1.排序的概念及其运用
1.1排序的概念
**排序:**所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
**稳定性:**假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排 序算法是稳定的;否则称为不稳定的。
**内部排序:**数据元素全部放在内存中的排序。
**外部排序:**数据元素太多不能同时放在内存中,根据排序过程的要求不断地在内外存之间移动数据的排序。
1.2常见的排序算法
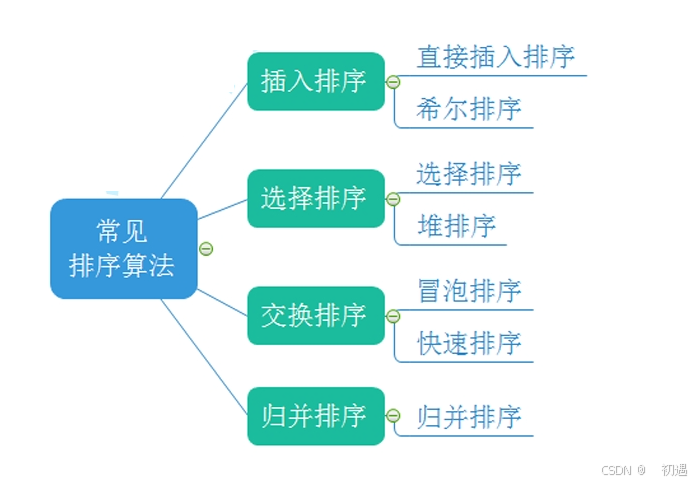
常见排序算法的实现
插入排序
1 插入排序
1.1基本思想:
插入排序的核心思想:把数组分成「已排序部分」和「未排序部分」 ,每次从未排序部分 取出第一个元素,往前插入到已排序部分的正确位置,直到整个数组有序。
1.2直接插入排序:
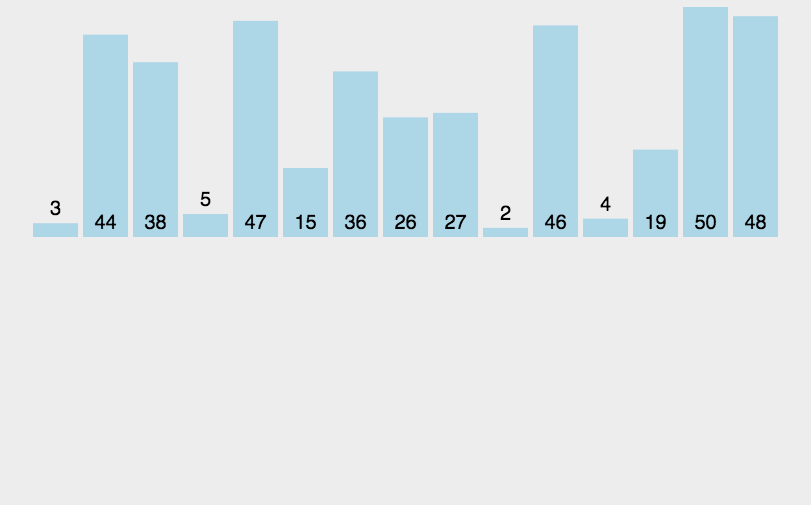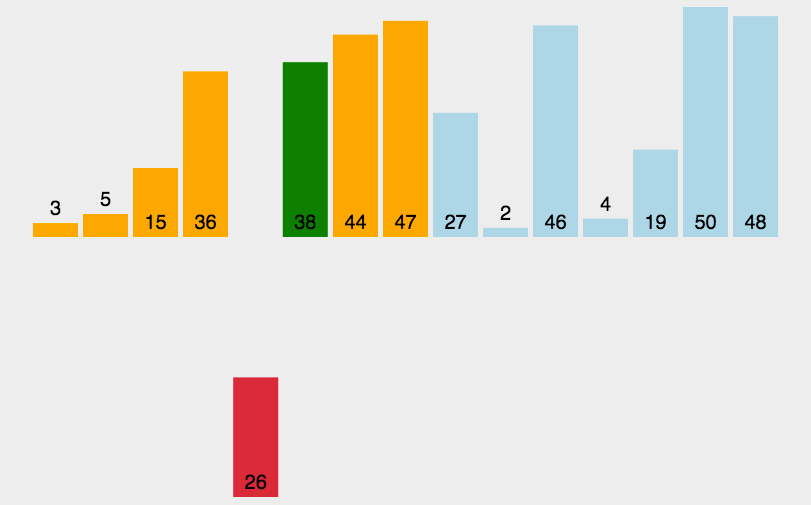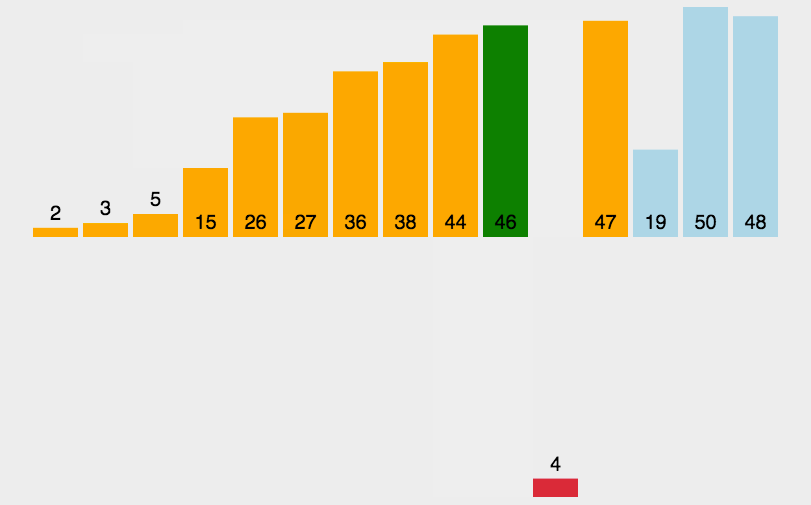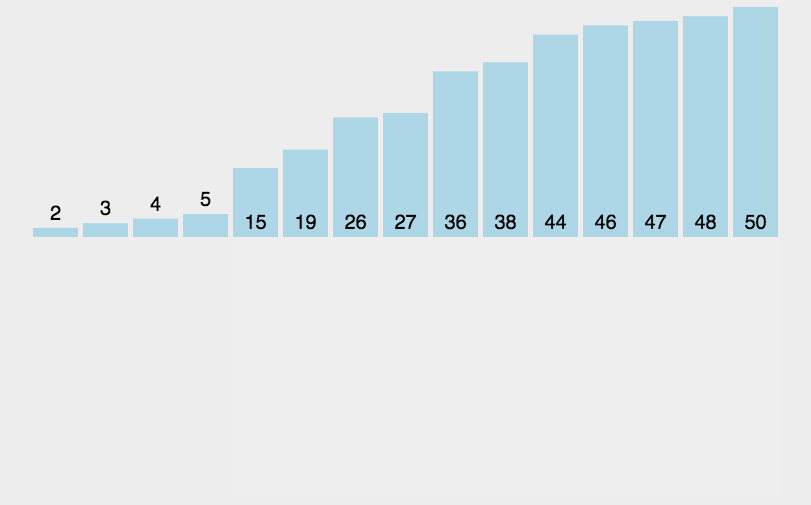
当插入第i(i>=1)个元素时,前面的array0,array1,...,arrayi-1已经排好序,此时用arrayi的排序码与 arrayi-1,arrayi-2,...的排序码顺序进行比较,找到插入位置即将arrayi插入,原来位置上的元素顺序后移
代码实现:
void insertionSort(int *arr, int n)
{
for(int i = 0; i < n - 1; i++)
{
int end = i;
int temp = arr[i + 1];
while (end >= 0) // 这里我帮你修正成 end >= 0,原来 end>0 会漏第一个元素
{
if(temp < arr[end])
{
arr[end + 1] = arr[end];
end--;
}
else{
break;
}
}
arr[end + 1] = temp;
}
}直接插入排序的特性总结:
1. 元素集合越接近有序,直接插入排序算法的时间效率越高
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1),它是一种稳定的排序算法
4. 稳定性:稳定
2希尔排序
2.1基本思想:
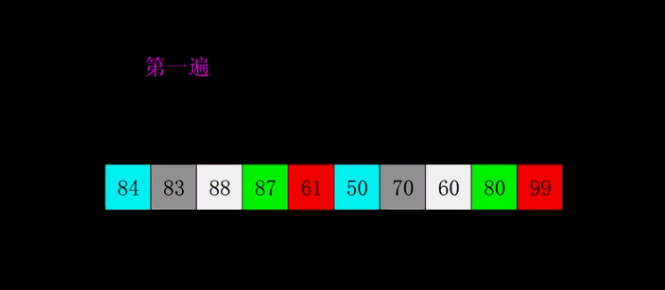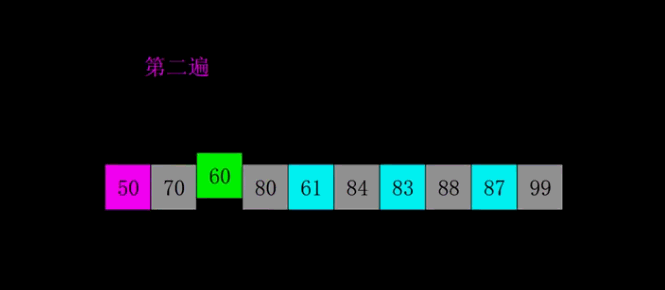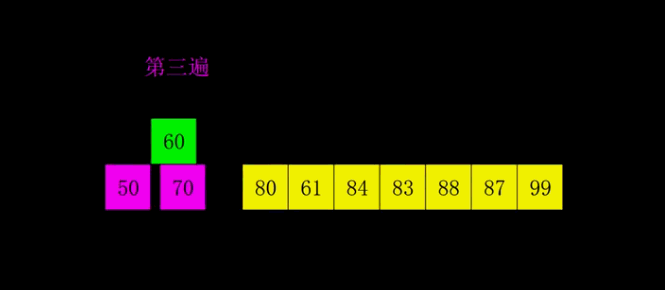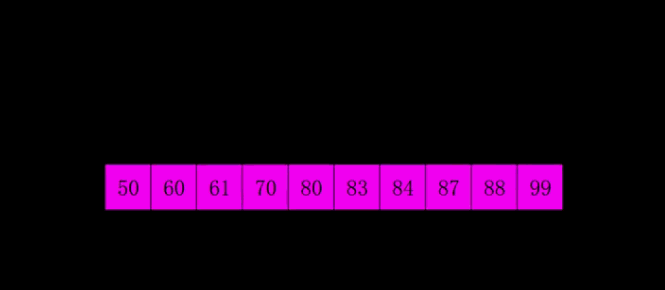
将原数组按照指定增量(gap) 分成多个子数组,对每个子数组分别进行插入排序,让数组整体快速变得基本有序;随后不断缩小增量,重复分组排序过程;当增量缩小为 1 时,数组已接近有序,最后执行一次直接插入排序即可完成整体排序,大幅降低了插入排序的时间消耗。
2.2希尔排序:
代码演示:
// 单组预排序示例(gap=3)
int gap = 3; // 分为3组
for(int j=0; j < n-gap; j++) {
for(int i=j; i < n-gap; i += gap) {
int end = i;
int temp = arr[end+gap];
while(end >= 0) {
if(temp < arr[end]) {
arr[end+gap] = arr[end];
end -= gap;
} else {
break;
}
}
arr[end+gap] = temp;
}
}
//多组并排序(完整希尔排序)
int gap = n;
while(gap > 1) {
gap = gap / 3; // 希尔常用增量序列(也可/2)
for(int i=0; i < n-gap; i++) {
int end = i;
int temp = arr[end+gap];
while(end >= 0) {
if(temp < arr[end]) {
arr[end+gap] = arr[end];
end -= gap;
} else {
break;
}
}
arr[end+gap] = temp;
}
}2.3希尔排序的特性总结:
gap越大:元素可以跨越多位置移动,大 / 小数快速归位,但数组越不接近有序。gap越小:元素移动步长变小,数组越接近有序。gap=1:等价于普通插入排序,完成最终有序。
选择排序
1选择排序
1.1基本思想:
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置或者最后位置,直到全部待排序的数据元素排完 。
1.2选择排序:
代码:
// 双向选择排序(同时找最小放前面、最大放后面)
void Selection(vector<int> &a)
{ // 修正拼写:Selction → Selection
int begin = 0;
int end = a.size() - 1;
while (begin <= end)
{
int max = begin;
int min = begin;
// 从 begin+1 到 end 找当前区间的最大/最小值
for (int i = begin + 1; i <= end; i++)
{
if (a[min] > a[i])
{
min = i; // 找到更小值,更新 min 下标
}
if (a[max] < a[i])
{
max = i; // 找到更大值,更新 max 下标
}
}
// 第一步:把最小值交换到当前区间的起始位置(begin)
Swap(&a[begin], &a[min]);
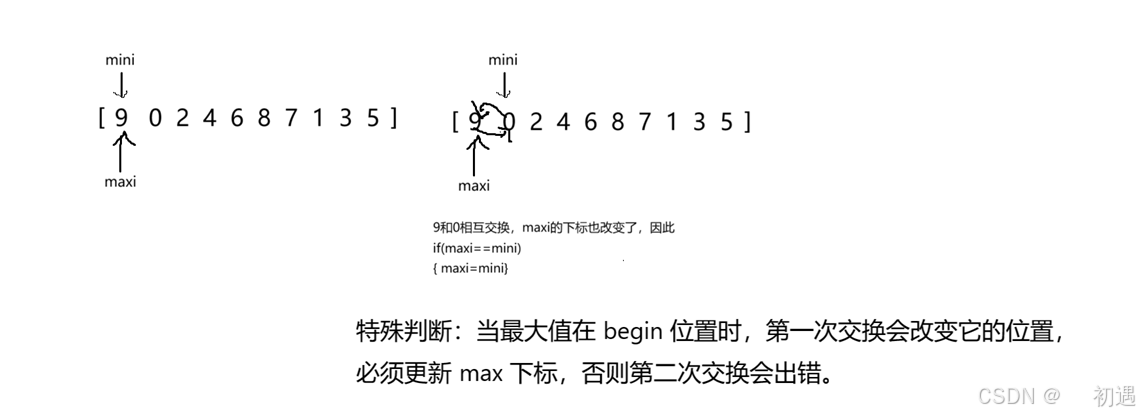
// 特殊情况处理:如果最大值原本在 begin 位置
// 刚才的交换会把最大值移到 min 位置,需要更新 max 下标
if (max == begin)
{
max = min;
}
// 第二步:把最大值交换到当前区间的末尾位置(end)
Swap(&a[end], &a[max]);
// 缩小待排序区间
begin++;
end--;
}
}交换排序
1快速排序
1.1基本思想:
任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右 子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
1.2快速排序:
代码:
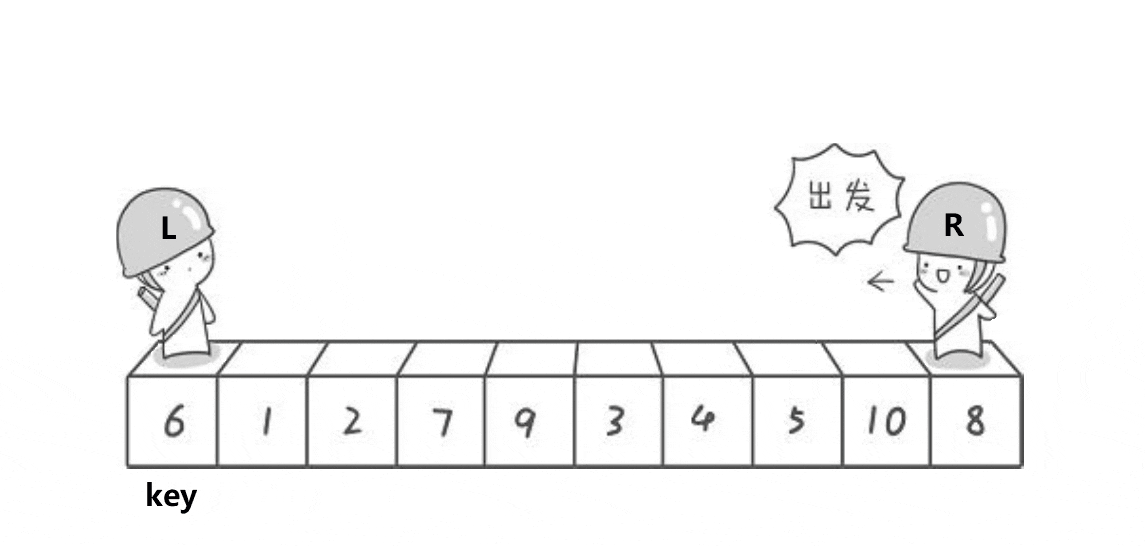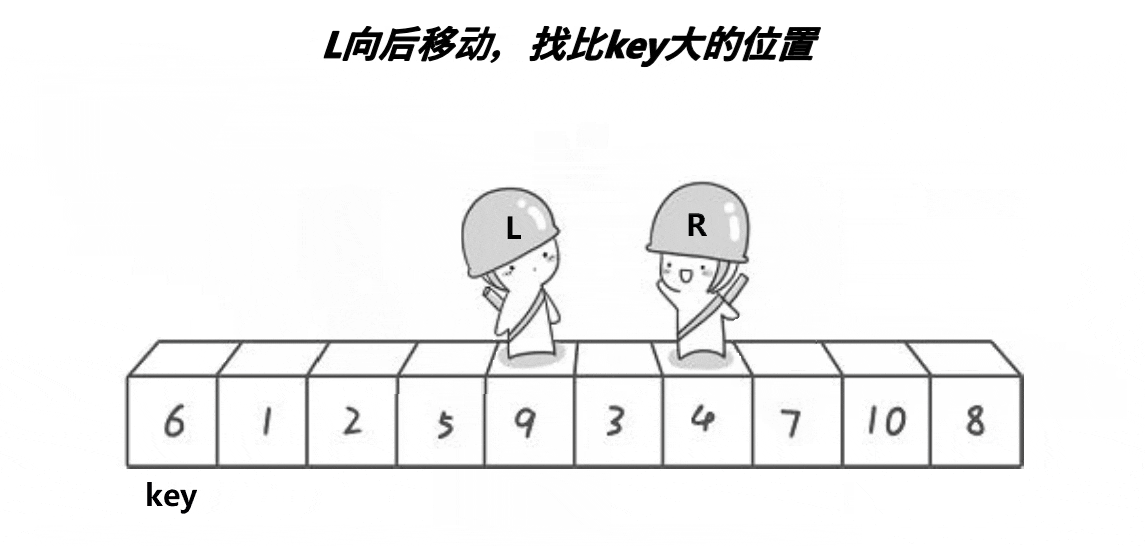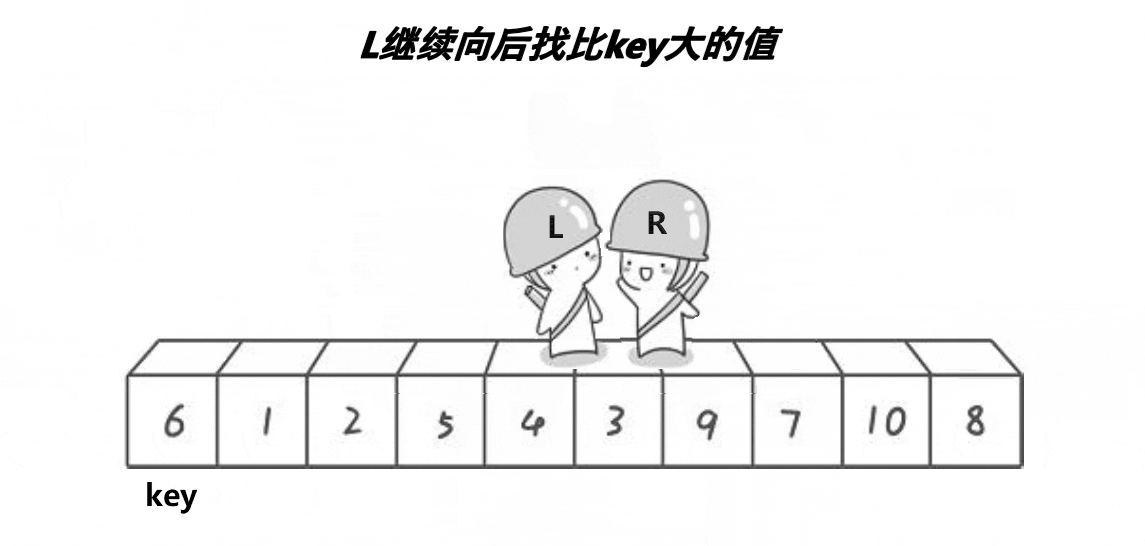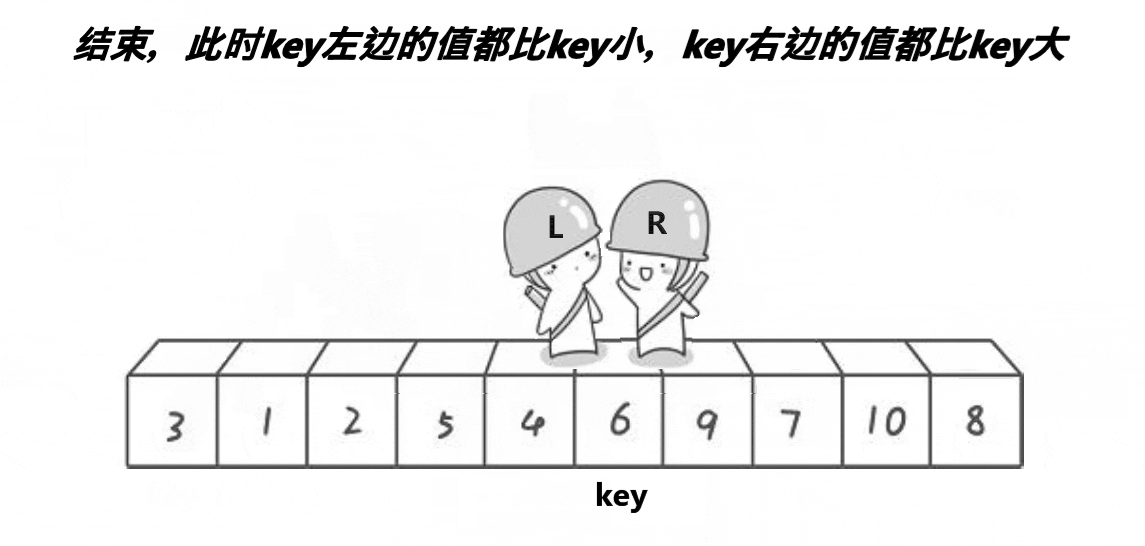
void Quicksort(int *a, int left, int right)
{
if (left >= right) {
return;
}
int keyi = left;
int begin = left;
int end = right;
while (begin < end)
{
while (begin < end && a[end] >= a[keyi]) {
end--;
}
while (begin < end && a[begin] <= a[keyi]) {
begin++;
}
swap(&a[begin], &a[end]);
}
// 相遇位置,把基准换到中间。结论:相遇位置一定小于keyi
swap(&a[begin], &a[keyi]);
keyi = begin; // 更新基准位置,给递归用
//[left,keyi-1]keyi[keyi+1,right]
// 递归左右子区间
Quicksort(a, left, keyi - 1);
Quicksort(a, keyi + 1, right);
}1.3快排优化
//三数取中
int GetMidi(int* a, int left, int right)
{
// 计算中间位置下标(防止溢出写法)
int mid = left + (right - left) / 2;
// 情况 1:a[left] < a[mid]
if (a[left] < a[mid])
{
// 左 < 中 < 右 → 中间值是 mid
if (a[mid] < a[right])
{
return mid;
}
// 左 < 右 < 中 → 中间值是 right
else if (a[left] < a[right])
{
return right;
}
// 右 < 左 < 中 → 中间值是 left
else
{
return left;
}
}
// 情况 2:a[mid] <= a[left]
else
{
// 右 < 中 <= 左 → 中间值是 mid
if (a[mid] > a[right])
{
return mid;
}
// 中 <= 右 < 左 → 中间值是 right
else if (a[left] > a[right])
{
return right;
}
// 中 <= 左 <= 右 → 中间值是 left
else
{
return left;
}
}
}
void Quicksort(int *a, int left, int right)
{
if (left >= right)
{
return;
}
// 小区间优化,不再递归分割排序,减少递归的次数
if ((right - left + 1) < 10)
{
InsertSort(a + left, right - left + 1);//插入排序
}
else
{
// 三数取中
int midi = GetMidi(a, left, right);
Swap(&a[left], &a[midi]);
int keyi = left;
int begin = left;
int end = right;
while (begin < end)
{
while (begin < end && a[end] >= a[keyi])
{
end--;
}
while (begin < end && a[begin] <= a[keyi])
{
begin++;
}
swap(&a[begin], &a[end]);
}
// 相遇位置,把基准换到中间。结论:相遇位置一定小于keyi
swap(&a[begin], &a[keyi]);
keyi = begin; // 更新基准位置,给递归用
//[left,keyi-1]keyi[keyi+1,right]
// 递归左右子区间
Quicksort(a, left, keyi - 1);
Quicksort(a, keyi + 1, right);
}
}1.4快速排序(非递归)
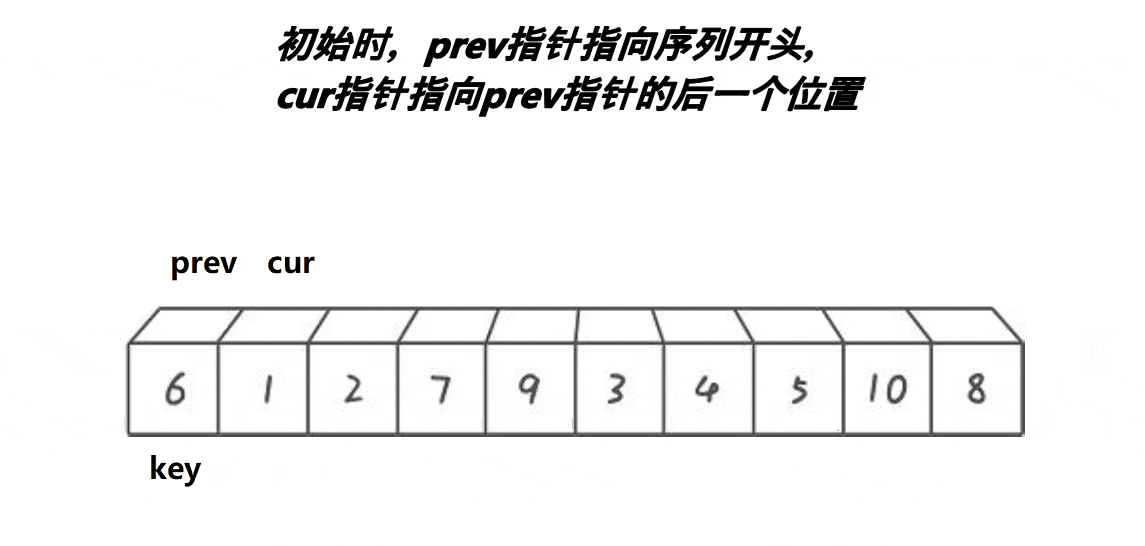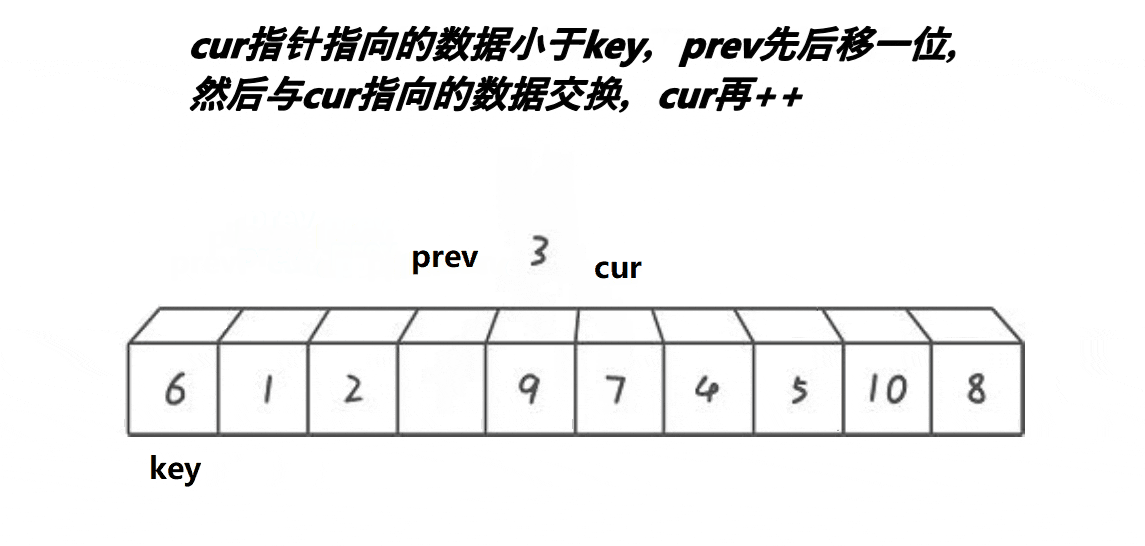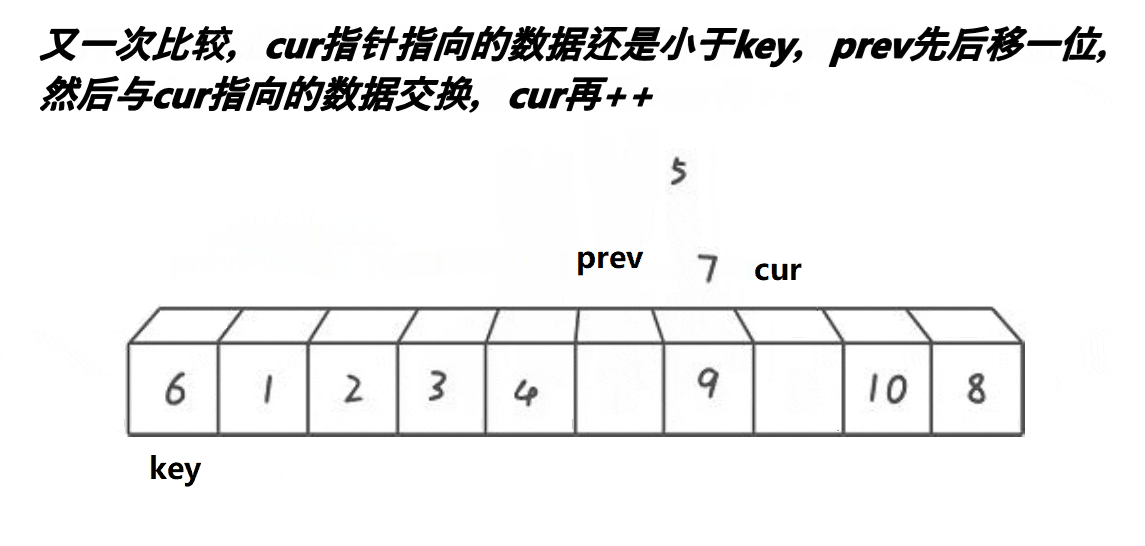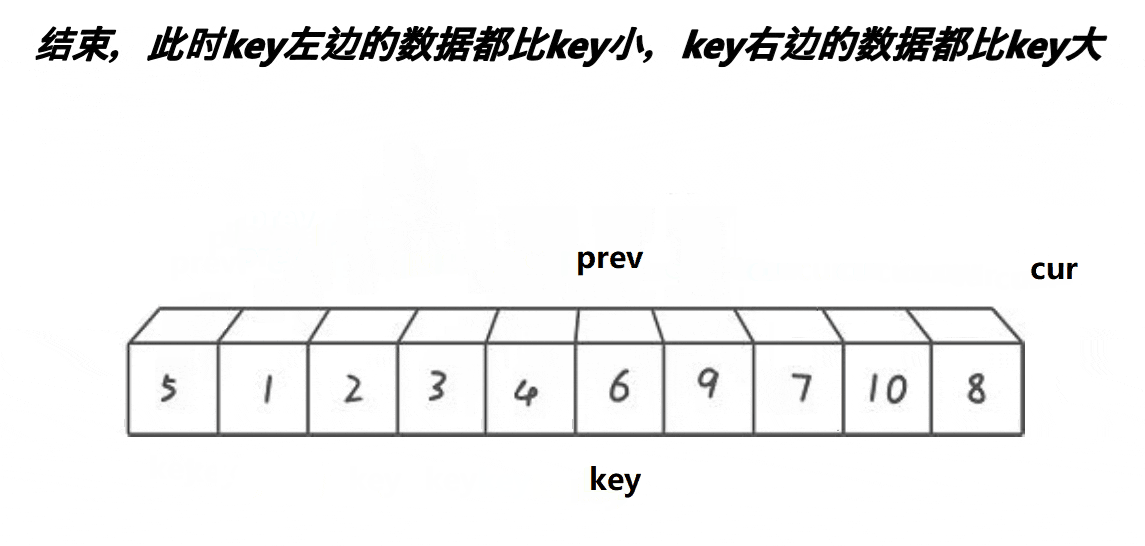
单趟逻辑
//快排单趟逻辑
int PartSort(int *a, int left, int right)
{
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[keyi])
{
prev++;
swap(&a[cur], &a[prev]);
}
cur++;
}
swap(&a[keyi], &a[prev]);
return prev;
}
// 栈的相关实现
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef struct Stack
{
int *arr;
int top;
int capacity;
} Stack, *pst;
// 初始化
void StackInit(pst p)
{
assert(p);
p->arr = NULL;
p->top = -1;
p->capacity = 0;
}
// 尾插
void StackPush(pst p, int val)
{
assert(p);
if (p->top + 1 == p->capacity)
{
int newCapacity = (p->capacity == 0) ? 4 : 2 * p->capacity;
int *newArr = realloc(p->arr, newCapacity * sizeof(int));
if (newArr == NULL)
{
perror("realloc fail");
exit(1);
}
p->arr = newArr;
p->capacity = newCapacity;
}
p->arr[++(p->top)] = val;
}
// 尾删
void StackPop(pst p)
{
assert(p->arr);
if (p->top + 1 > 0)
{
p->top--;
}
}
// 获取栈顶元素
int StackTop(pst p)
{
assert(p->arr);
return p->arr[p->top];
}
// 判空
bool StackEmpty(pst p)
{
// assert(p->arr);
assert(p);
return p->top == -1;
}
// 销毁
void StackDestory(pst p)
{
free(p->arr);
p->arr = NULL;
}
// 非递归快排
void P(int *a, int left, int right)
{
Stack st;
StackInit(&st);
// 先入栈,才有的排序
StackPush(&st, left);
StackPush(&st, right);
int keyi = 0;
while (!StackEmpty(&st))
{
right = StackTop(&st);
StackPop(&st);
left = StackTop(&st);
StackPop(&st);
// 单趟排序
keyi = PartSort(a, left, right);
if (left < keyi - 1)
{
// 入左边[left,keyi-1]
StackPush(&st, keyi - 1);
StackPush(&st, left);
}
if (keyi + 1 < right)
{
// 入右边[keyi+1,right]
StackPush(&st, right);
StackPush(&st, keyi + 1);
}
}2冒泡排序
1.1基本思想
通过相邻元素的比较与交换,将最大的元素一步步 "冒泡" 到数组的末尾。 每一趟排序都会确定一个最大元素的最终位置,下一趟就不需要再参与比较。如果某一趟没有发生任何交换,说明数组已经完全有序,可以直接提前结束排序。
2.2冒泡排序
// 冒泡排序
void Bubble Sort(int *a, int n)
{
for (int i = 0; i < n; i++)
{
int flag = 0;
// n-i 减去拍好个数 n-1防止j+1越界
for (int j = 0; j < n - 1 - i; j++)
{
if (a[j] > a[j + 1]) // 升序
{
swap(&a[j], &a[j + 1]);
flag = 1; // 发生交换
}
}
// 本趟没有交换 → 已经有序,直接退出
if (flag == 0)
{
break;
}
}
}归并排序
1.归并排序
1.1基本思想:
是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and
Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
1.2归并排序(递归):
代码:
void _Messagesoet(int*a,int *temp,int begin,int end)
{
//递归终止条件
if(begin>=end)
{
return ;
}
//分解
int mid=(begin+end)/2;
_Messagesoet(a,temp,begin,mid);//左边
_Messagesoet(a,temp,mid+1,end);//右边
//归并
int begin1=begin; int end1=mid-1;
int begin2=mid; int end2=end;
int i=begin;
while(begin1<=end1&&begin2<=end2)
{
if(a[begin1]<a[begin2])
{
temp[i++]=a[begin1];
}
else
{
temp[i++]=a[begin2];
}
}
//肯定会有剩余的
while(begin1<=end1)
{
temp[i++]=a[begin1];
}
while(begin2<=end2)
{
temp[i++]=a[begin2];
}
memcpy(a + begin, temp + begin, sizeof(int)*(end - begin + 1));
// memcpy(a,temp,sizeof(int)*(end-begin+1));
}
//归并递归
void Messagesoet(int*a,int n)
{
int *temp=(int *a)malloc(sizeof(int)*n);
if(temp==nullptr)
{
perror("amlloc fai");
}
_Messagesoet(a,temp,0,n-1);
free(temp);
}1.3递归过程(递归):
归并排序最详细过程(以 [10,6,7,1] 左半区为例)
一、整体思路
归并排序 = 分治思想
- 分解 :递归把数组不停二分 ,直到每个区间只有 1 个数字(天然有序)
- 归并 :把两个有序小区间 ,比大小合并成一个有序大区间
- 关键点 :
- 递归只拆分,不比较大小
- 真正排序 = 下面的 while 合并代码
二、以 [10, 6, 7, 1] 左半区完整执行过程
初始数组
[10, 6, 7, 1]``begin = 0, end = 3
阶段 1:递归分解(从上往下拆)
第 1 层分解
mid = (0+3)/2 = 1分成左区间 [0,1] → [10,6]分成右区间 [2,3] → [7,1]
第 2 层分解(处理左区间 0,1)
mid = (0+1)/2 = 0分成左区间 [0,0] → [10]分成右区间 [1,1] → [6]
递归终止
begin == end,区间只有 1 个数字,无法再分。
阶段 2:归并合并(从下往上合,真正排序)
第 1 次合并:[10] 和 [6]
这一步完全靠你写的 while 代码执行:
// 两个有序区间
left: [10]
right: [6]
// 比较 10 和 6
10 > 6 → 先放 6
剩下 10 → 放 10
合并结果:[6, 10]合并完成,回溯返回上一层
第 2 次合并:右边 [7] 和 [1]
left: [7]
right: [1]
1 < 7 → 先放 1
剩下 7 → 放 7
合并结果:[1, 7]第 3 次合并:[6,10] 和 [1,7]
两个都是有序数组,进入 while 逐个数比较:
[6,10] 和 [1,7]
1 < 6 → 放 1
6 < 7 → 放 6
7 < 10 → 放 7
最后放 10
最终合并:[1,6,7,10]结论:
1. 递归 = 只负责拆分,不比较、不排序
2. while 合并代码 = 真正比大小、排序的核心
3. 单个数字天然有序,合并时才会排序
1.4.归并排序(非递归)
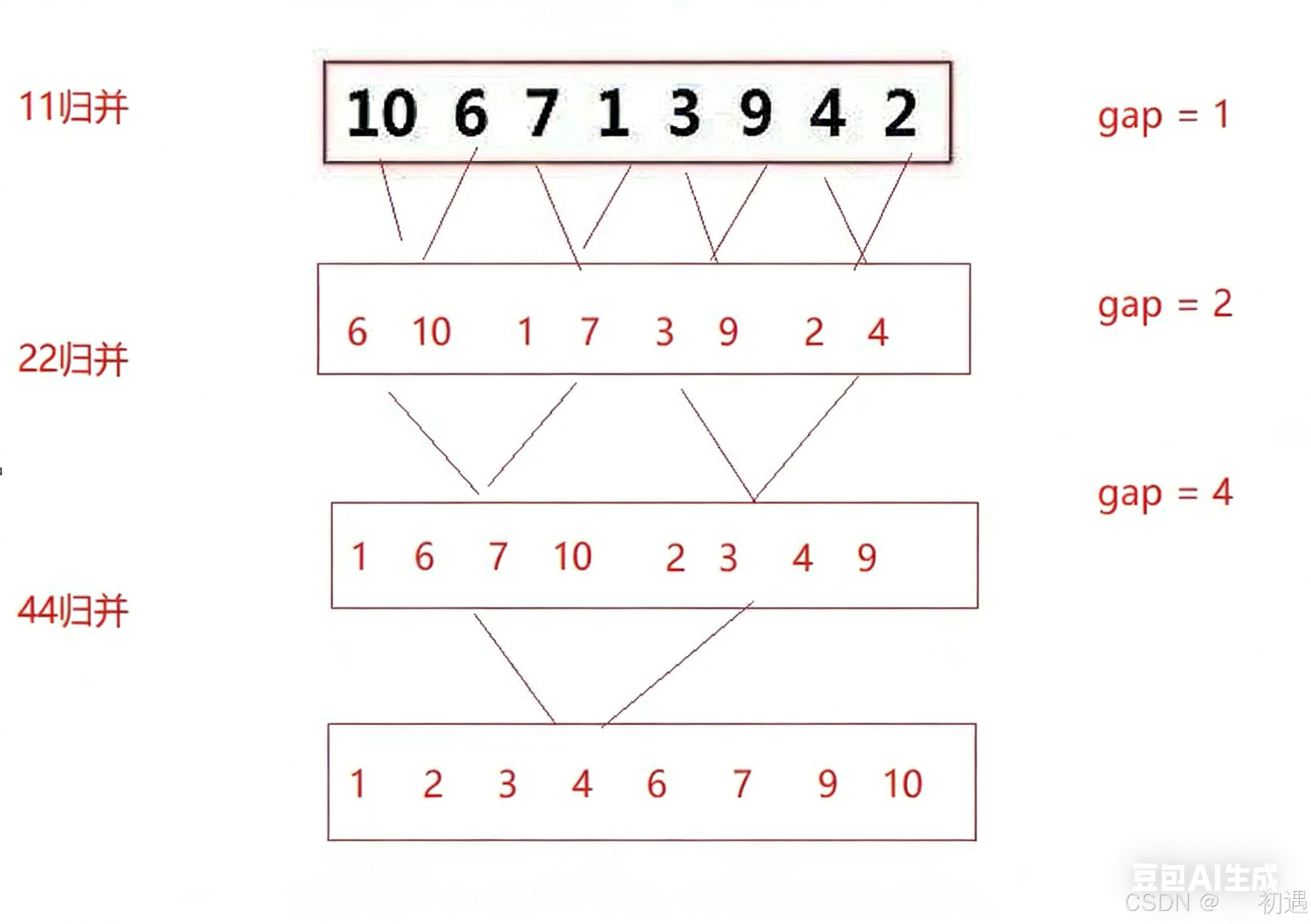
代码:
// 归并非递归
void MergeSortNonR(int *a, int n)
{
// 开整个数组大小的临时空间,不能只开4个!
int *temp = (int *)malloc(sizeof(int) * n);
if (temp == nullptr)
{
perror("fail malloc");
return;
}
// gap 是每组的大小,从1开始,每次×2
int gap = 1;
while (gap < n)
{
// 每次处理两组:[gap][gap],所以 i += 2*gap
for (int i = 0; i < n; i += 2 * gap)
{
// 确定两个要归并的区间
int begin1 = i; int end1 = i + gap - 1;
int begin2 = i + gap; int end2 = i + 2 * gap - 1;
// 边界修正!!!防止越界
if (end1 >= n) end1 = n - 1;
if (begin2 >= n) begin2 = n; // 第二组不存在
if (end2 >= n) end2 = n - 1;
// 归并到 temp 数组
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
temp[j++] = a[begin1++];
}
else
{
temp[j++] = a[begin2++];
}
}
// 处理剩余元素
while (begin1 <= end1)
{
temp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
temp[j++] = a[begin2++];
}
}
// 每处理完一轮 gap,把 temp 拷贝回 a
memcpy(a, temp, sizeof(int)*n);
gap *= 2;
}
free(temp);
temp = nullptr;
}计数排序
1.基本思想:
计数排序是一种非比较类排序 ,它不通过比较大小来排序,而是使用数组下标作为哈希映射,统计每个数字出现的次数,最后根据次数直接回写有序数组。
2.直接插入排序:
// 计数排序
void countsort(int *a, int n)
{
// 1. 找数组中的最大值和最小值
int max = a[0];
int min = a[0];
for (int i = 0; i < n; i++)
{
if (max < a[i])
{
max = a[i];
}
if (min > a[i])
{
min = a[i];
}
}
// 2. 计算数据范围,开辟计数数组
int range = max - min + 1;
int *count = (int *)calloc(range, sizeof(int));
if (count == NULL)
{
perror("calloc fail");
return;
}
// 3. 统计每个数字出现的次数(哈希映射思想)
for (int i = 0; i < n; i++)
{
count[a[i] - min]++;
}
// 4. 回写到原数组(排序完成)
int j = 0;
for (int i = 0; i < range; i++)
{
while (count[i]--)
{
a[j++] = i + min;
}
}
// 5. 释放动态开辟的内存
free(count);
count = NULL;
}