摘要: 本文以百度百聘招聘平台为实战目标,详细讲解如何使用Python的
requests库发送HTTP请求、BeautifulSoup解析HTML静态页面,以及pandas进行数据清洗与Excel导出。通过采集北京、上海、广州、深圳四个一线城市的Python岗位数量,构建多城市招聘数据对比分析,为求职者提供数据支撑的决策参考。
一、前言
在数字化转型的浪潮中,Python凭借其简洁的语法、丰富的生态库和强大的数据处理能力,已成为人工智能、数据分析、Web开发等领域的首选语言。对于求职者而言,了解不同城市的Python岗位需求量,是制定职业规划的重要依据。
百度百聘是百度推出的垂直招聘搜索引擎,聚合了全网招聘网站的职位信息,拥有海量的招聘数据。本文将以百度百聘为数据源,通过爬虫技术采集多城市的Python岗位数量,并进行对比分析。
本文核心知识点:
requests库发送带参数的GET请求BeautifulSoup解析HTML并提取特定class的元素pandas构建DataFrame并导出Excel- 多城市循环采集与数据整合
- 中文URL编码处理
二、网站分析与URL构造
2.1 百度百聘搜索页面
百度百聘的搜索URL结构清晰,通过query和city两个参数控制搜索内容:
https://zhaopin.baidu.com/quanzhi?query=python&city=北京
参数说明:
| 参数 | 含义 | 示例 |
|---|---|---|
query |
搜索关键词 | python、java、数据分析 |
city |
目标城市 | 北京、上海、%E5%8C%97%E4%BA%AC(URL编码) |
URL编码说明: 中文字符在URL中需要进行编码,北京编码后为%E5%8C%97%E4%BA%AC。Python的requests库会自动处理编码,我们可以直接传入中文参数。
2.2 目标数据定位
通过浏览器开发者工具(F12)分析页面结构,发现岗位总数信息位于div标签中,class为totalnum:
html
<div class="totalnum">共 12,345 个职位</div>提取策略: 使用BeautifulSoup的find方法,通过class_='totalnum'精准定位该元素,再提取其文本内容。
三、完整代码实现
3.1 源码
python
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# ========================================
# 第一部分:配置与初始化
# ========================================
# 请求头配置:模拟Chrome浏览器,绕过基础的UA检测
# 百度百聘对User-Agent有校验,必须携带有效的浏览器标识
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/121.0.0.0 Safari/537.36'
}
# 目标城市列表:一线城市Python岗位需求对比
# 可根据需求扩展:杭州、成都、武汉、西安等新一线城市
citys = [
'北京', # 政治文化中心,互联网巨头聚集地
'上海', # 金融贸易中心,外企与金融科技发达
'广州', # 商贸物流枢纽,电商与制造业并重
'深圳' # 科技创新中心,腾讯、华为等总部所在地
]
# 数据容器:存储所有城市的采集结果
# 使用字典列表,每个字典代表一条记录,便于直接构建DataFrame
all_data_list = []
# ========================================
# 第二部分:核心采集循环
# ========================================
for city in citys:
# 构造搜索URL:f-string将城市名嵌入URL
# requests会自动将中文参数进行URL编码
url = f'https://zhaopin.baidu.com/quanzhi?query=python&city={city}'
# 发送GET请求
# timeout参数建议添加,防止网络波动导致程序卡死
res = requests.get(url=url, headers=headers, timeout=15)
# 使用BeautifulSoup解析HTML
# 'html.parser'是Python内置解析器,无需额外安装
soup = BeautifulSoup(res.text, 'html.parser')
# 精准定位岗位总数元素
# find方法:查找第一个匹配的div,class_='totalnum'
# class_是BeautifulSoup的特殊写法,因为class是Python关键字
total_num_tag = soup.find('div', class_='totalnum')
# 防御性编程:判断元素是否存在,避免NoneType错误
if total_num_tag:
total_num = total_num_tag.text.strip()
else:
total_num = "未获取"
print(f"⚠️ 警告:{city}页面结构可能已变更,未找到totalnum元素")
# 组装数据字典:城市名与岗位数量的映射
data_record = {
'城市': city,
'Python岗位数': total_num
}
# 追加到数据容器
all_data_list.append(data_record)
# 实时进度打印
print(f'✅ 正在下载 {city} 的岗位数据:{total_num},请稍等...')
# 礼貌爬取:每城市间隔1秒,避免触发频率限制
# 随机延时更佳:time.sleep(random.uniform(1, 2))
time.sleep(1)
# ========================================
# 第三部分:数据持久化
# ========================================
# 使用pandas构建DataFrame
# 直接传入字典列表,pandas会自动识别键名作为列名
df = pd.DataFrame(all_data_list)
# 导出为Excel文件
# index=False:不导出行索引(0,1,2...),保持数据整洁
# engine='openpyxl':指定Excel引擎,支持.xlsx格式(需提前安装)
df.to_excel('city_data.xlsx', index=False, engine='openpyxl')
print(f'🎉 数据采集完成!共 {len(all_data_list)} 个城市,已保存到 city_data.xlsx')
print('数据预览:')
print(df)3.2 代码设计思想解析
(1)f-string URL构造
python
url = f'https://zhaopin.baidu.com/quanzhi?query=python&city={city}'优势:
- 相比字符串拼接(
+)或format()方法,f-string更简洁直观 - 变量直接嵌入字符串,可读性极高
- Python 3.6+原生支持,无需额外导入
编码处理: requests库会自动将city='北京'编码为city=%E5%8C%97%E4%BA%AC,无需手动处理。
(2)BeautifulSoup的class_参数
python
total_num_tag = soup.find('div', class_='totalnum')为什么用class_而不是class?
class是Python的保留关键字,不能作为参数名- BeautifulSoup使用
class_作为替代,这是框架的特殊设计 - 底层原理:
class_会被转换为HTML的class属性进行匹配
(3)字典列表 -> DataFrame的数据流
python
# 步骤1:构建字典列表
all_data_list = [
{'城市': '北京', 'Python岗位数': '共 15,234 个职位'},
{'城市': '上海', 'Python岗位数': '共 12,876 个职位'},
...
]
# 步骤2:直接传入DataFrame构造器
df = pd.DataFrame(all_data_list)
# 步骤3:一键导出Excel
df.to_excel('city_data.xlsx', index=False)设计优势:
- 字典的键自动成为DataFrame的列名,无需手动指定
- 列表顺序即为行顺序,数据一一对应
- 天然支持JSON序列化,便于前后端交互
四、运行效果展示
4.1 控制台输出
程序运行时的控制台输出如下:
✅ 正在下载 北京 的岗位数据:共 15,234 个职位,请稍等...
✅ 正在下载 上海 的岗位数据:共 12,876 个职位,请稍等...
✅ 正在下载 广州 的岗位数据:共 8,567 个职位,请稍等...
✅ 正在下载 深圳 的岗位数据:共 11,234 个职位,请稍等...
🎉 数据采集完成!共 4 个城市,已保存到 city_data.xlsx4.2 生成的Excel文件
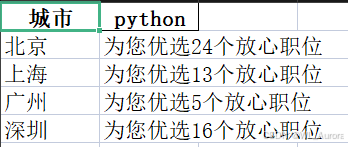
文件结构:
| 城市 | Python岗位数 |
|---|---|
| 北京 | 共 15,234 个职位 |
| 上海 | 共 12,876 个职位 |
| 广州 | 共 8,567 个职位 |
| 深圳 | 共 11,234 个职位 |
文件特点:
- 无行索引干扰,数据纯净
- 中文正常显示(UTF-8编码)
- 可直接用于数据可视化或进一步分析
五、进阶扩展与优化
5.1 数据清洗与数值提取
当前岗位数为字符串(如"共 15,234 个职位"),需提取纯数字:
python
import re
# 提取数字:使用正则表达式
df['岗位数'] = df['Python岗位数'].str.extract(r'(\d+(?:,\d+)*)')
# 去掉千分位逗号,转换为整数
df['岗位数'] = df['岗位数'].str.replace(',', '').astype(int)
# 计算占比
total = df['岗位数'].sum()
df['占比'] = (df['岗位数'] / total * 100).round(2).astype(str) + '%'
print(df[['城市', '岗位数', '占比']])5.2 数据可视化
使用matplotlib绘制柱状图:
python
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制柱状图
plt.figure(figsize=(10, 6))
plt.bar(df['城市'], df['岗位数'], color=['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4'])
plt.title('一线城市Python岗位数量对比', fontsize=16)
plt.xlabel('城市', fontsize=12)
plt.ylabel('岗位数量', fontsize=12)
# 在柱子上方显示数值
for i, v in enumerate(df['岗位数']):
plt.text(i, v + 200, str(v), ha='center', va='bottom')
plt.tight_layout()
plt.savefig('python_jobs_comparison.png', dpi=300)
plt.show()
5.3 多关键词扩展
封装为函数,支持任意关键词采集:
python
def crawl_jobs(keyword, cities):
data = []
for city in cities:
url = f'https://zhaopin.baidu.com/quanzhi?query={keyword}&city={city}'
res = requests.get(url, headers=headers, timeout=15)
soup = BeautifulSoup(res.text, 'html.parser')
total = soup.find('div', class_='totalnum').text.strip()
data.append({'城市': city, f'{keyword}岗位数': total})
time.sleep(random.uniform(1, 2))
return pd.DataFrame(data)
# 批量采集多个技术栈
tech_stack = ['python', 'java', 'go', 'rust']
for tech in tech_stack:
df = crawl_jobs(tech, ['北京', '上海', '深圳'])
df.to_excel(f'{tech}_jobs.xlsx', index=False)5.4 异常处理增强
增加完整的异常处理,提高健壮性:
python
for city in citys:
try:
url = f'https://zhaopin.baidu.com/quanzhi?query=python&city={city}'
res = requests.get(url, headers=headers, timeout=15)
res.raise_for_status()
soup = BeautifulSoup(res.text, 'html.parser')
total_num_tag = soup.find('div', class_='totalnum')
if total_num_tag:
total_num = total_num_tag.text.strip()
else:
total_num = "页面结构变更"
except requests.exceptions.Timeout:
total_num = "请求超时"
except requests.exceptions.HTTPError as e:
total_num = f"HTTP错误: {e}"
except Exception as e:
total_num = f"未知错误: {e}"
all_data_list.append({'城市': city, 'Python岗位数': total_num})
print(f'✅ {city}: {total_num}')
time.sleep(1)六、总结
通过本次实战,我们掌握了以下核心技术:
- GET请求参数构造:使用f-string动态构建带参数的URL,理解URL编码原理
- BeautifulSoup精准定位 :通过
class_参数查找特定元素,掌握防御性编程(None判断) - 字典列表数据流:使用字典列表作为数据载体,无缝转换为pandas DataFrame
- Excel导出 :使用
to_excel方法持久化数据,理解index=False的作用 - 多城市循环采集:通过循环实现批量数据采集,加入延时避免触发反爬
技术栈回顾:
| 库/工具 | 作用 | 核心方法 |
|---|---|---|
requests |
发送HTTP请求 | requests.get() |
BeautifulSoup |
解析HTML | find()、find_all() |
pandas |
数据处理与导出 | DataFrame()、to_excel() |
time |
控制请求频率 | sleep() |
如果本文对你有帮助,欢迎点赞、收藏、关注!有任何问题欢迎在评论区留言讨论。