NoSQL 集群是为应对海量数据、高并发读写、灵活数据结构而生的非关系型数据库集群方案。以 Redis 为例,通过主从复制、Sentinel 哨兵、Redis Cluster 集群等模式,实现缓存服务的高可用、水平扩展与自动故障转移。
- 对比一下,MySQL 像是一个精准的会计,专门负责记录需要绝对准确、关系清晰的交易和账本(如订单、用户信息),绝不允许出错。
- 而 NoSQL 则像是一个万能工具箱,专门用来应对 MySQL 搞不定的场景:比如处理海量数据爆发式增长、应对时刻变化的数据结构,或者需要极速读写(如实时热搜、缓存),它牺牲了部分严格规则来换取极致的灵活性和高性能。
一、关系型数据库和 NoSQL 数据库
1. 数据库类型
(1)关系型数据库
关系型数据库,是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库中的数据主流的 MySQL、Oracle、MS SQL Server 和 DB2 都属于这类传统数据库。
(2)NoSQL 数据库
NoSQL 数据库,全称为 Not Only SQL,意思就是适用关系型数据库的时候就使用关系型数据库,不适用的时候也没有必要非使用关系型数据库不可,可以考虑使用更加合适的数据存储。主要分为:
- 临时性键值存储(memcached、Redis)
- 永久性键值存储(ROMA、Redis)
- 面向文档的数据库(MongoDB、CouchDB)
- 面向列的数据库(Cassandra、HBase)
2. 为什么要用 NoSQL 数据库
主要是由于随着互联网发展,数据量越来越大,对性能要求越来越高,传统数据库存在着先天性的缺陷,即单机(单库)性能瓶颈,并且扩展困难。
这样既有单机单库瓶颈,却又扩展困难,自然无法满足日益增长的海量数据存储及其性能要求,所以才会出现了各种不同的 NoSQL 产品,NoSQL 根本性的优势在于在云计算时代,简单、易于大规模分布式扩展,并且读写性能非常高
3. RDBMS 和 NoSQL 区别
|----|------------------------------------------------------------------------------------------------------------|----------------------------------------------------|
| | 关系型数据库 | NoSQL数据库 |
| 特点 | - 数据关系模型基于关系模型,结构化存储,完整性约束 - 基于二维表及其之间的联系,需要连接、并、交、差、除等数据操作 - 采用结构化的查询语言(SQL)做数据读写 - 操作需要数据一致性,需要事务甚至是强一致性 | - 非结构化的存储 - 基于多维关系模型 - 具有特有用的使用场景 |
| 优点 | - 保持数据的一致性(事务处理) - 可以进行 join 等复杂查询 - 通用化,技术成熟 | - 高并发,大数据下读写能力较强 - 基于支持分布式,易于扩展,可伸缩 - 简单,弱结构化存储 |
| 缺点 | - 数据读写必须经过 sql 解析,大量数据,高并发下读写性能不足 - 对数据做读写,或修改数据结构时需要加锁,影响并发操作 - 无法适应非结构化存储 - 扩展困难 - 昂贵、复杂 | - join 等复杂操作能力较弱 - 事务支持较弱 - 通用性差 - 无完整约束复杂业务场景支持较差 |
二、Redis 简介
Redis 是市场上最流行,使用最广泛的内存型 NoSQL 数据库
1. Redis 特性
redis 特性
- 速度快: 10W QPS,基于内存,C语言实现
- 单线程,持久化
- 支持多种数据结构和多种编程语言
- 功能丰富: 支持 Lua 脚本,发布订阅,事务,pipeline 等功能
- 简单: 代码短小精悍(单机核心代码只有23000行左右),单线程开发容易,不依赖外部库,使用简单
- 主从复制
- 支持高可用和分布式
单线程为何如此快
- 纯内存
- 非阻塞
- 避免线程切换和竞态消耗
2. Redis 应用场景
- Session 共享:常见于web集群中的Tomcat或者PHP中多web服务器session共享
- 缓存:数据查询、电商网站商品信息、新闻内容
- 计数器:访问排行榜、商品浏览数等和次数相关的数值统计场景
- 微博/微信社交场合:共同好友,粉丝数,关注,点赞评论等
- 消息队列:ELK的日志缓存、部分业务的订阅发布系统
- 地理位置: 基于GEO(地理信息定位),实现摇一摇,附近的人,外卖等功能
三、Redis 部署
1. 创建批量操作脚本
通过循环方式来给多数主机进行统一操作,方便安装编译 redis
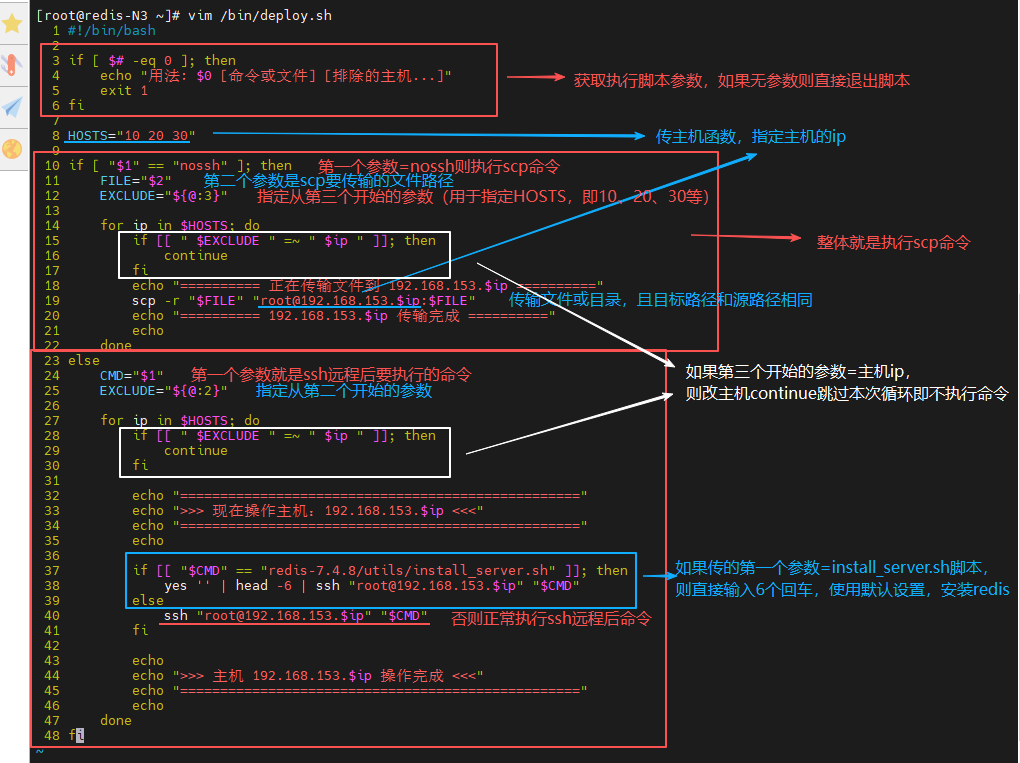
脚本解析------scp 命令区域
- 如果要执行"scp"命令,则第一个参数要等于"nossh"
- 然后第二个参数就是"scp"需要传输的文件/目录的路径
- 从第三个开始的参数作为不执行命令的主机
脚本解析------ssh 命令区域
-
如果要执行"ssh"命令,则第一个参数就是"ssh"远程后需要执行的命令
-
当第一个参数等于"redis-7.4.8/utils/install_server.sh"脚本时,也就是安装 redis 的脚本,则直接输入6个回车,使用默认设置(端口、配置文件、日志文件、数据目录和执行文件)
-
若第一个参数不等于"redis-7.4.8/utils/install_server.sh"脚本时,则正常执行命令
-
从第二个开始的参数作为不执行命令的主机
[root@redis-N1 ~]# vim /bin/deploy.sh
#!/bin/bashif [ # -eq 0 ]; then echo "用法: 0 [命令或文件] [排除的主机...]"
exit 1
fiHOSTS="10 20 30"
if [ "1" == "nossh" ]; then FILE="2"
EXCLUDE="${@:3}"for ip in $HOSTS; do if [[ " $EXCLUDE " =~ " $ip " ]]; then continue fi echo "========== 正在传输文件到 192.168.153.$ip ==========" scp -r "$FILE" "root@192.168.153.$ip:$FILE" echo "========== 192.168.153.$ip 传输完成 ==========" echo doneelse
CMD="1" EXCLUDE="{@:2}"for ip in $HOSTS; do if [[ " $EXCLUDE " =~ " $ip " ]]; then continue fi echo "==================================================" echo ">>> 现在操作主机:192.168.153.$ip <<<" echo "==================================================" echo if [[ "$CMD" == "redis-7.4.8/utils/install_server.sh" ]]; then yes '' | head -6 | ssh "root@192.168.153.$ip" "$CMD" else ssh "root@192.168.153.$ip" "$CMD" fi echo echo ">>> 主机 192.168.153.$ip 操作完成 <<<" echo "==================================================" echo donefi
[root@redis-N1 ~]# chmod +x /bin/deploy.sh
[root@redis-N1 ~]# deploy.sh nossh "/bin/deploy.sh" 10

2. 部署 Redis
(1)编译 Redis
redis 下载地址:https://download.redis.io/releases/
redis 下载链接:https://download.redis.io/releases/redis-7.4.8.tar.gz
安装依赖并进行编译 redis
[root@redis-N1 ~]# deploy.sh "dnf install make gcc initscripts -y"
[root@redis-N1 ~]# deploy.sh "wget https://download.redis.io/releases/redis-7.4.8.tar.gz"
[root@redis-N1 ~]# deploy.sh "tar zxf redis-7.4.8.tar.gz"
[root@redis-N1 ~]# deploy.sh "cd redis-7.4.8;make && make install"
(2)安装 Redis
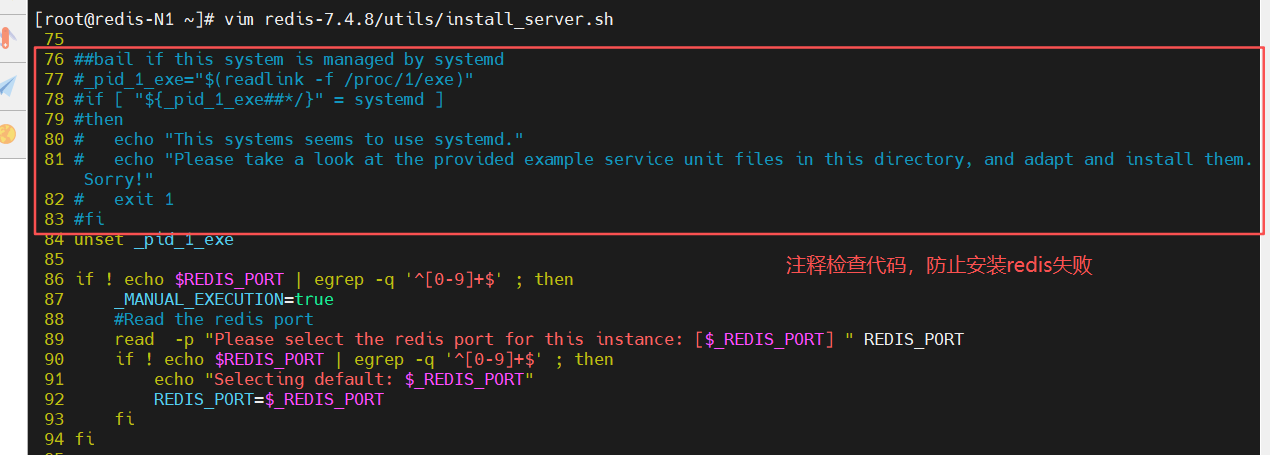
编辑"/install_server.sh"脚本,将76-83行的检查 systemd 代码注释掉,防止安装时会因报错退出安装
-
注释后运行"/install_server.sh"脚本(redis 安装脚本)后会自动创建"/etc/init.d/redis_6379"
-
可通过"systemctl start redis_6379"命令来启动 redis 服务
[root@redis-N1 ~]# vim redis-7.4.8/utils/install_server.sh
76 ##bail if this system is managed by systemd
77 #_pid_1_exe="(readlink -f /proc/1/exe)" 78 #if [ "{_pid_1_exe##*/}" = systemd ]
79 #then
80 # echo "This systems seems to use systemd."
81 # echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"
82 # exit 1
83 #fi
[root@redis-N1 ~]# deploy.sh nossh "redis-7.4.8/utils/install_server.sh"
安装 redis
注意:因为执行"install_server.sh"脚本即安装 redis 时,是使用默认设置,所以 redis 默认的配置文件是以端口号命名的------"/etc/redis/6379.conf"
[root@redis-N1 ~]# deploy.sh "redis-7.4.8/utils/install_server.sh"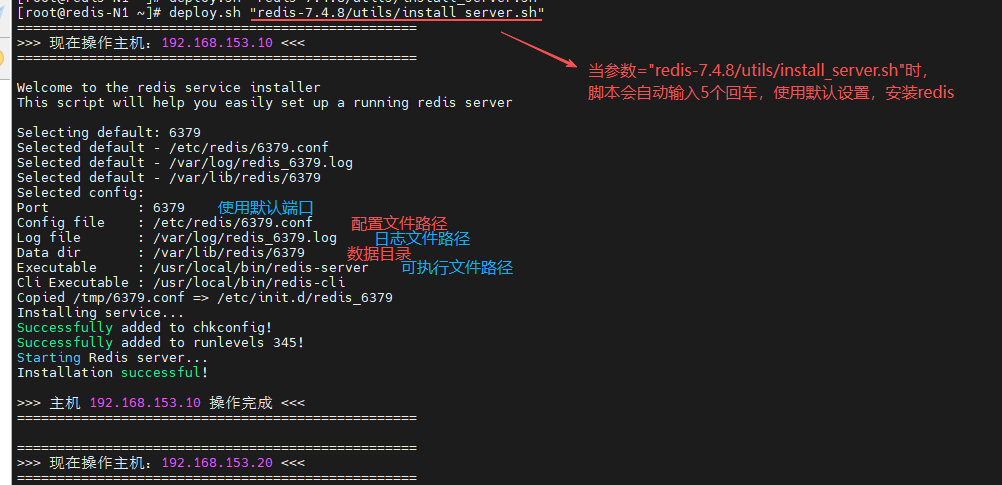
启动 redis
[root@redis-N1 ~]# deploy.sh "systemctl daemon-reload"
[root@redis-N1 ~]# deploy.sh "systemctl restart redis_6379.service"
[root@redis-N1 ~]# deploy.sh "systemctl status redis_6379.service"
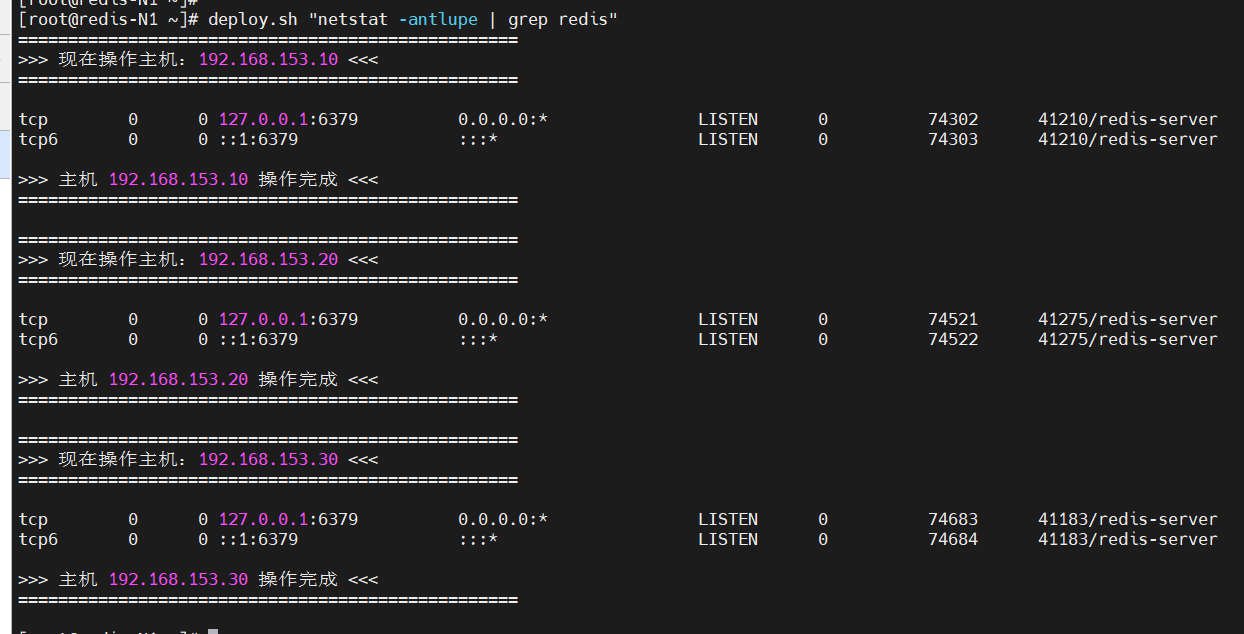
[root@redis-N1 ~]# deploy.sh "netstat -antlupe | grep redis"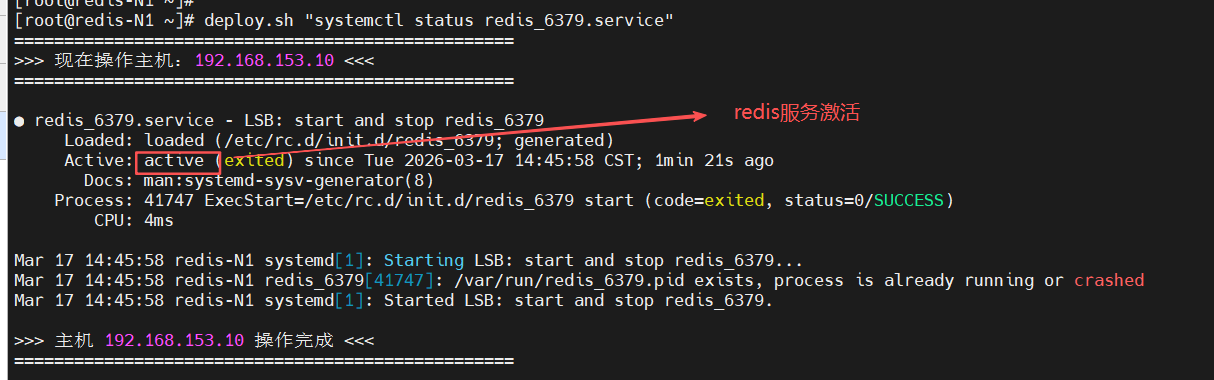
3. Redis 基础命令
(1)查看配置
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> CONFIG GET bind
127.0.0.1:6379> CONFIG GET *
127.0.0.1:6379> quit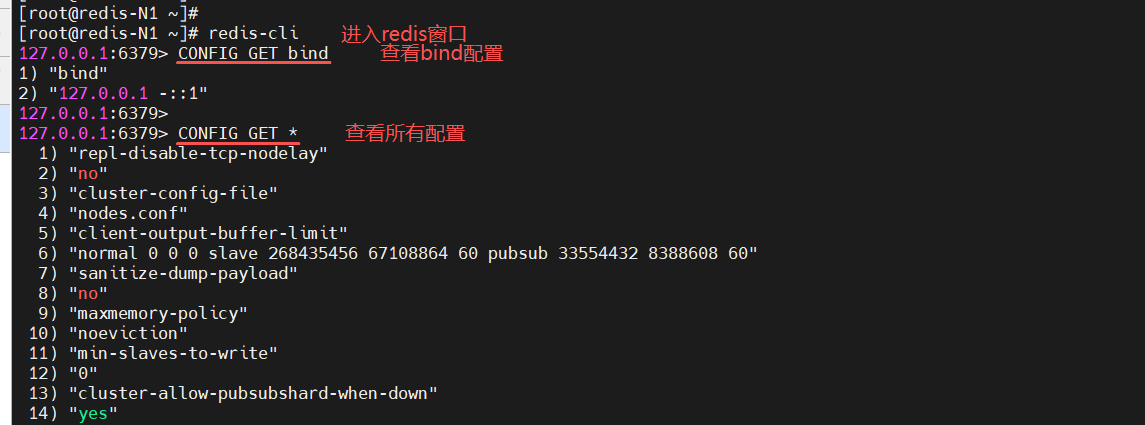
(2)读写数据
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> SET name lee
127.0.0.1:6379> GET name
127.0.0.1:6379> KEYS *
127.0.0.1:6379> quit
(3)删除数据
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> set name lee
127.0.0.1:6379> get name
127.0.0.1:6379> DEL name
127.0.0.1:6379> get name
127.0.0.1:6379> quit
(4)改键名
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> set name lee
127.0.0.1:6379> get name
127.0.0.1:6379> rename name id
127.0.0.1:6379> get name
127.0.0.1:6379> get id
127.0.0.1:6379> quit
(5)选择数据库
redis 有0-15号(共16个)数据库,默认在0号数据库
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> GET name
127.0.0.1:6379> SELECT 1
127.0.0.1:6379[1]> GET name
127.0.0.1:6379[1]> KEYS *
127.0.0.1:6379[1]> SELECT 15
127.0.0.1:6379[15]> SELECT 16
127.0.0.1:6379[15]> quit
(6)移动数据
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> set name lee
127.0.0.1:6379> move name 2
127.0.0.1:6379> get name
127.0.0.1:6379> select 2
127.0.0.1:6379[2]> get name
127.0.0.1:6379[2]> quit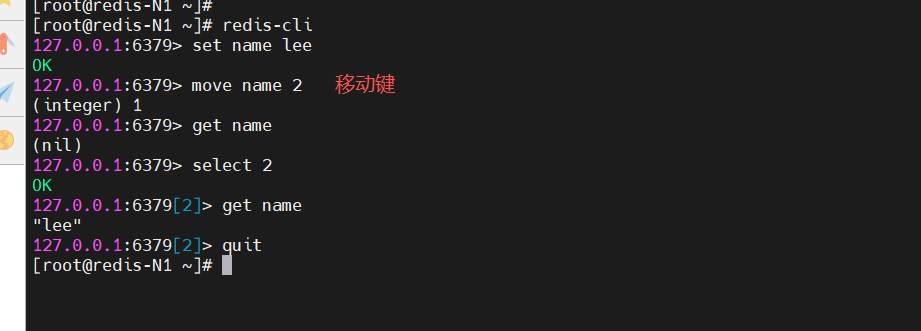
(7)设置过期时间
如果没有设定数据过期时间会一直存在, 即在"/var/lib/redis/6379/dump.rdb"内存快照中
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> set name lee
127.0.0.1:6379> get name
127.0.0.1:6379> set name lee ex 3
127.0.0.1:6379> get name
127.0.0.1:6379> set name lee ex 10000
127.0.0.1:6379> get name
127.0.0.1:6379> expire name 1
127.0.0.1:6379> get name
127.0.0.1:6379> quit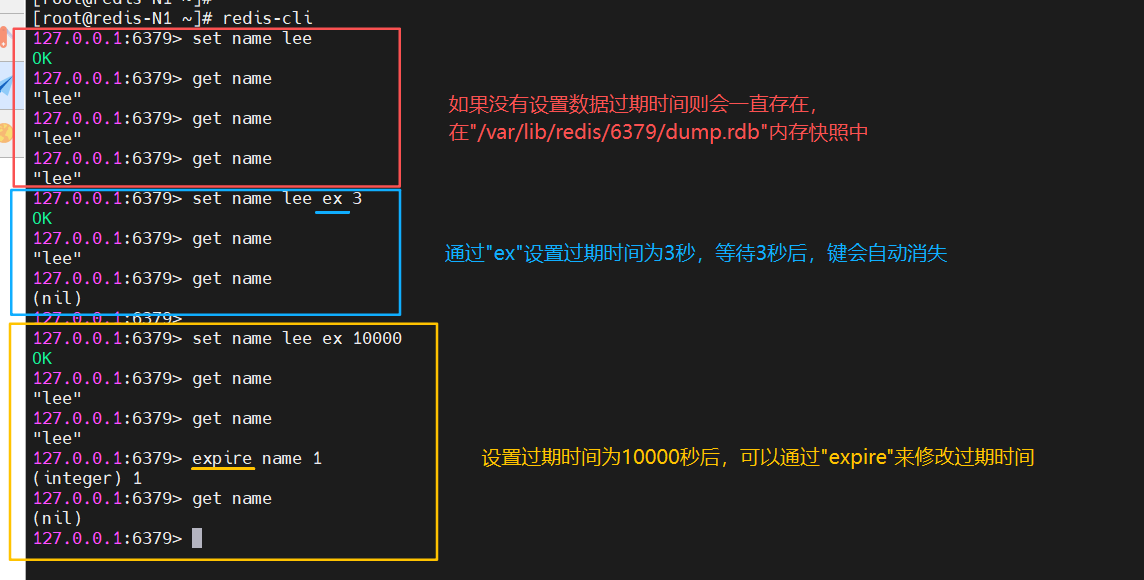
(8)持久化保存
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> set name lee
127.0.0.1:6379> get name
127.0.0.1:6379> persist name
127.0.0.1:6379> set id timing ex 10000
127.0.0.1:6379> get id
127.0.0.1:6379> persist id
127.0.0.1:6379> quit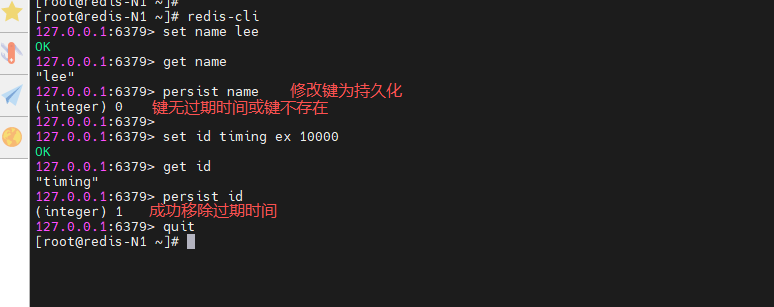
(9)判断 key 是否存在
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> exists name
127.0.0.1:6379> get name
127.0.0.1:6379> exists lee
127.0.0.1:6379> get lee
127.0.0.1:6379> quit
(10)清空数据库
清空当前库的数据
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> KEYS *
127.0.0.1:6379> FLUSHDB
127.0.0.1:6379> KEYS *
127.0.0.1:6379> quit
清空所有库的数据
[root@redis-N1 ~]# redis-cli -n 3
127.0.0.1:6379[3]> INFO keyspace
127.0.0.1:6379[3]> set name3 lee3
127.0.0.1:6379[3]> set id3 timing3
127.0.0.1:6379[3]> KEYS *
127.0.0.1:6379[3]> SELECT 6
127.0.0.1:6379[6]> set name6 lee6
127.0.0.1:6379[6]> set id6 timing6
127.0.0.1:6379[6]> INFO keyspace
127.0.0.1:6379[6]> FLUSHALL
127.0.0.1:6379[6]> INFO keyspace
127.0.0.1:6379[6]> quit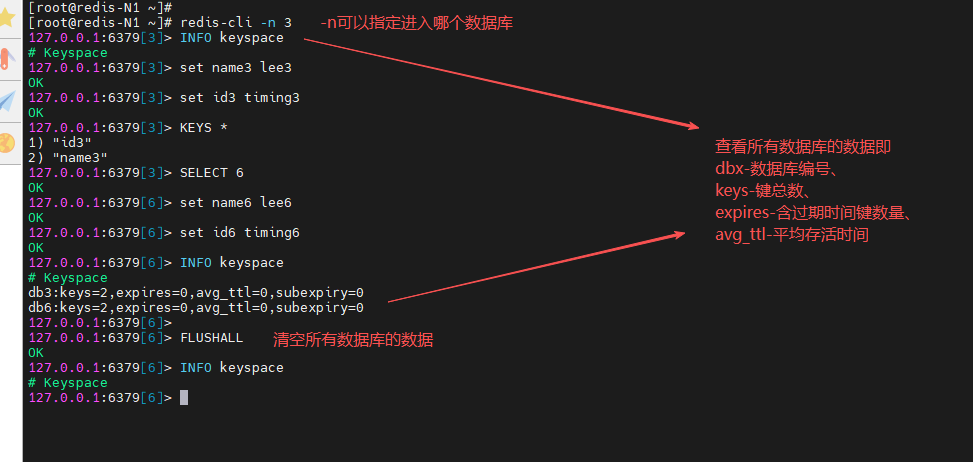
四、Redis 主从复制
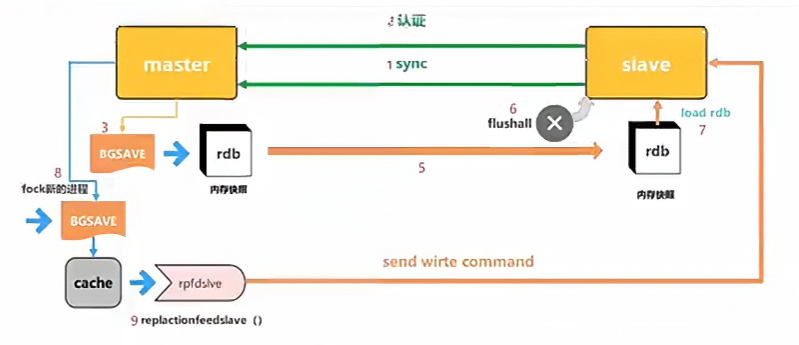
1. 主从同步过程
- slave 节点发送同步请求到 master 节点
- slave 节点通过 master 节点的认证开始进行同步
- master 节点会开启 bgsave 进程发送内存 rbd 到 slave 节点,在此过程中是异步操作,也就是说 master 节点仍然可以进行写入动作
- slave 节点收到 rdb 后首先清空自己的所有数据
- slave 节点加载 rdb 并进行数据恢复
- 在 master 和 slave 同步过程中 master 还会开启新的 bgsave 进程把没有同步的数据进行缓存
- 然后通过自有的 replactionfeedslave 函数把未通过内存快照发动到 slave 的数据一条一条写入到 slave 中
2. 部署主从复制
至少需要3台 redis 主机,一主两从
(1)配置 master 节点
编辑 redis 的主配置文件,修改 bind 允许所有 ip 访问,并关闭保护模式
[root@redis-N1 ~]# vim /etc/redis/6379.conf
89 #bind 127.0.0.1 -::1
90 bind * -::*
114 protected-mode no
[root@redis-N1 ~]# systemctl restart redis_6379.service(2)配置 slave 节点
同样允许所有 ip 访问和关闭保护模式,但需要指定主库 ip 和端口
[root@redis-N2 ~]# vim /etc/redis/6379.conf
89 #bind 127.0.0.1 -::1
90 bind * -::*
114 protected-mode no
542 replicaof 192.168.153.10 6379
[root@redis-N2 ~]# systemctl restart redis_6379.service
[root@redis-N2 ~]# scp /etc/redis/6379.conf 192.168.153.30:/etc/redis/6379.conf
[root@redis-N3 ~]# systemctl restart redis_6379.service(3)测试主从环境
查看主库状态
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> info replication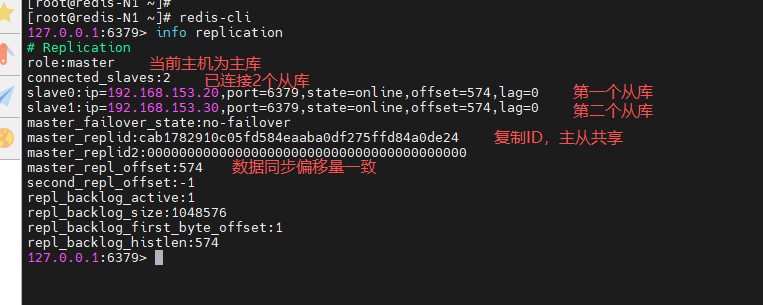
查看从库状态
[root@redis-N2 ~]# redis-cli
127.0.0.1:6379> INFO replication
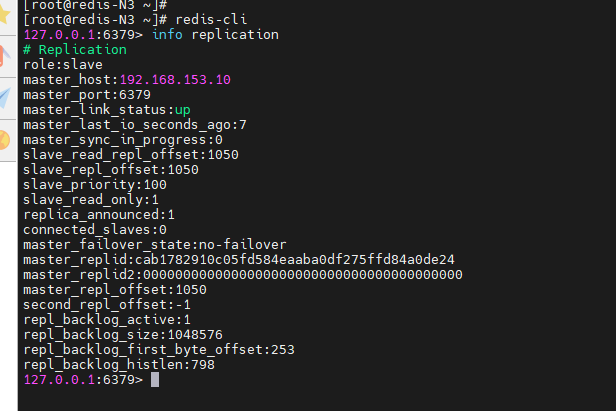
[root@redis-N3 ~]# redis-cli
127.0.0.1:6379> INFO replication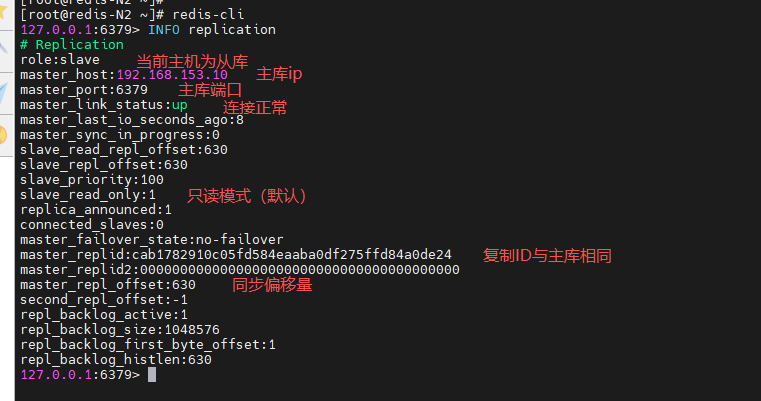
测试数据同步性
[root@redis-N2 ~]# redis-cli
127.0.0.1:6379> KEYS *
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> set name lee
127.0.0.1:6379> set id timing
[root@redis-N2 ~]# redis-cli
127.0.0.1:6379> KEYS *
127.0.0.1:6379> get name
127.0.0.1:6379> get id
测试从库是否能添加数据
[root@redis-N3 ~]# redis-cli
127.0.0.1:6379> KEYS *
127.0.0.1:6379> set haha 333
127.0.0.1:6379> KEYS *
五、Redis 哨兵模式
用一主两从来实现 Redis 的高可用架构,使主库挂后能进行转移
1. Redis 哨兵介绍
(1)Redis 哨兵简介
Sentinel 进程是用于监控 redis 集群中 Master 主服务器工作的状态,在 Master 主服务器发生故障的时候,可以实现 Master 和 Slave 服务器的切换,保证系统的高可用
在 redis2.6版本已引用,但在 redis2.8版本才稳定下来,所以建议在 redis2.8版本后使用哨兵模式
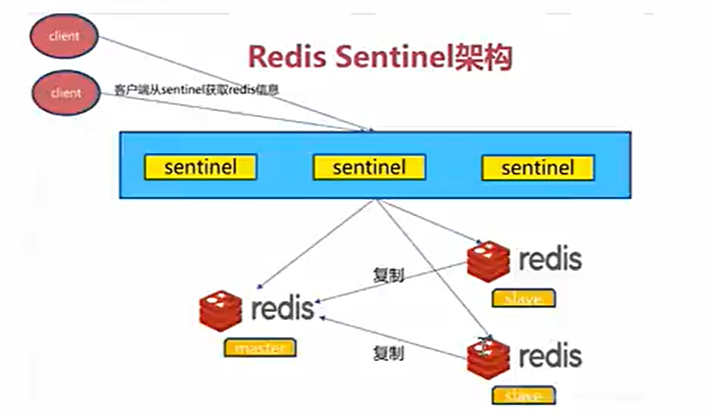
(2)主观与客观宕机
主观宕机SDOWN(Subjective Down)
- 每个哨兵(Sentinel)进程会向其它哨兵(Sentinel)、Master、Slave 定时发送消息,以确认对方是否"活"着
- 如果发现对方在指定配置时间内未得到回应,则暂时认为对方已离线,也就是所谓的"主观认为宕机"
- 主观:是每个成员都具有的独自的而且可能相同也可能不同的意识
客观宕机ODOWN(Objectively Down)
- 有主观宕机,对应的有客观宕机
- 当"哨兵群"中的多数 Sentinel 进程在对 Master 主服务器做出 SDOWN 的判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的 Master Server 下线判断,这种方式就是"客观宕机"
- 客观:是不依赖于某种意识而已经实际存在的一切事物
(3)主库转移原理
通过一定的 vote 算法,从剩下的 slave 从服务器节点中,选一台提升为 Master 服务器节点,然后自动修改相关配置,并开启故障转移(failover)
Sentinel 机制可以解决 master 和 slave 角色的自动切换问题,但单个 Master 的性能瓶颈问题无法解决,类似于 MySQL 中的 MHA 功能
Redis Sentinel 中的 Sentinel 节点个数应该为大于等于3且最好为奇数
(4)Sentinel 三个定时任务
每10秒每个 sentinel 对 master 和 slave 执行 info
- 发现slave节点
- 确认主从关系
每2秒每个 sentinel 通过 master 节点的 channel 交换信息(pub/sub)
- 通过 sentinel__:hello 频道交互
- 交互对节点的"看法"和自身信息
每1秒每个 sentinel 对其他 sentinel 和 redis 执行 pi
2. 部署哨兵模式
(1)配置哨兵
拷贝哨兵文件并进行配置
- protected-mode no------关闭保护模式,允许远程访问
- port 26379------默认 Sentinel 运行端口
- daemonize no------不以守护进程运行
- pidfile /var/run/redis-sentinel.pid------PID 文件位置
- loglevel notice------日志级别
- sentinel monitor mymaster 192.168.153.10 6379 2------监控主库
- sentinel down-after-milliseconds mymaster 10000------为了测试,设置若主库10000毫秒(10秒)无响应,则认为主库挂了
- sentinel parallel-syncs mymaster 1------发生故障转移后,同时开始同步新 master 数据的 slave 数量
- sentinel failover-timeout mymaster 180000------整个故障切换的超时时间为180000毫秒(3分钟)
配置主库的哨兵文件
[root@redis-N1 ~]# cp -p redis-7.4.8/sentinel.conf /etc/redis/
[root@redis-N1 ~]# vim /etc/redis/sentinel.conf
6 protected-mode no
10 port 26379
15 daemonize no
20 pidfile /var/run/redis-sentinel.pid
29 loglevel notice
92 sentinel monitor mymaster 192.168.153.10 6379 2
133 sentinel down-after-milliseconds mymaster 10000
208 sentinel parallel-syncs mymaster 1
233 sentinel failover-timeout mymaster 180000在从库的主配置文件关闭保护模式,并配置哨兵文件
[root@redis-N2 ~]# vim /etc/redis/6379.conf
114 protected-mode no
[root@redis-N2 ~]# systemctl restart redis_6379.service
[root@redis-N2 ~]# vim /etc/redis/6379.conf
114 protected-mode no
[root@redis-N2 ~]# systemctl restart redis_6379.service
[root@redis-N1 ~]# deploy.sh nossh "/etc/redis/sentinel.conf" 10(2)开启哨兵模式
按顺序,开启所有 redis 主机的哨兵模式,且不能退出哨兵模式窗口,否则会关闭哨兵模式(或者将哨兵模式挂入后台"redis-sentinel /etc/redis/sentinel.conf &")
[root@redis-N1 ~]# redis-sentinel /etc/redis/sentinel.conf
[root@redis-N2 ~]# redis-sentinel /etc/redis/sentinel.conf
[root@redis-N3 ~]# redis-sentinel /etc/redis/sentinel.conf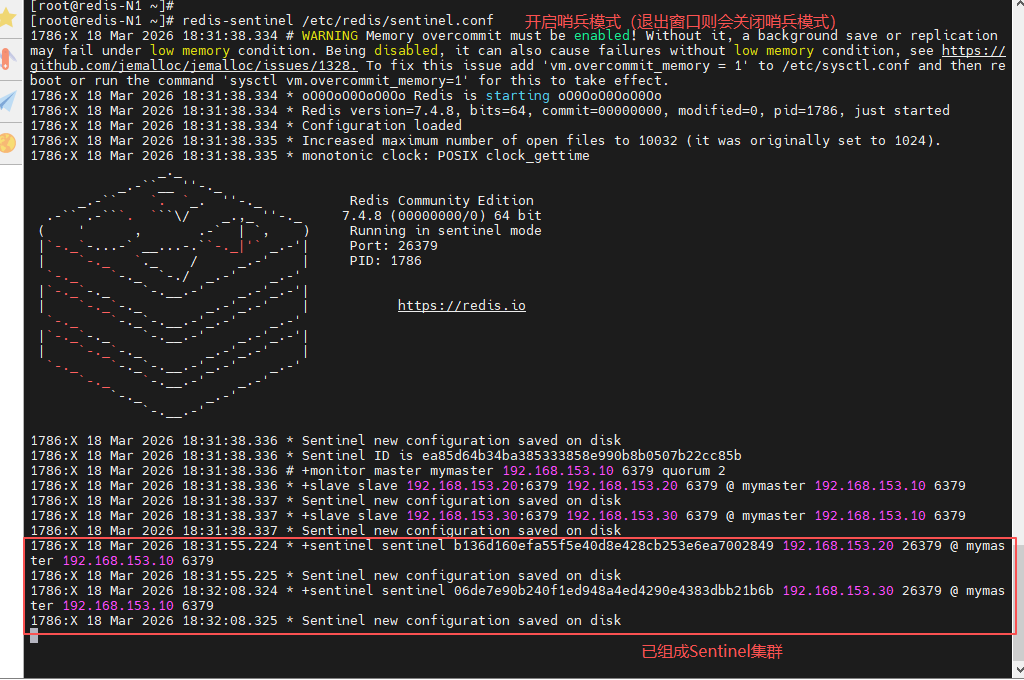
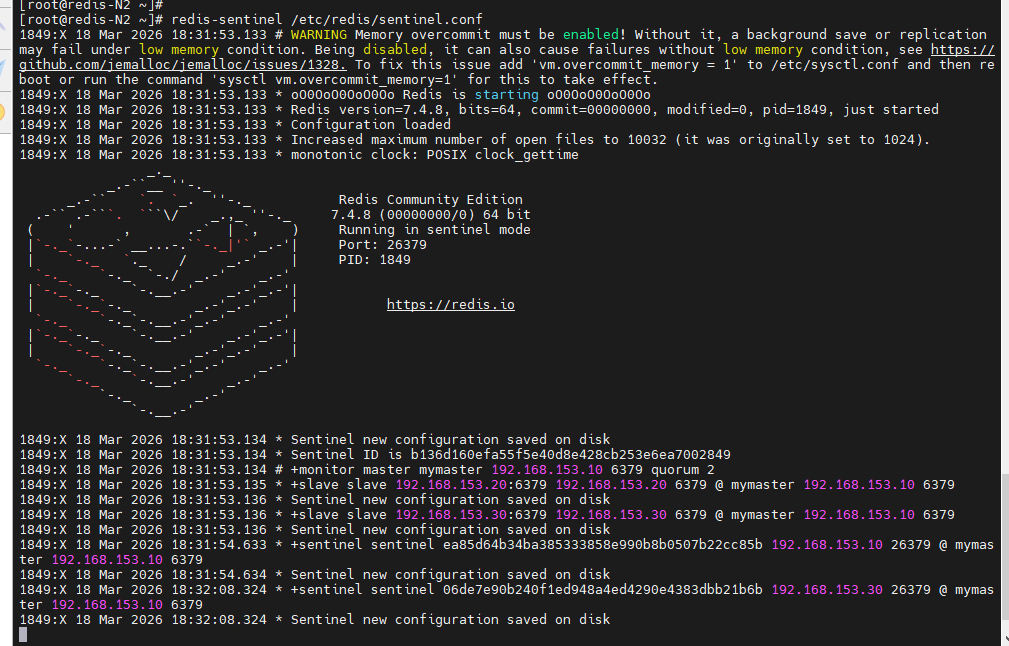
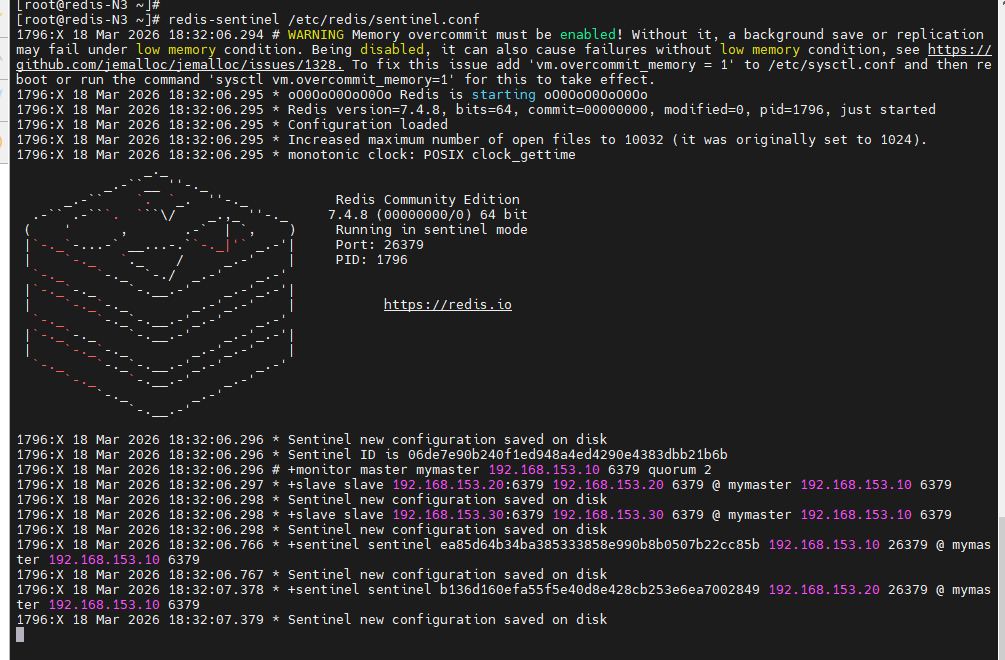
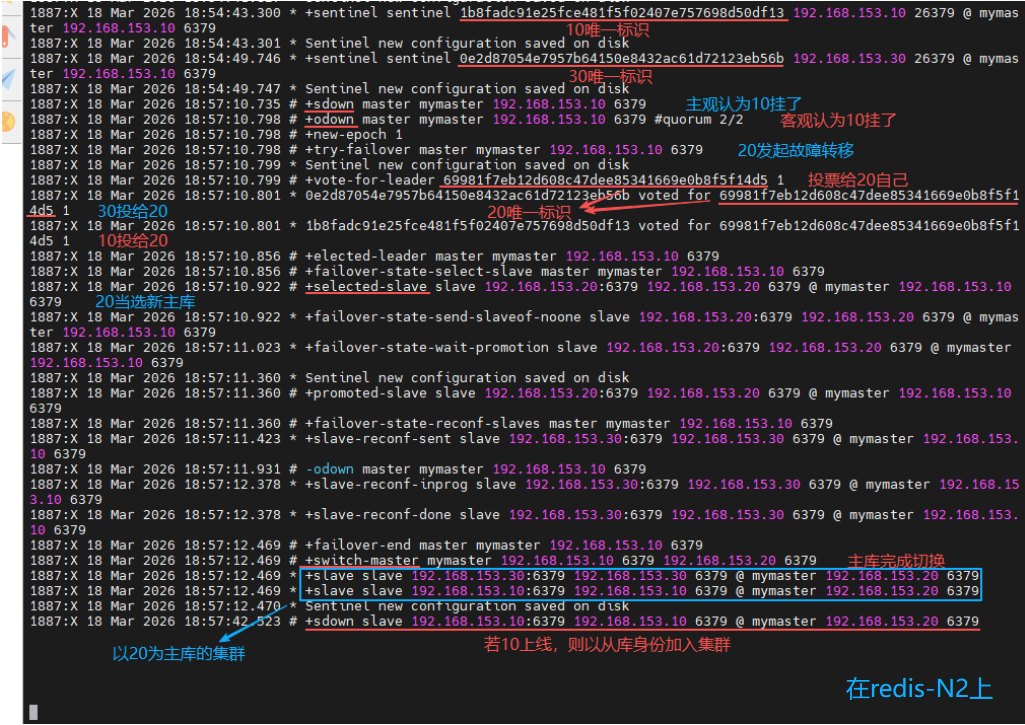
(3)测试故障切换
在不将哨兵模式切入后台的情况,复制当前 shell 窗口进行观察
- 如果要将哨兵模式切入后台则按"Ctrl键+z键",再用"bg"命令
- 如果要将哨兵模式调回前台则用"fg %1",即将作业1调回前台
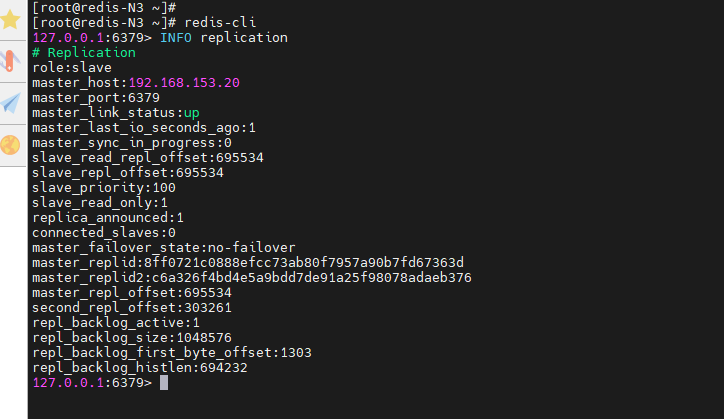
关闭 redis-N1 的 redis 服务,再观察 sentinel 实时运行日志;然后等待主库转移后,在 redis-N3 上查看信息
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> SHUTDOWN
not connected> quit
[root@redis-N3 ~]# redis-cli
127.0.0.1:6379> INFO replication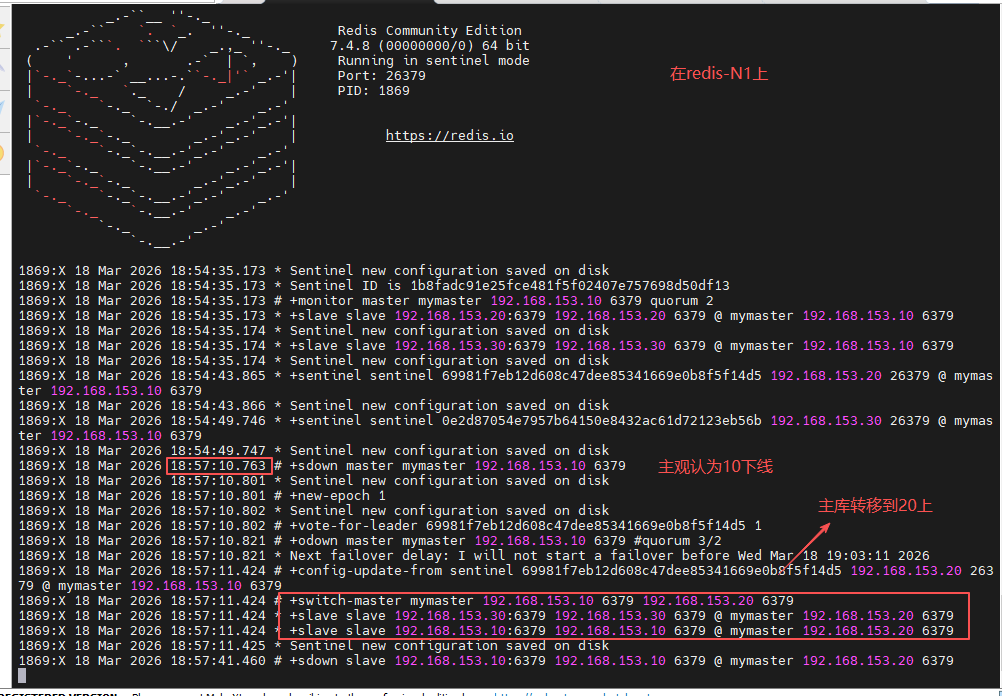
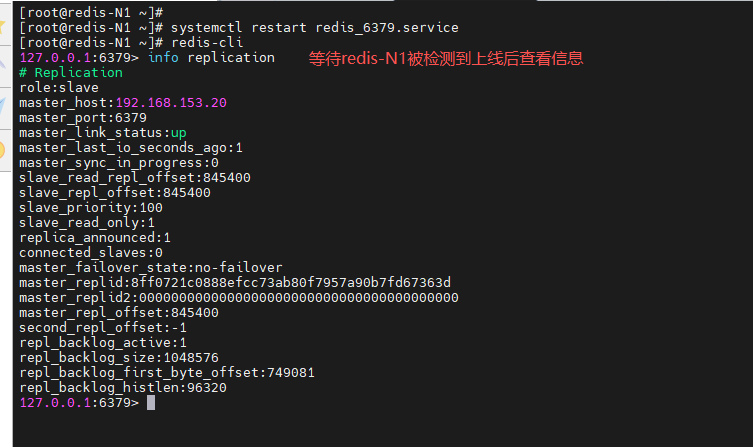
启动 redis-N1 的 redis 服务,并观察
[root@redis-N1 ~]# systemctl restart redis_6379.service
[root@redis-N1 ~]# redis-cli
127.0.0.1:6379> info replication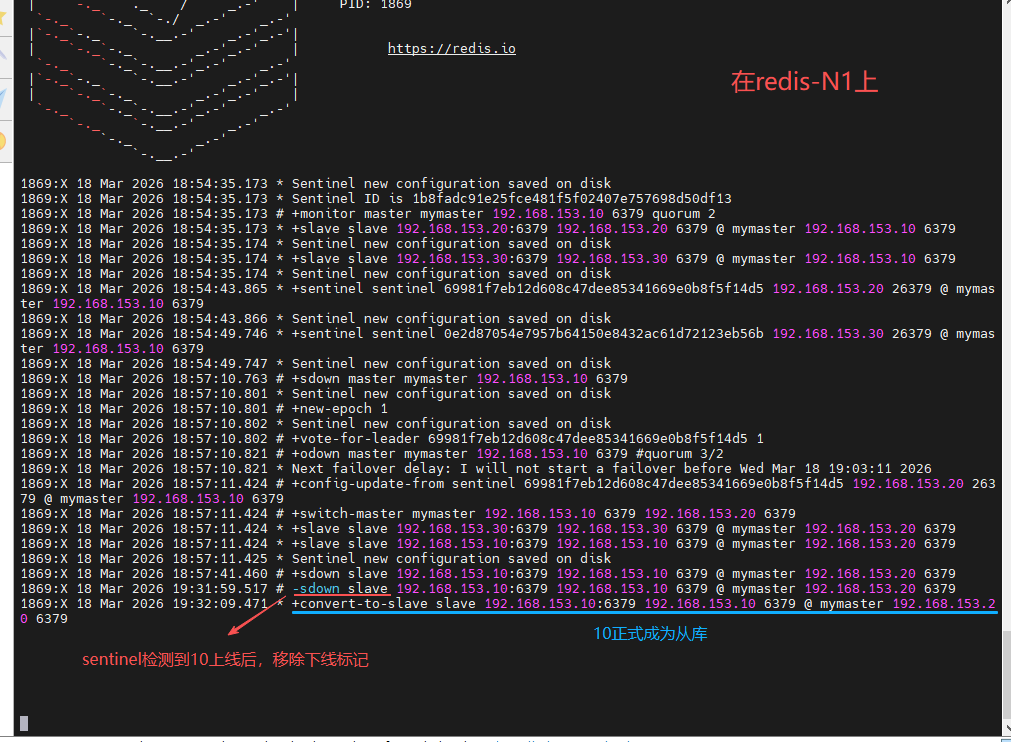
3. 架构中可能会出现的问题
问题
- 在生产环境中如果 master 和 slave 中的网络出现故障,由于哨兵的存在会把 master 提出去
- 当网络恢复后,master 发现环境发生改变,master 就会把自己的身份转换成 slave
- master 变成 slave 后会把网络故障那段时间写入自己中的数据清掉,这样数据就丢失了
解决:
- master 在被写入数据时会持续连接 slave,master 确保有2个 slave 可以写入我才允许写入
- 如果 slave 数量少于2个便拒绝写入
六、Redis Cluster
哨兵 Sentinel 能解决高可用问题,但是无法解决 redis 单机写入的瓶颈问题;所以 Redis Cluster 的出现,是为了解决单机 Redis 容量有限和不具备分布式能力的问题
1. Redis Cluster 介绍
(1)Redis Cluster 简介
redis 3.0版本之后推出了无中心架构的 redis cluster 机制,在无中心的 redis 集群当中,其每个节点保存当前节点数据和整个集群状态,每个节点都和其他所有节点连接
特点
- 所有 Redis 节点使用(PING 机制)互联
- 集群中某个节点的是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效
- 客户端不需要 proxy 即可直接连接 redis,应用程序中需要配置有全部的 redis 服务器 IP
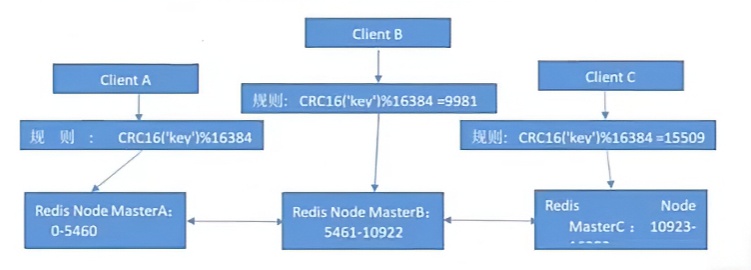
- redis cluster 把所有的 redis node 平均映射到 0-16383个槽位(slot)上,读写需要到指定的 redis node 上进行操作,因此有多少个 redis node 相当于 redis 并发扩展了多少倍,每个 redis node 承担16384/N个槽位
- Redis cluster 预先分配16384个(slot)槽位,当需要在 redis 集群中写入一个"key -value"的时候,会使用 CRC16(key) mod 16384之后的值,决定将 key 写入值哪一个槽位从而决定写入哪一个 Redis 节点上,从而有效解决单机瓶颈
- 每个槽位可以存放8000个键值对
(2)Redis Cluster 架构
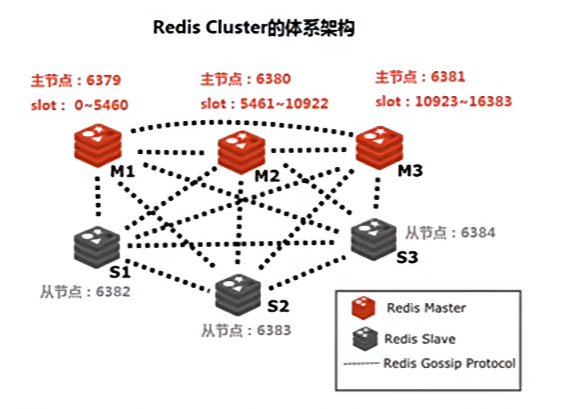
假如三个主节点分别是:A, B, C 三个节点,采用哈希槽(hash slot)的方式来分配16384个 slot 的话它们三个节点分别承担的 slot 区间可以是:
- 节点A覆盖 0-5460
- 节点B覆盖 5461-10922
- 节点C覆盖 10923-16383
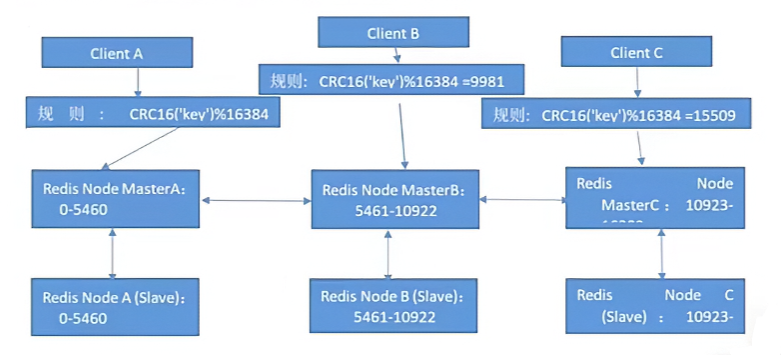
Redis Cluster 主从架构
- Redis Cluster 的架构虽然解决了并发的问题,但是又引入了一个新的问题,每个 Redis master 的高可用如何解决?
- 那就是对每个 master 节点都实现主从复制,从而实现 redis 高可用性
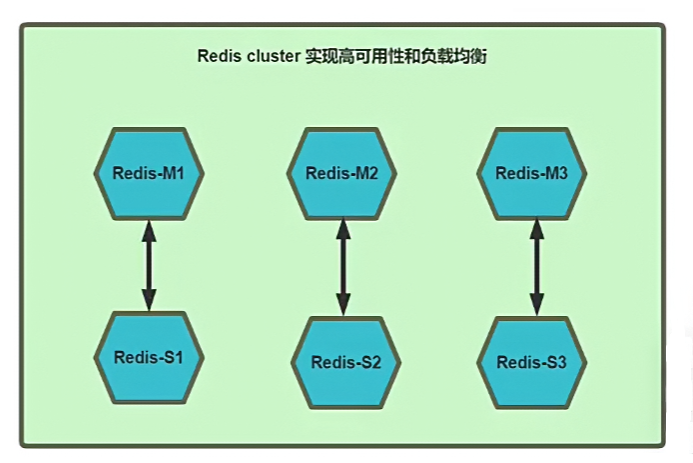
Redis Cluster 部署架构说明
(3)创建 Redis Cluster 前提
每个 redis node 节点采用相同的硬件配置、相同的密码、相同的 redis 版本
每个节点必须开启的参数
- cluster-enabled yes------必须开启集群状态,开启后 redis 进程会有 cluster 显示
- cluster-config-file nodes-6380.conf------此文件有 redis cluster 集群自动创建和维护,不需要任何手动操作
所有 redis 服务器必须没有任何数据
先启动为单机 redis 且没有任何 key value
2. 准备 Redis 环境
实验环境至少需要6台 redis 主机,制作三主三从来搭建集群
(1)创建批量操作脚本
将 HOSTS 函数修改为6台主机的 ip;添加能自定义安装 redis 时的设置区域
[root@redis-N1 ~]# vim /bin/deploy.sh
#!/bin/bash
if [ $# -eq 0 ]; then
echo "用法: $0 [命令或文件] [排除的主机...]"
exit 1
fi
HOSTS="10 20 30 40 50 60"
if [ "$1" == "nossh" ]; then
FILE="$2"
EXCLUDE="${@:3}"
for ip in $HOSTS; do
if [[ " $EXCLUDE " =~ " $ip " ]]; then
continue
fi
echo "========== 正在传输文件到 192.168.153.$ip =========="
scp -r "$FILE" "root@192.168.153.$ip:$FILE"
echo "========== 192.168.153.$ip 传输完成 =========="
echo
done
else
CMD="$1"
EXCLUDE="${@:2}"
for ip in $HOSTS; do
if [[ " $EXCLUDE " =~ " $ip " ]]; then
continue
fi
echo "=================================================="
echo ">>> 现在操作主机:192.168.153.$ip <<<"
echo "=================================================="
echo
if [[ "$CMD" == "redis-7.4.8/utils/install_server.sh" ]]; then
# yes '' | head -6 | ssh "root@192.168.153.$ip" "$CMD"
# Redis安装脚本交互配置
{
echo ""
echo "/etc/redis/redis.conf"
echo ""
echo ""
echo ""
echo ""
} | ssh "root@192.168.153.$ip" "$CMD"
else
ssh "root@192.168.153.$ip" "$CMD"
fi
echo
echo ">>> 主机 192.168.153.$ip 操作完成 <<<"
echo "=================================================="
echo
done
fi
[root@redis-N1 ~]# chmod +x /bin/deploy.sh
[root@redis-N1 ~]# deploy.sh nossh "/bin/deploy.sh" 10
(2)安装启动 redis
对所有 redis 主机进行编译安装并启动 redis 服务
编译时,如果直接在一台主机上做批量操作,可能会有点久,所以可以在它们自己的主机里做编译,减少等待时间
[root@redis-N1 ~]# deploy.sh "dnf install make gcc initscripts -y"
[root@redis-N1 ~]# deploy.sh "wget https://download.redis.io/releases/redis-7.4.8.tar.gz"
[root@redis-N1 ~]# deploy.sh "tar zxf redis-7.4.8.tar.gz"
[root@redis-N1 ~]# deploy.sh "cd redis-7.4.8;make && make install"
[root@redis-N1 ~]# vim redis-7.4.8/utils/install_server.sh
76 ##bail if this system is managed by systemd
77 #_pid_1_exe="$(readlink -f /proc/1/exe)"
78 #if [ "${_pid_1_exe##*/}" = systemd ]
79 #then
80 # echo "This systems seems to use systemd."
81 # echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"
82 # exit 1
83 #fi
[root@redis-N1 ~]# deploy.sh nossh "redis-7.4.8/utils/install_server.sh"
[root@redis-N1 ~]# deploy.sh "redis-7.4.8/utils/install_server.sh"
[root@redis-N1 ~]# vim /etc/redis/redis.conf
89 bind * -::*
113 protected-mode no
[root@redis-N1 ~]# deploy.sh nossh "/etc/redis/redis.conf"
[root@redis-N1 ~]# deploy.sh "systemctl daemon-reload"
[root@redis-N1 ~]# deploy.sh "systemctl restart redis_6379.service"
[root@redis-N1 ~]# deploy.sh "systemctl status redis_6379.service"
[root@redis-N1 ~]# deploy.sh "netstat -antlupe | grep redis"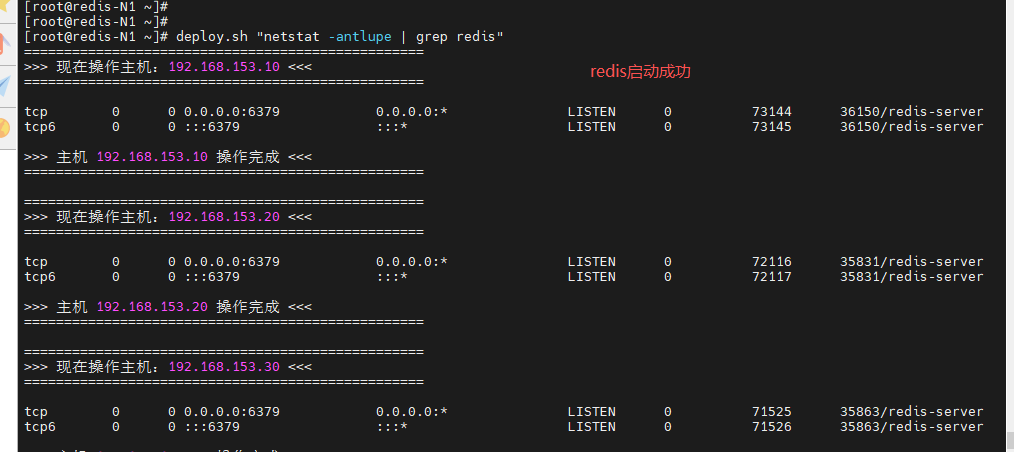
3. 部署 Redis Cluster
(1)配置集群模式
编辑主配置文件,设置集群模式,拷贝到所有主机上
-
masterauth "123456"------设置主从认证密码为123456
-
cluster-enabled yes------启用集群模式
-
cluster-config-file nodes-6379.conf------集群配置文件
-
cluster-node-timeout 15000------集群节点超时时间为15000毫秒(15秒)
[root@redis-N1 ~]# vim /etc/redis/redis.conf
548 masterauth "123456"
1597 cluster-enabled yes
1605 cluster-config-file nodes-6379.conf
1611 cluster-node-timeout 15000
[root@redis-N1 ~]# deploy.sh nossh "/etc/redis/redis.conf"
[root@redis-N1 ~]# deploy.sh "systemctl restart redis_6379.service"
(2)集群参数
[root@redis-N1 ~]# redis-cli --cluster help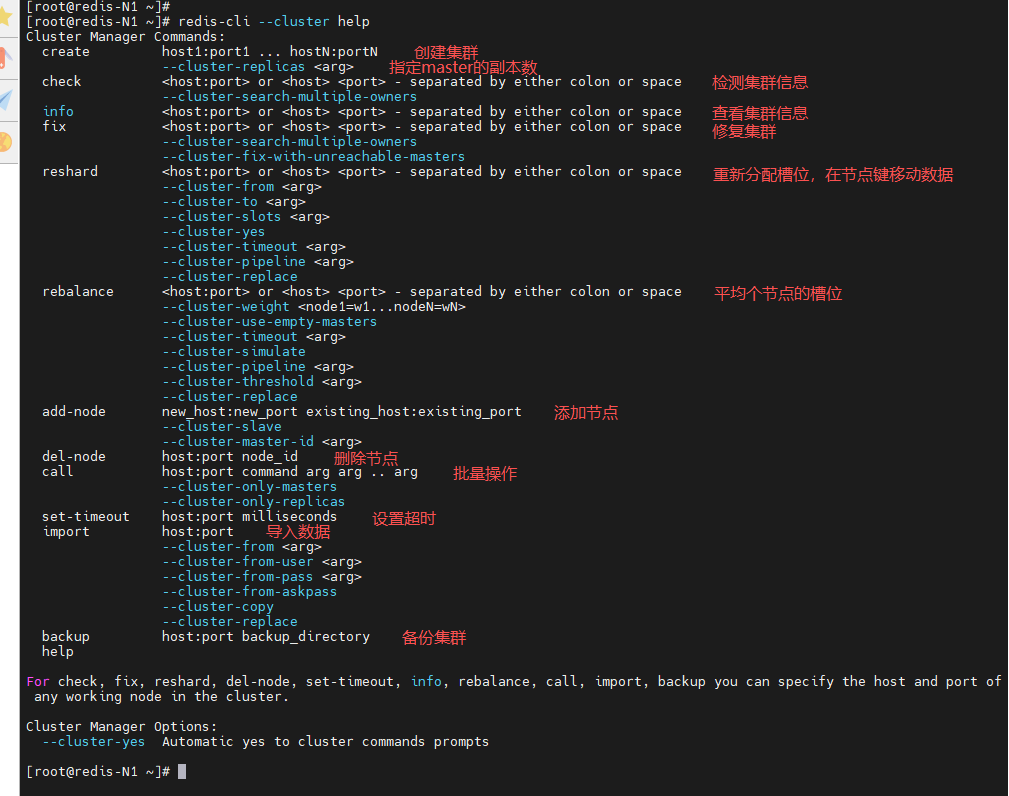
(3)启动集群
创建并启动集群
[root@redis-N1 ~]# redis-cli --cluster create 192.168.153.10:6379 192.168.153.20:6379 192.168.153.30:6379 192.168.153.40:6379 192.168.153.50:6379 192.168.153.60:6379 --cluster-replicas 1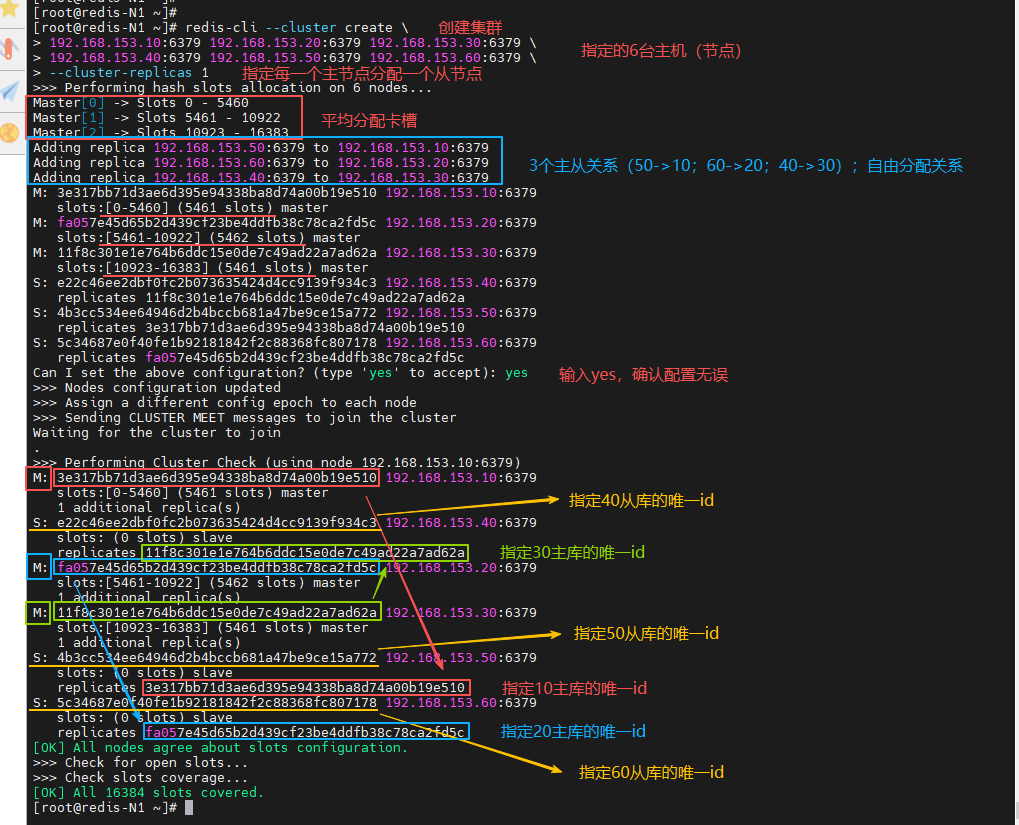
(4)查看集群状态
查看集群状态
[root@redis-N1 ~]# redis-cli --cluster info 192.168.153.10:6379
[root@redis-N1 ~]# redis-cli --cluster info 192.168.153.60:6379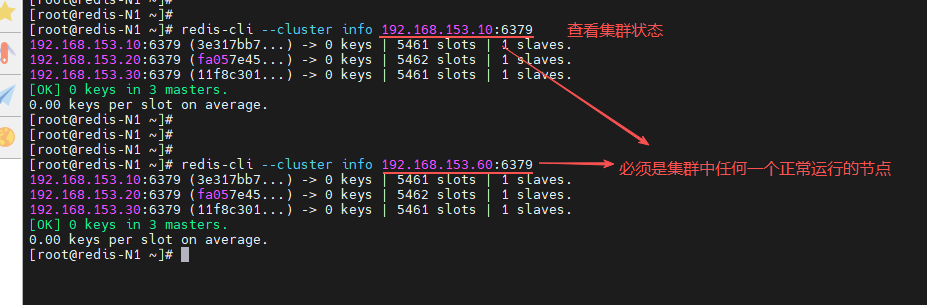
查看当前节点的集群状态
[root@redis-N1 ~]# redis-cli cluster info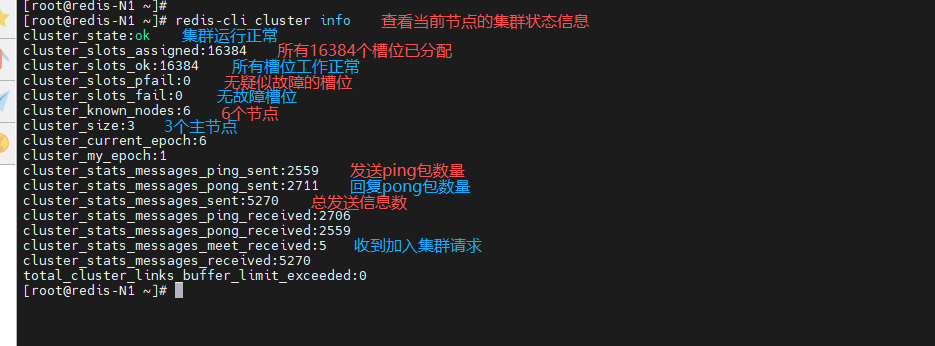
检测集群的详细状态
[root@redis-N1 ~]# redis-cli --cluster check 192.168.153.50:6379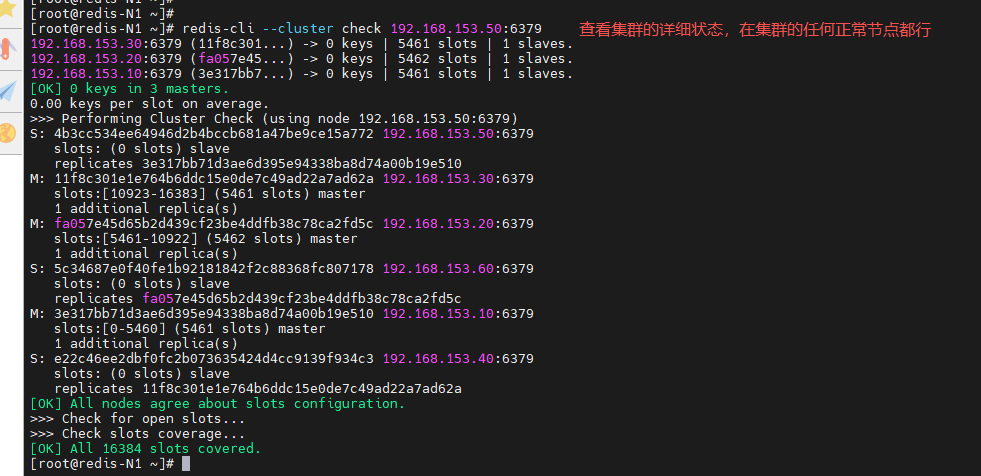
4. 集群扩容
当现有集群的存储容量或处理能力不足以支撑业务增长时,则需要扩容来增加空间和提升性能
(1)准备新节点
扩容时,需要添加一主一从即两台主机70和80
- 添加主节点------可以增加容量或性能
- 添加从加点------可以提高可用性
在之前已经配置好的主机下进行操作
-
将脚本的主机函数改为70和80
-
安装依赖后将已经编译好的"/root/redis-7.4.8"目录拷贝到两台新节点下
-
对新节点再次编译、安装 redis
-
拷贝主配置文件,并刷新服务,然后启动 redis(可能要重启两次,进程才激活)
[root@redis-N6 ~]# vim /bin/deploy.sh
8 #HOSTS="10 20 30 40 50 60"
9 HOSTS="70 80"
[root@redis-N6 ~]# deploy.sh "dnf install make gcc initscripts -y"
[root@redis-N6 ~]# deploy.sh nossh "/root/redis-7.4.8"
[root@redis-N6 ~]# deploy.sh "cd redis-7.4.8/;make install"
[root@redis-N6 ~]# deploy.sh "redis-7.4.8/utils/install_server.sh"
[root@redis-N6 ~]# deploy.sh nossh "/etc/redis/redis.conf"
[root@redis-N6 ~]# deploy.sh "systemctl daemon-reload"
[root@redis-N6 ~]# deploy.sh "systemctl restart redis_6379.service"
[root@redis-N6 ~]# deploy.sh "systemctl restart redis_6379.service"
[root@redis-N6 ~]# deploy.sh "systemctl status redis_6379.service"
[root@redis-N6 ~]# deploy.sh "netstat -antplue | grep redis"
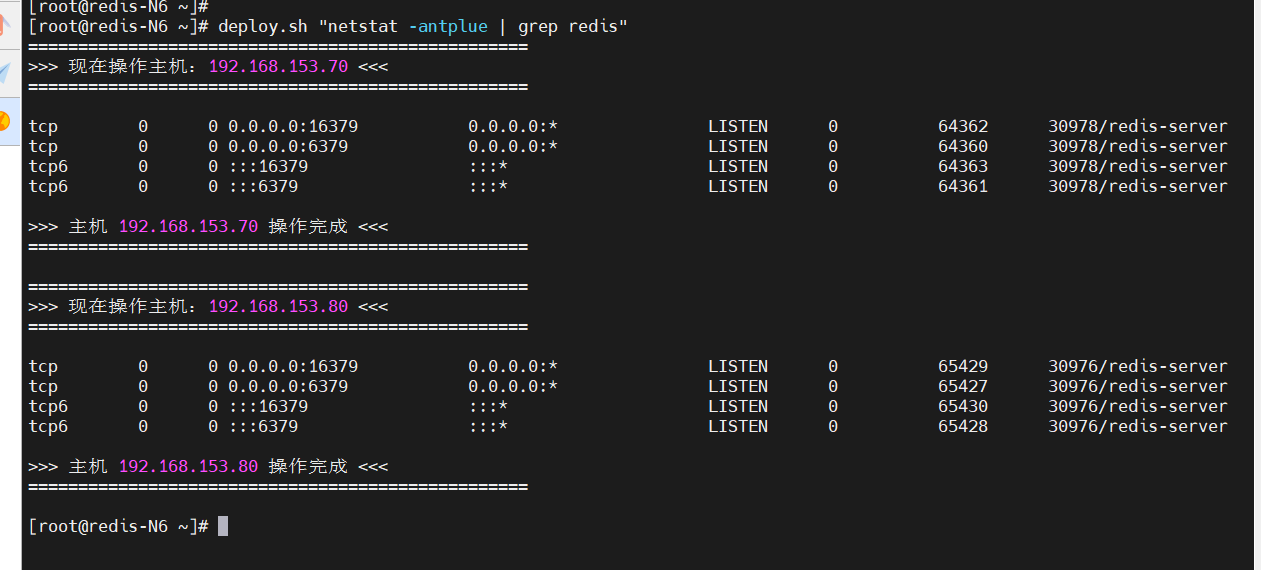
(2)添加新主节点
在集群中任意一台节点上进行操作,指定新节点加入到集群中
[root@redis-N3 ~]# redis-cli --cluster add-node 192.168.153.70:6379 192.168.153.40:6379
[root@redis-N3 ~]# redis-cli --cluster check 192.168.153.50:6379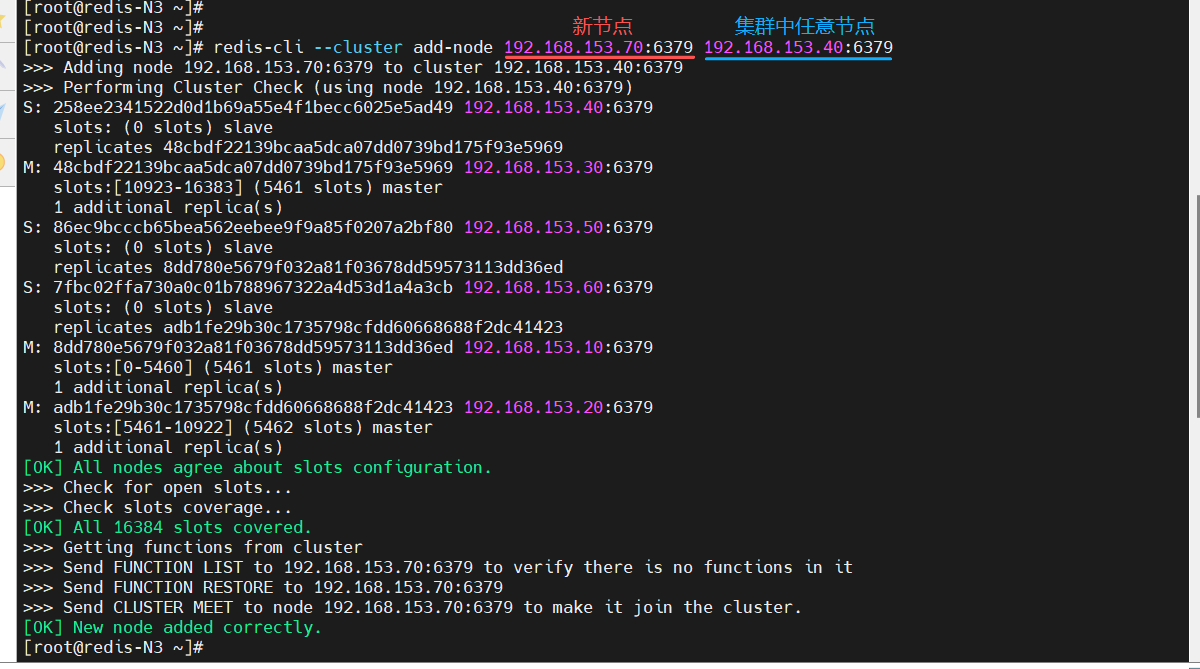
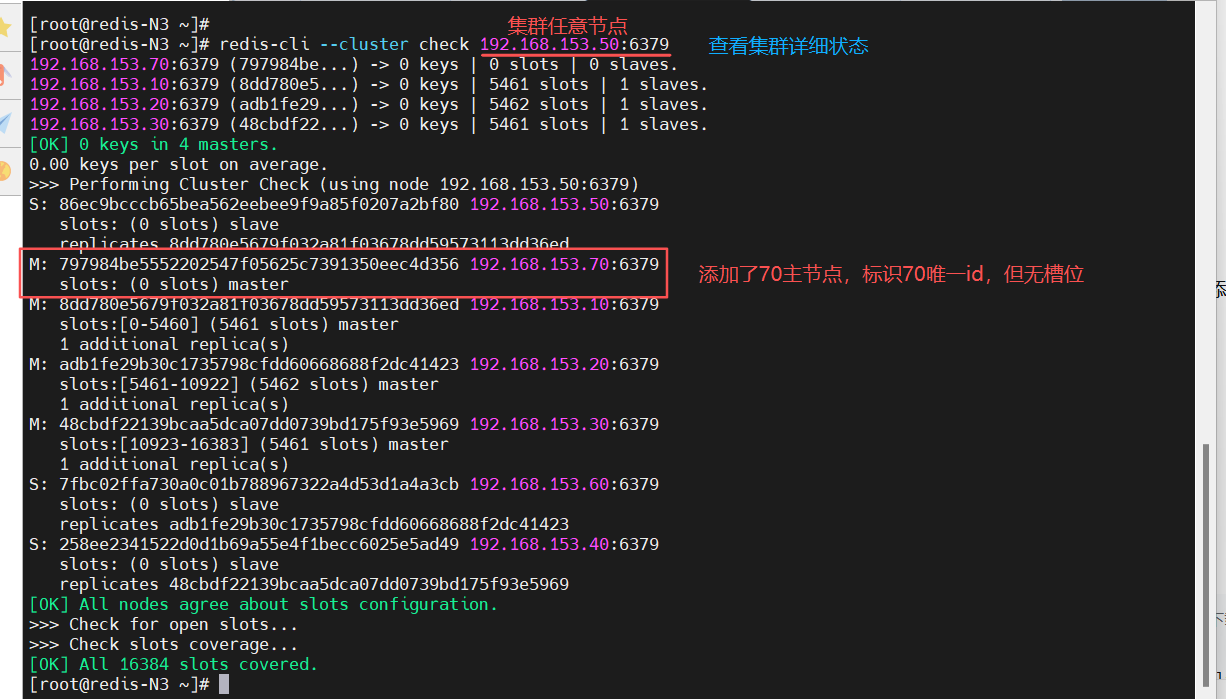
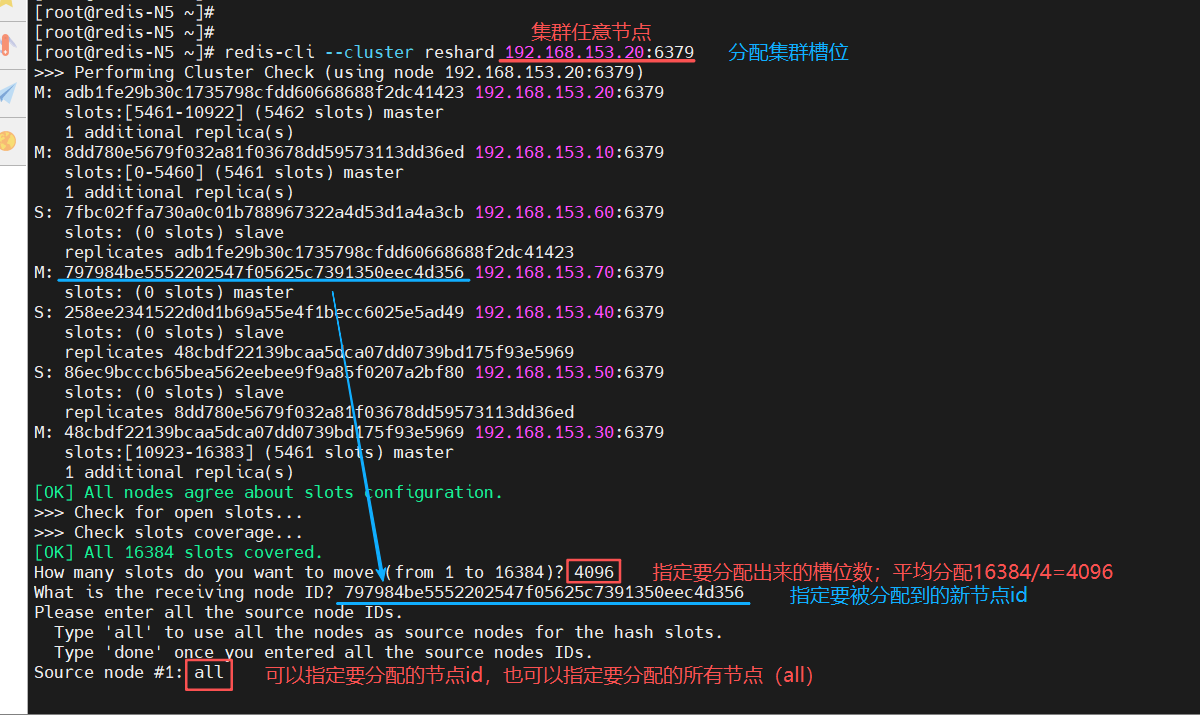
(3)分配槽位
在集群中的任意节点操作
-
指定分配槽位数量
-
被分配节点 id
-
要分配节点 id(或所有节点all);分配 id 时,可以持续写要分配的 id,然后输入 done 结束
-
输入 yes ,确认要分配槽位
[root@redis-N5 ~]# redis-cli --cluster reshard 192.168.153.20:6379
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? 797984be5552202547f05625c7391350eec4d356
Source node #1: all
······
Do you want to proceed with the proposed reshard plan (yes/no)? yes
······[root@redis-N5 ~]# redis-cli --cluster check 192.168.153.70:6379
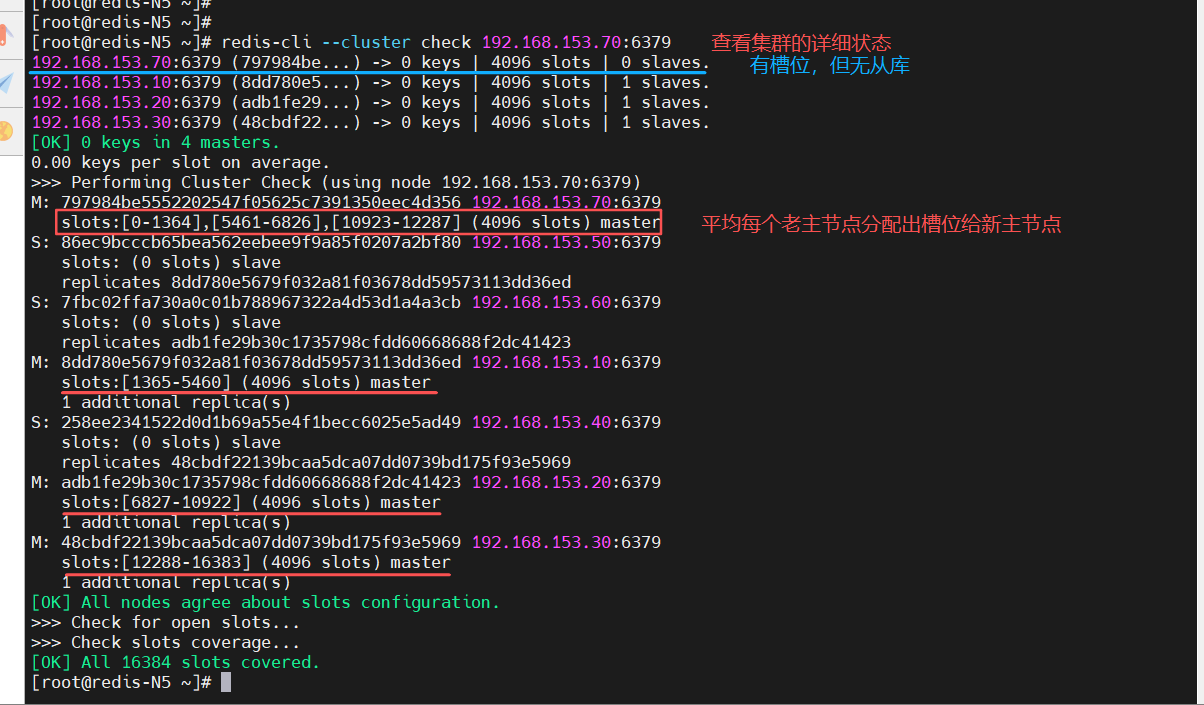
(4)添加新从节点
在集群中任意节点操作,复制70唯一 id,为70主节点添加80从节点
[root@redis-N4 ~]# redis-cli --cluster check 192.168.153.10:6379 | grep 192.168.153.70
[root@redis-N4 ~]# redis-cli --cluster add-node 192.168.153.80:6379 192.168.153.70:6379 --cluster-slave --cluster-master-id 2f340a95fad73b2816bf331ba477508eaaa1a36e
[root@redis-N4 ~]# redis-cli --cluster check 192.168.153.10:6379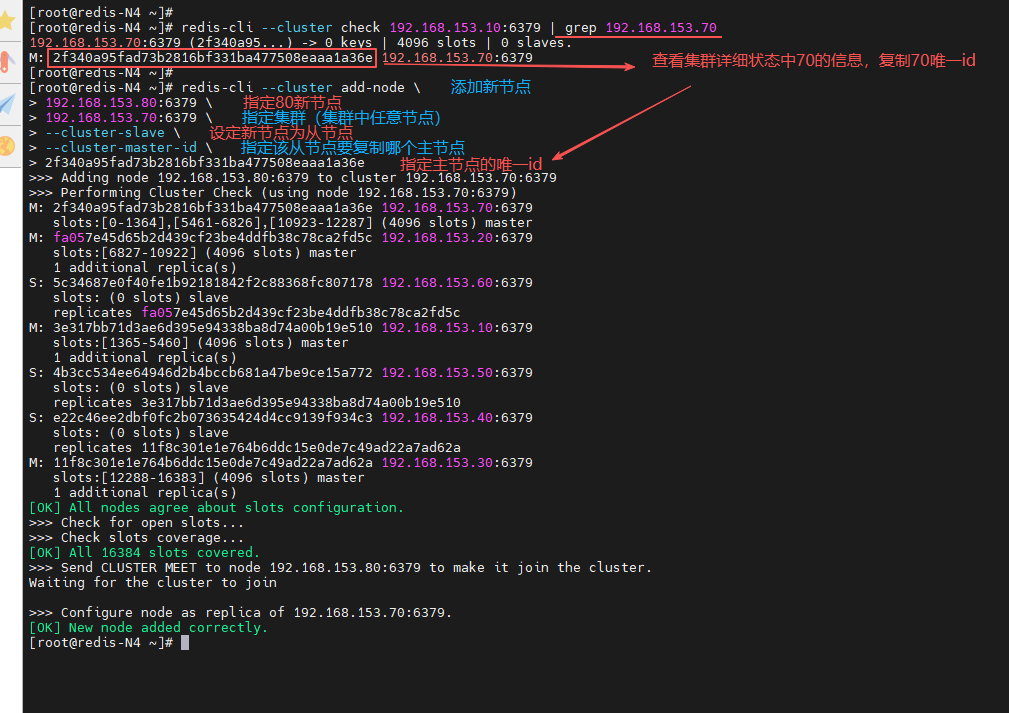
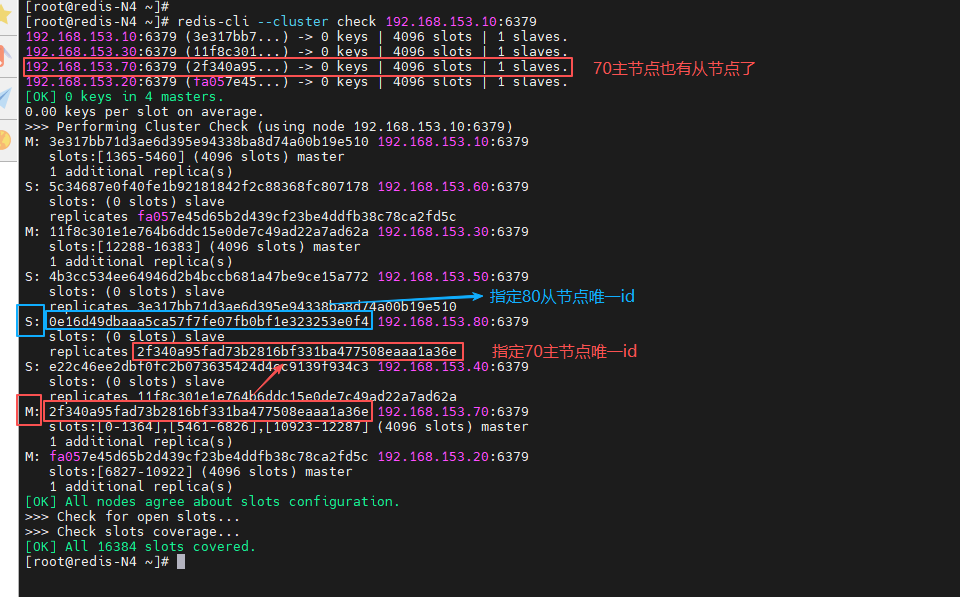
5. 集群缩容
当业务下降或资源过剩时,缩容可以移除节点、降低成本,同时避免资源浪费
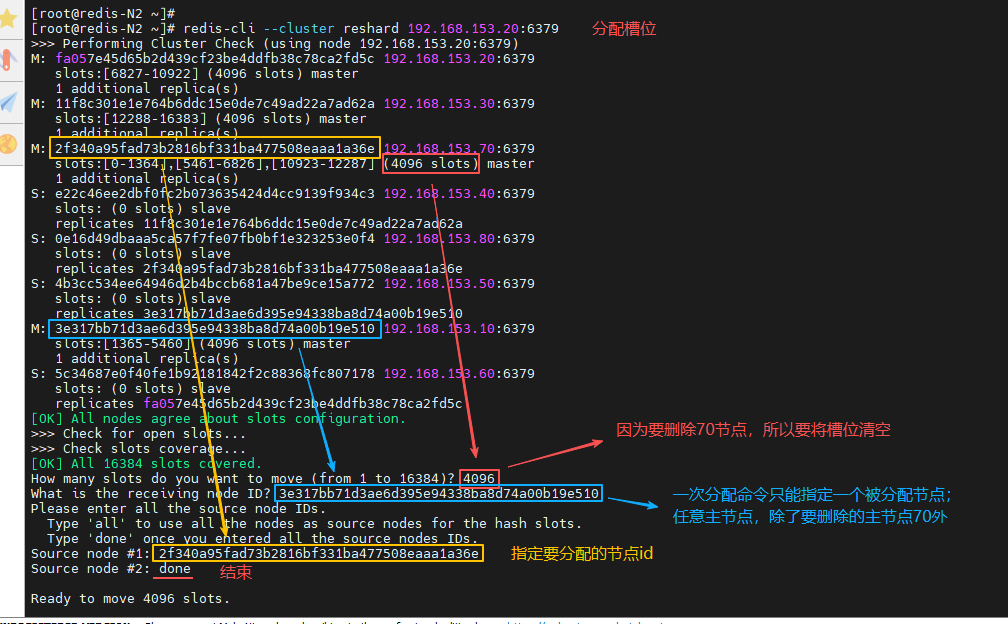
(1)回收槽位
在集群中任意节点上操作
-
分配完要删除节点的槽位
-
分配命令一次只能指定一个被分配节点,所以需要将所有槽位分配均匀需要多次执行分配命令
-
指定要分配节点的 id 后,再执行 done 结束
[root@redis-N2 ~]# redis-cli --cluster reshard 192.168.153.20:6379
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? 3e317bb71d3ae6d395e94338ba8d74a00b19e510
Source node #1: 2f340a95fad73b2816bf331ba477508eaaa1a36e
Source node #2: done
[root@redis-N2 ~]# redis-cli --cluster check 192.168.153.70:6379
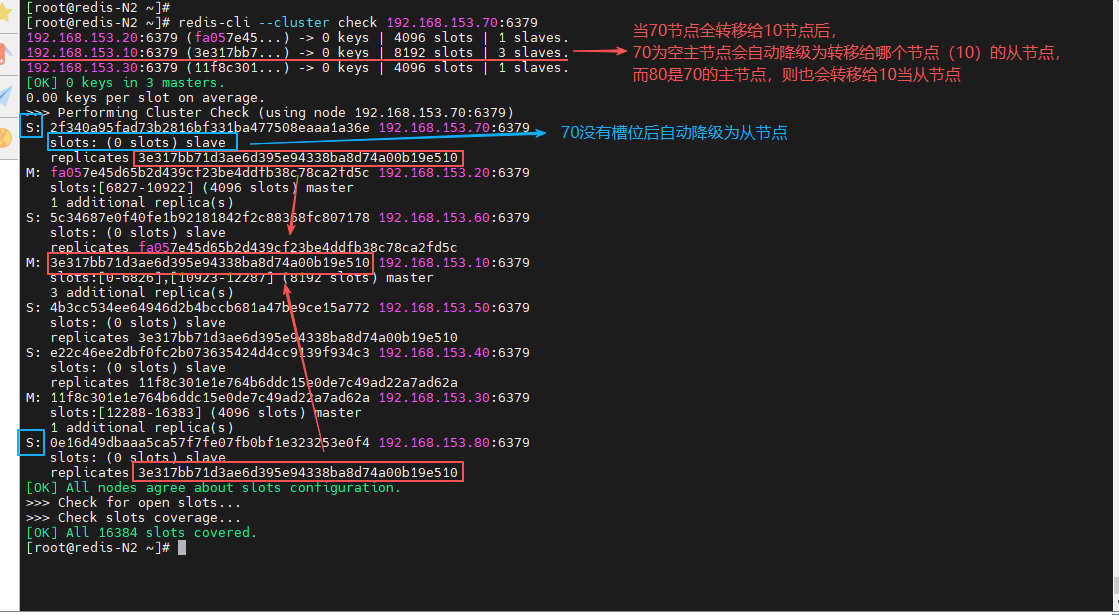
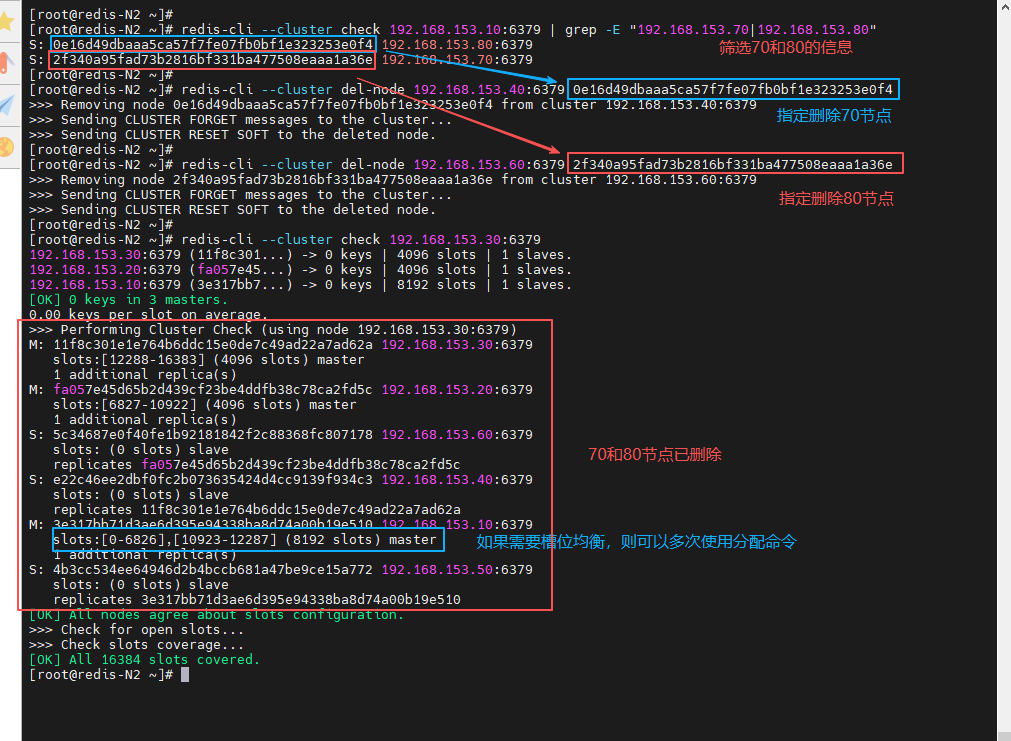
(2)删除节点
在集群中的任意节点操作,筛选删除节点的 id,并进行删除
[root@redis-N2 ~]# redis-cli --cluster check 192.168.153.10:6379 | grep -E "192.168.153.70|192.168.153.80"
[root@redis-N2 ~]# redis-cli --cluster del-node 192.168.153.40:6379 0e16d49dbaaa5ca57f7fe07fb0bf1e323253e0f4
[root@redis-N2 ~]# redis-cli --cluster del-node 192.168.153.60:6379 2f340a95fad73b2816bf331ba477508eaaa1a36e
[root@redis-N2 ~]# redis-cli --cluster check 192.168.153.30:6379