用 V2 生成的 "id=1001、name = 张三、age=25" 的数据,
用 V1 去解析,V1 虽然不认识 age,但会把 age 的二进制数据存起来,不会报错,还能正常解析自己认识的 id 和 name,这就是向前兼容(新版本数据适配旧版本)。
- 向后兼容(补充你可能用到的场景)
就是 旧版本数据,新版本能正常解析,还能恢复完整信息(你代码里的 V1 序列化后,V2 能解析出 age,就是向后兼容):
对应你的情况:V1 序列化的数据(包含之前保存的 age 未知字段),用 V2 去解析,能完整恢复出 age 的值(25),不会因为是 V1 生成的数据,V2 就解析不了。
原理:V1 保存了 age 的二进制数据,V2 认识 age 对应的字段号(3),所以能从 V1 序列化的数据里,把 age 解析出来,这就是向后兼容 ------旧版本数据,新版本能完整识别,不丢失信息。
不管是向前还是向后兼容,核心就 2 点,少一个都不行,代码里刚好都满足:
字段号不重复、不修改:你 V1 的 id(字段 1)、name(字段 2),V2 新增的 age(字段 3),
字段号都是唯一的,没有重复,也没有修改原有字段的字段号 ------ 这是兼容的基础(如果把 id 的
字段号改成 3,V1 就解析不了 V2 的数据了)。
未知字段不丢弃:V1 解析 V2 数据时,没有扔掉不认识的 age 字段,而是保存为未知字段,后续序列化时一起带出 ------ 这是向后兼容能实现的关键(如果 V1 直接扔掉 age 的数据,V2 就解析不出 age 了)
不兼容的情况(你不用踩坑):如果后续修改字段号(比如把 age 的字段号改成 2,和 name 重复),或者修改原有字段的类型(比如把 id 改成字符串),就会破坏兼容,旧版本就解析不了了。
3.reserved
一、reserved 字段的核心作用(一句话总结)
reserved 用于 "预留 / 禁用" 指定的字段号或字段名,防止后续版本误使用这些字段,从而保护 Protobuf 的前后兼容性 ------ 简单说,就是给 "不能用" 的字段号 / 名字 "上锁",避免踩坑。
二、结合 V1/V2 场景,讲 2 个最常用的作用(你大概率会用到)
作用 1:禁用 "废弃的字段号",防止后续误复用
假设你后续迭代,想把 V2 的 age=3 字段删掉(比如不用这个字段了),如果直接删掉,后续有人不知情,可能会新增一个新字段,又用了字段号 3 ------ 这就会破坏兼容(比如旧版本 V1 保存的、原来 age=3 的未知字段,会被新字段解析错,导致数据混乱)。
这时候用 reserved 禁用字段号 3,就能避免这种问题:
bash
// 迭代后的 V3 版本(删掉了 age 字段,用 reserved 禁用字段号3)
message UserInfoV3 {
int64 id = 1;
string name = 2;
reserved 3; // 禁用字段号3,后续不能再用这个字段号定义任何字段
}这样一来,不管谁后续修改这个 proto,只要用字段号 3,编译就会报错,从根源上避免兼容问题。
作用 2:预留字段号,为后续版本升级做准备
假设你现在做 V1,知道以后可能会新增 2 个字段,但暂时用不到,就可以用 reserved 预留几个字段号,防止其他人误占用:
protobuf
bash
// V1 版本,预留字段号3、4,后续升级时用
message UserInfoV1 {
int64 id = 1;
string name = 2;
reserved 3,4; // 预留字段号3和4,现在不用,后续新增字段时优先用这两个
}后续升级到 V2 时,就可以直接用预留的字段号 3 定义 age,不用怕和其他字段冲突,也能保证兼容。
三、关键注意事项(结合你的兼容场景,必看)
- reserved 可以同时禁用「字段号」和「字段名」,比如:
reserved 3, "age";------ 既不能用字段号 3,也不能用 "age" 这个名字,双重保护。 - 一旦用 reserved 禁用了字段号 / 名字,后续任何版本都不能再使用(哪怕你后悔了,也不能复用),否则会破坏前后兼容(比如旧版本保存的未知字段会被解析错误)。
- 结合你之前的未知字段机制:如果旧版本(V1)保存了某个字段号的未知字段,后续新版本用 reserved 禁用了这个字段号,那么新版本解析旧版本数据时,会自动忽略这个未知字段(不会报错,但也不会解析,避免数据混乱)。
- 不要和 existing 字段冲突:比如你 V2 已经用了字段号 3(age),就不能再写
reserved 3;------ 编译会直接报错,必须先删除原字段,再用 reserved 禁用。
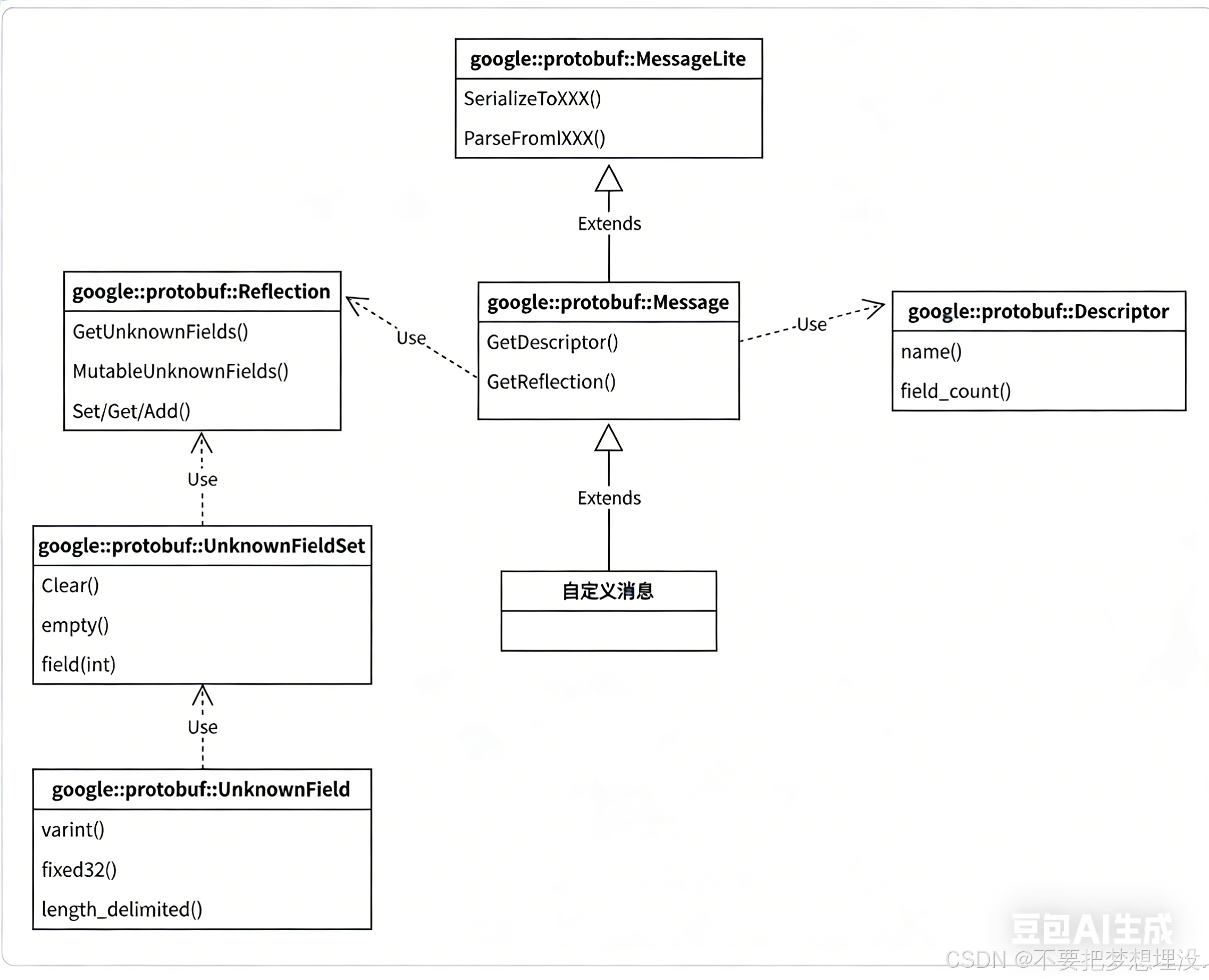
google::protobuf::MessageLite
所有 Protobuf 消息的「根类」,最基础的抽象
google::protobuf::Message
继承关系:继承自 MessageLite,在基础序列化上增加了反射 + 元数据能力
google::protobuf::Descriptor
作用:存储消息的静态元数据(比如 "这个消息叫什么?有几个字段?每个字段的号 / 类型 / 名字是什么?")。
google::protobuf::Reflection
作用:Protobuf 动态编程的核心!可以在运行时读写消息的字段,
google::protobuf::UnknownFieldSet
作用:存储消息里所有「不认识的字段」的二进制数据(比如 V1 解析 V2 时的 age 字段),是未知字段的容器。
google::protobuf::UnknownField
作用:存储单个未知字段的原始二进制数据,根据字段类型有不同的存储形式。
MessageLite 提供基础序列化能力。
Message + Reflection + UnknownFieldSet 实现了「未知字段保留」------ 旧版本不认识的字段不会丢,会被保存并传递。
Descriptor 提供元数据,让 Protobuf 能在运行时知道 "每个字段是什么"。
实际上我们是通过
google::protobuf::Reflection 中的
GetUnknownFields()接口可以得到google::protobuf::UnknownFieldSet
然后可以得到UnknownField 每一个单独未知字段的所有信息
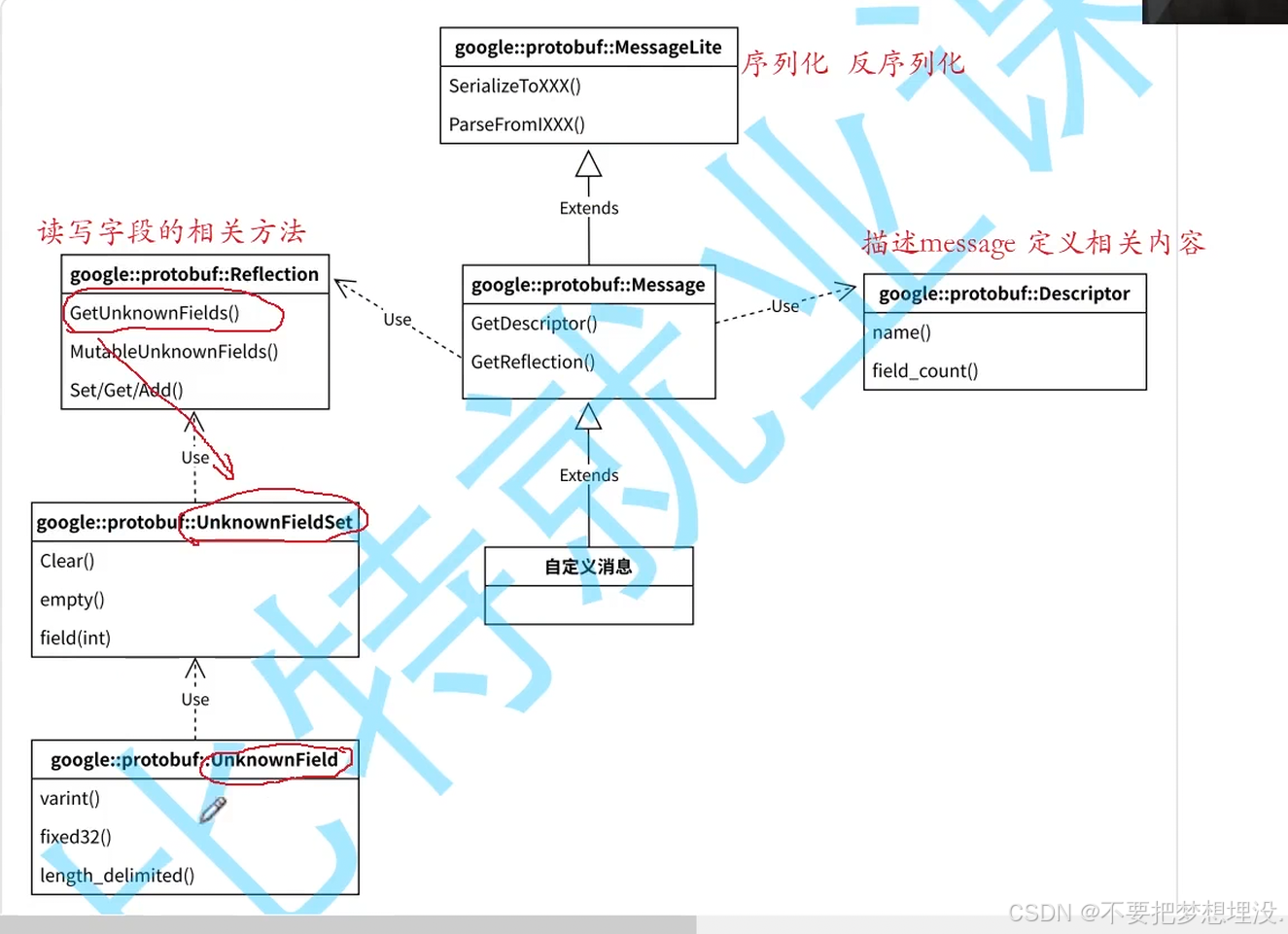

未知字段(UnknownField)的类型枚举与对应访问方法的映射关系,是处理 protobuf 未知字段的核心接口说明。
1. 左侧:Type 枚举(未知字段的 wire type)
它定义了 protobuf 未知字段的 5 种基础线类型(wire type),对应不同的二进制编码格式:
TYPE_VARINT:可变长整数编码(如int32、sint64、bool等类型的底层编码)TYPE_FIXED32:32 位固定长度编码(如fixed32、float)TYPE_FIXED64:64 位固定长度编码(如fixed64、double)TYPE_LENGTH_DELIMITED:长度分隔编码(如string、bytes、嵌套 message、packed 重复字段)TYPE_GROUP:旧版分组编码(protobuf 早期语法,现已极少使用,对应嵌套的字段组)
2. 右侧:UnknownField 访问方法
每个方法与左侧的 Type 枚举一一对应,用于读取对应类型的未知字段值:
varint():读取TYPE_VARINT类型的未知字段,返回uint64_tfixed32():读取TYPE_FIXED32类型的未知字段,返回uint32_tfixed64():读取TYPE_FIXED64类型的未知字段,返回uint64_tlength_delimited():读取TYPE_LENGTH_DELIMITED类型的未知字段,返回const std::string&(存储二进制数据或字符串)group():读取TYPE_GROUP类型的未知字段,返回const UnknownFieldSet&(嵌套的未知字段集合)
3. 核心作用
当 protobuf 解析一个包含未知字段 (即当前 .proto 文件中未定义的字段,通常是新版本消息新增的字段)的消息时,会将这些字段暂存到 UnknownFieldSet 中。
开发者可以通过 Reflection 接口获取 UnknownFieldSet,遍历其中的 UnknownField,再根据其 Type 调用右侧对应的方法,读取和处理这些未知字段数据,从而实现向前兼容(旧版本代码可以完整保留新版本消息中新增的字段数据,避免数据丢失)。
4.optimize_for
bash
option optimize_for = SPEED; // 默认值三个可选值及核心差异
| 取值 | 中文释义 | 核心特点 | 适用场景 |
|---|---|---|---|
SPEED(默认) |
速度优先 | 1. 生成的代码包含大量手写风格的序列化 / 反序列化逻辑,运行速度最快;2. 生成的代码体积最大;3. 依赖完整的 Protobuf 核心运行时库 | 绝大多数服务端 / 高性能场景(如高频 RPC 调用、大数据解析),是最常用的选择 |
CODE_SIZE |
代码体积优先 | 1. 生成的代码复用通用的反射(Reflection)逻辑完成序列化 / 反序列化,代码体积最小 ;2. 运行速度比 SPEED 慢(需通过反射动态处理字段);3. 依赖完整运行时库 |
嵌入式设备、移动端(安装包体积敏感)、低频调用的轻量场景 |
LITE_RUNTIME |
轻量运行时优先 | 1. 生成的代码体积较小,且运行速度接近 SPEED;2. 仅依赖轻量级的 protobuf-lite 库(剔除了反射、未知字段处理等高级功能);3. 不支持 Reflection、UnknownFieldSet 等特性 |
移动端(Android/iOS)、对运行时体积和性能都有要求的场景(需注意:使用该选项后,依赖反射的功能会失效) |
3. 关键注意事项
- proto3 兼容性 :proto3 简化了代码生成逻辑,移除了
optimize_for,默认采用类似SPEED的优化策略,且不再区分 lite 运行时(如需轻量版需单独引入protobuf-lite库); - 跨语言影响:该选项主要影响 C++ 代码生成,Java/Go 等语言的 Protobuf 实现已内置优化,无需配置此选项;
- 功能限制 :选择
LITE_RUNTIME后,无法使用反射(Reflection)、未知字段(UnknownFieldSet)、动态消息(DynamicMessage)等高级功能。
optimize_for : 该选项为⽂件选项,可以设置 protoc 编译器的优化级别,分别为 SPEED 、
CODE_SIZE 、 LITE_RUNTIME 。受该选项影响,设置不同的优化级别,编译 .proto ⽂件后⽣
成的代码内容不同。
bash
syntax="proto3";
//option optimize_for =LITE_RUNTIME;
//option optimize_for =SPEED;
message people{
string name =1;
}option optimize_for =LITE_RUNTIME;

option optimize_for =SPEED;

我们发现我们选择不同的ptimize_for
得到的方法所继承的父类是不同的
ProtoBuf 允许⾃定义选项并使⽤。该功能⼤部分场景⽤不到,在这⾥不拓展讲解
5.json protobuf xml对比
cpp
#include <iostream>
#include <chrono>
#include <string>
#include <cstdlib>
#include <functional>
// XML 解析库
#include "tinyxml2.h"
// 高性能 JSON 库:RapidJSON(替换原 nlohmann/json)
#include "rapidjson/document.h"
#include "rapidjson/writer.h"
#include "rapidjson/stringbuffer.h"
// Protobuf 生成的头文件(编译后生成)
#include "person.pb.h"
using namespace std;
using namespace chrono;
using namespace tinyxml2;
using namespace rapidjson;
using namespace test;
// 统一的测试数据结构
struct TestPerson {
int id;
string name;
int age;
// 初始化测试数据
TestPerson() : id(123), name("test_user"), age(25) {}
};
/**
* 通用计时工具函数:执行指定函数指定次数,返回总耗时(毫秒)
* @param func 要执行的函数
* @param iterations 执行次数
* @return 总耗时(毫秒)
*/
template <typename Func>
double measureTime(Func func, int iterations) {
auto start = high_resolution_clock::now();
for (int i = 0; i < iterations; ++i) {
func(); // 执行目标操作
}
auto end = high_resolution_clock::now();
duration<double, milli> total = end - start;
return total.count();
}
// -------------------------- XML 序列化/反序列化 --------------------------
string xmlSerialize(const TestPerson& p) {
XMLDocument doc;
XMLElement* root = doc.NewElement("Person");
doc.InsertFirstChild(root);
root->SetAttribute("id", p.id);
XMLElement* nameNode = doc.NewElement("Name");
nameNode->SetText(p.name.c_str());
root->InsertEndChild(nameNode);
XMLElement* ageNode = doc.NewElement("Age");
ageNode->SetText(p.age);
root->InsertEndChild(ageNode);
XMLPrinter printer;
doc.Print(&printer);
return printer.CStr();
}
TestPerson xmlDeserialize(const string& xmlStr) {
TestPerson p;
XMLDocument doc;
doc.Parse(xmlStr.c_str());
XMLElement* root = doc.FirstChildElement("Person");
if (root) {
p.id = root->IntAttribute("id");
XMLElement* nameNode = root->FirstChildElement("Name");
if (nameNode) p.name = nameNode->GetText();
XMLElement* ageNode = root->FirstChildElement("Age");
if (ageNode) p.age = ageNode->IntText();
}
return p;
}
// -------------------------- JSON 序列化/反序列化(RapidJSON 版) --------------------------
string jsonSerialize(const TestPerson& p) {
StringBuffer s;
Writer<StringBuffer> writer(s);
// 开始构建 JSON 对象
writer.StartObject();
// 写入 id(整数)
writer.Key("id");
writer.Int(p.id);
// 写入 name(字符串)
writer.Key("name");
writer.String(p.name.c_str());
// 写入 age(整数)
writer.Key("age");
writer.Int(p.age);
// 结束 JSON 对象
writer.EndObject();
// 返回 JSON 字符串
return s.GetString();
}
TestPerson jsonDeserialize(const string& jsonStr) {
TestPerson p;
Document doc;
// 解析 JSON 字符串(无额外分配,高性能)
doc.Parse(jsonStr.c_str());
// 读取字段(RapidJSON 直接访问,无类型转换开销)
if (doc.HasMember("id") && doc["id"].IsInt()) {
p.id = doc["id"].GetInt();
}
if (doc.HasMember("name") && doc["name"].IsString()) {
p.name = doc["name"].GetString();
}
if (doc.HasMember("age") && doc["age"].IsInt()) {
p.age = doc["age"].GetInt();
}
return p;
}
// -------------------------- Protobuf 序列化/反序列化 --------------------------
string protoSerialize(const TestPerson& p) {
Person proto_p;
proto_p.set_id(p.id);
proto_p.set_name(p.name);
proto_p.set_age(p.age);
string data;
// 显式忽略返回值,消除编译警告
(void)proto_p.SerializeToString(&data);
return data;
}
TestPerson protoDeserialize(const string& protoStr) {
TestPerson p;
Person proto_p;
// 显式忽略返回值,消除编译警告
(void)proto_p.ParseFromString(protoStr);
p.id = proto_p.id();
p.name = proto_p.name();
p.age = proto_p.age();
return p;
}
/**
* 执行单次格式的效率测试(拆分序列化/反序列化时间 + 打印序列化大小)
* @param formatName 格式名称(XML/JSON/Protobuf)
* @param serialize 序列化函数
* @param deserialize 反序列化函数
* @param testData 测试数据
* @param iterations 执行次数
*/
void runTest(const string& formatName,
function<string(const TestPerson&)> serialize,
function<TestPerson(const string&)> deserialize,
const TestPerson& testData,
int iterations) {
// 预先生成序列化数据(用于反序列化计时 + 计算序列化大小)
string preSerialized = serialize(testData);
// 计算序列化后数据的字节大小
size_t serializedSize = preSerialized.size();
// ========== 1. 单独计算序列化耗时 ==========
double serializeTime = measureTime([&]() {
// 仅执行序列化操作
string serialized = serialize(testData);
// 空操作,仅保证序列化逻辑执行
(void)serialized;
}, iterations);
// ========== 2. 单独计算反序列化耗时 ==========
double deserializeTime = measureTime([&]() {
// 仅执行反序列化操作
TestPerson deserialized = deserialize(preSerialized);
// 数据验证(确保反序列化逻辑正确)
if (deserialized.id != testData.id || deserialized.name != testData.name || deserialized.age != testData.age) {
cerr << formatName << " 反序列化数据错误!" << endl;
exit(1);
}
}, iterations);
// ========== 打印结果(新增序列化大小) ==========
cout << " " << formatName << ":" << endl;
cout << " 序列化后数据大小: " << serializedSize << " 字节" << endl;
cout << " 序列化总耗时: " << serializeTime << " 毫秒" << endl;
cout << " 反序列化总耗时: " << deserializeTime << " 毫秒" << endl;
}
int main() {
// 初始化Protobuf(必须)
GOOGLE_PROTOBUF_VERIFY_VERSION;
TestPerson testData;
// 测试次数列表
int testIterations[] = {100, 10000, 1000000};
// 遍历测试次数,执行所有格式的测试
for (int iter : testIterations) {
cout << "\n===== 测试次数: " << iter << " =====\n";
runTest("XML", xmlSerialize, xmlDeserialize, testData, iter);
runTest("JSON", jsonSerialize, jsonDeserialize, testData, iter);
runTest("Protobuf", protoSerialize, protoDeserialize, testData, iter);
}
// 清理Protobuf资源
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
- 序列化阶段 :JSON 已经比 XML 快了(比如 100 万次:JSON 序列化
1471.64ms< XML 序列化1587.43ms) - 反序列化阶段 :JSON 依然比 XML 慢(100 万次:JSON 反序列化
4367.61ms> XML 反序列化1780.73ms)
这说明 RapidJSON 的序列化已经优化到位,但反序列化在小数据场景下仍不如 tinyxml2,核心原因有几个:
🔍 为什么 JSON 反序列化还是比 XML 慢?
- 测试数据太小,库的「固定开销」被放大
你的测试数据只有 3 个字段(id=123、name="test_user"、age=25),数据量极小:
-
tinyxml2 :XML 结构简单,
Parse()是轻量级流式解析,直接遍历节点、读取属性 / 文本,几乎没有额外校验开销,小数据下效率极高。 -
RapidJSON :即使是极小的 JSON,
Parse()也要做完整的语法校验:-
识别
{}/:/""等符号边界 -
区分数字、字符串、对象类型
-
构建 DOM 树并做内存分配这些固定开销在小数据场景下占比极高,盖过了 JSON 格式本身的优势。
-
- tinyxml2 的反序列化逻辑更「极简」
-
tinyxml2 不做复杂类型校验:XML 里所有内容都是文本,
IntAttribute()/GetText()只是简单转换,没有类型安全检查。 -
RapidJSON 必须做严格类型校验:
HasMember()、IsInt()、GetInt()等操作需要在 DOM 树中查找键、验证类型,小对象下这些查找开销比 tinyxml2 的「直接节点访问」更重。
- 库的设计目标差异
-
tinyxml2:专为「轻量、快速」设计,代码精简,只保留 XML 核心功能,极端优化小数据处理。
-
RapidJSON:通用高性能 JSON 库,支持完整 JSON 标准(嵌套、数组、复杂类型),功能更全,所以在小数据场景下,额外功能的 overhead 会更明显。
| 序列化协议 | 通用性 | 格式 | 可读性 | 序列化大小 | 序列化性能 | 适用场景 |
|---|---|---|---|---|---|---|
| JSON | 通用(json、xml 已成为多种行业标准的编写工具) | 文本格式 | 好 | 轻量(使用键值对方式,压缩了一定的数据空间) | 中 | web 项目。因为浏览器对于 json 数据支持非常好,有很多内建的函数支持。 |
| XML | 通用 | 文本格式 | 好 | 重量(数据冗余,因为需要成对的闭合标签) | 低 | XML 作为一种扩展标记语言,衍生出了 HTML、RDF/RDFS,它强调数据结构化的能力和可读性。 |
| ProtoBuf | 独立(Protobuf 只是 Google 公司内部的工具) | 二进制格式 | 差(只能反序列化后得到真正可读的数据) | 轻量(比 JSON 更轻量,传输起来带宽和速度会有优化) | 高 | 适合高性能,对响应速度有要求的数据传输场景。Protobuf 比 XML、JSON 更小、更快。 |