引言
MNIST(Mixed National Institute of Standards and Technology)手写数字数据集是深度学习领域的经典入门数据集,包含0~9共10个类别的手写数字灰度图片,每张图片大小为28×28像素。本文将从零开始,使用PyTorch搭建一个简单的全连接神经网络(又称多层感知机,MLP),完成MNIST分类任务。文章将详细介绍数据加载、模型定义、训练与测试的完整流程,并附上代码和运行结果,适合深度学习初学者参考。
1. 环境配置与依赖
-
Python 3.8+
-
PyTorch 1.10+
-
torchvision
-
matplotlib
2. 导入必要的库
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt3. 加载MNIST数据集
torchvision.datasets.MNIST 提供了便捷的数据下载接口。通过 transform=ToTensor() 将原始PIL图像转换为PyTorch张量,并将像素值从 0,255 归一化到 0,1 区间,同时将形状从 (H, W) 调整为 (C, H, W),其中 C=1(灰度图)。
# 训练集:60000张图片
training_data = datasets.MNIST(
root='data', # 数据保存目录
train=True, # 加载训练集
download=True, # 若本地无数据则自动下载
transform=ToTensor() # 转换为张量
)
# 测试集:10000张图片
test_data = datasets.MNIST(
root='data',
train=False,
download=True,
transform=ToTensor()
)4. 可视化部分样本
为了直观了解数据,我们从训练集中取最后9张图片(索引59000~59008)进行展示。注意:img 的形状是 (1, 28, 28),需要调用 squeeze() 去掉维度1,才能用 matplotlib 正常显示灰度图。
figure = plt.figure(figsize=(8, 8))
for i in range(9):
img, label = training_data[i + 59000] # 取后9张
figure.add_subplot(3, 3, i + 1) # 3×3子图
plt.title(label) # 标题显示真实标签
plt.axis('off') # 关闭坐标轴
plt.imshow(img.squeeze(), cmap='gray') # 显示灰度图像
plt.show()运行后得到下图,可以看到手写数字的样式和对应的标签:

图1:MNIST训练集中部分样本及标签(从后往前取)
5. 创建DataLoader
DataLoader 负责将数据集分批、打乱(可选)、并行加载。这里设置 batch_size=32,即每个批次包含32张图片及其标签。
train_dataloader = DataLoader(training_data, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=32)
# 查看一个batch的形状
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}") # [32, 1, 28, 28]
print(f"Shape of y: {y.shape} {y.dtype}") # [32] torch.int64
break输出示例:
Shape of X [N, C, H, W]: torch.Size([32, 1, 28, 28])
Shape of y: torch.Size([32]) torch.int646. 定义神经网络模型
我们构建一个简单的全连接网络,包含两个隐藏层。网络结构如图所示:
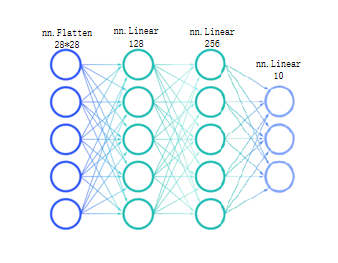
图2:全连接神经网络结构示意图
-
输入层 :28×28 = 784个像素,通过
nn.Flatten()展平为一维向量。 -
隐藏层1:全连接层,输入784,输出128,后接ReLU激活函数。
-
隐藏层2:全连接层,输入128,输出256,后接ReLU激活函数。
-
输出层:全连接层,输入256,输出10,对应10个数字类别(未使用softmax,因为损失函数内部包含)。
class NeuralNetwork(nn.Module):
def init(self):
super().init()
self.flatten = nn.Flatten() # 展平层:2828 -> 784
self.hidden1 = nn.Linear(2828, 128) # 输入784 -> 128
self.hidden2 = nn.Linear(128, 256) # 128 -> 256
self.out = nn.Linear(256, 10) # 256 -> 10def forward(self, x): x = self.flatten(x) x = self.hidden1(x) x = torch.relu(x) # ReLU激活 x = self.hidden2(x) x = torch.relu(x) x = self.out(x) return x
为什么需要 Flatten?
全连接层(nn.Linear)要求输入是二维的 [batch_size, features],而原始图像数据是三维的 [batch_size, 1, 28, 28],因此必须将每个样本的像素按顺序排成一列。
6.1 选择设备
自动检测GPU(CUDA)或Apple MPS(若使用Mac),否则使用CPU。
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using device: {device}")
model = NeuralNetwork().to(device)
print(model)输出示例:
Using device: cuda
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(hidden1): Linear(in_features=784, out_features=128, bias=True)
(hidden2): Linear(in_features=128, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
)7. 定义损失函数与优化器
-
损失函数 :多分类问题使用交叉熵损失
CrossEntropyLoss,它内部包含了softmax操作,因此模型输出层不需要额外添加激活函数。 -
优化器:选择Adam优化器,学习率设为0.01。Adam结合了动量与自适应学习率的优点,通常比SGD收敛更快。
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
8. 训练函数
train 函数完成一个epoch(遍历一次所有训练数据)的参数更新。流程包括:
-
设置模型为训练模式(
model.train()),对Dropout、BatchNorm等层生效。 -
遍历DataLoader,获取批次数据并送入设备。
-
前向传播计算预测值和损失。
-
反向传播:梯度清零、计算梯度、更新参数。
-
每100个batch打印一次损失值。
def train(dataloader, model, loss_fn, optimizer):
model.train() # 设置为训练模式
batch_num = 1
for X, y in dataloader:
X, y = X.to(device), y.to(device)# 前向传播 pred = model(X) loss = loss_fn(pred, y) # 反向传播 optimizer.zero_grad() # 梯度清零 loss.backward() # 计算梯度 optimizer.step() # 更新参数 # 每100个batch输出一次损失 if batch_num % 100 == 0: print(f"loss: {loss.item():>7f} [batch: {batch_num}]") batch_num += 1
9. 测试函数
测试函数用于评估模型在测试集上的表现,并计算平均损失和准确率。注意:
-
使用
model.eval()将模型切换为评估模式,关闭Dropout等训练专用操作。 -
使用
torch.no_grad()上下文管理器,禁用梯度计算,节省内存和计算时间。 -
pred.argmax(1)取每个样本预测概率最大的类别索引(因为输出层有10个神经元,对应logits)。 -
累加正确预测数,最后除以总样本数得到准确率。
def test(dataloader, model, loss_fn):
total = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() # 设置为评估模式
test_loss, correct = 0, 0with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() test_loss /= num_batches accuracy = correct / total print(f"Test accuracy: {100*accuracy:.2f}%, Avg loss: {test_loss:.4f}")
10. 训练与评估
10.1 先训练一个epoch并测试
print("Training for 1 epoch:")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)10.2 训练10个epoch并观察效果
epochs = 10
for epoch in range(epochs):
print(f"\nEpoch {epoch+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
print("Training completed!")
test(test_dataloader, model, loss_fn)11. 运行结果分析
经过10个epoch的训练,测试集准确率通常可以达到97%以上,平均损失在0.1左右。以下是一次典型训练过程的输出(部分):
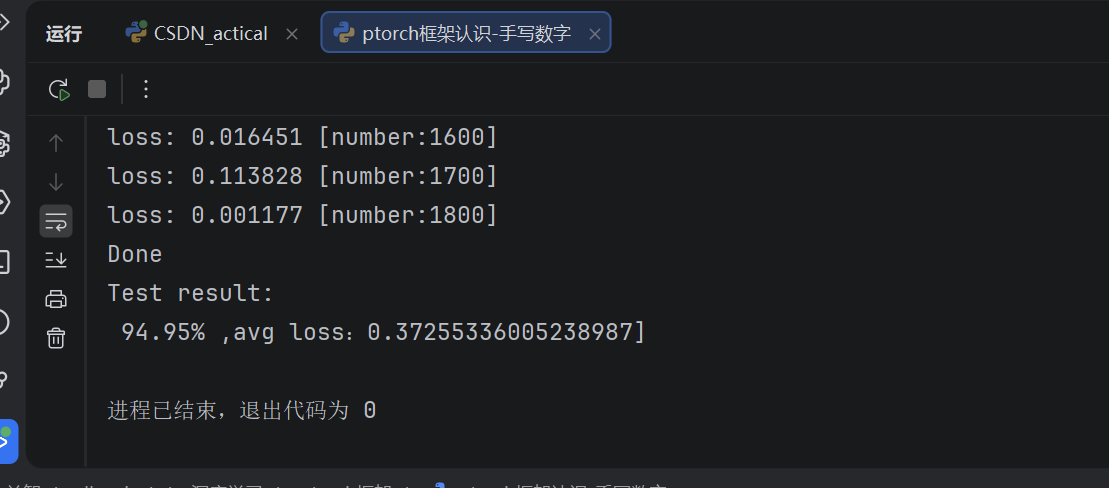
可以看到,随着训练的进行,损失值逐渐下降,准确率稳步提升。最终在测试集上达到了约95%的准确率,表明模型已经较好地学会了手写数字的分类。
12. 完整代码
将上述所有代码片段整合,即可得到完整的训练脚本。为了方便读者,以下是整理后的完整代码(可直接复制保存为 .py 文件运行):
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
# 1. 加载数据集
training_data = datasets.MNIST(root='data', train=True, download=True, transform=ToTensor())
test_data = datasets.MNIST(root='data', train=False, download=True, transform=ToTensor())
# 2. 可视化(可选)
figure = plt.figure(figsize=(8, 8))
for i in range(9):
img, label = training_data[i+59000]
figure.add_subplot(3, 3, i+1)
plt.title(label)
plt.axis('off')
plt.imshow(img.squeeze(), cmap='gray')
plt.show()
# 3. DataLoader
train_loader = DataLoader(training_data, batch_size=32, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32)
# 4. 设备
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using device: {device}")
# 5. 模型定义
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(28*28, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
x = self.flatten(x)
x = torch.relu(self.hidden1(x))
x = torch.relu(self.hidden2(x))
x = self.out(x)
return x
model = NeuralNetwork().to(device)
print(model)
# 6. 损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 7. 训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_num = 1
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_num % 100 == 0:
print(f"loss: {loss.item():>7f} [batch: {batch_num}]")
batch_num += 1
# 8. 测试函数
def test(dataloader, model, loss_fn):
total = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
accuracy = correct / total
print(f"Test accuracy: {100*accuracy:.2f}%, Avg loss: {test_loss:.4f}")
# 9. 开始训练
print("Training for 1 epoch:")
train(train_loader, model, loss_fn, optimizer)
test(test_loader, model, loss_fn)
epochs = 10
for epoch in range(epochs):
print(f"\nEpoch {epoch+1}")
train(train_loader, model, loss_fn, optimizer)
print("Training done!")
test(test_loader, model, loss_fn)13. 总结与拓展
本文从零开始实现了基于PyTorch的MNIST手写数字识别,涵盖了数据加载、模型构建、训练与测试等关键步骤。全连接神经网络虽然简单,但完整展示了深度学习的核心流程:前向传播、计算损失、反向传播、参数更新。
13.1 进一步改进的方向
-
增加模型复杂度:可以尝试添加更多隐藏层,或者使用卷积神经网络(CNN)来提取空间特征,通常会显著提升准确率。
-
调整超参数:学习率、批次大小、优化器类型、激活函数等都会影响训练效果,可以尝试不同的组合。
-
数据增强:对训练图像进行随机旋转、平移等变换,可以提高模型的泛化能力。
-
正则化:添加Dropout层或L2正则化,防止过拟合。
希望这篇文章能帮助读者快速入门PyTorch,为后续学习更复杂的深度学习任务打下坚实基础。如果有任何疑问或建议,欢迎在评论区留言交流!