在本专栏的第27篇文章中,我们已经初步介绍了Transformer解码器中的掩码注意力(Masked Attention),核心是通过"未来掩码"保证自回归生成时不会"偷看未来"。但这只是掩码机制的一部分,在完整的Transformer训练与推理流程中,我们需要处理两类更通用的场景:
- 变长序列的批量处理:在实际训练中,我们通常将多个长度不同的句子组成一个批次(Batch),通过在短句子末尾补零(Padding)对齐长度,但这些补零的位置是无效的,不应该参与注意力计算;
- 解码器的双重约束:解码器不仅要忽略padding位置,还要在自回归生成时忽略未来的token,保证训练与推理的行为完全一致。
这就需要我们构建一套全场景的掩码机制,它是Transformer训练与推理一致性的核心保障。同时,本文将呼应第27篇的内容,将掩码的逻辑从单一的"未来掩码"扩展到完整的三类掩码,并从反向传播来说明掩码是如何实现的。
一、掩码的数学本质:注意力分数的偏置与梯度无影响性
1.1 掩码的核心数学操作
在Transformer中,掩码的作用对象是注意力分数矩阵 (Attention Scores),也就是缩放点积后的结果。我们先回顾缩放点积注意力的前半部分:
Scores=QK⊤dk \text{Scores} = \frac{QK^\top}{\sqrt{d_k}} Scores=dk QK⊤
其中 Scores∈RLQ×LK\text{Scores} \in \mathbb{R}^{L_Q \times L_K}Scores∈RLQ×LK,LQL_QLQ 是查询序列长度,LKL_KLK 是键序列长度。
掩码的核心数学操作非常简单:对需要屏蔽的位置,在注意力分数中加上一个负无穷大的偏置 。我们用 M∈RLQ×LKM \in \mathbb{R}^{L_Q \times L_K}M∈RLQ×LK 表示掩码矩阵,其中:
- Mi,j=0M_{i,j} = 0Mi,j=0:表示第 iii 个查询可以关注第 jjj 个键,不做屏蔽;
- Mi,j=−∞M_{i,j} = -\inftyMi,j=−∞:表示第 iii 个查询不可以 关注第 jjj 个键,需要屏蔽。
于是,加入掩码后的注意力分数为:
Scoresmasked=Scores+M \text{Scores}_{\text{masked}} = \text{Scores} + M Scoresmasked=Scores+M
1.2 为什么加负无穷能让权重归零?
我们来看加入掩码后的softmax计算。对于第 iii 个查询的第 jjj 个键,如果 Mi,j=−∞M_{i,j}=-\inftyMi,j=−∞,那么:
Scoresmasked,i,j=Scoresi,j−∞=−∞ \text{Scores}{\text{masked},i,j} = \text{Scores}{i,j} - \infty = -\infty Scoresmasked,i,j=Scoresi,j−∞=−∞
经过softmax函数时,e−∞=0e^{-\infty} = 0e−∞=0,因此该位置的权重会严格归零:
Weighti,j=eScoresmasked,i,j∑k=1LKeScoresmasked,i,k=0∑k=1LKeScoresmasked,i,k=0 \text{Weight}{i,j} = \frac{e^{\text{Scores}{\text{masked},i,j}}}{\sum_{k=1}^{L_K} e^{\text{Scores}{\text{masked},i,k}}} = \frac{0}{\sum{k=1}^{L_K} e^{\text{Scores}_{\text{masked},i,k}}} = 0 Weighti,j=∑k=1LKeScoresmasked,i,keScoresmasked,i,j=∑k=1LKeScoresmasked,i,k0=0
而对于未被屏蔽的位置,Mi,j=0M_{i,j}=0Mi,j=0,注意力分数保持不变,权重计算也不受影响。
1.3 掩码对梯度传播的无影响性推导
一个非常关键的问题是:掩码操作会不会影响梯度的反向传播? 答案是:不会。我们从数学上简单推导:
设损失为 LLL,我们需要计算损失对原始注意力分数 Scoresi,j\text{Scores}{i,j}Scoresi,j 的梯度。根据链式法则:
∂L∂Scoresi,j=∂L∂Weighti,j⋅∂Weighti,j∂Scoresmasked,i,j⋅∂Scoresmasked,i,j∂Scoresi,j \frac{\partial L}{\partial \text{Scores}{i,j}} = \frac{\partial L}{\partial \text{Weight}{i,j}} \cdot \frac{\partial \text{Weight}{i,j}}{\partial \text{Scores}{\text{masked},i,j}} \cdot \frac{\partial \text{Scores}{\text{masked},i,j}}{\partial \text{Scores}_{i,j}} ∂Scoresi,j∂L=∂Weighti,j∂L⋅∂Scoresmasked,i,j∂Weighti,j⋅∂Scoresi,j∂Scoresmasked,i,j
我们看最后一项:
- 如果位置 (i,j)(i,j)(i,j) 未被屏蔽,Mi,j=0M_{i,j}=0Mi,j=0,则 ∂Scoresmasked,i,j∂Scoresi,j=1\frac{\partial \text{Scores}{\text{masked},i,j}}{\partial \text{Scores}{i,j}} = 1∂Scoresi,j∂Scoresmasked,i,j=1,梯度正常回传;
- 如果位置 (i,j)(i,j)(i,j) 被屏蔽,虽然前向传播时 Weighti,j=0\text{Weight}{i,j}=0Weighti,j=0,但在反向传播时,我们仍然有 ∂Scoresmasked,i,j∂Scoresi,j=1\frac{\partial \text{Scores}{\text{masked},i,j}}{\partial \text{Scores}{i,j}} = 1∂Scoresi,j∂Scoresmasked,i,j=1。不过,由于该位置的权重对最终输出没有贡献(权重为0),因此 ∂L∂Weighti,j\frac{\partial L}{\partial \text{Weight}{i,j}}∂Weighti,j∂L 本身也会是0,梯度不会回传到被屏蔽的位置。
核心结论:掩码操作仅在前向传播时对注意力分数做"加法偏置",不引入任何可学习参数,也不改变未屏蔽位置的梯度流,因此对模型的训练没有任何负面影响,仅起到"约束注意力范围"的作用。
二、三类核心掩码的完整拆解
在《Attention Is All You Need》原论文中,共涉及三类核心掩码,我们逐一拆解其作用、数学形式与实现逻辑。
2.1 第一类:编码器Padding掩码(Encoder Padding Mask)
作用场景
在批量训练时,我们需要将多个长度不同的源句子(编码器输入)对齐到同一长度,通常在短句子末尾补零(<pad> token)。这些补零的位置是无效的,不应该被编码器的自注意力关注,也不应该被解码器的交叉注意力关注。
数学形式
设源序列的有效长度为 LsrcL_{\text{src}}Lsrc,对齐后的长度为 LmaxL_{\text{max}}Lmax。我们首先生成一个"有效位置标记向量" src_mask∈RLmaxsrc\mask \in \mathbb{R}^{L{\text{max}}}src_mask∈RLmax:
src_maskk={0,第 k 个位置是有效token−∞,第 k 个位置是padding src\_mask_k = \begin{cases} 0, & \text{第 } k \text{ 个位置是有效token} \\ -\infty, & \text{第 } k \text{ 个位置是padding} \end{cases} src_maskk={0,−∞,第 k 个位置是有效token第 k 个位置是padding
然后,将其扩展为注意力分数矩阵形状的掩码矩阵 Menc∈RLQ×LmaxM_{\text{enc}} \in \mathbb{R}^{L_Q \times L_{\text{max}}}Menc∈RLQ×Lmax(在编码器自注意力中,LQ=LmaxL_Q = L_{\text{max}}LQ=Lmax):
Menc,i,j=src_maskj,∀i M_{\text{enc},i,j} = src\_mask_j, \quad \forall i Menc,i,j=src_maskj,∀i
也就是说,所有查询位置都不关注padding的键位置。
2.2 第二类:解码器未来掩码(Decoder Future Mask / Look-ahead Mask)
作用场景
这是本专栏第27篇介绍的核心掩码,用于保证解码器的自回归特性:在生成第 iii 个目标token时,只能关注第 111 到第 iii 个已生成的token,绝对不能"偷看"第 i+1i+1i+1 到第 LtgtL_{\text{tgt}}Ltgt 个未来token。这是Transformer训练与推理一致性的核心保障。
数学形式
设目标序列长度为 LtgtL_{\text{tgt}}Ltgt,未来掩码是一个下三角矩阵 (主对角线及下方为0,上方为负无穷):
Mfuture,i,j={0,j≤i−∞,j>i M_{\text{future},i,j} = \begin{cases} 0, & j \leq i \\ -\infty, & j > i \end{cases} Mfuture,i,j={0,−∞,j≤ij>i
直观来说,第 iii 行的掩码表示:生成第 iii 个token时,只能看到前 iii 个位置。
2.3 第三类:解码器Padding掩码(Decoder Padding Mask)
作用场景
与编码器类似,解码器的目标序列在批量训练时也需要补零对齐长度。这些padding的位置同样不应该被解码器的自注意力关注。
数学形式
与编码器Padding掩码完全一致,我们生成目标序列的有效位置标记向量 tgt_mask∈RLmaxtgt\mask \in \mathbb{R}^{L{\text{max}}}tgt_mask∈RLmax,然后扩展为掩码矩阵 Mdec_pad∈RLtgt×LmaxM_{\text{dec\pad}} \in \mathbb{R}^{L{\text{tgt}} \times L_{\text{max}}}Mdec_pad∈RLtgt×Lmax:
Mdec_pad,i,j=tgt_maskj,∀i M_{\text{dec\_pad},i,j} = tgt\_mask_j, \quad \forall i Mdec_pad,i,j=tgt_maskj,∀i
2.4 解码器双掩码的合并逻辑
解码器的自注意力需要同时满足两个约束:不看未来 + 不看padding 。因此,我们需要将未来掩码 和解码器Padding掩码合并为一个统一的掩码矩阵。
合并逻辑非常简单:两个掩码矩阵对应位置取"逻辑或" ,只要有一个掩码要求屏蔽,最终就屏蔽。在数学上,就是对两个掩码矩阵取元素级最大值 (因为 −∞<0-\infty < 0−∞<0,取最大值等价于"只要有一个是 −∞-\infty−∞,结果就是 −∞-\infty−∞"):
Mdec=max(Mfuture,Mdec_pad) M_{\text{dec}} = \max(M_{\text{future}}, M_{\text{dec\_pad}}) Mdec=max(Mfuture,Mdec_pad)
三、数值实例:长度为3的序列手算验证
我们沿用本专栏第27篇的例子,用一个长度为3的迷你目标序列做手算验证,直观展示未来掩码与Padding掩码如何共同修正注意力分数与权重分布。
基础设定
- 目标序列:
["I", "love", "<pad>"],有效长度为2,第3个位置是padding; - 缩放点积后的注意力分数矩阵(未加掩码):
Scores=1.02.00.50.83.01.20.30.72.5 \text{Scores} = \begin{bmatrix} 1.0 & 2.0 & 0.5 \\ 0.8 & 3.0 & 1.2 \\ 0.3 & 0.7 & 2.5 \end{bmatrix} Scores= 1.00.80.32.03.00.70.51.22.5
行表示查询位置(生成第1、2、3个token),列表示键位置(关注第1、2、3个token); - 模型维度 dk=2d_k=2dk=2,缩放因子 dk≈1.414\sqrt{d_k} \approx 1.414dk ≈1.414(为了简化,我们假设Scores已经是缩放后的结果)。
步骤1:生成未来掩码
目标序列长度为3,未来掩码是下三角矩阵:
Mfuture=0−∞−∞00−∞000 M_{\text{future}} = \begin{bmatrix} 0 & -\infty & -\infty \\ 0 & 0 & -\infty \\ 0 & 0 & 0 \end{bmatrix} Mfuture= 000−∞00−∞−∞0
步骤2:生成解码器Padding掩码
目标序列第3个位置是padding,因此Padding掩码为:
Mdec_pad=00−∞00−∞00−∞ M_{\text{dec\_pad}} = \begin{bmatrix} 0 & 0 & -\infty \\ 0 & 0 & -\infty \\ 0 & 0 & -\infty \end{bmatrix} Mdec_pad= 000000−∞−∞−∞
步骤3:合并双掩码
对两个掩码矩阵取元素级最大值:
Mdec=max(Mfuture,Mdec_pad)=0−∞−∞00−∞00−∞ M_{\text{dec}} = \max(M_{\text{future}}, M_{\text{dec\_pad}}) = \begin{bmatrix} 0 & -\infty & -\infty \\ 0 & 0 & -\infty \\ 0 & 0 & -\infty \end{bmatrix} Mdec=max(Mfuture,Mdec_pad)= 000−∞00−∞−∞−∞
注意:第3行第3列虽然未来掩码允许关注,但Padding掩码要求屏蔽,因此最终合并为 −∞-\infty−∞。
步骤4:修正注意力分数
将原始Scores与合并后的掩码相加:
Scoresmasked=Scores+Mdec=1.0−∞−∞0.83.0−∞0.30.7−∞ \text{Scores}{\text{masked}} = \text{Scores} + M{\text{dec}} = \begin{bmatrix} 1.0 & -\infty & -\infty \\ 0.8 & 3.0 & -\infty \\ 0.3 & 0.7 & -\infty \end{bmatrix} Scoresmasked=Scores+Mdec= 1.00.80.3−∞3.00.7−∞−∞−∞
步骤5:计算注意力权重
对每一行做softmax计算:
- 第1行(生成第1个token):只能关注第1个位置
Weight1=softmax(1.0,−∞,−∞)=1.0,0.0,0.0 \text{Weight}_1 = \text{softmax}(1.0, -\\infty, -\\infty) = 1.0, 0.0, 0.0 Weight1=softmax(1.0,−∞,−∞)=1.0,0.0,0.0 - 第2行(生成第2个token):可以关注第1、2个位置,忽略第3个
Weight2=softmax(0.8,3.0,−∞)=e0.8,e3.0,0e0.8+e3.0≈0.099,0.901,0.0 \text{Weight}_2 = \text{softmax}(0.8, 3.0, -\\infty) = \frac{e\^{0.8}, e\^{3.0}, 0}{e^{0.8} + e^{3.0}} \approx 0.099, 0.901, 0.0 Weight2=softmax(0.8,3.0,−∞)=e0.8+e3.0e0.8,e3.0,0≈0.099,0.901,0.0 - 第3行(生成第3个token,实际是padding,训练时会被忽略):可以关注第1、2个位置,忽略第3个
Weight3=softmax(0.3,0.7,−∞)≈0.401,0.599,0.0 \text{Weight}_3 = \text{softmax}(0.3, 0.7, -\\infty) \approx 0.401, 0.599, 0.0 Weight3=softmax(0.3,0.7,−∞)≈0.401,0.599,0.0
结果分析
- 未来掩码成功屏蔽了所有"未来"位置(第1行的第2、3列,第2行的第3列);
- Padding掩码成功屏蔽了所有padding位置(所有行的第3列);
- 最终的注意力权重严格符合自回归与变长序列处理的要求,与本专栏第27篇的示例形成了呼应与升级。
四、代码实现
我们实现与原论文完全对齐的通用掩码生成函数,支持批量数据处理,包括编码器Padding掩码、解码器未来掩码、解码器双掩码的生成。
完整代码实现
python
import torch
import torch.nn as nn
import numpy as np
def generate_padding_mask(seq: torch.Tensor, pad_idx: int) -> torch.Tensor:
"""
生成Padding掩码,适用于编码器自注意力、解码器交叉注意力
:param seq: 输入序列,shape [batch_size, seq_len]
:param pad_idx: padding token的索引
:return: Padding掩码,shape [batch_size, 1, 1, seq_len]
(扩展4维是为了兼容多头注意力的batch和head维度广播)
"""
# 生成mask矩阵:pad位置为True,非pad位置为False
mask = (seq == pad_idx)
# 扩展为4维:[batch_size, 1, 1, seq_len]
# 这样可以在多头注意力中广播到 [batch_size, n_heads, L_Q, L_K]
return mask.unsqueeze(1).unsqueeze(2)
def generate_future_mask(seq_len: int) -> torch.Tensor:
"""
生成未来掩码(Look-ahead Mask),适用于解码器自注意力
:param seq_len: 目标序列长度
:return: 未来掩码,shape [1, 1, seq_len, seq_len]
(扩展4维是为了兼容批量和多头维度广播)
"""
# 生成下三角矩阵:主对角线及下方为0,上方为1
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1)
# 转换为布尔类型:上方为True(需要mask),下方为False
mask = mask.bool()
# 扩展为4维:[1, 1, seq_len, seq_len]
return mask.unsqueeze(0).unsqueeze(0)
def generate_decoder_mask(tgt_seq: torch.Tensor, pad_idx: int) -> torch.Tensor:
"""
生成解码器自注意力的统一掩码:合并未来掩码和Padding掩码
:param tgt_seq: 目标序列,shape [batch_size, tgt_len]
:param pad_idx: padding token的索引
:return: 解码器统一掩码,shape [batch_size, 1, tgt_len, tgt_len]
"""
batch_size, tgt_len = tgt_seq.size()
# 1. 生成Padding掩码
pad_mask = generate_padding_mask(tgt_seq, pad_idx)
# 2. 生成未来掩码
future_mask = generate_future_mask(tgt_len)
# 3. 合并掩码:逻辑或(只要有一个为True,就mask)
# 在布尔运算中,| 表示逻辑或
combined_mask = pad_mask | future_mask
return combined_mask
def apply_mask(scores: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
"""
将掩码应用到注意力分数矩阵上
:param scores: 注意力分数,shape [batch_size, n_heads, L_Q, L_K]
:param mask: 掩码矩阵,shape [batch_size, 1, 1, L_K] 或 [batch_size, 1, L_Q, L_K]
True表示需要mask的位置
:return: 加入掩码后的注意力分数
"""
# 将mask为True的位置,在scores中加上负无穷大
# 注意:在PyTorch中,我们用一个极小的数(如-1e9)代替-inf,避免数值问题
scores = scores.masked_fill(mask, -1e9)
return scores
# ------------------------------
# 测试代码:验证与手算实例的一致性
# ------------------------------
if __name__ == "__main__":
# 模拟手算实例的目标序列:["I", "love", "<pad>"]
# 假设pad_idx=0,"I"=1,"love"=2
tgt_seq = torch.tensor([[1, 2, 0]], dtype=torch.long)
pad_idx = 0
# 1. 测试生成解码器统一掩码
dec_mask = generate_decoder_mask(tgt_seq, pad_idx)
print("="*50)
print("解码器统一掩码(True表示需要mask):")
print(dec_mask.numpy())
print("="*50)
# 2. 测试应用掩码到手算实例的Scores上
# 手算实例的Scores矩阵
scores = torch.tensor([[[
[1.0, 2.0, 0.5],
[0.8, 3.0, 1.2],
[0.3, 0.7, 2.5]
]]], dtype=torch.float32)
# 应用掩码
masked_scores = apply_mask(scores, dec_mask)
print("原始注意力分数:")
print(scores.numpy())
print("\n加入掩码后的注意力分数:")
print(masked_scores.numpy())
print("="*50)
# 3. 计算softmax后的权重,验证与手算结果一致
weights = torch.softmax(masked_scores, dim=-1)
print("最终注意力权重:")
print(weights.numpy())
print("="*50)运行结果
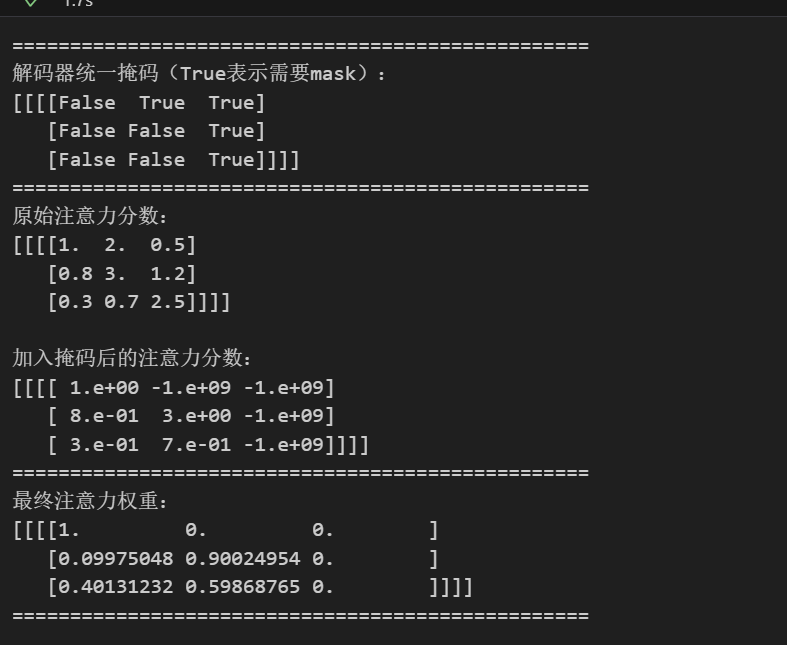
代码输出与我们的手算结果完全一致(微小差异是由于用-1e9代替了-inf),验证了实现的正确性。注意:代码中将掩码扩展为4维,是为了兼容多头注意力的"batch_size"和"n_heads"维度的广播机制,这是工程实现中的一个关键细节。
五、总结
本文完整拆解了Transformer的全场景掩码机制,核心结论如下:
- 掩码的数学本质是对注意力分数加负无穷偏置,使softmax后对应位置权重严格归零,且对梯度传播无任何影响;
- 原论文共涉及三类核心掩码:编码器Padding掩码(处理变长源序列)、解码器未来掩码(保证自回归不看未来)、解码器Padding掩码(处理变长目标序列),解码器自注意力需要合并后两类掩码;
- 通过长度为3的序列手算实例,直观展示了掩码如何修正注意力分数与权重分布,与第27篇的示例形成呼应与升级;
- 通用掩码生成函数完全对齐原论文,兼容批量数据处理,可直接复用在后续的编码器、解码器搭建中。
至此,我们已经完成了Transformer编码器、解码器所有核心基础组件的数学拆解与代码实现:注意力机制、子层连接、前馈网络、全场景掩码。接下来我们将正式进入完整编码器的搭建,整合所有已学组件,完成Transformer编码器的数学推导与代码实现。