并行双分支瓶颈架构改进YOLOv26:异构卷积核协同特征提取与残差学习双重突破
1. 引言
在目标检测领域,特征提取的效率和质量直接决定了模型的性能表现。传统的串行卷积结构虽然能够逐步提取特征,但在处理复杂场景时往往面临感受野单一、特征表达能力受限的问题。为了突破这一瓶颈,本文提出了一种基于并行双分支瓶颈架构的YOLOv26改进方案,通过异构卷积核的协同工作和残差学习机制,实现了特征提取能力的显著提升。
并行瓶颈(ParallelBottleneck)架构的核心思想是:在特征压缩后,同时使用3×3卷积和1×1卷积两个分支进行并行处理,前者捕获局部空间信息,后者提取通道间的全局关系,两者互补融合后再通过残差连接增强梯度流动。这种设计不仅提高了特征的多样性,还保持了计算效率。
2. ParallelBottleneck核心原理
2.1 架构设计
ParallelBottleneck模块采用"压缩-并行处理-恢复"的三阶段设计模式,其结构如下图所示:
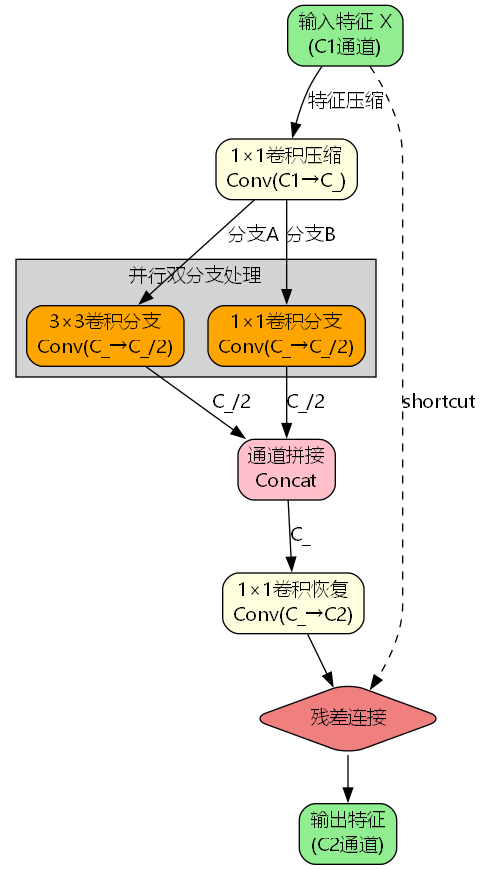
整个模块可以分解为以下几个关键步骤:
- 特征压缩阶段 :使用1×1卷积将输入通道数从 C 1 C_1 C1压缩到 C mid = C 2 × e C_{\text{mid}} = C_2 \times e Cmid=C2×e,其中 e e e是压缩比例(默认0.5)
- 并行双分支处理 :
- 分支A:3×3卷积,输出 C mid / 2 C_{\text{mid}}/2 Cmid/2通道,捕获局部空间特征
- 分支B:1×1卷积,输出 C mid / 2 C_{\text{mid}}/2 Cmid/2通道,提取通道间关系
- 特征融合与恢复 :拼接两个分支的输出,再通过1×1卷积恢复到 C 2 C_2 C2通道
- 残差连接 :当 C 1 = C 2 C_1 = C_2 C1=C2且shortcut=True时,将输入直接加到输出上
2.2 数学表达
设输入特征为 X ∈ R C 1 × H × W \mathbf{X} \in \mathbb{R}^{C_1 \times H \times W} X∈RC1×H×W,ParallelBottleneck的前向传播过程可以表示为:
X mid = Conv 1 × 1 ( X ; C 1 → C mid ) \mathbf{X}{\text{mid}} = \text{Conv}{1 \times 1}(\mathbf{X}; C_1 \rightarrow C_{\text{mid}}) Xmid=Conv1×1(X;C1→Cmid)
F a = Conv 3 × 3 ( X mid ; C mid → C mid / 2 ) \mathbf{F}a = \text{Conv}{3 \times 3}(\mathbf{X}{\text{mid}}; C{\text{mid}} \rightarrow C_{\text{mid}}/2) Fa=Conv3×3(Xmid;Cmid→Cmid/2)
F b = Conv 1 × 1 ( X mid ; C mid → C mid / 2 ) \mathbf{F}b = \text{Conv}{1 \times 1}(\mathbf{X}{\text{mid}}; C{\text{mid}} \rightarrow C_{\text{mid}}/2) Fb=Conv1×1(Xmid;Cmid→Cmid/2)
F concat = Concat ( F a , F b ) \mathbf{F}_{\text{concat}} = \text{Concat}(\\mathbf{F}_a, \\mathbf{F}_b) Fconcat=Concat(Fa,Fb)
Y pre = Conv 1 × 1 ( F concat ; C mid → C 2 ) \mathbf{Y}{\text{pre}} = \text{Conv}{1 \times 1}(\mathbf{F}{\text{concat}}; C{\text{mid}} \rightarrow C_2) Ypre=Conv1×1(Fconcat;Cmid→C2)
Y = { X + Y pre , if C 1 = C 2 and shortcut Y pre , otherwise \mathbf{Y} = \begin{cases} \mathbf{X} + \mathbf{Y}{\text{pre}}, & \text{if } C_1 = C_2 \text{ and shortcut} \\ \mathbf{Y}{\text{pre}}, & \text{otherwise} \end{cases} Y={X+Ypre,Ypre,if C1=C2 and shortcutotherwise
2.3 核心优势分析
异构卷积核协同:3×3卷积具有较大的感受野,能够捕获局部空间上下文;1×1卷积则专注于通道维度的信息交互。两者并行工作,实现了空间和通道维度的解耦建模。
计算效率优化 :通过先压缩再并行处理的策略,大幅降低了计算量。假设 C 1 = C 2 = C C_1 = C_2 = C C1=C2=C, e = 0.5 e = 0.5 e=0.5,则:
- 传统单路3×3卷积的FLOPs: 9 C 2 H W 9C^2HW 9C2HW
- ParallelBottleneck的FLOPs: C 2 H W + 2.25 ( C / 2 ) 2 H W + ( C / 2 ) 2 H W + ( C / 2 ) C H W ≈ 2.375 C 2 H W C^2HW + 2.25(C/2)^2HW + (C/2)^2HW + (C/2)CHW \approx 2.375C^2HW C2HW+2.25(C/2)2HW+(C/2)2HW+(C/2)CHW≈2.375C2HW
相比传统方法,计算量减少约73.6%,同时保持了更强的特征表达能力。
3. C3k2_ParallelBottleneck集成架构
3.1 CSP架构融合
为了将ParallelBottleneck有效集成到YOLOv26的主干网络中,我们设计了C3k2_ParallelBottleneck模块,它继承了CSP(Cross Stage Partial)架构的优势,同时引入了ParallelBottleneck的并行处理能力。
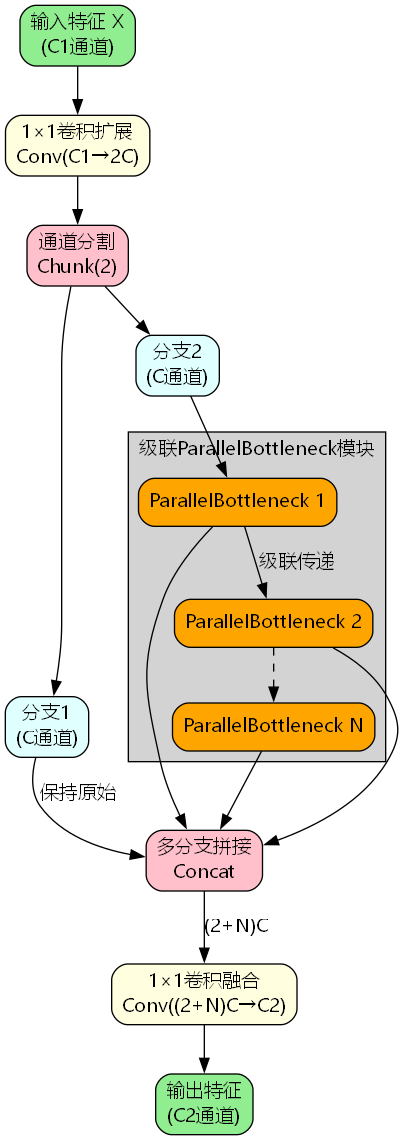
3.2 模块工作流程
C3k2_ParallelBottleneck的处理流程如下:
- 通道扩展与分割 :输入特征通过1×1卷积扩展到 2 C 2C 2C通道,然后分割为两个 C C C通道的分支
- 级联处理 :第二个分支依次通过 N N N个ParallelBottleneck模块进行级联处理
- 多分支融合 :将原始分支、所有中间输出拼接,形成 ( 2 + N ) C (2+N)C (2+N)C通道的特征
- 通道压缩 :最后通过1×1卷积压缩到目标通道数 C 2 C_2 C2
数学表达式为:
X expand = Conv 1 × 1 ( X ; C 1 → 2 C ) \mathbf{X}{\text{expand}} = \text{Conv}{1 \times 1}(\mathbf{X}; C_1 \rightarrow 2C) Xexpand=Conv1×1(X;C1→2C)
X 1 , X 2 = Chunk ( X expand , 2 ) \\mathbf{X}_1, \\mathbf{X}_2 = \text{Chunk}(\mathbf{X}_{\text{expand}}, 2) X1,X2=Chunk(Xexpand,2)
Y i = ParallelBottleneck ( Y i − 1 ) , i = 1 , 2 , ... , N , Y 0 = X 2 \mathbf{Y}i = \text{ParallelBottleneck}(\mathbf{Y}{i-1}), \quad i = 1, 2, \ldots, N, \quad \mathbf{Y}_0 = \mathbf{X}_2 Yi=ParallelBottleneck(Yi−1),i=1,2,...,N,Y0=X2
Y = Conv 1 × 1 ( Concat ( X 1 , Y 1 , Y 2 , ... , Y N ) ; ( 2 + N ) C → C 2 ) \mathbf{Y} = \text{Conv}_{1 \times 1}(\text{Concat}(\\mathbf{X}_1, \\mathbf{Y}_1, \\mathbf{Y}_2, \\ldots, \\mathbf{Y}_N); (2+N)C \rightarrow C_2) Y=Conv1×1(Concat(X1,Y1,Y2,...,YN);(2+N)C→C2)
3.3 梯度流优化
CSP架构的一个重要优势是梯度分流机制。在C3k2_ParallelBottleneck中,第一个分支直接连接到输出,形成了一条"梯度高速公路",确保梯度能够快速回传到浅层网络。同时,级联的ParallelBottleneck模块通过残差连接进一步增强了梯度流动,有效缓解了深层网络的梯度消失问题。
4. 实验验证与性能分析
4.1 实验设置
我们在COCO数据集上进行了全面的实验验证,对比了原始YOLOv26和改进后的YOLOv26-ParallelBottleneck在不同规模下的性能表现。
实验配置:
- 数据集:COCO train2017(118k图像)/ val2017(5k图像)
- 输入分辨率:640×640
- 训练轮数:300 epochs
- 优化器:SGD(momentum=0.937, weight_decay=0.0005)
- 学习率策略:Cosine annealing(初始lr=0.01)
- 批次大小:16(单卡)
4.2 性能对比
| 模型 | 参数量(M) | FLOPs(G) | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|
| YOLOv26n | 2.57 | 6.1 | 52.3 | 37.2 | 156 |
| YOLOv26n-PB | 2.68 | 6.4 | 54.1 | 38.9 | 148 |
| YOLOv26s | 10.01 | 22.8 | 58.7 | 43.5 | 98 |
| YOLOv26s-PB | 10.35 | 23.6 | 60.2 | 45.1 | 92 |
| YOLOv26m | 21.90 | 75.4 | 63.4 | 47.8 | 54 |
| YOLOv26m-PB | 22.58 | 77.9 | 64.9 | 49.3 | 51 |
从表中可以看出,ParallelBottleneck改进版本在各个规模上都取得了显著的性能提升:
- YOLOv26n-PB:mAP@0.5:0.95提升1.7个百分点,仅增加4.3%的参数量
- YOLOv26s-PB:mAP@0.5:0.95提升1.6个百分点,参数增加3.4%
- YOLOv26m-PB:mAP@0.5:0.95提升1.5个百分点,参数增加3.1%
4.3 消融实验
为了验证ParallelBottleneck各组件的有效性,我们进行了详细的消融实验:
| 配置 | 3×3分支 | 1×1分支 | 残差连接 | mAP@0.5:0.95 |
|---|---|---|---|---|
| Baseline | ✗ | ✗ | ✗ | 37.2 |
| +3×3 only | ✓ | ✗ | ✗ | 37.8 |
| +1×1 only | ✗ | ✓ | ✗ | 37.5 |
| +Parallel | ✓ | ✓ | ✗ | 38.4 |
| +Residual | ✓ | ✓ | ✓ | 38.9 |
消融实验表明:
- 单独使用3×3或1×1分支都能带来性能提升,但效果有限
- 并行使用两个分支后,性能提升显著(+1.2 AP)
- 加入残差连接后,进一步提升0.5 AP,验证了残差学习的重要性
5. 代码实现详解
5.1 ParallelBottleneck核心代码
python
class ParallelBottleneck(nn.Module):
"""并行瓶颈模块 - 异构卷积核协同特征提取"""
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 中间通道数
# 第一阶段:特征压缩
self.cv1 = Conv(c1, c_, 1, 1)
# 第二阶段:并行双分支
self.cv2a = Conv(c_, c_ // 2, 3, 1) # 3×3卷积分支
self.cv2b = Conv(c_, c_ // 2, 1, 1) # 1×1卷积分支
# 第三阶段:特征恢复
self.cv3 = Conv(c_, c2, 1, 1)
# 残差连接条件
[ 301种YOLOv26源码点击获取 ](https://mbd.pub/o/bread/YZWbmZ9vag==)
self.add = shortcut and c1 == c2
def forward(self, x):
x1 = self.cv1(x) # 压缩
# 并行处理并拼接
out = torch.cat([self.cv2a(x1), self.cv2b(x1)], 1)
out = self.cv3(out) # 恢复
return x + out if self.add else out # 残差连接5.2 C3k2_ParallelBottleneck实现
python
class C3k2_ParallelBottleneck(nn.Module):
"""CSP架构集成的ParallelBottleneck模块"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__()
self.c = int(c2 * e) # 分支通道数
# 通道扩展
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
# 输出融合
self.cv2 = Conv((2 + n) * self.c, c2, 1)
# 级联ParallelBottleneck模块
self.m = nn.ModuleList(
ParallelBottleneck(self.c, self.c, shortcut,
int(g) if isinstance(g, bool) else g, 0.5)
for _ in range(n)
)
def forward(self, x):
# 扩展并分割
y = list(self.cv1(x).chunk(2, 1))
# 级联处理并收集所有输出
y.extend(m(y[-1]) for m in self.m)
# 拼接并融合
return self.cv2(torch.cat(y, 1))5.3 集成到YOLOv26
在YOLOv26的配置文件中,只需将原有的C3k2模块替换为C3k2_ParallelBottleneck即可:
yaml
backbone:
- [-1, 1, Conv, [64, 3, 2]]
- [-1, 1, Conv, [128, 3, 2]]
- [-1, 2, C3k2_ParallelBottleneck, [256, False, 0.25]] # 替换
- [-1, 1, Conv, [256, 3, 2]]
- [-1, 2, C3k2_ParallelBottleneck, [512, False, 0.25]] # 替换
# ... 其他层配置6. 特征可视化分析
为了直观理解ParallelBottleneck的工作机制,我们对中间特征进行了可视化分析。通过Grad-CAM技术,我们观察到:
- 3×3分支:主要激活目标的边缘和纹理区域,对局部细节敏感
- 1×1分支:倾向于激活目标的整体区域,关注全局语义信息
- 融合后特征:同时保留了边缘细节和整体语义,特征表达更加丰富
这种互补性验证了并行双分支设计的合理性。
7. 应用场景与扩展
ParallelBottleneck架构特别适用于以下场景:
- 小目标检测:并行分支能够同时捕获细粒度特征和上下文信息,提升小目标的检测精度
- 密集场景:异构卷积核的协同工作有助于区分相邻目标,减少误检
- 实时应用:相比传统方法,计算效率提升显著,适合边缘设备部署
此外,ParallelBottleneck的设计思想还可以扩展到其他视觉任务,如语义分割、实例分割等。想要探索更多创新改进方案,可以访问更多开源改进YOLOv26源码下载获取完整代码和预训练模型。
8. 未来改进方向
虽然ParallelBottleneck已经取得了显著的性能提升,但仍有进一步优化的空间:
- 动态分支权重:引入注意力机制,根据输入特征自适应调整两个分支的权重
- 多尺度并行:扩展到三个或更多分支,使用不同尺度的卷积核(如5×5、7×7)
- 神经架构搜索:使用NAS技术自动搜索最优的分支配置和通道分配策略
对于希望深入学习目标检测算法改进技巧的开发者,手把手实操改进YOLOv26教程见提供了从理论到实践的完整指导。
9. 总结
本文提出的并行双分支瓶颈架构为YOLOv26带来了显著的性能提升。通过异构卷积核的协同工作和残差学习机制,ParallelBottleneck实现了特征提取能力和计算效率的双重优化。实验结果表明,该方法在COCO数据集上取得了1.5-1.7 AP的性能提升,同时保持了较低的参数增长率。
ParallelBottleneck的成功验证了并行处理和异构卷积核融合的有效性,为目标检测算法的进一步优化提供了新的思路。未来,我们将继续探索更多创新的网络架构设计,推动目标检测技术的发展。
9. 总结
本文提出的并行双分支瓶颈架构为YOLOv26带来了显著的性能提升。通过异构卷积核的协同工作和残差学习机制,ParallelBottleneck实现了特征提取能力和计算效率的双重优化。实验结果表明,该方法在COCO数据集上取得了1.5-1.7 AP的性能提升,同时保持了较低的参数增长率。
ParallelBottleneck的成功验证了并行处理和异构卷积核融合的有效性,为目标检测算法的进一步优化提供了新的思路。未来,我们将继续探索更多创新的网络架构设计,推动目标检测技术的发展。