11.深度优先搜索(DFS)
深度优先搜索(DFS)是一种遍历技术,探索尽可能远的分支然后回溯。
在图或树中探索所有路径或分支时使用此模式。
核心逻辑:一条路走到黑,走不通再回头
递归本质:用系统栈保存遍历状态,深入到最深的分支后,回溯到上一层,继续探索其他分支。
适用场景:需要遍历所有路径、分支、状态的问题,比如:
- 树 / 图的全路径遍历(根到叶子、所有路径)
- 连通性判断、图的遍历
- 回溯类问题(组合、排列、子集)
- 拓扑排序(课程表这类问题)
核心三要素:
- 终止条件:什么时候停止递归(比如到叶子节点、访问过的节点、越界)
- 递归逻辑:对当前节点做什么,然后递归子节点 / 邻居
- 回溯操作:递归返回后,撤销当前状态(比如路径回退、访问标记清除)
克隆图(LeetCode#133)
题目描述
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(listNode)。
python
class Node {
public int val;
public List<Node> neighbors;
}测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
示例 1:
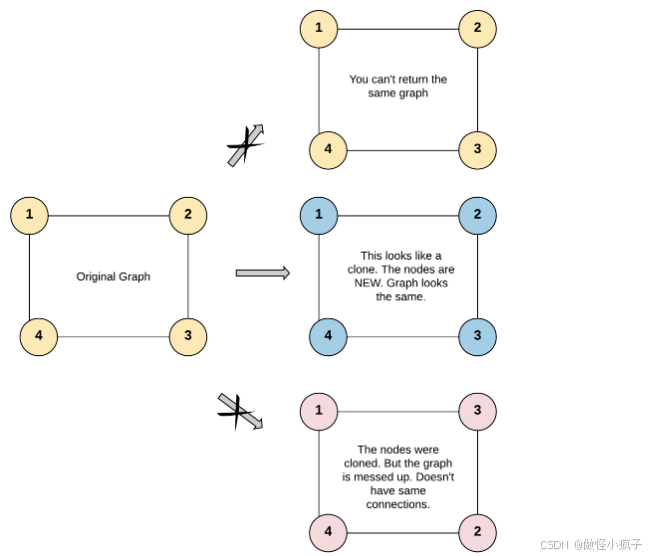
输入:adjList = \[2,4,1,3,2,4,1,3]
输出:\[2,4,1,3,2,4,1,3]
解释:
图中有 4 个节点。
节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
示例 2:

输入:adjList = \[]
输出:\[]
解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。
示例 3:
输入:adjList = \[\]
输出:\[\]
解释:这个图是空的,它不含任何节点。
提示:
这张图中的节点数在 0, 100 之间。
1 <= Node.val <= 100
每个节点值 Node.val 都是唯一的,
图中没有重复的边,也没有自环。
图是连通图,你可以从给定节点访问到所有节点。
题目求解
哈希表 是 图DFS的核心,解决环、重复访问的问题。
哈希表存储,原节点-克隆节点
核心逻辑:用 DFS 遍历原图 + 哈希表记录映射关系:
- 哈希表 visited:键是「原图节点」,值是「克隆后的新节点」,解决「环」和「重复克隆」问题
- DFS 过程:
- 遍历到一个节点时,先看哈希表:如果已克隆过,直接返回克隆节点
- 如果没克隆过,先创建克隆节点,存入哈希表
- 递归克隆当前节点的所有邻居,把克隆后的邻居添加到新节点的邻居列表中
- 返回当前克隆节点
python
"""
# Definition for a Node.
class Node:
def __init__(self, val = 0, neighbors = None):
self.val = val
self.neighbors = neighbors if neighbors is not None else []
"""
from typing import Optional
class Solution:
def cloneGraph(self, node: Optional['Node']) -> Optional['Node']:
visited = {} # 用哈希表
def dfs(node):
if not node: return
if node in visited:
return visited[node] # 返回我们克隆的节点
clone_node = Node(node.val)
visited[node] = clone_node
for neighbor in node.neighbors:
clone_neighbor = dfs(neighbor)
clone_node.neighbors.append(clone_neighbor)
return clone_node
return dfs(node)路径总和Il(LeetCode#113)
题目描述
叶子节点 是指没有子节点的节点。
示例 1:
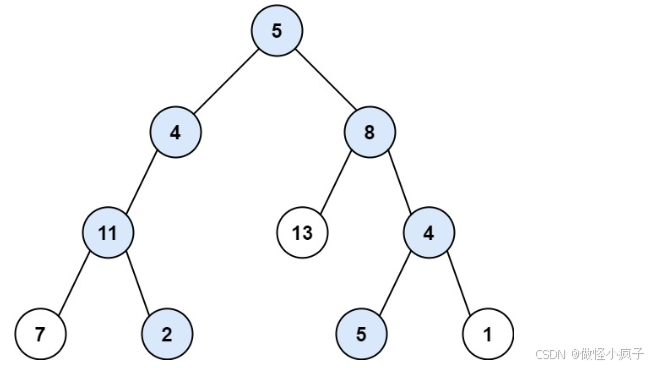
输入:root = 5,4,8,11,null,13,4,7,2,null,null,5,1, targetSum = 22
输出:\[5,4,11,2,5,8,4,5]
示例 2:
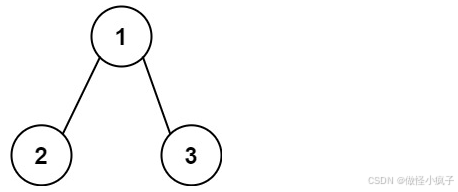
输入:root = 1,2,3, targetSum = 5
输出:\[\]
示例 3:
输入:root = 1,2, targetSum = 0
输出:\[\]
提示:
树中节点总数在范围 0, 5000 内
-1000 <= Node.val <= 1000
-1000 <= targetSum <= 1000
题目求解
用列表存路径时,回溯必须pop(),否则路径会被污染;拷贝列表用copy()或:。
python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
result = []
path = []
def dfs(node, currentSum):
if not node:
return
currentSum += node.val
path.append(node.val)
if not node.left and not node.right:
# 叶子节点,判断根节点到叶子节点路径和是否等于给定目标的路径
if currentSum == targetSum:
result.append(path.copy())
else:
dfs(node.left, currentSum)
dfs(node.right, currentSum)
path.pop()
dfs(root, 0)
return result课程表Il(LeetCode#210)
题目描述
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisitesi = ai, bi ,表示在选修课程 ai 前 必须 先选修 bi 。
例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示:0,1 。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
示例 1:
输入:numCourses = 2, prerequisites = \[1,0]
输出:0,1
解释:总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 0,1 。
示例 2:
输入:numCourses = 4, prerequisites = \[1,0,2,0,3,1,3,2]
输出:0,2,1,3
解释:总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 0,1,2,3 。另一个正确的排序是 0,2,1,3 。
示例 3:
输入:numCourses = 1, prerequisites = \[\]
输出:0
提示:
1 <= numCourses <= 2000
0 <= prerequisites.length <= numCourses * (numCourses - 1)
prerequisitesi.length == 2
0 <= ai, bi < numCourses
ai != bi
所有ai, bi 互不相同
题目求解
解决「有向无环图(DAG)」的依赖排序问题。
解决「先修依赖」类排序问题:
- 比如「修 A 课前必须先修 B 课」→ 有向边 B → A
- 要求输出满足所有依赖的合法学习顺序(拓扑序);若图中有环(比如 A 依赖 B、B 依赖 A),则无法完成,返回空数组。
核心逻辑:
| 核心要素 | 作用 | 课程表 II 中的具体实现 |
|---|---|---|
| 邻接表 | 存储图的依赖关系 | adj[b].append(a):表示 b 是 a 的先修课,有向边 b→a |
| 状态数组 | 标记节点状态,解决「环」的问题 | 0=未访问/1=访问中/2=已访问:- 0→1:开始遍历节点- 1→2:节点遍历完成- 遇到状态 1 的节点→存在环 |
| 后序遍历 + 逆序 | 生成拓扑序 | 后序遍历收集的节点是「依赖完成的节点」,逆序后就是满足依赖的拓扑序 |
python
class Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
# 构建邻接表
adj = [[] for _ in range(numCourses)]
for a, b in prerequisites:
adj[b].append(a) # b -> a
# 状态 0 未访问, 1 访问中, 2 已访问
status = [0] * numCourses
res = [] # 存放结果
has_cycle = False
def dfs(u):
nonlocal has_cycle
status[u] = 1 # 访问中
if has_cycle: return
for v in adj[u]:
if status[v] == 0:
dfs(v)
elif status[v] == 1:
has_cycle = True
return
# 标记为已访问
status[u] = 2
res.append(u)
for i in range(numCourses):
if status[i] == 0 and not has_cycle:
dfs(i)
return [] if has_cycle else res[::-1]