紧接上文
二、层次聚类
层次聚类(Hierarchical Clustering)分析是一种数据聚类方法,能够根据样本之间的相似度或距离,将样本分层次地组织成树状结构(即树状图或树形图)。该方法广泛应用于基因表达数据分析、文本挖掘、图像分类等需要揭示数据层次结构的领域。
层次聚类可以分为自底向上和自顶向下两种方法。
**(1)**自底向上(凝聚法,Agglomerative):从每个样本自身作为一个簇开始,不断将相似的样本合并成新的簇,直到所有样本被合并到同一个簇。该方法是目前应用最广泛的一种。
**(2)**自顶向下(分裂法,Divisive):从所有样本作为一个簇开始,不断将簇拆分成较小的簇,直到每个样本单独成为一个簇。
在层次聚类中,选择适当的样本距离和簇间距离是非常关键的。常用的样本距离和簇间距离包括:
**(1)**样本距离:欧氏距离、曼哈顿距离、杰卡德距离、皮尔逊相关系数等。
**(2)**簇间距离:
单连接:两个簇中最近的样本之间的距离。
完全连接:两个簇中最远的样本之间的距离。
平均连接:两个簇之间所有样本对的平均距离。
质心距离:簇质心(中心点)之间的距离。
Ward's方法:通过最小化每个簇内的平方和来合并或分裂簇。
以自底向上的方法为例,层次聚类的实现步骤如下。
步骤01计算距离矩阵:计算数据集中每对样本之间的距离。
步骤02合并最近的簇:找到距离最小的两个样本或簇,将其合并为一个新的簇。
步骤03 更新距离矩阵:更新新的簇与其他簇之间的距离,依据选择的簇间距离方法重新计算。
步骤04 重复步骤02 和步骤03:继续合并簇,直到所有样本被合并为一个大簇,形成树状结构。
在R中,可以使用hclust()函数来进行层次聚类分析,并使用dendrogram()函数绘制树状图。其中,函数hclust()的语法结构如下:
hclust(d,method="complete",members=NULL)其中,参数选项含义如下表所示。


函数dendrogram()的语法结构如下:
dendrogram(object)其中,参数选项含义如下表所示。

【例7】使用hclust()函数计算并使用plot()绘图以及dendrogram()函数美化树状图。
在代码编辑器中依次输入以下代码,选中后单击RUN按钮运行。
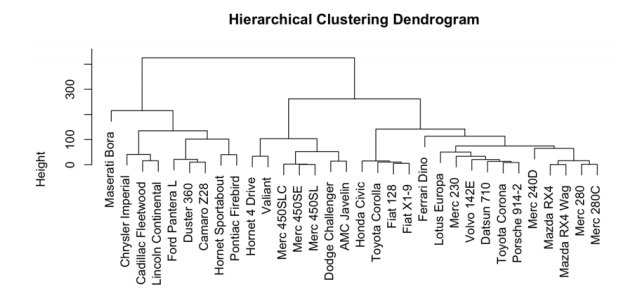
dist_matrix <- dist(mtcars) # 计算距离矩阵(以欧氏距离为例)
hc <- hclust(dist_matrix,method="complete") # 进行层次聚类(以完全连接为例)
# 绘制树状图
plot(hc,main="Hierarchical Clustering Dendrogram",xlab="",sub="")运行后输出结果如下图所示。
继续在代码编辑器中依次输入以下代码,选中后单击RUN按钮运行。
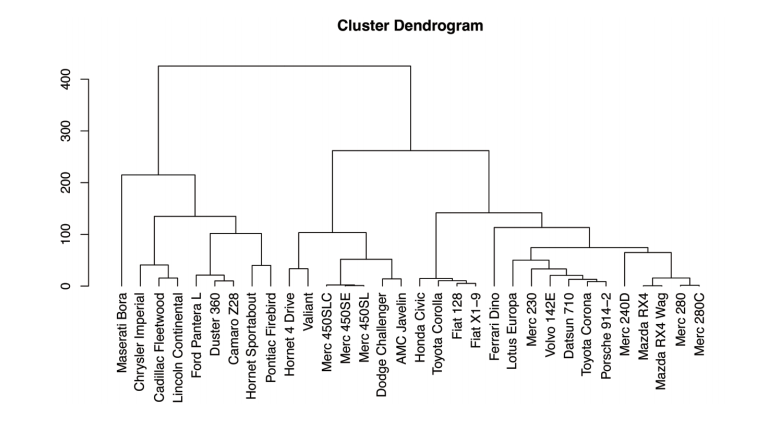
dendro <- as.dendrogram(hc) # 使用hclust对象生成dendrogram,并绘制图形
plot(dendro,main="Cluster Dendrogram",hang=-1) # 绘图运行后输出结果如下图所示。可以看出,通过dendrogram()函数绘制图形会更加美观。
三、均值聚类
均值聚类(K-means Clustering)是一种常见的非层次聚类方法,适合在数据集中识别出具有相似特征的多个簇。均值聚类是通过迭代优化的方法,将数据划分为预定义的K个簇,并通过最小化簇内平方误差来达到聚类效果。均值聚类的原理如下。
**(1)**初始化簇心:首先随机选择K个数据点作为簇的中心(簇心)。
**(2)**分配数据点:将每个数据点分配到与其欧氏距离最近的簇中心,形成K个簇。
**(3)**更新簇心:重新计算每个簇的中心点,方法是将每个簇中的所有数据点的均值作为新的簇心。
**(4)**重复迭代:重复"分配数据点"和"更新簇心"步骤,直到簇中心不再发生显著变化或达到最大迭代次数为止。
这种算法的目标是最小化簇内数据点到簇心的平方距离总和。最终得到的簇使得簇内数据点的相似性高,而簇间数据点的差异性大。
在R中,kmeans()函数用于执行K-means聚类分析。其语法结构如下:
kmeans(x,centers,iter.max=10,nstart=1,
algorithm=c("Hartigan-Wong","Lloyd","Forgy","MacQueen"))其中,参数选项含义如下表所示。

K-means聚类分析作为一种无监督的聚类方法,通常我们会先用代码找出自己的数据适合分为几类,再来输出结果。
在选取具体分几类进行比较时,我们这里提供两种常用的方式,最终选取分为几类时,可在上述分类方法的基础上根据自己数据的特征确定具体分为几类。
方法一:肘部法
肘部法(Elbow Method)是最常用的确定K值的方法。它通过计算不同K值下的总平方误差(SSE)来帮助找到最佳的聚类数。随着K值增加,SSE会逐渐减小,但减少的幅度会在某个点显著减缓,这个点被称为"肘部",即最佳的K值。使用factoextra包中的fviz_nbclust()函数可以实现该方法。其语法结构如下:
fviz_nbclust(x,FUNcluster,method="wss",...)其中,参数选项含义如下表所示。

方法二:Gap统计量方法
Gap统计量方法通过计算数据的实际聚类效果与在同等条件下随机分布数据的聚类效果的差异来确定最佳的K值。Gap统计量值越大,表示当前的K值越合理。使用cluster包中的clusGap()函数可以实现该方法。其语法结构如下:
clusGap(x,FUNcluster,K.max,...)其中,参数选项含义如下表所示。

确定好具体分几类最合适后,一般会将数据使用fviz_cluster()函数可视化。其语法结构如下:
fviz_cluster(object,data=NULL,geom="point",stand=TRUE,
frame=TRUE,frame.type="convex",frame.level=0.95,
ellipse=FALSE,ellipse.type="t",ellipse.level=0.95,
labelsize=12,main="Clusterplot",ggtheme=theme_minimal(),...)其中,参数选项含义如下表所示。
【例8】以鸢尾花数据集iris的前4列数据为例进行聚类分析。
在代码编辑器中依次输入以下代码,选中后单击RUN按钮运行。
library(factoextra)
library(cluster)
library(patchwork)
df <- iris[1:4] # 使用R语言自带的鸢尾花数据
# 第1种方法
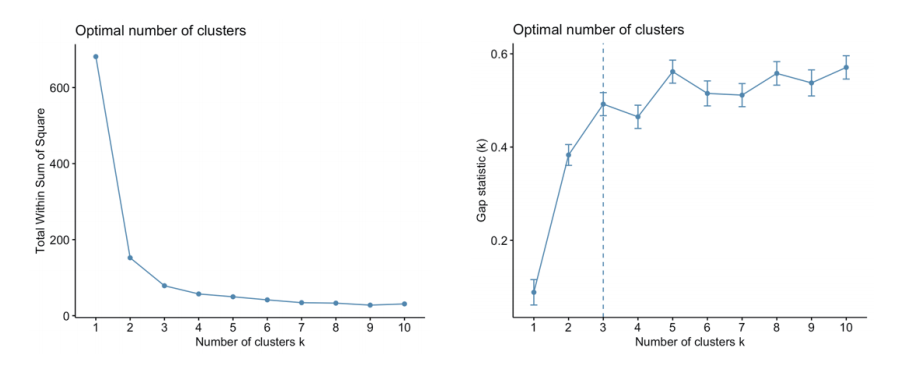
par(mfrow=c(1,2))
fviz_nbclust(df,kmeans,method="wss")
# 第2种方法
gap_stat <- clusGap(df,kmeans,K.max=10)
fviz_gap_stat(gap_stat)运行后输出结果如下图所示。第1种方法发现到3之后就缓慢下降了,说明3比较好;第2种方法虚线在3,说明3比较好。可以发现,两种方法得到的结果是一致的。
继续在代码编辑器中依次输入以下代码,选中后单击RUN按钮运行。
set.seed(1)
km <- kmeans(df,centers=3,nstart=25) # 选取3类作为分类
km
# 使用fviz_cluster作图
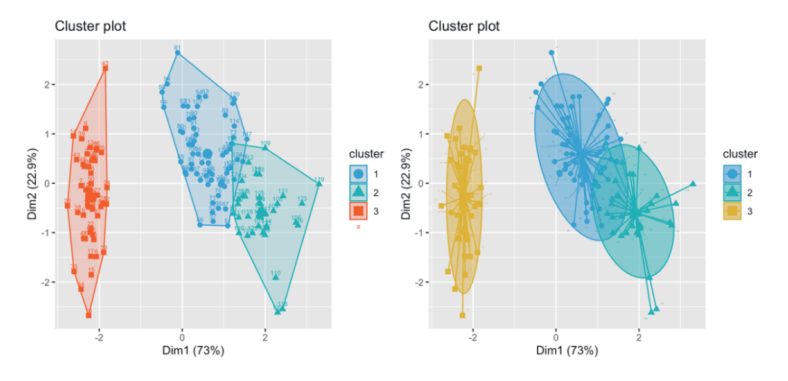
p1 <- fviz_cluster(km,data=df,
palette=c("#2E9FDF","#00AFBB","#FC4E07"),
pointsize=2, # 图中点的大小
labelsize=6) # 图中标签的大小
# 更改作图方式
p2 <- fviz_cluster(km,data=df,
palette=c("#2E9FDF","#00AFBB","#FC4E07"),
ellipse.type="t",
ellipse.level=0.95, # 置信区间
ellipse.alpha=0.5, # 颜色的透明度
star.plot=TRUE,
pointsize=2, # 图中点的大小
labelsize=2, # 图中标签的大小
repel=TRUE,
show.clust.cent=T # 是否展示中心点
)
p1+p2运行后输出结果如下图所示。
四、本章小结
通过本章的学习,你应该已经掌握了聚类分析的基本概念、常用算法以及在R语言中的实际操作。聚类分析为探索数据提供了强大的工具,使我们能够在数据中发现自然分组并揭示隐藏的关系。无论是K均值聚类、层次聚类还是密度聚类,各种方法各有特点,可以灵活应用于不同类型的数据。
在实际应用中,选择合适的聚类方法及其参数尤为重要,而对聚类结果的评估和可视化有助于验证和解释模型的有效性。希望通过本章的内容,你能够深入理解聚类分析的原理,并具备在实际数据分析中进行聚类探索的能力。
本文摘自《R语言医学数据分析与可视化》,具体内容请以书籍为准。