引言
在图像处理中,模板匹配是一项基础且重要的技术。通过模板匹配,我们可以在目标图像中寻找与给定模板最相似的区域。银行卡号识别是计算机视觉中一个经典的应用场景,常用于自动化信息录入、金融身份验证等系统。由于银行卡号区域具有固定的字体、大小和排列方式,我们可以通过图像处理技术定位该区域,并利用模板匹配方法识别每个数字字符。
本文将基于OpenCV实现一个完整的银行卡号识别系统,主要包含以下模块:
-
数字模板的构建(从包含0-9数字的模板图片
kahao.png中提取数字) -
信用卡图像的预处理与卡号区域定位
-
数字分组与单个字符的分割
-
模板匹配识别数字
-
结果输出与可视化
代码将逐步解释每个环节,并重点剖析轮廓排序 、顶帽操作 和模板匹配 这几个关键用法。同时,我们也会借鉴参考文章中对max(contours, key=cv2.contourArea)的解析思路,深入理解Python高阶函数在OpenCV中的应用。
环境与依赖
-
Python 3.x
-
OpenCV(
cv2) -
NumPy(
np) -
argparse(用于命令行参数解析)
任务描述
给定一张信用卡图片(例如card1.png)和一张包含0-9数字的模板图片kahao.png,要求自动识别信用卡上的卡号,并输出:
-
信用卡类型(根据首数字判断,如4开头为Visa)
-
完整的卡号
-
在图像上绘制出卡号区域及识别结果
模板图片 (kahao.png) 示意:
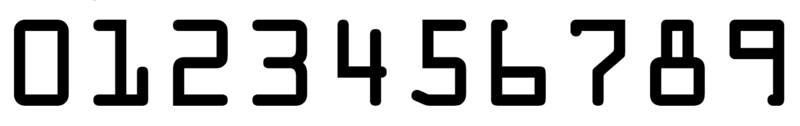
信用卡图片 (card1.png) 示例:

最终效果示意:

实现步骤详解
1. 工具函数准备
我们首先定义两个辅助函数(放在**myutils.py**中),用于轮廓排序和图像缩放。这些函数将在后续步骤中反复使用。
1.1 轮廓排序函数 sort_contours
import cv2
def sort_contours(cnts, method='left-to-right'):
reverse = False
i = 0
if method == 'right-to-left' or method == 'bottom-to-top':
reverse = True
if method == 'top-to-bottom' or method == 'bottom-to-top':
i = 1
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i], reverse=reverse))
return cnts, boundingBoxes代码解析:
-
cv2.boundingRect(c):计算轮廓c的最小外接矩形,返回(x, y, w, h)。 -
zip(cnts, boundingBoxes):将轮廓列表和对应的边界框列表打包成元组列表,每个元组为(轮廓, 边界框)。 -
sorted(..., key=lambda b: b[1][i]):根据边界框的x(i=0)或y(i=1)坐标排序。 -
zip(*...):将排序后的元组列表解包,重新得到两个列表:排序后的轮廓和排序后的边界框。
该函数根据指定方向(如从左到右)对轮廓列表排序,返回排序后的轮廓和对应的边界框。在识别卡号时,我们需要保证数字顺序正确。
1.2 图像缩放函数 resize
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized代码解析:
-
image.shape[:2]:获取图像的高度和宽度。 -
r = width / float(w):计算缩放比例。 -
cv2.resize(image, dim, interpolation=inter):执行缩放,inter默认为cv2.INTER_AREA(适用于图像缩小)。
该函数按指定宽度或高度等比例缩放图像,方便统一处理。
2. 数字模板构建(从kahao.png提取)
模板图片kahao.png包含0-9十个数字,我们需要从中提取每个数字的ROI,并缩放到统一尺寸(57×88),作为后续匹配的模板库。
2.1 读取模板图像并预处理
import cv2
import numpy as np
import argparse
import myutils
# 设置命令行参数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="path to input image") # 信用卡图片
ap.add_argument("-t", "--template", required=True, help="path to template image") # 模板图片
args = vars(ap.parse_args())
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
# 读取模板图像
img = cv2.imread(args["template"])
cv_show('img', img)
# 灰度化
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv_show('ref', ref)
# 二值化(黑底白字,方便找轮廓)
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
cv_show('ref', ref)代码解析:
-
argparse:用于解析命令行参数,使程序可以通过-i指定信用卡图片,-t指定模板图片,增加灵活性。 -
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY):将BGR彩色图像转换为灰度图,简化后续处理。 -
cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV):阈值10是一个较小的值,因为模板图片通常是黑白分明的。THRESH_BINARY_INV表示反色二值化,将原本的黑色数字变为白色(255),背景变为黑色(0),便于轮廓检测。
结果展示:

2.2 轮廓检测与排序
# 检测轮廓(只检测外轮廓)
_, refCnts, hierarchy = cv2.findContours(ref, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 在原图上绘制轮廓,检查效果
cv2.drawContours(img, refCnts, -1, (0, 0, 255), 3)
cv_show('refcnts', img)代码解析:
-
cv2.findContours(ref, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE):-
cv2.RETR_EXTERNAL:只检测最外层轮廓,忽略内部空洞。 -
cv2.CHAIN_APPROX_SIMPLE:压缩轮廓点,只保留端点(例如矩形只保留四个角点)。
-
-
OpenCV版本差异 :
cv2.findContours在不同版本中返回值个数不同。使用_, refCnts, hierarchy可以兼容新版本(返回3个值),旧版本可能只返回2个值。参考文章中使用[-2:]来兼容,这里我们明确新版本写法,如果遇到旧版本可调整。 -
cv2.drawContours(img, refCnts, -1, (0, 0, 255), 3):在图像上绘制所有轮廓,-1表示绘制所有轮廓,颜色红色,线宽3。
结果展示:

# 对轮廓从左到右排序
refCnts = myutils.sort_contours(refCnts, method="left-to-right")[0]
# 遍历每个轮廓,提取数字并保存
dig = {} # 字典,键为数字0-9,值为对应的模板图像
for (i, c) in enumerate(refCnts):
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y+h, x:x+w]
roi = cv2.resize(roi, (57, 88)) # 统一缩放到57x88
cv_show('roi', roi) # 可选:显示每个模板
dig[i] = roi # i从0开始,正好对应数字0-9代码解析:
-
enumerate(refCnts):同时获取索引i和轮廓c,i正好对应数字0-9。 -
cv2.boundingRect(c):获取轮廓的外接矩形坐标。 -
ref[y:y+h, x:x+w]:从灰度图ref中截取该矩形区域(即数字图像)。 -
cv2.resize(roi, (57, 88)):将截取的数字缩放到固定尺寸,保证与待识别字符尺寸一致。 -
为什么不用
max(contours, key=cv2.contourArea)?:在参考文章的花朵轮廓提取中,使用该方法获取最大轮廓。但这里我们需要所有数字轮廓,因此遍历全部。如果模板图片中有噪声轮廓,可以先用面积筛选,但本例假设模板干净。
部分roi展示:
3. 信用卡图像预处理
对输入的信用卡图片进行预处理,突出数字区域。
# 读取信用卡图像
image = cv2.imread(args["image"])
# 缩放至合适大小(宽度300像素)
image = myutils.resize(image, width=300)
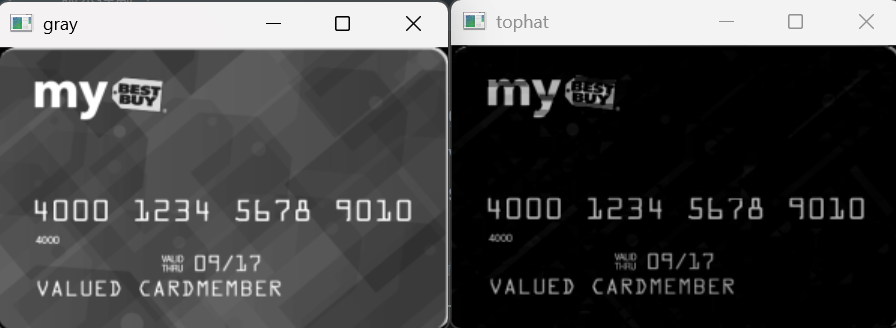
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv_show('gray', gray)
# 初始化卷积核
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3)) # 矩形核,用于连接数字
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 方形核,用于后续操作
# 顶帽运算:突出图像中的亮细节(即数字部分)
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
cv_show('tophat', tophat)代码解析:
-
cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3)):创建一个9x3的矩形结构元素,用于形态学操作。矩形形状适合连接横向排列的数字。 -
顶帽运算(MORPH_TOPHAT) :定义为
src - open(src, kernel)。开运算先腐蚀后膨胀,会消除图像中的亮细节。因此顶帽能提取出原图中较亮的部分,非常适合增强银行卡号这种较亮的区域,同时抑制背景。
结果展示:
4. 定位数字区域
通过闭运算将相邻的数字连接成一个整体,然后二值化、筛选轮廓,找到四组数字区域。
# 闭操作:将数字连接成一块
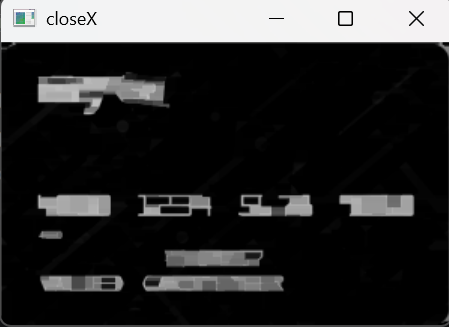
closeX = cv2.morphologyEx(tophat, cv2.MORPH_CLOSE, rectKernel)
cv_show('closeX', closeX)代码解析:
- 闭运算(MORPH_CLOSE):先膨胀后腐蚀,可以填充物体内部的小空洞,连接邻近的物体。这里用9x3的矩形核,目的是将同一组内横向排列的4个数字连接成一个连通的区域。
结果展示:
# 二值化(使用OTSU自动阈值)
thresh = cv2.threshold(closeX, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('thresh', thresh)代码解析:
-
cv2.THRESH_OTSU:大津法自动寻找最优阈值,适合图像直方图呈双峰分布的情况。这里将阈值参数设为0,实际由OTSU自动确定。 -
cv2.THRESH_BINARY:二值化类型,大于阈值的设为255,否则为0。
结果展示:

# 再执行一次闭操作,填补空洞
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
cv_show('close2', thresh)
# 查找轮廓
_, cnts, h = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制所有轮廓,查看效果
cnts_img = image.copy()
cv2.drawContours(cnts_img, cnts, -1, (0, 0, 255), 3)
cv_show('cnts_img', cnts_img)结果展示:
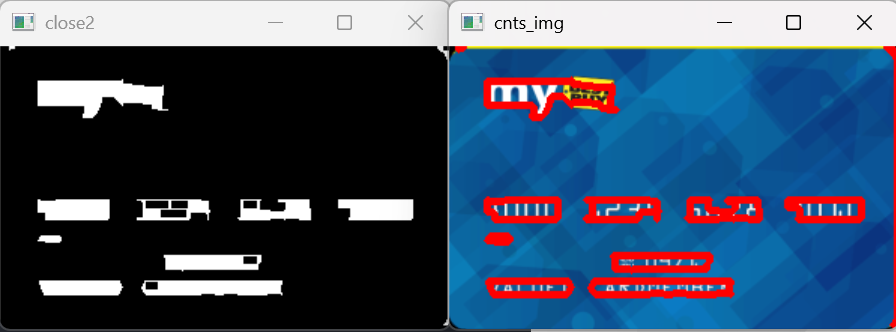
# 筛选轮廓:根据宽高比和尺寸,保留数字组区域
locs = []
for c in cnts:
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
if 2.5 < ar < 4: # 宽高比范围(银行卡号组通常较宽扁)
if (40 < w < 55) and (10 < h < 20): # 根据实际图像调整的尺寸范围
locs.append((x, y, w, h))
# 按x坐标从左到右排序
locs = sorted(locs, key=lambda x: x[0])
print(locs)代码解析:
-
宽高比筛选:银行卡号一般由4组数字组成,每组4个数字。在预处理后的图像中,每组数字形成一个较宽的矩形,宽高比大致在2.5~4之间。
-
尺寸筛选:宽度约40~55像素,高度10~20像素(取决于图像缩放比例)。这些参数可根据实际图像微调。
-
sorted(locs, key=lambda x: x[0]):按边界框的x坐标排序,确保四组数字从左到右排列。
5. 数字分割与识别
对每组数字区域,进一步分割出单个数字,并与模板进行匹配。
output = [] # 存储所有识别出的数字
for (gx, gy, gw, gh) in locs:
groupOutput = []
# 提取当前组区域,并适当扩大边界
group = gray[gy-5:gy+gh+5, gx-5:gx+gw+5]
cv_show('group', group)
# 对该区域进行二值化
group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('group', group)
# 查找轮廓(每个数字)
_, digitCnts, hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 对数字轮廓从左到右排序
digitCnts = myutils.sort_contours(digitCnts, method="left-to-right")[0]代码解析:
-
group = gray[gy-5:gy+gh+5, gx-5:gx+gw+5]:在原灰度图上截取当前组区域,并向外扩展5个像素,避免因轮廓检测不精确而切掉数字边缘。 -
cv2.threshold(..., cv2.THRESH_OTSU):对组内区域再次二值化,确保数字清晰。 -
cv2.findContours:查找组内每个数字的轮廓。 -
myutils.sort_contours:对组内数字轮廓从左到右排序。遍历每个数字轮廓
for c in digitCnts: (x, y, w, h) = cv2.boundingRect(c) roi = group[y:y+h, x:x+w] roi = cv2.resize(roi, (57, 88)) # 缩放到与模板相同尺寸 cv_show('roi', roi) # 模板匹配计算得分 scores = [] for (digit, digitROI) in dig.items(): result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF) (_, score, _, _) = cv2.minMaxLoc(result) scores.append(score) # 取最高得分对应的数字 groupOutput.append(str(np.argmax(scores)))
代码解析:
-
cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF):使用相关系数法进行模板匹配,返回值越大表示匹配度越高。 -
cv2.minMaxLoc(result):返回匹配结果矩阵的最小值、最大值及其位置。这里我们只关心最大值score。 -
np.argmax(scores):从10个得分中找出最大值的索引,该索引正好对应数字0-9。
部分结果展示:
# 在原图上绘制矩形框并标注数字
cv2.rectangle(image, (gx-5, gy-5), (gx+gw+5, gy+gh+5), (0, 255, 0), 1)
cv2.putText(image, "".join(groupOutput), (gx, gy-15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 255, 0), 1)
output.extend(groupOutput)
# 根据卡号首数字判断类型
FIRST_NUMBER = {
"3": "American Express",
"4": "Visa",
"5": "MasterCard",
"6": "Discover"
}
print("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))
print("Credit Card #: {}".format("".join(output)))
# 显示最终结果
cv2.imshow("Image", image)
cv2.waitKey(0)
cv2.destroyAllWindows()代码解析:
-
cv2.rectangle(image, (gx-5, gy-5), (gx+gw+5, gy+gh+5), (0, 255, 0), 1):在原图上绘制绿色矩形框,标注卡号组区域。 -
cv2.putText(...):在矩形框上方标注识别出的四个数字。 -
FIRST_NUMBER[output[0]]:根据卡号第一位数字判断发卡行类型。
结果展示:

关键点解析
1. 轮廓排序函数 sort_contours 的设计
该函数的设计思想是:通过cv2.boundingRect获取每个轮廓的外接矩形,然后利用Python内置的sorted函数,配合key参数指定按矩形的x或y坐标排序。代码中的zip和*操作符用于打包和解包,非常巧妙。
等价实现:如果不使用这个函数,我们可以手动排序:
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
# 按x坐标排序
sorted_indices = sorted(range(len(cnts)), key=lambda i: boundingBoxes[i][0])
sorted_cnts = [cnts[i] for i in sorted_indices]但使用sort_contours更加简洁通用,且同时返回排序后的边界框。
2. max(contours, key=cv2.contourArea) 的用法(参考文章亮点)
在参考文章的花朵轮廓提取中,使用了max(contours, key=cv2.contourArea)来获取面积最大的轮廓。这一用法同样适用于本项目的数字模板提取------如果我们只想保留最大的数字轮廓(虽然本例中所有轮廓都要保留)。理解key参数是关键:
-
contours是一个列表,每个元素是一个轮廓(NumPy数组)。 -
max()是Python内置函数,用于返回可迭代对象中的最大值。 -
key=cv2.contourArea指定了一个"键函数":在比较每个轮廓时,先用cv2.contourArea计算该轮廓的面积,然后根据面积大小决定哪个轮廓最大。
等价代码:
max_area = 0
max_contour = None
for c in contours:
area = cv2.contourArea(c)
if area > max_area:
max_area = area
max_contour = c这种写法体现了Python函数式编程的简洁性,也是OpenCV与Python结合的精髓之一。
3. 顶帽操作(MORPH_TOPHAT)的原理与应用
顶帽运算定义为:src - open(src, kernel)。其中open是开运算(先腐蚀后膨胀),可以消除亮细节。因此顶帽能提取出原图中较亮的部分,非常适合增强银行卡号这种较亮的区域,同时抑制背景。
在代码中,我们对灰度图进行顶帽运算:
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)这里使用9x3的矩形核,因为数字是横向排列的,矩形核有助于增强横向特征。
4. 闭操作连接数字
闭运算(先膨胀后腐蚀)可以填充物体内部的小空洞,连接邻近的物体。我们两次使用闭操作:
-
第一次用
rectKernel连接同一组内的数字,使其形成连通的块。 -
第二次用
sqKernel填补二值化后可能出现的空洞,使轮廓更完整。
5. 模板匹配方法选择
cv2.matchTemplate支持多种方法,如TM_CCOEFF、TM_CCORR、TM_SQDIFF等。我们选择TM_CCOEFF(相关系数法),因为:
-
它对线性光照变化有一定鲁棒性。
-
结果值越大表示匹配越好,便于取最大值。
-
与
TM_CCOEFF_NORMED相比,非归一化版本计算更快,且在本场景下效果足够。
6. 窗口显示管理
cv2.waitKey(0)等待用户按键,cv2.destroyAllWindows()关闭所有窗口。注意不要在显示前调用destroyAllWindows,否则窗口会立即关闭。
运行结果与讨论
运行上述代码(假设card1.png和kahao.png已准备),将依次弹出多个窗口显示中间处理步骤,最终输出类似:
text
Credit Card Type: Visa
Credit Card #: 4000123456789010并在图像上绿色框出卡号区域,上方标注数字。
可能遇到的问题及改进
-
光照不均:如果信用卡照片光照过暗或不均,顶帽操作可能效果不佳。可尝试使用自适应直方图均衡化(CLAHE)预处理。
-
数字粘连:如果数字之间间隙过小,闭操作后可能无法分开单个数字。可调整卷积核大小或使用形态学梯度辅助分割。
-
模板泛化能力:模板图片的字体应与目标卡号字体一致,否则匹配效果会下降。可以制作多种字体的模板库,或使用深度学习OCR方法。
-
阈值参数:代码中的阈值(如10、宽高比范围)是经验值,实际应用中需要根据具体图像调整。建议增加滑动条调试,或使用机器学习自动确定。
总结
本文通过一个完整的银行卡号识别示例,展示了OpenCV在图像处理中的典型应用流程:
-
模板构建:从模板图像中提取数字轮廓,排序并统一尺寸。
-
图像预处理:灰度化、顶帽运算突出数字区域。
-
区域定位:闭操作连接数字、二值化、轮廓筛选找到四组数字。
-
数字分割与识别:对每组数字进一步分割,与模板匹配,获取数字序列。
-
结果输出:绘制矩形框、标注数字,输出卡号和类型。
重点剖析了轮廓排序 、顶帽操作 和模板匹配 的实现细节,并借鉴参考文章对max(contours, key=cv2.contourArea)的解析,帮助读者理解Python高阶函数在OpenCV中的应用。该方案简单高效,适合作为入门级项目实践。读者可根据实际场景优化预处理参数,提升识别鲁棒性。
希望这篇文章对你在图像处理和字符识别方面有所帮助!如果有任何问题或建议,欢迎留言讨论。
注意 :实际运行代码时,请确保kahao.png和信用卡图片存在,并根据图像调整阈值和尺寸范围。