
已在GitHub开源与本博客同步的YOLOv8_RDKX5_object_pose项目,地址:https://github.com/A7bert777/YOLOv8_RDKX5_object_pose
详细使用教程,可参考README.md或参考本博客第八章 模型部署
注:本文是以sunrise5 SoC进行示例,旭日其他系列SoC的部署流程也基本一致,如需帮助,可通过Github仓库的 README.md 沟通。
文章目录
- 一、项目回顾
- 二、文件梳理
- 三、模型训练
- 四、PT转ONNX
- 五、ONNX转bin-Dokcer容器配置
- 六、ONNX转bin-OE工具链配置
- 七、容器内ONNX量化bin
- [八、RDK X5边缘模型部署](#八、RDK X5边缘模型部署)
一、项目回顾
博主之前主要使用瑞芯微、昇腾系列的SoC及对应生态,现在逐渐转向地平线/地瓜系列,博主本人使用的是RDK X5开发套件,如下图所示,SoC为sunrise5,但发现CSDN上目前没有什么比较详细的免费文章与开源项目供大家入手,因此自己尝试进行完整流程的部署,遂以此文分享,供大家一起学习。

博主之前有写过在华为Ascend、瑞芯微RK系列SoC上的YOLOv8目标检测&图像分割、YOLOv10目标检测、MoblieNetv2图像分类的模型训练、转换、部署文章,感兴趣的小伙伴可以了解下:
【YOLOv8seg部署至RDK X5】模型训练→转换bin→Sunrise 5部署
【YOLOv8部署至RDK X5】模型训练→转换bin→Sunrise 5部署
【YOLOv8部署至Ascend 310B】模型训练→转换om→310B部署
【YOLO11-obb部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLO11部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv10部署RK3588】模型训练→转换rknn→部署流程
【YOLOv8-obb部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8-pose部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8seg部署RK3588】模型训练→转换rknn→部署全流程
【YOLOv8部署至RK3588】模型训练→转换rknn→部署全流程
【YOLOv7部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv6部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv5部署至RK3588】模型训练→转换RKNN→开发板部署
【MobileNetv2图像分类部署至RK3588】模型训练→转换rknn→部署流程
【ResNet50图像分类部署至RK3588】模型训练→转换RKNN→开发板部署
YOLOv8n部署RK3588开发板全流程(pt→onnx→rknn模型转换、板端后处理检测)
二、文件梳理
之前博主发布过YOLOv8转RKNN模型并在开发板上部署的流程,现在尝试在地瓜的RDK X5 开发板上,使用旭日sunrise5进行YOLOv8实例分割模型的部署。
OK,进入正题,模型转换需要以下工具:
第一个文件:github上ultralytics的yolov8项目
第二个文件:github上地瓜的rdk_model_zoo仓库
第三个文件:博主个人Github仓库:YOLOv8_RDKX5_object_pose
三、模型训练
YOLOv8的模型训练环境配置、训练步骤,网上的很多相关教程很多,基础不多叙述,大家可以直接参考其他文章
python
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8-pose.yaml") # 从头开始构建新模型
#model = YOLO("yolov8n.pt") # 加载预训练模型(推荐用于训练)
# Use the model
# 以下设置最好不要改动!!!可能会出现关键点漂移的问题
results = model.train(
data="knob-pose.yaml",
epochs=300,
batch=4,
augment=False, # 关闭所有数据增强
degrees=0, # 旋转角度=0
translate=0, # 平移=0
scale=0, # 缩放=0
shear=0, # 剪切=0
flipud=0, # 上下翻转概率=0
fliplr=0 # 左右翻转概率=0
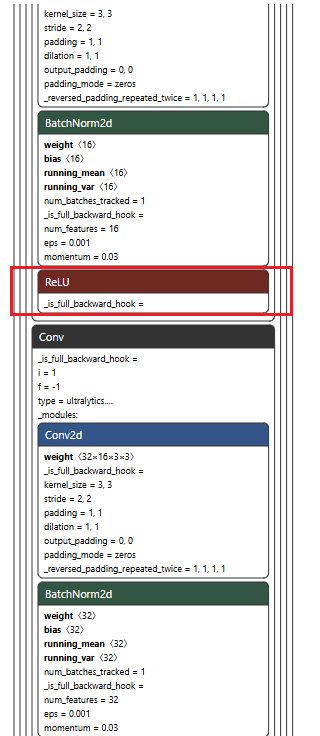
)训练完成后,在当前路径下的runs/pose下生成我们的best.pt,我将其重命名为yolov8npose_knob.pt,博主比较喜欢实用ReLU激活函数,因此netron打开模型后如下所示:
将best.pt重命名为yolov8npose_knob.pt,如下所示:
四、PT转ONNX
先在项目下创建转换脚本export_monkey_patch.py,内容如下所示,直接复制:
python
#!/user/bin/env python
# Copyright (c) 2025, WuChao D-Robotics.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# 注意: 此程序在Ultralytics模型的训练环境中运行
# Attention: This program runs on Ultralytics training Environment.
import argparse
from ultralytics import YOLO
from ultralytics.nn.modules.head import Detect, v10Detect, Segment, OBB, Pose, Classify
# from ultralytics.nn.modules.block import Attention, AAttn
import torch
import types
import os
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--pt', type=str, default='./yolo11n.pt', help='path to *.pt model.')
parser.add_argument('--optse', type=int, default=11, help='opset version.')
opt = parser.parse_args()
# Init Ultralytics YOLO Model
m = YOLO(opt.pt)
# Replace some efficient modules
modelZooOptimizer(m.model.model)
# Export to ONNX
m.export(format='onnx', simplify=False, opset=11)
def modelZooOptimizer(model): # Monkey Patch
for name, child in model.named_children():
# print(name)
if type(child) == Classify:
child.forward = types.MethodType(Classify_forward, child)
print("\033[1;31m" + f"[Cauchy] Replaced Classify_forward in {name}" + "\033[0m")
elif type(child) == Detect:
child.forward = types.MethodType(Detect_forward, child)
print("\033[1;31m" + f"[Cauchy] Replaced Detect_forward in {name}" + "\033[0m")
elif type(child) == v10Detect:
child.forward = types.MethodType(v10Detect_forward, child)
print("\033[1;31m" + f"[Cauchy] Replaced v10Detect_forward in {name}" + "\033[0m")
elif type(child) == Segment:
child.forward = types.MethodType(Segment_forward, child)
print("\033[1;31m" + f"[Cauchy] Replaced Segment_forward in {name}" + "\033[0m")
elif type(child) == Pose:
child.forward = types.MethodType(Pose_forward, child)
print("\033[1;31m" + f"[Cauchy] Replaced Pose_forward in {name}" + "\033[0m")
elif type(child) == OBB:
child.forward = types.MethodType(OBB_forward, child)
print("\033[1;31m" + f"[Cauchy] Replaced OBB_forward in {name}" + "\033[0m")
# elif type(child) == AAttn:
# child.forward = types.MethodType(AAttn_forward, child)
# print("\033[1;31m" + f"[Cauchy] Replaced AAttn_forward in {name}" + "\033[0m")
# elif type(child) == Attention:
# child.forward = types.MethodType(Attention_forward, child)
# print("\033[1;31m" + f"[Cauchy] Replaced Attention_forward in {name}" + "\033[0m")
modelZooOptimizer(child)
def Attention_forward(self, x):
# Effieicient for Bayes-e BPU
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim * 2 + self.head_dim, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.permute(0, 3, 1, 2).contiguous() # CHW2HWC like
max_attn = attn.max(dim=1, keepdim=True).values
exp_attn = torch.exp(attn - max_attn)
sum_attn = exp_attn.sum(dim=1, keepdim=True)
attn = exp_attn / sum_attn
attn = attn.permute(0, 2, 3, 1).contiguous() # HWC2CHW like
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
x = self.proj(x)
return x
def AAttn_forward(self, x):
# Effieicient for Bayes-e BPU
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x).flatten(2).transpose(1, 2)
if self.area > 1:
qkv = qkv.reshape(B * self.area, N // self.area, C * 3)
B, N, _ = qkv.shape
q, k, v = (qkv.view(B, N, self.num_heads, self.head_dim * 3).permute(0, 2, 3, 1).split([self.head_dim, self.head_dim, self.head_dim], dim=2))
attn = (q.transpose(-2, -1) @ k) * (self.head_dim**-0.5)
attn = attn.permute(0, 3, 1, 2).contiguous() # CHW2HWC like
max_attn = attn.max(dim=1, keepdim=True).values
exp_attn = torch.exp(attn - max_attn)
sum_attn = exp_attn.sum(dim=1, keepdim=True)
attn = exp_attn / sum_attn
attn = attn.permute(0, 2, 3, 1).contiguous() # HWC2CHW like
x = v @ attn.transpose(-2, -1)
x = x.permute(0, 3, 1, 2)
v = v.permute(0, 3, 1, 2)
if self.area > 1:
x = x.reshape(B // self.area, N * self.area, C)
v = v.reshape(B // self.area, N * self.area, C)
B, N, _ = x.shape
x = x.reshape(B, H, W, C).permute(0, 3, 1, 2).contiguous()
v = v.reshape(B, H, W, C).permute(0, 3, 1, 2).contiguous()
x = x + self.pe(v)
return self.proj(x)
def Classify_forward(self, x):
# Effieicient for Bernoulli2, Bayes, Bayes-e, Nash-{e/m/p} BPU
x = torch.cat(x, 1) if isinstance(x, list) else x
return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
def Detect_forward(self, x):
# Effieicient for Bernoulli2, Bayes, Bayes-e, Nash-{e/m/p} BPU
result = []
for i in range(self.nl):
result.append(self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous()) # cls
result.append(self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous()) # bbox
return result
def v10Detect_forward(self, x):
# Effieicient for Bernoulli2, Bayes, Bayes-e, Nash-{e/m/p} BPU
result = []
for i in range(self.nl):
result.append(self.one2one_cv3[i](x[i]).permute(0, 2, 3, 1).contiguous()) # cls
result.append(self.one2one_cv2[i](x[i]).permute(0, 2, 3, 1).contiguous()) # bbox
return result
def Segment_forward(self, x):
# Effieicient for Bernoulli2, Bayes, Bayes-e, Nash-{e/m/p} BPU
result = []
for i in range(self.nl):
result.append(self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous()) # cls
result.append(self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous()) # bbox
result.append(self.cv4[i](x[i]).permute(0, 2, 3, 1).contiguous()) # proto weights
result.append(self.proto(x[0]).permute(0, 2, 3, 1).contiguous()) # proto mask
return result
def Pose_forward(self, x):
# Effieicient for Bernoulli2, Bayes, Bayes-e, Nash-{e/m/p} BPU
result = []
for i in range(self.nl):
result.append(self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous()) # cls
result.append(self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous()) # bbox
result.append(self.cv4[i](x[i]).permute(0, 2, 3, 1).contiguous()) # kpts
return result
def OBB_forward(self, x):
# Effieicient for Bernoulli2, Bayes, Bayes-e, Nash-{e/m/p} BPU
# TODO: Test and PostProcess Code in Model Zoo.
result = []
for i in range(self.nl):
result.append(self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous()) # cls
result.append(self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous()) # bbox
result.append(self.cv4[i](x[i]).permute(0, 2, 3, 1).contiguous()) # theta logits
return result
if __name__ == '__main__':
main()然后将yolov8npose_knob.pt也复制到ultralytics同级目录下,这样pt模型和转换脚本在同一目录下,如下所示:
执行命令,注意模型名改成你自己的:
bash
python export_monkey_patch.py --pt yolov8npose_knob.pt结果如下所示:

此时可以看到,在pt模型同路径下生成了对应的onnx模型:
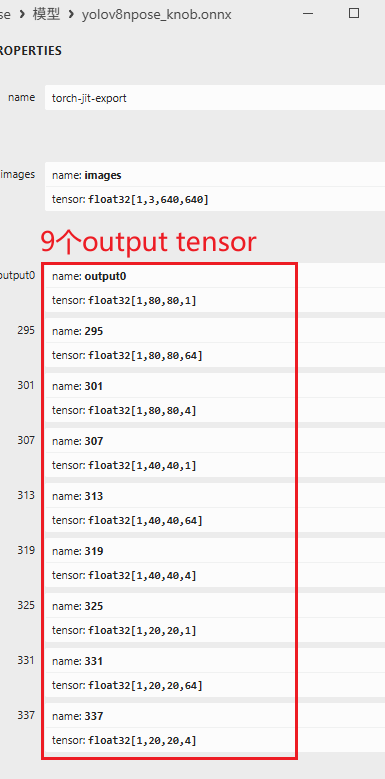
可以看到,转出的onnx模型已经被改成9个输出tensor了,用netron打开如下所示:
五、ONNX转bin-Dokcer容器配置
--------------------------------这一步骤全部在PC端的虚拟机中完成--------------------------------
①:docker镜像文件下载:
bash
wget -c ftp://x5ftp@vrftp.horizon.ai/OpenExplorer/v1.2.8_release/docker_openexplorer_ubuntu_20_x5_cpu_v1.2.8.tar.gz --ftp-password=x5ftp@123$%如下所示:

②:加载docke镜像:
bash
sudo docker load -i docker_openexplorer_ubuntu_20_x5_cpu_v1.2.8.tar.gz如下所示:

③:查看确定镜像已加载:
bash
docker images
六、ONNX转bin-OE工具链配置
--------------------------------这一步骤同样全部在PC端的虚拟机中完成--------------------------------
①:下载地瓜所需的OE工具链
bash
wget -c ftp://x5ftp@vrftp.horizon.ai/OpenExplorer/v1.2.8_release/horizon_x5_open_explorer_v1.2.8-py310_20240926.tar.gz --ftp-password=x5ftp@123$%如下所示:

下载完成后解压,文件夹内容如下所示,其中run_docker.sh是我们的启动容器的脚本:

②:打开run_docker.sh,在version参数后加-py310,如下所示:
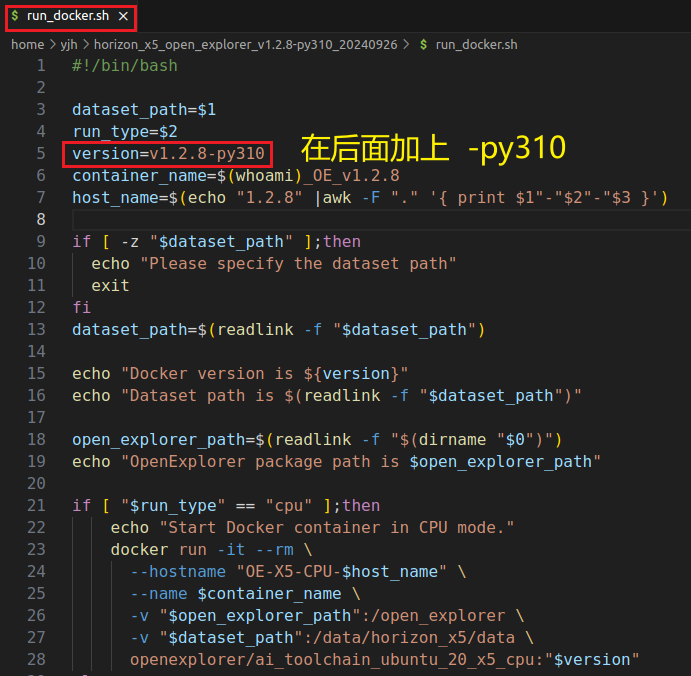
修改后完整的run_docker.sh如下所示:
bash
#!/bin/bash
dataset_path=$1
run_type=$2
version=v1.2.8-py310
container_name=$(whoami)_OE_v1.2.8
host_name=$(echo "1.2.8" |awk -F "." '{ print $1"-"$2"-"$3 }')
if [ -z "$dataset_path" ];then
echo "Please specify the dataset path"
exit
fi
dataset_path=$(readlink -f "$dataset_path")
echo "Docker version is ${version}"
echo "Dataset path is $(readlink -f "$dataset_path")"
open_explorer_path=$(readlink -f "$(dirname "$0")")
echo "OpenExplorer package path is $open_explorer_path"
if [ "$run_type" == "cpu" ];then
echo "Start Docker container in CPU mode."
docker run -it --rm \
--hostname "OE-X5-CPU-$host_name" \
--name $container_name \
-v "$open_explorer_path":/open_explorer \
-v "$dataset_path":/data/horizon_x5/data \
openexplorer/ai_toolchain_ubuntu_20_x5_cpu:"$version"
else
echo "Start Docker container in GPU mode."
docker run -it --rm \
--hostname "OE-X5-GPU-$host_name" \
--name $container_name \
--gpus all \
--shm-size="15g" \
-v "$open_explorer_path":/open_explorer \
-v "$dataset_path":/data/horizon_x5/data \
openexplorer/ai_toolchain_ubuntu_20_x5_gpu:"$version"
fi③:在home下创建一个容器挂载时的文件夹:RDK_X5_related
④:把你转换得到的onnx模型放到 RDK_X5_related 文件夹中
请添加图片描述
⑤:在 RDK_X5_related 文件夹下再创建一个 cal_data_knob 文件夹,用于存放量化校正数据集
⑥:在数据集中挑选一部分图片,大概50张,放到 cal_data_knob (这里可以对应你自己创建的文件夹名称)文件夹下,如下所示:

⑦:在 RDK_X5_related 文件夹下再创建一个 yolov8_config.yaml 文件:
⑧:修改 yolov8_config.yaml 内容,设置好你的onnx模型名以及bin模型名前缀,尽量保持一致,如下所示:

yolov8_config.yaml 代码内容如下所示:
yaml
model_parameters:
# 你的 ONNX 模型文件名
onnx_model: 'yolov8npose_knob.onnx'
# RDK X5 的 BPU 微架构必须指定为 bayes-e
march: 'bayes-e'
layer_out_dump: False
# 编译产物的工作目录
working_dir: 'model_output'
# 生成的 bin 模型名称前缀
output_model_file_prefix: 'yolov8npose_knob'
input_parameters:
input_name: ""
# 推荐在板端实际推理时使用的输入格式(NV12 内存占用小,BPU 处理最快)
input_type_rt: 'nv12'
# 你在 PyTorch 训练时的图像格式和排布
input_type_train: 'rgb'
input_layout_train: 'NCHW'
# 归一化方式。YOLOv8 默认是将 0-255 的像素值除以 255
norm_type: 'data_scale'
scale_value: 0.003921568627451 # 1 / 255.0 的精确值
calibration_parameters:
# 刚才存放校准图片的相对路径
cal_data_dir: './cal_data_knob'
cal_data_type: 'float32'
# 开启自动预处理,工具链会自动用 OpenCV 把你的图片 resize 到 640x640
preprocess_on: True
# 量化校准策略,默认使用 max 即可
calibration_type: 'max'
compiler_parameters:
# 编译优化策略:latency 优先保证单帧推理延迟最低
compile_mode: 'latency'
debug: False
# 开启最高级别的图优化
optimize_level: 'O3'⑨:在horizon_x5_open_explorer_v1.2.8-py310_20240926路径下执行容器运行脚本:
bash
sudo bash run_docker.sh /home/yjh/RDK_X5_related cpu如下所示:
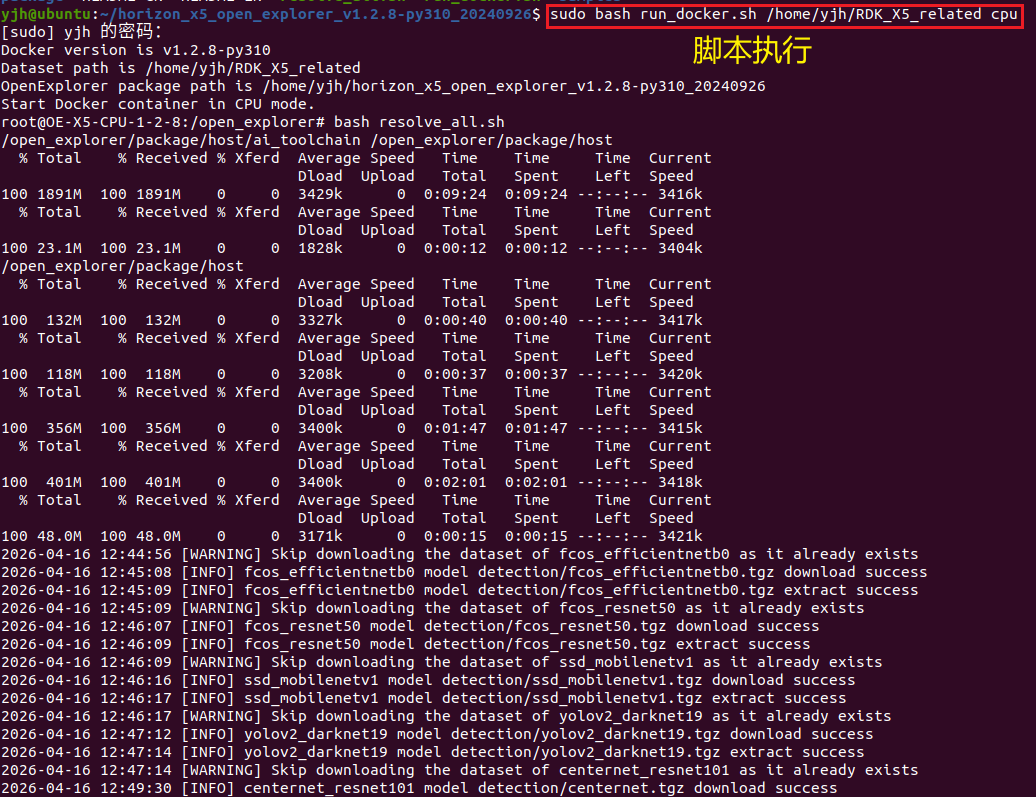
虚拟机内执行完脚本后进入容器了,ls结果:

进入容器后进入挂载路径 /data/horizon_x5/data :

可以看到挂载路径下的内容和我们home下的 rdk_x5_related 文件夹下的内容是一模一样的:

七、容器内ONNX量化bin
在完成第六章的最后一步后,直接在容器内的 /data/horizon_x5/data 路径下,调用OE工具链检查onnx模型格式是否正确,注意复制代码时候要改成自己的模型名,如下所示:
一、ONNX模型检查
bash
hb_mapper checker --model-type onnx --march bayes-e --model yolov8npose_knob.onnx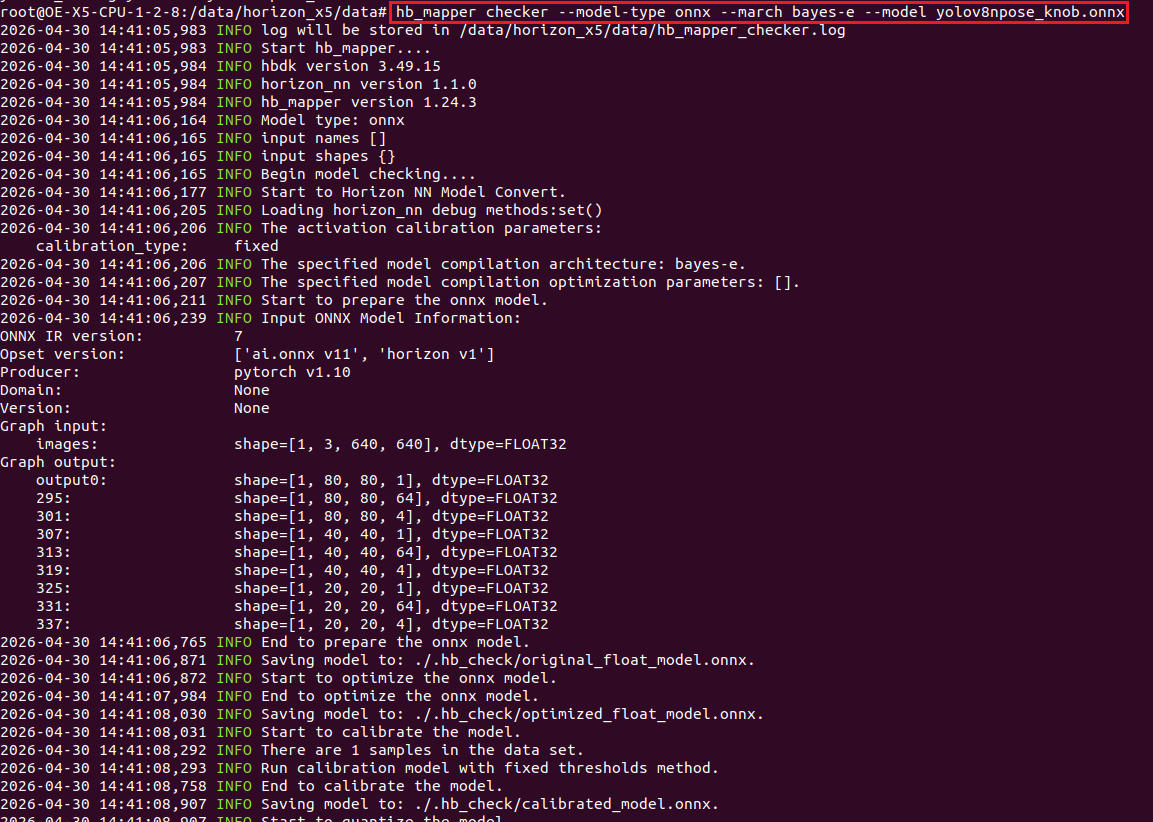
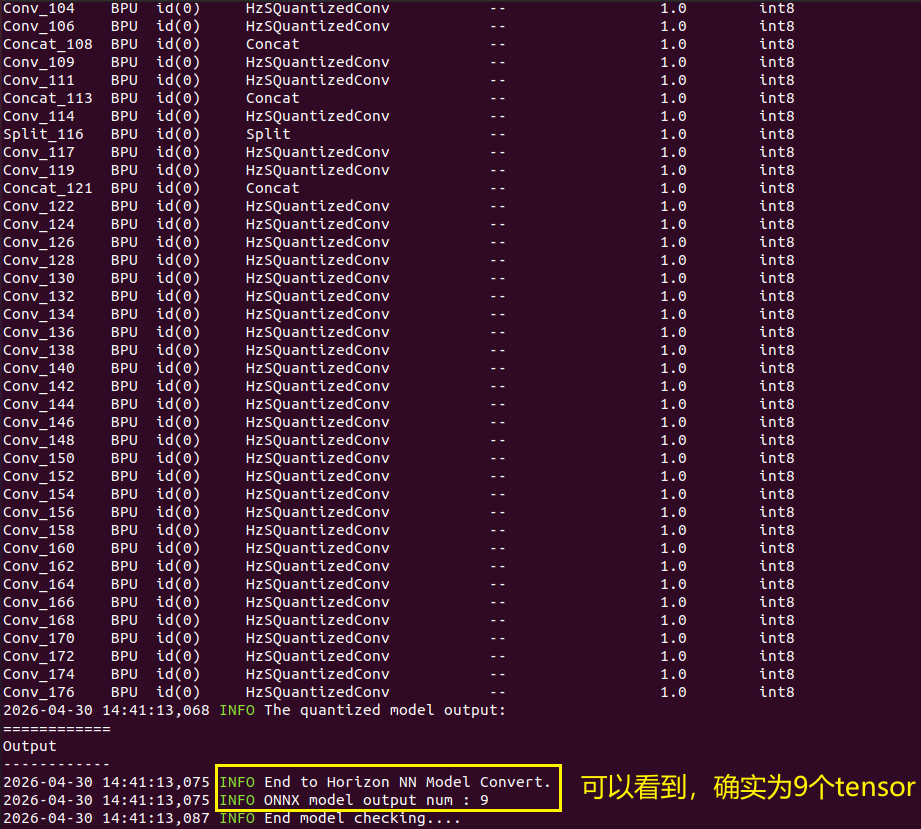
二、开始执行模型量化:
bash
hb_mapper makertbin --model-type onnx --config yolov8_config.yaml如下所示:
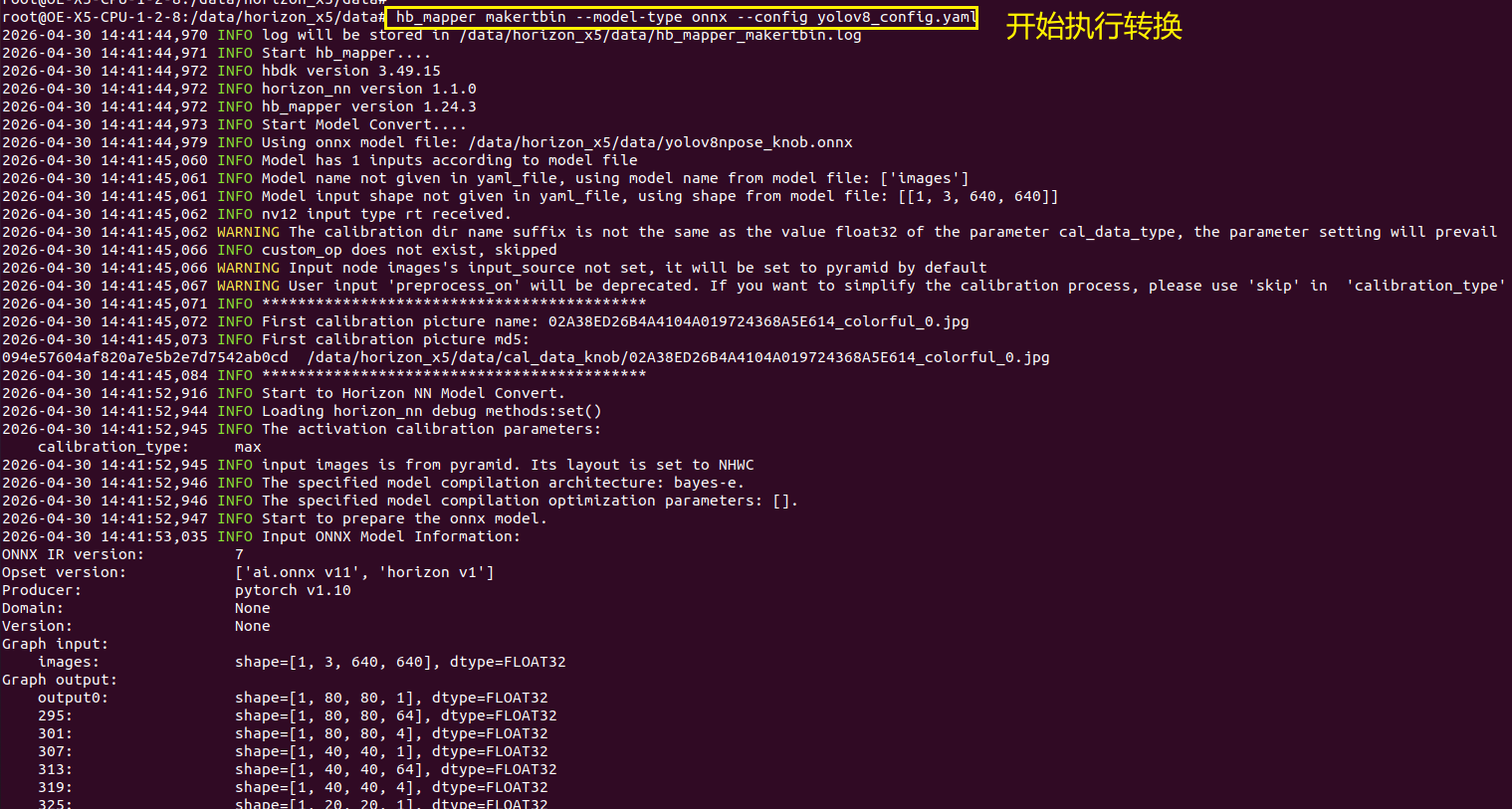
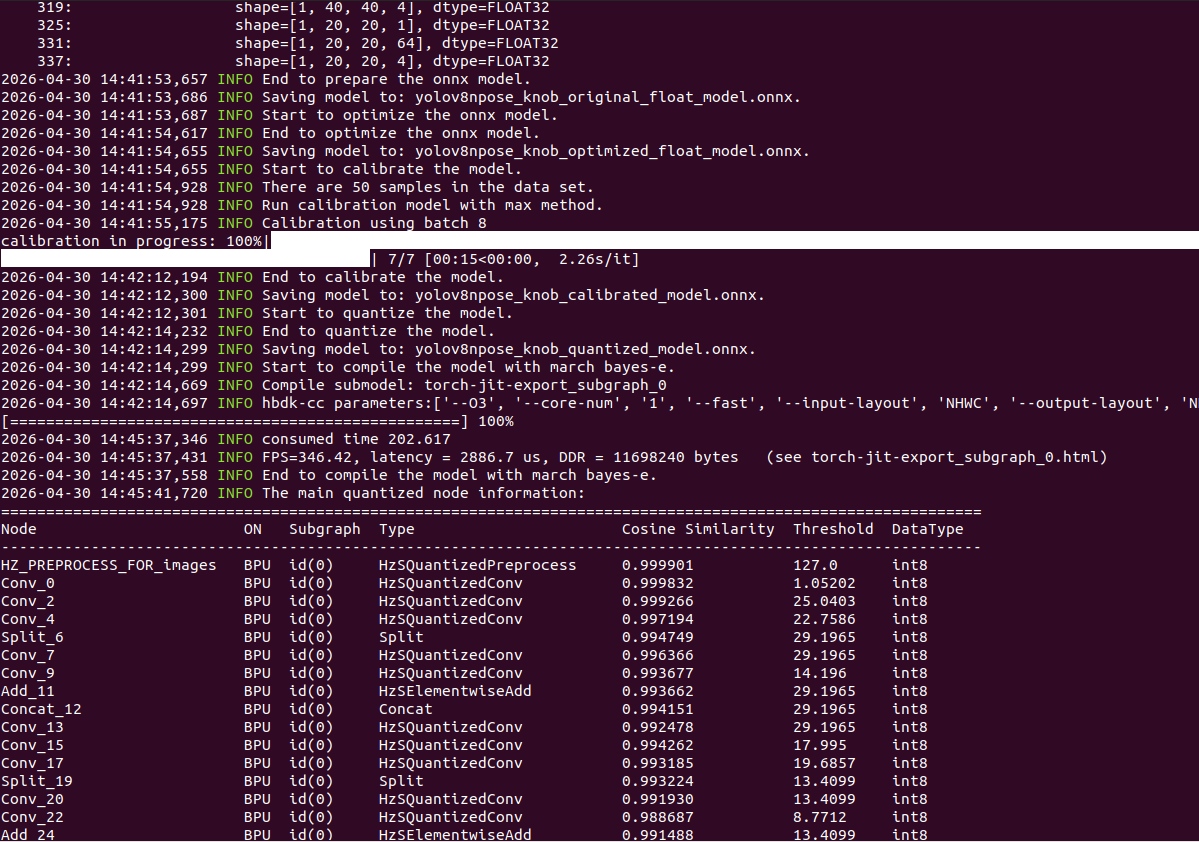
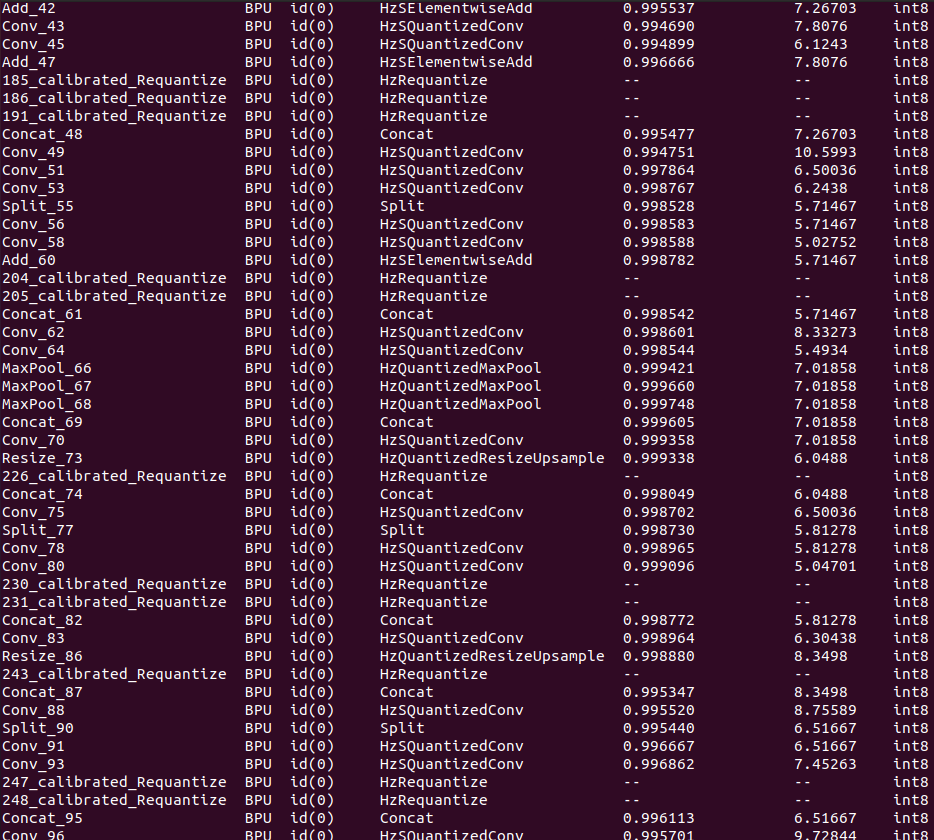
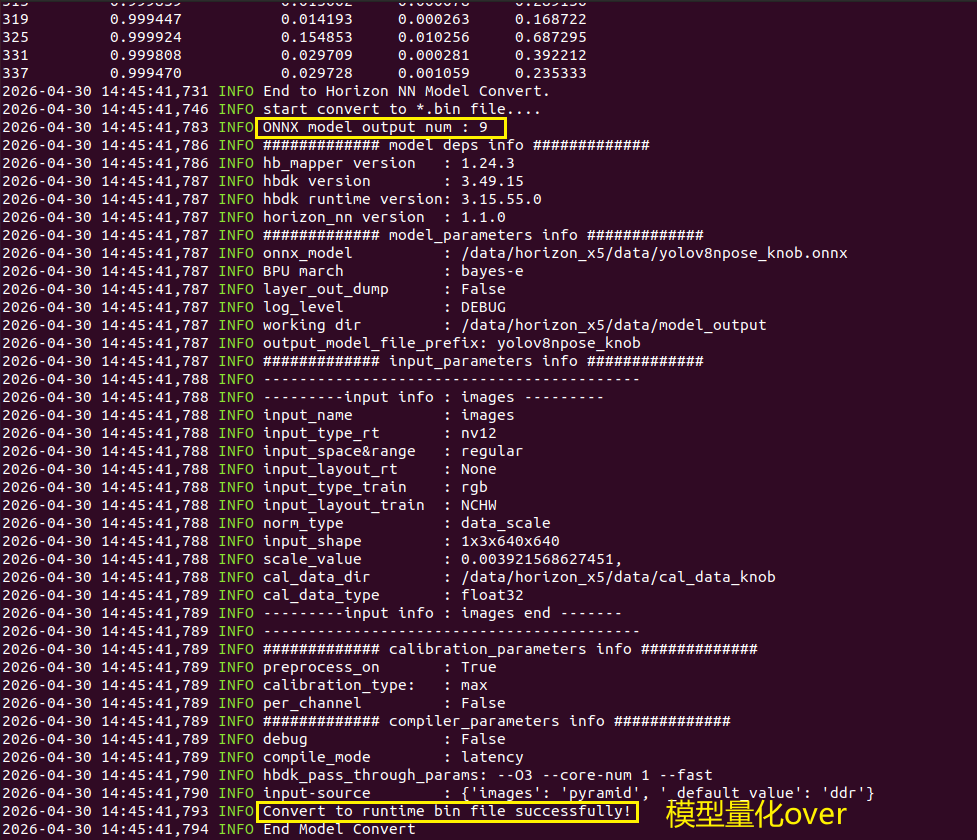
↑可以看到终端输出,模型量化成功
此时,量化好后的bin文件后放在自动生成的RDK_X5_related/model_output文件夹下
三、在量化生成的.bin模型基础上,剪除其反量化节点:
注意,反量化节点可能有点刚接触的同学不太熟悉,底层数学原理就不一一介绍了,直接按博主流程操作即可
1、查询.bin模型中能够删除的反量化节点名称:
bash
hb_model_modifier yolov8npose_knob.bin如下所示:

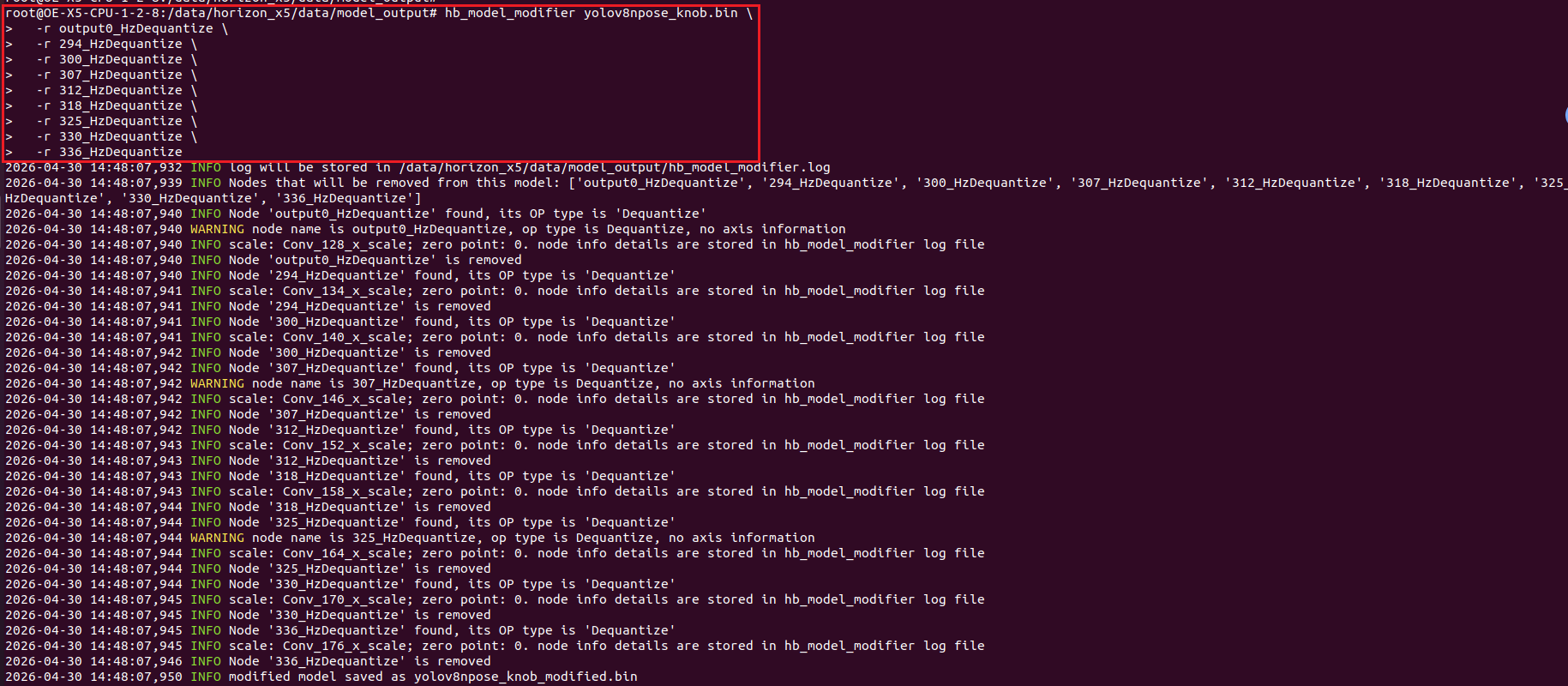
2、执行删除命令,注意要把模型名以及对应的节点名改成自己的:
bash
hb_model_modifier yolov8npose_knob.bin \
-r output0_HzDequantize \
-r 294_HzDequantize \
-r 300_HzDequantize \
-r 307_HzDequantize \
-r 312_HzDequantize \
-r 318_HzDequantize \
-r 325_HzDequantize \
-r 330_HzDequantize \
-r 336_HzDequantize如下所示:
↑可以看到,已经生成了yolov8npose_knob_modified.bin,这里modified的意思就是指去除了反量化节点后的.bin模型,而且这个xxx_modified.bin模型同样保存在 model_output 文件夹下:
然后现在可以把yolov8npose_knob.bin和yolov8npose_knob_modified.bin这两个模型都复制到PC端本地了,然后上传到RDK X5开发板上
八、RDK X5边缘模型部署
在完成上述流程后,我们已经得到了符合要求的.bin以及xxx_modified.bin模型了,此时打开第三个项目文件,即博主的个人仓库,我已经把自己的yolov8npose_knob.bin和yolov8npose_knob_modified.bin这两个模型放到了Github项目的model文件夹下、测试图片放到inputimage文件夹下,大家 git clone 后可直接先把编译的相关内容删掉然后重新编译,再用我的模型和图片直接运行测试
如果项目对大家有所帮助,希望点个免费的小星星:
git clone后把项目复制到开发板上,按如下流程操作:
如果需要直接测试博主的模型效果,如下所示:
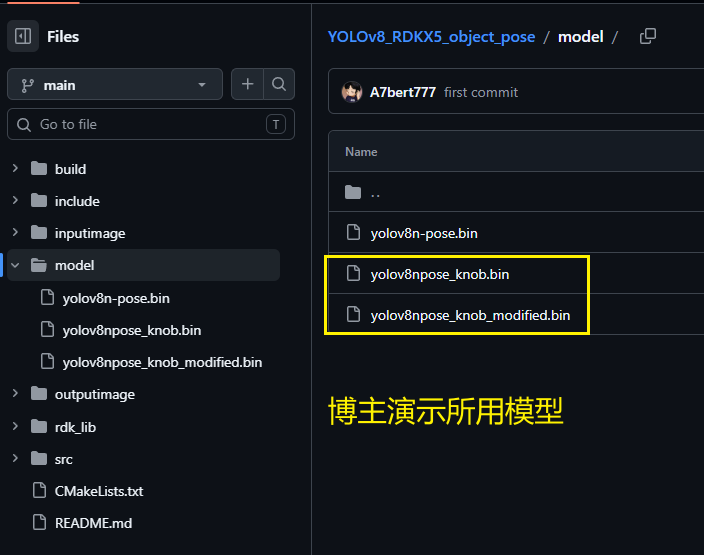
可以在进入build文件夹,直接执行:
bash
./rdkx5_yolov8_pose查看运行结果。
如果使用自己的模型,修改流程如下所示:
①:cd build,删除所有build文件夹下的内容
②:cd src 修改main.cc,修改main函数中的如下几处内容:
先修改模型路径名、输入图片文件夹路径、输出图片文件夹路径、以及REMOVE_DEQUANT_NODE参数
这里着重说一下REMOVE_DEQUANT_NODE参数,
如果你加载的模型你是带反量化节点的模型,即xxx.bin,则REMOVE_DEQUANT_NODE设置为0或1都可以,
如果加载的是xxx_modified.bin,则REMOVE_DEQUANT_NODE必须设置为1
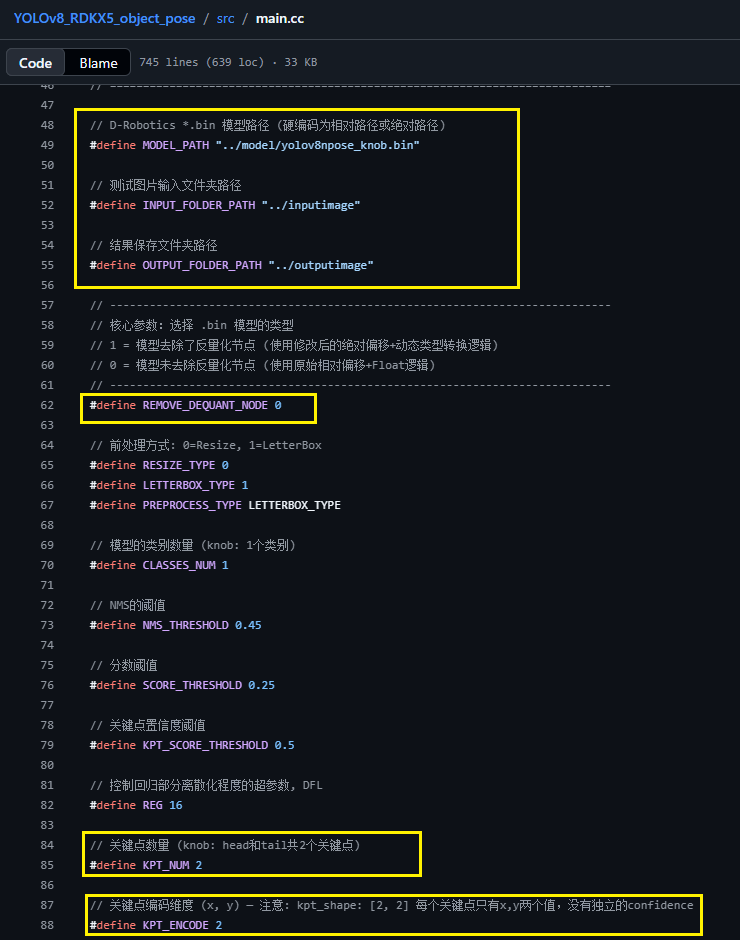
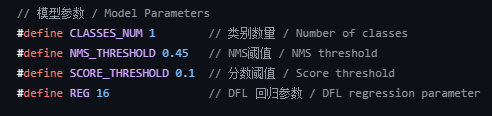
再修改CLASSES_NUM、NMS阈值、得分阈值:
再定义关键点名称:

修改完成后,保存main.cc
再删除inputimage和outputimage下的所有图片,然后将你要批量检测的图片放到inputimage下后,
在build路径下执行如下命令:
bash
cmake ..
bash
make
bash
./rdkx5_yolov8_pose终端结果如下所示:
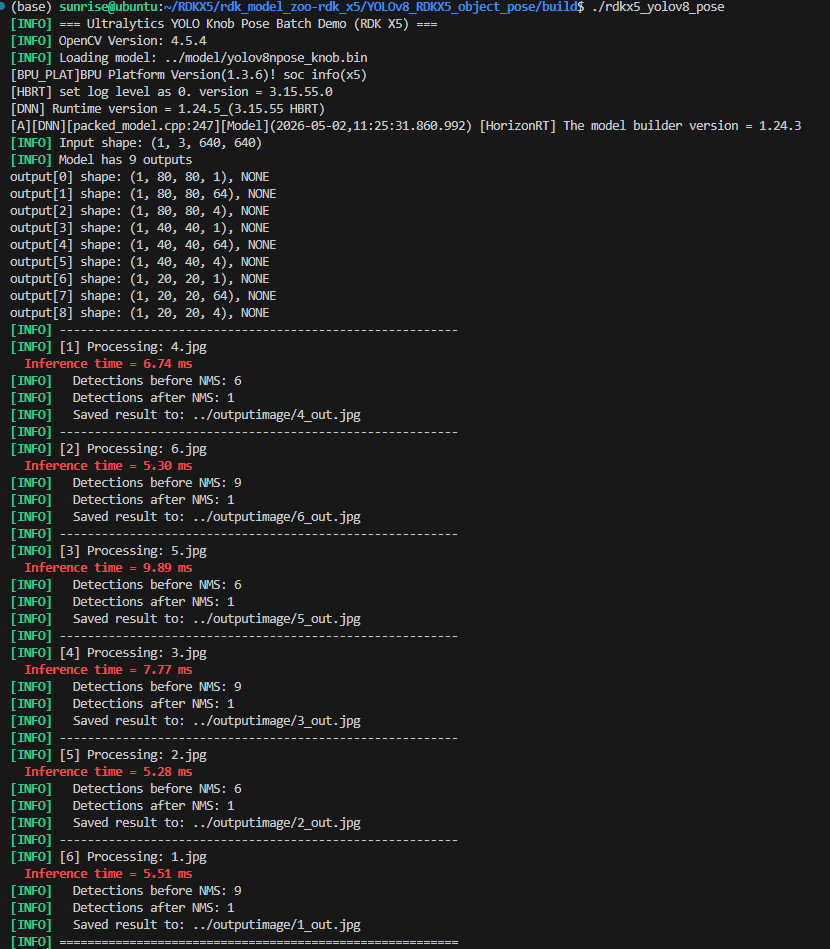
注意,此时使用的是xxx.bin模型跑出的结果。
现在换成xxx_modified.bin模型后,修改REMOVE_DEQUANT_NODE参数后再次make后运行,如下所示:
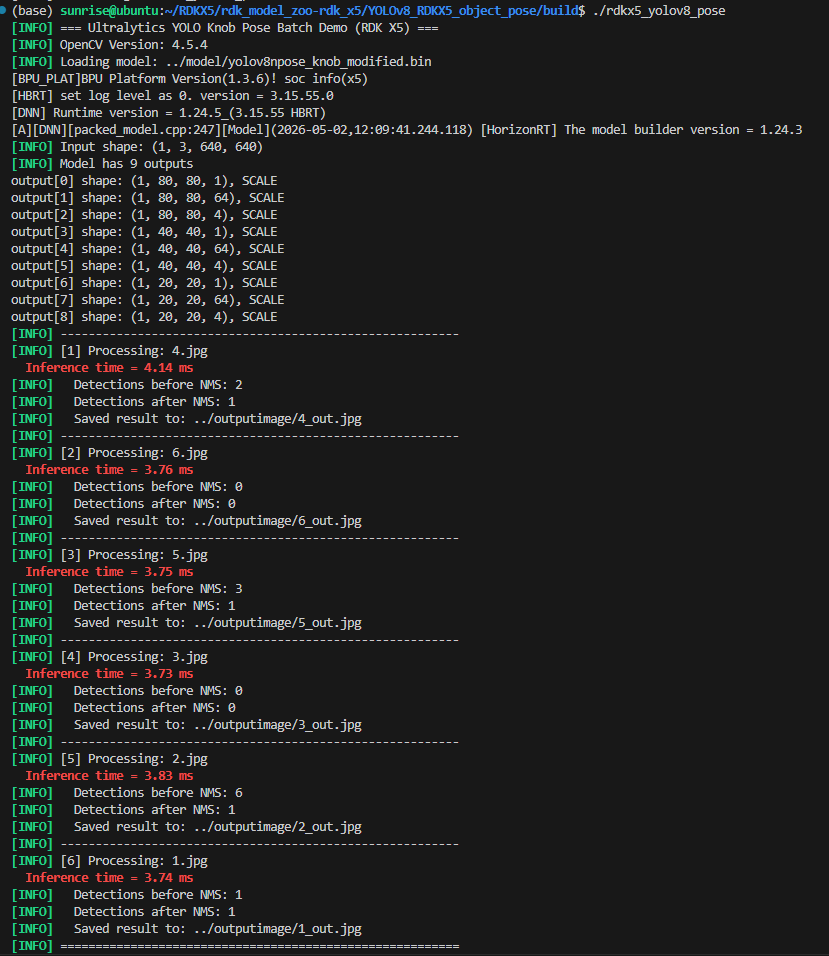
两次结果对比可以明显看到,去除了反量化节点后的xxx_modified.bin模型的推理速度明显要快于xxx.bin模型,所以说xxx.bin模型和xxx_modified.bin模型都可以用,但是xxx_modified.bin模型对RDKX5上的Sunrise5 SoC更快,优化了大量的总线带宽被严重挤占的问题,对于开发板整体运行情况有较大改善。
以下是博主在RDKX5上完成推理自测后的结果图:
原图1:

结果图1:

原图2:

结果图2:

原图3:

结果图3:

上述即博主此次更新的YOLOv8pose部署地瓜RDK X5适配Sunrise 5 SoC的全部流程,包含PT转ONNX转.bin/modified.bin的完整步骤,欢迎交流!