这篇发表于 CVPR 的论文提出了UltraFusion------ 首个能融合曝光差达 9 档(stops)图像的曝光融合技术,针对传统高动态范围(HDR)成像在超大曝光差、动态场景运动模糊 / 重影、色调映射伪影等问题提出解决方案,通过将曝光融合建模为引导式修复问题,结合扩散先验、定制化网络分支和专属训练数据集,实现了超高动态范围场景下的高质量成像,且在静态、动态数据集及自建基准测试中均显著优于现有方法。
摘要
高动态范围(HDR)场景成像是相机设计领域的核心研究问题之一。目前主流相机均采用曝光融合技术,通过融合不同曝光度下采集的图像来提升动态范围,但该方法仅能处理曝光差异有限的图像,通常为 3-4 档。当应用于需要超大曝光差的超高动态范围场景时,因输入图像配准错误、光照不一致或色调映射伪影等问题,传统曝光融合方法往往失效。
本文提出 UltraFusion 方法,作为首个可融合曝光差达 9 档图像的曝光融合技术。其核心思路是将曝光融合建模为引导式图像修复问题:以欠曝光图像为引导,填补过曝光区域中丢失的高光细节信息。该方法将欠曝光图像作为软引导而非硬约束,使其对潜在的配准误差和光照变化具有鲁棒性;同时借助生成模型的图像先验,即便在超高动态范围场景下,也能生成自然的色调映射结果。实验表明,UltraFusion 在最新的 HDR 基准数据集上的性能优于 HDR-Transformer 模型。为验证其在超高动态范围场景中的表现,我们构建了全新的真实世界曝光融合基准数据集 ------UltraFusion 数据集,该数据集的图像曝光差最高达 9 档。实验结果证明,UltraFusion 能在各类场景下生成视觉效果优异、画质精良的融合图像。
相关代码与数据集将开源至:https://openimaginglab.github.io/UltraFusion。

- 图 1 我们将所提出的引导式修复高动态范围成像方法,与目前主流的高动态范围重建方法 25 和多曝光融合方法 48 展开对比。两组实验场景均选自我们采集的全新真实场景基准数据集:左侧为存在大曝光差的夜间城市景观,右侧为存在运动遮挡的午后街道场景。现有方法难以处理这类场景,而我们通过将高动态范围成像建模为图像修复问题,能够在这些具有挑战性的场景中生成视觉效果优异的结果,且无重影伪影。
引言
本章围绕高动态范围(HDR)成像的核心研究背景展开,指出传统技术的关键局限,并提出本文的研究问题与核心解决思路,同时阐明研究的必要性和创新方向。
- 研究背景与技术现状:HDR 成像是现代相机设计的基础问题,受硬件限制,相机传感器的动态范围远低于真实场景,主流解决方案是融合多张相同或不同曝光度的图像来提升动态范围,但现有多数 HDR 算法仅能实现有限的动态范围提升(如商用相机的 HDR + 仅能稳健提升 3 档,即 8 倍动态范围),无法应对超大曝光差的超高动态范围场景。
- 核心研究问题:提出核心探索问题 ------ 能否通过融合曝光差达 9 档的两张图像,大幅提升相机的动态范围,这也是本文研究的核心目标。
- 超大曝光差成像的三大核心挑战:该研究问题存在根本性难点,一是大亮度差导致动态场景下的图像配准难度极高,配准失效易产生重影伪影;二是传统算法假设欠曝光图像仅是正常曝光图像的暗版本,而实际曝光变化会改变物体外观,造成融合结果不自然;三是 HDR 图像转 LDR 显示的色调映射过程,在超高动态范围下易丢失细节、破坏自然对比度,引入额外伪影。
- 本文核心解决思路:提出全新的 UltraFusion 融合方法,摒弃传统曝光融合的直接聚合思路,将其建模为引导式修复问题------ 以过曝光图像为参考,用欠曝光图像作为引导,填补过曝光区域丢失的高光信息,且该引导为软约束而非硬约束,从根源上缓解上述三大挑战。
- 方法的核心优势铺垫:初步说明该思路的三大优势,一是沿用曝光融合直接生成 LDR 输出的设定,避免先生成 HDR 再色调映射的级联误差;二是软引导策略让模型对配准误差和光照变化具有鲁棒性;三是借助生成模型的图像先验,保证输出图像的自然性,减少伪影产生。

- 图 2 本文将直接使用 ControlNet 65 的效果与我们的 UltraFusion 方法进行视觉效果对比。在无预配准数据的情况下,ControlNet 难以确定单一参考帧;而我们的方法将过曝光图像固定为参考帧,把欠曝光图像作为修复任务的引导信息,从而有效避免了伪影的产生。
相关工作
本章从HDR 成像、扩散模型、色调映射方法三个核心研究方向展开,梳理现有技术的研究现状、成果与局限性,明确本文研究与现有工作的差异,突出 UltraFusion 的创新切入点与技术价值。
高动态范围(HDR)成像
HDR 成像主要分为HDR 重建和 ** 多曝光融合(MEF)** 两类,二者的核心区别在于融合发生的域,且均面临动态场景下的重影伪影难题:
HDR 重建:在线性 HDR 域通过反演相机响应函数融合曝光序列,需经色调映射才能在 LDR 显示器显示,步骤繁琐易引入误差;
多曝光融合(MEF):直接在 LDR 域融合图像,规避了相机响应函数校准和复杂色调映射,是更具成本效益的方案;
共同局限:两类方法均受相机抖动、物体运动引发的重影伪影困扰,现有方法虽通过光流、注意力机制做显式 / 隐式配准,但在大运动导致互补区域遮挡时,仍易产生不良伪影,且均难以处理超大曝光差场景。
扩散模型
扩散模型在可控图像生成、图像修复 / 编辑等任务中应用广泛,在 HDR 成像领域的应用目前聚焦于HDR 去重影,但存在明显局限:现有扩散基 HDR 去重影方法未利用大规模数据集学习的扩散先验,泛化能力受限于 HDR 数据集规模;
少数引入扩散先验的工作仅针对单张图像 HDR 重建,无不同曝光图像作为参考,生成结果的可靠性不足;
本文差异:不同于现有方法,UltraFusion 利用扩散先验,并以欠曝光图像为参考,对过曝光图像的高光区域做可靠修复,实现自然且鲁棒的 HDR 场景重建;同时区别于纯从头开始的扩散基图像修复,借助欠曝光图像的信息引导,让修复过程更精准。
色调映射方法
色调映射的核心目标是将 HDR 图像转换为 LDR 图像以适配常规显示,同时保留视觉细节,现有方法的局限性显著:
因难以获取色调映射的真实标签,现有方法多采用对抗学习、对比学习的无监督深度学习方案,部分研究通过人工筛选不同方法的最优结果构建训练数据,解决数据受限问题;
核心缺陷:缺乏鲁棒的图像先验且受数据约束,在极端超高动态范围场景中,难以生成视觉效果良好的结果,泛化能力差;
本文改进:UltraFusion 融入基于扩散的图像先验,即便在超高动态范围的挑战性场景中,也能生成视觉效果美观的色调映射结果,弥补了传统方法的短板。
整体而言,现有相关工作在超大曝光差处理、扩散先验的有效利用、极端场景色调映射鲁棒性等方面存在明显不足,为本文 UltraFusion 方法的提出留下了研究空间,也明确了本文的技术突破方向。
本文方法
给定过曝光图像 IoeI_{oe}Ioe 和欠曝光图像 IueI_{ue}Iue,传统曝光融合算法会直接对两幅图像的不同频率波段进行融合,这类方法对配准误差和光照变化十分敏感。对此,我们将该问题转化为图像修复问题:具体而言,以过曝光图像 IoeI_{oe}Ioe 为基础图像,对其高光区域中缺失的信息进行修复;同时,利用欠曝光图像中的高光信息作为引导,确保修复后的高光区域真实可信。
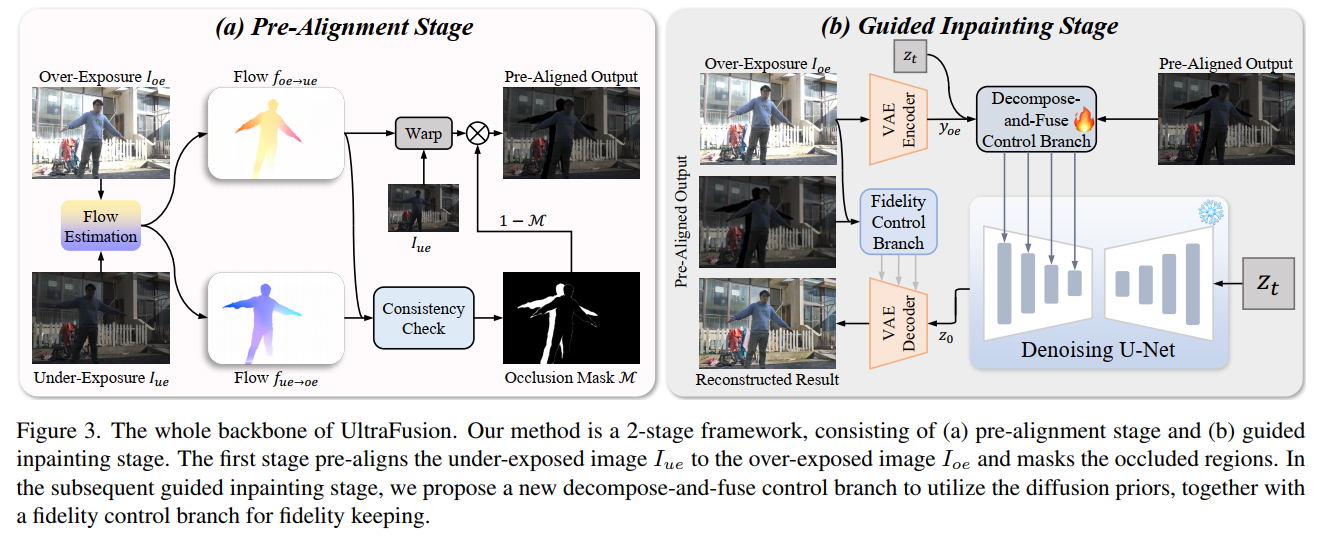
基于这一思路,我们设计了一个包含两个阶段的网络模型(见图3),该模型由预配准阶段 和引导式修复阶段 构成。预配准阶段会输出欠曝光图像 IueI_{ue}Iue 的粗配准版本,该结果将作为后续引导式修复阶段的软引导。下文将详细阐述每个阶段的具体实现细节。
3.1 预配准阶段
大多数光流配准算法均假设输入图像具有相似的亮度特征。因此,我们首先通过亮度映射函数调整欠曝光图像 IueI_{ue}Iue 的亮度,使其亮度分布与过曝光图像 IoeI_{oe}Ioe 相匹配。随后,采用预训练的光流网络RAFT估计双向光流 foe→uef_{oe→ue}foe→ue 和 fue→oef_{ue→oe}fue→oe,并通过反向变形将欠曝光图像 IueI_{ue}Iue 配准至过曝光图像 IoeI_{oe}Ioe 的视角。但反向变形会在遮挡边界处产生重影伪影,进而给后续的引导式修复阶段带来干扰。为解决这一问题,我们利用前向-后向一致性校验估计遮挡区域掩码 M\mathcal{M}M,并在变形输出结果中对遮挡区域进行掩码屏蔽。最终,我们可得到第一阶段的预配准输出结果Iue→oeI_{ue→oe}Iue→oe,计算公式如下:
Iue→oe=(1−M)⋅W(Iue,foe→ue)(1)I_{ue→oe}=(1-\mathcal{M}) \cdot \mathcal{W}\left(I_{ue}, f_{oe→ue}\right) \tag{1}Iue→oe=(1−M)⋅W(Iue,foe→ue)(1)
其中W\mathcal{W}W代表反向变形操作。图3(a)展示了该阶段的输出结果为经过掩码处理和配准的欠曝光图像。
3.2 引导式修复阶段
我们基于稳定扩散模型(Stable Diffusion Model)构建引导式修复模型,因其强大的生成先验能力,能够有效解决修复过程中的信息模糊问题。与其他基于扩散模型的图像增强技术类似,我们通过一个额外的控制分支向模型注入三类信息(见图3(b)):1)待修复图像,即过曝光图像IoeI_{oe}Ioe;2)高光区域的额外引导信息,即欠曝光图像IueI_{ue}Iue;3)当前扩散步骤的扩散潜变量ztz_tzt --- 已有研究表明,将扩散潜变量作为额外条件引入模型,能够有效提升图像生成质量。模型的核心扩散去噪网络为预训练的U-Net网络;过曝光图像在输入扩散模块前,需先通过预训练的变分自编码器(VAE)进行编码,而扩散模块的输出则通过预训练的解码器转换回图像空间。
本文方法与通用的基于扩散模型的图像增强方法相比,核心差异体现在两个方面:第一,我们提出了一种全新的分解-融合控制分支 ,将两幅输入图像和扩散潜变量作为控制信号注入模型---直接注入这类信息无法引导扩散模型,从欠曝光图像中准确提取缺失的高光信息并完成修复;第二,我们额外训练了一个保真度控制分支,通过快捷连接为解码过程提供真实的结构和颜色信息。下文将对这两个分支进行详细说明。
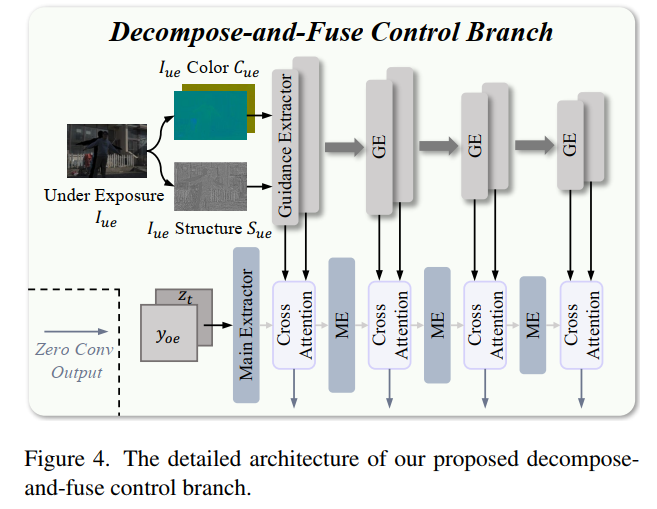
分解-融合控制分支
图4 展示了该控制分支的具体结构。我们将过曝光图像IoeI_{oe}Ioe作为主控制信号,将欠曝光图像 IueI_{ue}Iue 作为软引导。借鉴ControlNet 的设计思路,我们复制去噪U-Net网络的编码器和中间模块作为主特征提取器,并在训练过程中对其权重进行更新。一种简单的软引导方式是,将变分自编码器编码器输出的欠曝光图像潜变量 yuey_{ue}yue 与过曝光图像潜变量 yoey_{oe}yoe 直接融合,但欠曝光图像通常亮度极低,直接作为软引导易被模型忽略,因此该方式并不适用。为此,我们将欠曝光图像分解为 颜色信息 和 结构信息 ------这两类信息均对亮度变化具有鲁棒性。具体而言,我们将归一化后的图像作为结构分量(该思路与结构相似性指数SSIM的设计一致),计算公式如下:
Sue=(Yue−μ(Yue))/σ(Yue)(2)S_{ue}=\left(Y_{ue}-\mu\left(Y_{ue}\right)\right) / \sigma\left(Y_{ue}\right) \tag{2}Sue=(Yue−μ(Yue))/σ(Yue)(2)
其中YueY_{ue}Yue 为欠曝光图像 IueI_{ue}Iue 在YUV色彩空间中的亮度通道,μ(⋅)\mu(\cdot)μ(⋅) 和 σ(⋅)\sigma(\cdot)σ(⋅) 分别代表亮度的均值和标准差;而YUV色彩空间的色度通道(UV)则作为颜色信息。提取得到的结构和颜色信息,将通过训练后的颜色提取器和结构提取器(图4中灰色GE模块)做进一步的特征编码------借鉴现有研究,我们采用多个简单的卷积层实现特征提取器(GE),以提取多尺度特征。最终,提取的多尺度特征通过多尺度交叉注意力机制注入主特征提取器(见图4下半部分);每个交叉注意力模块的输出,将通过零卷积同时输入至主特征提取器的下一层级和对应的U-Net模块。
保真度控制分支
即便引入了上述控制分支,变分自编码器(VAE)仍可能对图像纹理做出非预期的修改(示例见图11©)。因此,为进一步提升图像保真度,我们受相关研究启发设计了保真度控制分支(FCB) 。该分支通过向VAE解码器注入特征,缓解纹理失真问题,其架构与分解-融合控制分支相似,但存在两个核心差异:1)保真度控制分支的主特征提取器采用与VAE编码器相同的结构(而非去噪U-Net的结构),为VAE解码器提供对应的快捷连接,同时对软引导特征提取器做相应调整;2)该分支的主特征提取器直接以过曝光图像作为输入。
在训练保真度控制分支时,我们冻结预训练的VAE编码器和解码器,将真实标签图像 IgtI_{gt}Igt 编码至潜空间,模拟推理过程中的去噪潜变量 z0z_0z0;随后,将对应的过曝光图像和欠曝光图像输入保真度控制分支,提取具有真实感的特征;最后,VAE解码器将压缩后的潜变量解码为重建图像 I^gt\hat{I}{gt}I^gt。我们将 L1L_1L1 重建损失 ∥I^gt−Igt∥1\left\|\hat{I}{gt}-I_{gt}\right\|_{1} I^gt−Igt 1 作为额外的损失项,用于训练该分支。
3.3 训练数据合成
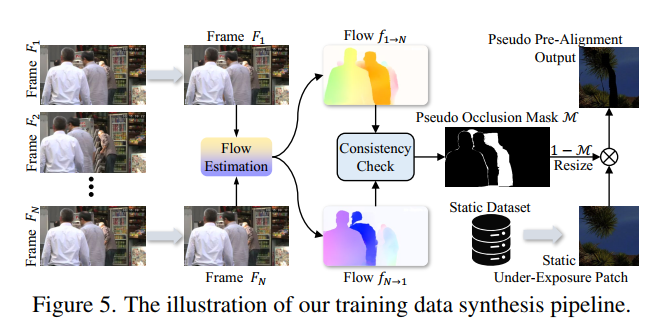
为所提出的引导式修复网络准备训练数据具有较大挑战性。理想情况下,训练该模型需要一个大规模的HDR数据集,且需满足三个条件:1)涵盖各类动态场景;2)图像曝光差最高达9档;3)包含曝光融合的真实标签结果。但目前尚无同时满足上述所有条件的数据集。
为解决这一问题,我们提出了一种全新的训练数据合成流程。具体而言(见图5),我们首先从视频数据集中随机采样包含N帧的图像序列,为模拟大运动场景,选取序列的第一帧和最后一帧;随后,与预配准阶段的操作相似,利用光流算法估计所选两帧之间的双向光流,并通过前向-后向一致性校验生成伪遮挡掩码;接着,从高质量的静态多曝光数据集中随机采样欠曝光图像块,调整伪遮挡掩码的尺寸以匹配图像块大小,并对伪遮挡区域进行掩码屏蔽,合成伪预配准输出结果。通过该合成的训练数据,我们的 UltraFusion 模型能够仅利用静态多曝光图像对,学习处理动态场景的能力。
实验
实验设置
数据集
我们利用 SICE 数据集和 Vimeo-90K 数据集合成训练数据。参考现有研究方法,我们选取 SICE 数据集中每个曝光序列中亮度最高和最低的图像作为模型输入。本文方法在静态数据集和动态数据集上均开展了性能验证:验证阶段选用包含 100 组静态欠 / 过曝光图像对的 MEFB 数据集,以及包含 50 个不同运动模式场景的动态 HDR 去重影测试集 RealHDRV。
UltraFusion 基准数据集
现有曝光融合基准数据集无法充分验证模型在真实复杂场景下的融合性能,这类数据集要么缺乏真实的运动信息,要么动态范围有限。为此,我们构建了全新的真实世界 UltraFusion 基准数据集,包含 100 组真实拍摄的欠 / 过曝光图像对。相较于现有数据集,该基准数据集的测试难度更高,原因有三:1)输入图像对的曝光差异更大,最高可达 9 档;2)包含更贴合真实场景的运动信息,多个场景存在大量无规则的前景运动;3)场景多样性极强,涵盖白天、夜晚、室内、室外场景,且由单反相机(佳能 R8)和多款手机(iPhone12、iPhone13、红米 K50 Pro、OPPO Reno8 Pro)拍摄完成。我们在图 6 (a) 中总结了该基准数据集的曝光差异分布和曝光时间分布,结果表明,该数据集覆盖了广泛的曝光差异范围和多样的曝光时间,可有效测试各类 HDR 方法的鲁棒性。
实现细节
我们充分利用 Stable Diffusion V2.1 中封装的生成先验。分解 - 融合控制分支在 8 块 NVIDIA RTX 4090 显卡上完成训练,共训练 14 万次迭代,批次大小设为 32;保真度控制分支在单块 NVIDIA RTX 4090 显卡上训练,共训练 100 万次迭代,批次大小设为 1。优化器选用 Adam,学习率固定为 0.0001。为使各类 HDR 重建方法适配两组不同曝光的输入图像,我们按照其默认设置对这些方法进行了重新实现。
评价指标
本文采用四种广泛使用的无参考评价指标(MUSIQ、DeQA-Score、PAQ2PIQ、HyperIQA)开展定量对比。此外,针对无真实标签的静态数据集 MEFB,我们选用面向该任务的 MEF-SSIM 指标评估模型的结构保留能力;针对含 HDR 真实标签的动态数据集 RealHDRV,采用 TMQI 指标评估模型结果的保真度和自然度。同时,我们在 UltraFusion 基准数据集上开展了用户研究,完成主观性能评估。
与现有 HDR 成像方法的对比实验
将 UltraFusion 与当前主流的 HDR 重建方法(HDR-Transformer、SCTNet、SAFNet)和多曝光融合方法(Deepfuse、HSDS-MEF、TC-MoA 等)展开全面对比,因 HDR 重建方法无法直接输出 LDR 图像,额外采用专业软件 Photomatix 为其结果做色调映射处理,分别在静态、动态数据集及自建 UltraFusion 基准数据集上验证性能,核心结果如下:
静态数据集(MEFB):UltraFusion 在所有无参考质量指标上均取得最优结果,MUSIQ 较次优方法 HSDS-MEF 提升 2.06;在结构保留指标 MEF-SSIM 上与最优方法持平,实现了视觉质量与信息保留的最优平衡,解决了传统 HDR 重建方法高光细节丢失、多曝光融合方法亮暗区域过渡不自然的问题。
动态数据集(RealHDRV):在所有评价指标上均达到 SOTA 性能,尤其是动态场景核心指标 TMQI 取得最高值(0.8925);因软引导修复的设计,模型对配准误差和遮挡具有强鲁棒性,融合结果几乎无伪影,优于专为动态场景设计的 HDR 重建方法,而传统多曝光融合方法因未针对动态场景设计,存在明显伪影且 TMQI 分值较低。
自建 UltraFusion 基准数据集:在所有无参考指标上大幅领先对比方法,视觉对比结果显示模型能自然重建极端高光区域(如太阳),同时保持图像整体色调美观;136 名用户参与的主观研究中,UltraFusion 的支持率显著高于其他对比方法,验证了结果的自然度更符合人眼视觉感知。
消融实验
为验证 UltraFusion 各核心组件的有效性,针对 ** 配准策略、分解 - 融合控制分支(DFCB)、保真度控制分支(FCB)** 三大关键模块开展消融实验,并对各模块的设计细节进行深入探究,核心结论如下:
三大核心组件缺一不可:在 RealHDRV 数据集上的实验表明,移除任意一个组件均会导致模型性能显著下降(TMQI 和 MUSIQ 分值降低);无配准策略时模型无法处理大运动场景,无 DFCB 时模型无法有效融合大曝光差的特征且丢失细节,无 FCB 时模型存在纹理失真、色彩不逼真的问题。
配准策略是框架核心:该策略包含训练阶段的数合成流程和测试阶段的预配准模块,单独使用预配准仅能小幅减少伪影,单独使用数据合成无法解决遮挡区域的运动问题,二者结合后模型才具备处理动态场景的强能力。
分解 - 融合控制分支的设计优化:直接将欠曝光 RGB 图像作为引导会被模型忽略细节,仅用结构信息能保留细节但色彩失真,结合结构 + 颜色信息可实现细节与色彩的双重保留,再引入多尺度交叉注意力后,特征融合效果进一步提升,成为最优设计。
在通用图像融合中的拓展应用
依托引导式修复的灵活设计,UltraFusion 可轻松扩展至通用图像融合任务,突破了传统曝光融合仅能处理同一场景不同曝光图像的限制。实验中,将不同相机、不同拍摄地点的无关图像作为输入(如以含月亮 / 蓝天的欠曝光图像为引导,以另一幅过曝光图像为基准),UltraFusion 能成功将引导图像中的高光目标(月亮、蓝天)融合到过曝光图像中,且融合结果自然无伪影。该拓展实验验证了 UltraFusion 的通用性,为图像调和等下游计算机视觉任务提供了新的实现思路和方法支撑。