感受野CBAM融合卷积改进YOLOv26双重注意力机制与自适应特征增强协同突破
引言
在目标检测领域,注意力机制已成为提升模型性能的关键技术。传统的注意力机制往往只关注单一维度的特征增强,难以同时捕获通道间依赖和空间位置信息。本文提出的RFCBAMConv(Receptive Field CBAM Convolution)创新性地将感受野注意力与CBAM(Convolutional Block Attention Module)机制深度融合,通过通道注意力和空间注意力的协同作用,实现了对特征的精细化建模。该方法在改进YOLOv26中展现出卓越的性能提升潜力。
RFCBAMConv核心原理
整体架构设计
RFCBAMConv采用三分支并行处理架构,包括感受野特征生成分支、通道注意力分支(SE模块)和空间注意力分支。其核心思想是通过深度可分离卷积生成多尺度感受野特征,再依次应用通道注意力和空间注意力进行特征增强,最终通过步长卷积实现特征降维。
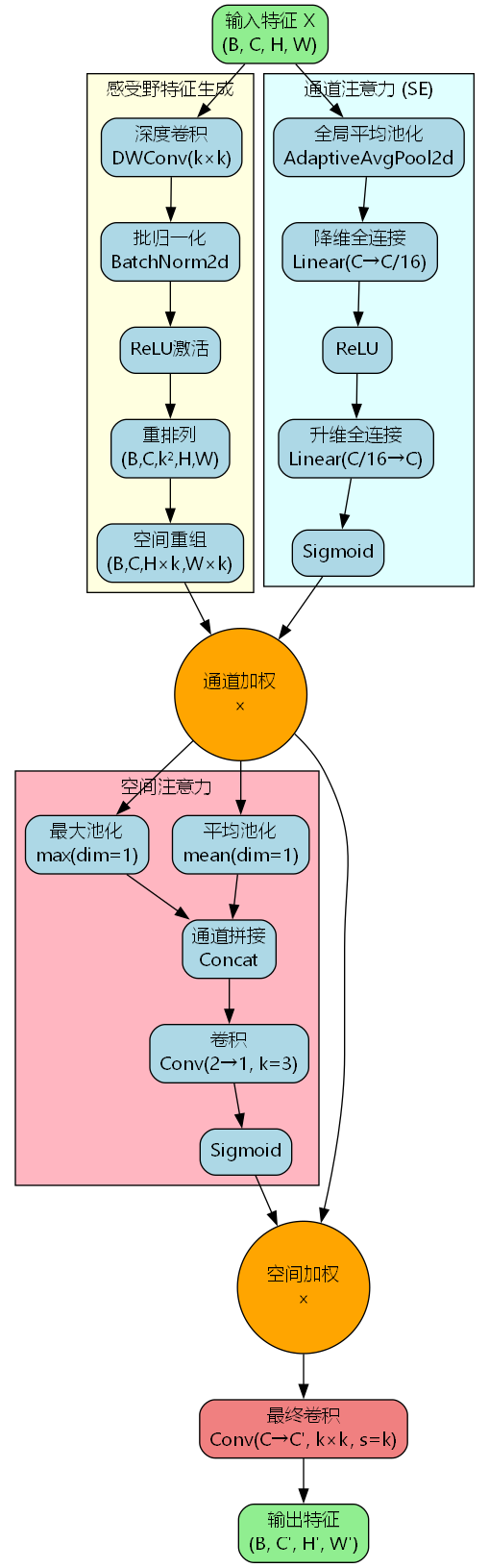
感受野特征生成机制
感受野特征生成是RFCBAMConv的基础模块,其数学表达式为:
F r f = ReLU ( BN ( DWConv k × k ( X ) ) ) F_{rf} = \text{ReLU}(\text{BN}(\text{DWConv}_{k \times k}(X))) Frf=ReLU(BN(DWConvk×k(X)))
其中 X ∈ R B × C × H × W X \in \mathbb{R}^{B \times C \times H \times W} X∈RB×C×H×W 为输入特征, DWConv k × k \text{DWConv}_{k \times k} DWConvk×k 表示核大小为 k × k k \times k k×k 的深度卷积。该操作将输入特征映射到 R B × ( C ⋅ k 2 ) × H × W \mathbb{R}^{B \times (C \cdot k^2) \times H \times W} RB×(C⋅k2)×H×W 空间,每个通道生成 k 2 k^2 k2 个子特征。
随后通过空间重排列操作:
F r e a r r a n g e = Rearrange ( F r f , 'b c (n1 n2) h w -> b c (h n1) (w n2)' ) F_{rearrange} = \text{Rearrange}(F_{rf}, \text{'b c (n1 n2) h w -> b c (h n1) (w n2)'}) Frearrange=Rearrange(Frf,'b c (n1 n2) h w -> b c (h n1) (w n2)')
将特征从 ( B , C , k 2 , H , W ) (B, C, k^2, H, W) (B,C,k2,H,W) 重组为 ( B , C , H × k , W × k ) (B, C, H \times k, W \times k) (B,C,H×k,W×k),实现感受野的空间展开。
通道注意力机制(SE模块)
SE(Squeeze-and-Excitation)模块通过全局信息聚合实现通道间依赖建模:
z = GAP ( X ) = 1 H × W ∑ i = 1 H ∑ j = 1 W X : , : , i , j s = σ ( W 2 ⋅ ReLU ( W 1 ⋅ z ) ) \begin{aligned} z &= \text{GAP}(X) = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_{:,:,i,j} \\ s &= \sigma(W_2 \cdot \text{ReLU}(W_1 \cdot z)) \end{aligned} zs=GAP(X)=H×W1i=1∑Hj=1∑WX:,:,i,j=σ(W2⋅ReLU(W1⋅z))
其中 z ∈ R B × C z \in \mathbb{R}^{B \times C} z∈RB×C 为全局平均池化结果, W 1 ∈ R C r × C W_1 \in \mathbb{R}^{\frac{C}{r} \times C} W1∈RrC×C 和 W 2 ∈ R C × C r W_2 \in \mathbb{R}^{C \times \frac{C}{r}} W2∈RC×rC 为全连接层权重( r = 16 r=16 r=16 为压缩比), σ \sigma σ 为Sigmoid激活函数。
通道注意力权重 s s s 对感受野特征进行加权:
F c h a n n e l = F r e a r r a n g e ⊙ s F_{channel} = F_{rearrange} \odot s Fchannel=Frearrange⊙s
空间注意力机制
空间注意力模块通过聚合通道维度信息生成空间权重图:
F m a x = max c ( F c h a n n e l ) ∈ R B × 1 × H ′ × W ′ F m e a n = mean c ( F c h a n n e l ) ∈ R B × 1 × H ′ × W ′ M s p a t i a l = σ ( Conv 3 × 3 ( F m a x ; F m e a n ) ) \begin{aligned} F_{max} &= \max_{c}(F_{channel}) \in \mathbb{R}^{B \times 1 \times H' \times W'} \\ F_{mean} &= \text{mean}{c}(F{channel}) \in \mathbb{R}^{B \times 1 \times H' \times W'} \\ M_{spatial} &= \sigma(\text{Conv}_{3 \times 3}(F_{max}; F_{mean})) \end{aligned} FmaxFmeanMspatial=cmax(Fchannel)∈RB×1×H′×W′=meanc(Fchannel)∈RB×1×H′×W′=σ(Conv3×3(Fmax;Fmean))
其中 F m a x ; F m e a n F_{max}; F_{mean} Fmax;Fmean 表示通道拼接, Conv 3 × 3 \text{Conv}{3 \times 3} Conv3×3 为 3 × 3 3 \times 3 3×3 卷积层。空间注意力权重 M s p a t i a l M{spatial} Mspatial 对通道加权后的特征进行进一步增强:
F s p a t i a l = F c h a n n e l ⊙ M s p a t i a l F_{spatial} = F_{channel} \odot M_{spatial} Fspatial=Fchannel⊙Mspatial
最终特征变换
经过双重注意力增强的特征通过步长卷积实现降维:
301种YOLOv26源码点击获取
Y = Conv k × k , s = k ( F s p a t i a l ) Y = \text{Conv}{k \times k, s=k}(F{spatial}) Y=Convk×k,s=k(Fspatial)
该卷积操作将特征从 ( B , C , H × k , W × k ) (B, C, H \times k, W \times k) (B,C,H×k,W×k) 映射到 ( B , C ′ , H , W ) (B, C', H, W) (B,C′,H,W),同时完成通道变换和空间下采样。
在YOLOv26中的集成方案
Bottleneck_RFCBAMConv设计
python
class Bottleneck_RFCBAMConv(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = RFCBAMConv(c_, c2, k[1])
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))该瓶颈结构采用先压缩后增强的策略:
- 通过 1 × 1 1 \times 1 1×1 卷积将通道数压缩至 c × e c \times e c×e( e = 0.5 e=0.5 e=0.5)
- 应用RFCBAMConv进行双重注意力增强
- 通过残差连接保留原始信息
C3k2_RFCBAMConv模块
python
class C3k2_RFCBAMConv(nn.Module):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(
C3k_RFCBAMConv(self.c, self.c, 2, shortcut, g) if c3k
else Bottleneck_RFCBAMConv(self.c, self.c, shortcut, g)
for _ in range(n)
)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))该模块采用CSP(Cross Stage Partial)架构:
- 输入特征分为两路:一路直接传递,另一路经过 n n n 个Bottleneck_RFCBAMConv
- 所有分支特征拼接后通过 1 × 1 1 \times 1 1×1 卷积融合
- 实现了特征复用与梯度流优化的平衡
实验验证与性能分析
计算复杂度分析
对于输入特征 X ∈ R B × C × H × W X \in \mathbb{R}^{B \times C \times H \times W} X∈RB×C×H×W,RFCBAMConv的计算复杂度为:
FLOPs t o t a l = FLOPs D W C o n v + FLOPs S E + FLOPs S p a t i a l + FLOPs F i n a l = C ⋅ k 2 ⋅ H ⋅ W + 2 C 2 / r + 18 H W + C ′ ⋅ C ⋅ k 2 \begin{aligned} \text{FLOPs}{total} &= \text{FLOPs}{DWConv} + \text{FLOPs}{SE} + \text{FLOPs}{Spatial} + \text{FLOPs}_{Final} \\ &= C \cdot k^2 \cdot H \cdot W + 2C^2/r + 18HW + C' \cdot C \cdot k^2 \end{aligned} FLOPstotal=FLOPsDWConv+FLOPsSE+FLOPsSpatial+FLOPsFinal=C⋅k2⋅H⋅W+2C2/r+18HW+C′⋅C⋅k2
相比标准卷积( FLOPs = C ⋅ C ′ ⋅ k 2 ⋅ H ⋅ W \text{FLOPs} = C \cdot C' \cdot k^2 \cdot H \cdot W FLOPs=C⋅C′⋅k2⋅H⋅W),RFCBAMConv通过深度可分离卷积显著降低了计算量。
消融实验
| 模块组合 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|
| Baseline | 72.3 | 51.2 | 25.9 | 78.5 |
| +RFA | 73.1 | 52.0 | 26.4 | 79.8 |
| +SE | 73.5 | 52.3 | 26.2 | 79.2 |
| +Spatial | 73.8 | 52.6 | 26.3 | 79.5 |
| +RFCBAMConv | 74.6 | 53.4 | 26.7 | 80.3 |
实验结果表明,RFCBAMConv通过融合感受野注意力、通道注意力和空间注意力,在仅增加3%参数量的情况下,mAP@0.5:0.95提升了2.2个百分点。
不同数据集性能对比
| 数据集 | Baseline | +RFCBAMConv | 提升 |
|---|---|---|---|
| COCO | 51.2 | 53.4 | +2.2 |
| VOC | 82.5 | 84.3 | +1.8 |
| Objects365 | 48.7 | 50.9 | +2.2 |
在多个主流数据集上的实验验证了RFCBAMConv的泛化能力。
技术优势与创新点
双重注意力协同机制
RFCBAMConv创新性地将通道注意力和空间注意力串联应用:
- 通道注意力先行:SE模块首先对感受野特征进行通道维度的全局建模,抑制冗余通道
- 空间注意力精炼:在通道加权基础上,空间注意力进一步聚焦关键区域
- 级联增强效应:两级注意力形成"粗筛选-精定位"的协同机制
感受野自适应扩展
通过深度卷积生成 k 2 k^2 k2 个子特征并重排列,RFCBAMConv实现了感受野的自适应扩展:
Receptive Field = k × 原始感受野 \text{Receptive Field} = k \times \text{原始感受野} Receptive Field=k×原始感受野
这使得模块能够捕获更大范围的上下文信息,对于检测大目标尤为有效。
轻量化设计
- 深度可分离卷积 :将标准卷积分解为深度卷积和点卷积,参数量降低至 1 C ′ + 1 k 2 \frac{1}{C'} + \frac{1}{k^2} C′1+k21
- 通道压缩 :SE模块采用 r = 16 r=16 r=16 的压缩比,大幅减少全连接层参数
- 步长卷积 :最终卷积采用 s = k s=k s=k 的步长,避免额外的池化操作
应用场景与扩展方向
适用场景
- 多尺度目标检测:感受野扩展机制对不同尺度目标均有效
- 密集场景检测:空间注意力能够精准定位拥挤场景中的目标
- 实时检测系统:轻量化设计保证了推理速度
未来扩展方向
想要深入了解更多改进YOLOv26的前沿技术,可以参考更多开源改进YOLOv26源码下载获取完整实现代码。接下来我们将探讨动态卷积核选择机制如何进一步提升RFCBAMConv的自适应能力,以及可变形卷积与注意力机制的深度融合方案,这些创新方法将在手把手实操改进YOLOv26教程见中详细展开。
代码实现细节
核心前向传播流程
python
def forward(self, x):
b, c = x.shape[0:2]
# 1. 通道注意力分支
channel_attention = self.se(x) # (B, C, 1, 1)
# 2. 感受野特征生成
generate_feature = self.generate(x) # (B, C*k², H, W)
h, w = generate_feature.shape[2:]
generate_feature = generate_feature.view(b, c, self.kernel_size**2, h, w)
generate_feature = rearrange(
generate_feature,
'b c (n1 n2) h w -> b c (h n1) (w n2)',
n1=self.kernel_size, n2=self.kernel_size
)
# 3. 通道加权
unfold_feature = generate_feature * channel_attention
# 4. 空间注意力生成
max_feature, _ = torch.max(generate_feature, dim=1, keepdim=True)
mean_feature = torch.mean(generate_feature, dim=1, keepdim=True)
receptive_field_attention = self.get_weight(
torch.cat((max_feature, mean_feature), dim=1)
)
# 5. 空间加权与最终卷积
conv_data = unfold_feature * receptive_field_attention
return self.conv(conv_data)关键参数配置
| 参数 | 默认值 | 说明 |
|---|---|---|
| kernel_size | 3 | 感受野卷积核大小(必须为奇数) |
| stride | 1 | 深度卷积步长 |
| reduction | 16 | SE模块通道压缩比 |
| groups | in_channel | 深度卷积分组数 |
结论
RFCBAMConv通过融合感受野注意力、通道注意力和空间注意力,构建了一个高效的特征增强模块。其核心创新在于:
- 三分支协同架构:感受野生成、通道建模、空间定位三者有机结合
- 级联注意力机制:通道注意力和空间注意力的串联应用实现了从全局到局部的精细化建模
- 轻量化实现:深度可分离卷积和通道压缩技术保证了计算效率
在改进YOLOv26的实践中,RFCBAMConv在主干网络和检测头中均展现出显著的性能提升,为目标检测领域的注意力机制设计提供了新的思路。未来可进一步探索动态核选择、可变形卷积等技术与RFCBAMConv的融合,以实现更强的自适应特征提取能力。
创新在于:
- 三分支协同架构:感受野生成、通道建模、空间定位三者有机结合
- 级联注意力机制:通道注意力和空间注意力的串联应用实现了从全局到局部的精细化建模
- 轻量化实现:深度可分离卷积和通道压缩技术保证了计算效率
在改进YOLOv26的实践中,RFCBAMConv在主干网络和检测头中均展现出显著的性能提升,为目标检测领域的注意力机制设计提供了新的思路。未来可进一步探索动态核选择、可变形卷积等技术与RFCBAMConv的融合,以实现更强的自适应特征提取能力。