1、介绍
Kubernetes是一个基于Docker容器的开源编制系统,它能在跨多个主机上管理Docker应用,并提供应用程序部署 维护和扩展的基本机制。
它透明地为用户提供原生态系统,如"需要5个 WildFly服务器和1个 MySQL服务器运行". Kubernetes具有自我修复机制,如重新启动 重新启动定时计划 复制容器以确保恢复状态,用户只需要定义状态,那么 Kubernetes就会确保状态总是在集群中。
Docker定义了运行代码时的容器,有命令用来启动 停止 重启 链接容器,Kubernetes使用Docker打包以及实例化应用程序。
一个典型的应用程序必须跨多个主机。 例如,您的web层(Apache)可能运行在一个容器。 同样地,应用程序层将会运行在另外一组不同的容器中。 web层需要将请求委托给应用程序层。 当然,在某些情况下,你可能将web服务器和应用服务器打包在一起放在相同的容器。 但是数据库层通常运行在一个单独层中。 这些容器之间需要相互交互。 使用上面的任何解决方案都需要编制脚本启动容器,以及监控容器,因防止出现问题。 而Kubernetes在应用程序状态被定义后将为用户实现所有这些工作。
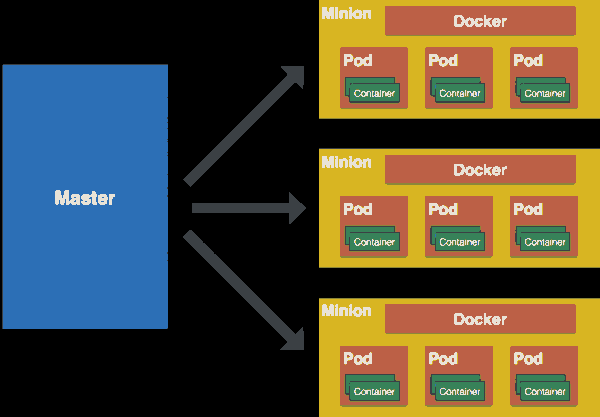
2、主要组件
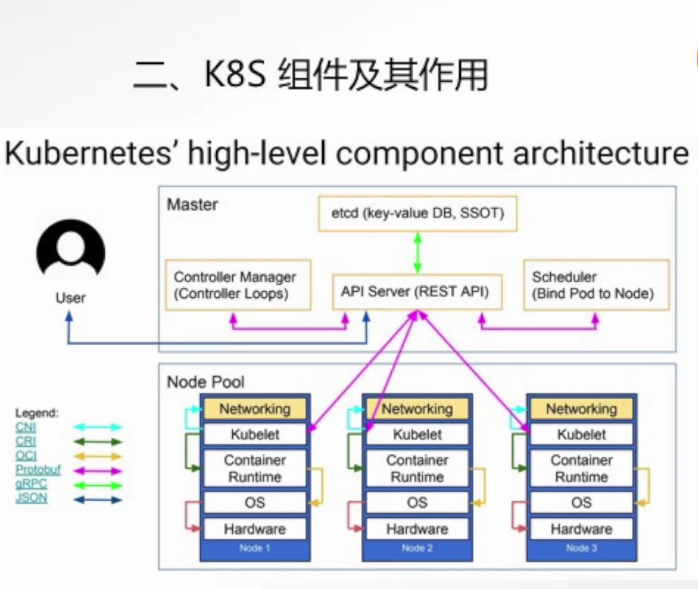
核心结构概览:两级架构,一个大脑
在深入细节之前,请记住这张蓝图:Kubernetes 集群由两大部分构成。
-
控制平面 (Control Plane) :集群的大脑 和指挥中心。它做出全局性决策(例如,将一个新应用调度到哪个节点上),并检测和响应集群事件(例如,当一个节点宕机时,启动一个新的 Pod 来替补)。控制平面组件可以运行在集群中的任何节点上,但为了高可用,通常将它们部署在专用的、与普通工作负载隔离的服务器上。
-
节点 (Node) :集群的肢体 和劳动力。它们是负责运行实际工作负载(即容器化应用)的机器,可以是物理服务器或虚拟机。每个节点都由控制平面管理,并包含运行 Pod 所需的服务。
一、 控制平面组件 (Control Plane Components) ------ 大脑的精密结构
1. kube-apiserver (API 服务器)
-
角色:整个集群的"网关"和"安全卫兵"
-
深度解析:
-
唯一入口 :无论是用户通过
kubectl发出的指令,还是其他组件(如调度器、控制器)的内部沟通,甚至是集群内外的数据查询,所有对集群进行管理和控制的请求都必须经过 kube-apiserver。它暴露了 Kubernetes API,是集群的"前端"。 -
无状态设计:kube-apiserver 本身并不存储任何数据。当它接收到创建 Pod 的请求后,会将该 Pod 的状态数据持久化到后端的 etcd 中。这种设计使其可以轻松地进行水平扩展------你只需要在负载均衡器后面部署多个 apiserver 实例,即可应对更大的请求流量。
-
核心处理流程:
-
认证:接收到请求后,首先检查请求者是谁(客户端证书、token、用户名/密码等)。
-
授权:确认请求者有权限执行所请求的操作(通过 RBAC 等授权模块)。
-
准入控制 :在对象被持久化之前,通过一系列"准入控制器"对请求进行拦截和修改。例如,
AlwaysPullImages控制器会强制每次拉取最新镜像;ResourceQuota控制器会检查此次创建是否会超出命名空间的资源配额。 -
验证与持久化:验证对象的合法性(如必填字段是否缺失),然后将合法的对象序列化后保存到 etcd 中。
-
-
2. etcd
-
角色:集群的"金库"和"记忆存储器"
-
深度解析:
-
分布式、强一致性:etcd 是一个键值存储数据库,但它不是普通的数据库。它使用 Raft 共识算法来确保数据在多个副本之间的一致性。这意味着只要大多数节点(例如,3 个节点中的 2 个)存活,etcd 就能正常工作并保证数据准确无误。
-
唯一可信源 :etcd 存储了集群的所有状态信息 。包括节点信息、所有 API 对象(Pod、Service、ConfigMap 等)的规格(Spec)和状态(Status)、以及集群的各种配置。没有 etcd,Kubernetes 集群就会"失忆",无法恢复任何信息。
-
Watch 机制:etcd 提供了强大的 Watch 功能。客户端(如 kube-apiserver)可以"监听"特定的键或目录。一旦这些键的值发生变化,etcd 会立即通知客户端。这正是 Kubernetes 中所有控制器能够实时响应集群状态变化的底层机制。
-
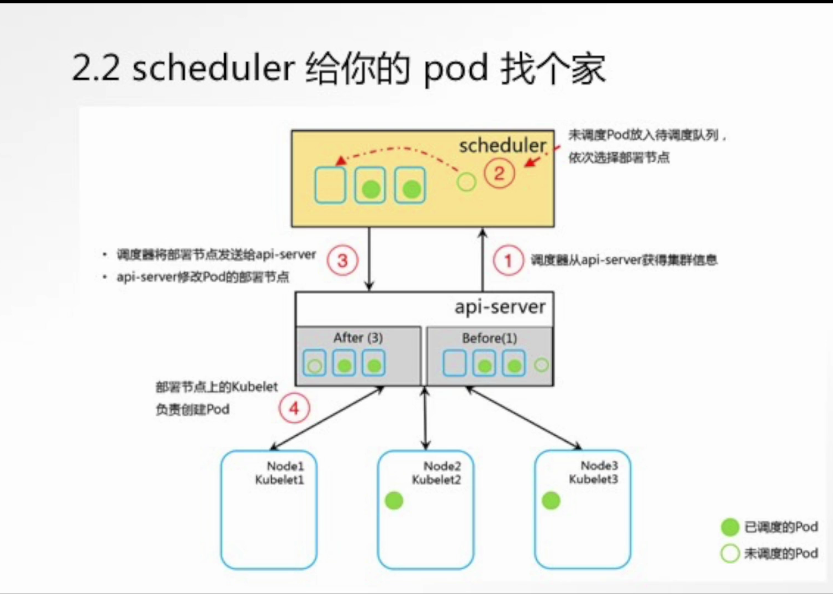
3. kube-scheduler (调度器)
-
角色:新 Pod 的"专属房产中介"
-
深度解析:
-
监视与决策 :kube-scheduler 通过 API Server 的 Watch 机制持续监听新创建的、还未分配到节点(
nodeName字段为空)的 Pod。 -
两阶段调度算法:当发现一个新 Pod 时,它会为这个 Pod 选择一个最合适的节点。这个过程分为两步:
-
预选 (Predicates):过滤掉那些不满足 Pod 运行条件的节点。例如:
-
资源充足:节点剩余 CPU 和内存是否满足 Pod 的请求?
-
端口冲突:Pod 请求的端口(如 hostPort)在节点上是否已被占用?
-
污点容忍:节点是否打了"污点"(Taint),而 Pod 是否容忍(Tolerations)这个污点?
-
节点选择器 :Pod 是否指定了
nodeSelector,要求节点必须包含特定标签?
-
-
优选 (Priorities):对通过预选的节点进行打分,选出最合适的一个。评分因素包括:
-
资源富余度:尽可能将 Pod 调度到资源(CPU/内存)使用率较低的节点上,以平衡负载。
-
亲和性/反亲和性:如果 Pod 希望与某些 Pod 靠在一起(亲和)以提高性能,或者希望互相远离(反亲)以提高容灾能力,调度器会根据这些规则打分。
-
-
-
绑定:选定节点后,scheduler 会通过 API Server 创建一个 Binding 对象,将该 Pod 绑定到选定的节点上。然后该节点上的 kubelet 才会接管并创建 Pod。
-
4. kube-controller-manager (控制器管理器)
-
角色:一群不知疲倦的"自动化纠察员"的队长
-
深度解析:
-
控制器的集合 :kube-controller-manager 并不是一个单一的程序,它是一个将多个控制器逻辑编译成同一个二进制文件,并在同一个进程中运行的"管理器"。所有这些控制器都遵循同一个核心模式------控制循环 (Control Loop)。
-
控制循环模式:
-
观察 :通过 API Server 持续获取某种资源(如 Deployment)的期望状态 (
spec)和实际状态 (status)。 -
分析差异:比较期望状态和实际状态,找出差异。例如,Deployment 期望 3 个副本,但实际状态显示只有 2 个 Pod 在运行。
-
采取行动:执行操作使实际状态趋向期望状态。例如,命令调度器再创建一个新的 Pod。
-
-
主要控制器举例:
-
Node Controller :定期检查每个节点的健康状态。如果一个节点超过一定时间没有上报心跳,它会将该节点上的 Pod 标记为
Terminating或Unknown,并在其他健康节点上重新创建这些 Pod(如果这些 Pod 由 ReplicaSet 管理)。 -
Deployment Controller :管理 Deployment 对象的生命周期。当你更新 Deployment 的镜像版本时,它会创建一个新的 ReplicaSet,然后按照滚动更新策略(如
maxSurge和maxUnavailable)逐步将旧 ReplicaSet 缩容,新 ReplicaSet 扩容。 -
ReplicaSet Controller:确保由它管理的指定数量的 Pod 副本在任何时候都处于运行状态。
-
ServiceAccount & Token Controllers:负责为新的命名空间创建默认的 ServiceAccount,并为 ServiceAccount 自动创建 API 访问所需的 Token(Secret)。
-
-
二、 节点组件 (Node Components) ------ 执行命令的肌肉
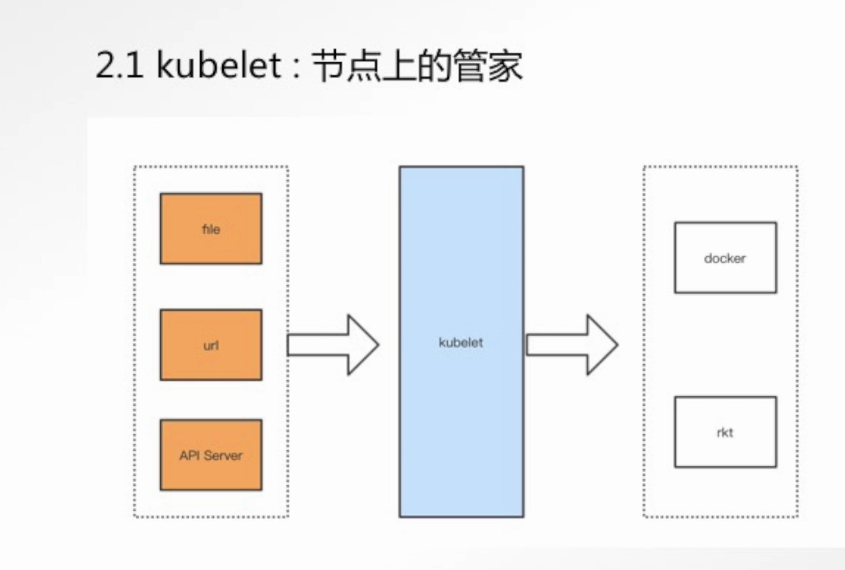
1. kubelet
-
角色:节点上的"大管家",直接听命于控制平面
-
深度解析:
-
核心代理:运行在每个节点上的主要代理程序。它负责向控制平面注册节点。
-
Pod 生命周期管理:kubelet 通过 API Server 的 Watch 机制,持续监听哪些 Pod 被分配到了自己所在的节点。当发现一个新分配的 Pod,它会:
-
拉取 Pod 所需的容器镜像。
-
根据 Pod 的描述(PodSpec),调用容器运行时(如 containerd)来启动或停止容器。
-
同时,挂载 Pod 声明的 Volume。
-
-
健康检查 :kubelet 负责执行 Pod 中定义的探针 (Probe):
-
存活探针 (Liveness Probe):定期检查容器是否仍在运行。如果失败,kubelet 会杀掉容器并根据重启策略重启。
-
就绪探针 (Readiness Probe):定期检查容器是否已准备好对外提供服务。如果失败,该 Pod 的 IP 地址会从关联的 Service 的端点(Endpoint)中移除,确保不会有流量发送给未就绪的 Pod。
-
-
状态上报:kubelet 持续监控节点和其上 Pod 的资源使用情况,并定期将节点的状态、Pod 的状态以及事件上报给 API Server。
-
2. kube-proxy
-
角色:节点上的"轻量级负载均衡器"和"网络规则维护者"
-
深度解析:
-
Service 的实现者:它负责在节点上实现 Service 的抽象概念。主要工作是维护节点的网络规则,使得从集群内部或外部的网络请求能够正确地被转发到后端的 Pod 上。
-
工作模式:kube-proxy 有多种实现模式:
-
userspace 模式(旧,已弃用):最早的实现。请求通过 kube-proxy 代理,性能较差。
-
iptables 模式(默认常用):目前最常用的模式。kube-proxy 会监听 API Server 中 Service 和 Endpoint 的变化,并动态地在节点的 Netfilter 框架中创建大量的 iptables 规则。发往 Service IP 的流量会直接被这些规则 DNAT(修改目的地址)到某一个后端的 Pod IP 上。此模式性能高,但规则过多时更新会有延迟。
-
IPVS 模式:专为大型集群设计,利用 Linux 内核的 IPVS 模块。它同样使用 Netfilter 的钩子,但使用哈希表作为底层数据结构,当规则成千上万时,其性能和数据同步速度远优于 iptables 的线性规则链。
-
kernelspace 模式:Windows 节点上使用。
-
-
3. 容器运行时 (Container Runtime)
-
角色:真正的"容器执行者"
-
深度解析:
-
遵循 CRI 标准 :Kubernetes 并不直接与 Docker 或 containerd 交互,而是通过一个名为 CRI (Container Runtime Interface) 的抽象接口。这使得 Kubernetes 可以无缝地接入任何实现了 CRI 的容器运行时。
-
常见运行时:
-
containerd:一个工业级的容器运行时,强调简单性、健壮性和可移植性。它是 Docker 公司贡献给 CNCF 的核心运行时,也是目前最主流的选择。
-
CRI-O:专门为 Kubernetes 实现的 CRI 运行时,旨在成为 Kubernetes 的轻量级运行时。
-
Docker Engine (已弃用) :在 v1.24 版本之前,kubelet 中有一个名为
dockershim的组件,负责将 CRI 请求转换为 Docker Engine 能理解的请求。从 v1.24 开始,这个中间层被彻底移除,Kubernetes 不再支持 Docker 作为直接运行时,但 Docker 镜像仍然可以被任何 CRI 兼容的运行时运行。
-
-
核心功能:拉取容器镜像、创建和停止容器、管理容器内的文件系统。
-
三、 补充组件:管理员的工具箱
除了上述核心组件,还有一些组件虽然不是运行集群所必需的,但对于集群的运维、管理和对外提供服务至关重要。
-
kubectl :管理员的"指挥棒"。它是一个命令行工具,通过 HTTPS 协议与 kube-apiserver 通信,将用户的命令(如
kubectl get pods)转化为对 API Server 的 RESTful API 调用。 -
Ingress Controller (如 Nginx Ingress Controller) :它不是核心组件,但它是实现 Ingress 资源所必需的。Ingress Controller 本身是一个负载均衡器程序(通常以 Pod 形式运行),它会监听 API Server 中的 Ingress 和 Service 资源的变化,并动态地配置自身的路由规则(如 Nginx 配置文件),从而实现外部 HTTP/HTTPS 流量到集群内 Service 的智能路由。
-
DNS 服务 (如 CoreDNS) :集群内部的核心 DNS 服务器。它也是一个 Deployment,运行着 Pod。它会监视 API Server 中的 Service 和 Pod 变化,并为它们创建 DNS 记录。这使得 Pod 之间可以通过稳定的域名(如
my-svc.my-namespace.svc.cluster.local)而非易变的 IP 地址进行通信。