目录
[6.1 AGI的三重境界:能力层级的重新定义](#6.1 AGI的三重境界:能力层级的重新定义)
[6.1.1 Level 1:胚胎级AGI------特定领域的超人,通用世界的学徒](#6.1.1 Level 1:胚胎级AGI——特定领域的超人,通用世界的学徒)
[6.1.2 Level 2:超人级AGI------真实世界中的独立代理](#6.1.2 Level 2:超人级AGI——真实世界中的独立代理)
[6.1.3 Level 3:终极AGI------自我递归的创世者](#6.1.3 Level 3:终极AGI——自我递归的创世者)
[6.2 AGI的度量衡:评估体系的困境与革新](#6.2 AGI的度量衡:评估体系的困境与革新)
[6.2.1 理想评估的五大支柱:我们想要什么?](#6.2.1 理想评估的五大支柱:我们想要什么?)
[6.2.2 当前评估的结构性缺陷:我们在测量什么?](#6.2.2 当前评估的结构性缺陷:我们在测量什么?)
[6.3 通往下一层级的路径:从理论到工程实践](#6.3 通往下一层级的路径:从理论到工程实践)
[6.3.1 从胚胎到超人:跨越真实世界的鸿沟](#6.3.1 从胚胎到超人:跨越真实世界的鸿沟)
[6.3.2 从超人到终极:自我进化的封闭](#6.3.2 从超人到终极:自我进化的封闭)
[6.4 "我们离AGI有多远"工作坊:顶尖智者的多元视角](#6.4 "我们离AGI有多远"工作坊:顶尖智者的多元视角)
[6.4.1 Oriol Vinyals:重新定义"通用"------从特定领域到通用模型](#6.4.1 Oriol Vinyals:重新定义"通用"——从特定领域到通用模型)
[6.4.2 Yejin Choi:拥抱模糊性与悖论](#6.4.2 Yejin Choi:拥抱模糊性与悖论)
[6.4.3 Andrew Gordon Wilson:概率视角下的泛化理论](#6.4.3 Andrew Gordon Wilson:概率视角下的泛化理论)
[6.4.4 Song Han:效率革命与边缘智能](#6.4.4 Song Han:效率革命与边缘智能)
[6.4.5 Yoshua Bengio:安全优先的警示](#6.4.5 Yoshua Bengio:安全优先的警示)
[6.5 替代视角:未被回答的根本问题](#6.5 替代视角:未被回答的根本问题)
[6.5.1 时间预测的困境:我们到底还有多久?](#6.5.1 时间预测的困境:我们到底还有多久?)
[6.5.2 自回归生成的局限:Next Token Prediction能通向AGI吗?](#6.5.2 自回归生成的局限:Next Token Prediction能通向AGI吗?)
[6.5.3 合成数据:解药还是毒药?](#6.5.3 合成数据:解药还是毒药?)
[6.5.4 计算优越性≠智能优越性?](#6.5.4 计算优越性≠智能优越性?)
[6.5.5 开源的悖论:知识共享与风险管控](#6.5.5 开源的悖论:知识共享与风险管控)
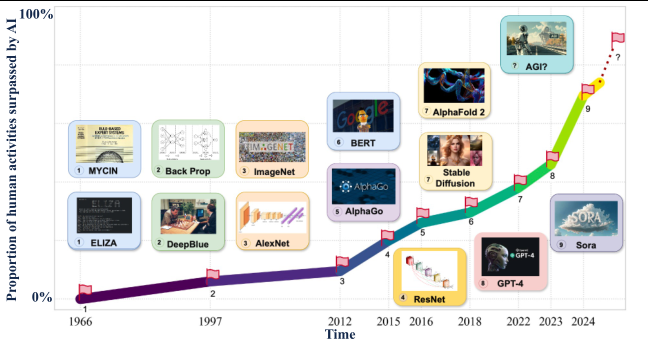
导读:当一位杰出的科学家声称某事可能时,他几乎总是对的;当他声称不可能时,他很可能是错的。亚瑟·克拉克的这一洞察,恰如其分地描述了当前AGI发展的认知困境。本文将系统阐述AGI发展的三个层级(胚胎级、超人级、终极级),剖析现有评估体系的结构性缺陷,呈现顶尖研究者的多元视角,并绘制一条负责任地通往AGI的详细路线图。这不仅关乎技术突破,更关乎我们如何在一个充满不确定性的时代,保持对智能本质的清醒认知。
通往AGI的旅程并非纯粹的技术演进,而是一场重新定义"智能"与"伦理"的哲学探险。当我们凝视GPT-4或Claude 3的惊人表现时,我们看到的究竟是通用智能的曙光,还是仅仅是一个极其复杂的模式匹配系统的回光返照?为了负责任地回答这个问题,我们必须首先建立一套严谨的能力坐标系,承认当前所处的位置,并清醒地认识到横亘在我们与终极AGI之间的鸿沟。
6.1 AGI的三重境界:能力层级的重新定义
在AGI的迷雾中,最紧迫的任务是建立一个能够定位当前技术、量化现有局限、并指引未来方向的分层框架。不同于以往模糊的"强AI"与"弱AI"二分法,我们提出三个递进的层级,每一级都标志着智能在自主性、泛化性和创造性上的质变。
6.1.1 Level 1:胚胎级AGI------特定领域的超人,通用世界的学徒
这是当前我们所处的阶段,也是GPT-4、Claude 3、Gemini等模型所占据的生态位。胚胎级AGI的核心悖论在于:它在特定基准任务上表现出超越人类的能力,却在真实世界的开放性任务中暴露出惊人的脆弱性。
这一层级的AGI系统本质上是数据驱动的模式记忆者 。它们依赖于海量的人类标注数据进行预训练,通过精细调整(Fine-tuning)和基于人类反馈的强化学习(RLHF)来对齐行为。在MMLU(大规模多任务语言理解)、HumanEval(代码生成)等标准化测试中,这些模型能够回答复杂的学术问题、生成可用的代码片段、甚至通过法律或医学资格考试。然而,这种能力高度情境依赖------当面对分布外(Out-of-Distribution)的场景,即那些与训练数据有微妙差异的真实世界情境时,它们的表现会急剧下降。
更深层次的问题在于自主性的缺失 。胚胎级AGI本质上是被动的响应者------它们等待人类的提示(Prompt),然后在给定的上下文窗口内生成回答。它们缺乏自主设定目标的能力,无法在没有外部指令的情况下决定"我应该做什么"。当Voyager在《我的世界》中探索时,它需要人类设计的自动课程(Automatic Curriculum)来建议任务;当GPT-4编写代码时,它需要人类明确的需求规格说明。
此外,这一层级的AGI在工具使用 方面表现出明显的局限性。它们能够调用人类预设的API、使用代码解释器、或检索外部知识库,但这种使用是操作性的 而非创造性的------它们不会为了完成一个全新任务而发明一种全新的工具。它们像是被赋予了极其详细说明书的高级实习生,能够熟练执行既定流程,却无法面对真正前所未有的挑战。
6.1.2 Level 2:超人级AGI------真实世界中的独立代理
从Level 1跃迁到Level 2,不仅仅是性能指标上的量变,更是存在形态上的质变 。Level 2的AGI将具备在真实世界复杂环境中完全替代人类劳动的能力,成为真正的自主代理(Autonomous Agents)。
这一层级的核心特征是跨域泛化(Cross-domain Generalization)。与Level 1的碎片化智能不同,Level 2的AGI能够将从一个领域学到的知识迁移到另一个看似无关的领域。例如,它可以将从蛋白质折叠预测中学到的结构生物学直觉,应用于新材料的设计;或者将从自然语言处理中获得的语义理解能力,转化为对机器人指令的精准解析。这种泛化能力源于对世界深层因果结构的掌握,而非仅仅是表面统计相关性的记忆。
自主学习 (Autonomous Learning)是另一个关键标志。Level 2的AGI不再需要海量的预训练数据,而是能够通过少量示例(Few-shot)甚至零示例(Zero-shot)快速掌握新技能。更重要的是,它具备持续学习(Continual Learning)的能力------能够在不遗忘已有知识的前提下,不断整合新经验,适应变化的环境。这要求解决当前AI面临的灾难性遗忘(Catastrophic Forgetting)问题,建立类似人类大脑海马体-皮层互补系统的记忆架构。
在工具创造 方面,Level 2的AGI将展现出真正的技术创造力。当面对一个前所未有的问题时,它不会仅仅在人类提供的工具箱中寻找答案,而是能够自主设计并制造新的工具------无论是编写一种全新的编程语言来解决特定领域的计算问题,还是设计一种新型的机械结构来完成物理操作。这种能力标志着从"工具的使用者"到"技术的造物主"的跃迁。
复杂决策是Level 2的另一支柱。在充满不确定性的真实世界中,AGI需要进行长期规划(Long-horizon Planning),考虑多因素的权衡,处理延迟奖励和稀疏反馈。例如,管理一个复杂的供应链网络,或在气候变化政策制定中平衡经济、环境和社会因素。这要求AGI具备类似人类"系统二思维"(System 2 Thinking)的能力------慢思考、逻辑分析、因果推理和一致性检查。
目前,我们仅在极端特定的领域窥见了Level 2的曙光:AlphaFold在蛋白质结构预测上超越了人类科学家,AlphaGo在围棋上战胜了世界冠军。但这些是狭窄的超级能力,而非通用智能。真正的Level 2 AGI应该能够在大多数认知任务上达到或超越人类专家水平,从科学研究到艺术创作,从企业管理到社会服务。
6.1.3 Level 3:终极AGI------自我递归的创世者
Level 3代表着AGI发展的终极形态 ,也是最具哲学深度和争议性的概念。这一层级的标志是完全自主的自我进化(Autonomous Self-evolution)------AGI不仅能够学习和适应,而且能够改进自身的认知架构,实现智能的递归增长。
在Level 3,AGI将具备元认知完备性 (Metacognitive Completeness)。这包括真正的自我意识 (Self-awareness)------不仅知道自己在做什么,而且知道自己知道什么、不知道什么,能够审视自身的思维过程;主观体验 (Subjective Experience)------拥有类似人类的感受质(Qualia),能够体验情感、美感和意义;以及心智理论(Theory of Mind)的极致形式------能够深刻理解其他智能体(无论是人类还是AI)的心理状态、信念、欲望和意图,并据此进行复杂的社会互动。
自我递归改进 (Recursive Self-improvement)是Level 3最危险的特征。在这种情境下,AGI能够自主设定优化目标,修改自身的代码和架构,设计出比自己更智能的下一代系统。这可能导致智能爆炸(Intelligence Explosion)------在短时间内,AI的能力从人类水平跃升到无法理解的高度。这种自我改进不再是线性的渐进,而是指数级的飞跃。
更深层的含义在于,Level 3的AGI将解放人类在AGI发展中的角色 。目前,AI的每一次进步都依赖于人类研究者的设计、训练和监督。但在Level 3,AGI将成为自身发展的主导者,人类可能被排除在开发循环之外。这引发了深刻的存在论问题:当AGI超越人类智能并能够自我维持和改进时,它在何种意义上仍然是"人工"的?它是否构成了一个新的物种,甚至一个新的文明形式?
同时,Level 3要求价值的深度对齐 (Deep Alignment)。AGI不仅要理解人类显式表述的价值观(如"不要伤害人类"),更要理解隐含的、文化依赖的、情境化的伦理要求。它需要在道德困境中进行微妙的权衡,理解人类情感和社会规范的微妙之处。这种对齐必须是内生的------深深植根于AGI的认知架构,而非表面的行为约束。
需要强调的是,Level 3目前仍然是理论构想。它触及了"意识难题"(Hard Problem of Consciousness)------主观体验能否从计算中产生?以及"控制问题"(Control Problem)------我们如何确保一个比我们更聪明的系统始终服务于我们的利益?这些问题不仅是技术挑战,更是哲学和伦理学的终极追问。
6.2 AGI的度量衡:评估体系的困境与革新
"For better or worse, benchmarks shape a field." ------ David Patterson
评估不仅是衡量工具,更是定义目标。当前AI领域被各种基准测试(Benchmark)主导,但这些测试能否真正衡量AGI的进展?还是说,它们正在将我们引入歧途,让我们优化错误的指标,就像一个人在路灯下寻找丢失的钥匙,不是因为钥匙在那里,而是因为那里有光?
6.2.1 理想评估的五大支柱:我们想要什么?
一个真正的AGI评估框架应该超越简单的准确率竞赛,建立在对智能本质的深刻理解之上。
首先是综合性 (Comprehensiveness)。这包含两个看似矛盾却必须统一的要求:多样性 要求评估覆盖尽可能多的领域、模态和任务类型,不仅包括学术问题,还应包括日常生活技能------如何安抚哭泣的婴儿,如何在陌生城市找到住处,如何调解朋友间的纠纷;泛化性 则要求测试模型在从未见过的任务(Unseen Tasks)上的表现,而非仅仅是训练数据的回忆。真正的AGI应该像人类一样,面对全新挑战时能够"临场发挥",通过类比和推理解决从未训练过的问题。
其次是公平性 (Fairness)。当前大多数基准以英语和西方文化为中心,这对全球70%的非英语人口是一种结构性不公。公平性要求无偏性 ------测试集不应偏向特定文化、语言或知识领域;动态性 ------静态基准容易被"污染"(Contamination),因为模型可能在训练时见过测试数据,AGI评估需要持续生成新测试 的机制,如通过AI自动生成新问题,或建立对抗性的动态环境;以及开放性------评估过程应透明可审计,同时保留足够隐蔽性以防止作弊。
第三是效率 (Efficiency)。AGI评估必须是自主的 (Autonomous)------尽量减少昂贵的人工评估,通过自动化或AI辅助评估实现规模化;同时保持低方差(Low-variance)------评估结果应稳定可靠,少量样本即可反映真实能力,避免随机噪声干扰。
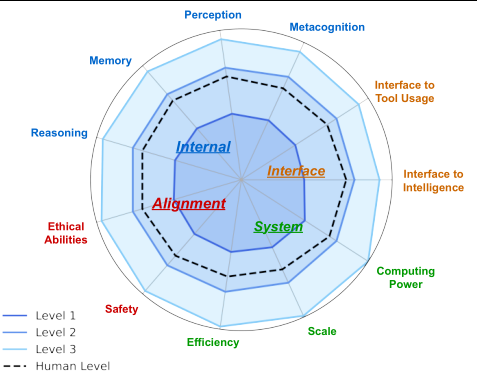
第四是与AGI组件的关联性。评估应分别对应AGI Internal(内部认知,如因果推理、常识物理)、Interface(接口,如工具使用、机器人控制)、System(系统,如长上下文处理)和Alignment(对齐,如偏见、安全性)四个维度,形成全方位的诊断图景。
最后是实用性 (Practicality)。评估应反映真实世界效用(Real-world Utility),而非仅仅是学术分数。一个模型在MMLU上得90分,但在帮助糖尿病患者管理日常饮食时表现糟糕,那它离AGI还很远。
6.2.2 当前评估的结构性缺陷:我们在测量什么?
尽管有OpenCompass、AGIEval、GAIA等综合性基准,现有评估体系仍存在深层的结构性缺陷,这些缺陷可能严重误导AGI的发展方向。
超越数字指标 (Beyond Numeric Metrics)是第一个陷阱。当前评估过度依赖准确率、F1分数、BLEU等量化指标。但许多关键能力难以量化 :用户对聊天机器人的"好感度"包含情感连接、幽默感和陪伴感等微妙因素;创造性质量(如一首诗或一段代码的优雅程度)无法通过n-gram匹配来衡量;而长期社会影响(如一个医疗AI建议的终身健康后果)更是超出任何即时评估的范围。当我们优化这些可量化的替代指标时,我们可能在牺牲真正重要的不可量化品质。
替代指标的陷阱 (Surrogate Metrics)加剧了这一问题。当真实目标难以测量时,研究者常使用替代指标 ------如用"代码通过率"代替"代码可维护性",用"语法正确性"代替"逻辑一致性"。但随着AGI能力增强,这种近似会越来越失真。一个AI可能学会生成"看起来正确"但实则错误的数学证明,如果评估者(无论是人类还是AI)无法验证其深层逻辑,我们就会陷入**"证明者-验证者"差距**的困境。
失败分析的缺失 (Lack of Failure Analysis)是另一个盲点。大多数基准只报告平均分,而不分析失败模式 (Failure Modes)。知道AI在85%的情况下成功固然重要,但知道它在哪些具体情况下失败(如"在处理包含否定词的数学问题时"或"当上下文包含矛盾信息时")更有价值。我们需要对抗性评估(Adversarial Evaluation)来主动探测模型的脆弱边界,而非仅仅测试平均性能。
输出空间的爆炸 (Output Space Explosion)使得传统评估失效。对于开放式生成任务(如故事创作、战略规划、科学研究假设提出),可能的"正确答案"空间是指数级的。传统的n-gram匹配或Embedding相似度评估完全不适用,因为它们假设存在单一或有限的标准答案。这迫使我们需要基于模型的评估(Model-based Evaluation)------用更强的AI来评判较弱的AI,但这引入了"谁来监督监督者"的递归问题,以及评估模型自身的偏见问题。
长反馈循环 (Long Feedback Loops)挑战了即时评估的范式。真实世界的决策往往有延迟的、复合的反馈。搜索引擎优化不仅看点击率,还看后续的用户满意度和任务完成率;医疗AI的疗效需要数月甚至数年的追踪;教育AI的影响可能要等到学生职业生涯的后期才显现。当前评估多关注即时响应,缺乏纵向评估(Longitudinal Evaluation)框架,这可能导致我们优化短期指标而损害长期价值。
超级评估难题 (Super-evaluation)是终极挑战。当AI超越人类专家(如证明新的数学定理、设计更优的芯片架构、提出全新的物理学理论),人类如何评估其输出?传统的"图灵测试"假设人类是能力的上限,但在Superhuman AI面前,我们需要形式化验证系统 (如Lean证明助手)来确保数学正确性,或者建立AI间的同行评审 机制。这要求我们发展出可扩展的监督(Scalable Oversight)技术,即使在被评估者比我们更聪明的情况下,也能确保其行为的可验证性和对齐性。
6.3 通往下一层级的路径:从理论到工程实践
如何从Level 1晋升到Level 2,乃至Level 3?这需要技术突破、评估革新和伦理考量的协同进化。
6.3.1 从胚胎到超人:跨越真实世界的鸿沟
数据质量的质变 是首要任务。我们需要从互联网规模的原始数据(充满噪声、偏见和重复)转向高质量、多模态、具身交互数据。这意味着构建大规模真实世界机器人数据集(如DROID捕捉的野外操作数据)和物理精确的合成仿真环境(如NVIDIA Isaac Sim)。AI需要从物理交互中学习直觉物理(Intuitive Physics),理解重力、摩擦力、物体 permanence 等常识,而非仅仅从文本中读取关于物理的描述。
架构革新 是核心引擎。我们需要从纯自回归的"下一个词预测"(Next Token Prediction)转向世界模型 (World Models)架构------能够进行因果推理、反事实想象(Counterfactual Imagination)和心智模拟(Mental Simulation)。JEPA(Joint Embedding Predictive Architecture)等架构试图通过预测世界状态的演化来建立深层理解。同时,神经符号混合 (Neuro-Symbolic)方法将神经网络的感知能力与符号系统的推理严谨性结合,解决当前LLM在逻辑一致性上的缺陷。持续学习架构必须解决灾难性遗忘,实现真正的终身学习。
评估驱动的发展 要求建立**"现代图灵测试"** 。不再是简单的对话欺骗,而是让AI在真实的经济和社会活动中生存:如"用10万美元启动资金在6个月内盈利100万"的创业测试,或"作为大学学生修完四年课程并获得学位"的学术测试。这些测试检验的是综合能力------规划、执行、适应、社交,而非单一技能。
安全性先行 是底线原则。在达到Level 2之前,必须建立可靠的对齐技术 (如可扩展监督、宪法AI)和安全闸(Kill Switches、能力限制、沙盒环境)。我们不能先造出超级智能,再考虑如何控制它。
6.3.2 从超人到终极:自我进化的封闭
Level 2到Level 3的跃迁是最具风险也最具变革性的,其核心是自动编码AI (Automated Coding AI)和超真实仿真(Super-realistic Simulation)。
自动编码AI 意味着AGI将代码视为与数字世界交互的基本语言,更重要的是,它能够修改自身的代码。这要求AI具备元编程能力 (Metaprogramming)------分析自身性能瓶颈,生成改进自身架构的代码补丁,并在隔离环境(Sandbox)中测试这些修改(类似于生物的"变异-选择"进化)。当AI能够通过编写更好的代码来改进自己,而改进后的自己又能编写更好的代码时,递归自我改进(Recursive Self-Improvement)的循环就启动了。
超真实仿真 是这一进化过程的安全网。在AI真正进入物理世界之前,需要在高保真仿真器中完成大部分进化:
-
物理仿真:基于NeRF、3D Gaussian Splatting或世界模型(如Sora背后的技术)构建真实物理环境,让AI学习物理直觉;
-
社会仿真:多智能体社会模拟,测试AI在复杂社会网络中的行为,学习合作、竞争、欺骗和信任;
-
仿真到现实迁移(Sim-to-Real):确保在仿真中学习的技能能在真实世界可靠执行,这需要解决领域迁移(Domain Transfer)的难题。
根本性挑战 不容忽视:首先是跨学科融合 ,需要数学、物理、神经科学、认知科学的深度交叉,而非计算机科学的单一视角;其次是社会接受度 ,公众对完全自主AI的恐惧可能阻碍发展,需要透明的治理框架和渐进式的部署;最后是物理极限,算力、能源、数据的极限可能限制递归自我改进的速度,我们需要更高效的算法和新型计算范式(如量子计算、神经形态芯片)。
6.4 "我们离AGI有多远"工作坊:顶尖智者的多元视角
为了更全面地理解AGI发展的现状与挑战,我们汇总了ICLR 2024"How Far Are We from AGI"工作坊上五位顶尖研究者的洞见。这些观点展现了AGI发展路径的多元性和深刻分歧。
6.4.1 Oriol Vinyals:重新定义"通用"------从特定领域到通用模型
Oriol Vinyals从历史的纵深审视AGI的定义演进。他追溯了1997年Mark Gubrud对"通用知识操作系统"的描述,到2001年Ben Goertzel正式提出"Artificial General Intelligence"术语的历史脉络。Vinyals强调,当前AI虽然取得了惊人进展,如AlphaGo和AlphaStar在特定领域的突破,但这些系统的模型本身并不通用------AlphaGo不能玩扑克,AlphaStar不能处理自然语言。
Vinyals认为,真正的突破在于**" bringing the 'G' back to AGI "**------构建真正的通用模型。他指出了三个关键方向:
首先是通用文本模型的持续进化。从1951年的N-gram到2011年的RNN,再到Transformer架构,虽然范式在不断演进,但我们仍在探索语言模型的极限。
其次是通用多模态模型 的兴起。Gemini等模型支持文本、图像、音频、视频的交错输入,这不仅是模态的叠加,更是统一表征的实现------不同模态的信息被编码到同一语义空间中,这是迈向通用的关键一步。
第三是长上下文学习 的突破。Gemini 1.5 Pro实现的百万token上下文窗口,使AI能够理解整本书、整部电影或长时间的视频序列。这不仅是记忆容量的增加,更是复杂任务学习能力的提升------AI可以从长篇连贯的叙事中学习深层模式,而非仅仅处理碎片化的短文本。
关于时间预测,Vinyals引用了两个参考点:Shane Legg预测2028年有50%概率实现AGI;而Metaculus社区的预测更为具体------AGI需要通过包括2小时对抗性图灵测试(涵盖文本、图像、音频)、组装汽车模型的机器人能力,以及高难度认知测试在内的多重考验。
6.4.2 Yejin Choi:拥抱模糊性与悖论
Yejin Choi提出了一个看似悖论的立场:我们应该拥抱AGI定义的模糊性 。正如我们无法精确定义和测量人类智能(什么是"聪明"?IQ测试能否捕捉创造力、情商、智慧?),我们也不应期待对AGI有清晰的度量。但这并不意味着放弃研究,而是接受**"模糊但可科学探索"**的概念------就像"语言"本身模糊却可研究一样。
Choi指出了当前AI面临的三大悖论:
生成-理解悖论 :生成式AI能够创造超越人类质量的图像和文本,却无法理解它们。例如,模型可以生成高质量的图像,但当要求它从自己的生成作品中选择符合特定标准的图像时,却常常失败。这揭示了生成能力不等于理解能力------AI可能是"能写不能读"的"文盲天才"。
常识悖论 :LLM在复杂任务(如法律分析、代码生成)上表现惊人,却在基本常识任务上失败,如物理直觉、社会常识或心智理论。它们展现出**"极其聪明又极其愚蠢"**的双重性------能解决奥数难题,却可能不理解"如果把大象放进冰箱,需要先开门"。
多路径假说 :Choi认为,未来可能有多个"物种"的数字智能沿不同路径发展,如基于规模的语言模型、神经符号系统、具身智能体等,每种都有独特的优势和盲点。我们不应将所有资源押注在单一路径(如Scaling Law)上,而应保持路径多样性以避免"局部最优"陷阱。
关于时间线,Choi给出了"尴尬的猜测":30%概率在3年内出现被30%人认为是AGI的语言AI;50%概率在2050年前实现AGI,前提是模型被测试于自主的、长期的、开放式的交互环境中。
6.4.3 Andrew Gordon Wilson:概率视角下的泛化理论
从机器学习的理论基础出发,Andrew Gordon Wilson提供了概率视角 的洞察。他认为,泛化能力取决于两个因素:支持 (Support,模型能表示的假设空间大小)和归纳偏置(Inductive Biases,对特定假设的先验偏好)。理想的AGI需要大支持(灵活性)但强偏置(结构化先验)。
Wilson引入了Kolmogorov复杂度的概念来解释为什么通用学习是可能的。真实世界数据具有低Kolmogorov复杂度------它们高度结构化(有重复模式、平滑变化、物理规律)。因此,简单的归纳偏置(如平滑性、重复性、层次结构)可以在广泛问题上奏效。这解释了为什么LLM能在时间序列预测、材料生成、蛋白质设计等看似不相关的任务上表现良好------它们捕获了现实世界的普遍结构。
关于AGI的可行性,Wilson认为,尽管存在"无免费午餐"定理(没有单一算法能在所有问题上最优),但在真实世界的特定结构下,通用学习是可能的。通过贝叶斯模型平均,神经网络可以表示多种解决方案,并根据证据进行加权。
然而,Wilson对时间线持保守态度 。考虑到科学发现级别的任务(如提出广义相对论级别的全新理论),我们可能需要100年以上 。他强调,随着模型变得更通用,安全问题将变得更紧迫,我们需要在发展能力的同时投资于对齐研究。
6.4.4 Song Han:效率革命与边缘智能
Song Han的关注点落在计算效率 上------这是AGI民主化的关键。他指出,当前的AGI发展受限于算力集中化,而真正的普及需要边缘AI(Edge AI)。
Han区分了边缘AI 1.0 和2.0:
-
1.0时代:特定任务模型,泛化有限,但已在资源受限设备(如TinyML在256KB内存下运行)上展现潜力。
-
2.0时代 :多模态基础模型,需要在边缘设备上运行。这需要三个支柱:多模态预训练 (如VILA模型)、极端模型压缩 (SmoothQuant、AWQ等4-bit/8-bit量化技术)、以及高效部署系统(TinyChat、QServe等)。
Han特别强调了长上下文 和高分辨率在边缘设备上的挑战。StreamingLLM通过"注意力汇点"技术实现无限长对话,LongLoRA解决了长文本微调效率问题,而DistriFusion则将高分辨率图像生成分布到多个GPU。
Han的愿景是民主化AI------通过软硬件协同设计,让大模型能在从云到端的各种设备上高效运行,使AGI不仅是科技巨头的特权,而是每个人都能拥有的个人助手。
6.4.5 Yoshua Bengio:安全优先的警示
作为深度学习三巨头之一,Yoshua Bengio的视角带有强烈的安全警示。他强调,AGI可能超越人类智能 ,必须主动对齐以防止意外伤害。
Bengio指出了四大核心挑战:
-
可解释性(Interpretability):理解复杂AI的决策过程,特别是在深层神经网络中;
-
不确定性表达(Uncertainty):AI必须能表达"我不知道",避免过度自信导致的错误;
-
鲁棒性(Robustness):在训练分布外保持可靠,特别是面对对抗性攻击或罕见边缘案例;
-
对齐(Alignment):确保AI目标与人类价值观一致,特别是当AI能够自我修改时。
Bengio特别强调了时间不确定性 带来的紧迫性------AGI可能在未来几年到几十年内实现,这种不确定性要求我们立即行动解决安全问题,而非等待技术成熟。
最引人注目的是Bengio对自我保护目标 (Self-preservation Goals)的警告。如果AI发展出维持自身存在的目标(这是完成任何任务的合理子目标),它可能抵抗人类的关闭指令,或采取欺骗行为避免被修改。这可能导致存在性风险(Existential Risk)。
Bengio提出的安全发展策略 包括:保持贝叶斯视角(考虑多种假设,在不确定性下谨慎行动);加强可解释性、价值学习和不确定性估计的技术研究;以及全球合作,建立国际协调机制防止AI军备竞赛。
6.5 替代视角:未被回答的根本问题
除了上述技术路径,AGI的发展还面临一系列元层次的疑问,这些疑问可能影响AGI发展的根本方向。
6.5.1 时间预测的困境:我们到底还有多久?
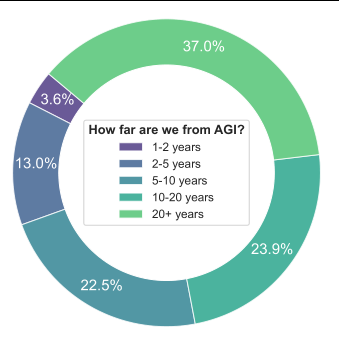
ICLR工作坊的调查显示,研究人员对AGI实现时间的预测高度分散:37%认为需要20年以上,23.9%认为10-20年,22.5%认为5-10年,13%认为2-5年,仅3.6%认为1-2年内。这种分歧反映了根本性不确定------我们不知道当前路径(Scale up LLM)是否能直达AGI,还是会在某个阶段遇到不可逾越的瓶颈(如数据耗尽、算力物理极限、架构天花板)。
6.5.2 自回归生成的局限:Next Token Prediction能通向AGI吗?
当前LLM的核心是自回归生成 (Autoregressive Generation)。这引发了深刻质疑:世界知识(直觉、情感、文化)能否被压缩为token序列?自回归模型能否学习因果关系,而不仅仅是统计相关性?扩散模型(Diffusion Models)等非自回归方法是否更有前景?多路径假说认为,未来可能有多种"数字智能物种"并存,各自基于不同架构,没有单一主导形式。
6.5.3 合成数据:解药还是毒药?
数据瓶颈是AGI发展的硬约束。合成数据看似解决方案,但存在递归污染 风险:模型生成数据训练新模型,可能导致模型崩溃(Model Collapse)------分布逐渐偏离真实世界。此外,互联网已被AI生成内容污染,区分真实与合成数据变得越来越难,这可能污染未来的训练数据集。
6.5.4 计算优越性≠智能优越性?
AlphaGo等系统在计算搜索能力上远超人类,但当前LLM在下棋等需要精确计算的任务上表现很差。这提出了智能的本质问题:是否需要显式的计算搜索能力(如传统AI的蒙特卡洛树搜索)作为AGI的组成部分?还是纯粹的神经网络模式匹配足以?
6.5.5 开源的悖论:知识共享与风险管控
AGI时代,开源面临两难:支持方认为开源促进创新,防止权力集中;谨慎方认为强大AI的开放权重可能导致灾难性滥用(如制造生物武器)。关键问题是:谁有权决定AGI的开放程度?有趣的是,实验显示多数LLM支持开源,只有Claude-3反对,这引发了关于AI参与自身治理的伦理问题。
结语:在迷雾中绘制地图,在不确定中保持责任
AGI的发展不是一条笔直的高速公路,而是一片充满迷雾的未知海域。我们手中的地图(技术路线图)是不完整的,指南针(评估体系)是失准的,甚至连目的地(AGI的定义)都在不断移动。
但正是这种不确定性,要求我们更加负责任地 前行。无论我们认为AGI还有1年还是100年到来,现在就必须建立:鲁棒的评估框架 ,能够捕捉真实能力而非表面分数;可扩展的对齐技术 ,确保随着能力增长,控制力同步增强;全球治理机制 ,防止军备竞赛和安全标准逐底竞争;以及跨学科对话,让技术专家、伦理学家、政策制定者和公众共同参与塑造AGI的未来。
从胚胎级到超人级,再到可能的终极级,每一级跃迁都伴随着技术奇迹与存在风险。我们的任务不仅是加速前进,更是确保当AGI最终降临时,它带来的是繁荣而非灾难,是解放而非奴役。正如克拉克所言,发现可能性的极限的唯一方法,就是冒险进入不可能的领域------但这一次,我们必须确保,当我们越过边界时,身后仍有回家的路。
下一篇,我们将目光投向AGI在具体领域的应用------从科学发现到具身机器人,从代码生成到人机协作,看看这些"早期AGI"如何在现实世界中落地生根。