第六章我们深入拆解 Spark 的执行计划与 DAG 调度机制,这是理解 Spark 为什么这样跑最核心的一章。
- 先看第一张,一条 SQL 从代码到物理执行的完整转换过程。执行计划的四个阶段搞清楚了;
- 接下来看 DAG 调度的核心------Job、Stage、Task 的层级关系和划分原理:层级结构搞清楚了;
- 接下来看最难理解的部分------Shuffle 的完整读写机制,以及为什么它是性能瓶颈:Shuffle 机制搞透了;
- 最后一张,看 AQE(自适应查询执行)的三大能力,这是 Spark 3.0 后最重要的运行时优化特性。
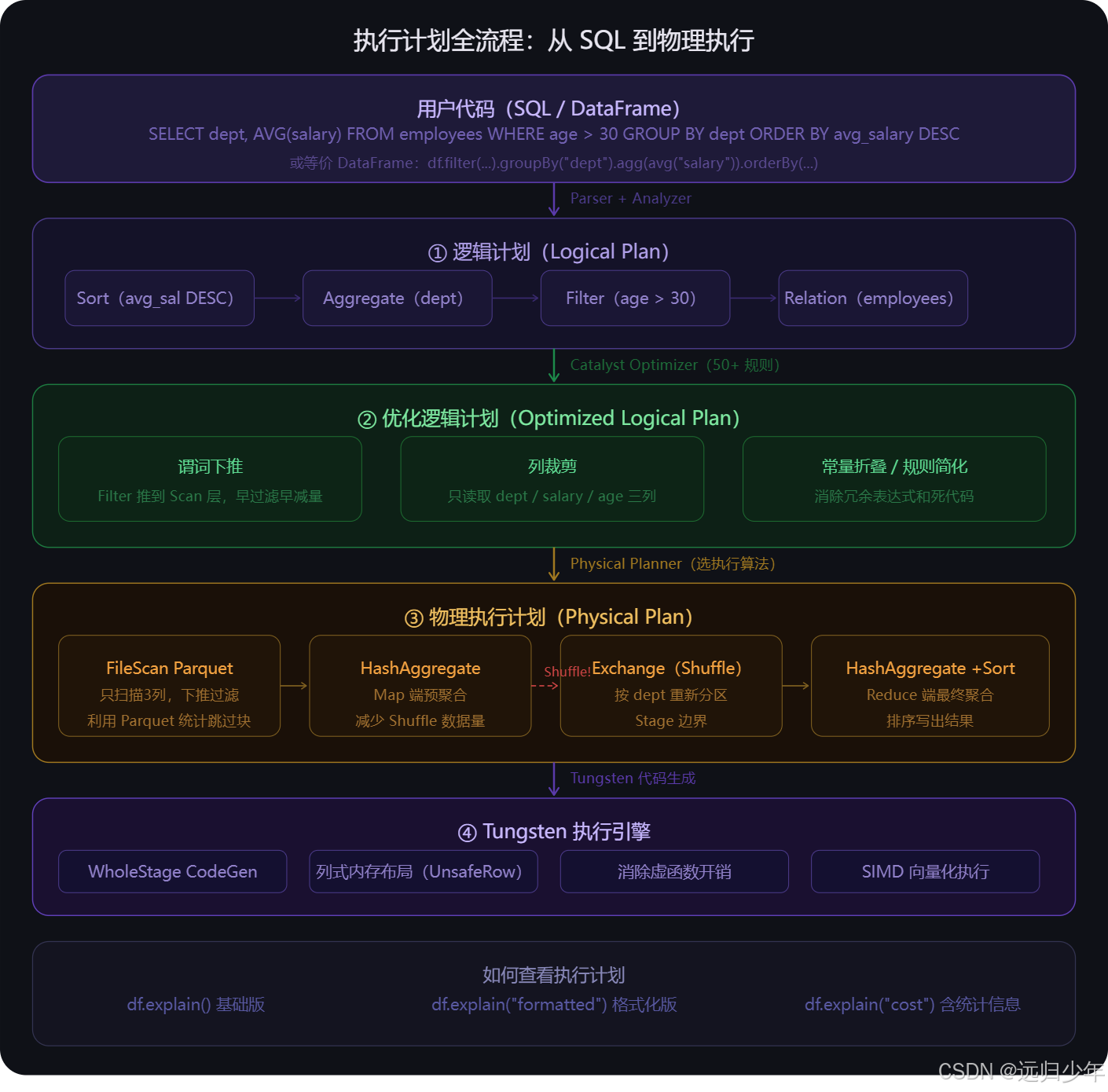
执行计划四阶段(第一张) 是理解 Spark SQL 工作原理的主线。一条 SQL 经历四次变换才真正被执行:
- 逻辑计划只是树形结构的操作描述,没有任何执行细节;
- Catalyst Optimizer 用 50 多条规则对逻辑计划做谓词下推、列裁剪、常量折叠等变换,让数据尽早缩减;
- Physical Planner 在优化后的逻辑计划基础上选择具体算法,比如用哪种聚合方式、用哪种 Join;
- 最后 Tungsten 把物理计划编译成 JVM 字节码,用 WholeStage CodeGen 把多个算子的循环合并成一个,消除虚函数调用开销,配合 SIMD 向量化真正高速执行。
查看执行计划用 df.explain("formatted"),生产排障必备。
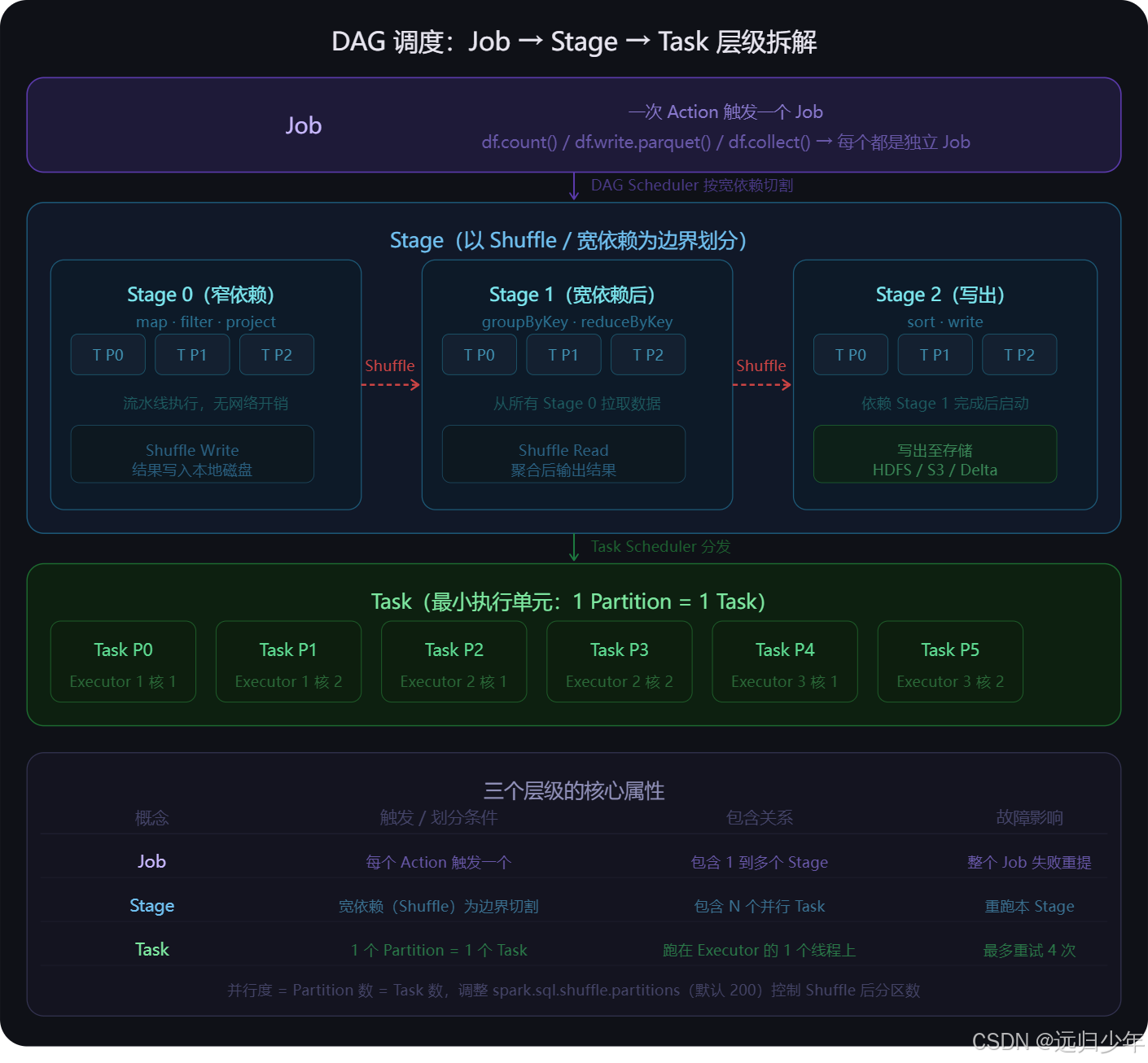
Job → Stage → Task(第二张) 是 DAG 调度的三层结构。
- 一次
count()或write()就是一个 Job; - Job 按宽依赖(Shuffle 边界)被 DAG Scheduler 切成多个 Stage,Stage 内部所有算子流水线执行无网络开销;
- 每个 Stage 被 Task Scheduler 拆成若干 Task 发给 Executor,一个 Partition 对应一个 Task,跑在一个线程上。
- 并行度由 Partition 数决定,
spark.sql.shuffle.partitions控制 Shuffle 后的分区数(默认 200,按数据量调整)。
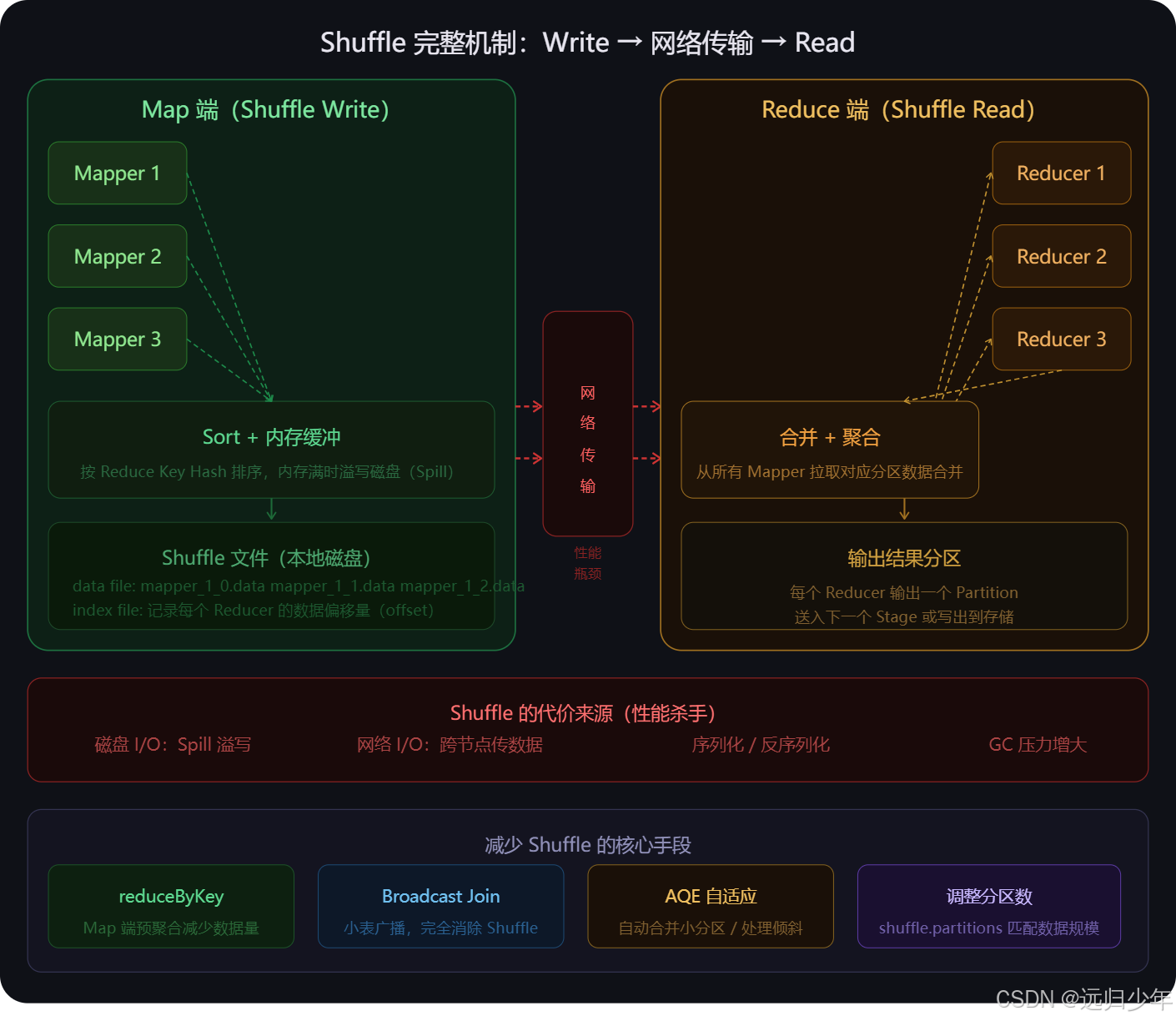
Shuffle 机制(第三张) 是 Spark 最贵操作的完整剖析。
- Map 端把每条数据按目标 Reducer 的 Hash 值排序写入本地磁盘,同时生成 index 文件记录偏移;
- Reduce 端通过网络从所有 Mapper 的磁盘拉取属于自己 Key 的数据块,合并后聚合输出。
- 代价来源有四个:Spill 溢写磁盘、跨节点网络传输、序列化反序列化、GC 压力。
- 减少 Shuffle 的核心手段:
- 能
reduceByKey就不用groupByKey(Map 端预聚合); - 能 broadcast 就广播(彻底消除 Shuffle);
- 开启 AQE 自动合并小分区;
- 调整
shuffle.partitions匹配数据规模。
- 能
AQE 三大能力(第四张) 是 Spark 3.0 后最重要的运行时优化。
传统 Catalyst 只能在编译期用统计估算优化,AQE 则在每个 Stage 完成后收集真实数据量重新优化后续计划,相当于"边跑边调"。
三个核心能力:
- 自动合并小分区把 200 个 1MB 小 Task 合并成几个 64MB 的大 Task,大幅减少调度开销;
- 数据倾斜处理把超大分区拆成多个子分区并行处理,彻底解决"一个 Task 拖累全局"的问题;
- 动态切换 Join 策略在运行期发现某张表实际只有 6MB 时自动切为 Broadcast Join,消除原本计划中的 Shuffle。
这三项都默认开启,但倾斜阈值和分区目标大小值得根据业务数据分布手动调整。
