案例网址:spiderbuf第C7题
接口+加密参数
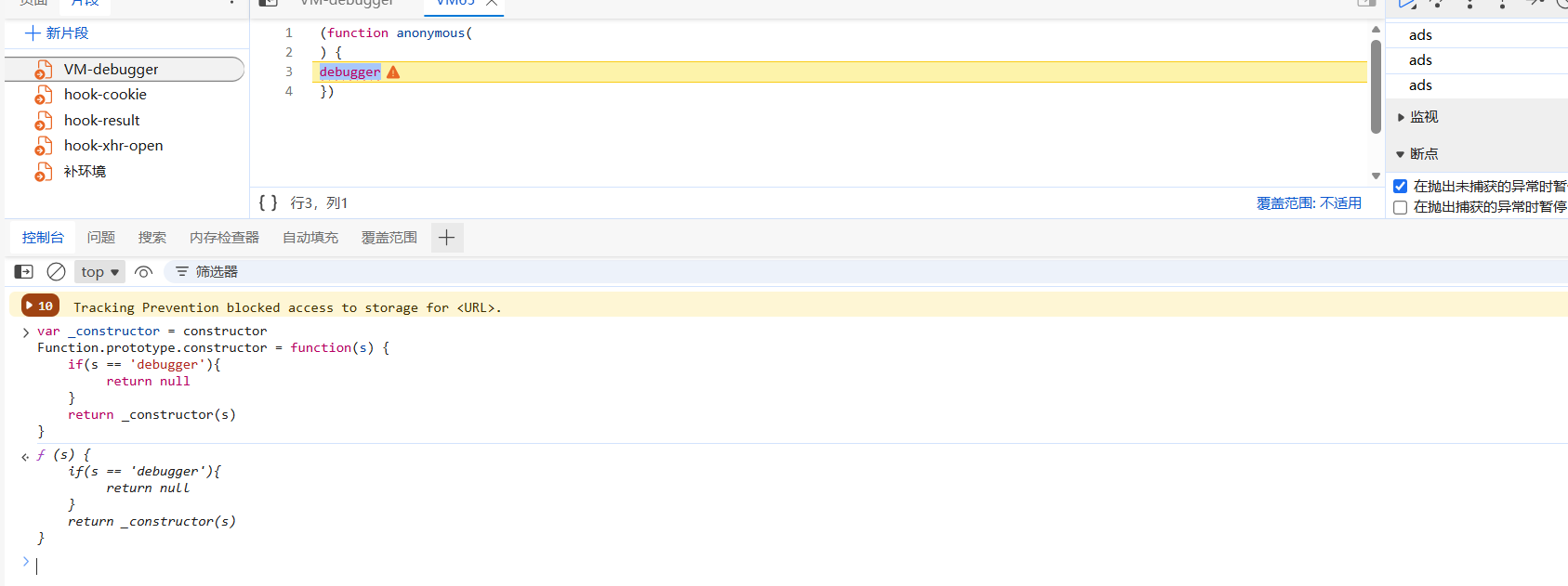
这里有个无限debugger,hook一下直接过掉:
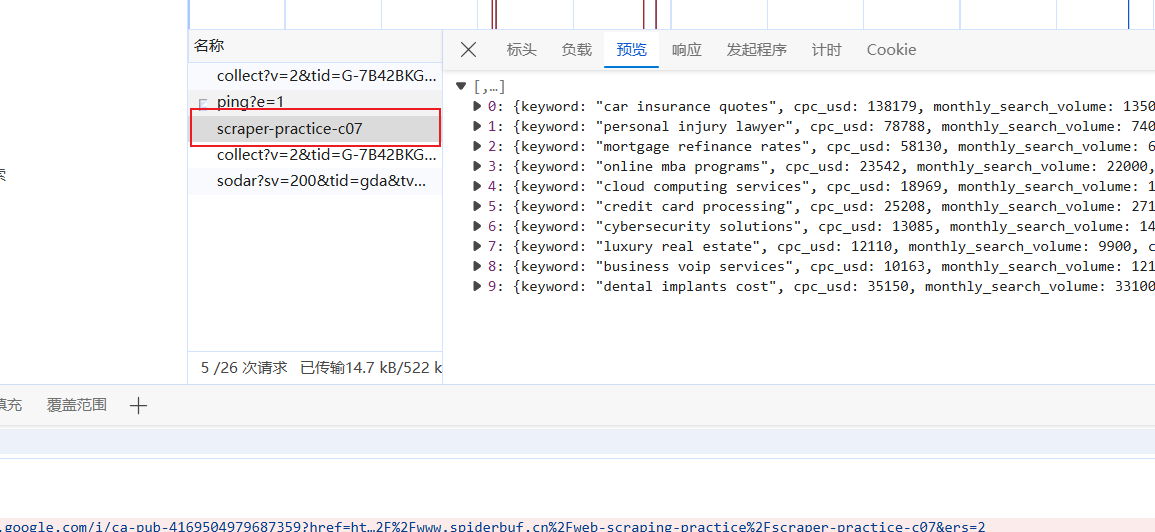
抓到数据包:
复制bash,用py验证一下看看那些参数需要逆向:
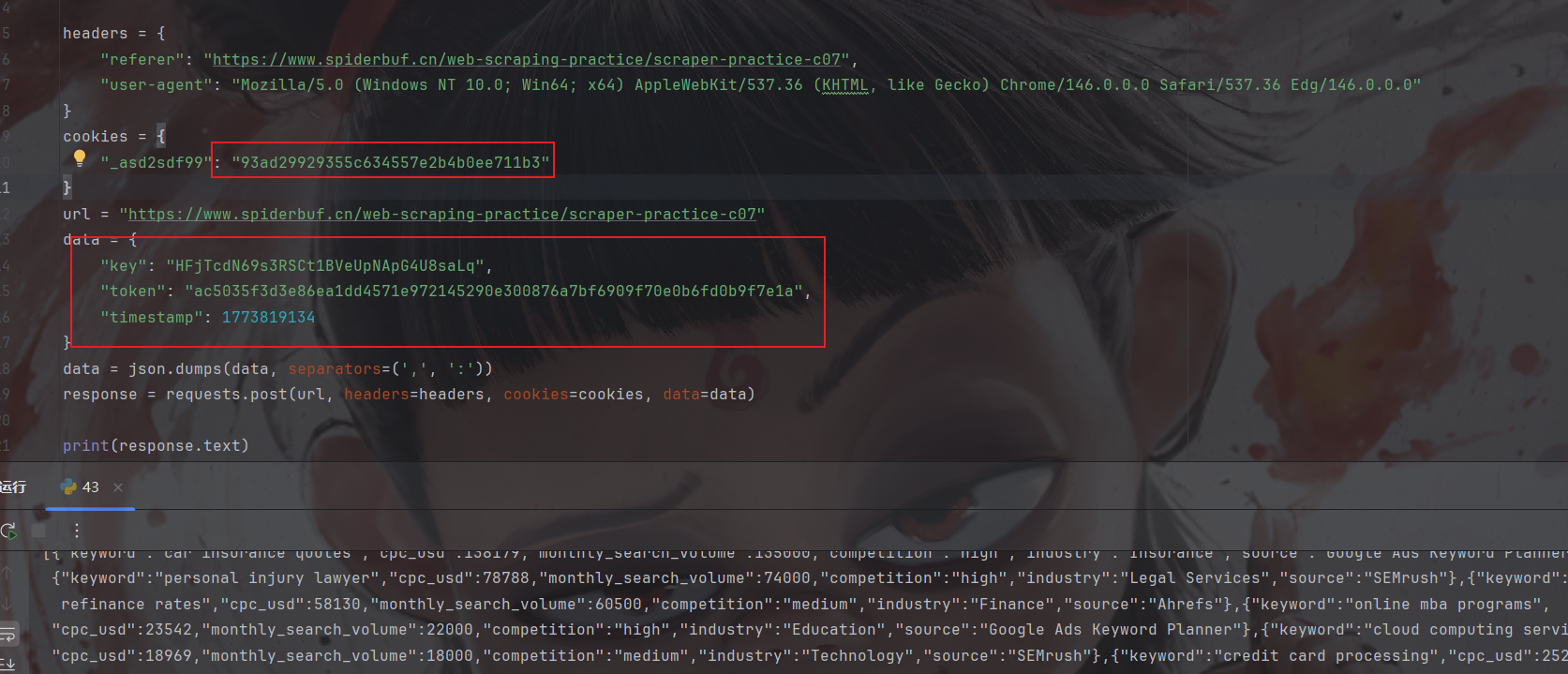
ok,这四个参数都需要逆向,开干:
找加密位置
启动器进去打断点:
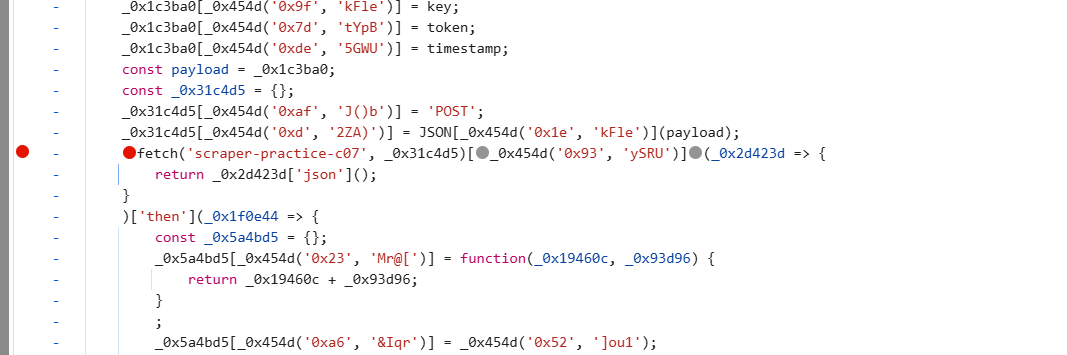
刷新网页,通过跟变量一步步找到data里三个加密参数位置:
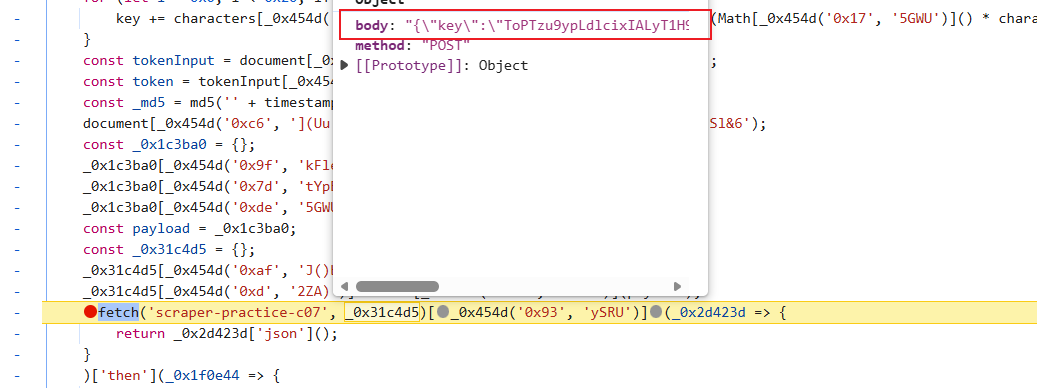
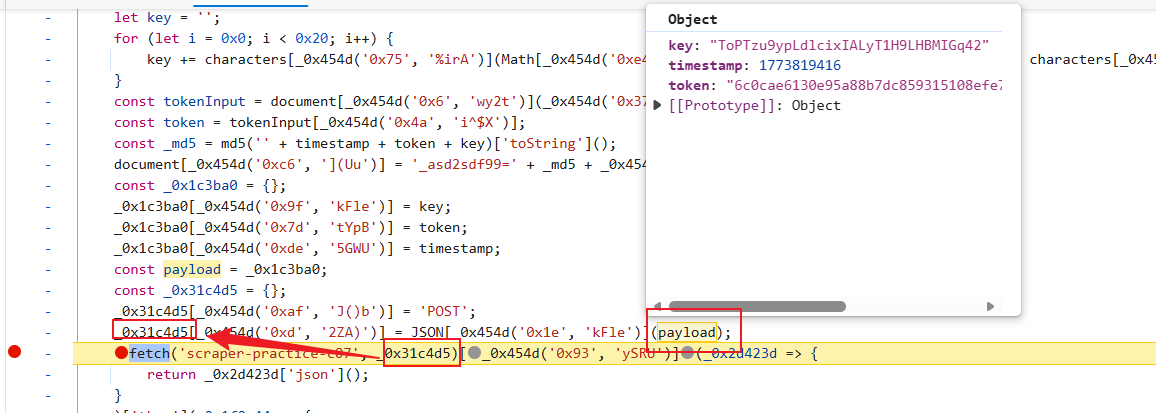
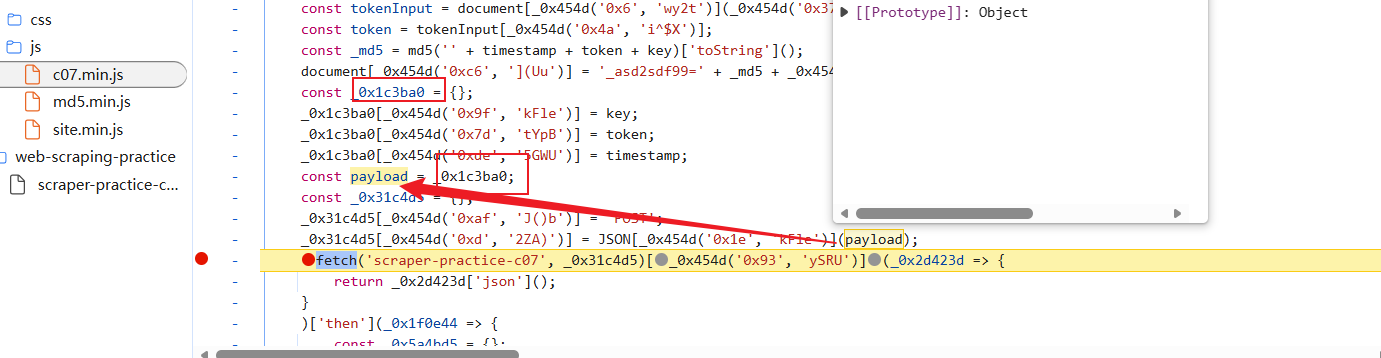
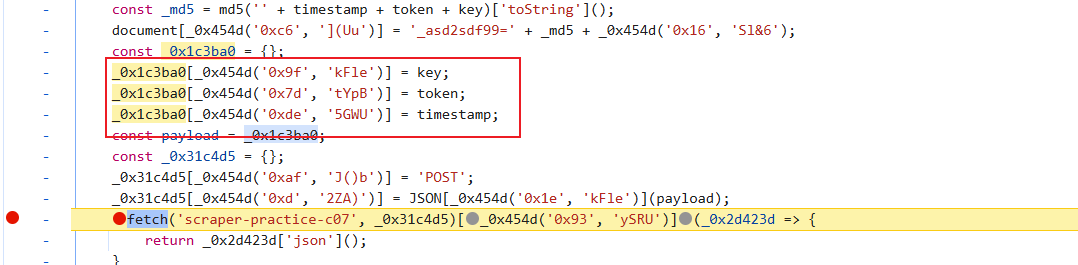
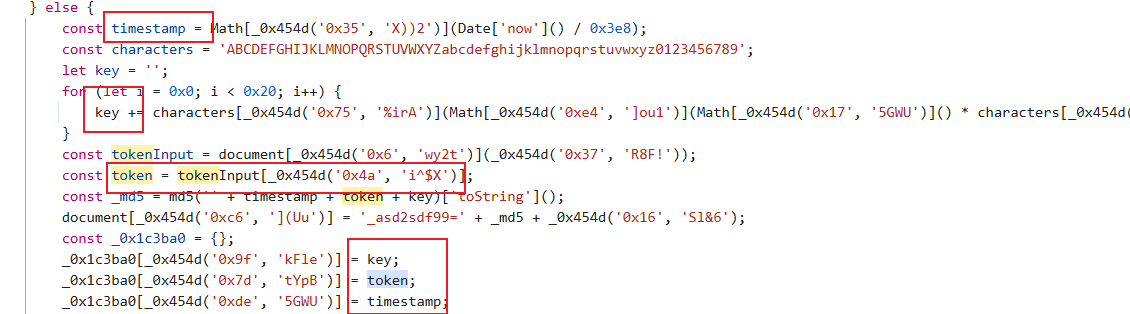
找到加密位置,稍做分析:

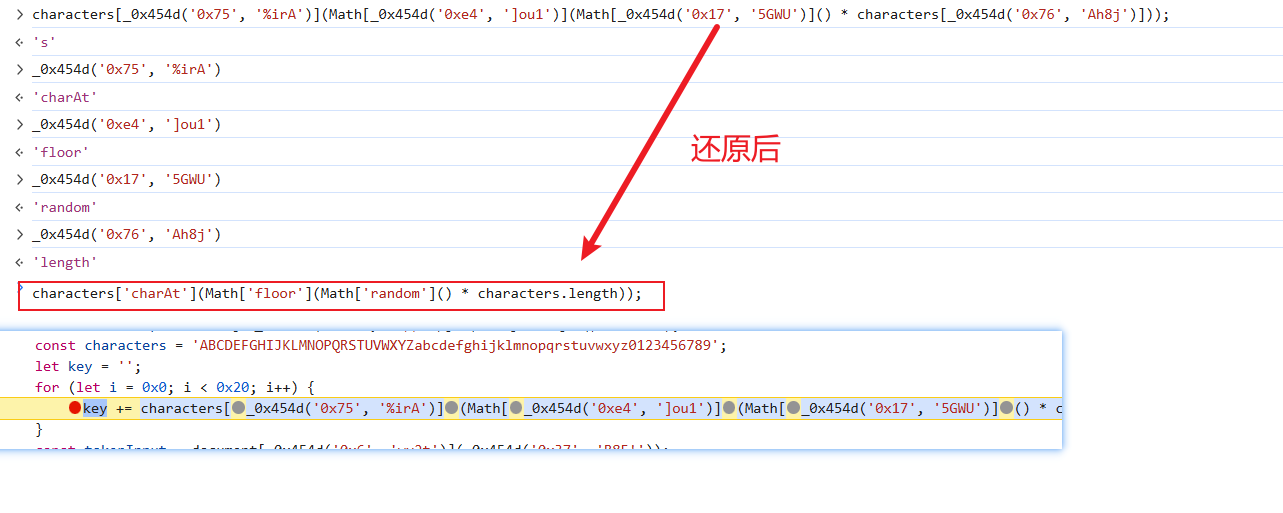

这里总结一下:timeStamp是十位之间戳,key是通过随机数取整后从characters中取字母,token应该是从主页面源代码中CSS匹配的token(#token是id选择器)这三个基本上明白了,但是还有一个cookie参数需要逆向,我们找一下:
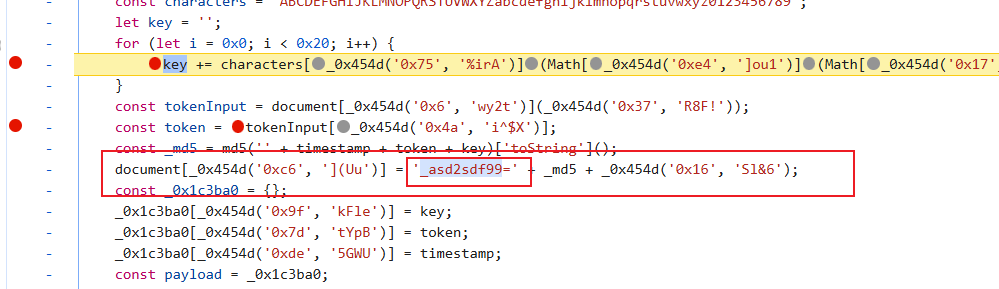
远在天边近在眼前,看名字像md5加密,我们试一试:


ok,标准md5,参数就是刚才几个参数拼接,下面开始复现吧:
加密逻辑复现
导入crypto-js库然后扣下来网页的代码,token先写死看看能不能出值:
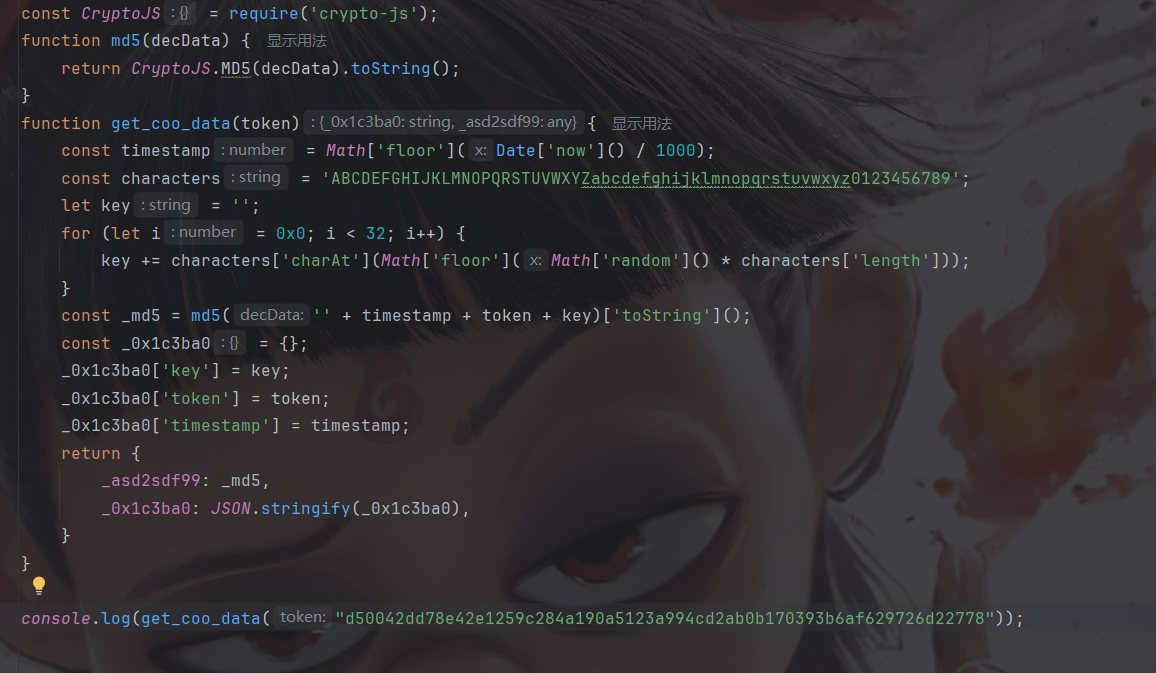
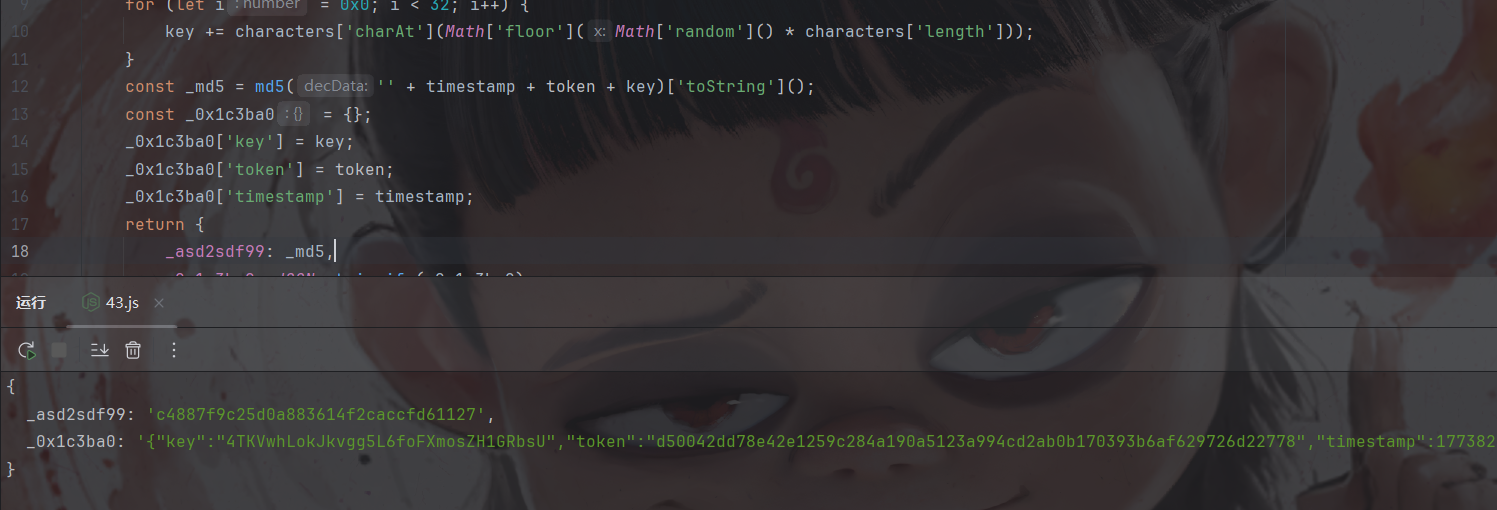
出值了,大家也可以将时间戳和token以及key和网页写的一样然后运行看看结果一样不,这里就不展示了,然后我们看看token是否真是首页获取的:
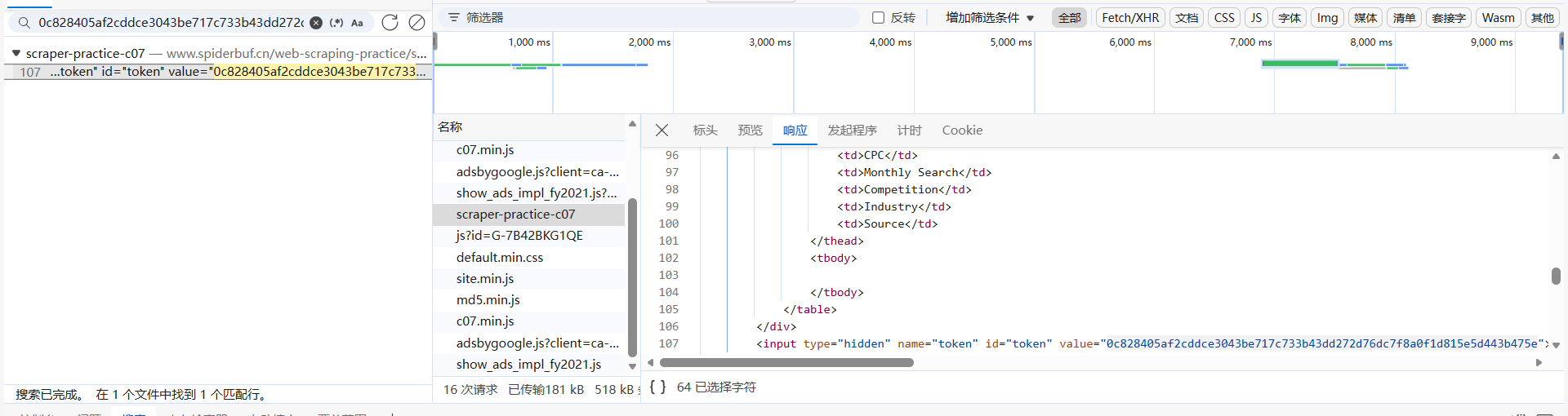
还真是,那就用DrissionPage拿一下token
py调用
python
import execjs
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
from DrissionPage.common import By
def get_token():
# 1. 创建配置对象,启用无头模式
co = ChromiumOptions()
co.headless() # 启用无头模式
dp = ChromiumPage(addr_or_opts=co)
dp.get('https://www.spiderbuf.cn/web-scraping-practice/scraper-practice-c07')
# time.sleep(1.5)
token_ele = dp.ele((By.XPATH, '//main/div[2]/input'))
token_data = token_ele.attr('value')
dp.quit()
return token_data
def get_params(token):
with open('xxx.js', 'r', encoding='utf-8') as f:
js_code = f.read()
js_code = execjs.compile(js_code)
return js_code.call('get_coo_data', token)
def get_data(_asd2sdf99, js_data):
cookies = {
'_asd2sdf99': _asd2sdf99,
}
headers = {
'origin': 'https://www.spiderbuf.cn',
'referer': 'https://www.spiderbuf.cn/web-scraping-practice/scraper-practice-c07',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.0.0',
}
data = js_data
response = requests.post(
'https://www.spiderbuf.cn/web-scraping-practice/scraper-practice-c07',
cookies=cookies,
headers=headers,
data=data,
)
return response.text
def main():
token = get_token()
params = get_params(token)
return get_data(params['_asd2sdf99'], params['_0x1c3ba0'])
if __name__ == '__main__':
print(main())result:
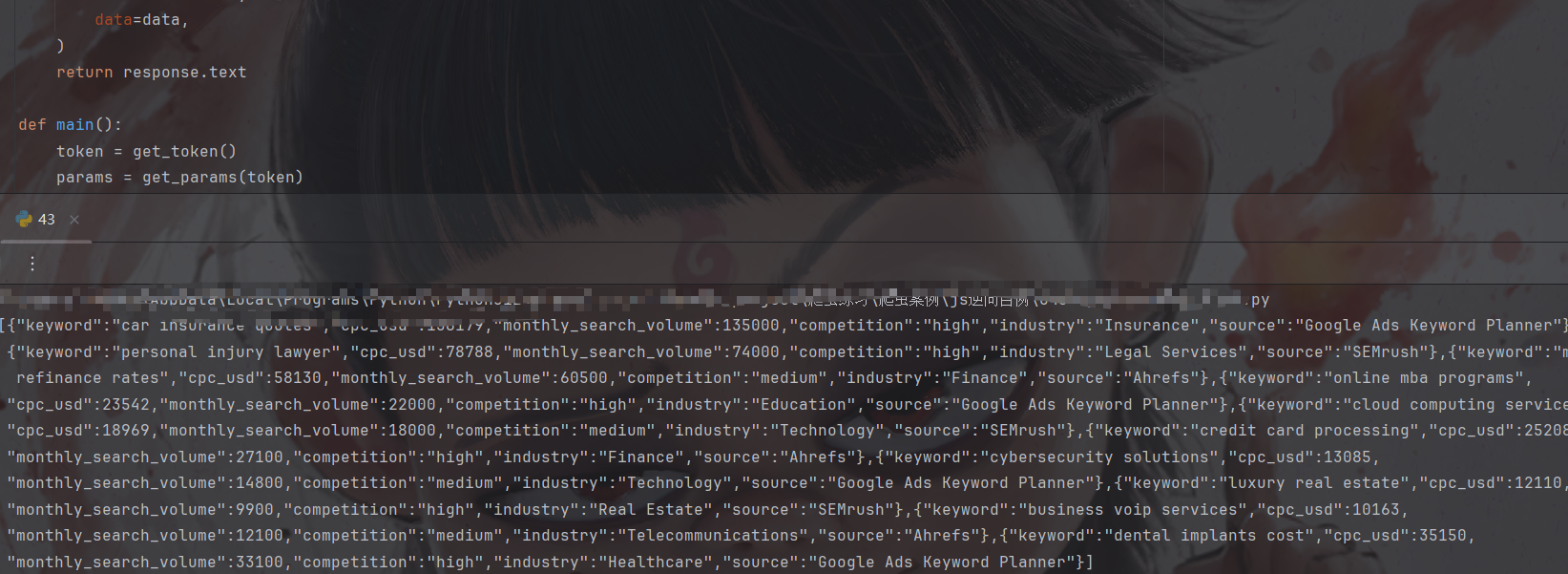
拿下
小结
文章比较简单,小白可以先自行练习一下,如有问题请及时提出加油加油