文章目录
推荐网站
https://github.com/shareAI-lab/learn-claude-code/blob/main/README-zh.md
工具与执行
agent 循环
最简单的agent,就是一个while循环+一个工具
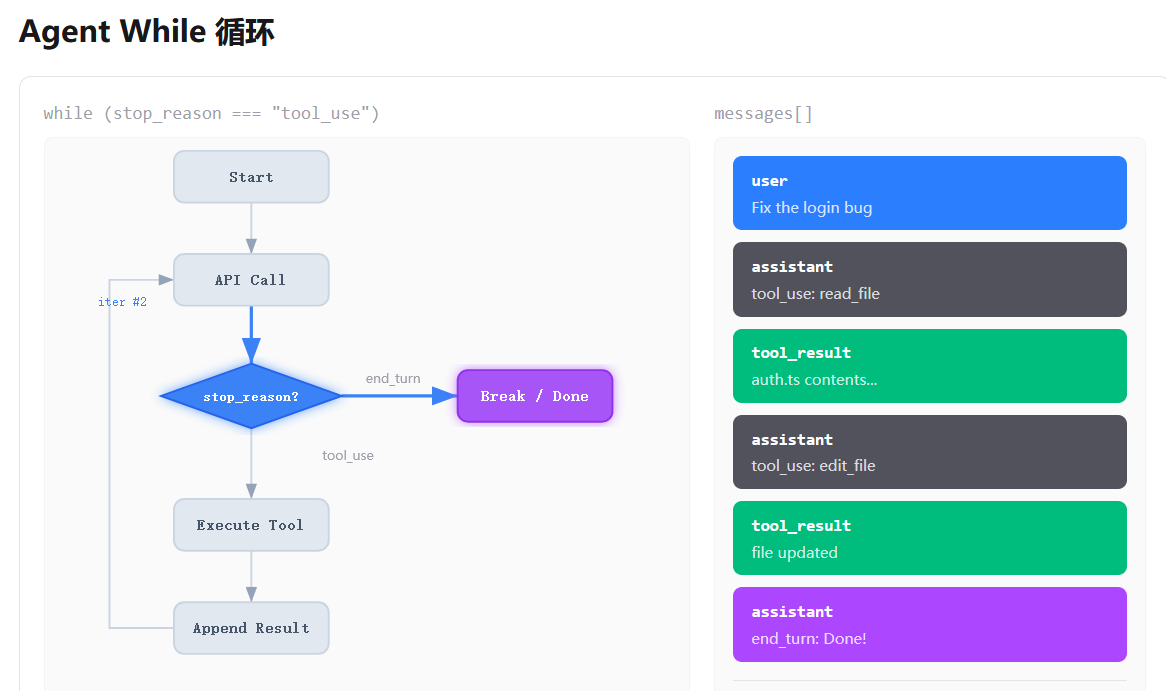
一个最简单的agent:
用户消息传入---创建含用户消息和可调用工具的模型---检查是否要继续调用工具---逐个调用工具并存储工具响应
python
def agent_loop(query):
messages = [{"role": "user", "content": query}]
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
results = []
for block in response.content:
if block.type == "tool_use":
output = run_bash(block.input["command"])
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
messages.append({"role": "user", "content": results})工具
新的工具加入,注册到分发图(dispatch map)里
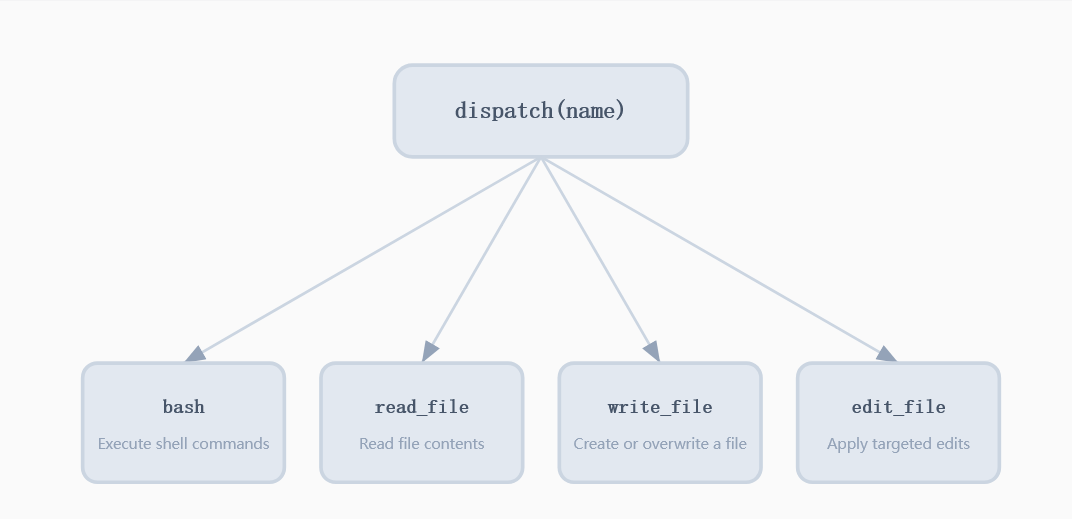
问题:只有 bash 时, 所有操作都走 shell。cat 截断不可预测, sed 遇到特殊字符就崩, 每次 bash 调用都是不受约束的安全面。专用工具 (read_file, write_file) 可以在工具层面做路径沙箱。
每个工具都有一个处理函数和路径沙箱
WORKDIR / p表示把用户传进来的相对路径拼到工作目录后面,resolve将路径标准化为绝对路径
python
def safe_path(p: str) -> Path:
path = (WORKDIR / p).resolve()
if not path.is_relative_to(WORKDIR):
raise ValueError(f"Path escapes workspace: {p}")
return path
def run_read(path: str, limit: int = None) -> str:
text = safe_path(path).read_text()
lines = text.splitlines()
if limit and limit < len(lines):
lines = lines[:limit]
return "\n".join(lines)[:50000]dispatch map将工具名映射到处理函数
**kw表示:接收任意数量的"关键字参数",并把它们打包成一个字典。
python
TOOL_HANDLERS = {
"bash": lambda **kw: run_bash(kw["command"]),
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"],
kw["new_text"]),
}循环中按名称查找处理函数
python
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler \
else f"Unknown tool: {block.name}"
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})| 组件 | 之前 (s01) | 之后 (s02) |
|---|---|---|
| Tools | 1 (仅 bash) | 4 (bash, read, write, edit) |
| Dispatch | 硬编码 bash 调用 | TOOL_HANDLERS 字典 |
| 路径安全 | 无 | safe_path() 沙箱 |
| Agent loop | 不变 | 不变 |
规划与协调
TodoWrite
正常的解决问题的思路是逐项完成任务清单
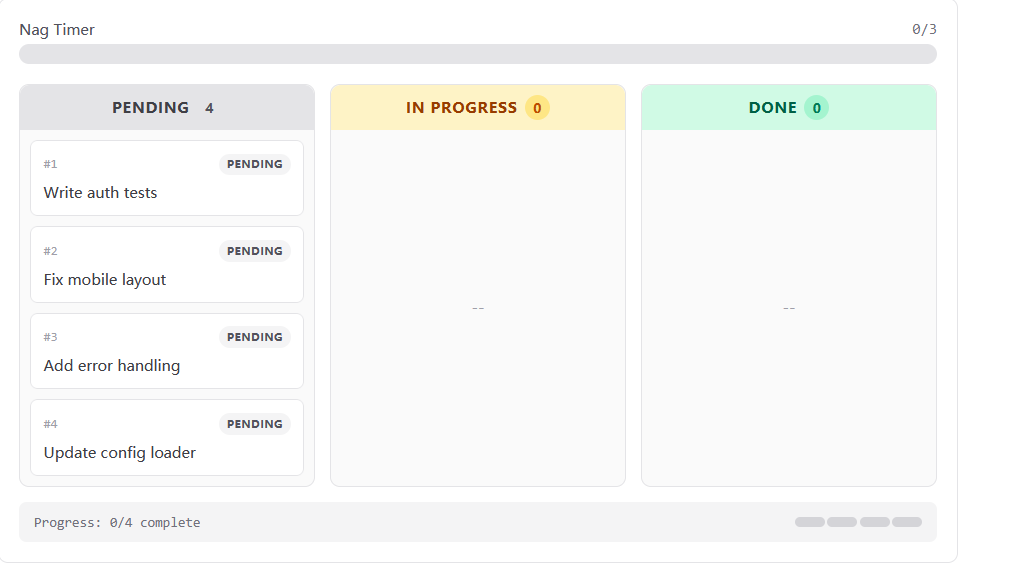
问题
多步任务中, 模型会丢失进度 -- 重复做过的事、跳步、跑偏。对话越长越严重: 工具结果不断填满上下文, 系统提示的影响力逐渐被稀释。一个 10 步重构可能做完 1-3 步就开始即兴发挥, 因为 4-10 步已经被挤出注意力了。
解决方案
不要只靠模型自己"记住自己做到哪一步了",而是额外加一个外部的任务状态管理器(TodoManager),持续提醒模型当前正在做哪一步。
+--------+ +-------+ +---------+
| User | ---> | LLM | ---> | Tools |
| prompt | | | | + todo |
+--------+ +---+---+ +----+----+
^ |
| tool_result |
+----------------+
|
+-----------+-----------+
| TodoManager state |
| [ ] task A |
| [>] task B <- doing |
| [x] task C |
+-----------------------+
|
if rounds_since_todo >= 3:
inject <reminder> into tool_result
(如果agent超过三轮没有关注todo,就加到工具结果 中以提醒)工作原理
- TodoManager 存储带状态的项目。同一时间只允许一个
in_progress。
get函数的第二个参数:默认值
python
class TodoManager:
def update(self, items: list) -> str:
validated, in_progress_count = [], 0
for item in items:
status = item.get("status", "pending")
if status == "in_progress":
in_progress_count += 1
validated.append({"id": item["id"], "text": item["text"],
"status": status})
if in_progress_count > 1:
raise ValueError("Only one task can be in_progress")
self.items = validated
return self.render()todo工具和其他工具一样加入 dispatch map。
python
TOOL_HANDLERS = {
# ...base tools...
"todo": lambda **kw: TODO.update(kw["items"]),
}- nag reminder: 模型连续 3 轮以上不调用
todo时注入提醒。
python
if rounds_since_todo >= 3 and messages:
last = messages[-1]
if last["role"] == "user" and isinstance(last.get("content"), list):
last["content"].insert(0, {
"type": "text",
"text": "<reminder>Update your todos.</reminder>",
})"同时只能有一个 in_progress" 强制顺序聚焦。nag reminder 制造问责压力 -- 你不更新计划, 系统就追着你问。
子agent
智能体工作越久, messages 数组越胖。每次读文件、跑命令的输出都永久留在上下文里。
解决方案
子agent需要和主agent做上下文隔离。
把一个大任务拆给"子代理(subagent)"单独处理,子代理用全新的上下文去跑,跑完后只把精简结果或摘要返回给父代理(parent agent)。
Parent agent Subagent
+------------------+ +------------------+
| messages=[...] | | messages=[] | <-- fresh
| | dispatch | |
| tool: task | ----------> | while tool_use: |
| prompt="..." | | call tools |
| | summary | append results |
| result = "..." | <---------- | return last text |
+------------------+ +------------------+
Parent context stays clean. Subagent context is discarded.工作原理
- 父智能体有一个
task工具。子智能体拥有除task外的所有基础工具 (禁止递归生成)。
这个 task 工具不是去读文件或跑命令,而是:
"新开一个子智能体,让它用全新上下文去完成某个子任务。"
python
PARENT_TOOLS = CHILD_TOOLS + [
{"name": "task",
"description": "Spawn a subagent with fresh context.",
"input_schema": {
"type": "object",
"properties": {"prompt": {"type": "string"}},
"required": ["prompt"],
}},
]- 子智能体以
messages=[]启动, 运行自己的循环。只有最终文本返回给父智能体。
python
def run_subagent(prompt: str) -> str:
sub_messages = [{"role": "user", "content": prompt}]
for _ in range(30): # safety limit
response = client.messages.create(
model=MODEL, system=SUBAGENT_SYSTEM,
messages=sub_messages,
tools=CHILD_TOOLS, max_tokens=8000,
)
sub_messages.append({"role": "assistant",
"content": response.content})
if response.stop_reason != "tool_use":
break
results = []
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input)
results.append({"type": "tool_result",
"tool_use_id": block.id,
"content": str(output)[:50000]})
sub_messages.append({"role": "user", "content": results})
return "".join(
b.text for b in response.content if hasattr(b, "text")
) or "(no summary)"子智能体可能跑了 30+ 次工具调用, 但整个消息历史直接丢弃。父智能体收到的只是一段摘要文本, 作为普通 tool_result 返回。
skill
skill.md里详细描述一个技能的步骤
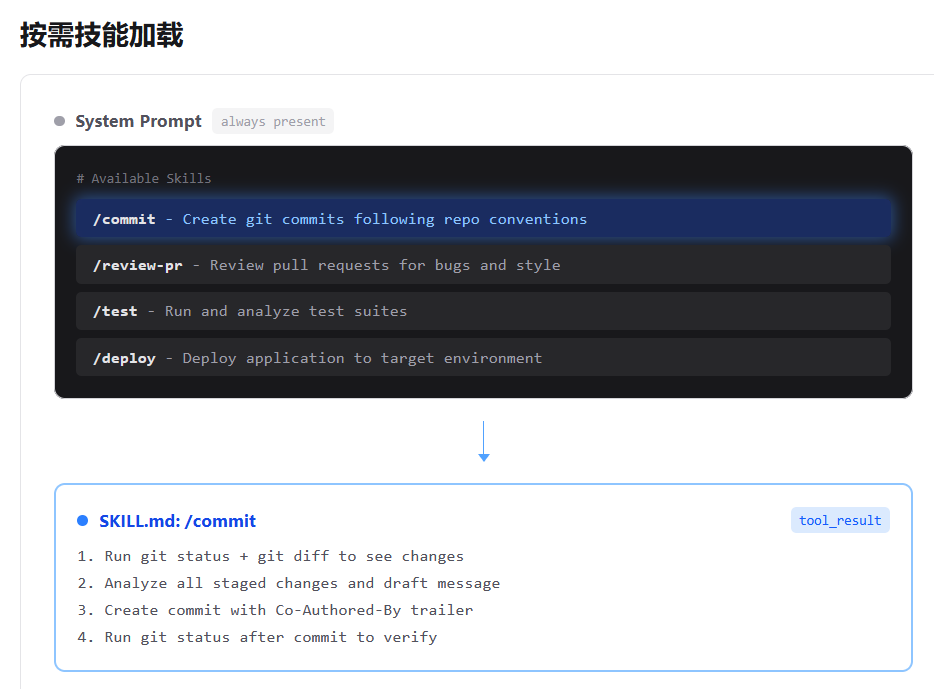
存在的意义:你希望智能体遵循特定领域的工作流: git 约定、测试模式、代码审查清单。全塞进系统提示太浪费 -- 10 个技能, 每个 2000 token(输入token), 就是 20,000 token, 大部分跟当前任务毫无关系。
解决方案
核心思想是:
不要把所有能力说明一开始全塞进 system prompt,而是只放一个很薄的总说明;当模型真的需要某项技能时,再通过工具把那项技能的详细说明动态注入进去。
System prompt (Layer 1 -- always present):
+--------------------------------------+
| You are a coding agent. |
| Skills available: |
| - git: Git workflow helpers | ~100 tokens/skill
| - test: Testing best practices |
+--------------------------------------+
When model calls load_skill("git"):
+--------------------------------------+
| tool_result (Layer 2 -- on demand): |
| <skill name="git"> |
| Full git workflow instructions... | ~2000 tokens
| Step 1: ... |
| </skill> |
+--------------------------------------+工作原理
每个技能都被封装成一个带 YAML frontmatter 的 SKILL.md 文件;SkillLoader 会递归扫描这些文件,读取 frontmatter 中的 name 和 description 作为技能元数据,把简短描述放到 system prompt 作为第一层目录,再通过 load_skill(name) 工具按需把技能正文作为第二层内容动态注入上下文。
-
每个技能是一个目录, 包含
SKILL.md文件和 YAML frontmatter(markdown文件前面的一段简短的描述,可以理解为技能的简单总结,包括技能名和功能,而md文件里则包含详细的技能流程)。skills/
pdf/
SKILL.md # ---\n name: pdf\n description: Process PDF files\n ---\n ...
code-review/
SKILL.md # ---\n name: code-review\n description: Review code\n ---\n ... -
SkillLoader 递归扫描
SKILL.md文件, 用目录名作为技能标识。
python
class SkillLoader:
def __init__(self, skills_dir: Path):
self.skills = {}
for f in sorted(skills_dir.rglob("SKILL.md")):
text = f.read_text()
meta, body = self._parse_frontmatter(text)
name = meta.get("name", f.parent.name)
self.skills[name] = {"meta": meta, "body": body}
def get_descriptions(self) -> str:
lines = []
for name, skill in self.skills.items():
desc = skill["meta"].get("description", "")
lines.append(f" - {name}: {desc}")
return "\n".join(lines)
def get_content(self, name: str) -> str:
skill = self.skills.get(name)
if not skill:
return f"Error: Unknown skill '{name}'."
return f"<skill name=\"{name}\">\n{skill['body']}\n</skill>"- 第一层写入系统提示。第二层不过是 dispatch map 中的又一个工具。
python
SYSTEM = f"""You are a coding agent at {WORKDIR}.
Skills available:
{SKILL_LOADER.get_descriptions()}"""
TOOL_HANDLERS = {
# ...base tools...
"load_skill": lambda **kw: SKILL_LOADER.get_content(kw["name"]),
}任务系统
s03 的 TodoManager 只是内存中的扁平清单: 没有顺序、没有依赖、状态只有做完没做完。真实目标是有结构的 -- 任务 B 依赖任务 A, 任务 C 和 D 可以并行, 任务 E 要等 C 和 D 都完成。
没有显式的关系, 智能体分不清什么能做、什么被卡住、什么能同时跑。而且清单只活在内存里, 上下文压缩 (s06) 一跑就没了。
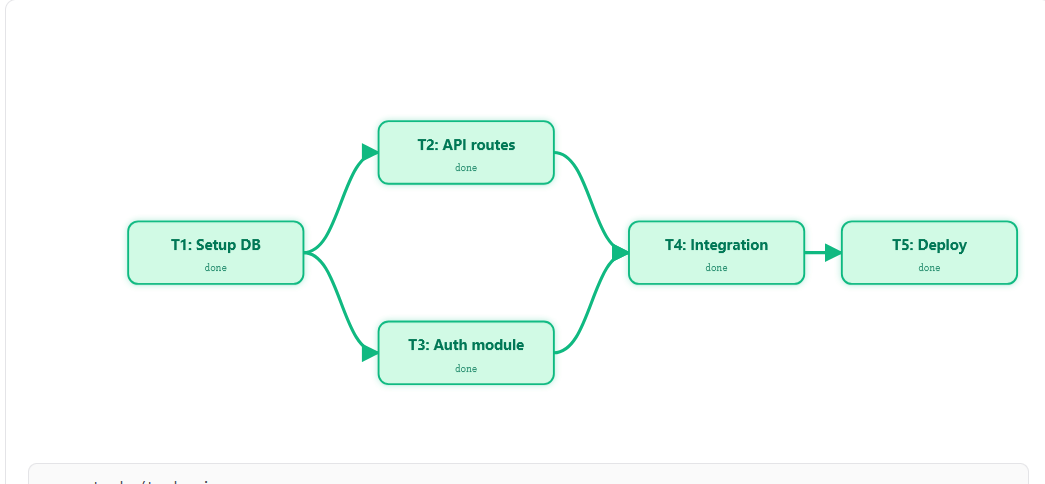
解决方案
把扁平清单升级为持久化到磁盘的任务图 。每个任务是一个 JSON 文件, 有状态、前置依赖 (blockedBy) 和后置依赖 (blocks)。任务图随时回答三个问题:
-
什么可以做? -- 状态为
pending且blockedBy为空的任务。 -
什么被卡住? -- 等待前置任务完成的任务。
-
什么做完了? -- 状态为
completed的任务, 完成时自动解锁后续任务。.tasks/
task_1.json {"id":1, "status":"completed"}
task_2.json {"id":2, "blockedBy":[1], "status":"pending"}
task_3.json {"id":3, "blockedBy":[1], "status":"pending"}
task_4.json {"id":4, "blockedBy":[2,3], "status":"pending"}任务图 (DAG):
+----------+
+--> | task 2 | --+
| | pending | |
+----------+ +----------+ +--> +----------+
| task 1 | | task 4 |
| completed| --> +----------+ +--> | blocked |
+----------+ | task 3 | --+ +----------+
| pending |
+----------+顺序: task 1 必须先完成, 才能开始 2 和 3
并行: task 2 和 3 可以同时执行
依赖: task 4 要等 2 和 3 都完成
状态: pending -> in_progress -> completed
工作原理
- TaskManager: 每个任务一个 JSON 文件, CRUD(创读更删) + 依赖图。
python
class TaskManager:
def __init__(self, tasks_dir: Path):
self.dir = tasks_dir
self.dir.mkdir(exist_ok=True)
创建任务管理的目录
self._next_id = self._max_id() + 1
计算下一个可用任务 ID。
def create(self, subject, description=""):
创建一个任务对象
task = {"id": self._next_id, "subject": subject,
"status": "pending", "blockedBy": [],
"blocks": [], "owner": ""}
self._save(task)
存到磁盘
self._next_id += 1
return json.dumps(task, indent=2)- 依赖解除 : 完成任务时, 自动将其 ID 从其他任务的
blockedBy中移除, 解锁后续任务。
python
def _clear_dependency(self, completed_id):
for f in self.dir.glob("task_*.json"):
task = json.loads(f.read_text())
if completed_id in task.get("blockedBy", []):
task["blockedBy"].remove(completed_id)
self._save(task)- 状态变更 + 依赖关联 :
update更新任务,比如改状态、减依赖。
python
def update(self, task_id, status=None,
add_blocked_by=None, add_blocks=None):
task = self._load(task_id)
if status:
task["status"] = status
if status == "completed":
self._clear_dependency(task_id)
self._save(task)- 四个任务工具加入 dispatch map。
python
TOOL_HANDLERS = {
# ...base tools...
"task_create": lambda **kw: TASKS.create(kw["subject"]),
"task_update": lambda **kw: TASKS.update(kw["task_id"], kw.get("status")),
"task_list": lambda **kw: TASKS.list_all(),
"task_get": lambda **kw: TASKS.get(kw["task_id"]),
}从 s07 起, 任务图是多步工作的默认选择。s03 的 Todo 仍可用于单次会话内的快速清单。
内存管理
上下文压缩
上下文窗口是有限的。读一个 1000 行的文件就吃掉 ~4000 token; 读 30 个文件、跑 20 条命令, 轻松突破 100k token。不压缩, 智能体根本没法在大项目里干活。
Every turn:
+------------------+
| Tool call result |
+------------------+
|
v
[Layer 1: micro_compact] (silent, every turn)
Replace tool_result > 3 turns old
with "[Previous: used {tool_name}]"
|
v
[Check: tokens > 50000?]
| |
no yes
| |
v v
continue [Layer 2: auto_compact]
Save transcript to .transcripts/
LLM summarizes conversation.
Replace all messages with [summary].
|
v
[Layer 3: compact tool]
Model calls compact explicitly.工作原理
第一层 -- micro_compact: 每次 LLM 调用前, 将旧的 tool result 替换为占位符。相当于把之前调用工具的所有上下文替换为:调用过XX工具。放到agent_loop里是默认保存最近三轮对话
python
def micro_compact(messages: list) -> list:
tool_results = []
for i, msg in enumerate(messages):
if msg["role"] == "user" and isinstance(msg.get("content"), list):
for j, part in enumerate(msg["content"]):
if isinstance(part, dict) and part.get("type") == "tool_result":
tool_results.append((i, j, part))
if len(tool_results) <= KEEP_RECENT:
return messages
for _, _, part in tool_results[:-KEEP_RECENT]:
if len(part.get("content", "")) > 100:
part["content"] = f"[Previous: used {tool_name}]"
return messages第二层 -- auto_compact: token 超过阈值时, 保存完整对话到磁盘, 让 LLM 做摘要。
python
def auto_compact(messages: list) -> list:
# Save transcript for recovery
transcript_path = TRANSCRIPT_DIR / f"transcript_{int(time.time())}.jsonl"
with open(transcript_path, "w") as f:
for msg in messages:
f.write(json.dumps(msg, default=str) + "\n")
# LLM summarizes
response = client.messages.create(
model=MODEL,
messages=[{"role": "user", "content":
"Summarize this conversation for continuity..."
+ json.dumps(messages, default=str)[:80000]}],
max_tokens=2000,
)
return [
{"role": "user", "content": f"[Compressed]\n\n{response.content[0].text}"},
{"role": "assistant", "content": "Understood. Continuing."},
]第三层 -- manual compact : compact 工具按需触发同样的摘要机制。其实第三层跟第二层调用的函数是一样的。第三层存在的意义就是模型自己觉得需要整理一下了,就调用函数
循环整合三层:
python
def agent_loop(messages: list):
while True:
micro_compact(messages) # Layer 1
if estimate_tokens(messages) > THRESHOLD:
messages[:] = auto_compact(messages) # Layer 2
response = client.messages.create(...)
# ... tool execution ...
if manual_compact:
messages[:] = auto_compact(messages) # Layer 3完整历史通过 transcript 保存在磁盘上。信息没有真正丢失, 只是移出了活跃上下文。
并发
后台任务
有些命令要跑好几分钟: npm install、pytest、docker build。阻塞式循环下模型只能干等。用户说 "装依赖, 顺便建个配置文件", 智能体却只能一个一个来。
解决方案
核心目标是:
不要让一次很慢的 bash/subprocess 阻塞整个 agent loop。
可以用一句话概括:
主线程继续和 LLM 交互;耗时命令丢到后台线程里跑;后台跑完后,把结果塞进一个通知队列,等下一次 LLM 调用前再喂给模型。
Main thread Background thread
+-----------------+ +-----------------+
| agent loop | | subprocess runs |
| ... | | ... |
| [LLM call] <---+------- | enqueue(result) |
| ^drain queue | +-----------------+
+-----------------+
Timeline:
Agent --[spawn A]--[spawn B]--[other work]----
| |
v v
[A runs] [B runs] (parallel)
| |
+-- results injected before next LLM call --+工作原理
- BackgroundManager 用线程安全的通知队列追踪任务。
python
class BackgroundManager:
def __init__(self):
self.tasks = {}
self._notification_queue = []
这是通知队列。后台线程跑完后,不直接操作 messages,而是把结果先塞进这里。
self._lock = threading.Lock()
线程锁。
因为:主线程可能在取通知,后台线程可能在塞通知
这两个动作会并发发生,所以要加锁,避免数据结构被同时改坏。run()启动守护线程, 立即返回。
python
def run(self, command: str) -> str:
task_id = str(uuid.uuid4())[:8]
self.tasks[task_id] = {"status": "running", "command": command}
thread = threading.Thread(
target=self._execute, args=(task_id, command), daemon=True)
thread.start()
return f"Background task {task_id} started"- 子进程完成后, 结果进入通知队列。
python
def _execute(self, task_id, command):
try:
r = subprocess.run(command, shell=True, cwd=WORKDIR,
capture_output=True, text=True, timeout=300)
output = (r.stdout + r.stderr).strip()[:50000]
except subprocess.TimeoutExpired:
output = "Error: Timeout (300s)"
with self._lock:
加锁,避免线程混乱
self._notification_queue.append({
"task_id": task_id, "result": output[:500]})- 每次 LLM 调用前排空通知队列。
python
def agent_loop(messages: list):
while True:
notifs = BG.drain_notifications()
if notifs:
notif_text = "\n".join(
f"[bg:{n['task_id']}] {n['result']}" for n in notifs)
messages.append({"role": "user",
"content": f"<background-results>\n{notif_text}\n"
f"</background-results>"})
messages.append({"role": "assistant",
"content": "Noted background results."})
response = client.messages.create(...)循环保持单线程。只有子进程 I/O 被并行化。
协作
agent团队
子智能体 是一次性的: 生成、干活、返回摘要、消亡。没有身份, 没有跨调用的记忆。后台任务 能跑 shell 命令, 但做不了 LLM 引导的决策。
真正的团队协作需要三样东西: (1) 能跨多轮对话存活的持久智能体, (2) 身份和生命周期管理, (3) 智能体之间的通信通道。
解决方案
核心思想是:
不要让多个 agent 直接共享同一段上下文,而是给每个队友一个独立 loop,再用磁盘上的"团队配置 + 收件箱"互相传消息。
你可以把它理解成:
-
config.json是团队花名册 -
inbox/*.jsonl是每个人的邮箱 -
每个队友都是一个独立线程里的 agent
-
发消息就是往对方邮箱里追加一行 JSON
-
收消息就是把自己邮箱全部读出来,然后清空
Teammate lifecycle:
spawn -> WORKING -> IDLE -> WORKING -> ... -> SHUTDOWNCommunication:
.team/
config.json <- team roster + statuses
inbox/
alice.jsonl <- append-only, drain-on-read
bob.jsonl
lead.jsonl+--------+ send("alice","bob","...") +--------+ | alice | -----------------------------> | bob | | loop | bob.jsonl << {json_line} | loop | +--------+ +--------+ ^ | | BUS.read_inbox("alice") | +---- alice.jsonl -> read + drain ---------+ 这里的通信是异步邮箱式,不是同步函数调用
工作原理
TeammateManager 通过 config.json 维护团队名册。
这个类就是"团队管理器"。
它负责:
- 初始化团队目录
- 读取/保存
config.json - 管理每个队友对应的线程
self.threads = {}
这里通常是拿来存:
alice对应哪个线程bob对应哪个线程
便于后续查看或管理。
python
class TeammateManager:
def __init__(self, team_dir: Path):
self.dir = team_dir
self.dir.mkdir(exist_ok=True)
self.config_path = self.dir / "config.json"
self.config = self._load_config()
self.threads = {}spawn() 创建队友并在线程中启动 agent loop。
python
def spawn(self, name: str, role: str, prompt: str) -> str:
member = {"name": name, "role": role, "status": "working"}
self.config["members"].append(member)
self._save_config()
thread = threading.Thread(
target=self._teammate_loop,
args=(name, role, prompt), daemon=True)
thread.start()
return f"Spawned teammate '{name}' (role: {role})"MessageBus: append-only 的 JSONL 收件箱。send() 追加一行; read_inbox() 读取全部并清空。
python
class MessageBus:
def send(self, sender, to, content, msg_type="message", extra=None):
msg = {"type": msg_type, "from": sender,
"content": content, "timestamp": time.time()}
if extra:
msg.update(extra)
with open(self.dir / f"{to}.jsonl", "a") as f:
f.write(json.dumps(msg) + "\n")
def read_inbox(self, name):
path = self.dir / f"{name}.jsonl"
if not path.exists(): return "[]"
msgs = [json.loads(l) for l in path.read_text().strip().splitlines() if l]
path.write_text("") # drain
return json.dumps(msgs, indent=2)每个队友在每次 LLM 调用前检查收件箱, 将消息注入上下文。
python
def _teammate_loop(self, name, role, prompt):
messages = [{"role": "user", "content": prompt}]
for _ in range(50):
inbox = BUS.read_inbox(name)
if inbox != "[]":
messages.append({"role": "user",
"content": f"<inbox>{inbox}</inbox>"})
messages.append({"role": "assistant",
"content": "Noted inbox messages."})
response = client.messages.create(...)
if response.stop_reason != "tool_use":
break
# execute tools, append results...
self._find_member(name)["status"] = "idle"团队协议
队友能干活能通信, 但缺少结构化协调:
关机: 直接杀线程会留下写了一半的文件和过期的 config.json。需要握手 -- 领导请求, 队友批准 (收尾退出) 或拒绝 (继续干)。
计划审批: 领导说 "重构认证模块", 队友立刻开干。高风险变更应该先过审。
两者结构一样: 一方发带唯一 ID 的请求, 另一方引用同一 ID 响应。
解决方案
核心思想是:
- 不管是"请求队友关机"
- 还是"队友提交计划等领导审批"
都统一成一种模式:
- 发起方生成一个
request_id - 接收方收到后作出 approve / reject
- 系统用这个
request_id跟踪请求状态 - 状态只能从
pending走到approved或rejected
这就是图里说的:
Shutdown Protocol Plan Approval Protocol
================== ======================
Lead Teammate Teammate Lead
| | | |
|--shutdown_req-->| |--plan_req------>|
| {req_id:"abc"} | | {req_id:"xyz"} |
| | | |
|<--shutdown_resp-| |<--plan_resp-----|
| {req_id:"abc", | | {req_id:"xyz", |
| approve:true} | | approve:true} |
Shared FSM:
[pending] --approve--> [approved]
[pending] --reject---> [rejected]
Trackers:
shutdown_requests = {req_id: {target, status}}
plan_requests = {req_id: {from, plan, status}}FSM 是 Finite State Machine,有限状态机。
这里很简单,就是一个请求只能处于这几种状态之一:
pending:等待处理approved:已批准rejected:已拒绝
工作原理
领导生成 request_id, 通过收件箱发起关机请求。
python
shutdown_requests = {}
def handle_shutdown_request(teammate: str) -> str:
req_id = str(uuid.uuid4())[:8]
shutdown_requests[req_id] = {"target": teammate, "status": "pending"}
BUS.send("lead", teammate, "Please shut down gracefully.",
"shutdown_request", {"request_id": req_id})
return f"Shutdown request {req_id} sent (status: pending)"队友收到请求后, 用 approve/reject 响应。
python
if tool_name == "shutdown_response":
req_id = args["request_id"]
approve = args["approve"]
shutdown_requests[req_id]["status"] = "approved" if approve else "rejected"
BUS.send(sender, "lead", args.get("reason", ""),
"shutdown_response",
{"request_id": req_id, "approve": approve})计划审批遵循完全相同的模式。队友提交计划 (生成 request_id), 领导审查 (引用同一个 request_id)。
python
plan_requests = {}
def handle_plan_review(request_id, approve, feedback=""):
req = plan_requests[request_id]
req["status"] = "approved" if approve else "rejected"
BUS.send("lead", req["from"], feedback,
"plan_approval_response",
{"request_id": request_id, "approve": approve})一个 FSM, 两种用途。同样的 pending -> approved | rejected 状态机可以套用到任何请求-响应协议上。
自主agent
之前队友只在被明确指派时才动。领导得给每个队友写 prompt, 任务看板上 10 个未认领的任务得手动分配。这扩展不了。
真正的自治: 队友自己扫描任务看板, 认领没人做的任务, 做完再找下一个。
一个细节: 上下文压缩 (s06) 后智能体可能忘了自己是谁。身份重注入解决这个问题。
解决方案
Teammate lifecycle with idle cycle:
+-------+
| spawn |
+---+---+
|
v
+-------+ tool_use +-------+
| WORK | <------------- | LLM |
+---+---+ +-------+
|
| stop_reason != tool_use (or idle tool called)
v
+--------+
| IDLE | poll every 5s for up to 60s
+---+----+
|
+---> check inbox --> message? ----------> WORK
|
+---> scan .tasks/ --> unclaimed? -------> claim -> WORK
|
+---> 60s timeout ----------------------> SHUTDOWN
Identity re-injection after compression:
if len(messages) <= 3:
messages.insert(0, identity_block)工作原理
- 队友循环分两个阶段: WORK 和 IDLE。LLM 停止调用工具 (或调用了
idle) 时, 进入 IDLE。
python
def _loop(self, name, role, prompt):
while True:
# -- WORK PHASE --
messages = [{"role": "user", "content": prompt}]
for _ in range(50):
response = client.messages.create(...)
if response.stop_reason != "tool_use":
break
# execute tools...
if idle_requested:
break
# -- IDLE PHASE --
self._set_status(name, "idle")
resume = self._idle_poll(name, messages)
if not resume:
self._set_status(name, "shutdown")
return
self._set_status(name, "working")- 空闲阶段循环轮询收件箱和任务看板。
python
def _idle_poll(self, name, messages):
for _ in range(IDLE_TIMEOUT // POLL_INTERVAL): # 60s / 5s = 12
time.sleep(POLL_INTERVAL)
inbox = BUS.read_inbox(name)
if inbox:
messages.append({"role": "user",
"content": f"<inbox>{inbox}</inbox>"})
return True
unclaimed = scan_unclaimed_tasks()
if unclaimed:
claim_task(unclaimed[0]["id"], name)
messages.append({"role": "user",
"content": f"<auto-claimed>Task #{unclaimed[0]['id']}: "
f"{unclaimed[0]['subject']}</auto-claimed>"})
return True
return False # timeout -> shutdown- 任务看板扫描: 找 pending 状态、无 owner、未被阻塞的任务。
python
def scan_unclaimed_tasks() -> list:
unclaimed = []
for f in sorted(TASKS_DIR.glob("task_*.json")):
task = json.loads(f.read_text())
if (task.get("status") == "pending"
and not task.get("owner")
and not task.get("blockedBy")):
unclaimed.append(task)
return unclaimed- 身份重注入: 上下文过短 (说明发生了压缩) 时, 在开头插入身份块。
python
if len(messages) <= 3:
messages.insert(0, {"role": "user",
"content": f"<identity>You are '{name}', role: {role}, "
f"team: {team_name}. Continue your work.</identity>"})
messages.insert(1, {"role": "assistant",
"content": f"I am {name}. Continuing."})worktree+工作隔离
到 s11, 智能体已经能自主认领和完成任务。但所有任务共享一个目录。两个智能体同时重构不同模块 -- A 改 config.py, B 也改 config.py, 未提交的改动互相污染, 谁也没法干净回滚。
任务板管 "做什么" 但不管 "在哪做"。解法: 给每个任务一个独立的 git worktree 目录, 用任务 ID 把两边关联起来。
解决方案
Control plane (.tasks/) Execution plane (.worktrees/)
+------------------+ +------------------------+
| task_1.json | | auth-refactor/ |
| status: in_progress <------> branch: wt/auth-refactor
| worktree: "auth-refactor" | task_id: 1 |
+------------------+ +------------------------+
| task_2.json | | ui-login/ |
| status: pending <------> branch: wt/ui-login
| worktree: "ui-login" | task_id: 2 |
+------------------+ +------------------------+
|
index.json (worktree registry)
events.jsonl (lifecycle log)
State machines:
Task: pending -> in_progress -> completed
Worktree: absent -> active -> removed | kept工作原理
创建任务。 先把目标持久化。
python
TASKS.create("Implement auth refactor")
# -> .tasks/task_1.json status=pending worktree=""创建 worktree 并绑定任务。 传入 task_id 自动将任务推进到 in_progress。
python
WORKTREES.create("auth-refactor", task_id=1)
# -> git worktree add -b wt/auth-refactor .worktrees/auth-refactor HEAD
# -> index.json gets new entry, task_1.json gets worktree="auth-refactor"绑定同时写入两侧状态:
python
def bind_worktree(self, task_id, worktree):
task = self._load(task_id)
task["worktree"] = worktree
if task["status"] == "pending":
task["status"] = "in_progress"
self._save(task)在 worktree 中执行命令。 cwd 指向隔离目录。
python
subprocess.run(command, shell=True, cwd=worktree_path,
capture_output=True, text=True, timeout=300)-
收尾。
两种选择:
worktree_keep(name)-- 保留目录供后续使用。worktree_remove(name, complete_task=True)-- 删除目录, 完成绑定任务, 发出事件。一个调用搞定拆除 + 完成。
python
def remove(self, name, force=False, complete_task=False):
self._run_git(["worktree", "remove", wt["path"]])
if complete_task and wt.get("task_id") is not None:
self.tasks.update(wt["task_id"], status="completed")
self.tasks.unbind_worktree(wt["task_id"])
self.events.emit("task.completed", ...)事件流。 每个生命周期步骤写入 .worktrees/events.jsonl:
json
{
"event": "worktree.remove.after",
"task": {"id": 1, "status": "completed"},
"worktree": {"name": "auth-refactor", "status": "removed"},
"ts": 1730000000
}事件类型: worktree.create.before/after/failed, worktree.remove.before/after/failed, worktree.keep, task.completed。
崩溃后从 .tasks/ + .worktrees/index.json 重建现场。会话记忆是易失的; 磁盘状态是持久的。