Python语言深度掌握
- 语言核心,深入理解Python运行机制:深入理解Python对象模型、内存管理、GIL机制、解释器工作原理
- 精通Python语法与高级特性:装饰器、元类、上下文管理器、生成器协程、异步编程(asyncio)等
- 性能优化:代码性能分析、内存泄漏排查、C扩展开发
- 熟练使用标准库与常用第三方库:如 requests、pandas、numpy、logging、collections 等。
生成器协程
Python 生成器协程 是指利用生成器(generator)的特性(特别是 yield 和 send() 方法)来实现协程(coroutine)功能的一种编程模式。它并非 Python 原生支持的现代协程(即 async/await 协程),而是早期基于生成器实现的"基于生成器的协程"(generator-based coroutines)。
-
生成器:通过 yield 关键字定义,用于惰性生成数据序列,支持暂停与恢复执行。
- 生成器是一种特殊的迭代器,其核心是惰性求值(Lazy Evaluation)。普通函数使用return一次性返回所有结果,而生成器函数使用yield在每次调用next()或迭代时暂停并返回一个值,同时保留函数的完整执行状态(包括局部变量、指令指针等),等待下一次唤醒。其底层原理涉及生成器对象(Generator Object) 和协程状态机:
- 函数定义:当一个函数体内包含yield关键字时,Python会将其识别为生成器函数。
- 调用与对象创建:调用生成器函数并不会执行其内部代码,而是返回一个生成器对象。这个对象实现了迭代器协议(__iter__和__next__方法)。
- 执行与挂起:首次调用next(gen_obj)时,函数体开始执行,直到遇到第一个yield,函数在此处挂起,并将yield后的表达式值返回给调用者。
- 恢复执行:再次调用next(gen_obj)时,函数从上次挂起的位置恢复执行,直到遇到下一个yield或函数结束(此时会抛出StopIteration异常)。
这种机制避免了一次性生成所有数据对内存的消耗,特别适用于处理大数据流、无限序列或高昂计算成本的场景。
-
协程:一种可在执行过程中挂起和恢复的轻量级并发单元,适用于 I/O 密集型任务。
- 协程是生成器概念的延伸,其核心是能够暂停执行并接收外部传入的值。早期的Python协程(称为"基于生成器的协程")正是通过增强生成器的功能来实现的,即生成器不仅可以yield一个值出去,还可以通过.send(value)方法接收一个值,这个值会成为yield表达式的返回值。
- 这使得生成器函数从一个数据的生产者,转变为一个可双向通信的、能维持状态的子程序(Subroutine)。每个协程都维护着自己的上下文,可以在多个协程之间由程序员或事件循环(Event Loop)调度切换,实现协作式多任务,尤其擅长处理I/O密集型并发。
-
生成器协程:将生成器用作协程,利用其双向通信能力(yield 产出值 + send() 传入值)实现任务调度与协作式并发。关键特性:
- 双向通信:yield 可产出值给调用方。send(value) 可向生成器内部传入值,赋值给 yield 表达式。
- 手动调度:需自行实现调度器(如用队列轮询),通过 next() 或 send() 驱动协程执行。
- 单线程并发:多个生成器协程交替执行,模拟并发,但不涉及多线程或进程。
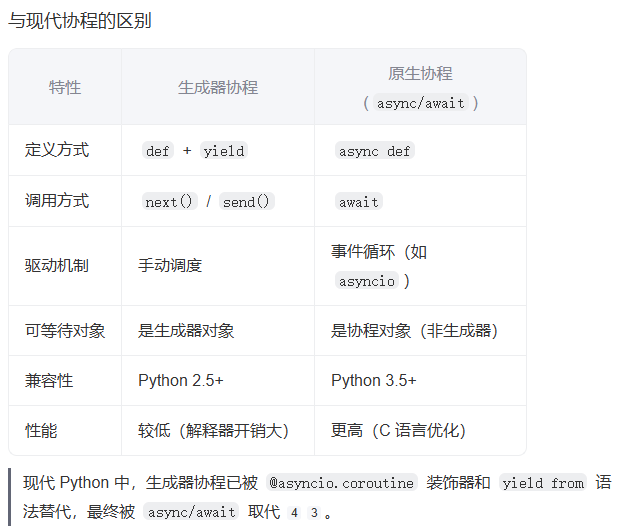
生成器与协程的关系与对比

生成器基础用法
此例展示了生成器按需生成数据,节省内存。
python
# 示例1:生成一个斐波那契数列的生成器
def fibonacci(limit):
a, b = 0, 1
count = 0
while count < limit:
yield a # 每次迭代产生一个值并暂停
a, b = b, a + b
count += 1
# 使用
fib_gen = fibonacci(5) # 创建生成器对象,代码未执行
for num in fib_gen: # 每次循环触发 next(fib_gen),执行到yield处
print(num) # 输出: 0, 1, 1, 2, 3
# 生成器耗尽后,再调用 next(fib_gen) 会引发 StopIteration生成器作为协程(传统方式)
此例中,生成器函数averager维持了total、count、average的状态,成为一个可以持续接收和处理数据的协程。
python
# 示例2:一个简单的协程,计算移动平均值
def averager():
total = 0.0
count = 0
average = None
while True:
# yield 在这里扮演双重角色:
# 1. 暂停并返回当前平均值(给调用方的 print 语句)
# 2. 接收调用方通过 .send() 发来的新值,赋值给 `term`
term = yield average
total += term
count += 1
average = total / count
# 使用
avg_coroutine = averager()
next(avg_coroutine) # 预激(prime)协程,使其运行到第一个yield处等待数据
print(avg_coroutine.send(10)) # 输出: 10.0
print(avg_coroutine.send(20)) # 输出: 15.0
print(avg_coroutine.send(30)) # 输出: 20.0使用 yield from 简化协程委派
yield from是Python 3.3引入的语法,用于简化在生成器中嵌套另一个生成器(或协程)的循环委派过程,并建立了调用方与子生成器之间的双向通道,允许值直接传递和异常传播。
python
# 示例3:使用 yield from 聚合多个生成器
def sub_generator():
yield '[sub] 1'
yield '[sub] 2'
return 'Sub Done!'
def delegating_generator():
result = yield from sub_generator() # 委派给 sub_generator
print(f'Sub-generator returned: {result}')
yield '[delegator] finished'
# 使用
for item in delegating_generator():
print(item)
# 输出:
# [sub] 1
# [sub] 2
# Sub-generator returned: Sub Done!
# [delegator] finished现代原生协程 (async/await)
Python 3.5+ 使用async def定义原生协程,await用于挂起等待另一个协程或Future对象完成。
此例展示了现代异步编程模型,通过事件循环管理多个协程,在遇到I/O等待时挂起当前协程并切换执行其他协程,从而实现高效并发。
python
# 示例4:使用 async/await 模拟异步I/O操作
import asyncio
async def fetch_data(task_name, delay):
print(f"{task_name}: 开始获取数据...")
await asyncio.sleep(delay) # 模拟I/O等待,不会阻塞事件循环
print(f"{task_name}: 数据获取完成")
return f"{task_name}_result"
async def main():
# 并发执行多个协程
task1 = fetch_data("任务A", 2)
task2 = fetch_data("任务B", 1)
# gather 用于调度并发
results = await asyncio.gather(task1, task2)
print(f"所有任务结果: {results}")
# 运行事件循环
asyncio.run(main())应用场景
- 并发处理I/O:使用asyncio库配合async/await协程,可以轻松构建高性能的网络服务器或爬虫,在单线程内处理成千上万的连接,避免线程切换开销和GIL的限制。
- 数据管道:生成器可以串联,形成数据处理管道,如(item for line in file for item in line.split()),实现流式处理。
- 上下文管理:生成器可以与contextmanager装饰器结合,创建自定义的上下文管理器。
对于I/O密集型应用,采用asyncio协程通常是性能最佳的选择;而对于简单的惰性数据生成,使用经典生成器则更加简洁直观。
异步编程(asyncio)
在处理I/O密集型任务时,传统的同步编程模型会因阻塞而浪费大量CPU等待时间。异步编程通过"单线程内并发"的模式,在等待一个I/O操作完成时,立即切换到执行其他任务,从而大幅提升程序的吞吐量和响应速度。其核心优势在于高并发、低资源消耗。asyncio是Python标准库中内置的异步I/O框架,是实现这一模式的核心工具。
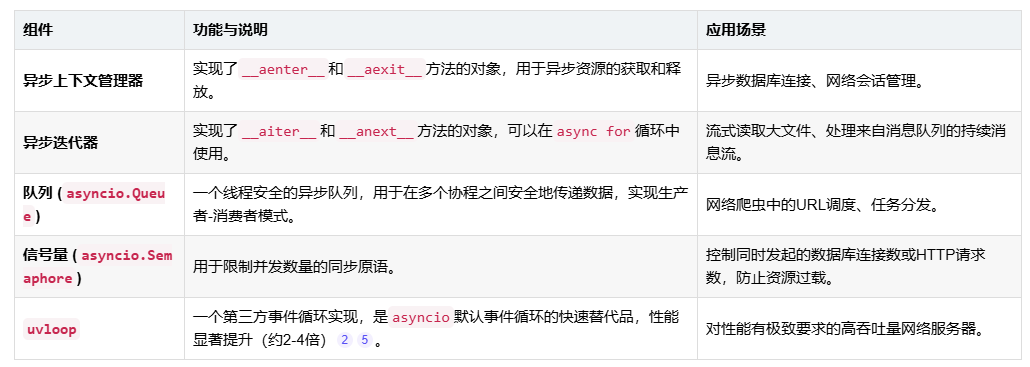
其核心组成部分通过以下表格清晰地展示:

asyncio 基本用法与工作流程
- 定义协程:使用async def来定义一个协程函数。直接调用协程函数不会执行其内部代码,而是返回一个协程对象。
python
import asyncio
async def say_hello(name: str):
await asyncio.sleep(1) # 模拟一个耗时的I/O操作
print(f"Hello, {name}!")- 运行协程:有三种主要方式来驱动协程的执行:
- asyncio.run(): 这是运行异步程序的主入口,它创建一个新的事件循环,运行传入的协程,并在完成后关闭循环。这是最简单、最推荐的方式。
python
if __name__ == "__main__":
asyncio.run(say_hello("World"))- 手动管理事件循环: 适用于旧版或复杂场景。
python
loop = asyncio.get_event_loop()
loop.run_until_complete(say_hello("World"))
loop.close()- await表达式: 在一个协程中等待另一个协程。
python
async def main():
await say_hello("Alice")
await say_hello("Bob")- 并发运行任务
使用asyncio.create_task()将协程包装为Task,可以让它们在事件循环中并发执行。这是实现并发的关键。
python
import asyncio
async def fetch_data(task_id: int, delay: float):
print(f"任务 {task_id} 开始")
await asyncio.sleep(delay) # 模拟网络请求或数据库查询
print(f"任务 {task_id} 结束,耗时 {delay} 秒")
return f"数据 {task_id}"
async def main():
# 创建多个任务,它们将并发执行
task1 = asyncio.create_task(fetch_data(1, 2.0))
task2 = asyncio.create_task(fetch_data(2, 1.0))
task3 = asyncio.create_task(fetch_data(3, 0.5))
# 等待所有任务完成并收集结果
results = await asyncio.gather(task1, task2, task3)
print(f"所有任务完成,结果:{results}")
if __name__ == "__main__":
asyncio.run(main())输出示例:
text
任务 1 开始
任务 2 开始
任务 3 开始
任务 3 结束,耗时 0.5 秒
任务 2 结束,耗时 1.0 秒
任务 1 结束,耗时 2.0 秒
所有任务完成,结果:['数据 1', '数据 2', '数据 3']可以看到,任务按创建顺序开始,但结束顺序取决于各自的delay时间,总耗时约等于最长的任务(2秒),而非它们的总和(3.5秒),这体现了异步并发的效率优势。
高级组件与应用场景