01 背景
系统初期车辆数据主要来源于第三方网站,通过爬虫方式进行采集:
- 依赖网页结构解析,稳定性较差
- 网站结构或策略调整会导致采集失败
- 存在数据缺失问题,尤其是新车信息获取不及时或无法获取
随着业务发展,对车辆数据的准确性、完整性和时效性要求不断提高,爬虫方式已难以满足稳定数据供给需求。后续引入12123平台接口作为新的数据来源:
- 数据权威性高、结构规范
- 获取稳定性显著提升
- 但接口调用需申请权限,且存在调用次数限制
02 对接12123接口获取车辆信息
12123接口对接流程
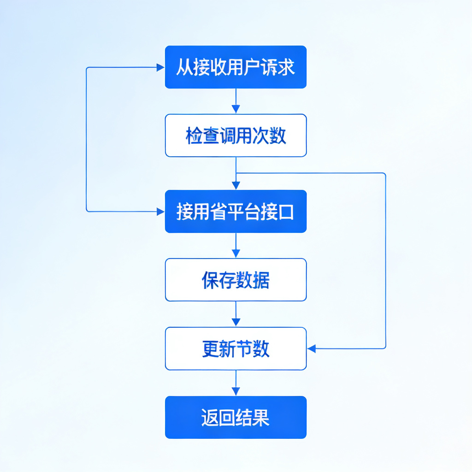
本页详细展示了调用12123接口获取车辆信息的完整流程,涵盖请求接收、次数校验、接口调用、数据处理及结果返回等关键环节,确保操作规范与数据完整。
接口对接执行步骤:
- 接收请求: 用户扫码或输入车辆编码发起查询请求
- 次数检查: 校验Redis中当日调用次数上限
- 调用接口: 获取token,构造参数调用12123查询接口
- 接收响应: 获取JSON格式的车辆信息数据
- 数据保存: 解析数据并存入本地数据库
- 更新计数: 调用INCR命令累加调用次数
- 返回结果: 将车辆信息最终返回给用户
对接12123接口实现
初始化接口调用器与获取Token代码示例:
java
// 初始化接口调用器
invoker = new NetServiceInvoker(
//参数一:NetServiceInvoker的加解密封装类,采用模板模式
new BaseHttpCryptData() {
// ... 一些信息配置
@Override
public AesToken getToken(CryptInfo info) {
return getTokenHard(info);
}
},
//参数二:NetServiceInvoker的java对象序列化封装类。
//要求将java对象序列化为json后,转化为byte[]
new IObjectByteArrayConverter() {
// 重写convert方法
}
);
// 获取Token
public AesToken getTokenHard(CryptInfo info) {
// 配置一些基本信息
NetClientRequest clientRequest = buildRequest();
clientRequest.setRequestUrl("http://XXX");
clientRequest.setCryptType(IHttpCryptData.CryptType.RSA_CRYPT);
clientRequest.setCompressType(IHttpCompressData.CompressType.GZIP);
clientRequest.setClientId(info.getClientId());
try {
NetClientResponse response = invoker.doPost(clientRequest);
AesResult token = JSONObject.parseObject(response.getData().toString(), AesResult.class);
return token.getData();
} catch (Exception e) {
return null;
}
}接口调用次数限制实现
1、技术选型
使用 Redis Key-Value 结构实现高效计数,利用其高性能特性保障接口调用次数统计的实时性、准确性,且原生支持多服务节点的分布式部署。
2、实现逻辑
- Key设计: 以特定标识作为Key,确保计数粒度。
- 计数与判断: 调用前执行INCR递增,立即判断结果是否超过阈值。
- 过期策略: 为Key设置过期时间(1天),实现每日限额。
3、代码示例
java
public long getIncrementForDay(String key) {
long serialNumber = redisTemplate.opsForValue().increment(key, 1);
if (serialNumber == 1) {
redisTemplate.expire(key, 1, TimeUnit.DAYS);
}
return serialNumber;
}03 多网站爬虫获取车辆信息
多网站循环调用策略
为提高数据获取成功率,系统采用多网站循环调用策略,依次尝试访问不同网站,直到成功获取数据或所有网站尝试完毕,极大增强了系统的容错能力和稳定性。
具体流程:
- 接收请求:
- 场景 1:用户输入车辆编码,发起通用爬虫请求;
- 场景 2:用户扫描车辆二维码,系统解析二维码获取目标 URL,发起定向爬虫请求。
- 确定爬虫目标:
- 场景 1:任务管理器从配置列表中选取未尝试的网站;
- 场景 2:直接锁定二维码解析出的目标 URL。
- 调用解析器: 调用对应网站 / URL 的解析器,尝试抓取并解析车辆信息。
- 结果判断: 检查解析器是否返回有效车辆数据。
- 成功处理: 若获取有效数据,立即整合数据并返回给用户(终止流程)。
- 失败重试 / 终止:
- 场景 1:失败则检查配置列表中剩余未尝试的网站,有则返回步骤 2 重试,无则返回爬虫失败;
- 场景 2:失败则直接返回爬虫失败(无重试环节)。
爬虫技术选型与实现(Jsoup)
Jsoup简介:
一款非常流行的Java HTML解析器,提供了类似于jQuery的CSS选择器,能够方便地提取和操作HTML数据。
核心步骤:
- 使用
Document document = Jsoup.parse(body);方法获取网页的Document对象。 - 使用
document.getElementsByTag("xxx")方法定位到包含目标数据的HTML元素。 - 通过
.text()或.attr()方法提取元素的文本内容或属性值。
简单代码示例:
java
public void doDecoder(Document document, QrcodeDecoderResult result) {
Elements tables = document.getElementsByTag("tbody");
for (Element table : tables) {
Elements trs = table.getElementsByTag("tr");
for (Element tr : trs) {
Elements tds = tr.getElementsByTag("td");
if (tds.size() == 2) {
Element labelTd = tds.get(0);
Element valueTd = tds.get(1);
if (labelTd.text().contains("车辆编码")) {
result.setBicycleCode(valueTd);
}
}
}
}
}爬虫获取车辆信息网站对接对比
目前对接的第三方网站常用的有中国质量认证中心与北京中轻联认证中心,下面基于这两个网站描述登记备案爬虫获取车辆信息的流程。
中国质量认证中心(CloseableHttpClient)
- 获取验证码图片
↓ - 验证码识别(OCR)
↓ - 携带验证码发起查询请求
↓ - 解析返回结果获取车辆信息
北京中轻联认证中心(RestTemplate)
- 发起查询请求
↓ - 解析返回结果获取车辆信息
04 备案数据推送至六合一
数据推送流程
- 新车录入/更新: 交警或经销商新增车辆备案登记或交警进行车辆业务变更。
- 定时任务推送事件: 定时任务按时触发数据推送事件,扫描新数据或新变更数据。
- 读取待推送数据: 推送服务从数据库中读取新数据或新变更数据。
- 调用推送接口: 封装成指定格式(JSON),SM2对主体数据进行解密,并对调用请求内容进行签名后调用六合一平台推送接口。
- 接收推送结果: 接收六合一平台返回的处理结果及失败原因。
- 更新本地状态: 根据结果更新车辆推送信息的推送状态(成功/失败)。
- 记录推送日志: 记录推送时间、结果等,便于后续排查。
- 失败数据处理: 对推送失败的数据根据失败原因进行数据排查。
数据推送实现代码
java
JSONObject headJson = new JSONObject();
// ... 构造请求头参数
String head = headJson.toString();
JSONObject bicycleJson = new JSONObject();
// ... 构造车辆参数
JSONObject object = new JSONObject();
object.put("param",bicycleJson);
object.put("sjbs","01-01-000005");
JSONArray jsonArray = new JSONArray();
jsonArray.add(object);
String data=SM2Util.encrypt(SM2公钥,jsonArray.toString().getBytes("UTF-8"));
// 下面是处理图片
JSONObject jsonObject = new JSONObject();
jsonObject.put("fileid","zczp");
jsonObject.put("data",getImgFileToBase64(图片路径));
JSONObject object2 = new JSONObject();
JSONArray jsonArrayFile = new JSONArray();
jsonArrayFile.add(jsonObject);
object2.put("param",jsonArrayFile);
object2.put("sjbs","01-01-000005");
JSONArray jsonArray2 = new JSONArray();
jsonArray2.add(object2);
String files = jsonArray2.toString();
// 组装生成签名,下面一些是接口分配的代码或固定参数
String ori = fwxlh+"#"+jgbh+"#"+dxbj+"#"+wgcdbh+"#"+czrglbm+"#"+czrsfzmhm+"#"+zdbh+"#"+zdsjip+"#"+dateString;
String sign= SM2Util.sign(privatekey,ori.getBytes());
// 请求调用
String result = Https.sendPostByXW(url, head,data,files,sign);05 总结
系统核心功能总结
-
多源数据获取
通过结合12123官方接口和第三方网站爬虫,构建了一个稳定、冗余的数据获取渠道,确保在单一来源不可用时,仍能获取到车辆信息。
-
智能调用控制
利用Redis实现了精准的接口调用次数限制,不仅遵守了外部平台的规范,也防止了系统资源被滥用,保障了服务的稳定性。
-
数据推送
通过定时任务按时扫描数据库中新增或修改的车辆数据确保数据尽快的上报到六合一平台,满足业务合规要求。
常见问题与解决方案
Q1: 调用省平台接口返回"次数超限"怎么办?
A1: 这是正常的限流机制。请等待限制周期(一天)结束后再试,或者联系省12123管理员申请调整调用配额。
Q2: 爬虫获取数据失败如何处理?
A2: 首先检查目标网站是否正常访问,页面结构是否发生变化。如果是结构变化,需要更新对应的解析规则。同时,系统会自动尝试其他网站的爬虫,确保数据获取的成功率。
Q3: 数据推送失败如何排查?
A3: 首先查看系统的推送日志,检查平台返回的具体错误信息。根据错误提示处理数据内容或联系平台方确认接口状态。