map & set
目录
[map & set](#map & set)
一、序列式容器和关联式容器
1.1.序列式容器
string,vector,list,deque,array,forward_list...
**逻辑结构:**线性
1.2.关联式容器
map,set,unordered_map,unordered_set
**逻辑结构:**非线性
map和set的底层为红黑树,是一颗平衡二叉搜索树
- set是key搜索场景的结构
- map是key/value搜索场景的结构
二、set系列的使用
2.1.set容器

**T:**set底层关键字的类型
**比较方法:**默认T支持小于比较
(注:如果想按自己的需求,可以手动实现仿函数传给第二个模板参数)
**存储数据内存:**从空间适配器中申请
(注:可以自己实现内存池,传给第三个参数)
**底层:**红黑树
**增删查效率:**O(logN)
**迭代器遍历:**搜索树的中序
2.2.set的构造和迭代器
set的构造
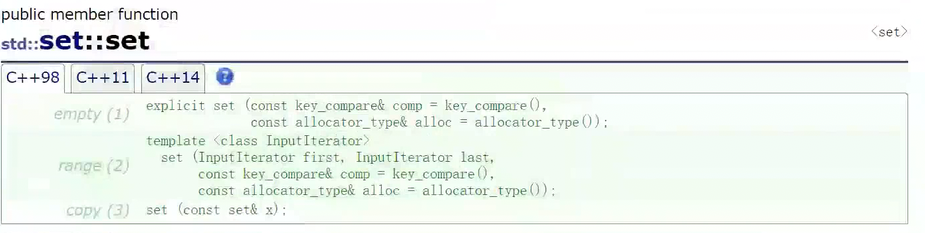
无参默认构造
cpp
explicit set(const key_compare & comp = key_compare(),const allocator_type & alloc = allocator_type());迭代器区间构造
cpp
template < class InputIterator>
set(InputIterator first, InputIterator last,const key_compare & comp = key_compare(),const allocator_type & = allocator_type());拷贝构造
cpp
set (const set& x);初始化列表构造
cpp
set(initializer_list<value_type> il,const key_compare & comp = key_compare(),const allocator_type & alloc = allocator_type());set的迭代器
双向迭代器
cpp
iterator->a bidirectional iterator to const value_type正向迭代器
cpp
iterator begin();
iterator end();反向迭代器
cpp
reverse_iterator rbegin();
reverse_iterator rend();2.3.set的增删查

单值插入
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
set<int> s1;
//去重+升序
s1.insert(5);
s1.insert(2);
s1.insert(7);
s1.insert(5);
s1.insert(3);
//去重+降序
set<int, greater<int>> s2;
s2.insert(5);
s2.insert(2);
s2.insert(7);
s2.insert(5);
s2.insert(3);
//升序打印
set<int>::iterator it1 = s1.begin();
while (it1 != s1.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
//降序打印
set<int, greater<int>>::iterator it2 = s2.begin();
while (it2 != s2.end())
{
cout << *it2 << " ";
++it2;
}
cout << endl;
return 0;
}**注:**如果已经存在则插入失败
列表插入
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
set<int> s3;
s3.insert({ 2,8,3,3,9 });
for (auto e : s3)
{
cout << e << " ";
}
cout << endl;
return 0;
}**注:**已经在容器中存在的值不会插入
字符串插入
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
set<string> strset = {"sort","insert","add"};
for (auto& e : strset)
{
cout << e << " ";
}
cout << endl;
return 0;
}**注:**按ASCII码进行比较

删除最小值
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
set<int> s = { 4,2,7,2,8,5,9 };
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
//删除最小值
s.erase(s.begin());
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
return 0;
}删除输入值
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
set<int> s = { 4,2,7,2,8,5,9 };
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
//直接删除x
int x;
cin >> x;
int num = s.erase(x);
if (num == 0)
{
cout << x << "不存在!" << endl;
}
else
{
cout << "删除成功!" << endl;
}
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
return 0;
}查找+迭代器删除
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
set<int> s = { 4,2,7,2,8,5,9 };
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
//直接查找在利用迭代器删除x
int x;
cin >> x;
auto pos = s.find(x);
if (pos != s.end())
{
s.erase(pos);
}
else
{
cout << x << "不存在!" << endl;
}
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
return 0;
}**注:**删除后的pos迭代器会失效
两种查找方法
cpp
int main()
{
set<int> s({2,3,5,4,8,7});
int x;
//算法库的查找O(N)
auto pos1 = find(s.begin(), s.end(), x);
//set自身实现的查找O(logN)
auto pos2 = s.find(x);
//利用count间接实现快速查找
cin >> x;
if (s.count(x))
{
cout << x << "在!" << endl;
}
else
{
cout << x << "不存在!" << endl;
}
return 0;
}区间查找删除
lower_bound
返回大于等于val位置的迭代器
cpp
iterator lower_bound(const value_type& val) const;upper_bound
返回大于val位置的迭代器
cpp
iterator upper_bound(const value_type val) const;**示例:**删除某个区间的一些值
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
std::set<int> myset;
for (int i = 1; i < 10; i++)
{
myset.insert(i * 10);
}
for (auto e : myset)
{
cout << e << " ";
}
cout << endl;
//删除[30,50]值
//返回 >= 30
//auto itlow = myset.lower_bound(30);
//返回 > 50
//auto itup = myset.upper_bound(50);
//删除[25,55]值
//返回 >= 25
auto itlow = myset.lower_bound(25);
//返回 > 55
auto itup = myset.upper_bound(55);
//删除这段区间的值
myset.erase(itlow, itup);
for (auto e : myset)
{
cout << e << " ";
}
cout << endl;
return 0;
}2.4.multiset和set的差异
multiset和set的使用基本完全类似
**主要区别:**multiset支持值沉余
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
//multiset:排序,但是不去重
multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };
auto it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}迭代器查找
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
//multiset:排序,但是不去重
multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };
//multiset:x可能会存在多个,find查找中序的第一个
int x;
cin >> x;
auto pos = s.find(x);
while (pos != s.end() && *pos == x)
{
cout << *pos << " ";
++pos;
}
cout << endl;
return 0;
}迭代器查找+删除
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };
int x;
cin >> x;
auto pos = s.find(x);
while (pos != s.end() && *pos == x)
{
cout << *pos << " ";
++pos;
}
cout << endl;
/*pos = s.find(x);
while (pos != s.end() && *pos == x)
{
pos = s.erase(pos);
}*/
s.erase(x);
auto it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}count计算每个值出现次数
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <set>
int main()
{
multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };
int x;
cin >> x;
auto pos = s.find(x);
while (pos != s.end() && *pos == x)
{
cout << *pos << " ";
++pos;
}
cout << endl;
s.erase(x);
auto it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
cout << s.count(2) << endl;
return 0;
}2.5.与set有关的试题
试题1:两个数组的交集
题目内容:
给定两个数组nums1和nums2,返回它们的交集
输出结构中每个元素一定是唯一的
示例:
输入:nums1 = 1,2,2,1,num2 = 2,2
输出:2
cpp
class Solution
{
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2)
{
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
vector<int> ret;
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 < *it2)
{
it1++;
}
else if(*it1 > *it2)
{
it2++;
}
else
{
ret.push_back(*it1);
it1++;
it2++;
}
}
return ret;
}
};**交集:**相同存数据,同时++,不同小的++
**差集:**相同同时++,不同小的存数据后++
同步算法(叉集与并集)
假设以云相册为主
将相册(照片A,B,C)分给手机端,电脑端,平板端
当手机端输入一个新的照片D时,会和云相册作差集,将D上传到云相册
平板端与电脑端再与云相册比对,ABC是交集,而D是差集,所以会从云相册中下载照片D
当对手机端的C照片进行修改后,因为最后修改时间不同
会以时间最新的照片为准,同时其他的客户端也会同步更新
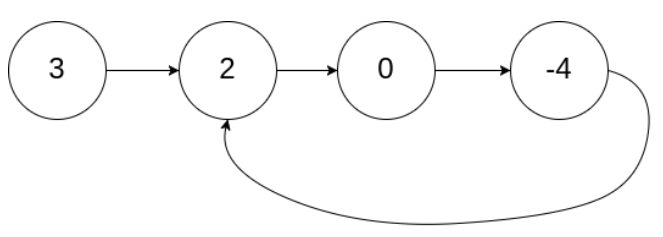
试题2:环形链表II
题目内容:
给定一个链表的头节点 head
返回链表开始入环的第一个节点
如果链表无环,则返回 null
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环
示例:
输入:head = 3,2,0,-4,pos = 1
输出:返回索引为1的链表节点
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution
{
public:
ListNode *detectCycle(ListNode *head)
{
set<ListNode*> s;
ListNode* cur = head;
while(cur)
{
if(s.count(cur))
{
return cur;
}
else
{
s.insert(cur);
}
cur = cur->next;
}
return nullptr;
}
};三、map系列的使用
3.1.map容器

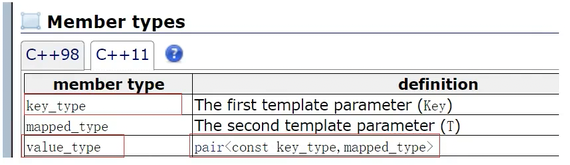
**Key:**key
**T:**value
3.2.map的插入
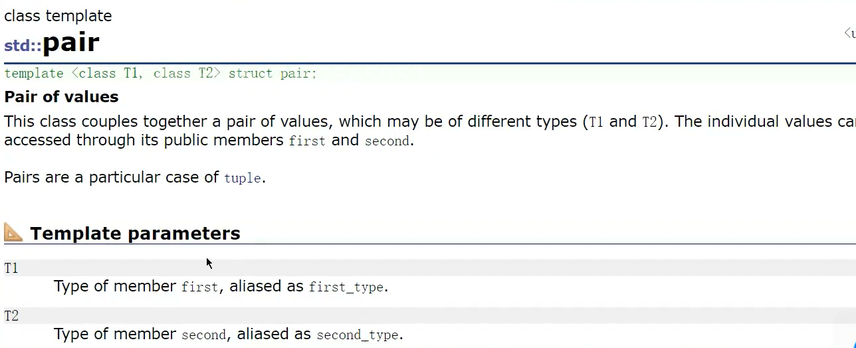
pair类类型:
cpp
typedef pair<const Key, T> value_type;
template < class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair() : first(T1()), second(T2())
{}
pair(const T1 & a, const T2 & b) : first(a), second(b)
{}
template < class U, class V>
pair(const pair<U, V>&pr) : first(pr.first), second(pr.second)
{}
};**make_pair函数模板:**自动判断参数类型,并且返回

cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <map>
int main()
{
//默认无参构造
//map<string, string> dict;
//initializer_list列表构造
map<string, string>dict = { {"left","左边"},{"right","右边"},{"insert","插入"},{"string","字符串"} };
//法1:
pair<string, string> kv1("first", "第一个");
dict.insert(kv1);
//法2:
dict.insert(pair<string, string>("second", "第二个"));
//法3:
dict.insert(make_pair("sort", "排序"));
//法4:(C++11,多参数隐式类型转接)
dict.insert({ "auto","自动的" });
//遍历打印
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
//可以修改value,不支持修改key
//it->first += 'x';
it->second += 'x';
cout << (*it).first << (*it).second << endl;
cout << it->first << it->second << endl;
cout << it.operator->()->first << it.operator->()->second << endl;
++it;
}
cout << endl;
return 0;
}**注:**插入时,如果key相同,value不相等时,数据不会更新
3.3.map的迭代器和\[\]功能
示例1:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <map>
int main()
{
//利用find和iterator修改功能,统计水果出现的次数
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };
map<string, int> countMap;
for (const auto& str : arr)
{
//先查找水果在不在map中
//不在:说明水果第一次出现,则插入{水果, 1}
//在:则查找到的节点中水果对应的次数++
auto ret = countMap.find(str);
if (ret == countMap.end())
{
countMap.insert({ str, 1 });
}
else
{
ret->second++;
}
}
for (const auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
return 0;
}示例2:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <map>
int main()
{
//利用find和iterator修改功能,统计水果出现的次数
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };
map<string, int> countMap;
for (const auto& str : arr)
{
//[]先查找水果在不在map中
//不在:说明水果第一次出现,则插入{水果, 0},同时返回次数的引用,++一下就变成1次了
//在:则返回水果对应的次数++
countMap[str]++;
}
for (const auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
return 0;
}示例3:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <map>
int main()
{
map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
//插入{"insert", string()} (key不在)
dict["insert"];
//插入+修改
dict["left"] = "左边";
//修改
dict["left"] = "左边、剩余";
//查找(key在)
cout << dict["left"] << endl;
//插入{"right",string()} (key不在)
cout << dict["right"] << endl;
return 0;
}注:
**str不存在时\[\]的功能:**插入+修改
**str存在时\[\]的功能:**查找+修改
3.4.insert返回值说明

The single element versions (1) return a pair, with its member
pair::first set to an iterator pointing to either the newly inserted element or to the
element with an equivalent key in the map.
The pair::second element in the pair is set to true if a new element was inserted or false if an
equivalent key already existed.
insert插入一个pair<key, T>对象
如果key在map中,插入失败,则返回一个pair<iterator,bool>对象
返回pair对象:first是key所在结点的迭代器,second是false
如果key不在map中,插入成功,则返回一个pair<iterator,bool>对象
返回pair对象:first是新插入key所在结点的迭代器,second是true
无论插入成功还是失败,返回pair<iterator,bool>对象的first都会指向key所在的迭代器
意味着insert插入失败时充当了查找的功能,所以insert可以用来实现operator\[\]
**注:**这里有两个pair
- map底层红黑树节点中存的pair<key, T>
- insert返回值pair<iterator,bool>
operator\[\]的内部实现
cpp
// operator的内部实现
mapped_type& operator[] (const key_type& k)
{
//如果k不在map中:
//insert会插入k和mapped_type默认值,同时[]返回结点中存储mapped_type值的引用
//可以通过引用修改返映射值,所以[]具备了插入 + 修改功能
//如果k在map中:
//insert会插入失败,但是insert返回pair对象的first是指向key结点的迭代器
//返回值同时[]返回结点中存储mapped_type值的引用,所以[]具备了查找 + 修改功能
pair<iterator, bool> ret = insert({ k, mapped_type() });
iterator it = ret.first;
return it->second;
}3.5.multimap和map的差异
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <map>
int main()
{
multimap<string, string> dict;
dict.insert({ "sort","排序" });
dict.insert({ "sort","排序" });
dict.insert({ "sort","排序1" });
dict.insert({ "sort","排序2" });
dict.insert({ "sort","排序3" });
dict.insert({ "string","字符串" });
for (auto e : dict)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
dict.erase("sort");
for (auto e : dict)
{
cout << e.first << ":" << e.second << endl;
}
return 0;
}3.6.与map有关的试题
试题3:随机链表的复制
题目内容:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针random
该指针可以指向链表中的任何节点或空节点,构造这个链表的深拷贝
深拷贝应该正好由 n 个全新节点组成
每个新节点的值都设为其对应的原节点的值
新节点的 next 指针和 random 指针也都应指向复制链表中的新节点
并使原链表和复制链表中的这些指针能够表示相同的链表状态
复制链表中的指针都不应指向原链表中的节点
示例:
输入:head = \[7,null,13,0,11,4,10,2,1,0]
输出:\[7,null,13,0,11,4,10,2,1,0]

cpp
class Solution {
public:
Node * copyRandomList(Node * head)
{
map<Node*, Node*> nodeMap;
Node * copyhead = nullptr, *copytail = nullptr;
Node * cur = head;
while (cur)
{
if (copytail == nullptr)
{
copyhead = copytail = new Node(cur->val);
}
else
{
copytail->next = new Node(cur->val);
copytail = copytail->next;
}
//原节点和拷⻉节点map kv存储
nodeMap[cur] = copytail;
cur = cur->next;
}
//处理random
cur = head;
Node * copy = copyhead;
while (cur)
{
if (cur->random == nullptr)
{
copy->random = nullptr;
}
else
{
copy->random = nodeMap[cur->random];
}
cur = cur->next;
copy = copy->next;
}
return copyhead;
}
};试题4:前k个高频单词
题目内容:
给定一个单词列表 words 和一个整数 k
返回前 k 个出现次数最多的单词
返回的答案应该按单词出现频率由高到低排序
如果不同的单词有相同出现频率, 按字典顺序排序
示例:
输入:words = "i", "love", "leetcode", "i", "love", "coding",k = 2
输出:"i", "love"
解析:"i" 和 "love" 为出现次数最多的两个单词,均为2次
注意:按字母顺序 "i" 在 "love" 之前。
**法1:**使用stable_sort
cpp
class Solution
{
public:
struct kvCompare
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k)
{
map<string,int> countMap;
for(auto& e : words)
{
countMap[e]++;
}
vector<pair<string,int>> v(countMap.begin(),countMap.end());
stable_sort(v.begin(),v.end(),kvCompare());
vector<string> strV;
for(int i = 0;i < k;i++)
{
strV.push_back(v[i].first);
}
return strV;
}
};注: sort底层是快排,不稳定,使用stable_sort更加稳定
**法2:**完善仿函数
cpp
class Solution
{
public:
struct kvCompare
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second || (kv1.second == kv2.second && kv1.first < kv2.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k)
{
map<string,int> countMap;
for(auto& e : words)
{
countMap[e]++;
}
vector<pair<string,int>> v(countMap.begin(),countMap.end());
sort(v.begin(),v.end(),kvCompare());
vector<string> strV;
for(int i = 0;i < k;i++)
{
strV.push_back(v[i].first);
}
return strV;
}
};**法3:**使用优先级队列
cpp
class Solution
{
public:
struct Compare
{
bool operator()(const pair<string, int>& x, const pair<string, int>& y) const
{
//要注意优先级队列底层是反的
//大堆要实现小于比较,所以这里次数相等
//想要字典序小的在前面要比较字典序大的为真
return x.second < y.second || (x.second == y.second && x.first > y.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k)
{
map<string, int> countMap;
for(auto& e : words)
{
countMap[e]++;
}
//将map中的<单词,次数>放到priority_queue中
//仿函数控制大堆,次数相同按照字典序规则排序
priority_queue<pair<string, int>, vector<pair<string, int>>, Compare>
p(countMap.begin(), countMap.end());
vector<string> strV;
for(int i = 0; i < k; ++i)
{
strV.push_back(p.top().first);
p.pop();
}
return strV;
}
};